Doel helder krijgen en voor wie de app is
Voordat je functies of een tech stack kiest, stem af wat een “runbook” in jouw organisatie betekent. Sommige teams gebruiken runbooks voor incident response playbooks (hoge druk, tijdkritisch). Anderen bedoelen standaard operationele procedures (herhaalbare taken), gepland onderhoud of klantondersteuningsworkflows. Als je de scope niet van tevoren definieert, probeert de app elk documenttype te bedienen—en doet uiteindelijk geen van allen het goed.
Definieer je runbook-types (en wat “goed” is)
Schrijf de categorieën op die je verwacht in de app, met een kort voorbeeld per categorie:
- Incident playbooks: stappen voor “API latency spike”, escalatiepaden, rollback-instructies
- SOP’s: “Een nieuwe klant provisionen,” “Wachtwoorden draaien,” “Wekelijkse capacity-check”
- Onderhoudstaken: “Database patchen,” “Certificaat vernieuwen”
Definieer ook minimale standaarden: verplichte velden (eigenaar, getroffen services, laatst beoordeeld), wat “klaar” betekent (elke stap afgevinkt, notities vastgelegd) en wat vermeden moet worden (lange proza die lastig te scannen is).
Identificeer doelgebruikers en hun beperkingen
Maak een lijst van de primaire gebruikers en wat zij in het moment nodig hebben:
- On-call engineers: snelheid, duidelijkheid, weinig frictie tijdens multitasken
- Operations/support: consistente processen, minder overdrachten, duidelijke definities
- Managers/leads: zicht op coverage, review-cadans en eigenaarschap
Verschillende gebruikers optimaliseren voor verschillende dingen. Ontwerpen voor de on-call case dwingt vaak de interface eenvoudig en voorspelbaar te houden.
Stel uitkomsten en meetbare succesmetingen vast
Kies 2–4 kernuitkomsten, zoals snellere respons, consistente uitvoering en eenvoudigere reviews. Koppel daar meetbare metrics aan die je kunt volgen:
- Tijd om het juiste runbook te vinden (search-to-open)
- Voltooiingspercentage voor terugkerende taken
- Incident time-to-mitigation wanneer een playbook beschikbaar is vs. niet
- Review-cadans: % runbooks beoordeeld in de laatste 90 dagen
Deze beslissingen moeten elke later keuze sturen, van navigatie tot permissies.
Vereisten vastleggen vanuit echte operationele workflows
Voordat je een tech stack kiest of schermen schetst, kijk hoe operations daadwerkelijk werken als er iets stukgaat. Een runbook-beheer webapp slaagt als het aansluit op echte gewoontes: waar mensen naar zoeken, wat “goed genoeg” betekent tijdens een incident en wat wordt genegeerd als iedereen overbelast is.
Begin bij de pijn die je oplost
Interview on-call engineers, SRE’s, support en service-eigenaren. Vraag naar specifieke recente voorbeelden, geen algemene meningen. Veelvoorkomende pijnpunten zijn verspreide docs over meerdere tools, verouderde stappen die niet met productie overeenkomen en onduidelijk eigenaarschap (niemand weet wie een runbook moet bijwerken na een wijziging).
Leg elk pijnpunt vast met een kort verhaal: wat gebeurde, wat probeerde het team, wat ging er mis en wat had geholpen. Deze verhalen worden later acceptatiecriteria.
Inventariseer bestaande bronnen en importbehoeften
Maak een lijst waar runbooks en SOP’s vandaag leven: wiki’s, Google Docs, Markdown-repo’s, PDF’s, ticketcomments en incidentpostmortems. Noteer voor elke bron:
- Formaat en structuur (tabellen, checklists, screenshots, links)
- Volume en welke geschiedenis “moet blijven”
- Vereiste metadata (service, omgeving, severity, eigenaar)
Dit vertelt je of je een bulk-importer nodig hebt, een eenvoudige copy/paste-migratie of beide.
Breng de end-to-end runbook-flow in kaart
Omschrijf de typische lifecycle: create → review → use → update. Let op wie bij elke stap betrokken is, waar goedkeuringen plaatsvinden en wat updates triggert (servicewijzigingen, incidentlearnings, kwartaalreviews).
