07 aug 2025·8 min
Noam Shazeer en de Transformer-architectuur achter LLMs
Lees hoe Noam Shazeer meehielp aan het vormen van de Transformer: self-attention, multi-head attention en waarom dit ontwerp de ruggengraat van moderne LLMs werd.
Waarom de Transformer nog steeds belangrijk is
Een Transformer is een manier om computers te helpen sequenties te begrijpen—dingen waarvan volgorde en context ertoe doen, zoals zinnen, code of een reeks zoekopdrachten. In plaats van token voor token te lezen en op een kwetsbaar geheugen voort te bouwen, kijkt een Transformer naar de hele sequentie en besluit wat belangrijk is om op te letten bij het interpreteren van elk deel.
Die eenvoudige verschuiving bleek enorm belangrijk. Het is een belangrijke reden waarom moderne large language models (LLMs) context kunnen vasthouden, instructies volgen, samenhangende alinea's schrijven en code genereren die naar eerder gedefinieerde functies en variabelen verwijst.
Waarom je steeds Transformers tegenkomt
Als je een chatbot, een ‘vat dit samen’-functie, semantische zoekfunctie of een code-assistent hebt gebruikt, heb je waarschijnlijk met Transformer-gebaseerde systemen gewerkt. Hetzelfde fundamentele ontwerp ondersteunt:
- chat- en klantenservice-tools die bijhouden wat je eerder zei
- zoek- en aanbevelingssystemen die op betekenis matchen, niet alleen op trefwoorden
- samenvattingen die kunnen wegen wat centraal is versus bijzaken
- codeertools die definities, gebruik en intenties over bestanden heen verbinden
Wat je in dit artikel leert
We leggen de belangrijkste onderdelen uit—self-attention, multi-head attention, positionele encodering en het basis Transformer-blok—en waarom dit ontwerp zo goed schaalt naarmate modellen groter worden.
We bekijken ook moderne varianten die hetzelfde kernidee behouden maar het aanpassen voor snelheid, kosten of langere contextvensters.
Wat je kunt verwachten (en wat niet)
Dit is een hoogoverzicht met verklaringen in eenvoudige taal en minimale wiskunde. Het doel is intuïtie op te bouwen: wat de onderdelen doen, waarom ze samenwerken en hoe dat zich vertaalt naar echte productmogelijkheden.
Noam Shazeer’s rol in het Transformer-verhaal
Noam Shazeer is een AI-onderzoeker en engineer, vooral bekend als een van de co-auteurs van het 2017-paper "Attention Is All You Need." Dat paper introduceerde de Transformer-architectuur, die later de basis werd voor veel moderne LLMs. Shazeer’s werk hoort thuis in een teamprestatie: de Transformer werd gemaakt door een groep onderzoekers bij Google, en dat verdient erkenning.
Wat het 2017-paper veranderde
Voor de Transformer vertrouwden veel NLP-systemen op recurrente modellen die tekst stap voor stap verwerkten. De Transformer toonde aan dat je sequenties effectief kon modelleren zonder recursie door aandacht als het primaire mechanisme te gebruiken om informatie over een zin te combineren.
Die verschuiving was belangrijk omdat trainen makkelijker te paralleliseren werd (je kunt veel tokens tegelijk verwerken), en het opende de deur naar het schalen van modellen en datasets op een manier die snel praktisch werd voor echte producten.
Van onderzoeksidee naar bouwsteen voor producten
Shazeer’s bijdrage—samen met de andere auteurs—bleef niet beperkt tot academische benchmarks. De Transformer werd een herbruikbaar module dat teams konden aanpassen: onderdelen wisselen, de grootte veranderen, finetunen voor taken en later op grote schaal pretrainen.
Zo bereiken veel doorbraken productgebruik: een paper introduceert een helder, algemeen recept; engineers verfijnen het; bedrijven operationaliseren het; en uiteindelijk wordt het een standaardkeuze voor het bouwen van taalfuncties.
