30 aug 2025·8 min
Nginx vs HAProxy: Kies de juiste reverse proxy
Vergelijk Nginx en HAProxy als reverse proxies: prestaties, load balancing, TLS, observeerbaarheid, beveiliging en veelvoorkomende opstellingen om de beste keuze te maken.
Vergelijk Nginx en HAProxy als reverse proxies: prestaties, load balancing, TLS, observeerbaarheid, beveiliging en veelvoorkomende opstellingen om de beste keuze te maken.
Een reverse proxy is een server die voor je applicaties staat en eerst clientverzoeken ontvangt. Hij stuurt elk verzoek door naar de juiste backendservice (je app-servers) en retourneert het antwoord aan de client. Gebruikers praten met de proxy; de proxy praat met je apps.
Een forward proxy werkt andersom: hij staat vóór clients (bijvoorbeeld binnen een bedrijfsnetwerk) en stuurt hun uitgaande verzoeken naar het internet door. Het gaat daarbij vaak om het controleren, filteren of verbergen van clientverkeer.
Een load balancer wordt vaak als reverse proxy geïmplementeerd, maar met een specifieke focus: het verdelen van verkeer over meerdere backend-instanties. Veel producten (inclusief Nginx en HAProxy) doen zowel reverse proxying als load balancing, dus de termen worden soms door elkaar gebruikt.
De meeste implementaties beginnen om één of meer van deze redenen:
/api naar een API-service, / naar een webapp).Reverse proxies staan vaak vóór websites, API's en microservices—zowel aan de edge (publiek internet) als intern tussen services. In moderne stacks worden ze ook gebruikt als bouwstenen voor ingress-gateways, blue/green-deploys en high-availability-opstellingen.
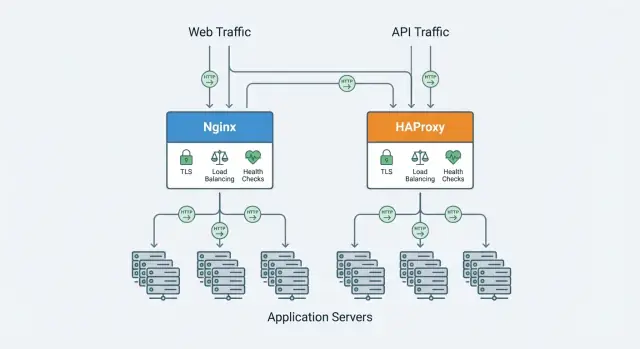
Nginx en HAProxy overlappen, maar leggen de nadruk op verschillende dingen. In de volgende secties vergelijken we beslisfactoren zoals prestaties bij veel verbindingen, load balancing en health checks, protocolondersteuning (HTTP/2, TCP), TLS-functies, observeerbaarheid, en dagelijkse configuratie en operatie.
Nginx wordt veel gebruikt als zowel webserver als reverse proxy. Veel teams beginnen ermee om een publieke website te serveren en breiden het later uit om voor applicatieservers te staan—door TLS te verwerken, verkeer te routeren en pieken glad te strijken.
Nginx blinkt uit wanneer je verkeer voornamelijk HTTP(S) is en je één “voordeur” wilt die van alles een beetje kan. Het is bijzonder sterk in:
X-Forwarded-For, security-headers)Doordat het zowel content kan serveren als proxy'en naar apps, is Nginx een veelgemaakte keuze voor kleine tot middelgrote omgevingen waar je minder bewegende onderdelen wilt.
Populaire mogelijkheden zijn onder andere:
Nginx wordt vaak gekozen wanneer je één toegangspunt nodig hebt voor:
Als je prioriteit rijke HTTP-afhandeling is en je het idee waardeert om webserving en reverse proxying te combineren, is Nginx vaak de standaardkeuze.
