17 dec 2025·7 min
PostgreSQL connection pooling: app-pooling vs PgBouncer
PostgreSQL connection pooling: vergelijk app-pools en PgBouncer voor Go-backends, metrieken om te monitoren en misconfiguraties die latentiepieken veroorzaken.
PostgreSQL connection pooling: vergelijk app-pools en PgBouncer voor Go-backends, metrieken om te monitoren en misconfiguraties die latentiepieken veroorzaken.
Een databaseverbinding is als een telefoonlijn tussen je app en Postgres. Het openen van een verbinding kost tijd en werk aan beide kanten: TCP/TLS-opzet, authenticatie, geheugen en een backend-proces aan de Postgres-kant. Een connection pool houdt een klein aantal van deze “telefoonlijnen” open zodat je app ze kan hergebruiken in plaats van voor elk verzoek opnieuw te bellen.
Als pooling uitgeschakeld is of verkeerd geschaald, zie je zelden eerst een nette foutmelding. Je krijgt willekeurige traagheid. Requests die normaal 20–50 ms duren, duren plots 500 ms of 5 seconden en de p95 schiet omhoog. Daarna verschijnen timeouts, gevolgd door “too many connections”, of er ontstaat een wachtrij in je app terwijl die wacht op een vrije verbinding.
Limieten voor verbindingen doen er zelfs voor kleine apps toe omdat verkeer bursty is. Een marketingmail, een cron job of een paar trage endpoints kan tientallen requests tegelijk naar de database sturen. Als elk request een nieuwe verbinding opent, kan Postgres veel van zijn capaciteit besteden aan het accepteren en beheren van verbindingen in plaats van queries uit te voeren. Als je al een pool hebt maar die te groot is, kun je Postgres overbelasten met te veel actieve backends en context switching en geheugendruk veroorzaken.
Let op vroege symptomen zoals:
Pooling vermindert verbinding-churn en helpt Postgres om pieken af te handelen. Het lost geen trage SQL op. Als een query een volledige tabelscan doet of op locks wacht, verandert pooling vooral hoe het systeem faalt (eerder queueing, later timeouts), niet of het snel is.
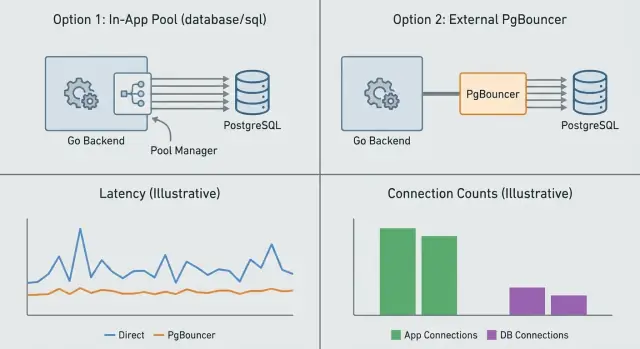
Connection pooling gaat over het beheersen van hoeveel databaseverbindingen er tegelijk bestaan en hoe ze worden hergebruikt. Je kunt dit in je app doen (app-level pooling) of met een aparte service voor Postgres (PgBouncer). Ze lossen verwante maar verschillende problemen op.
App-level pooling (in Go meestal de ingebouwde database/sql-pool) beheert verbindingen per proces. Het beslist wanneer een nieuwe verbinding open moet, wanneer er een hergebruikt kan worden en wanneer idle verbindingen gesloten worden. Dit voorkomt dat je bij elk request de opstartkosten betaalt. Wat het niet kan doen, is coördineren tussen meerdere app-instances. Als je 10 replicas draait, heb je in feite 10 gescheiden pools.
PgBouncer staat tussen je app en Postgres en pooled namens veel clients. Het is het meest nuttig wanneer je veel korte requests hebt, veel app-instances of piekerig verkeer. Het begrenst het aantal server-side verbindingen naar Postgres, zelfs als er honderden client-verbindingen tegelijk binnenkomen.
Een eenvoudige scheiding van verantwoordelijkheden:
Ze kunnen samenwerken zonder problemen met “dubbele pooling” zolang elke laag een duidelijke rol heeft: een verstandige database/sql-pool per Go-process, plus PgBouncer om een globaal connectie-budget af te dwingen.
Een veelvoorkomende verwarring is denken dat “meer pools meer capaciteit betekent.” Meestal betekent het het tegenovergestelde. Als elke service, worker en replica zijn eigen grote pool heeft, kan het totale aantal verbindingen exploderen en queueing, context switching en plotselinge latentiepieken veroorzaken.
database/sql-pooling zich echt gedraagtIn Go is sql.DB een connection pool manager, niet één enkele verbinding. Wanneer je db.Query of db.Exec aanroept, probeert database/sql een idle verbinding te hergebruiken. Als dat niet lukt, kan het een nieuwe openen (tot je limiet) of het verzoek laten wachten.
