03 nov 2025·8 min
Multi-tenant SaaS-patronen: isolatie, schaal en AI-ontwerp
Leer veelvoorkomende multi-tenant SaaS-patronen, afwegingen voor tenant-isolatie en schaalstrategieën. Zie hoe AI-gegenereerde architecturen ontwerp en review versnellen.
Wat multi-tenancy betekent (zonder jargon)
Multi-tenancy betekent dat één softwareproduct meerdere klanten (tenants) bedient vanuit hetzelfde draaiende systeem. Elke tenant denkt dat ze “hun eigen app” hebben, maar achter de schermen delen ze delen van de infrastructuur—zoals dezelfde webservers, dezelfde codebase en vaak dezelfde database.
Een nuttig mentaal model is een appartementencomplex. Iedereen heeft een eigen afgesloten unit (hun data en instellingen), maar je deelt de lift, het sanitair en het onderhoudsteam van het gebouw (de compute, opslag en operatie van de app).
Waarom teams voor multi-tenancy kiezen
De meeste teams kiezen niet voor multi-tenant SaaS omdat het hip is—ze kiezen het omdat het efficiënt is:
- Lagere kosten per klant: gedeelde infrastructuur is meestal goedkoper dan voor elke klant een volledige stack opzetten.
- Eenvoudigere operatie: één platform om te monitoren, patchen en beveiligen (in plaats van honderden kleine deploys).
- Sneller uitrollen: verbeteringen gaan meteen naar iedereen en je voorkomt “version drift” tussen klanten.
Waar het mis kan gaan
De twee klassieke faalwijzen zijn beveiliging en prestaties.
Op beveiliging: als tenant-grenzen niet overal worden afgedwongen, kan een bug data tussen klanten lekken. Zulke lekken zijn zelden dramatische “hacks”—meestal gewone fouten zoals een ontbrekende filter, een verkeerd ingestelde permissiecontrole of een achtergrondjob die zonder tenant-context draait.
Op prestaties: gedeelde resources betekenen dat één drukke tenant anderen kan vertragen. Dat “noisy neighbor”-effect kan zich tonen als langzame queries, bursty workloads of één klant die onevenredig veel API-capaciteit gebruikt.
Kort overzicht van de besproken patronen
Dit artikel bespreekt de bouwstenen die teams gebruiken om die risico's te beheersen: data-isolatie (database, schema of rijen), tenant-bewuste identiteit en permissies, controls tegen noisy neighbors en operationele patronen voor schaal en change management.
De kernafweging: isolatie versus efficiëntie
Multi-tenancy is een keuze over waar je op een spectrum zit: hoeveel je deelt tussen tenants versus hoeveel je per tenant toewijst. Elk architectuurpatroon hieronder is gewoon een ander punt op die lijn.
Gedeelde vs toegewezen resources: het kernspectrum
Aan het ene uiteinde delen tenants bijna alles: dezelfde app-instanties, dezelfde databases, dezelfde queues, dezelfde caches—gescheiden op logische wijze door tenant-ID's en toegangsregels. Dit is typisch het goedkoopste en makkelijkste om te draaien omdat je capaciteit poolt.
Aan het andere uiteinde krijgt elke tenant een eigen “slice” van het systeem: aparte databases, aparte compute, soms zelfs aparte deploys. Dit verhoogt veiligheid en controle, maar ook operationele overhead en kosten.
Waarom isolatie en kosten elkaar tegenwerken
Isolatie verkleint de kans dat één tenant toegang krijgt tot andermans data, hun performance-budget opeet of wordt beïnvloed door ongewone gebruikspatronen. Het maakt ook bepaalde audits en compliance-eisen eenvoudiger te behalen.
Efficiëntie verbetert wanneer je idle capaciteit over veel tenants amortiseert. Gedeelde infrastructuur laat je minder servers draaien, eenvoudigere deployment pipelines houden en schalen op basis van aggregaatvraag in plaats van piek per tenant.
