10 okt 2025·8 min
Redis voor je applicaties: patronen, valkuilen en tips
Leer praktische manieren om Redis in je apps te gebruiken: caching, sessies, queues, pub/sub en rate limiting — plus schalen, persistentie, monitoring en valkuilen.
Leer praktische manieren om Redis in je apps te gebruiken: caching, sessies, queues, pub/sub en rate limiting — plus schalen, persistentie, monitoring en valkuilen.
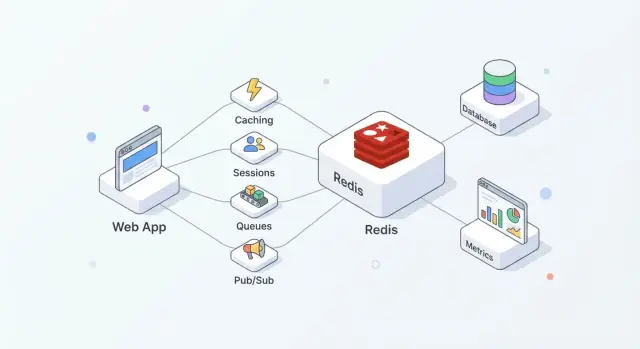
Redis is een in-memory datastore die vaak wordt gebruikt als gedeelde “snellaag” voor applicaties. Teams waarderen het omdat het eenvoudig te adopteren is, extreem snel voor veelvoorkomende operaties en flexibel genoeg om meerdere taken te vervullen (cache, sessies, tellers, queues, pub/sub) zonder voor elke taak een compleet nieuw systeem in te voeren.
In de praktijk werkt Redis het beste wanneer je het ziet als snelheid + coördinatie, terwijl je primaire database de bron van waarheid blijft.
Een veelvoorkomende opstelling ziet er zo uit:
Deze scheiding houdt je database gefocust op correctheid en duurzaamheid, terwijl Redis hoge-frequentie reads/writes absorbeert die anders voor latentie of load zouden zorgen.
Goed gebruikt levert Redis een paar praktische voordelen:
Redis vervangt geen primaire database. Als je complexe queries, langdurige opslaggaranties of analytics/reporting nodig hebt, is je database nog steeds de juiste plek.
Veronderstel ook niet dat Redis “standaard duurzaam” is. Als het onacceptabel is om zelfs maar een paar seconden data te verliezen, heb je zorgvuldige persistentie-instellingen nodig — of een ander systeem — op basis van je daadwerkelijke herstelvereisten.
Redis wordt vaak beschreven als een “key-value store”, maar het is nuttiger om het te zien als een zeer snelle server die kleine datastukken bij naam (de key) kan vasthouden en manipuleren. Dat model stimuleert voorspelbare toegangspatronen: je weet meestal precies wat je wilt (een sessie, een gecachte pagina, een teller) en Redis kan het ophalen of bijwerken in één round trip.
Redis houdt data in RAM, daarom kan het reageren in microseconden tot lage milliseconden. De wisselwerking is dat RAM beperkt en duurder is dan schijf.
Bepaal vroeg of Redis een:
Redis kan data naar schijf persistenteren (RDB-snapshots en/of AOF append-only logs), maar persistentie voegt schrijf-overhead toe en dwingt keuzes af (bijv. “snel maar kan een seconde verliezen” vs “langzamer maar veiliger”). Behandel persistentie als een knop die je instelt op basis van business-impact, niet als een vakje dat je automatisch aanvinkt.
Redis voert commando’s grotendeels single-threaded uit, wat beperkend klinkt totdat je twee zaken onthoudt: operaties zijn meestal klein en er is geen lock-overhead tussen meerdere werkers. Zolang je dure commando’s en opgeblazen payloads vermijdt, kan dit model extreem efficiënt zijn bij hoge concurrency.
Je app praat met Redis over TCP via clientbibliotheken. Gebruik connection pooling, houd requests klein en geef de voorkeur aan batching/pipelining wanneer je meerdere operaties nodig hebt.
