05 okt 2025·8 min
RabbitMQ voor je applicaties: patronen, inrichting en beheer
Leer hoe je RabbitMQ gebruikt in je applicaties: kernconcepten, veelvoorkomende patronen, betrouwbaarheidstips, schalen, beveiliging en monitoring voor productie.
Leer hoe je RabbitMQ gebruikt in je applicaties: kernconcepten, veelvoorkomende patronen, betrouwbaarheidstips, schalen, beveiliging en monitoring voor productie.
RabbitMQ is een message broker: het zit tussen onderdelen van je systeem en verplaatst betrouwbaar “werk” (berichten) van producers naar consumers. Applicatieteams grijpen er vaak naar als directe, synchrone calls (service-naar-service HTTP, gedeelde databases, cronjobs) fragiele afhankelijkheden, ongelijke load en moeilijk te debuggen foutketens beginnen te creëren.
Verkeerspieken en ongelijke werklast. Als je app in korte tijd 10× meer aanmeldingen of bestellingen krijgt, kan alles direct verwerken downstream-services overweldigen. Met RabbitMQ zetten producers taken snel in de wachtrij en consumers werken die af in een gecontroleerd tempo.
Strakke koppeling tussen services. Wanneer Service A Service B moet aanroepen en wachten, verspreiden fouten en latentie zich. Messaging ontkoppelt: A publiceert een bericht en gaat door; B verwerkt het wanneer beschikbaar.
Veiliger foutafhandeling. Niet elke fout hoort direct als fout aan de gebruiker te worden getoond. RabbitMQ helpt je met achtergrondretries, het isoleren van “poison” berichten en het vermijden van verlies van werk tijdens tijdelijke storingen.
Teams krijgen meestal gladdere werklasten (pieken bufferen), ontkoppelde services (minder runtime-afhankelijkheden) en gecontroleerde retries (minder handmatige nabehandeling). Net zo belangrijk: het wordt makkelijker uit te zoeken waar werk vastzit — bij de producer, in een queue of in een consumer.
Deze gids focust op praktisch gebruik van RabbitMQ voor applicatieteams: kernconcepten, veelvoorkomende patronen (pub/sub, work queues, retries en dead-letter queues) en operationele aandachtspunten (security, schaling, observeerbaarheid, troubleshooting).
Hij is niet bedoeld als volledige AMQP-specificatie of een diepe duik in alle RabbitMQ-plugins. Het doel is je te helpen berichtstromen te ontwerpen die onderhoudbaar blijven in echte systemen.
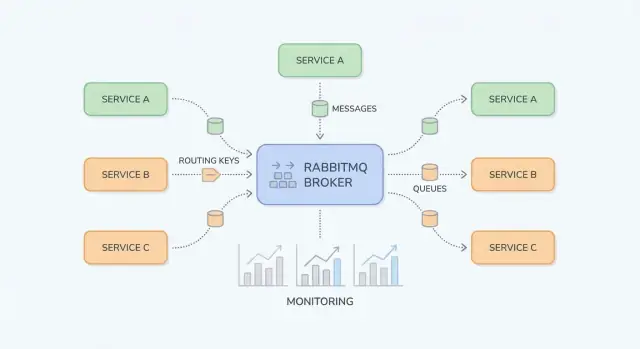
RabbitMQ is een message broker die berichten tussen onderdelen van je systeem routeert, zodat producers werk kunnen afgeven en consumers het verwerken wanneer ze eraan toe zijn.
Bij een directe HTTP-call stuurt Service A een verzoek naar Service B en wacht meestal op een antwoord. Als Service B traag is of down, faalt of vertraagt Service A, en moet je timeouts, retries en backpressure in elke caller afhandelen.
Met RabbitMQ (meestal via AMQP) publiceert Service A een bericht naar de broker. RabbitMQ slaat het op en routeert het naar de juiste queue(s), en Service B consumeert het asynchroon. De kernverandering is dat je via een duurzame tussenlaag communiceert die pieken buffert en ongelijke werklast gladstrijkt.
Messaging is een goede keuze als je:
Messaging is minder geschikt als je:
Synchronous (HTTP):
Een checkout-service roept via HTTP een invoicing-service aan: “Maak factuur.” De gebruiker wacht terwijl de facturatie loopt. Is de facturatie traag, dan stijgt de checkout-latentie; is hij down, dan faalt checkout.