HAProxy (High Availability Proxy) wordt meestal gebruikt als een reverse proxy en load balancer die vóór één of meer applicatieservers staat. Hij accepteert inkomend verkeer, past routing- en verkeersregels toe en stuurt verzoeken door naar gezonde backends—vaak met stabiele responstijden bij hoge concurrentie.
Teams zetten HAProxy typisch in voor verkeersbeheer: requests over meerdere servers verspreiden, services beschikbaar houden bij fouten en verkeerspieken gladstrijken. Het is een veelgebruikte keuze aan de “edge” (north–south verkeer) en ook intern tussen services (east–west), vooral wanneer je voorspelbaar gedrag en strikte controle over connecties nodig hebt.
HAProxy staat bekend om efficiënt omgaan met grote aantallen gelijktijdige verbindingen. Dat is belangrijk wanneer veel clients tegelijk verbonden zijn (drukke API's, langlevende verbindingen, chatty microservices) en je wilt dat de proxy responsief blijft.
De load balancing-mogelijkheden zijn een hoofdreden om het te kiezen. Naast simpele round-robin ondersteunt het meerdere algoritmes en routingstrategieën die je helpen om:
Health checks zijn ook een sterk punt. HAProxy kan actief backends verifiëren en ongezonde instanties automatisch uit de rotatie verwijderen en weer toevoegen zodra ze herstellen. In de praktijk vermindert dit downtime en voorkomt het dat “half-gebroken” deployments alle gebruikers beïnvloeden.
HAProxy kan opereren op Layer 4 (TCP) en Layer 7 (HTTP).
Het praktische verschil: L4 is doorgaans eenvoudiger en erg snel voor TCP-forwarding, terwijl L7 rijkere routing en request-logica biedt wanneer je dat nodig hebt.
HAProxy wordt vaak gekozen wanneer het primaire doel betrouwbare, hoge-prestatie load balancing met sterke health checking is—bijvoorbeeld het verdelen van API-verkeer over meerdere app-servers, failover beheren tussen availability zones, of services fronten waarbij connectievolume en voorspelbaar verkeersgedrag belangrijker zijn dan geavanceerde webserverfuncties.
Vergelijkingen van prestaties gaan vaak mis omdat men naar één getal kijkt (zoals “max RPS”) en negeert wat gebruikers voelen.
Een proxy kan throughput verhogen terwijl tail latency slechter wordt als hij te veel werk priceht en gaat queue'en onder belasting.
Denk aan de “vorm” van je applicatie:
Als je met één patroon benchmarkt maar een ander pattern inzet, zijn de resultaten niet overdraagbaar.
Buffering kan helpen als clients traag of bursty zijn, omdat de proxy het volledige request (of response) kan lezen en je app constanter kan voeden.
Buffering kan schaden wanneer je app van streaming profiteert (server-sent events, grote downloads, real-time API's). Extra buffering voegt geheugenbelasting toe en kan tail latency verhogen.
Meet meer dan “max RPS”:
Als p95 scherp stijgt voordat fouten verschijnen, zie je vroege signalen van saturatie—niet “vrije capaciteit”.
Zowel Nginx als HAProxy kunnen verkeer over meerdere applicatie-instanties verdelen, maar ze verschillen in hoe uitgebreid hun load-balancing features out-of-the-box zijn.
Round-robin is de standaard “goed genoeg” keuze wanneer je backends vergelijkbaar zijn (zelfde CPU/geheugen,zelfde requestkosten). Simpel, voorspelbaar en werkt goed voor stateless apps.
Least connections is nuttig wanneer requests in duur variëren (bestanddownloads, lange API-calls, chat/WebSocket-achtige workloads). Het voorkomt dat tragere servers overbelast raken doordat het backends met minder actieve requests bevoordeelt.
Weighted balancing (round-robin met gewichten, of weighted least connections) is praktisch wanneer servers niet identiek zijn—oude en nieuwe nodes mixen, verschillende instancegroottes, of geleidelijke traffic shifts tijdens migraties.