Identificeer compliance- en auditverwachtingen
Zelfs zonder gereguleerde industrie willen teams vaak antwoord op “wie heeft wat veranderd, wanneer en waarom.” Definieer minimale audittrail-eisen vroeg: wijzigingssamenvattingen, identiteit van goedkeurder, tijdstempels en de mogelijkheid om versies te vergelijken tijdens incidentresponse-executies.
Ontwerp het datamodel voor runbooks en versies
Een runbook-app slaagt of faalt op basis van hoe goed het datamodel past bij hoe operationele teams werken: veel runbooks, gedeelde bouwblokken, frequente edits en veel vertrouwen in “wat waar was op dat moment.” Begin met het definiëren van kernobjecten en hun relaties.
Kernobjecten
Modelleer minimaal:
- Runbook: titel, samenvatting, status (draft/published/archived), severity/use-case flags, last_reviewed_at.
- Step: geordende items binnen een runbook (met optionele beslissingsvertakkingen).
- Tag: lichte labels voor zoeken en filteren.
- Service: waar het runbook betrekking op heeft (payments, API, datapipe).
- Owner: persoon/team verantwoordelijk voor juistheid.
- Version: onveranderlijke snapshot van een runbook op een bepaald moment.
- Execution: een vastgelegde “run” van een runbook tijdens een incident of routine taak.
Relaties die operations weerspiegelen
Runbooks leven zelden op zichzelf. Plan links zodat de app het juiste document onder druk kan tonen:
- Runbook ↔ Service (many-to-many): een service kan meerdere runbooks hebben; een runbook kan meerdere services bestrijken.
- Runbook ↔ Incident type / alert rule: bewaar verwijzingen naar alert-identifiers of incidentcategorieën zodat integraties het juiste playbook kunnen voorstellen.
- Runbook ↔ Tags: voor cross-cutting concerns (database, customer-impacting, rollback).
Versiebeheer: concept vs. gepubliceerd
Behandel versies als append-only records. Een Runbook verwijst naar een current_draft_version_id en een current_published_version_id.
- Bewerken maakt nieuwe draft-versies aan.
- Publiceren “promoot” een draft tot published (en maakt daarmee een nieuwe onveranderlijke published-versie).
- Bewaar oude versies voor audit en postmortems; overweeg een retentiebeleid alleen voor drafts, niet voor gepubliceerde versies.
Opslaan van rijke inhoud en bijlagen
Voor stappen bewaar je inhoud als Markdown (simpel) of als gestructureerde JSON-blocks (beter voor checklists, callouts en templates). Houd bijlagen buiten de database: bewaar metadata (bestandnaam, grootte, content_type, storage_key) en zet bestanden in object storage.
Deze structuur bereidt je voor op betrouwbare audittrails en een soepele executie-ervaring later.
Plan de feature-set en gebruikersreizen
Een runbook-app werkt het beste als die voorspelbaar blijft onder druk. Begin met het definiëren van een minimum viable product (MVP) dat de kernlus ondersteunt: een runbook schrijven, publiceren en betrouwbaar gebruiken tijdens werk.
MVP: het minimale om nuttig te zijn
Houd de eerste release compact:
- List / library: blader runbooks op service, team en tag.
- View: een schone read-only pagina die snel laadt en goed print.
- Create: begin vanaf nul met titel, samenvatting en geordende stappen.
- Edit: maak draft-wijzigingen zonder de gepubliceerde versie te beïnvloeden.
- Publish: een duidelijke actie die een versie “officieel” maakt.
- Search: full-text search over titels, samenvattingen en staptekst.
Als je deze zes dingen niet snel kunt leveren, zullen extra functies niet veel uitmaken.
“Nice to have” later (blokkeer de eerste release niet)
Als de basis stabiel is, voeg dan mogelijkheden toe die controle en inzicht verbeteren:
- Templates voor veelvoorkomende incidenttypes en terugkerend onderhoud.
- Approvals en reviewers voor high-risk systemen.
- Executions (checklists) om vast te leggen wat er is gedaan en wanneer.
- Analytics zoals meestgebruikte runbooks, verouderde content en zoekopdrachten zonder resultaten.