Credit nauwkeurig houden
Het is juist te zeggen dat Shazeer een sleutelbijdrager en co-auteur van het Transformer-paper was. Het zou onjuist zijn hem als enige uitvinder te presenteren. De impact komt uit het collectieve ontwerp—en uit de vele verbeteringen die de community daarna bouwde op dat originele recept.
Wat eraan voorafging: RNNs, LSTMs en hun beperkingen
Voor Transformers domineerden Recurrent Neural Networks (RNNs) en later LSTMs (Long Short-Term Memory networks) de meeste sequentieproblemen (vertaling, spraak, tekstgeneratie). Het grote idee was simpel: lees tekst één token tegelijk, houd een lopend “geheugen” (een hidden state) bij en gebruik die staat om het volgende te voorspellen.
Een kort beeld van hoe ze werkten
Een RNN verwerkt een zin als een keten. Elke stap werkt de hidden state bij op basis van het huidige woord en de vorige hidden state. LSTMs verbeterden dit door poorten toe te voegen die beslissen wat te bewaren, te vergeten of uit te voeren—waardoor het makkelijker werd om nuttige signalen langer vast te houden.
Waarom langbereikafhankelijkheden moeilijk waren
In de praktijk heeft sequentieel geheugen een bottleneck: veel informatie moet door één enkele staat worden geperst naarmate de zin langer wordt. Zelfs met LSTMs kunnen signalen van ver eerdere woorden vervagen of overschreven raken.
Dit maakte bepaalde relaties lastig betrouwbaar te leren—zoals het koppelen van een voornaamwoord aan het juiste zelfstandig naamwoord tientallen woorden eerder, of het bijhouden van een onderwerp over meerdere clausules.
Training- en schaaluitdagingen
RNNs en LSTMs zijn ook traag om te trainen omdat ze niet volledig kunnen paralleliseren over tijd. Je kunt batchen over verschillende zinnen, maar binnen één zin hangt stap 50 af van stap 49, die weer afhangt van stap 48, enzovoort.
Die stapsgewijze berekening wordt een serieuze beperking wanneer je grotere modellen, meer data en snellere experimenten wilt.
De motivatie voor een meer parallelvriendelijke aanpak
Onderzoekers hadden een ontwerp nodig dat woorden aan elkaar kon relateren zonder strikt links-naar-rechts te marcheren tijdens training—een manier om lang-afstandsrelaties direct te modelleren en beter gebruik te maken van moderne hardware. Die druk zette het toneel klaar voor de attention-eerst benadering in Attention Is All You Need.
Attention, uitgelegd zonder wiskunde
Attention is de manier waarop het model vraagt: “Welke andere woorden moet ik nu bekijken om dit woord te begrijpen?” In plaats van een zin strikt links-naar-rechts te lezen en te hopen dat het geheugen het volhoudt, laat attention het model piepen naar de meest relevante delen van de zin op het moment dat het ze nodig heeft.
Het “zoeken en ophalen”-idee
Een nuttig mentaal model is een klein zoekmachientje dat binnen de zin draait.
- Query: wat het huidige woord zoekt (de vraag)
- Keys: wat elk ander woord aanbiedt (labels op mogelijke matches)
- Values: de feitelijke informatie om op te halen als er een match is (de inhoud)
Het model vormt dus een query voor de huidige positie, vergelijkt die met de keys van alle posities en haalt vervolgens een mengsel van values op.
Relevantie-scores → attention-gewichten
Die vergelijkingen produceren relevantie-scores: ruwe “hoe gerelateerd is dit?” signalen. Het model zet die vervolgens om in attention-gewichten, proporties die optellen tot 1.
Als één woord erg relevant is, krijgt het een groter aandeel van de focus. Als meerdere woorden belangrijk zijn, kan attention zich over hen verspreiden.
Een eenvoudig voorbeeld (voornaamwoorden en grammatica)
Neem: “Maria vertelde Jenna dat zij later zou bellen.”
Om zij te interpreteren moet het model terugkijken naar kandidaten zoals “Maria” en “Jenna.” Attention geeft een hoger gewicht aan de naam die het beste in de context past.