Veelvoorkomende beslissingsfactoren
Je “juiste” punt op het spectrum is zelden filosofisch—het wordt bepaald door beperkingen:
- SLA en klantverwachtingen: strikte uptime- of latencydoelen duwen je richting meer isolatie.
- Compliance en dataresidency: eisen kunnen gedwongen toewijzing van opslag of omgevingen vereisen.
- Groeifase: vroege producten starten vaak met meer gedeeld om sneller te gaan; later kun je toegewijde opties aanbieden voor grote klanten.
- Operationele volwassenheid: meer isolatie betekent doorgaans meer dingen om te monitoren, patchen en migreren.
Een eenvoudig mentaal model om patronen te kiezen
Stel twee vragen:
-
Wat is de blast radius als één tenant zich misdraagt of gecompromitteerd wordt?
-
Wat zijn de bedrijfskosten om die blast radius te verkleinen?
Als de blast radius minimaal moet zijn, kies je voor meer toegewezen componenten. Als kosten en snelheid het belangrijkst zijn, deel je meer—en investeer je in sterke toegangcontroles, rate limits en per-tenant monitoring om delen veilig te houden.
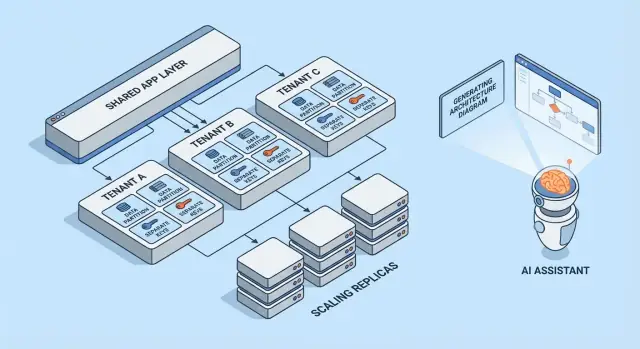
Multi-tenant modellen in vogelvlucht
Multi-tenancy is niet één enkele architectuur—het is een set manieren om infrastructuur tussen klanten te delen (of niet te delen). Het beste model hangt af van hoeveel isolatie je nodig hebt, hoeveel tenants je verwacht en hoeveel operationele overhead je team aankan.
1) Single-tenant (dedicated) — de basislijn
Elke klant krijgt hun eigen app-stack (of op zijn minst hun eigen geïsoleerde runtime en database). Dit is het makkelijkst om over na te denken voor beveiliging en performance, maar meestal het duurst per tenant en kan je operationele schaal vertragen.
2) Gedeelde app + gedeelde DB — laagste kosten, meeste zorg nodig
Alle tenants draaien op dezelfde applicatie en database. Kosten zijn meestal het laagst omdat je hergebruik maximaliseert, maar je moet uiterst zorgvuldig zijn over tenant-context overal (queries, caching, achtergrondjobs, analytics-exports). Eén fout kan een cross-tenant datalek veroorzaken.
3) Gedeelde app + aparte DB — sterkere isolatie, meer ops
De applicatie is gedeeld, maar elke tenant heeft een eigen database (of database-instance). Dit verbetert blast-radius controle bij incidenten, maakt tenant-level backups/restores eenvoudiger en kan compliance-gesprekken vergemakkelijken. De trade-off is operationeel: meer databases om te provisionen, monitoren, migreren en beveiligen.
4) Hybride modellen voor “grote tenants”
Veel SaaS-producten mixen benaderingen: de meeste klanten leven in gedeelde infrastructuur, terwijl grote of gereguleerde tenants dedicated databases of compute krijgen. Hybride is vaak de praktische eindtoestand, maar het vereist duidelijke regels: wie komt in aanmerking, wat het kost en hoe upgrades uitgerold worden.
Als je dieper wilt duiken in isolatietechnieken binnen elk model, verwijst dit naar de blogpost over data-isolatiepatronen.