In het algemeen biedt HAProxy meer keuze in algoritmes en fijnmazige controle op Layer 4/7, terwijl Nginx de veelvoorkomende gevallen helder afhandelt (en uitbreidbaar is afhankelijk van editie/modules).
Stickiness houdt een gebruiker bij dezelfde backend over requests:
Gebruik persistentie alleen wanneer het nodig is (legacy server-side sessies). Stateless apps schalen en herstellen doorgaans beter zonder het.
Actieve health checks pingen periodiek backends (HTTP-endpoint, TCP-connect, verwachte status). Ze vangen fouten zelfs bij lage traffic.
Passieve health checks reageren op echt verkeer: timeouts, connect-fouten of foute responses markeren een server als ongezond. Lichtgewicht, maar detecteert problemen mogelijk langzamer.
HAProxy staat bekend om rijke health-check en failure-handling controls (drempels, rise/fall-tellingen, gedetailleerde checks). Nginx ondersteunt solide checks ook, met mogelijkheden afhankelijk van build en editie.
Voor rolling deploys zoek je:
Koppel draining aan korte, goed gedefinieerde timeouts en een duidelijk "ready/unready" health-endpoint zodat verkeer soepel verschuift tijdens deploys.
Reverse proxies staan aan de rand van je systeem, dus protocol- en TLS-keuzes beïnvloeden alles van browserprestaties tot hoe veilig services met elkaar praten.
Zowel Nginx als HAProxy kunnen TLS “termineren”: ze accepteren versleutelde clientverbindingen, ontsleutelen verkeer en sturen verzoeken door naar je apps over HTTP of opnieuw versleuteld TLS.
De operationele realiteit is certificaatbeheer. Je hebt een plan nodig voor:
Nginx wordt vaak gekozen wanneer TLS-terminatie gecombineerd wordt met webserverfuncties (statische bestanden, redirects). HAProxy wordt vaak gekozen wanneer TLS vooral deel uitmaakt van het verkeersbeheersingslaag (load balancing, connectiebeheer).
HTTP/2 kan paginalaad-tijden voor browsers verkorten door multiplexing van meerdere requests over één verbinding. Beide tools ondersteunen HTTP/2 aan de clientzijde.
Belangrijke overwegingen:
Als je niet-HTTP verkeer moet routeren (databases, SMTP, Redis, custom protocollen), heb je TCP-proxying nodig in plaats van HTTP-routing. HAProxy wordt veel gebruikt voor high-performance TCP-load balancing met fijnmazige connectiecontrole. Nginx kan TCP proxien via zijn stream-capaciteiten, wat voldoende kan zijn voor eenvoudige pass-through setups.
mTLS verifieert beide kanten: clients presenteren certificaten, niet alleen servers. Het past goed bij service-to-service-communicatie, partnerintegraties of zero-trustontwerpen. Beide proxies kunnen clientcertificaatvalidatie afdwingen aan de rand, en veel teams gebruiken mTLS ook intern tussen proxy en upstreams om het "trusted network"-aanname te verkleinen.
Reverse proxies zitten midden in elk request, dus ze zijn vaak de beste plek om te beantwoorden "wat is er gebeurd?" Goede observeerbaarheid betekent consistente logs, een kleine set hoge-signaalmetrics en een herhaalbare manier om timeouts en gateway-fouten te debuggen.
Houd minimaal access logs en error logs aan in productie. Voor access logs neem upstream timing op zodat je kunt zien of traagheid door de proxy of de applicatie kwam.
In Nginx zijn veelgebruikte velden request time en upstream timing (bijv. $request_time, $upstream_response_time, $upstream_status). In HAProxy zet je HTTP log mode aan en capture timing-velden (queue/connect/response times) zodat je "wachten op een backendslot" kunt scheiden van "backend was traag."
Houd logs gestructureerd (JSON indien mogelijk) en voeg een request ID toe (van inkomende header of gegenereerd) om proxy-logs met app-logs te correleren.