Die wachttijd is waar de “mystery latency” vaak vandaan komt. Wanneer de pool verzadigd is, queueen requests binnen je app. Van buitenaf lijkt het alsof Postgres traag is, maar de tijd wordt eigenlijk gespendeerd aan wachten op een vrije verbinding.
De meeste tuning draait om vier instellingen:
MaxOpenConns: harde limiet op open verbindingen (idle + in gebruik). Als je dit bereikt, blokkeren aanroepen.MaxIdleConns: hoeveel verbindingen klaar kunnen zitten voor hergebruik. Te laag zorgt voor frequente reconnects.ConnMaxLifetime: dwingt periodieke recycling van verbindingen af. Nuttig bij load balancers en NAT-timeouts, maar te laag veroorzaakt churn.ConnMaxIdleTime: sluit verbindingen die te lang ongebruikt zijn.Herbruik van verbindingen verlaagt meestal latency en database-CPU omdat je herhaalde opzet (TCP/TLS, auth, sessie-init) vermijdt. Maar een te grote pool kan het tegenovergestelde doen: het staat meer gelijktijdige queries toe dan Postgres goed kan verwerken, wat meer contention en overhead veroorzaakt.
Denk in totalen, niet per proces. Als elke Go-instance 50 open verbindingen toestaat en je schaalt naar 20 instances, heb je effectief 1.000 verbindingen toegestaan. Vergelijk dat met wat je Postgres-server daadwerkelijk soepel kan draaien.
Een praktisch startpunt is MaxOpenConns te koppelen aan verwachte concurrency per instance en dat vervolgens te valideren met pool-metrieken (in-use, idle en wait time) voordat je het verhoogt.
PgBouncer is een kleine proxy tussen je app en PostgreSQL. Je service maakt verbinding met PgBouncer, en PgBouncer houdt een beperkt aantal echte serververbindingen naar Postgres. Tijdens pieken queueet PgBouncer client-werk in plaats van meteen meer Postgres-backends te maken. Die wachtrij kan het verschil zijn tussen een gecontroleerde vertraging en een database die omvalt.
PgBouncer heeft drie pooling-modi:
Session pooling gedraagt zich het meest als directe verbindingen naar Postgres. Het is het minst verrassend, maar bespaart minder serververbindingen bij bursty load.
Voor typische Go HTTP-API’s is transaction pooling vaak een sterke default. De meeste requests doen een kleine query of een korte transactie en zijn dan klaar. Transaction pooling laat veel client-verbindingen een kleiner Postgres-verbindingbudget delen.
Het compromis is sessiestate. In transaction-mode kan alles wat ervan uitgaat dat een enkele serververbinding blijft hangen, breken of vreemd gedrag laten zien, zoals:
SET, SET ROLE, search_path)Als je app afhankelijk is van dat soort state, is session pooling veiliger. Statement pooling is het meest beperkend en past zelden bij webapps.
Een nuttige regel: als elk request binnen één transactie kan opzetten wat het nodig heeft, houdt transaction pooling de latency meestal constanter onder load. Als je langdurige sessiegedrag nodig hebt, gebruik dan session pooling en focus op striktere limieten in de app.
Als je een Go-service met database/sql draait, heb je al app-side pooling. Voor veel teams is dat genoeg: een paar instances, steady traffic en queries die niet extreem piekerig zijn. In dat geval is de eenvoudigste en veiligste keuze de Go-pool tunen, de databaseverbindinglimiet realistisch houden en het daar bij laten.
PgBouncer helpt het meest wanneer de database door te veel clientverbindingen tegelijk wordt geraakt. Dit zie je bij veel app-instances (of serverless-achtige scaling), bursty traffic en veel korte queries.
PgBouncer kan ook schade doen als het in de verkeerde modus wordt gebruikt. Als je code afhankelijk is van sessiestate (temp tables, prepared statements hergebruikt, advisory locks over calls heen of sessieinstellingen), kan transaction pooling verwarrende fouten veroorzaken. Als je echt sessiegedrag nodig hebt, gebruik dan session pooling of sla PgBouncer over en schaal app-pools zorgvuldig.
Gebruik deze vuistregel:
Connectielimieten zijn een budget. Als je het in één keer uitgeeft, wacht elk nieuw verzoek en springt de tail-latency omhoog. Het doel is concurrency op een gecontroleerde manier te begrenzen en tegelijkertijd de throughput zo stabiel mogelijk te houden.
Meet de pieken en tail-latency van vandaag. Noteer piek actieve verbindingen (geen gemiddelden), plus p50/p95/p99 voor requests en belangrijke queries. Noteer eventuele connection errors of timeouts.