Asynchroon (RabbitMQ):
De checkout publiceert invoice.requested met het order-id. De gebruiker krijgt direct een bevestiging dat de bestelling ontvangen is. Invoicing consumeert het bericht, genereert de factuur en publiceert vervolgens invoice.created zodat e-mail/notifications het kunnen oppikken. Elke stap kan onafhankelijk retryen en tijdelijke uitval breekt niet automatisch de hele flow.
RabbitMQ is het meest begrijpelijk als je “waar berichten gepubliceerd worden” scheidt van “waar ze opgeslagen worden”. Producers publiceren naar exchanges; exchanges routeren naar queues; consumers lezen van queues.
Een exchange slaat geen berichten op. Hij evalueert regels en stuurt berichten door naar één of meer queues.
billing of email).region=eu AND tier=premium), maar bewaar het voor speciale gevallen omdat het lastiger te doorgronden is.Een queue is waar berichten wachten tot een consumer ze verwerkt. Een queue kan één consumer hebben of meerdere (concurrerende consumers), en berichten worden meestal één voor één aan een consumer geleverd.
Een binding verbindt een exchange met een queue en definieert de routingregel. Denk eraan als: “Als een bericht bij exchange X aankomt met routing key Y, lever het dan aan queue Q.” Je kunt meerdere queues aan dezelfde exchange binden (pub/sub) of één queue voor meerdere routing keys binden.
Voor direct exchanges is routing exact. Voor topic exchanges zien routing keys eruit als puntgescheiden woorden, bijvoorbeeld:
orders.createdorders.eu.refundedBindings kunnen wildcards bevatten:
* matcht precies één woord (bijv. orders.* matcht orders.created)# matcht nul of meer woorden (bijv. orders.# matcht orders.created en orders.eu.refunded)Dit geeft je een nette manier om nieuwe consumers toe te voegen zonder producers te veranderen — maak een nieuwe queue en bind die met het patroon dat je nodig hebt.
Nadat RabbitMQ een bericht aflevert, rapporteert de consumer wat er gebeurde:
Wees voorzichtig met requeue: een bericht dat altijd faalt kan eindeloos blijven lopen en de queue blokkeren. Veel teams koppelen nacks aan een retry-strategie en een dead-letter queue (later behandeld) zodat fouten voorspelbaar worden afgehandeld.
RabbitMQ blinkt uit wanneer je werk of notificaties tussen delen van je systeem wilt verplaatsen zonder alles te laten wachten op één trage stap. Hieronder patronen die vaak in producten voorkomen.
Wanneer meerdere consumers op hetzelfde event moeten reageren — zonder dat de publisher weet wie ze zijn — is publish/subscribe een nette oplossing.
Voorbeeld: als een gebruiker zijn profiel bijwerkt, wil je misschien parallel search-indexering, analytics en een CRM-sync informeren. Met een fanout exchange broadcast je naar alle gebonden queues; met een topic exchange routeer je selectief (bv. user.updated, user.deleted). Dit voorkomt strakke koppeling en laat teams later nieuwe subscribers toevoegen zonder de producer te veranderen.
Als een taak tijd kost, duw hem in een queue en laat workers asynchroon verwerken:
Dit houdt webrequests snel en laat je workers onafhankelijk schalen. Het is ook een natuurlijke manier om concurrency te beheersen: de queue is je “todo-lijst” en het aantal workers is je “doorvoersnelheid-knop”.
Veel workflows overschrijden servicegrenzen: order → billing → shipping is het klassieke voorbeeld. In plaats van dat één service de volgende aanroept en blokkeert, publiceert elke service een event wanneer een stap klaar is. Downstream services consumeren die events en zetten de workflow voort.
Dit verbetert veerkracht (een tijdelijke storing bij shipping breekt de checkout niet) en maakt eigenaarschap duidelijker: elke service reageert op de events die voor hem relevant zijn.
RabbitMQ is ook een buffer tussen je app en afhankelijkheden die traag of flaky zijn (third-party APIs, legacy systemen, batch-databases). Je zet verzoeken snel in de wachtrij en verwerkt ze met gecontroleerde retries. Als de dependency down is, hoopt werk veilig op en wordt het later afgehandeld — in plaats van dat timeouts je hele applicatie verstoren.
Als je queues gefaseerd wilt invoeren, is een kleine “async outbox” of één achtergrondjob-queue vaak een goede eerste stap (zie blogpost over rollout-plan).
Een RabbitMQ-opzet blijft prettig als routes voorspelbaar zijn, namen consistent zijn en payloads evolueren zonder oudere consumers te breken. Voordat je nog een queue toevoegt, zorg dat het “verhaal” van een bericht duidelijk is: waar het vandaan komt, hoe het gerouteerd wordt en hoe een collega het end-to-end kan debuggen.
