02 sep 2025·8 min
Protobuf vs JSON voor API's: snelheid, grootte en compatibiliteit
Vergelijk Protobuf en JSON voor API's: payloadgrootte, snelheid, leesbaarheid, tooling, versiebeheer en wanneer elk formaat het beste past in echte producten.
Vergelijk Protobuf en JSON voor API's: payloadgrootte, snelheid, leesbaarheid, tooling, versiebeheer en wanneer elk formaat het beste past in echte producten.
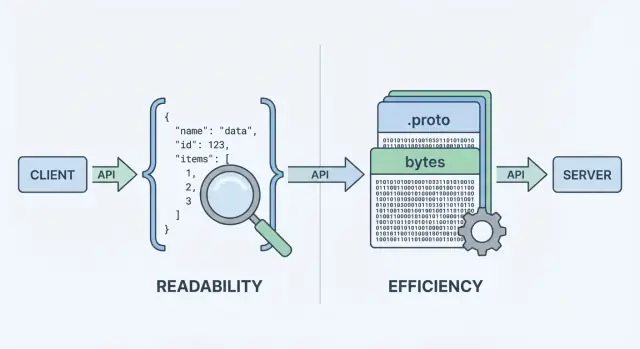
Als je API data verzendt of ontvangt, heeft het een dataformaat nodig — een gestandaardiseerde manier om informatie in request- en response-body's te representeren. Dat formaat wordt vervolgens geserialiseerd (omgezet in bytes) voor transport over het netwerk, en gedeserialiseerd terug naar bruikbare objecten op client en server.
Twee van de meest voorkomende keuzes zijn JSON en Protocol Buffers (Protobuf). Ze kunnen dezelfde zakelijke data representeren (gebruikers, orders, timestamps, lijsten met items), maar maken verschillende afwegingen rond prestaties, payloadgrootte en ontwikkelaarsworkflow.
JSON (JavaScript Object Notation) is een tekstgebaseerd formaat opgebouwd uit eenvoudige structuren zoals objecten en arrays. Het is populair voor REST-API's omdat het makkelijk te lezen is, eenvoudig te loggen en makkelijk te inspecteren met tools zoals curl en browser DevTools.
Een belangrijke reden waarom JSON overal is: de meeste talen hebben uitstekende ondersteuning en je kunt een response visueel inspecteren en meteen begrijpen.
Protobuf is een binaire serialisatietechniek van Google. In plaats van tekst te sturen, stuurt het een compacte binaire representatie die wordt gedefinieerd door een schema (een .proto-bestand). Het schema beschrijft de velden, hun types en hun numerieke tags.
Omdat het binair en schema-gedreven is, levert Protobuf vaak kleinere payloads en kan het sneller te parsen zijn — wat belangrijk is bij hoge requestvolumes, mobiele netwerken of latency-gevoelige services (veelal in gRPC-omgevingen, maar niet beperkt tot gRPC).
Het is belangrijk om wat je verstuurt te scheiden van hoe het gecodeerd wordt. Een “user” met een id, naam en e-mail kan zowel in JSON als in Protobuf worden gemodelleerd. Het verschil zit in de prijs die je betaalt in:
Er is geen pasklaar antwoord. Voor veel publiek beschikbare API's blijft JSON de standaard omdat het toegankelijk en flexibel is. Voor interne service-naar-service communicatie, prestatiegevoelige systemen of strikte contracten kan Protobuf beter passen. Het doel van deze gids is je te helpen kiezen op basis van beperkingen — niet op basis van ideologie.
Als een API data retourneert kan het geen “objecten” direct over het netwerk sturen. Het moet ze eerst omzetten naar een stream bytes. Die conversie is serialisatie — denk aan het als het inpakken van data in een verzendbare vorm. Aan de andere kant decodeert de client die bytes weer (deserialisatie), het uitpakken naar bruikbare datastructuren.
Een typisch request/response-flow ziet er zo uit:
Die “encodeerstap” is waar de formatkeuze telt. JSON-encoding produceert leesbare tekst zoals {\"id\":123,\"name\":\"Ava\"}. Protobuf-encoding produceert compacte binaire bytes die zonder tooling niet menselijk betekenisvol zijn.