Stel een veilig Postgres-verbindingbudget voor de app in. Begin bij max_connections en trek headroom af voor admin-toegang, migraties, achtergrondjobs en pieken. Als meerdere services de database delen, verdeel het budget doelbewust.
Vertaal het budget naar Go-limieten per instance. Deel het app-budget door het aantal instances en stel MaxOpenConns daarop in (of iets lager). Zet MaxIdleConns hoog genoeg om constante reconnects te vermijden en kies lifetimes zodat verbindingen af en toe gerecycled worden zonder churn te veroorzaken.
Voeg PgBouncer alleen toe als het nodig is en kies een modus. Gebruik session pooling als je sessiestate nodig hebt. Gebruik transaction pooling wanneer je de grootste vermindering van serververbindingen wilt en je app compatibel is.
Rol geleidelijk uit en vergelijk voor en na. Verander één ding tegelijk, canary het en vergelijk tail-latency, pool wait time en database-CPU.
Voorbeeld: als Postgres veilig 200 verbindingen aan je service kan geven en je draait 10 Go-instances, begin met MaxOpenConns=15-18 per instance. Dat laat ruimte voor pieken en verkleint de kans dat elke instance tegelijk het plafond raakt.
Pooling-problemen verschijnen zelden eerst als “teveel verbindingen.” Meestal zie je een langzaam oplopende wachttijd en dan een plotselinge jump in p95 en p99.
Begin met wat je Go-app rapporteert. Met database/sql monitor open connections, in-use, idle, wait count en wait time. Als wait count stijgt terwijl het verkeer gelijk blijft, is je pool te klein of worden verbindingen te lang vastgehouden.
Aan de database-kant: volg actieve verbindingen versus max, CPU en lock-activiteit. Als CPU laag is maar latency hoog, is het vaak queueing of locks, niet ruwe rekencapaciteit.
Als je PgBouncer draait, voeg dan een derde zicht toe: client connections, server connections naar Postgres en queue depth. Een groeiende wachtrij met stabiele server connections is een duidelijk signaal dat het budget verzadigd is.
Goede alert-signalen:
Pooling-problemen verschijnen vaak tijdens bursts: requests hopen zich op en wachten op een verbinding, en daarna ziet alles er weer normaal uit. De oorzaak is vaak een instelling die op één instance redelijk lijkt maar gevaarlijk wordt zodra je veel kopieën van de service draait.
Veelvoorkomende oorzaken:
MaxOpenConns per instance ingesteld zonder globaal budget. 100 verbindingen per instance over 20 instances is 2.000 potentiële verbindingen.ConnMaxLifetime / ConnMaxIdleTime te laag ingesteld. Dit kan reconnect-stormen veroorzaken wanneer veel verbindingen tegelijk gerecycled worden.Een eenvoudige manier om pieken te verminderen is pooling als een gedeeld limiet te behandelen, niet als een app-lokaal default: cap totale verbindingen over alle instances, houd een bescheiden idle pool en gebruik lifetimes lang genoeg om gesynchroniseerde reconnects te vermijden.
Bij traffic-surges zie je meestal één van drie uitkomsten: requests queueen terwijl ze wachten op een vrije verbinding, requests timen out, of alles wordt zo traag dat retries zich opstapelen.
Queueing is de heimelijke. Je handler draait nog steeds, maar staat geparkeerd terwijl hij wacht op een verbinding. Die wachttijd wordt deel van de responsetijd, dus een kleine pool kan een 50 ms query veranderen in een multi-seconde endpoint onder load.
Een nuttig mentaal model: als je pool 30 bruikbare verbindingen heeft en er ineens 300 gelijktijdige requests komen die allemaal de DB nodig hebben, moeten 270 daarvan wachten. Als elk request een verbinding 100 ms vasthoudt, loopt de tail-latency snel op naar seconden.
Stel een duidelijk timeout-budget en houd je eraan. De app-timeout moet iets korter zijn dan de database-timeout zodat je snel faalt en druk reduceert in plaats van werk te laten hangen.
statement_timeout zodat één slechte query geen verbindingen kan blokkerenVoeg vervolgens backpressure toe zodat je de pool niet overspoelt. Kies één of twee voorspelbare mechanismen, zoals het limiteren van concurrency per endpoint, load shedding met duidelijke fouten (zoals 429), of het scheiden van achtergrondjobs van gebruikerverkeer.
Tot slot: repareer trage queries eerst. Onder pooling-druk houden trage queries verbindingen langer vast, wat wachtijden verhoogt, wat timeouts verhoogt, wat retries triggert. Die feedback-loop is hoe “een beetje traag” verandert in “alles is traag.”
Behandel load testing als een manier om je connectie-budget te valideren, niet alleen throughput. Het doel is bevestigen dat pooling zich onder druk hetzelfde gedraagt als in staging.