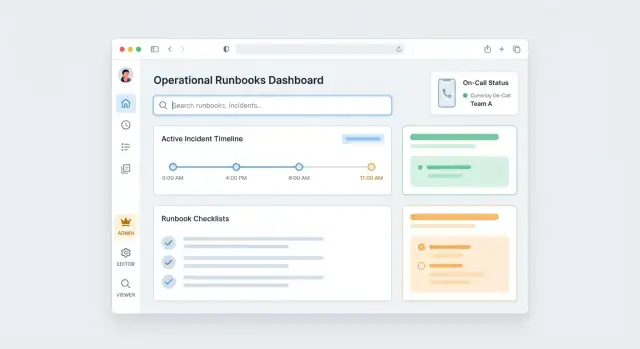
Layout: drie primaire werkruimtes
Maak de UI-indeling zoals operators denken:
- Runbook Library: snel vinden en filteren.
- Editor: concepten schrijven, herzien en de gepubliceerde weergave previewen.
- Execution View: een gefocuste “do the steps”-modus met voortgangsregistratie.
Een simpele paginamap (voorspelbare navigatie)
- /runbooks (library)
- /runbooks/new
- /runbooks/:id (published view)
- /runbooks/:id/edit (draft editor)
- /runbooks/:id/versions
- /runbooks/:id/execute (execution mode)
- /search
Ontwerp gebruikersreizen rond rollen: een auteur die maakt en publiceert, een responder die zoekt en uitvoert, en een manager die controleert wat actueel of verouderd is.
Bouw een runbook-editor die stappen helder en herhaalbaar houdt
Een runbook-editor moet het “juiste” manier om procedures te schrijven het gemakkelijkst maken. Als mensen snel schone, consistente stappen kunnen maken, blijven runbooks bruikbaar als stress hoog is en tijd schaars.
Kies een editorstijl die bij je gebruikers past
Er zijn drie veelvoorkomende benaderingen:
- Markdown editor: snel voor ervaren operators, goed voor keyboard-first workflows, maar makkelijker om inconsistent te worden.
- Block editor: gestructureerde inhoud (stappen, callouts, links) met goede leesbaarheid; meestal de beste balans voor gemengde teams.
- Form-based steps: elke stap is een formulier met specifieke velden (actie, verwacht resultaat, eigenaar, links). Dit levert de meest consistente output en is ideaal bij strikte herhaalbaarheid.
Veel teams beginnen met een block editor en voegen formulierachtige beperkingen toe voor kritieke staptypes.
Modelleer stappen als eersteklas objecten
In plaats van één lang document, sla een runbook op als een geordende lijst van stappen met types zoals:
- Text (context)
- Command (met copy-knop en optioneel “expected output”)
- Link (naar dashboards, tickets, docs)
- Decision (if/then-vertakkingen)
- Checklist (meerdere subitems)
- Caution note (hoogzichtbare waarschuwingen)
Getypeerde stappen maken consistente rendering, zoeken, veiliger hergebruik en betere executie-UX mogelijk.
Voeg guardrails toe die “mystery steps” voorkomen
Guardrails houden content leesbaar en uitvoerbaar:
- Verplichte velden (bijv. elk command-step vereist een commando en omgeving)
- Validatie (gebroken links, lege placeholders, ontbrekende prerequisites)
- Preview die execution mode nabootst zodat auteurs zien wat responders zien
- Formatteringsregels (beperk headings, standaardiseer namen zoals “Verify…”, “Rollback…”, “Escalate…”)
Maak hergebruik moeiteloos
Ondersteun templates voor veelvoorkomende patronen (triage, rollback, post-incident checks) en een Duplicate runbook-actie die structuur kopieert maar gebruikers vraagt kernvelden bij te werken (servicenaam, on-call kanaal, dashboards). Hergebruik vermindert variatie—en variatie is waar fouten zich verbergen.
Voeg goedkeuringen, eigenaarschap en reviewherinneringen toe
Use a Custom Domain
Put your runbook library on a custom domain your team can remember under pressure.
Operational runbooks zijn alleen nuttig als mensen ze vertrouwen. Een lichte governance-laag—duidelijke eigenaren, een voorspelbaar goedkeuringspad en terugkerende reviews—houdt content accuraat zonder van elke wijziging een bottleneck te maken.