Omdat elke response gepakt en uitgepakt moet worden, beïnvloedt het formaat:
Je API-stijl duwt vaak de beslissing:
curl, en simpel te loggen en inspecteren.Je kunt JSON met gRPC gebruiken (via transcoding) of Protobuf over plain HTTP, maar de standaard ergonomie van je stack — frameworks, gateways, clientlibraries en debuggewoonten — bepaalt vaak wat dagelijks het makkelijkst draait.
Wanneer mensen protobuf vs json vergelijken, beginnen ze meestal bij twee metrics: hoe groot is de payload en hoe lang duurt encode/decode. De kopregel is simpel: JSON is tekst en neigt naar verhalend; Protobuf is binair en is meestal compacter.
JSON herhaalt veldnamen en gebruikt tekstrepresentaties voor nummers, booleans en structuur, dus het stuurt vaak meer bytes over het netwerk. Protobuf vervangt veldnamen door numerieke tags en pakt waarden efficiënt in, wat doorgaans leidt tot merkbaar kleinere payloads — zeker voor grote objecten, herhaalde velden en diep geneste data.
Dat gezegd hebbende kan compressie het verschil verkleinen. Met gzip of brotli comprimeert JSON herhaalde sleutels heel goed, dus de "JSON versus Protobuf grootte"-verschillen kunnen in echte omgevingen kleiner worden. Protobuf kan ook gecomprimeerd worden, maar het relatieve voordeel is vaak kleiner.
JSON-parsers moeten tekst tokenizen en valideren, strings naar nummers omzetten en omgaan met randgevallen (escaping, whitespace, unicode). Protobuf-decodering is directer: lees tag → lees getypeerde waarde. In veel services vermindert Protobuf CPU-tijd en garbage creatie, wat de tail latency onder load kan verbeteren.
Op mobiele netwerken of verbindingen met hoge latency betekent minder bytes doorgaans snellere overdracht en minder radio-tijd (wat ook batterij kan sparen). Maar als je responses al klein zijn, kunnen handshake-overhead, TLS en serververwerking domineren — waardoor de formatkeuze minder zichtbaar is.
Meet met je echte payloads:
Dat verandert discussies over “API-serialisatie” in data die je voor jouw API kunt vertrouwen.
Op ontwikkelaarservaring wint JSON vaak standaard. Je kunt vrijwel overal een JSON-request of -response inspecteren: in browser DevTools, curl output, Postman, reverse proxies en platte tekstlogs. Wanneer iets faalt, is “wat hebben we daadwerkelijk gestuurd?” meestal één copy/paste verwijderd.
Protobuf is anders: compact en strikt, maar niet mensleesbaar. Als je rauwe Protobuf-bytes logt zie je base64-blobs of onleesbare binaire data. Om de payload te begrijpen heb je het juiste .proto-schema en een decoder nodig (bijv. protoc, taalspecifieke tooling of de gegenereerde types van je service).
Met JSON is issues reproduceren eenvoudig: pak een gelogde payload, redacteer secrets, replay met curl en je hebt vaak een minimal testgeval.
Met Protobuf debug je doorgaans door:
Dat extra stapje is beheersbaar — mits het team een herhaalbare workflow heeft.
Gestructureerde logging helpt beide formaten. Log request IDs, methodenames, gebruikers-/accountidentifiers en sleutelvelden in plaats van hele bodies.
Voor Protobuf specifiek:
.proto hebben we gebruikt?" te vermijden.Voor JSON: overweeg het loggen van gecanonicaliseerde JSON (stabiele sleutelvolgorde) om diffs en incidenttijdlijnen beter leesbaar te maken.
API's verplaatsen niet alleen data — ze verplaatsen betekenis. Het grootste verschil tussen JSON en Protobuf is hoe duidelijk die betekenis wordt gedefinieerd en afgedwongen.
JSON is standaard “schema-loos”: je kunt elk object met willekeurige velden sturen, en veel clients accepteren het zolang het er redelijk uitziet.
Die flexibiliteit is handig in het begin, maar kan ook fouten verbergen. Veelvoorkomende valkuilen zijn:
userId in de ene response, user_id in een andere, of ontbrekende velden afhankelijk van de codepad."42", "true" of "2025-12-23" — makkelijk te maken, makkelijk mis te interpreteren.null kan “onbekend”, “niet gezet” of “bewust leeg” betekenen, en verschillende clients behandelen het anders.Je kunt een JSON Schema of OpenAPI specificatie toevoegen, maar JSON zelf verplicht consumenten daar niet aan.