Data-isolatiepatronen (DB, Schema, Rij)
Data-isolatie beantwoordt een eenvoudige vraag: “Kan één klant ooit de data van een andere klant zien of beïnvloeden?” Er zijn drie gangbare patronen, elk met verschillende beveiligings- en operationele implicaties.
Rij-niveau isolatie (gedeelde tabellen + tenant_id)
Alle tenants delen dezelfde tabellen, en elke rij bevat een tenant_id-kolom. Dit is het meest efficiënte model voor kleine tot middelgrote tenants omdat het infrastructuur minimaliseert en reporting/analytics eenvoudig houdt.
Het risico is ook eenvoudig: als een query vergeet te filteren op tenant_id, kun je data lekken. Zelfs één “admin”-endpoint of achtergrondjob kan een zwak punt worden. Mitigaties omvatten:
- Het afdwingen van tenant-filters in een gedeelde data-accesslaag (zodat ontwikkelaars geen filters handmatig hoeven te schrijven)
- Het gebruik van databasefuncties zoals row-level security (RLS) waar beschikbaar
- Geautomatiseerde tests toevoegen die bewust cross-tenant toegang proberen
- Indexeren voor veelgebruikte toegangswegen (vaak
(tenant_id, created_at)of(tenant_id, id)) zodat tenant-gescopeerde queries snel blijven
Schema-per-tenant (zelfde database, aparte schemas)
Elke tenant krijgt zijn eigen schema (namespaces zoals tenant_123.users, tenant_456.users). Dit verbetert isolatie ten opzichte van rij-deling en kan tenant-export of tenant-specifieke tuning makkelijker maken.
De trade-off is operationele overhead. Migraties moeten over veel schemas worden uitgevoerd, en fouten worden complexer: je kunt 9.900 tenants succesvol migreren en vastlopen op 100. Monitoring en tooling zijn hier belangrijk—je migratieproces heeft duidelijke retry- en rapportagegedrag nodig.
Database-per-tenant (aparte databases)
Elke tenant krijgt een aparte database. Isolatie is sterk: toegangsgrenzen zijn duidelijker, noisy queries van één tenant beïnvloeden minder snel anderen, en het herstellen van één tenant uit backup is veel schoner.
Kosten en schaal zijn de belangrijkste nadelen: meer databases om te beheren, meer connection pools en mogelijk meer upgrade/migratiewerk. Veel teams reserveren dit model voor high-value of gereguleerde tenants, terwijl kleinere tenants op gedeelde infrastructuur blijven.
Sharding en plaatsingsstrategieën naarmate tenants groeien
Echte systemen mixen vaak deze patronen. Een veelgebruikt pad is rij-niveau isolatie tijdens vroege groei, en grotere tenants “promoveren” naar aparte schemas of databases.
Sharding voegt een plaatsingslaag toe: beslissen op welk database-cluster een tenant woont (op regio, grootte-tier of hashing). De sleutel is expliciete en veranderbare tenant-plaatsing—zodat je een tenant kunt verplaatsen zonder de app te herschrijven en kunt schalen door shards toe te voegen in plaats van alles te herontwerpen.
Identiteit, toegang en tenant-context
Multi-tenancy faalt op verrassend gewone manieren: een ontbrekende filter, een gecachte object gedeeld tussen tenants of een admin-feature die vergeet voor wie het verzoek is. De oplossing is geen enkele grote beveiligingsfeature—het is consistente tenant-context van de eerste byte van een request tot de laatste databasequery.
Tenant-identificatie (hoe je weet “wie”)
De meeste SaaS-producten kiezen één primaire identifier en behandelen alles anders als gemak:
- Subdomein:
acme.yourapp.comis gebruiksvriendelijk en werkt goed met tenant-gebrandde ervaringen. - Header: handig voor API-clients en interne services (maar moet geauthenticeerd zijn).
- Token-claim: een gesigneerde JWT (of sessie) bevat
tenant_id, waardoor het moeilijk te manipuleren is.
Kies één bron van waarheid en log die overal. Als je meerdere signalen ondersteunt (subdomein + token), definieer prioriteit en weiger ambigu verzoeken.