Of je nu Prometheus scrape gebruikt of metrics elders heen stuurt, exporteer een consistente set:
Nginx gebruikt vaak de stub status endpoint of een Prometheus-exporter; HAProxy heeft een ingebouwde stats-endpoint die veel exporters uitlezen.
Exposeer een lichte /health (proces draait) en /ready (kan dependencies bereiken) endpoint. Gebruik beide in automatisering: load balancer health checks, deployments en autoscaling-beslissingen.
Bij troubleshooting vergelijk proxy-timing (connect/queue) met upstream-response-tijd. Als connect/queue hoog is, voeg capaciteit toe of pas load balancing aan; als upstream-tijd hoog is, focus op applicatie en database.
Het runnen van een reverse proxy gaat niet alleen over piekdoorvoer—het gaat ook over hoe snel je team veilige wijzigingen kan doorvoeren om 14:00 (of 02:00).
Nginx configuratie is directive-gebaseerd en hiërarchisch. Het leest als "blokken binnen blokken" (http → server → location), wat veel mensen prettig vinden als ze denken in termen van sites en routes.
HAProxy configuratie is meer "pijplijn-achtig": je definieert frontends (wat je accepteert), backends (waar je verkeer naartoe stuurt) en voegt regels (ACLs) toe om de twee te verbinden. Het voelt explicieter en voorspelbaarder zodra je het model beheerst, vooral voor traffic-routinglogica.
Nginx herlaadt typisch config door nieuwe workers te starten en oude netjes te laten doorwerken. Dat is vriendelijk voor frequente route-updates en certificaatvernieuwingen.
HAProxy kan ook naadloze reloads doen, maar teams behandelen het vaak meer als een “appliance”: striktere change control, versiebeheer van config en zorgvuldige coördinatie rond reload-commando's.
Beide ondersteunen config-tests voordat je herlaadt (een must voor CI/CD). In de praktijk houd je configs DRY door ze te genereren:
De belangrijkste operationele gewoonte: behandel proxy-config als code—gereviewd, getest en uitgerold zoals applicatiecode.
Naarmate het aantal services groeit, wordt certificaat- en routing-spaghetti de echte pijnpunt. Plan voor:
Als je honderden hosts verwacht, overweeg centralisatie van patronen en configgeneratie uit servicemetadata in plaats van handmatig files bewerken.
Als je meerdere services bouwt en iterateert, is een reverse proxy slechts één deel van de delivery-pijplijn—je hebt nog steeds herhaalbare app-scaffolding, omgeving-pariteit en veilige rollouts nodig.
Koder.ai kan teams helpen sneller van “idee” naar draaiende services te komen door React webapps, Go + PostgreSQL backends en Flutter mobiele apps te genereren via een chat-gebaseerde workflow, en daarna broncode-export, deploy/hosting, custom domains en snapshots met rollback te ondersteunen. In de praktijk kun je zo een API + web frontend prototype bouwen, uitrollen en daarna op basis van echt verkeer beslissen of Nginx of HAProxy de beste voordeur is in plaats van te gokken.
Beveiliging draait zelden om één magische feature—het gaat om het verkleinen van blast radius en het aanscherpen van defaults rond verkeer dat je niet volledig vertrouwt.
Draai de proxy met zo weinig mogelijk privileges: bind naar privilegierde poorten via capabilities (Linux) of een voorkeerservice, en houd worker processen onprivileged. Beveilig config en key-materialen (TLS private keys, DH-params) zodat ze alleen leesbaar zijn voor het service-account.
Op netwerkniveau: sta inbound alleen toe vanaf verwachte bronnen (internet → proxy; proxy → backends). Wees voorzichtig met directe toegang tot backends; laat de proxy bij voorkeur het enige toegangspunt zijn voor authenticatie, rate limiting en logging.