Of overweeg: “De sleutels van de kast zijn weg.” Attention helpt “zijn” te koppelen aan “sleutels” (het echte onderwerp), niet aan “kast”, zelfs als “kast” dichterbij staat. Dat is het kernvoordeel: attention verbindt betekenis over afstand, op aanvraag.
Self-Attention: het kernmechanisme
Self-attention is het idee dat elk token in een sequentie naar andere tokens in diezelfde sequentie kan kijken om te beslissen wat nu belangrijk is. In plaats van woorden strikt links-naar-rechts te verwerken (zoals oudere recurrente modellen deden), laat de Transformer elk token aanwijzingen verzamelen uit de hele input.
Tokens die naar tokens kijken
Stel je de zin voor: “Ik goot het water in de beker omdat het leeg was.” Het woord “het” moet verbonden worden met “beker”, niet met “water.” Met self-attention kent het token voor “het” een hogere belangrijkheid toe aan tokens die helpen de betekenis op te lossen (“beker”, “leeg”) en lagere belangrijkheid aan irrelevante tokens.
Hoe context wordt opgebouwd
Na self-attention is elk token niet langer alleen zichzelf. Het wordt een contextbewuste versie—een gewogen mengsel van informatie uit andere tokens. Je kunt het zien als dat elk token een gepersonaliseerde samenvatting van de hele zin creëert, afgestemd op wat dat token nodig heeft.
In de praktijk betekent dit dat de representatie voor “beker” signalen kan dragen van “goot”, “water” en “leeg”, terwijl “leeg” kan ophalen wat het beschrijft.
Waarom training parallel kan zijn
Omdat elk token zijn attention over de volledige sequentie tegelijkertijd kan berekenen, hoeft training niet te wachten op eerdere tokens die stap voor stap verwerkt worden. Deze parallelle verwerking is een belangrijke reden waarom Transformers efficiënt trainen op grote datasets en opschalen naar enorme modellen.
Waarom het sterk is voor lang-afstandsrelaties
Self-attention maakt het makkelijker om verre delen van tekst te verbinden. Een token kan direct focussen op een relevant woord ver weg—zonder informatie te hoeven doorgeven via een lange keten van tussenstappen.
Dat directe pad helpt bij taken zoals coreference (“zij”, “het”, “zij”), het bijhouden van onderwerpen over paragrafen heen en het afhandelen van instructies die afhangen van eerder genoemde details.
Multi-Head Attention: meerdere kijkhoeken op dezelfde zin
Plan voordat je codeert
Schets de workflow in de planningsmodus voordat je code genereert.
Eén attention-mechanisme is krachtig, maar het voelt soms alsof je een gesprek probeert te begrijpen met slechts één camerapositie. Zinnen bevatten vaak meerdere relaties tegelijk: wie deed wat, waarnaar “het” verwijst, welke woorden de toon zetten en wat het algemene onderwerp is.
Waarom één aandachtskijk onvoldoende is
Bij het lezen van “De trofee paste niet in de koffer omdat hij te klein was” moet je misschien meerdere aanwijzingen tegelijk volgen (grammatica, betekenis en wereldkennis). Eén attention-“kijk” kan zich vastzetten op het dichtstbijzijnde zelfstandig naamwoord; een andere kan de werkwoordelijke frase gebruiken om te beslissen waar “hij” naar verwijst.
Wat meerdere heads doen
Multi-head attention voert meerdere attention-berekeningen parallel uit. Elke “head” wordt aangemoedigd om de zin door een andere lens te bekijken—vaak beschreven als verschillende subruimtes. In de praktijk kunnen heads zich specialiseren in patronen zoals:
- lokale syntaxis (bv. bijvoeglijk naamwoord → zelfstandig naamwoord)
- lange-afstand koppelingen (bv. onderwerp ↔ werkwoord over een clausule)
- coreferentie (bv. voornaamwoord → entiteit)
- topische signalen (woorden die het onderwerp of sentiment zetten)
Hoe de heads worden gecombineerd
Nadat elke head zijn eigen inzichten produceert, kiest het model niet maar één. Het concateneert de head-outputs (stapelt ze naast elkaar) en projecteert ze vervolgens terug in de hoofd-"werkruimte" van het model met een geleerde lineaire laag.