Request-scoping (hoe elke query binnen een tenant blijft)
Een goede regel: zodra je tenant_id hebt opgelost, moet alles downstream het uit één plek lezen (request context), niet steeds opnieuw afleiden.
Gebruikelijke vangrails zijn:
- Middleware die
tenant_idaan de request-context koppelt - Data-access helpers die
tenant_idals parameter verplichten - Database-afdwinging (zoals row-level policies) zodat fouten dichtgaan
handleRequest(req):
tenantId = resolveTenant(req) // subdomain/header/token
req.context.tenantId = tenantId
return next(req)
(De bovenstaande codefence blijft ongewijzigd als voorbeeld.)
Autorisatie basics (rollen binnen een tenant)
Scheid authenticatie (wie de gebruiker is) van autorisatie (wat ze mogen doen).
Typische SaaS-rollen zijn Owner / Admin / Member / Read-only, maar het belangrijkste is scope: een gebruiker kan Admin zijn in Tenant A en Member in Tenant B. Sla permissies per tenant op, niet globaal.
Voorkomen van cross-tenant leaks (tests en vangrails)
Behandel cross-tenant toegang als een top-incident en voorkom het proactief:
- Voeg geautomatiseerde tests toe die proberen Tenant B-data te lezen terwijl je bent geauthenticeerd als Tenant A
- Maak het lastig om bugs zonder tenant-filter te releasen (linters, query-builders, verplichte tenant-parameters)
- Log en waarschuw bij verdachte patronen (bijv. mismatch tussen token en subdomein)
Als je een diepere operationele checklist wilt, verbind deze regels met je engineering-runbooks voor beveiliging en houd ze versiebeheer naast je code.
Isolatie voorbij de database
Prototypeer multi-tenancy snel
Genereer een React + Go + PostgreSQL-skelet om tenant-scoping vroeg te testen.
Database-isolatie is maar de helft van het verhaal. Veel echte multi-tenant incidenten gebeuren in de gedeelde leidingen rond je app: caches, queues en opslag. Deze lagen zijn snel, handig en makkelijk per ongeluk globaal te maken.
Gedeelde caches: voorkom key-collisions en datalekken
Als meerdere tenants Redis of Memcached delen, is de belangrijkste regel simpel: sla nooit tenant-agnostische keys op.
Een praktisch patroon is om elke key te prefixen met een stabiele tenant-identifier (niet een e-maildomein, niet een displaynaam). Bijvoorbeeld: t:{tenant_id}:user:{user_id}. Dit doet twee dingen:
- Voorkomt collisions wanneer twee tenants dezelfde interne IDs hebben
- Maakt bulk-invalidatie haalbaar (delete per prefix) tijdens support-incidenten of migraties
Bepaal ook wat globaal gedeeld mag worden (bijv. publieke feature flags, statische metadata) en documenteer het—per ongeluk globals zijn een veelvoorkomende bron van cross-tenant blootstelling.
Tenant-bewuste rate limits en quotas
Zelfs als data geïsoleerd is, kunnen tenants elkaar nog beïnvloeden via gedeelde compute. Voeg tenant-bewuste limieten toe aan de randen:
- API-rate limits per tenant (en vaak per gebruiker binnen een tenant)
- Quotas voor kostbare bewerkingen (exports, rapportgeneratie, AI-calls)
Maak de limiet zichtbaar (headers, UI-meldingen) zodat klanten begrijpen dat throttling beleid is, geen instabiliteit.
Achtergrondjobs: partitioneer queues per tenant
Een enkele gedeelde queue kan één drukke tenant dominante worker-tijd geven.
Gebruikelijke oplossingen:
- Aparte queues per tier/plan (bijv.
free,pro,enterprise) - Gepartitioneerde queues per tenant-bucket (hash tenant_id naar N queues)
- Tenant-bewuste scheduling zodat elke tenant een eerlijke slice krijgt
Propageer altijd tenant-context in de job-payload en logs om wrong-tenant bijwerkingen te voorkomen.