Plan voor timeouts en retries: Redis is snel, maar netwerken niet, en je applicatie moet gracieus degraderen wanneer Redis druk of tijdelijk onbereikbaar is.
Als je een nieuwe dienst bouwt en deze basics snel wilt standaardiseren, kan een platform zoals Koder.ai je helpen een React + Go + PostgreSQL-app te scaffolden en vervolgens Redis-ondersteunde features (caching, sessies, rate limiting) toe te voegen via een chatgestuurde workflow—terwijl je nog steeds de broncode kunt exporteren en overal kunt draaien waar je dat wilt.
Caching helpt alleen wanneer het duidelijke eigenaarschap heeft: wie vult het, wie invalideert het en wat betekent “goed genoeg” versheid.
Cache-aside betekent dat je applicatie—niet Redis—reads en writes controleert.
Typische flow:
Redis is een snelle key-value store; je app bepaalt hoe te serialiseren, versioneren en expireren.
Een TTL is evenzeer een productbeslissing als een technische. Korte TTLs verminderen veroudering maar verhogen database-load; lange TTLs besparen werk maar vergroten het risico op verouderde resultaten.
Praktische tips:
user:v3:123) zodat oude cached vormen geen nieuwe code breken.Wanneer een hot key verloopt, kunnen veel requests tegelijk missen.
Gangbare verdedigingen:
Goede kandidaten zijn API-responses, dure queryresultaten, en gecomputeerde objecten (aanbevelingen, aggregaties). Volledige HTML-pagina’s cachen kan werken, maar wees voorzichtig met personalisatie en permissies—cache fragments wanneer er gebruikersspecifieke logica is.
Redis is een praktische plek voor kortdurende login-state: sessie-IDs, refresh-token metadata en “onthoud dit apparaat”-vlaggen. Het doel is authenticatie snel te maken en tegelijkertijd sessieduur en intrekking strak te beheren.
Een veelgebruikt patroon: je app geeft een willekeurige session ID uit, slaat een compact record in Redis op en retourneert de ID aan de browser als een HTTP-only cookie. Bij elk verzoek kijk je de sessiesleutel op en voeg je de identiteit en permissies aan de requestcontext toe.
Redis werkt hier goed omdat sessiereads frequent zijn en sessieverval ingebouwd is.
Ontwerp keys zodat ze makkelijk te scannen en intrekken zijn:
sess:{sessionId} → sessiepayload (userId, issuedAt, deviceId)user:sessions:{userId} → een Set van actieve session IDs (optioneel, voor “uitloggen overal”)Gebruik een TTL op sess:{sessionId} die bij je sessieduur past. Als je sessies roteert (aanbevolen), maak een nieuw session ID aan en verwijder direct de oude.
Wees voorzichtig met “sliding expiration” (TTL bij elk verzoek verlengen): het kan sessies eeuwig levend houden voor zware gebruikers. Een veiliger compromis is TTL alleen verlengen als deze bijna verlopen is.
Om één apparaat uit te loggen: verwijder sess:{sessionId}.
Om over apparaten heen uit te loggen, kun je óf:
user:sessions:{userId} verwijderen, ofuser:revoked_after:{userId} timestamp bijhouden en elke sessie die vóór dat tijdstip is uitgegeven als ongeldig behandelenDe timestamp-methode voorkomt grote fan-out deletes.
Sla minimaal benodigde gegevens in Redis op—geef de voorkeur aan ID’s boven persoonlijke data. Sla nooit ruwe wachtwoorden of langlevende geheimen op. Als je token-gerelateerde data moet bewaren, sla dan hashes op en gebruik strakke TTLs.
Beperk wie verbinding kan maken met Redis, vereist authenticatie en houd session IDs hoog-entropisch om raden te voorkomen.
Rate limiting is een area waar Redis uitblinkt: het is snel, gedeeld over je app-instances en biedt atomische operaties die tellers consistent houden bij zware traffic. Het is nuttig om login-endpoints, dure zoekopdrachten, password-reset flows en elke API die gescraped of brute-forced kan worden te beschermen.