Denk eraan als het samenvoegen van meerdere deelnotities tot één nette samenvatting die de volgende laag kan gebruiken. Het resultaat is een representatie die veel relaties tegelijk kan vastleggen—een van de redenen waarom Transformers zo goed werken op schaal.
Positionele encodering: het model woordvolgorde leren
Self-attention is uitstekend in het vinden van relaties—maar op zichzelf weet het niet wie eerst kwam. Als je de woorden in een zin husselt, kan een simpele self-attention-laag de gehusselde versie als even valide beschouwen, omdat hij tokens vergelijkt zonder ingebouwd gevoel voor positie.
Positionele encodering lost dit op door informatie over “waar ben ik in de sequentie?” aan de tokenrepresentaties toe te voegen. Zodra positie is toegevoegd, kan attention patronen leren zoals “het woord direct na niet is erg belangrijk” of “het onderwerp verschijnt meestal voor het werkwoord” zonder volgorde volledig uit de data te moeten afleiden.
Hoe positionele encoderingen volgorde toevoegen
Het kernidee is simpel: elke tokenembedding wordt gecombineerd met een positiegeluid voordat het de Transformer-blok ingaat. Die positiesignalen kun je zien als extra features die een token taggen als 1e, 2e, 3e… in de input.
Er zijn een paar gangbare benaderingen:
- Absolute (vaste) posities: Klassieke Transformers gebruikten deterministische, sinusoïdale patronen. Deze voegen geen nieuwe parameters toe en kunnen tot op zekere hoogte generaliseren naar lengtes buiten de training.
- Geleerde absolute posities: Het model leert een vector voor “positie 1”, “positie 2”, enz. Dit kan goed werken, maar bindt het model vaak aan een maximaal contextvenster waarop het getraind is.
- Relatieve posities: In plaats van “dit is token 57” encodeert het model afstanden zoals “dit token staat 3 stappen vóór dat token”. Moderne varianten (inclusief rotary-stijlen) vallen vaak in deze familie.
Waarom het belangrijk is voor lange-contexttaken
Positie-keuzes kunnen merkbaar effect hebben op lange-contextmodellering—dingen als het samenvatten van een lang rapport, het bijhouden van entiteiten over vele paragrafen of het ophalen van een detail dat duizenden tokens eerder werd genoemd.
Bij lange inputs leert het model niet alleen taal; het leert waar te kijken. Relatieve en rotary-stijl schema’s maken het vaak eenvoudiger om ver uit elkaar liggende tokens te vergelijken en patronen te behouden naarmate de context groter wordt, terwijl sommige absolute schema’s sneller kunnen verslechteren als ze buiten hun trainingsvenster worden geduwd.
In de praktijk is positionele encodering een stille ontwerpkeuze die kan bepalen of een LLM scherp en consistent aanvoelt bij 2.000 tokens—en nog steeds coherent bij 100.000.
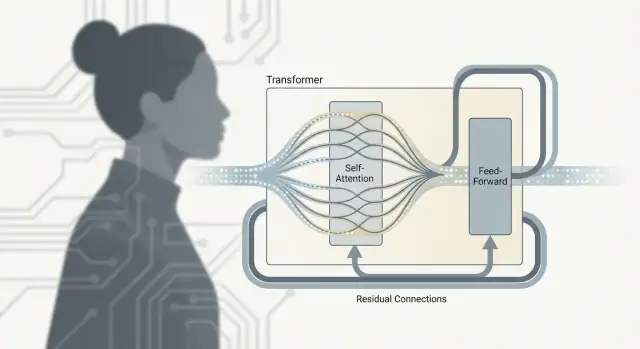
Het Transformer-blok: Attention + MLP + stabilisatoren
Prototype RAG-workflows
Test retrieval, embeddings en tool-loops zonder dezelfde basisstructuur opnieuw te bouwen.
Een Transformer is niet alleen “attention.” Het echte werk gebeurt in een herhalende eenheid—vaak een Transformer-blok genoemd—dat informatie tussen tokens mengt en die daarna verfijnt. Stapel er veel van en je krijgt de diepte die grote taalmodellen zo capabel maakt.