Bestands-/objectopslag: aparte paden, policies en keys
Voor S3/GCS-achtige opslag is isolatie meestal pad- en policy-gebaseerd:
- Bucket-per-tenant voor strikte scheiding (sterkere grenzen, meer overhead)
- Gedeelde bucket met tenant-prefixes (eenvoudiger, vereist zorgvuldige IAM en signed URLs)
Welke keuze je ook maakt, dwing af dat uploads/downloads tenant-eigendom valideren bij elk verzoek, niet alleen in de UI.
Omgaan met noisy neighbors en eerlijke resource-gebruik
Multi-tenant systemen delen infrastructuur, wat betekent dat één tenant per ongeluk (of opzettelijk) meer dan hun eerlijke deel kan verbruiken. Dit is het noisy neighbor-probleem: één luide workload degradeert de ervaring voor anderen.
Hoe een noisy neighbor eruitziet
Stel je een rapportagefeature voor die een jaar aan data naar CSV exporteert. Tenant A plant 20 exports om 9:00. Die exports verzadigen CPU en database I/O, dus Tenant B's normale app-schermen beginnen te timen out—ondanks dat B niets ongewoons doet.
Resource-controls: limieten, quotas en workload shaping
Voorkomen begint met expliciete resource-grenzen:
- Rate limits (requests per seconde) per tenant en per endpoint, zodat dure API's niet gespamd kunnen worden.
- Quotas (dagelijkse/maandelijkse totalen) voor dingen als exports, e-mails, AI-calls of achtergrondjobs.
- Workload shaping: zet zware taken (exports, imports, re-indexing) in queues met per-tenant concurrency caps en prioritatieregels.
Een praktisch patroon is interactieve traffic scheiden van batchwerk: houd user-facing requests op de snelle baan en zet alles anders naar gecontroleerde queues.
Per-tenant circuit breakers en bulkheads
Voeg veiligheidskleppen toe die triggeren wanneer een tenant een drempel overschrijdt:
- Circuit breakers: weiger of stel tijdelijk dure operaties uit wanneer foutpercentages, latency of queue-diepte voor die tenant limieten overschrijden.
- Bulkheads: isoleer gedeelde pools (DB-connections, worker-threads, cache) zodat één tenant niet de globale capaciteit uitput.
Goed geïmplementeerd kan Tenant A alleen hun eigen export-snelheid schaden zonder Tenant B neer te halen.
Wanneer een tenant naar dedicated capaciteit verhuizen
Verplaats een tenant naar dedicated resources wanneer ze consequent gedeelde aannames overschrijden: langdurig hoge throughput, onvoorspelbare spikes gekoppeld aan bedrijfskritieke gebeurtenissen, strikte compliance-vereisten of wanneer hun workload custom tuning vereist. Een simpele regel: als het beschermen van andere tenants permanente throttling van een betalende klant vereist, wordt het tijd voor dedicated capaciteit (of een hoger plan) in plaats van voortdurend blussen.
Schaalpatronen die werken in multi-tenant SaaS
Plan je tenant-model
Stel een multi-tenant app-plan op in de chat en iteratief veilig met planningsmodus.
Multi-tenant schalen gaat minder over “meer servers” en meer over voorkomen dat de groei van één tenant iedereen verrast. De beste patronen maken schaal voorspelbaar, meetbaar en omkeerbaar.
Horizontaal schalen voor stateless services
Begin met je web/API-laag stateless te maken: sla sessies op in een gedeelde cache (of gebruik token-based auth), bewaar uploads in objectopslag en zet langdurige werkstukken naar achtergrondjobs. Zodra requests niet afhankelijk zijn van lokale geheugen of schijf, kun je instanties achter een load balancer toevoegen en snel uitrollen.
Een praktisch tip: houd tenant-context aan de rand (afgeleid van subdomein of headers) en draag die door naar elke requesthandler. Stateless betekent niet tenant-onbewust—het betekent tenant-bewust zonder sticky servers.
