Wat hier met “Palantir” en “traditionele enterprise‑software” wordt bedoeld
Mensen gebruiken “Palantir” vaak als verzamelterm voor een paar verwante producten en een algemene manier om data‑gedreven operaties op te bouwen. Om deze vergelijking duidelijk te houden, helpt het om te benoemen wat er wél en níet besproken wordt.
Waar “Palantir” in dit stuk naar verwijst
Wanneer iemand “Palantir” zegt in een enterprise‑context, bedoelen ze meestal een (of meer) van de volgende:
- Foundry: Palantir’s commerciële platform, gericht op dataintegratie, modellering en het mogelijk maken van operationele besluitvorming.
- Gotham: Vaak gekoppeld aan defensie en publieke sector‑use‑cases, met vergelijkbare thema’s maar een andere geschiedenis en positionering.
- Apollo: Een deployment‑ en leveringssysteem dat gebruikt wordt om software te versturen en te beheren over veel omgevingen (inclusief beperkte omgevingen).
In dit artikel gebruiken we “Palantir‑achtig” om de combinatie te beschrijven van (1) sterke dataintegratie, (2) een semantische/ontologie‑laag die teams op betekenis afstemt, en (3) implementatiepatronen die cloud, on‑prem en losgekoppelde omgevingen kunnen omvatten.
Waar “traditionele enterprise‑software” hier voor staat
“Traditionele enterprise‑software” is geen enkel product — het is de typische stack die veel organisaties in de loop van tijd samenstellen, zoals:
- ERP‑ en CRM‑systemen (registratie‑systemen voor financiën, supply chain, verkoop)
- Een datawarehouse of lake plus BI‑dashboards (systemen voor rapportage en analytics)
- Integratie‑middleware (ETL/ELT‑tools, iPaaS, message queues, API's)
Bij deze aanpak worden integratie, analytics en operatie vaak door losse tools en teams afgehandeld, verbonden via projecten en governanceprocessen.
Wat deze vergelijking wél en níet is
Dit is een vergelijking van aanpakken, geen vendor‑aanbeveling. Veel organisaties slagen met conventionele stacks; anderen hebben voordeel van een meer uniform platformmodel.
De praktische vraag is: welke afwegingen maak je in snelheid, controle en hoe direct analytics verbonden is met het dagelijkse werk?
Om de rest van het artikel concreet te houden, focussen we op drie gebieden:
- Dataintegratie: hoe data verbonden, beheerd en toegewezen wordt
- Operationele analytics: hoe analyse verder gaat dan dashboards en besluitvorming ondersteunt
- Implementatiemodellen: cloud, on‑prem en losgekoppelde/air‑gapped realiteiten
Dataintegratie: pijplijnen en verantwoordelijkheden
Het meeste datawerk in een “traditionele enterprise‑software” volgt een bekend patroon: data uit systemen (ERP, CRM, logs) wordt gehaald, getransformeerd, in een warehouse of lake geladen, en daarna gebruiken teams BI‑dashboards en een paar downstream apps.
Dat patroon kan goed werken, maar het verandert vaak in een reeks kwetsbare overdrachten: het ene team beheert extractiescripts, een ander team beheert warehouse‑modellen, een derde team beheert dashboarddefinities, en business‑teams onderhouden spreadsheets die stilletjes de “echte” cijfers herschrijven.
Het traditionele patroon: ETL/ELT als estafette
Met ETL/ELT hebben veranderingen de neiging om door te slaan. Een nieuw veld in het bronsysteem kan een pijplijn breken. Een “snelle fix” creëert een tweede pijplijn. Al snel heb je gedupliceerde metrics (“omzet” op drie plekken), en is het onduidelijk wie verantwoordelijk is als cijfers niet overeenkomen.
Batchverwerking komt hier vaak voor: data landt ’s nachts, dashboards worden in de ochtend bijgewerkt. Near‑real‑time is mogelijk, maar wordt vaak een aparte streaming‑stack met eigen tooling en eigenaren.
