18 jul 2025·8 min
Hoe je een mobiele app bouwt voor externe apparaatbewaking
Leer hoe je een mobiele app plant, bouwt en lanceert voor externe apparaatbewaking: architectuur, datastromen, realtime-updates, waarschuwingen, beveiliging en testen.
Leer hoe je een mobiele app plant, bouwt en lanceert voor externe apparaatbewaking: architectuur, datastromen, realtime-updates, waarschuwingen, beveiliging en testen.
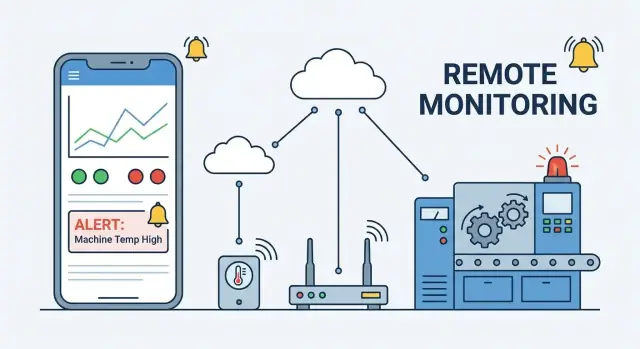
Externe apparaatbewaking betekent dat je kunt zien wat een apparaat doet — en of het gezond is — zonder er fysiek naast te staan. Een mobiele monitoring-app is het “venster” naar een vloot apparaten: hij haalt signalen van elk apparaat binnen, zet ze om in begrijpelijke statusinformatie en stelt de juiste mensen in staat snel te handelen.
Externe monitoring komt overal voor waar apparatuur verspreid of moeilijk bereikbaar is. Typische voorbeelden zijn:
In alle gevallen is de taak van de app om gokken te verminderen en te vervangen door duidelijke, actuele informatie.
Een goede app voor externe apparaatbewaking levert meestal vier basisfuncties:
De beste apps maken het ook eenvoudig om te zoeken en te filteren op locatie, model, ernst of eigenaar — omdat vlootmonitoring minder over één apparaat gaat en meer over prioriteiten.
Voordat je functies bouwt, bepaal wat “betere monitoring” voor je team betekent. Veelvoorkomende succesmetrics zijn:
Wanneer deze metrics verbeteren, rapporteert de monitoring-app niet alleen data — hij voorkomt actief downtime en verlaagt operationele kosten.
Voordat je protocollen kiest of grafieken ontwerpt, bepaal voor wie de app is en wat “succes” op dag één betekent. Remote monitoring-apps falen vaak wanneer ze proberen iedereen met dezelfde workflow tevreden te stellen.
Schrijf 5–10 concrete scenario’s die je app moet ondersteunen, zoals:
Deze scenario’s helpen je voorkomen dat je functies bouwt die er nuttig uitzien maar de responstijd niet verkorten.
Plan minimaal voor:
Must-have: authenticatie + rollen, apparaatinventaris, real-time(achtig) status, basisgrafieken, waarschuwingen + pushmeldingen en een minimaal incidentworkflow (acknowledge/resolve).
Nice-to-have: kaartweergave, geavanceerde analytics, automatiseringsregels, QR-onboarding, in-app chat en aangepaste dashboards.
Kies op basis van wie de telefoon in de praktijk draagt. Als veldtechnici gestandaardiseerd zijn op één OS, begin daar. Als je snel beide nodig hebt, kan een cross-platform aanpak werken — maar houd de MVP-scope klein zodat prestaties en notificatiegedrag voorspelbaar blijven.
Als je het MVP snel wilt valideren, kunnen platforms zoals Koder.ai helpen met het prototypen van een monitoring-UI en backend-workflows vanuit een chatgestuurde specificatie (bijv.: apparaatlijst + apparaatdetail + waarschuwingen + rollen), en daarna itereren richting productie zodra de kernworkflows bewezen zijn.
Voordat je protocollen kiest of dashboards ontwerpt, wees specifiek over welke data er is, waar het vandaan komt en hoe het moet reizen. Een duidelijke “datakaart” voorkomt twee veelvoorkomende fouten: alles verzamelen (en er voor altijd voor betalen), of te weinig verzamelen (en blind zijn tijdens incidenten).