Ontwerp een simpele reviewflow
Begin met een kleine set statussen die bij teams passen:
- Draft: wordt geschreven of bijgewerkt
- In review: wacht op feedback van specifieke reviewers
- Approved: klaar, maar niet per se direct zichtbaar voor iedereen (optionele buffer)
- Published: de versie die wordt gebruikt tijdens incidenten en routinematig werk
Maak transities expliciet in de UI (bijv. “Request review”, “Approve & publish”), en leg vast wie welke actie wanneer uitvoerde.
Voeg eigenaarschap en review-datums toe
Elk runbook zou ten minste moeten hebben:
- Primary owner: verantwoordelijk voor juistheid
- Backup owner: dekking voor vakanties en rotaties
- Review due date (of “review every X days”): zodat runbooks niet stilletjes verouderen
Behandel ownership als een operationeel on-call concept: eigenaren veranderen als teams veranderen en die wijzigingen moeten zichtbaar zijn.
Vereis wijzigingssamenvattingen voor edits
Als iemand een gepubliceerd runbook bijwerkt, vraag om een korte change summary en (waar relevant) een verplichte opmerking zoals “Waarom wijzigen we deze stap?” Dit creëert gedeelde context voor reviewers en vermindert heen-en-weer tijdens goedkeuring.
Plan notificaties zonder vast te zitten aan één provider
Runbook-reviews werken alleen als mensen een seintje krijgen. Stuur herinneringen voor “review requested” en “review due soon”, maar hard-codeer niet alleen e-mail of Slack. Definieer een eenvoudige notificatie-interface (events + ontvangers) en plug later providers in—Slack vandaag, Teams morgen—zonder kernlogica te herschrijven.
Beheer authenticatie en permissies veilig
Operationele runbooks bevatten vaak precies de informatie die je niet breed gedeeld wilt zien: interne URL’s, escalatiecontacten, herstelcommando’s en soms gevoelige configuratiedetails. Behandel authenticatie en autorisatie als een kernfunctie, niet als een latere hardeningtaak.
Begin met eenvoudige RBAC
Implementeer minimaal rolgebaseerde toegang met drie rollen:
- Viewer: kan runbooks lezen en execution mode gebruiken.
- Editor: kan runbooks aanmaken en bijwerken waarvoor ze toegang hebben.
- Admin: kan permissies, teams/services en globale instellingen beheren.
Houd deze rollen consistent in de UI (knoppen, editor-toegang, goedkeuringen) zodat gebruikers niet hoeven te raden wat ze kunnen doen.
Scope toegang op team of service (en optioneel per runbook)
De meeste organisaties organiseren operations per team of service, en permissies moeten die structuur volgen. Een praktische benadering is:
- Gebruikers behoren tot één of meer teams.
- Runbooks zijn gelabeld met een service (eigendom van een team).
- Permissies worden toegekend op team/service-niveau.
Voor hoog-risico-inhoud voeg een optionele runbook-level override toe (bijv. “alleen Database SREs kunnen dit runbook bewerken”). Dit houdt het systeem beheersbaar en ondersteunt uitzonderingen.
Bescherm gevoelige stappen
Sommige stappen moeten alleen zichtbaar zijn voor een kleinere groep. Ondersteun beperkte secties zoals “Sensitive details” die verhoogde permissie vereisen om te bekijken. Geef bij voorkeur redactie (“hidden to viewers”) in plaats van verwijderen zodat het runbook onder druk coherent blijft.
Houd authenticatie flexibel
Ook al begin je met e-mail/wachtwoord, ontwerp de auth-laag zodat je later SSO kunt toevoegen (OAuth, SAML). Gebruik een plug-in aanpak voor identity providers en bewaar stabiele gebruikersidentifiers zodat overstappen naar SSO ownership, goedkeuringen en audittrails niet breekt.
Maak runbooks makkelijk vindbaar onder druk
Plan the Core Workflow
Use planning mode to map runbooks, versions, RBAC, and audits before implementation.
Als er iets stuk is, wil niemand documentatie doorploegen. Ze willen binnen enkele seconden het juiste runbook, zelfs als ze zich slechts een vaag woord uit een alert herinneren. Vindbaarheid is een productfunctie, geen luxe.