Na aandacht: wat de FFN/MLP doet
Self-attention is de communicatiestap: elk token verzamelt context van andere tokens.
Het feed-forward netwerk (FFN), ook MLP genoemd, is de denkstap: het neemt de bijgewerkte representatie van elk token en voert hetzelfde kleine neurale netwerk onafhankelijk erop uit.
In gewone bewoordingen transformeert de FFN en vormt wat elk token nu weet, waardoor het model rijkere features (zoals syntaxispatronen, feiten of stijlsignalen) kan bouwen nadat het relevante context heeft verzameld.
Waarom blokken attention en FFN afwisselen
De afwisseling is belangrijk omdat de twee delen verschillende taken uitvoeren:
- Attention verplaatst informatie tussen tokens (wie moet door wie beïnvloed worden)
- De FFN verwerkt informatie binnen elk token (hoe die context in bruikbare features wordt omgezet)
Door dit patroon te herhalen kan het model langzaam hogere-orde betekenis opbouwen: communiceer, reken uit, communiceer opnieuw, reken opnieuw.
Residual connections: de “skip-lanes”
Elke sublaag (attention of FFN) is omgeven door een residual connection: de input wordt opgeteld bij de output. Dit helpt diepe modellen trainen omdat gradients door de “skip-lane” kunnen stromen, zelfs als een bepaalde laag nog leert. Het laat een laag ook kleine aanpassingen maken in plaats van alles opnieuw te moeten leren.
Layer normalization: signalen stabiel houden
Layer normalization is een stabilisator die activaties voorkomt dat ze te groot of te klein worden terwijl ze door vele lagen gaan. Zie het als het constant houden van het volumeniveau zodat latere lagen niet overweldigd of uitgedroogd raken—waardoor training vloeiender en betrouwbaarder wordt, zeker op LLM-schaal.
Encoder–Decoder vs Decoder-only: welke drijft LLMs aan?
De originele Transformer in Attention Is All You Need was gebouwd voor machinevertaling, waar je de ene sequentie (bijv. Frans) naar een andere (bijv. Engels) omzet. Die taak splitst natuurlijk in twee rollen: goed lezen van de input en vloeiend schrijven van de output.
Encoder–Decoder: “Lees, dan Schrijf”
In een encoder–decoder Transformer verwerkt de encoder de hele inputzin tegelijk en produceert rijke representaties. De decoder genereert vervolgens output token voor token.
Belangrijk: de decoder vertrouwt niet alleen op zijn eigen eerdere tokens. Hij gebruikt ook cross-attention om naar de output van de encoder terug te kijken, wat helpt gegrond te blijven in de brontekst.
Deze opzet is nog steeds uitstekend wanneer je strikt op een input moet conditioneren—vertaling, samenvatting of vraagbeantwoording met een specifieke passage.
Decoder-only: één model dat blijft voorspellen
De meeste moderne large language models zijn decoder-only. Ze worden getraind voor een eenvoudige, krachtige taak: het volgende token voorspellen.
Hiervoor gebruiken ze gemaskerde self-attention (causal attention). Elke positie kan alleen naar eerdere tokens kijken, niet naar toekomstige, zodat generatie consistent blijft: het model schrijft links-naar-rechts en breidt de sequentie continu uit.
Dit is dominant voor LLMs omdat het eenvoudig is om op enorme tekstcorpora te trainen, het direct past bij het genereren en het efficiënt schaalt met data en compute.
Waar encoder-only modellen passen
Encoder-only Transformers (zoals BERT-stijl modellen) genereren geen tekst; ze lezen de hele input bidirectioneel. Ze zijn ideaal voor classificatie, zoek en embeddings—alles waar tekstbegrip belangrijker is dan het produceren van een lange continuatie.
Waarom Transformers uitgroeien tot Large Language Models
Transformers blijken buitengewoon schaalvriendelijk: als je ze meer tekst, meer rekenkracht en grotere modellen geeft, blijven ze zich op voorspelbare wijze verbeteren.