Begin met het opsommen van de signalen die elk apparaat kan produceren en hoe betrouwbaar ze zijn:
Bij elk item noteer je eenheden, verwachte bereiken en wat “slecht” betekent. Dit wordt later de ruggengraat voor waarschuwingsregels en UI-drempels.
Niet alle data verdient realtime levering. Bepaal wat moet bijwerken in seconden (bijv. veiligheidsalarmen, kritieke machine-status), wat kan in minuten (batterij, signaalsterkte) en wat uur/dagelijks kan (gebruikssamenvattingen). Frequentie bepaalt batterijimpact, datakosten en hoe “live” je app aanvoelt.
Een praktische aanpak is tiers te definiëren:
Retentie is een productbeslissing, niet alleen een opslaginstelling. Bewaar ruwe data lang genoeg om incidenten te onderzoeken en fixes te valideren, en downsample daarna naar samenvattingen (min/max/gemiddelde, percentielen) voor trendgrafieken. Voorbeeld: raw 7–30 dagen, uurlijkse aggregaten voor 12 maanden.
Apparaten en telefoons gaan offline. Definieer wat op het apparaat wordt gebufferd, wat mag worden verloren, en hoe vertraagde data in de app wordt gelabeld (bijv. “laatst bijgewerkt 18 min geleden”). Zorg dat tijdstempels van het apparaat komen (of server-side worden gecorrigeerd) zodat geschiedenis na reconnects accuraat blijft.
Een monitoring-app is maar zo betrouwbaar als het systeem erachter. Voor je schermen en dashboards kiest, kies een architectuur die past bij de mogelijkheden van je apparaten, de netwerksituatie en hoe "realtime" je het echt nodig hebt.
Meestal ziet een opzet er zo uit:
Device → (optioneel) Gateway → Cloud backend → Mobile app
Direct-to-cloud apparaten werken het beste wanneer apparaten betrouwbare IP-connectiviteit (Wi‑Fi/LTE) en voldoende stroom/CPU hebben.
Gateway-gebaseerde architecturen passen bij beperkte apparaten of industriële omgevingen.
Een veelvoorkomende verdeling is MQTT voor device→cloud, en WebSockets + REST voor cloud→mobile.
[Device Sensors]
|
| telemetry (MQTT/HTTP)
v
[Gateway - optional] ---- local protocols (BLE/Zigbee/Serial)
|
| secure uplink (MQTT/HTTP)
v
[Cloud Ingest] -\u003e [Rules/Alerts] -\u003e [Time-Series Storage]
|
| REST (queries/commands) + WebSocket (live updates)
v
[Mobile App Dashboard]
Kies de eenvoudigste architectuur die nog werkt onder je slechtste netwerkcondities — ontwerp vervolgens alles (datamodel, waarschuwingen, UI) rondom die keuze.
Een monitoring-app is alleen zo betrouwbaar als de manier waarop je apparaten identificeert, hun status volgt en hun “leven” beheert van onboarding tot pensioen. Goed lifecyclebeheer voorkomt mysterie-apparaten, dubbele records en verouderde statusschermen.
Begin met een duidelijke identiteitsstrategie: elk apparaat moet een unieke ID hebben die nooit verandert. Dit kan een fabrieksserienummer zijn, een veilige hardware-identifier of een gegenereerde UUID die op het apparaat is opgeslagen.
Tijdens provisioning leg je minimale maar nuttige metadata vast: model, eigenaar/site, installatiedatum en mogelijkheden (bv. heeft GPS, ondersteunt OTA-updates). Houd provisioning-flows eenvoudig — scan een QR-code, claim het apparaat en bevestig dat het in de vloot verschijnt.
Definieer een consistent statemodel zodat de mobiele app realtime apparaatstatus kan tonen zonder te raden:
Maak de regels expliciet (bijv. “offline als geen heartbeat voor 5 minuten”) zodat support en gebruikers het dashboard op dezelfde manier interpreteren.
Commando's moeten behandeld worden als getraceerde taken:
Deze structuur helpt je voortgang in de app te tonen en voorkomt verwarring over “werkt het of niet?”.
Apparaten zullen wegvallen, rondzwerven of slapen. Ontwerp er voor:
Als je identiteit, staat en commando's op deze manier beheert, wordt de rest van je monitoring-app veel betrouwbaarder en beter te gebruiken.