Per-tenant hotspots: identificeren en egaliseren
De meeste schaalproblemen zijn “één tenant is anders.” Let op hotspots zoals:
- Één tenant genereert buitensporig veel traffic
- Een paar tenants met zeer grote datasets
- Batch-gedrag (einde-van-de-maand rapporten, nachtelijke imports)
Egalisatietactieken omvatten per-tenant rate limits, queue-based ingestie, caching van tenant-specifieke read paden en heavy tenants sharden naar aparte worker pools.
Read replicas, partitionering en asynchrone workloads
Gebruik read replicas voor read-heavy workloads (dashboards, search, analytics) en houd writes op de primaire. Partitionering (op tenant, tijd of beide) helpt indexes klein te houden en queries snel. Voor dure taken—exports, ML-scoring, webhooks—geef de voorkeur aan async jobs met idempotentie zodat retries geen load vermenigvuldigen.
Capacity planning-signalen en eenvoudige drempels
Houd signalen simpel en tenant-bewust: p95-latency, foutpercentage, queue-diepte, DB-CPU en per-tenant request-rate. Stel makkelijke drempels in (bijv. “queue-diepte > N gedurende 10 minuten” of “p95 > X ms”) die autoscaling of tijdelijke tenant-limieten triggeren—voordat andere tenants het voelen.
Observability en operatie per tenant
Multi-tenant systemen falen meestal niet globaal eerst—ze falen meestal voor één tenant, één plan-tier of één noisy workload. Als je logs en dashboards niet binnen seconden kunnen beantwoorden “welke tenant is getroffen?”, wordt on-call gissen.
Tenant-bewuste logs, metrics en traces
Begin met consistente tenant-context in je telemetry:
- Logs: includeer
tenant_id,request_iden een stabieleactor_id(gebruiker/service) op elk request en achtergrondjob. - Metrics: emit counters en latency-histogrammen uitgesplitst op tenant-tier minimaal (bijv.
tier=basic|premium) en per hoog-niveau endpoint (niet ruwe URLs). - Traces: draag tenant-context als trace-attributes zodat je een trage trace kunt filteren op een specifieke tenant en kunt zien waar tijd wordt besteed (DB, cache, derde-partij calls).
Houd cardinaliteit onder controle: per-tenant metrics voor alle tenants kan duur worden. Een veelvoorkomend compromis is tier-level metrics standaard plus per-tenant drill-down op aanvraag (bijv. sampling van traces voor “top 20 tenants naar traffic” of “tenants die SLO’s schenden”).
Gevoelige data in telemetry vermijden
Telemetry is een data-extractiekanaal. Behandel het als productie-data.
Geef de voorkeur aan IDs boven content: log customer_id=123 in plaats van namen, e-mails, tokens of query-payloads. Voeg redactie toe in de logger/SDK-laag en blocklist veelvoorkomende secrets (Authorization-headers, API-keys). Voor supportworkflows bewaar debugpayloads in een aparte, toegang-gecontroleerde opslag—niet in gedeelde logs.
SLOs per tenant-tier (zonder te veel te beloven)
Definieer SLOs die overeenkomen met wat je werkelijk kunt afdwingen. Premium-tenants kunnen strakkere latency/error-budgetten krijgen, maar alleen als je ook controls hebt (rate limits, workload isolation, priority queues). Publiceer tier-SLOs als doelen en volg ze per tier en voor een geselecteerde set high-value tenants.
On-call runbooks: veelvoorkomende incidenten in multi-tenant SaaS
Je runbooks moeten beginnen met “identificeer getroffen tenant(s)” en vervolgens de snelste isolerende actie:
- Noisy neighbor: throttle de tenant, pauzeer zware jobs of verplaats ze naar een lager-prioriteitsqueue.
- DB-hotspots/runaway queries: zet query timeouts aan, inspecteer top queries per tenant, pas een index toe of limiteer het endpoint.