Het juiste exchange-type voorkomt one-off bindings en onverwachte fan-outs:
billing.invoice.created).billing.*.created, *.invoice.*). Dit is de meest voorkomende keuze voor onderhoudbare event-routing.Een goede vuistregel: als je complexe routinglogica in code begint te maken, hoort dat vaak in een topic exchange patroon thuis.
Behandel message bodies als publieke API's. Gebruik expliciete versioning (bijv. een top-level veld schema_version: 2) en streef naar backward compatibility:
Zo blijven oudere consumers werken terwijl nieuwe langzaam migreren.
Maak troubleshooting eenvoudig door metadata te standaardiseren:
correlation_id: verbindt commando's/events die bij dezelfde business-actie horen.trace_id (of W3C traceparent): linkt berichten aan distributed tracing over HTTP en async flows.Als elke publisher deze consistent zet, kun je één transactie volgen over meerdere services zonder giswerk.
Gebruik voorspelbare, doorzoekbare namen. Een veelgebruikt patroon:
<domain>.<type> (bijv. billing.events)<domain>.<entity>.<verb> (bijv. billing.invoice.created)<service>.<purpose> (bijv. reporting.invoice_created.worker)Consistentie wint van creativiteit: toekomstige jij (en je on-call team) zal je dankbaar zijn.
Betrouwbare messaging gaat vooral over plannen voor falen: consumers crashen, downstream APIs timen uit en sommige events zijn gewoon malformed. RabbitMQ geeft je de tools, maar je applicatiecode moet meewerken.
Een veelvoorkomende opzet is at-least-once delivery: een bericht kan meer dan eens worden afgeleverd, maar het mag niet stilletjes verloren gaan. Dit gebeurt typisch wanneer een consumer een bericht ontvangt, begint met verwerken en dan faalt vóór het ack — RabbitMQ zal het bericht requeue'en en opnieuw afleveren.
Praktische conclusie: duplicaten zijn normaal, dus je handler moet meerdere keren draaien veilig kunnen verwerken.
Idempotentie betekent dat “het twee keer verwerken van hetzelfde bericht hetzelfde effect heeft als één keer.” Handige aanpakken:
message_id op (of een business key zoals order_id + event_type + version) en sla die op in een “processed” tabel/cache met een TTL.PENDING is) of database-uniciteitsconstraints om dubbele creaties te voorkomen.Retries behandel je het beste als een aparte stroom, niet als een tight loop in je consumer.
Een veelgebruikt patroon:
Dit creëert backoff zonder berichten “vast” te houden als unacked.
Sommige berichten zullen nooit slagen (foute schema's, missende referentiegegevens, codebugs). Detecteer ze via:
Routeer deze naar een DLQ voor quarantaine. Behandel de DLQ als een operationele inbox: inspecteer payloads, los het onderliggende probleem op en replay geselecteerde berichten handmatig (bij voorkeur via een gecontroleerd script/tool) in plaats van alles terug te knallen in de hoofdqueue.
RabbitMQ-prestaties worden meestal beperkt door een paar praktische factoren: hoe je verbindingen beheert, hoe snel consumers veilig werk kunnen verwerken, en of queues als “storage” worden gebruikt. Het doel is stabiele throughput zonder een groeiende backlog.
Een veelgemaakte fout is voor elke publisher of consumer een nieuwe TCP-verbinding te openen. Verbindingen zijn zwaarder dan je denkt (handshakes, heartbeats, TLS), dus houd ze langlevend en hergebruik ze.
Gebruik channels om werk te multiplexen over een kleiner aantal verbindingen. Vuistregel: weinig connecties, veel channels. Maak ook geen duizenden channels blindelings — elk channel heeft overhead en je clientbibliotheek kan eigen limieten hebben. Geef de voorkeur aan een kleine channel-pool per service en hergebruik channels voor publiceren.
Als consumers te veel berichten tegelijk pakken, zie je geheugenspikes, lange verwerkingstijden en ongelijke latentie. Stel een prefetch (QoS) in zodat elke consumer slechts een gecontroleerd aantal unacked-berichten vasthoudt.
Praktische richtlijnen:
Grote berichten verlagen throughput en verhogen geheugenbelasting (bij publishers, brokers en consumers). Als je payload groot is (documenten, afbeeldingen, grote JSON), overweeg dan opslag elders (object storage of database) en stuur alleen een ID + metadata via RabbitMQ.