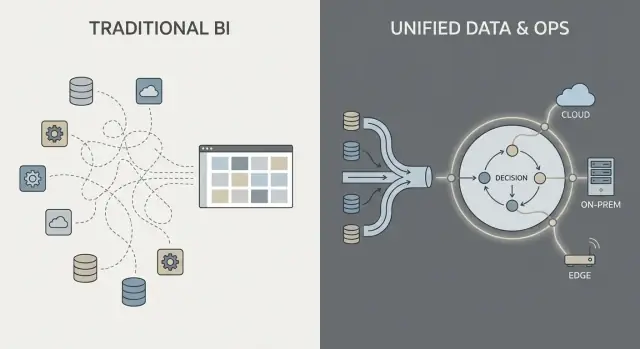
Het Palantir‑achtige patroon: integreren, betekenis standaardiseren, dan overal hergebruiken
Een Palantir‑achtige aanpak streeft ernaar bronnen te verenigen en consistente semantiek (definities, relaties en regels) eerder toe te passen, en daarna dezelfde gecureerde data aan analytics en operationele workflows bloot te stellen.
In eenvoudige bewoordingen: in plaats van dat elk dashboard of elke app zelf moet uitzoeken wat een klant, asset, case of zending betekent, wordt die betekenis één keer gedefinieerd en hergebruikt. Dit kan gedupliceerde logica verminderen en eigenaarschap duidelijker maken — want wanneer een definitie verandert, weet je waar die staat en wie het goedkeurt.
Veelvoorkomende pijnpunten om op te letten
Integratie faalt meestal op verantwoordelijkheden, niet op connectors:
- Kwetsbare pijplijnen die breken bij kleine bron‑wijzigingen
- Gedupliceerde metrics die per team verschillend zijn gedefinieerd
- Onduidelijk eigenaarschap voor datakwaliteit, definities en fixes
De kernvraag is niet alleen “Kunnen we systeem X verbinden?” maar “Wie is eigenaar van de pijplijn, de metric‑definities en de zakelijke betekenis in de loop van de tijd?”
Semantische laag en ontologie: een ander zwaartepunt
Traditionele enterprise‑software behandelt “betekenis” vaak als bijzaak: data staat in vele app‑specifieke schema's, metricdefinities leven in individuele dashboards, en teams onderhouden stilletjes hun eigen versie van “wat een order is” of “wanneer een case is opgelost.” Het resultaat is bekend — verschillende cijfers op verschillende plekken, trage reconciliatievergaderingen en onduidelijk eigenaarschap als iets niet klopt.
Ontologie, in duidelijke taal
In een Palantir‑achtige aanpak is de semantische laag niet alleen een rapportagegemak. Een ontologie fungeert als een gedeeld bedrijfsmodel dat definieert:
- Entiteiten (dingen die belangrijk zijn voor je business): Order, Klant, Asset, Zending, Case
- Relaties (hoe die dingen verbonden zijn): een Order behoort tot een Klant; een Zending vult een Order in; een Asset is geïnstalleerd op een Locatie
- Acties (wat mensen ermee doen): goedkeuren, dispatchen, escaleren, buiten gebruik stellen, terugbetalen
Dit wordt het “zwaartepunt” voor analytics en operatie: meerdere datasources kunnen bestaan, maar ze mappen naar een gemeenschappelijke set business‑objecten met consistente definities.
Waarom semantiek belangrijker is dan men verwacht
Een gedeeld model verkleint mismatchende cijfers omdat teams definities niet in elke rapportage of app opnieuw uitvinden. Het verbetert ook de verantwoording: als “On‑time delivery” gedefinieerd is aan de hand van Shipment‑events in de ontologie, is het duidelijker wie verantwoordelijk is voor de onderliggende data en businesslogica.
Praktische voorbeelden
- Orders: Sales, finance en support zien hetzelfde Order‑object, inclusief status, waarde, goedkeuringen en uitzonderingen — geen aparte “order‑tabellen” per afdeling.
- Assets: Maintenance, operations en compliance delen één Asset‑record met locatie, inspectiegeschiedenis en risicoflags.
- Cases: Supportcases koppelen aan klanten, orders en zendingen, zodat escalatieregels en servicemetingen niet per team wegdrijven.
Goed gedaan maakt een ontologie niet alleen dashboards schoner — het versnelt dagelijkse beslissingen en voorkomt discussies.
Operationele analytics versus BI‑dashboards
BI‑dashboards en traditionele rapportage gaan vooral over achteromkijken en monitoren. Ze beantwoorden vragen als “Wat gebeurde er vorige week?” of “Liggen we op koers ten opzichte van KPI’s?” Een salesdashboard, een finance‑close‑rapport of een executive‑scorecard is waardevol — maar stopt vaak bij zichtbaarheid.
Operationele analytics is anders: het is analytics ingebed in dagelijkse beslissingen en uitvoering. In plaats van een apart “analytics‑bestemming” verschijnt analyse binnen de workflow waar werk gebeurt en stuurt het een concrete volgende stap aan.