- Tenant-context bugs (data mix-ups): schakel onmiddellijk de feature flag of endpoint uit en verifieer tenant-scoping in toegangcontroles.
- Achtergrondjob-opstapelingen: leeg per-tenant queues, cap concurrency en replay met idempotentie safeguards.
Operationeel is het doel simpel: detecteer per tenant, bevat per tenant en herstel zonder iedereen te raken.
Deployments, migraties en tenant-voor-tenant releases
Multi-tenant SaaS verandert het ritme van uitrollen. Je deployed niet “een app”; je deployed een gedeelde runtime en gedeelde datapaden waar veel klanten tegelijk afhankelijk van zijn. Het doel is nieuwe features leveren zonder een gesynchroniseerde big-bang upgrade over alle tenants heen te forceren.
Rolling deploys en low-downtime migraties
Geef de voorkeur aan deploymentpatronen die gemixte versies voor korte windows verdragen (blue/green, canary, rolling). Dat werkt alleen als je database-wijzigingen ook gefaseerd zijn.
Een praktische regel is expand → migrate → contract:
- Expand: voeg nieuwe kolommen/tabellen/indexes toe zonder bestaande code te breken.
- Migrate: backfill data in batches (vaak per tenant) en verifieer.
- Contract: verwijder oude velden pas nadat alle app-instanties er niet meer op vertrouwen.
Voor hot tables doe je backfills incrementeel (en throttle), anders creëer je tijdens een migratie je eigen noisy-neighbor-event.
Feature flags per tenant voor veiligere rollouts
Tenant-level feature flags laten je code globaal uitrollen terwijl gedrag selectief wordt ingeschakeld.
Dit ondersteunt:
- Early access-programma's voor een paar tenants
- Snel terugdraaien door een feature voor alleen getroffen tenants uit te schakelen
- A/B-experimenten zonder deploy-forks
Houd het flag-systeem auditeerbaar: wie wat inschakelde, voor welke tenant en wanneer.
Versionering en backward-compatibility verwachtingen
Ga ervan uit dat sommige tenants achter kunnen blijven qua configuratie, integraties of gebruikspatronen. Ontwerp API's en events met duidelijke versionering zodat nieuwe producers oude consumers niet breken.
Veelvoorkomende interne verwachtingen:
- Nieuwe releases moeten zowel oude als nieuwe vormen lezen tijdens migratiewindows.
- Deprecations vereisen een gepubliceerd tijdspad (zelfs als het alleen interne notities plus een klant-emailtemplate is).
Tenant-specifiek configuratiebeheer
Behandel tenant-config als product-surface: het heeft validatie, defaults en wijzigingsgeschiedenis nodig.
Sla configuratie apart van code op (en bij voorkeur apart van runtime-secrets) en ondersteun een safe-mode fallback wanneer configuratie ongeldig is. Een eenvoudige interne pagina voor tenant-instellingen kan uren besparen tijdens incidentrespons en gefaseerde uitrol.
Hoe AI-gegenereerde architecturen helpen (en hun beperkingen)
Beheers noisy neighbors
Bouw per-tenant rate limits en gequeue-de jobs zodat noisy neighbors ingeperkt blijven.
AI kan vroege architectuurgedachten voor een multi-tenant SaaS versnellen, maar het vervangt geen engineeringoordeel, testen of security review. Behandel het als een hoogwaardige brainstormpartner die drafts oplevert—verifieer vervolgens elke aanname.
Wat AI-gegenereerde architectuur zou moeten (en niet zou moeten) doen
AI is nuttig om opties te genereren en typische faalwijzen te belichten (zoals waar tenant-context kan verdwijnen of waar gedeelde resources verrassingen veroorzaken). Het zou niet je model moeten beslissen, compliance garanderen of performance valideren. Het kan je verkeer, de sterktes van je team of de randgevallen in legacy-integraties niet zien.