Je backend is de “control room” voor een monitoring-app: hij ontvangt telemetrie, slaat die efficiënt op en serveert snelle, voorspelbare API's naar de mobiele app.
De meeste teams hebben een kleine set services (apart codebases of duidelijk gescheiden modules):
Veel systemen gebruiken beide: relationeel voor controlegegevens, time-series voor telemetrie.
Mobiele dashboards hebben grafieken die snel moeten laden. Bewaar raw data, maar bereken ook vooraf:
Houd API's eenvoudig en cache-vriendelijk:
GET /devices (lijst + filters zoals site, status)GET /devices/{id}/status (last-known state, batterij, connectiviteit)GET /devices/{id}/telemetry?from=&to=&metric= (historiequeries)GET /alerts en POST /alerts/rules (waarschuwingen bekijken en beheren)Ontwerp responses rondom de mobiele UI: prioriteer “wat is de huidige status?” eerst en bied dan diepere geschiedenis wanneer gebruikers inzoomen.
“Realtime” in zo'n app betekent zelden “elke milliseconde.” Het betekent meestal “vers genoeg om te handelen”, zonder de radio wakker te houden of je backend te overbelasten.
Polling (de app vraagt periodiek de server om de laatste status) is simpel en batterijvriendelijk wanneer updates zeldzaam zijn. Het is vaak voldoende voor dashboards die een paar keer per dag worden bekeken of wanneer apparaten elke paar minuten rapporteren.
Streaming-updates (de server pusht wijzigingen naar de app) voelen direct, maar houden een verbinding open en kunnen het energieverbruik verhogen — vooral op onbetrouwbare netwerken.
Een praktische aanpak is hybride: poll op de achtergrond met een lage frequentie en schakel naar streaming alleen wanneer de gebruiker actief een scherm bekijkt.
Gebruik WebSockets (of vergelijkbare pushkanalen) wanneer:
Blijf bij polling wanneer:
Batterij- en schaalproblemen hebben vaak dezelfde oorzaak: te veel requests.
Batch updates (haal meerdere apparaten in één call op), pagineer lange histories en pas rate limits toe zodat één scherm niet per ongeluk honderden apparaten elke seconde kan opvragen. Als je high-frequency telemetrie hebt, downsample dan voor mobiel (bijv. 1 punt per 10–30 seconden) en laat de backend aggregeren.
Toon altijd:
Dit bouwt vertrouwen en voorkomt dat gebruikers handelen op verouderde “realtime” apparaatgegevens.
Waarschuwingen zijn waar een monitoring-app vertrouwen wint — of verliest. Het doel is niet “meer notificaties”; het doel is de juiste persoon naar de juiste actie brengen met genoeg context om het probleem snel op te lossen.
Begin met een kleine set categorieën die map naar echte operationele problemen:
Gebruik in-app notificaties als het volledige dossier (doorzoekbaar, filterbaar). Voeg pushmeldingen toe voor tijdkritische issues en overweeg email/SMS alleen voor hoge-ernst of buiten-kantoortijd-escalatie. Push moet bondig zijn: apparaatsnaam, ernst en één duidelijke actie.
Ruis vermindert responspercentages. Bouw in:
Behandel waarschuwingen als incidenten met staten: Triggered → Acknowledged → Investigating → Resolved. Elke stap moet worden vastgelegd: wie erkende, wanneer, wat veranderde en optionele notities. Deze audittrail helpt bij compliance, postmortems en het afstemmen van drempels zodat je /blog/monitoring-best-practices sectie later op echte data kan baseren.
Een monitoring-app slaagt of faalt op één vraag: kan iemand in een paar seconden begrijpen wat er mis is? Streef naar glanceable schermen die uitzonderingen eerst benadrukken, met details één tik verwijderd.
Je home-screen is meestal een apparaatlijst. Maak het snel om een vloot te beperken:
Gebruik duidelijke statuschips (Online, Degraded, Offline) en toon één belangrijke secundaire regel zoals laatste heartbeat (“Gezien 2m geleden”).