BI: observeren en verklaren
BI/rapportage richt zich doorgaans op:
- Gestandaardiseerde metrics en KPI‑definities
- Geplande verversingen en wekelijkse/maandelijkse reviews
- Geaggregeerde overzichten (teams, regio's, perioden)
- Root‑cause verkenning nadat uitkomsten bekend zijn
Dat is uitstekend voor governance, prestatiemanagement en verantwoording.
Operationele analytics: beslissen en handelen
Operationele analytics focust op:
- Realtime of near‑realtime signalen
- Besluitondersteuning bij het moment van actie
- Aanbevelingen, prioritering en uitzonderingbehandeling
- Feedbackloops (werkte de actie en wat veranderde?)
Concrete voorbeelden lijken minder op “een grafiek” en meer op een werkwachtrij met context:
- Dispatching: kiezen welk werk naar welk team gaat op basis van locatie, vaardigheden, SLA en onderdelenbeschikbaarheid
- Voorraaltoewijzing: bepalen waar beperkt stock heen gaat om backorders en gemiste leveringen te verminderen
- Fraude‑triage: cases rangschikken op risico en routeren naar onderzoekers met het juiste bewijs
- Onderhoudsplanning: voorspellen van uitval en onderhoud inplannen rond productiebeperkingen
De belangrijkste verschuiving: van “zien” naar “doen”
De belangrijkste verandering is dat analyse gekoppeld is aan een specifieke workflowstap. Een BI‑dashboard kan tonen “te late leveringen nemen toe.” Operationele analytics verandert dat in “hier zijn de 37 zendingen die vandaag risico lopen, de waarschijnlijke oorzaken en de aanbevolen interventies,” met de mogelijkheid om direct te executeren of toe te wijzen.
Van inzichten naar acties: workflow‑gecentreerd ontwerp
Traditionele enterprise‑analytics eindigt vaak bij een dashboard: iemand ziet een probleem, exporteert naar CSV, mailt een rapport, en een ander team “doet iets” later. Een Palantir‑achtige aanpak is ontworpen om die kloof te verkleinen door analytics rechtstreeks in de workflow te embedden waar beslissingen worden genomen.
Menselijke beslissingen in de lus (geen volledige autopilot)
Workflow‑gecentreerde systemen genereren meestal aanbevelingen (bijv. “prioriteer deze 12 zendingen”, “flag deze 3 leveranciers”, “plan onderhoud binnen 72 uur”) maar vragen nog steeds expliciete goedkeuringen. Die goedkeuringsstap is belangrijk omdat het creëert:
- Besluitverantwoording: wie keurde goed, wanneer en op basis van welke data
- Auditsporen: een opgenomen keten van inputdata → logica/model → aanbeveling → actie
- Gecentraliseerde uitzonderingen: operators kunnen overschrijven met een reden, in plaats van omwegen te gebruiken
Dit is vooral nuttig in gereguleerde of hoog‑risico omgevingen waar “het model zei het” geen aanvaardbare rechtvaardiging is.
Workflows vervangen de “rapport‑overdracht”
In plaats van analytics als een aparte bestemming te behandelen, kan de interface inzichten naar taken routeren: toewijzen aan een wachtrij, om goedkeuring vragen, een notificatie triggeren, een case openen of een werkorder aanmaken. Het belangrijke verschil is dat uitkomsten binnen hetzelfde systeem worden gevolgd — zodat je kunt meten of acties werkelijk risico, kosten of vertragingen hebben verminderd.
Rolgebaseerde ervaringen en beslissingsrechten
Workflow‑gecentreerd ontwerp scheidt meestal ervaringen per rol:
- Frontline operators: snelle wachtrijen, duidelijke next‑best‑action, minimale context nodig
- Analisten: diepere drill‑downs, scenario‑testen en monitoring van data/model‑kwaliteit
- Executives: KPI’s gekoppeld aan operationele doorstroom en knelpunten, niet alleen grafieken
De gemeenschappelijke succesfactor is het product afstemmen op beslissingsrechten en bedrijfsprocedures: wie mag handelen, welke goedkeuringen zijn vereist en wat operationeel “klaar” betekent.
Governance, beveiliging en vertrouwen in de data
Governance is waar veel analytics‑programma's slagen of vastlopen. Het is niet alleen “beveiligingsinstellingen” — het is de praktische set regels en bewijzen die mensen vertrouwen geeft in de cijfers, veilig delen en gebruiken om echte beslissingen te nemen.