Input die ertoe doet: vereisten, beperkingen, risico's, groei
De kwaliteit van de output hangt af van wat je erin stopt. Handige inputs zijn:
- Aantal tenants vandaag versus over 12–24 maanden, en verwachte datavolumes per tenant
- Isolatievereisten (contractueel, regulatoir, klantverwachtingen)
- Budget en operationele capaciteit (on-call volwassenheid, SRE-ondersteuning, tooling)
- Latencydoelen, piekpatronen en burstiness per tenant
- Risicotolerantie: wat gebeurt er als één tenant een andere raakt?
AI gebruiken om patroonopties met afwegingen voor te stellen
Vraag om 2–4 kandidaatontwerpen (bijv. database-per-tenant vs. schema-per-tenant vs. rij-niveau isolatie) en vraag om een duidelijk overzicht van afwegingen: kosten, operationele complexiteit, blast radius, migratie-inspanning en schaalgrenzen. AI is goed in het opsommen van valkuilen die je kunt omzetten in ontwerpvragen voor je team.
Als je van “draft-architectuur” naar een werkend prototype wilt gaan, kan een vibe-coding platform zoals Koder.ai je helpen die keuzes om te zetten in een echt app-skelet via chat—vaak met een React-frontend en een Go + PostgreSQL-backend—zodat je tenant-context-propagatie, rate limits en migratieworkflows eerder kunt valideren. Features zoals planning mode plus snapshots/rollback zijn vooral nuttig bij itereren op multi-tenant datamodellen.
AI gebruiken om threat models en checklist-items te genereren
AI kan een eenvoudige threat model schetsen: entry points, trust boundaries, tenant-context-propagatie en veelgemaakte fouten (zoals ontbrekende autorisatiechecks op achtergrondjobs). Gebruik het om reviewchecklists voor PRs en runbooks te maken—maar verifieer met echte security-expertise en je eigen incidenthistorie.
Een praktische selectie-checklist voor je team
Een multi-tenant aanpak kiezen gaat minder over “best practice” en meer over fit: je datagevoeligheid, je groeisnelheid en hoeveel operationele complexiteit je kunt dragen.
Stapsgewijze checklist (gebruik dit in een 30-minuten workshop)
-
Data: Welke data wordt gedeeld tussen tenants (indien van toepassing)? Wat mag nooit samen geplaatst worden?
-
Identiteit: Waar leeft tenant-identity (invite-links, domeinen, SSO-claims)? Hoe wordt tenant-context bij elk request vastgesteld?
-
Isolatie: Beslis je standaard isolatieniveau (rij/schema/database) en identificeer uitzonderingen (bijv. enterprise-klanten die sterkere scheiding nodig hebben).
-
Schaal: Identificeer de eerste schaaldruk die je verwacht (opslag, read-traffic, achtergrondjobs, analytics) en kies het eenvoudigste patroon dat het aanpakt.
Vragen om te valideren met engineers en security reviewers
- Hoe voorkomen we cross-tenant toegang als een ontwikkelaar een filter vergeet?
- Wat is ons auditverhaal per tenant (wie deed wat, wanneer)?
- Hoe behandelen we data-verwijdering en retentie per tenant?
- Wat is de blast radius van een slechte migratie of runaway query?
- Kunnen we per-tenant throttling, rate-limiting en resource-budgetteren?
Rode vlaggen die diepgaander ontwerpwerk nodig hebben
- “We voegen tenant-checks later toe.”
- Gedeelde admin-tools die alles kunnen zien zonder strikte controls.
- Geen plan voor per-tenant backup/restore of incidentrespons.
- Een enkele queue/worker pool zonder per-tenant fairness.
Voorbeeld van aangeraden volgende stap samenvatting
Aanbeveling: Begin met rij-niveau isolatie + strikte tenant-context-handhaving, voeg per-tenant throttles toe en definieer een upgradepad naar schema-/database-isolatie voor risicovolle tenants.
Volgende acties (2 weken): threat-model tenant-grenzen, prototype afdwinging in één endpoint en voer een migratie-repetitie uit op een staging-kopie. Voor rollout-richtlijnen, raadpleeg het blog over tenant-release-strategieën.