Test met realistisch verkeer: dezelfde request-mix, burst-patronen en hetzelfde aantal app-instances als in productie. "One endpoint"-benchmarks verbergen vaak pool-problemen tot de lanceringsdag.
Neem een warm-up op zodat je koude caches en ramp-up-effecten niet meet. Laat pools hun normale grootte bereiken en begin dan pas met meten.
Als je strategieën vergelijkt, houd de workload identiek en voer uit:
database/sql, geen PgBouncer)Noteer na elke run een klein scorekaartje dat je bij elke release opnieuw kunt gebruiken:
Na verloop van tijd maakt dit capacity planning herhaalbaar in plaats van giswerk.
Voordat je pool-groottes aanpast, schrijf één getal op: je connection budget. Dat is het maximale veilige aantal actieve Postgres-verbindingen voor deze omgeving (dev, staging, prod), inclusief achtergrondjobs en admin-toegang. Als je het niet kunt benoemen, gok je.
Een korte checklist:
MaxOpenConns) binnen het budget (of de PgBouncer-cap) past.max_connections en gereserveerde verbindingen overeenkomen met je plan.Rollout-plan dat rollback gemakkelijk houdt:
Als je een Go + PostgreSQL-app bouwt en host op Koder.ai (koder.ai), kan Planning Mode je helpen de wijziging en wat je gaat meten in kaart te brengen, en snapshots plus rollback maken het makkelijker om terug te draaien als tail-latency slechter wordt.
Volgende stap: voeg één meting toe vóór de volgende verkeerspiek. "Time spent waiting for a connection" in de app is vaak het meest bruikbare, omdat het pooling-druk laat zien voordat gebruikers het voelen.
Een pool houdt een klein aantal PostgreSQL-verbindingen open en hergebruikt die over meerdere requests. Dit voorkomt dat je steeds de opstartkosten (TCP/TLS, authenticatie, backend-proces opzetten) betaalt en helpt de tail-latency stabiel te houden tijdens pieken.
Als de pool vol zit, wachten requests in je applicatie op een vrije verbinding en die wachttijd verschijnt als trage responses. Daardoor zie je vaak “willekeurige traagheid” omdat gemiddelden prima kunnen blijven terwijl p95/p99 opdraaien tijdens verkeerspieken.
Nee. Pooling verandert vooral hoe het systeem zich gedraagt bij load door reconnect-churn te verminderen en concurrency te beperken. Als een query langzaam is door scans, locks of slechte indexering, dan maakt pooling die query niet sneller; het beperkt alleen hoeveel trage queries tegelijk kunnen draaien.
App-pooling beheert verbindingen per proces, dus elke app-instance heeft zijn eigen pool en grenzen. PgBouncer staat vóór Postgres en handhaaft een globaal connectie-budget over veel clients, wat handig is bij veel replicas of piekerig verkeer.
Als je een klein aantal instances draait en het totaal aantal open verbindingen ruim onder de database-limiet blijft, is het afstemmen van Go’s database/sql-pool meestal voldoende. Voeg PgBouncer toe wanneer veel instances, autoscaling of bursty traffic het totaal aan verbindingen boven wat Postgres goed kan afhandelen zou duwen.
Een handige aanpak is een connectie-budget voor de service vastleggen en dat door het aantal instances delen. Stel MaxOpenConns iets lager in dan dat resultaat per instance. Begin klein, bekijk wachttijd en p95/p99, en verhoog alleen als de database echt headroom heeft.
Transaction pooling is vaak een goede standaard voor typische HTTP-API’s omdat het veel client-verbindingen toestaat om een kleiner aantal server-verbindingen te delen en stabieler blijft bij pieken. Gebruik session pooling als je code afhankelijk is van sessiestate die persist over statements moet blijven.
Prepared statements, tijdelijke tabellen, advisory locks en sessie-instellingen kunnen anders werken omdat een client mogelijk niet steeds dezelfde server-verbinding krijgt. Als je die features nodig hebt, houd dan alles binnen één transactie per request of gebruik session pooling om verwarrende fouten te voorkomen.
Houd p95/p99 in de gaten samen met app-side pool-wachttijd, want wachttijd stijgt vaak voordat gebruikers het merken. Op Postgres: actieve verbindingen, CPU en locks monitoren; op PgBouncer: client connections, server connections en queue depth om te zien of je het budget verzadigt.
Stop eerst onbeperkt wachten door request-deadlines en statement_timeout in te stellen zodat één trage query geen verbindingen voor altijd blokkeert. Voeg daarna backpressure toe door concurrency te limiteren op DB-intensieve endpoints, load shedding (bijv. 429) of achtergrondjobs te scheiden, en vermijd te korte connection lifetimes die reconnect-storms veroorzaken.