Wat governance moet omvatten (meer dan inloggen)
De meeste ondernemingen hebben dezelfde kerncontroles nodig, ongeacht de leverancier:
- Toegangscontroles: wie kan data, modellen en operationele outputs zien, bewerken of goedkeuren
- Datalijnage: waar een metric vandaan komt, welke bronnen het voedden en welke transformaties plaatsvonden
- Auditlogs: een verdedigbaar record van wie wat wanneer veranderde
- Goedkeuringen en change control: vooral voor “officiële” metrics, gedeelde datasets en productieworkflows
Dit is geen bureaucratie omwille van bureaucratie. Het voorkomt het “twee versies van de waarheid”‑probleem en vermindert risico wanneer analytics dichter bij operatie komt.
“Beveiliging bij het dashboard” versus beveiliging over de hele keten
Traditionele BI‑implementaties plaatsen beveiliging vaak vooral op het rapportlageniveau: gebruikers mogen bepaalde dashboards zien, en beheerders beheren permissies daar. Dat kan werken wanneer analytics vooral descriptief is.
Een Palantir‑achtige aanpak duwt beveiliging en governance door de hele keten heen: van raw data‑ingestie, naar de semantische laag (objecten, relaties, definities), naar modellen en zelfs naar de acties die uit inzichten voortkomen. Het doel is dat een operationeel besluit (zoals het dispatchen van een team, vrijgeven van voorraad of prioriteren van cases) dezelfde controles erft als de data erachter.
Least privilege en scheiding van taken (in eenvoudige termen)
Twee principes zijn belangrijk voor veiligheid en verantwoordingsplicht:
- Least privilege: mensen krijgen alleen de toegang die ze nodig hebben om hun werk te doen
- Segregation of duties: wie logica bouwt of verandert is niet dezelfde persoon die het voor productie goedkeurt
Bijvoorbeeld: een analist kan een metricdefinitie voorstellen, een data steward keurt het goed, en operations gebruikt het — met een duidelijk auditspoor.
Waarom governance adoptie aanjaagt
Goede governance is niet alleen voor compliance‑teams. Wanneer businessgebruikers lineage kunnen aanklikken, definities kunnen zien en op consistente permissies kunnen vertrouwen, houden ze op met ruzie over spreadsheets en beginnen ze te handelen op inzicht. Dat vertrouwen is wat analytics verandert van “interessante rapporten” in operationeel gedrag.
Implementatiemodellen: cloud, on‑prem en losgekoppelde omgevingen
Waar enterprise‑software draait is niet langer een IT‑detail — het bepaalt wat je met data kunt doen, hoe snel je kunt veranderen en welke risico's je accepteert. Kopers evalueren meestal vier implementatiepatronen.
Public cloud
Public cloud (AWS/Azure/GCP) optimaliseert voor snelheid: provisioning is snel, managed services verminderen infralast en schalen is eenvoudig. De belangrijkste vragen voor kopers zijn dataresidentie (welke regio, welke backups, welke supporttoegang), integratie met on‑prem systemen, en of je securitymodel cloud‑connectiviteit accepteert.
Private cloud
Een private cloud (single‑tenant of klant‑beheerde Kubernetes/VM's) wordt vaak gekozen als je cloud‑achtige automatisering nodig hebt maar strengere controle over netwerkgrenzen en auditvereisten. Het kan compliancefrictie verminderen, maar je hebt nog steeds strakke operationele discipline rond patching, monitoring en toegangsreviews nodig.
On‑prem
On‑prem deploys blijven gangbaar in productie, energie en sterk gereguleerde sectoren waar kernsystemen en data de faciliteit niet mogen verlaten. De afweging is operationele overhead: hardwarelevenscyclus, capaciteitsplanning en meer werk om omgevingen consistent te houden tussen dev/test/prod. Als je organisatie moeite heeft om platforms betrouwbaar te draaien, kan on‑prem de time‑to‑value vertragen.
Losgekoppeld / air‑gapped
Losgekoppelde (air‑gapped) omgevingen zijn een speciale casus: defensie, kritieke infrastructuur of locaties met beperkte connectiviteit. Hier moet het implementatiemodel strikte updatecontroles ondersteunen — gesigneerde artifacts, gecontroleerde promotie van releases en herhaalbare installatie in geïsoleerde netwerken.
Netwerkbeperkingen beïnvloeden ook databeweging: in plaats van continue sync vertrouw je mogelijk op staged transfers en “export/import” workflows.