Fixed window is het eenvoudigst: “100 requests per minuut.” Je telt requests in de huidige minutebucket. Het is makkelijk, maar kan bursts aan de grens toestaan (bijv. 100 op 12:00:59 en 100 op 12:01:00).
Sliding window maakt grenzen vloeiender door naar de laatste N seconden/minuten te kijken in plaats van de huidige bucket. Het is eerlijker, maar vaak duurder (je hebt sorted sets of extra bookkeeping nodig).
Token bucket is uitstekend voor burstafhandeling. Gebruikers “verdienen” tokens over tijd tot een limiet; elk request verbruikt een token. Dit staat korte bursts toe terwijl een gemiddelde snelheid wordt gehandhaafd.
Een veelvoorkomend fixed-window-patroon is:
INCR key om een teller te verhogenEXPIRE key window_seconds om een TTL te zetten/herstellenDe truc is het veilig doen. Als je INCR en EXPIRE als aparte calls uitvoert, kan een crash ertussen keys creëren die nooit vervallen.
Veiliger zijn onder andere:
INCR uit te voeren en EXPIRE alleen te zetten wanneer de teller voor het eerst wordt aangemaakt.SET key 1 EX <ttl> NX voor initialisatie en daarna INCR (vaak nog steeds in een script om races te vermijden).Atomische operaties zijn cruciaal bij verkeerspieken: zonder hen kunnen twee requests dezelfde resterende quota “zien” en allebei doorgaan.
De meeste apps hebben meerdere lagen nodig:
rl:user:{userId}:{route})Voor bursty endpoints helpt token bucket (of een royale fixed window plus een korte “burst” window) om legitieme spikes zoals paginaloads of mobiele reconnects geen pijn te doen.
Bepaal van tevoren wat “veilig” betekent:
Een veelgebruikte compromis is fail-open voor laag-risico routes en fail-closed voor gevoelige routes (login, password reset, OTP), met monitoring zodat je direct merkt wanneer rate limiting stopt met werken.
Redis kan achtergrondjobs aandrijven wanneer je een lichte queue nodig hebt voor het versturen van e-mails, wijzigen van afbeeldingsformaten, data-synchronisatie of periodieke taken. De sleutel is het kiezen van de juiste datastructuur en duidelijke regels voor retries en foutafhandeling.
Lists zijn de eenvoudigste queue: producers LPUSH, workers BRPOP. Ze zijn simpel, maar je hebt extra logica nodig voor “in-flight” jobs, retries en visibility timeouts.
Sorted sets zijn ideaal wanneer scheduling belangrijk is. Gebruik de score als timestamp (of prioriteit) en workers halen de volgende due job op. Dit past bij vertraagde jobs en prioriteitsqueues.
Streams zijn vaak de beste default voor duurzame werkdistributie. Ze ondersteunen consumer groups, bewaren een geschiedenis en laten meerdere workers coördineren zonder je eigen “processing list” te moeten uitvinden.
Bij Streams consumer groups leest een worker een bericht en ACKt het later. Als een worker crasht blijft het bericht pending en kan door een andere worker opgeëist worden.
Voor retries houd attempt counts bij (in het berichtpayload of een zijkey) en gebruik exponentiële backoff (vaak via een sorted set “retry schedule”). Na een maximumaantal pogingen verplaats je de job naar een dead-letter queue (een andere stream of list) voor handmatige review.
Ga ervan uit dat jobs twee keer kunnen draaien. Maak handlers idempotent door:
job:{id}:done) met SET ... NX vóór bijwerkingenHoud payloads klein (bewaar grote data elders en geef referenties). Voeg backpressure toe door queue-lengte te beperken, producers te vertragen wanneer de achterstand groeit en workers te schalen op basis van pending depth en verwerkingstijd.
Redis Pub/Sub is de eenvoudigste manier om events te broadcasten: publishers sturen een bericht naar een kanaal en elke verbonden subscriber ontvangt het meteen. Er is geen polling—alleen een lichte push die goed werkt voor realtime updates.
Pub/Sub is ideaal wanneer je snelheid en fan-out belangrijker vindt dan gegarandeerde aflevering:
Een nuttig beeld: Pub/Sub is als een radiostation. Iedereen die afgestemd is hoort de uitzending, maar niemand krijgt automatisch een opname.