Nginx heeft ingebouwde primitives zoals request rate limiting en connection limiting (vaak via limit_req / limit_conn). HAProxy gebruikt doorgaans stick tables om request-rates, gelijktijdige verbindingen of foutpatronen te volgen en vervolgens te blokkeren, vertragen of beperken.
Kies een aanpak die bij je threat model past:
Wees expliciet over welke headers je vertrouwt. Accepteer X-Forwarded-For (en aanverwanten) alleen van bekende upstreams; anders kunnen aanvallers client-IP's spoofen en IP-gebaseerde controles omzeilen. Valideer of zet ook Host om host-header aanvallen en cache poisoning te voorkomen.
Een simpele vuistregel: de proxy moet forwarding-headers zetten, niet blind doorgeven.
Request smuggling misbruikt vaak ambigue parsing (conflicterende Content-Length / Transfer-Encoding, rare whitespace, of ongeldige headerformattering). Geef de voorkeur aan strikte HTTP-parsing, weiger malformed headers en stel conservatieve limieten in:
Connection, Upgrade en hop-by-hop headersDeze controls verschillen in syntax tussen Nginx en HAProxy, maar het resultaat moet hetzelfde zijn: bij ambigue falen gesloten falen en duidelijke limieten hanteren.
Reverse proxies worden meestal op twee manieren geïntroduceerd: als een dedicated voordeur voor één applicatie, of als een gedeelde gateway voor veel services. Beide Nginx en HAProxy kunnen dit doen—het gaat erom hoeveel routinglogica je aan de edge wilt hebben en hoe je het dagelijks wilt beheren.
Dit patroon zet een reverse proxy direct voor één webapp (of een kleine set nauw verwante services). Het is geschikt wanneer je vooral TLS-terminatie, HTTP/2, compressie, caching (bij Nginx) of een duidelijke scheiding tussen "publiek internet" en "private app" nodig hebt.
Gebruik dit wanneer:
Hier routeert één (of een klein cluster) proxies verkeer naar meerdere applicaties op basis van hostnaam, pad, headers of andere requesteigenschappen. Dit vermindert het aantal publieke toegangspunten maar vergroot het belang van schone configuratiemanagement en change control.
Gebruik het wanneer:
app1.example.com, app2.example.com) en één ingresslaag wilt.Proxies kunnen verkeer splitsen tussen "oud" en "nieuw" zonder DNS of applicatiecode te veranderen. Een veelgebruikte aanpak is twee upstream-pools definieren (blue en green) of twee backends (v1 en v2) en verkeer geleidelijk verschuiven.
Typische uses:
Handig als je deploymenttooling geen gewogen rollouts ondersteunt of als je een consistente rollout-mechaniek over teams wilt.
Een enkele proxy is een single point of failure. Veelgebruikte HA-patronen zijn:
Kies op basis van je omgeving: VRRP is populair op traditionele VMs/bare metal; beheerde load balancers zijn vaak het makkelijkst in de cloud.
Een typische "front-to-back" keten is: CDN (optioneel) → WAF (optioneel) → reverse proxy → applicatie.
Als je al een CDN/WAF gebruikt, houd de proxy gericht op application delivery en routing in plaats van te proberen de enige security-laag te zijn.
Kubernetes verandert hoe je applicaties voorstelt: services zijn vluchtig, IPs veranderen en routingbeslissingen gebeuren vaak aan de rand van het cluster via een Ingress-controller. Zowel Nginx als HAProxy kunnen hier goed passen, maar ze blinken vaak uit in iets andere rollen.
In de praktijk is de beslissing zelden "wat is beter" en meer "wat past bij je verkeerspatronen en hoeveel HTTP-manipulatie je aan de edge nodig hebt".