Een grote reden is structurele eenvoud. Een Transformer is opgebouwd uit herhaalde blokken (self-attention + een klein feed-forward netwerk, plus normalisatie), en die blokken gedragen zich vergelijkbaar of je nu op een miljoen woorden of een biljoen traint.
Parallel trainen is de verborgen superkracht
Eerdere sequentiemodellen (zoals RNNs) moesten tokens één voor één verwerken, wat beperkt hoeveel werk je tegelijk kunt doen. Transformers kunnen tijdens training alle tokens in een sequentie parallel verwerken.
Dat maakt ze uitstekend geschikt voor GPU/TPU en grote gedistribueerde setups—precies wat je nodig hebt bij het trainen van moderne LLMs.
Het “contextvenster” en waarom het telt
Het contextvenster is het stuk tekst dat het model tegelijk kan “zien”—je prompt plus recente conversatie of documenttekst. Een groter venster laat het model ideeën over meer zinnen of pagina’s verbinden, beperkingen onthouden en vragen beantwoorden die afhangen van eerdergenoemde details.
Maar context is niet gratis.
De belangrijkste beperking: attentionkosten groeien met lengte
Self-attention vergelijkt tokens met elkaar. Naarmate de sequentie langer wordt, groeit het aantal vergelijkingen snel (ongeveer het kwadraat van de lengte).
Daarom kunnen zeer lange contextvensters duur zijn in geheugen en rekenkracht, en veel moderne inspanningen richten zich op het efficiënter maken van attention.
Schalen ontgrendelde algemeen bruikbaar gedrag
Wanneer Transformers op schaal worden getraind, worden ze niet alleen beter in één smalle taak. Ze beginnen vaak brede, flexibele vaardigheden te tonen—samenvatten, vertalen, schrijven, coderen en redeneren—omdat dezelfde algemene leermachine op enorme, gevarieerde data wordt toegepast.
Moderne varianten gebouwd op hetzelfde blueprint
Deploy terwijl je iterereert
Deploy en host je app terwijl je iteraties doet op prompts en evaluatie.
Het originele Transformer-ontwerp is nog steeds het referentiepunt, maar de meeste productie-LLMs zijn “Transformers plus”: kleine, praktische aanpassingen die het kernblok (attention + MLP) behouden en tegelijk snelheid, stabiliteit of contextlengte verbeteren.
Veelvoorkomende verbeteringen die je zult zien
Veel upgrades veranderen niet zozeer wat het model is, maar maken het makkelijker te trainen en te draaien:
- Betere positionele methoden: Alternatieven voor klassieke sinusoidale posities (vaak rotary of relatieve stijlen) kunnen langeafstandshantering soepeler maken.
- Attention-optimalisaties: Implementaties die geheugen verminderen en throughput verhogen (bijv. fused kernels of efficiëntere attention-berekeningen).
- Normalisatietweaks: Variaties in waar en hoe normalisatie wordt toegepast kunnen trainingsstabiliteit verbeteren en hyperparameter-gevoeligheid verminderen.
Deze veranderingen veranderen meestal niet de fundamentele “Transformer-essentie”—ze verfijnen die.
Lange-context benaderingen (hoog niveau)
Het uitbreiden van context van een paar duizend tokens naar tienduizenden of honderdduizenden berust vaak op sparse attention (alleen naar geselecteerde tokens aandacht) of efficiënte attention-varianten (approximeren of herstructureren van attention om berekening te verminderen).
De afweging betreft meestal nauwkeurigheid, geheugen en engineeringcomplexiteit.
Mixture-of-Experts (MoE): meer capaciteit zonder lineaire kosten
MoE-modellen voegen meerdere “expert”-subnetwerken toe en routeren elk token door slechts een subset. Conceptueel: je krijgt een grotere ‘hersenen’, maar je activeert niet alles elke keer.
Dit kan de compute per token verlagen voor een gegeven parameteraantal, maar het verhoogt systeemscomplexiteit (routering, experts balanceren, serving).