Een goede vuistregel: houd berichten in de KB-range, niet MB.
Groeien van queues is een symptoom, geen strategie. Voeg backpressure toe zodat producers vertragen als consumers niet bijblijven:
Bij twijfel: verander één knop tegelijk en meet: publish rate, ack rate, queue length en end-to-end latency.
Security voor RabbitMQ draait om het versmallen van de “randen”: hoe clients verbinden, wie wat mag doen en hoe je credentials buiten de verkeerde plekken houdt. Gebruik deze checklist als basis en pas hem aan je compliance-eisen aan.
RabbitMQ-permissies zijn krachtig als je ze consequent toepast.
Voor operationele hardening (poorten, firewalls en auditing) houd een korte interne runbook bij en verwijs ernaar vanuit /docs/security zodat teams één standaard volgen.
Als RabbitMQ niet goed werkt, zien gebruikers dat vaak eerst in je applicatie: trage endpoints, timeouts, ontbrekende updates of taken die “nooit klaar” lijken te komen. Goede observability laat je bevestigen of de broker de oorzaak is, het knelpunt (publisher, broker of consumer) aanwijzen en handelen voordat gebruikers het merken.
Begin met een klein setje signals die aangeven of berichten doorstromen.
Alert op trends, niet alleen op absolute drempels.
Brokerlogs helpen je onderscheiden of “RabbitMQ down is” of “clients het verkeerd gebruiken”. Zoek naar authenticatiefouten, geblokkeerde connecties (resource alarms) en frequente channel-errors. Aan applicatiezijde log elke verwerkingspoging met een correlation ID, queue-naam en resultaat (acked, rejected, retried).
Als je distributed tracing gebruikt, propageren trace-headers door message properties zodat je kunt verbinden: “API request → gepubliceerd bericht → consumer werk”.
Bouw één dashboard per kritische flow: publish rate, ack rate, depth, unacked, requeues en consumer count. Voeg links in het dashboard naar je interne runbook, bijvoorbeeld /docs/monitoring, en een “wat eerst te controleren”-checklist voor on-call responders.
Als iets “gewoon niet meer beweegt” in RabbitMQ, weerhoud je dan van de neiging meteen te herstarten. De meeste problemen worden duidelijk zodra je (1) bindings en routing, (2) consumergezondheid en (3) resource-alarms checkt.
Als publishers “succesvol verstuurd” rapporteren maar queues leeg blijven (of de verkeerde queue vult), controleer routing vóór je code bekijkt.
Begin in de Management UI:
topic exchanges).Als de queue berichten bevat maar niemand consumeert, controleer:
Duplicaten ontstaan meestal door retries (consumercrash na verwerking maar vóór ack), netwerkonderbrekingen of handmatige requeue. Beperk dit door handlers idempotent te maken (bijv. dedupe op message ID in de database).
Out-of-order levering is te verwachten bij meerdere consumers of requeues. Als volgorde belangrijk is, gebruik één consumer voor die queue of partitioneer op key in meerdere queues.
Alarms betekenen dat RabbitMQ zichzelf beschermt.
Voordat je gaat replayen, los de root cause op en voorkom poison-looping. Requeue in kleine batches, voeg een retrycap toe en stempel failures met metadata (aantal pogingen, laatste fout). Overweeg replay eerst naar een afzonderlijke queue, zodat je snel kunt stoppen als dezelfde fout terugkomt.
Een messaging-tool kies je minder op “beste” en meer op wat bij je trafficpatroon, fouttolerantie en operationele voorkeuren past.
RabbitMQ blinkt uit als je betrouwbare aflevering en flexibele routing tussen applicatiecomponenten nodig hebt. Het is een sterke keuze voor klassieke async-workflows — commando's, achtergrondjobs, fan-out notificaties en request/response-patronen — vooral als je wilt:
Als je toepassingen event-driven zijn maar het primaire doel is werk verplaatsen in plaats van het behouden van een lange event history, is RabbitMQ vaak een comfortabele default.
Kafka en soortgelijke platforms zijn gebouwd voor hoge throughput streaming en langdurige event logs. Kies een Kafka-achtig systeem als je nodig hebt:
Nadeel: Kafka-achtige systemen kunnen meer operationele overhead hebben en sturen je richting throughput-georiënteerde designs (batching, partitionstrategie). RabbitMQ is meestal makkelijker voor laag-tot-moderate throughput met lage end-to-end latency en complexe routing.