Op het apparaatdetailscherm, vermijd lange tabellen. Gebruik statuskaarten voor de essentie:
Voeg een Recente events paneel toe met menselijk leesbare berichten (“Deur geopend”, “Firmware-update mislukt”) en tijdstempels. Als commando's beschikbaar zijn, verberg ze achter een expliciete actie (bijv. “Herstart apparaat”) met bevestiging.
Grafieken moeten beantwoorden “wat veranderde?” niet pronken met datavolume.
Voeg een tijdbereikkiezer toe (1u / 24u / 7d / Aangepast), toon eenheden overal en gebruik leesbare labels (vermijd cryptische afkortingen). Wanneer mogelijk, annoteer anomalieën met markeringen die overeenkomen met je eventlog.
Vertrouw niet alleen op kleur. Combineer kleurcontrast met statusiconen en tekst (“Offline”). Vergroot tikdoelen, ondersteun Dynamic Type en houd kritieke status zichtbaar, ook bij fel licht of in laag batterijmodus.
Beveiliging is geen “later”-functie voor een monitoring-app. Zodra je realtime apparaatgegevens toont of remote commando's toestaat, handel je met gevoelige operationele data — en mogelijk controle over fysieke apparatuur.
Voor de meeste teams is magic link sign-in een goed uitgangspunt: gebruikers voeren een e-mailadres in, ontvangen een tijdsgebonden link en je vermijdt wachtwoordproblemen.
Houd de magic link kort-lived (minuten), single-use en koppel waar mogelijk aan apparaat/browsercontext. Als je meerdere orgs ondersteunt, maak de org-selectie expliciet zodat mensen niet per ongeluk toegang krijgen tot de verkeerde monitoring-workspace.
Authenticatie bewijst wie iemand is; autorisatie bepaalt wat ze mogen doen. Gebruik role-based access control (RBAC) met minstens twee rollen:
In de praktijk is de risicovolle actie “besturen”. Behandel command endpoints als een aparte permissieset, zelfs als de UI één knop is.
Gebruik TLS overal — tussen mobiele app en backend-API's en tussen apparaten en ingestiediensten (MQTT of HTTP maakt niet uit als het niet versleuteld is).
Sla tokens op in de OS keychain/keystore, niet in platte voorkeuren. Ontwerp op de backend least-privilege API's: een dashboardrequest mag geen geheime sleutels retourneren en een device-control endpoint mag geen brede “doe alles”-payloads accepteren.
Log security-relevante events (aanmeldingen, rolwijzigingen, device-commando pogingen) als audit events die je later kunt reviewen. Voor gevaarlijke handelingen — zoals het uitschakelen van een apparaat, het wijzigen van eigendom of het dempen van monitoring-pushmeldingen — voeg bevestigingsstappen en zichtbare attributie toe (“wie deed wat, wanneer”).
Een monitoring-app kan perfect lijken in het lab en toch falen in het veld. Het verschil is meestal “het echte leven”: wankele netwerken, lawaaierige telemetrie en apparaten die onverwacht gedrag vertonen. Testen moet deze omstandigheden zo dicht mogelijk benaderen.
Begin met unittests voor parsing, validatie en staatsovergangen (bijv. hoe een apparaat van online naar stale naar offline beweegt). Voeg API-tests toe die authenticatie, paginatie en filtering van apparaathistorie verifiëren.
Draai daarna end-to-end tests voor de belangrijkste gebruikersstromen: een fleet-dashboard openen, inzoomen op een apparaat, recente telemetrie bekijken, een commando sturen en het resultaat bevestigen. Dit zijn de tests die fouten tussen mobiele UI, backend en apparaatprotocol vangen.
Vertrouw niet alleen op een paar fysieke apparaten. Bouw een fake telemetrie-generator die kan:
Koppel dit aan netwerksimulatie op mobiel: vliegtuigmodus-wissels, pakketverlies en schakelen tussen Wi‑Fi en mobiel. Het doel is bevestigen dat je app begrijpelijk blijft wanneer data laat, gedeeltelijk of ontbrekend is.
Monitoring-systemen ontmoeten regelmatig:
Schrijf gerichte tests die bewijzen dat je geschiedenisweergaven, “laatst gezien”-labels en waarschuwingstriggers correct werken onder deze condities.