Hoe variantclaims te evalueren
Als een model een nieuwe Transformer-variant promoot, vraag dan naar:
- Benchmarks die relevant zijn voor jouw taken (niet alleen headline-scores)
- Latency (time-to-first-token en tokens/sec)
- Kosten (training en inference), inclusief geheugen en hardwarebehoeften
De meeste verbeteringen zijn echt—maar zelden gratis.
Wat dit betekent voor teams die met LLMs bouwen
Transformer-ideeën zoals self-attention en schalen zijn fascinerend—maar productteams merken ze meestal als afwegingen: hoeveel tekst je kunt invoeren, hoe snel je een antwoord krijgt en wat het kost per request.
Een model of provider kiezen: de vier afwegingen
Contextlengte: Meer context laat toe meer documenten, chatgeschiedenis en instructies op te nemen. Het verhoogt ook tokengebruik en kan reacties vertragen. Als je feature afhankelijk is van “lees deze 30 pagina’s en beantwoord”, geef dan prioriteit aan contextlengte.
Latency: Gebruikersgerichte chat- en copilot-ervaringen leven of sterven met reactietijd. Streaming output helpt, maar modelkeuze, regio en batching zijn ook belangrijk.
Kosten: Prijzen zijn meestal per token (input + output). Een model dat 10% “beter” is, kan 2–5× zo duur zijn. Gebruik prijsvergelijkingen om te bepalen welk kwaliteitsniveau de kosten waard is.
Kwaliteit: Definieer het voor jouw use case: feitelijke nauwkeurigheid, instructievoldoening, toon, toolgebruik of code. Evalueer met echte voorbeelden uit je domein, niet alleen generieke benchmarks.
Wanneer embeddings generatie verslaan
Als je vooral zoeken, deduplicatie, clustering, aanbevelingen of “vind vergelijkbaar” nodig hebt, zijn embeddings (vaak encoder-stijl modellen) doorgaans goedkoper, sneller en stabieler dan een chatmodel te prompten. Gebruik generatie alleen voor de laatste stap (samenvattingen, verklaringen, opstellen) nadat retrieval heeft plaatsgevonden.
Voor een diepere uitleg, verwijs je team naar een technische toelichting zoals /blog/embeddings-vs-generation.
Waar dit zichtbaar wordt in echte workflows
Als je Transformer-capaciteiten in een product omzet, is het lastige meestal minder de architectuur en meer de workflow eromheen: prompt iteratie, grounding, evaluatie en veilige deployment.
Een praktische route is het gebruik van een vibe-coding platform zoals Koder.ai om LLM-gestuurde features sneller te prototypen en uit te rollen: je kunt de webapp, backend endpoints en datamodel in chat beschrijven, itereren in planningmodus en dan broncode exporteren of deployen met hosting, custom domains en rollback via snapshots. Dat is vooral nuttig als je experimenteert met retrieval, embeddings of tool-calling loops en snelle iteratie wil zonder elke keer dezelfde basisstructuur te herbouwen.
Een praktische adoptie-checklist
- Schrijf een één-pagina spec: gebruikersdoel, faalmodi en wat “goed” betekent.
- Bepaal wat in jouw data gegrond moet zijn (RAG, citaten of tool-calls).
- Stel budgetten voor tokens, latency en maandelijkse uitgaven; meet ze in staging.
- Voeg veiligheidsrails toe: weigeringen, redactie en “dat weet ik niet”-gedrag.
- Bouw evaluatie vroeg in: gouden prompts, regressietests en menselijke review.
- Plan voor modelwissels: houd prompts en routering configureerbaar.
Veelgestelde vragen
Wat is een Transformer in eenvoudige bewoordingen?
Een Transformer is een neurale netwerkarchitectuur voor sequentiegegevens die self-attention gebruikt om elk token te relateren aan alle andere tokens in dezelfde input.
In plaats van informatie stap voor stap door te geven (zoals RNNs/LSTMs), bouwt hij context op door te beslissen waarop hij moet letten over de hele sequentie, wat het begrip op lange afstand verbetert en trainen paralleler mogelijk maakt.
Waarom hebben Transformers RNNs en LSTMs voor veel NLP-taken vervangen?