Protobuf vereist een schema gedefinieerd in een .proto-bestand. Een schema is een gedeeld contract dat zegt:
Dat contract helpt onbedoelde wijzigingen te voorkomen — zoals het veranderen van een integer naar een string — omdat de gegenereerde code specifieke types verwacht.
Met Protobuf blijven nummers nummers, enums zijn beperkt tot bekende waarden, en timestamps worden typisch gemodelleerd met well-known types (in plaats van ad-hoc stringformaten). “Niet gezet” is ook duidelijker: in proto3 is afwezigheid onderscheidbaar van default-waarden als je optional velden of wrapper types gebruikt.
Als je API afhankelijk is van precieze types en voorspelbare parsing tussen teams en talen, biedt Protobuf vangrails die JSON meestal via conventies probeert te bereiken.
API's evolueren: je voegt velden toe, past gedrag aan en stopt met oude onderdelen. Het doel is het contract te veranderen zonder consumenten te verrassen.
Een goede evolutiestrategie streeft naar beide, maar achterwaartse compatibiliteit is meestal de minimale eis.
In Protobuf heeft elk veld een nummer (bijv. email = 3). Dat nummer — niet de veldnaam — gaat op het netwerk. Namen zijn vooral voor mensen en gegenereerde code.
Daardoor:
Veilige wijzigingen (meestal)
Riskante wijzigingen (vaak brekend)
Beste praktijk: gebruik reserved voor oude nummers/namen en houd een changelog bij.
JSON heeft geen ingebouwd schema, dus compatibiliteit hangt af van je patronen:
Documenteer deprecations vroeg: wanneer een veld is uitgefaseerd, hoe lang het ondersteund blijft en wat het vervangt. Publiceer een simpel versiebeleid (bijv. “additieve wijzigingen zijn niet-brekend; verwijderingen vereisen een nieuwe major versie”) en houd je eraan.
De keuze tussen JSON en Protobuf komt vaak neer op waar je API moet draaien — en wat je team wil onderhouden.
JSON is vrijwel universeel: elke browser en backend runtime kan het parsen zonder extra dependencies. In een web-app is fetch() + JSON.parse() het eenvoudige pad, en proxies, API-gateways en observability-tools “begrijpen” JSON vaak uit het doosje.
Protobuf kan ook in de browser draaien, maar het is geen zero-cost default. Meestal voeg je een Protobuf-library (of gegenereerde JS/TS-code) toe, beheer je bundelgrootte en beslis je of je Protobuf over HTTP stuurt op manieren die je browser-tools makkelijk kunnen inspecteren.
Op iOS/Android en in backendtalen (Go, Java, Kotlin, C#, Python, etc.) is Protobuf-ondersteuning volwassen. Het grote verschil is dat Protobuf ervan uitgaat dat je per platform libraries gebruikt en meestal code genereert uit .proto-bestanden.
Codegeneratie brengt echte voordelen:
Het voegt ook kosten toe:
.proto-pakketten publiceren, versie-pinning)Protobuf is nauw verbonden met gRPC, wat je een compleet toolingverhaal geeft: servicedefinities, client-stubs, streaming en interceptors. Als je gRPC overweegt, is Protobuf de natuurlijke keuze.
Als je een traditionele JSON REST API bouwt, blijft JSON's tooling-ecosysteem eenvoudiger — zeker voor publieke API's en snelle integraties.
Als je de API-surface nog verkent, helpt het om snel in beide stijlen te prototypen voordat je standaardiseert. Teams die Koder.ai gebruiken prototypen bijvoorbeeld vaak een JSON REST API voor brede compatibiliteit en een interne gRPC/Protobuf-service voor efficiëntie, en benchmarken vervolgens echte payloads voordat iets de definitieve standaard wordt. Omdat Koder.ai full-stack apps kan genereren (React voor het web, Go + PostgreSQL op de backend, Flutter voor mobiel) en planningmodus plus snapshots/rollback ondersteunt, is het praktisch om contracten iteratief bij te stellen zonder dat formatbeslissingen in een langdurige refactor veranderen.
De keuze tussen JSON en Protobuf gaat niet alleen over payloadgrootte of snelheid. Het beïnvloedt ook hoe goed je API past bij caching-lagen, gateways en de tools waarop je team vertrouwt tijdens incidenten.