Pub/Sub kent belangrijke trade-offs:
Daarom is Pub/Sub geen goede keuze voor workflows waarbij elk event zeker verwerkt moet worden.
Als je duurzaamheid, retries, consumer groups of backpressure nodig hebt, zijn Redis Streams meestal een betere keuze. Streams slaan events op, laten acknowledgements toe en herstellen na restarts—veel dichter bij een lichtgewicht message queue.
In echte deployments heb je meerdere app-instances die subscriben. Enkele praktische tips:
app:{env}:{domain}:{event} (bijv. shop:prod:orders:created).notifications:global, target gebruikers met notifications:user:{id}.Op deze manier is Pub/Sub een snel event-signaal, terwijl Streams (of een andere queue) events afhandelt die je niet kunt missen.
De keuze van een Redis-datastructuur gaat verder dan “wat werkt”—het beïnvloedt geheugenverbruik, query-snelheid en hoe eenvoudig je code op termijn blijft. Een goede regel is te kiezen voor de structuur die past bij de vragen die je later gaat stellen (leespatronen), niet alleen hoe je data nu opslaat.
INCR/DECR.SISMEMBER en makkelijke set-operaties.Redis-operaties zijn op commandoniveau atomair, dus je kunt tellers veilig incrementen zonder race-condities. Pageviews en rate-limit tellers gebruiken doorgaans strings met INCR plus expiry.
Leaderboards zijn waar sorted sets uitblinken: je kunt scores bijwerken (ZINCRBY) en de top spelers ophalen (ZREVRANGE) efficiënt, zonder alle entries te scannen.
Als je veel keys aanmaakt zoals user:123:name, user:123:email, user:123:plan verhoog je metadata-overhead en maak je keybeheer moeilijker.
Een hash zoals user:123 met velden (name, email, plan) houdt gerelateerde data samen en vermindert doorgaans het aantal keys. Het maakt partiële updates ook eenvoudiger (update één veld in plaats van een hele JSON-string).
In twijfelgevallen modelleer een kleine steekproef en meet geheugenverbruik voordat je een structuur kiest voor high-volume data.
Redis wordt vaak “in-memory” genoemd, maar je hebt keuzes voor wat er gebeurt bij een node-restart, volle schijf of serveruitval. De juiste setup hangt af van hoeveel data je kunt verliezen en hoe snel je moet herstellen.
RDB snapshots slaan een point-in-time dump van je dataset op. Ze zijn compact en snel te laden bij opstart, wat restarts kan versnellen. Het nadeel is dat je de recentste schrijfbewerkingen sinds de laatste snapshot kunt verliezen.
AOF (append-only file) logt schrijfoperaties terwijl ze gebeuren. Dit vermindert doorgaans potentieel dataverlies omdat wijzigingen continu worden vastgelegd. AOF-bestanden kunnen groter worden en replays bij opstart langer duren—hoewel Redis AOF kan herschrijven/compacten om het beheersbaar te houden.
Veel teams draaien beide: snapshots voor snellere restarts en AOF voor betere schrijfduurzaamheid.
Persistentie kost iets: schijfwrites, AOF fsync-beleid en achtergrond-herschrijfoperaties kunnen latentiespikes veroorzaken als je opslag traag of verzadigd is. Aan de andere kant maakt persistentie restarts minder eng: zonder persistentie betekent een ongeplande restart een lege Redis.
Replicatie houdt een kopie (of meerdere) van data op replicas zodat je kunt failoveren als de primary uitvalt. Het doel is meestal beschikbaarheid eerst, niet perfecte consistentie. Bij falen kunnen replicas iets achterlopen en kan een failover de laatste erkende schrijfbewerkingen verliezen in sommige scenario’s.
Voordat je iets tunet, schrijf twee getallen op:
Gebruik die doelen om RDB-frequentie, AOF-instellingen en of je replicas/automatische failover nodig hebt te kiezen, afhankelijk van de rol van je Redis—cache, session store, queue of primaire datastore.