Als je één app hebt die jobs produceert en één workerpool die ze consumeert — en je bent tevreden met eenvoudigere semantiek — kan een Redis-gebaseerde queue (of een managed task service) volstaan. Teams groeien er meestal uit wanneer ze sterkere aflevergaranties, dead-lettering, meerdere routingpatronen of duidelijkere scheiding tussen producers en consumers nodig hebben.
Ontwerp je message contracts alsof je later zou kunnen migreren:
Als je later replaybare streams nodig hebt, kun je RabbitMQ-events vaak naar een log-based systeem bridgen en RabbitMQ blijven gebruiken voor operationele workflows. Voor een praktisch rollout-plan, zie rabbitmq-rollout-plan-and-checklist.
Een RabbitMQ-rollout werkt het beste als je het behandelt als een product: begin klein, definieer eigenaarschap en bewijs betrouwbaarheid voordat je uitbreidt.
Kies één workflow die voordeel heeft bij async-verwerking (bijv. e-mails verzenden, rapporten genereren, syncen naar een derde partij API).
Als je een referentietemplate voor naamgeving, retry-tiers en basispolicies nodig hebt, houd die gecentraliseerd in /docs.
Teams die met Koder.ai werken, genereren bijvoorbeeld vaak een klein producer/consumer-skelet vanuit een chatprompt (inclusief naamconventies, retry/DLQ-wiring en trace/correlation headers), exporteren de broncode voor review en itereren in de planningsfase vóór rollout.
RabbitMQ slaagt wanneer “iemand eigenaar is van de queue”. Beslis dit vóór productie:
Als je support of managed hosting formaliseert, stel dan verwachtingen vroeg vast (zie pricing) en definieer een contactroute voor incidenten of onboarding-hulp via contact.
Voer kleine, time-boxed oefeningen uit om vertrouwen op te bouwen:
Zodra één service een paar weken stabiel is, repliceer dezelfde patronen — verzin ze niet per team opnieuw.
Gebruik RabbitMQ wanneer je services wilt ontkoppelen, pieken wilt opvangen of traag werk van het request-pad wilt halen.
Goede cases zijn achtergrondtaken (e-mails, PDF's), event-notificaties naar meerdere consumenten en workflows die moeten blijven werken tijdens tijdelijke uitval van downstream systemen.
Vermijd het wanneer je echt een directe, onmiddellijke reactie nodig hebt (eenvoudige reads/validatie) of wanneer je je niet aan versiebeheer, retries en monitoring kunt houden — die zijn in productie niet optioneel.
Publiceer naar een exchange en routeer naar queues:
orders.* of orders.#.De meeste teams kiezen standaard voor topic exchanges voor onderhoudsvriendelijke event-achtige routing.
Een queue slaat berichten op totdat een consumer ze verwerkt; een binding is de regel die een exchange met een queue verbindt.
Om routingproblemen te debuggen:
topic exchanges).Deze drie controles verklaren de meeste gevallen van “gepubliceerd maar niet geconsumeerd”.
Gebruik een work queue wanneer je wilt dat één van meerdere workers elke taak verwerkt.
Praktische tips:
At-least-once delivery betekent dat een bericht meer dan eens bezorgd kan worden (bijvoorbeeld als een consumer crasht nadat het werk is gedaan maar vóór het ack).
Maak consumers veilig door:
message_id (of business key) te gebruiken en verwerkte ID's met een TTL op te slaan.Ga ervan uit dat duplicaten normaal zijn en ontwerp eromheen.
Vermijd strakke requeue-loops. Een veelgebruikte aanpak is “retry queues” plus een DLQ:
Replay uit de DLQ alleen nadat de oorzaak is verholpen, en verwerk in kleine batches.
Begin met voorspelbare namen en behandel berichten als publieke API's:
schema_version toe aan payloads.Standaardiseer ook metadata:
Focus op een klein aantal signalen die laten zien of werk vloeit:
Alert op trends (bijv. “backlog groeit 10 minuten”), en gebruik logs met queue-naam, correlation_id en verwerkingsresultaat (acked/retried/rejected).
Doe de basis consequent:
Houd een korte interne runbook bij zodat teams één standaard volgen (bijv. verwijzing naar /docs/security).
Begin met uit te zoeken waar de stroom stopt:
Herstarten is zelden de eerste of beste stap.
correlation_id om events/commando's aan dezelfde business-actie te koppelen.trace_id (of W3C trace headers) om async werk aan distributed traces te koppelen.Dit maakt onboarding en incidentonderzoek veel makkelijker.