Als je een service mesh draait (bijv. mTLS en traffic policies intern), kun je Nginx/HAProxy nog steeds aan de perimeter houden voor north–south verkeer (internet naar cluster). De mesh handelt east–west verkeer. Deze verdeling houdt edge-zorgen—TLS-terminatie, WAF/rate limiting, basisrouting—gescheiden van interne betrouwbaarheidseigenschappen zoals retries en circuit breaking.
gRPC en langlevende verbindingen belasten proxies anders dan korte HTTP-requests. Let op:
Test met realistische duur (minuten/uren), niet alleen korte smoke-tests.
Behandel proxy-config als code: houd het in Git, valideer wijzigingen in CI (linting, config-test) en rol uit via CD met gecontroleerde deploys (canary of blue/green). Dit maakt upgrades veiliger en geeft een audittrail wanneer een routing- of TLS-wijziging productie raakt.
De snelste manier is te beginnen bij wat je verwacht dat de proxy dagelijks doet: content serveren, HTTP-verkeer vormgeven, of strikt verbindingen en balancing-logica beheren.
Als je reverse proxy ook de web-"voordeur" is, is Nginx vaak de handigere default.
Als je prioriteit precieze verkeersverdeling en strikte controle onder load is, blinkt HAProxy uit.
Het combineren van beiden komt vaak voor wanneer je webservergemakken en gespecialiseerde balancing wilt:
Deze split helpt teams ook om verantwoordelijkheden te scheiden: webzaken vs traffic engineering.
Stel jezelf:
Een reverse proxy staat vóór je applicaties: clients verbinden met de proxy, en de proxy stuurt verzoeken door naar de juiste backendservice en levert de response terug.
Een forward proxy staat vóór clients en regelt uitgaand internetverkeer (gebruikelijk in bedrijfsnetwerken).
Een load balancer richt zich op het verdelen van verkeer over meerdere backend-instanties. Veel load balancers worden als reverse proxy geïmplementeerd, daarom overlappen de termen.
In de praktijk gebruik je vaak één tool (zoals Nginx of HAProxy) voor beide rollen: reverse proxying + load balancing.
Plaats de proxy op het punt waar je één controlepunt wilt hebben:
Het belangrijkste is dat clients niet rechtstreeks je backends bereiken, zodat de proxy het choke point blijft voor beleid en zichtbaarheid.
TLS-terminatie betekent dat de proxy HTTPS afhandelt: hij accepteert versleutelde clientverbindingen, ontsleutelt ze en stuurt verkeer naar je upstreams via HTTP of opnieuw versleuteld TLS.
Operationeel moet je rekening houden met:
Kies Nginx wanneer je proxy ook het web-“voordeur”-werk doet:
Kies HAProxy wanneer verkeersbeheer en voorspelbaarheid onder belasting prioriteit hebben:
Gebruik round-robin voor gelijkwaardige backends en redelijk uniforme request-kosten.
Gebruik least connections wanneer verzoekduur varieert (downloads, lange API-calls, lange verbindingen) zodat tragere instanties niet overladen worden.
Gebruik gewogen varianten wanneer backends verschillen (verschillende instancegroottes, gemengde hardware, geleidelijke migraties) zodat je verkeer gecontroleerd kunt verschuiven.
Stickiness houdt een gebruiker bij dezelfde backend over meerdere verzoeken.
Vermijd stickiness als je kunt: stateless services schalen en herstellen doorgaans beter zonder het.
Buffering kan helpen door langzame of bursty clients glad te strijken, zodat je app stabieler verkeer ziet.
Het kan nadelig zijn voor streaming workloads (SSE, WebSockets, grote downloads), omdat extra buffering geheugendruk verhoogt en tail-latency kan verergeren.
Als je app stream-georiënteerd is, test en tune buffering expliciet in plaats van te vertrouwen op defaults.
Begin met het scheiden van proxy-vertraging en backend-vertraging via logs/metrics.
Typische betekenissen:
Handige signalen om te vergelijken:
Oplossingen zijn meestal timeout-aanpassingen, meer backend-capaciteit, of betere health checks/readiness-endpoints.