Een enkele Redis-node kan je verrassend ver ver brengen: het is eenvoudig te beheren, makkelijk te begrijpen en vaak snel genoeg voor veel caching-, sessie- of queue-workloads.
Schaalbaarheid wordt noodzakelijk als je harde limieten bereikt—gewoonlijk geheugenplafond, CPU-saturatie of een enkele node die een onacceptabel single point of failure wordt.
Overweeg meer nodes wanneer één (of meer) van deze waar is:
Een praktische eerste stap is vaak het scheiden van workloads (twee onafhankelijke Redis-instanties) voordat je in een cluster duikt.
Sharding betekent je keys over meerdere Redis-nodes splitsen zodat elke node slechts een deel van de data opslaat. Redis Cluster is Redis’ ingebouwde manier om dit automatisch te doen: de keyspace wordt verdeeld in slots en elke node bezit een subset van die slots.
De winst is meer totaal geheugen en hogere doorvoer. De trade-off is extra complexiteit: multi-key operaties worden beperkt (keys moeten op dezelfde shard liggen) en troubleshooting omvat meer onderdelen.
Zelfs met ‘gelijke’ sharding kan echt verkeer scheef lopen. Een populaire key (een “hot key”) kan één node overbelasten terwijl anderen idle zijn.
Mitigaties zijn korte TTLs met jitter, het splitsen van de waarde over meerdere keys (key hashing) of het herontwerpen van toegangs- en leespatronen zodat reads verspreid raken.
Een Redis Cluster vereist een cluster-aware client die topologie kan ontdekken, requests naar de juiste node kan routeren en redirecties volgt wanneer slots verhuizen.
Controleer vóór migratie:
Schaalbaarheid werkt het beste als geplande evolutie: valideer met loadtests, instrumenteer key-latency en migreer verkeer geleidelijk in plaats van alles in één keer om te zetten.
Redis wordt vaak als “interne infrastructuur” behandeld, en precies daarom is het een veelvoorkomend doelwit: één blootgesteld poort kan leiden tot een volledige datalek of een door een aanvaller gecontroleerde cache. Ga ervan uit dat Redis gevoelige infrastructuur is, ook als je alleen “tijdelijke” data opslaat.
Begin met authenticatie inschakelen en gebruik ACLs (Redis 6+). ACLs laten je:
Vermijd het delen van één wachtwoord over alle componenten. Geef per-service credentials en houd permissies smal.
De meest effectieve controle is niet bereikbaar zijn. Bind Redis aan een privé-interface, plaats het op een privénetwerk en beperk inbound verkeer met security groups/firewalls tot alleen de services die het nodig hebben.
Gebruik TLS wanneer Redis-verkeer hostgrenzen overschrijdt die je niet volledig controleert (multi-AZ, gedeelde netwerken, Kubernetes-nodes of hybride omgevingen). TLS voorkomt sniffing en credential-diefstal en is de overhead waard voor sessies, tokens of andere gebruikersgerelateerde data.
Beperk commando’s die grote schade kunnen aanrichten als ze misbruikt worden. Veelvoorkomende voorbeelden om te disable-en of via ACLs te beperken: FLUSHALL, FLUSHDB, CONFIG, SAVE, DEBUG, en EVAL (of beperk scripting zorgvuldig).
Bescherm het rename-command-patroon met zorg—ACLs zijn meestal duidelijker en makkelijker te auditen.
Bewaar Redis-credentials in je secrets manager (niet in code of container-images) en plan voor rotatie. Rotatie is het makkelijkst wanneer clients credentials kunnen herladen zonder een redeploy, of wanneer je twee geldige credentials toestaat tijdens een overgangsperiode.
Als je een praktische checklist wilt, houd die bij in je runbooks naast je /blog/monitoring-troubleshooting-redis aantekeningen.
Redis voelt vaak “prima”… totdat verkeer verandert, geheugen kruipt of een langzaam commando alles blokkeert. Een lichte monitoringroutine en een duidelijk incident-checklist voorkomen de meeste verrassingen.