De meeste HTTP-cachinginfrastructuur (browsercaches, reverse proxies, CDNs) is geoptimaliseerd rond HTTP-semantiek, niet rond een specifiek body-formaat. Een CDN kan elke bytes cachen zolang de response cacheable is.
Dat gezegd hebbende verwachten veel teams HTTP/JSON aan de edge omdat het makkelijk te inspecteren en te troubleshooten is. Met Protobuf werkt cachen nog steeds, maar je wilt zorgvuldig zijn over:
Vary)Cache-Control, ETag, Last-Modified)Als je zowel JSON als Protobuf ondersteunt, gebruik content negotiation:
Accept: application/json of Accept: application/x-protobufContent-TypeZorg dat caches dit begrijpen door Vary: Accept te zetten. Anders kan een cache een JSON-response opslaan en naar een Protobuf-client serveren (of andersom).
API-gateways, WAFs, request/response transformers en observability-tools nemen vaak JSON-bodies aan voor:
Binaire Protobuf kan die features beperken tenzij je tooling Protobuf-aware is (of je decodeerstappen toevoegt).
Een veelgebruikt patroon is JSON aan de rand, Protobuf binnenin:
Dit houdt externe integraties simpel terwijl je Protobuf's prestatiewinsten benut waar je zowel client als server beheert.
De keuze JSON of Protobuf verandert hoe data gecodeerd en geparsed wordt — maar vervangt geen kernvereisten zoals authenticatie, encryptie, autorisatie en server-side validatie. Een snelle serializer redt geen API die onbetrouwbare input accepteert zonder limieten.
Het kan verleidelijk zijn Protobuf als “veiliger” te zien omdat het binair en minder leesbaar is. Dat is geen beveiligingsstrategie. Aanvallers hebben je payloads niet mensleesbaar nodig — ze hebben alleen je endpoint nodig. Als de API gevoelige velden lekt, onveilige toestanden accepteert of zwakke auth heeft, zal het veranderen van formaat dat niet oplossen.
Versleutel transport (TLS), handhaaf autorisaties, valideer inputs en log veilig ongeacht of je JSON REST API of grpc protobuf gebruikt.
Beide formaten delen gemeenschappelijke risico's:
Om API's betrouwbaar te houden onder load en misbruik, pas je dezelfde vangrails toe op beide formaten:
Kortom: "binair versus tekstformaat" beïnvloedt vooral prestaties en ergonomie. Beveiliging en betrouwbaarheid komen van consistente limieten, up-to-date dependencies en expliciete validatie — onafhankelijk van welke serializer je kiest.
Kiezen tussen JSON en Protobuf gaat minder over welke beter is en meer over wat je API moet optimaliseren: mensvriendelijkheid en bereik, of efficiëntie en strikte contracten.
JSON is meestal de veiligste default wanneer je brede compatibiliteit en eenvoudig debuggen nodig hebt.
Typische scenario's:
Protobuf wint vaak als prestaties en consistentie belangrijker zijn dan leesbaarheid.
Typische scenario's:
Gebruik deze vragen om snel te beslissen:
Als je nog twijfelt is de aanpak “JSON aan de rand, Protobuf binnenin” vaak een pragmatisch compromis.
Migreren van formaten gaat minder over alles herschrijven en meer over het verminderen van risico voor consumenten. De veiligste overgangen houden de API bruikbaar tijdens de transitie en maken terugdraaien eenvoudig.
Kies een laag-risico oppervlak — vaak een interne service-call of één read-only endpoint. Zo valideer je snel het Protobuf-schema, gegenereerde clients en observeerbaarheidswijzigingen zonder een big-bang project.
Een praktische eerste stap is het toevoegen van een Protobuf-representatie voor een bestaand resource terwijl je de JSON-vorm ongewijzigd houdt. Je ontdekt snel waar je datamodel ambigu is (null vs missing, nummers vs strings, datumformaten) en kunt dat in het schema oplossen.
Voor externe API's is dubbele ondersteuning meestal de soepelste route:
Content-Type en Accept headers./v2/...) aan als negotiating moeilijk is met je tooling.Zorg dat beide formaten uit dezelfde source-of-truth worden geproduceerd om subtiele drift te vermijden.
Plan voor:
Publiceer .proto-bestanden, veldcommentaar en concrete request/response-voorbeelden (JSON en Protobuf) zodat consumenten kunnen verifiëren dat ze de data correct interpreteren. Een korte “migration guide” en changelog vermindert supportload en versnelt adoptie.