RNNs en LSTMs verwerken tekst één token tegelijk, wat het trainen moeilijker paralleliseerbaar maakt en een knelpunt vormt voor langetermijnafhankelijkheden.
Transformers gebruiken aandacht om verre tokens direct te verbinden, en ze kunnen veel token-naar-token-interacties tegelijk berekenen tijdens training—waardoor ze sneller schaalbaar zijn met meer data en rekenkracht.
Wat is "attention" en hoe moet ik erover denken?
Attention is een mechanisme om te beantwoorden: “Welke andere tokens zijn nu het belangrijkst om dit token te begrijpen?”
Je kunt het zien als een in-zin retrieval:
- een query vraagt welke informatie nodig is
- keys representeren wat elk token aanbiedt
- values zijn de informatie die wordt gemengd
De output is een gewogen mengsel van relevante tokens, waardoor elke positie een contextbewuste representatie krijgt.
Wat is het verschil tussen attention en self-attention?
Self-attention betekent dat de tokens in een sequentie aandacht geven aan andere tokens in diezelfde sequentie.
Het is het kernmiddel waarmee een model zaken oplost zoals coreferentie (bijv. waar "het" naar verwijst), onderwerp–werkwoordsrelaties over clausules heen, en afhankelijkheden die ver uit elkaar liggen—zonder alles door één recurrente “geheugen”-vector te hoeven duwen.
Waarom gebruiken Transformers multi-head attention?
Multi-head attention voert meerdere attention-berekeningen parallel uit, en elk head kan zich specialiseren in andere patronen.
In de praktijk focussen verschillende heads vaak op verschillende relaties (zinsbouw, lange-afstand-verbindingen, voornaamwoordresolutie, topische signalen). Het model combineert deze visies vervolgens zodat het meerdere structuren tegelijk kan representeren.
Als attention naar alles kijkt, hoe weet het model dan woordvolgorde?
Self-attention op zichzelf bevat geen ingebouwd idee van volgorde—zonder positie-informatie kunnen woordvolgordes door elkaar lijken.
Positionele encoderingen injecteren volgorde-informatie in tokenrepresentaties zodat het model patronen kan leren zoals “wat direct na niet komt is belangrijk” of dat het onderwerp meestal vóór het werkwoord komt.
Veelvoorkomende opties zijn sinusoidale (vast), geleerde absolute posities en relatieve/rotary-stijl methoden.
Wat zit er in een Transformer-blok behalve attention?
Een Transformer-blok combineert meestal:
- Attention: verplaatst informatie tussen tokens
- FFN/MLP: verwerkt informatie binnen elk token
- Residual connections: helpen gradients stromen en laten lagen incrementele wijzigingen maken
- Layer normalization: stabiliseert activaties voor diepe stapels
Encoder–decoder vs decoder-only: welke gebruikt men voor LLMs?
Het originele Transformer-ontwerp is encoder–decoder:
- de encoder leest de input bidirectioneel
- de decoder genereert output terwijl hij gebruikmaakt van cross-attention naar de encoder
De meeste LLMs van vandaag zijn , getraind om het volgende token te voorspellen met , wat goed past bij links-naar-rechts generatie en efficiënt schaalt op grote corpora.
Wat was Noam Shazeer’s rol in de creatie van de Transformer?
Noam Shazeer was een co-auteur van het 2017-paper “Attention Is All You Need,” waarin de Transformer werd geïntroduceerd.
Het is correct hem als belangrijke bijdrager te noemen, maar de architectuur ontstond binnen een team bij Google, en de impact komt ook door de vele vervolgstappen van de community en industrie bovenop dat originele ontwerp.
Waarom zijn lange contextvensters duur, en wat kunnen teams eraan doen?
Bij lange inputs wordt standaard self-attention duur omdat het aantal vergelijkingen ruwweg toeneemt met het kwadraat van de sequentielengte, wat geheugen- en rekenkosten verhoogt.
Praktische manieren om hiermee om te gaan zijn:
- modellen kiezen met grotere native contextvensters
- RAG gebruiken (haal relevante stukken op in plaats van alles in te proppen)
- lange-context varianten toepassen (vaak sparse/efficient attention)