Begin met een kleine set die je aan iedereen in het team kunt uitleggen:
Als iets “traag” is, bevestig het met Redis’ eigen tools:
KEYS, SMEMBERS of grote LRANGE-calls is een veelvoorkomend alarm.Als latentie stijgt terwijl CPU normaal is, overweeg netwerkverzadiging, opgeblazen payloads of geblokkeerde clients.
Plan voor groei door headroom te houden (meestal 20–30% vrij geheugen) en herzie aannames na lanceringen of feature flags. Behandel “aanhoudende evictions” als een incident, niet als waarschuwing.
Tijdens een incident controleer (in volgorde): geheugen/evictions, latentie, clientconnecties, slowlog, replicatie-lag en recente deploys. Schrijf de meest voorkomende oorzaken neer en los ze structureel op—alerts alleen volstaan niet.
Als je team snel iterereert, helpt het om deze operationele verwachtingen in je ontwikkelworkflow te verankeren. Bijvoorbeeld: met Koder.ai’s planning mode en snapshots/rollback kun je Redis-ondersteunde features (caching, rate limiting) prototypen, onder load testen en veilig terugdraaien—terwijl je implementatie in je codebase blijft via broncode-export.
Redis is het beste als gedeelde, in-memory “snellaag” voor:
Gebruik je primaire database voor duurzame, gezaghebbende data en complexe queries. Zie Redis als een versneller en coördinator, niet als je bron van waarheid.
Nee. Redis kan persistentie bieden, maar het is niet “standaard duurzaam”. Als je complexe queries, sterke duurzaamheidsgaranties of analytics/reporting nodig hebt, houd die data dan in je primaire database.
Als het onacceptabel is om zelfs maar een paar seconden aan data te verliezen, ga er dan niet van uit dat Redis-persistentie zonder zorg voldoet — configureer het zorgvuldig of overweeg een ander systeem voor die workload.
Kies op basis van hoeveel dataverlies en hersteltijd je accepteert:
Schrijf eerst je RPO/RTO-doelen op en stem daarna je persistentie-instellingen af.
In cache-aside beheert je app de logica:
Dit werkt goed wanneer je app af en toe misses kan verdragen en je een duidelijk plan hebt voor vervallen/invalideren.
Kies TTLs op basis van gebruikersimpact en backend-load:
user:v3:123) als de gecachte vorm kan veranderen.Als je twijfelt: begin met kortere TTLs, meet database-load en pas aan.
Gebruik een of meer van deze technieken:
Deze patronen voorkomen gesynchroniseerde cache-misses die je database overbelasten.
Een gangbare aanpak is:
sess:{sessionId} met een TTL die overeenkomt met de sessieduur.user:sessions:{userId} als een Set van actieve sessie-IDs voor “uitloggen op alle apparaten”.Vermijd het verlengen van de TTL bij elk verzoek (“sliding expiration”) tenzij je het gecontroleerd doet (bv. alleen verlengen als de TTL bijna verlopen is).
Gebruik atomische updates zodat counters niet kunnen vastlopen of race-condities krijgen:
INCR en EXPIRE niet als twee losse, onbeschermde aanroepen uit.Schaal keys zorgvuldig (per-gebruiker, per-IP, per-route) en bepaal vooraf of je fail-open of fail-closed wilt zijn als Redis niet beschikbaar is — vooral bij gevoelige endpoints zoals login.
Kies op basis van duurzaamheid en operationele behoeften:
LPUSH/BRPOP): eenvoudig, maar je moet retries, in-flight tracking en timeouts zelf bouwen.Gebruik Pub/Sub voor snelle realtime broadcasts waarbij gemiste berichten acceptabel zijn (presence, live dashboards). Kenmerken:
Als elk event verwerkt moet worden, gebruik dan Redis Streams voor duurzaamheid, consumer groups, retries en backpressure. Voor operationele hygiëne: beveilig Redis met ACLs/netwerkisolatie en houd latency/evictions bij; bewaak met een runbook zoals /blog/monitoring-troubleshooting-redis.
Houd payloads klein; bewaar grote blobs elders en geef verwijzingen door.