De belangrijkste afwegingen
In de praktijk is het een driehoek: flexibiliteit (cloud), controle (on‑prem/air‑gapped) en snelheid van verandering (automatisering + updates). De juiste keuze hangt af van residentieregels, netwerkrealiteit en hoeveel platform‑operaties je team wil dragen.
Operationeel maken van updates: wat Apollo‑achtige levering verandert
“Een Apollo‑achtige levering” is in wezen continuous delivery voor omgevingen met hoge eisen: je kunt regelmatig verbeteringen leveren (wekelijks, dagelijks, zelfs meerdere keren per dag) terwijl je de operatie stabiel houdt.
Het doel is niet “move fast and break things.” Het is “move often and don't break anything.”
Continuous delivery in simpele termen
In plaats van wijzigingen te bundelen in een grote kwartaalrelease, leveren teams kleine, omkeerbare updates. Elke update is makkelijker te testen, makkelijker uit te leggen en eenvoudiger terug te draaien als er iets misgaat.
Voor operationele analytics is dat belangrijk omdat je “software” niet alleen een UI is — het zijn datapijplijnen, businesslogica en workflows waarop mensen vertrouwen. Een veiliger updateproces wordt onderdeel van de dagelijkse operatie.
Hoe dit verschilt van traditionele enterprisecycli
Traditionele enterprise‑upgrades lijken vaak op projecten: lange planningsvensters, coördinatie voor downtime, compatibiliteitszorgen, training en een harde omschakeldatum. Zelfs als leveranciers patches aanbieden, stellen veel organisaties updates uit omdat risico en inspanning onvoorspelbaar zijn.
Apollo‑achtige tooling probeert upgraden routine te maken in plaats van uitzonderlijk — meer als het onderhouden van infrastructuur dan het uitvoeren van een grote migratie.
“Bouwen” scheiden van “leveren”
Moderne deploymenttooling laat teams ontwikkelen en testen in geïsoleerde omgevingen, en vervolgens dezelfde build promoten door stages (dev → test → staging → productie) met consistente controles. Die scheiding helpt verrassingen te verminderen die ontstaan door verschillen tussen omgevingen.
Vragen voor leveranciers om te stellen
- Hoe handelen jullie rollback — één klik, gedeeltelijke rollback of complex herstel?
- Welke versiebeheer bestaat er voor pijplijnen, modellen en ontologie‑wijzigingen (niet alleen de UI)?
- Hoe werkt environment‑promotie en wie kan dat goedkeuren?
- Kunnen jullie canary‑releases draaien (eerst een kleine subset) of feature flags gebruiken?
- Welke audittrail toont wie wat wanneer en waarom heeft uitgerold?
- Wat is de verwachte downtime — idealiter geen — voor typische updates?
Implementatie en time‑to‑value: waar echt inspanning zit
Time‑to‑value gaat minder over hoe snel je iets kunt “installeren” en meer over hoe snel teams het eens kunnen worden over definities, rommelige data kunnen verbinden en inzichten in dagelijkse beslissingen kunnen omzetten.
Traditionele enterprise‑software legt vaak nadruk op configuratie: je neemt een vooraf gedefinieerd datamodel en workflows aan, en mapt je business erop.
Palantir‑achtige platformen mengen meestal drie modi:
- Configuratie voor toegangscontroles, dataconnecties en standaardcomponenten
- Hergebruikbare bouwblokken (templates, componenten, patronen) die in nieuwe use‑cases te assembleren zijn
- Aangepaste applicatieontwikkeling wanneer de workflow uniek is (bijv. goedkeuringen, uitzonderingbeheer, operationele overdrachten)
De belofte is flexibiliteit — maar het betekent ook dat je duidelijkheid nodig hebt over wat je bouwt versus wat je standaardiseert.
Een praktische optie tijdens vroege discovery is snel prototype‑apps te bouwen — voordat je je vastlegt op een groot platformproject. Bijvoorbeeld, teams gebruiken soms Koder.ai (een vibe‑coding platform) om een workflowbeschrijving via chat om te zetten in een werkende webapp en vervolgens met stakeholders te itereren met planning mode, snapshots en rollback. Omdat Koder.ai source code export ondersteunt en normale productie‑stacks (React op het web; Go + PostgreSQL op de backend; Flutter voor mobiel), kan het een laagdrempelige manier zijn om de “inzicht → taak → audittrail” UX en integratie‑vereisten te valideren tijdens een proof‑of‑value.