Test tot slot met grote vlootgroottes en lange datumbereiken. Verifieer dat de app responsief blijft op trage netwerken en oudere telefoons, en dat de backend tijdreeksgeschiedenis efficiënt kan serveren zonder de mobiele app meer te laten downloaden dan nodig.
Het uitbrengen van een monitoring-app is geen finishlijn — het is het begin van het runnen van een dienst waarop mensen vertrouwen wanneer er iets misgaat. Plan veilige releases, meetbare operatie-telemetrie en voorspelbare veranderingen.
Begin met een gefaseerde rollout: interne testers → een kleine pilotvloot → een groter percentage gebruikers/apparaten → volledige release. Koppel dit aan feature flags zodat je nieuwe dashboards, waarschuwingsregels of connectiviteitsmodi per klant, per apparaattype of per appversie kunt inschakelen.
Heb een rollbackstrategie die meer dekt dan de mobiele app-store:
Als je app apparaat-uptime rapporteert maar je ingestie-pijplijn vertraagd is, zien gebruikers "offline" apparaten die eigenlijk oké zijn. Volg de gezondheid van de hele keten:
Verwacht doorlopende updates: firmwarewijzigingen kunnen telemetrievelden, commandomogelijkheden en timing veranderen. Behandel telemetrie als een versioned contract — voeg velden toe zonder oude te breken, documenteer deprecations en houd parsers tolerant voor onbekende waarden. Voor command-API's, versioneer endpoints en valideer payloads per apparaattype en firmwareversie.
Als je budget en tijdslijnen plant, zie /pricing. Voor diepgaande artikelen, verken onderwerpen zoals MQTT vs HTTP en tijdreeksopslag in /blog, en zet je inzichten om in een kwartaalroadmap die prioriteit geeft aan minder, maar zekerder verbeteringen.
Als je vroege levering wilt versnellen, kan Koder.ai nuttig zijn om de MVP-vereisten hierboven (rollen, device registry, waarschuwingworkflow, dashboards) om te zetten in een werkende web-backend + UI en zelfs een cross-platform mobiele ervaring, met source-code-export en iteratieve aanpassingen vanuit planningsspecs — zodat je team meer tijd kan besteden aan het valideren van apparaatworkflows en minder aan scaffolding.
Begin met vast te leggen wat “betere monitoring” voor je team betekent:
Gebruik deze metrics als acceptatiecriteria voor het MVP zodat functies gekoppeld zijn aan operationele uitkomsten, niet alleen aan mooie dashboards.
Typische rollen komen overeen met verschillende workflows:
Ontwerp schermen en permissies per rol zodat je niet iedereen in één workflow hoeft te duwen.
Neem de kernstroom op voor problemen zien, begrijpen en erop reageren:
Maak per apparaattype een datakaart:
Dit voorkomt overmatig verzamelen (kosten) of onderverzamelen (blinde vlekken tijdens incidenten).
Gebruik een gelaagde aanpak:
Dit houdt de app responsief en ondersteunt toch post-incidentanalyse.
Kies op basis van apparaatbeperkingen en netwerkomstandigheden:
Kies de eenvoudigste optie die nog steeds werkt onder je slechtste verbindingsomstandigheden.
Een veelvoorkomende, praktische verdeling is:
Vermijd “altijd streamen” als gebruikers vooral de laatste bekende status nodig hebben; een hybride aanpak (achtergrond pollen, streamen in voorgrond) werkt vaak het beste.
Behandel commando's als getraceerde taken zodat gebruikers vertrouwen hebben in resultaten:
Voeg retries/timeouts en toe (dezelfde command ID wordt niet twee keer uitgevoerd) en toon staten zoals vs vs in de UI.
Ontwerp voor onbetrouwbare connectiviteit op zowel apparaat als telefoon:
Het doel is duidelijkheid: gebruikers moeten direct weten wanneer data verouderd is.
Gebruik RBAC en scheid “zien” van “besturen” capabilities:
Beveilig de volledige keten met TLS, sla tokens op in de OS keychain/keystore en houd een audit trail bij voor aanmeldingen, rolwijzigingen en commando-pogingen. Behandel device-control endpoints als risicovoller dan statusreads.
Stel kaarten, geavanceerde analytics en aangepaste dashboards uit totdat je hebt bewezen dat de responstijd verbetert.