Kiezen tussen JSON en Protobuf is vaak minder ideologisch en meer gebaseerd op de realiteit van je verkeer, clients en operationele beperkingen. De meest betrouwbare route is meten, beslissingen documenteren en veranderingen saai houden.
Draai een klein experiment op representatieve endpoints.
Volg:
Doe dit in staging met productie-achtige data en valideer daarna in productie op een kleine slice van het verkeer.
Of je nu JSON Schema/OpenAPI of .proto-bestanden gebruikt:
Zelfs als je Protobuf kiest voor prestaties, houd je docs vriendelijk:
Als je docs of SDK-guides onderhoudt, noem ze duidelijk (bijvoorbeeld: /docs en /blog). Als prijsstelling of gebruikslimieten formatkeuzes beïnvloeden, maak dat ook zichtbaar (/pricing).
JSON is een tekstgebaseerd formaat dat makkelijk te lezen, loggen en testen is met gangbare tools. Protobuf is een compact binair formaat gedefinieerd door een .proto-schema, dat vaak kleinere payloads en snellere parsing oplevert.
Kies op basis van je randvoorwaarden: bereik en debugbaarheid (JSON) versus efficiëntie en strikte contracten (Protobuf).
APIs sturen bytes, geen in-memory objecten. Serialisatie codeert je serverobjecten naar een payload (JSON-tekst of Protobuf-binaire) voor transport; deserialisatie decodeert die bytes terug naar client/server-objecten.
Je formatkeuze beïnvloedt bandbreedte, latency en CPU besteed aan (de)serialisatie.
Vaak wel, vooral bij grote of geneste objecten en herhaalde velden, omdat Protobuf numerieke tags en efficiënte binaire codering gebruikt.
Als je gzip/brotli inschakelt, comprimeert JSON herhaalde sleutels echter goed, dus het verschil in praktijk kan kleiner worden. Meet zowel raw als gecomprimeerde groottes.
Dat kan. JSON-parsers moeten tekst tokenizen, escaping/unicode afhandelen en strings naar nummers converteren. Protobuf-decodering is directer (tag → getypeerde waarde), wat vaak CPU-tijd en allocaties vermindert.
Als payloads echter erg klein zijn, kunnen TLS, netwerk-RTT en applicatiewerk de meeste latency bepalen, waardoor het voordeel van Protobuf minder zichtbaar is.
Standaard is het lastiger. JSON is mensleesbaar en makkelijk te inspecteren in DevTools, logs, curl en Postman. Protobuf-payloads zijn binair, dus je hebt meestal het bijbehorende .proto-schema en decodeertools nodig.
Een praktische verbetering is het loggen van een gedecodeerde, geredigeerde debugweergave (bijv. JSON) naast request IDs en kernvelden.
JSON is flexibel en vaak “schema-loos” tenzij je JSON Schema/OpenAPI afdwingt. Die flexibiliteit kan leiden tot inconsistente velden, “stringy-typed” waarden en ambigu null-semantiek.
Protobuf handhaaft types via een .proto-contract, genereert sterk getypte code en maakt evolueerbare contracten duidelijker—zeker wanneer meerdere teams en talen meedoen.
Protobuf-compatibiliteit wordt bepaald door veldnummers (tags). Veilige wijzigingen zijn meestal additief (nieuwe optionele velden met nieuwe nummers). Brekende wijzigingen omvatten het hergebruiken van veldnummers of het incompatible wijzigen van types.
Gebruik reserved voor verwijderde veldnummers/naam en houd een changelog bij. Voor JSON: geef de voorkeur aan additionele velden, houd types stabiel en behandel onbekende velden als negeerbaar.
Ja. Gebruik HTTP content negotiation:
Accept: application/json of Accept: application/x-protobufContent-TypeVary: Accept toe zodat caches geen formaten door elkaar halenAls tooling negotiatie lastig maakt, kan een aparte endpoint/version tijdelijk helpen.
Het hangt af van je omgeving:
Houd rekening met de onderhoudskosten van codegen en gedeelde schema-versiebeheer bij het kiezen voor Protobuf.
Behandel beide als onbetrouwbare input. Formaatkeuze is geen beveiligingslaag.
Praktische voorzorgen voor beide:
Houd parsers/bibliotheken up-to-date om blootstelling aan parserkwetsbaarheden te verminderen.