Bouw zoekfunctie die werkt als het on-call brein
Implementeer één zoekvak dat meer doorzoekt dan alleen titels. Indexeer titels, tags, eigenaar service en stapinhoud (inclusief commando’s, URL’s en foutstrings). Mensen plakken vaak een logsnippet of alerttekst—stap-niveau zoeken zorgt dat dat een match wordt.
Ondersteun tolerante matching: gedeeltelijke woorden, typefouten en prefix-queries. Geef resultaten terug met gemarkeerde snippets zodat gebruikers kunnen bevestigen dat ze het juiste proces hebben zonder vijf tabbladen te openen.
Voeg filters toe die snel ruis wegnemen
Zoeken is het snelst als gebruikers de context kunnen beperken. Bied filters die overeenkomen met hoe ops teams denken:
- Service (of systeem/component)
- Severity (SEV-levels, prioriteit)
- Omgeving (prod/stage/dev, regio)
- Team/eigenaar
- Laatst beoordeeld datum (of “review overdue”)
Maak filters sticky voor on-call gebruikers en toon actieve filters duidelijk zodat het helder is waarom resultaten ontbreken.
Leer het systeem synoniemen en incidenttaal
Teams gebruiken niet één vocabulaire. “DB”, “database”, “postgres”, “RDS” en een interne bijnaam kunnen hetzelfde betekenen. Voeg een lichte synonymendictionary toe die je kunt bijwerken zonder te deployen (admin-UI of config). Gebruik het tijdens query-tijd (vergroot zoektermen) en eventueel tijdens indexering.
Leg ook veelvoorkomende termen vast uit incidenttitels en alertlabels zodat synoniemen aansluiten op de realiteit.
Ontwerp een runbook-weergave om te scannen, niet te lezen
De runbook-pagina moet informatie-dicht en scanbaar zijn: een duidelijke samenvatting, prerequisites en een inhoudsopgave voor stappen. Toon belangrijke metadata bovenaan (service, toepasselijke omgeving, laatst beoordeeld, eigenaar) en houd stappen kort, genummerd en inklapbaar.
Voeg een “kopieer”-knop toe voor commando’s en URL’s, en een compact “related runbooks”-gebied om naar veelvoorkomende vervolgstappen te springen (bijv. rollback, verificatie, escalatie).
Implementeer execution mode voor incidenten en routine taken
Execution mode is waar runbooks stoppen met “documentatie” en een tool worden waarop mensen onder tijdsdruk kunnen vertrouwen. Behandel het als een gefocuste, afleidingsvrije weergave die iemand van eerste tot laatste stap begeleidt en vastlegt wat er daadwerkelijk gebeurde.
Een gefocuste UI: stappen, status en tijd
Elke stap moet een duidelijke status en eenvoudige bediening hebben:
- Een checkbox of Mark complete-knop (plus Skip waar passend)
- Stapstatussen zoals Not started / In progress / Blocked / Done
- Optionele timers: een run-level timer (sinds start) en stap-level timers (besteede tijd)
Kleine details helpen: pin de huidige stap, toon “next up” en houd lange stappen leesbaar met inklapbare details.
Notities, links en bewijs—vastgelegd in het moment
Tijdens execution moeten operators context toevoegen zonder de pagina te verlaten. Sta per stap toe:
- Vrije notities (wat je zag, wat je probeerde, waarom je een pad koos)
- Links naar dashboards, tickets of chatgesprekken
- Bewijsbijlagen (screenshots, logs, commando-output)
Maak deze toevoegingen automatisch met tijdstempel en bewaar ze ook als de run gepauzeerd en hervat wordt.
Vertakkingen en escalatiepaden
Echte procedures zijn niet altijd lineair. Ondersteun “if/then” vertakkingen zodat een runbook zich aan omstandigheden kan aanpassen (bijv. “If error rate > 5%, then…”). Voeg ook expliciete Stop and escalate-acties toe die:
- De run als geëscaleerd/geblokkeerd markeren
- Vragen wie is gecontacteerd en waarom
- Optioneel een overdrachtsamenvatting genereren voor de volgende responder
Bewaar execution-geschiedenis voor leren
Elke run moet een onveranderlijk execution-record maken: gebruikte runbookversie, tijdstempels per stap, notities, bewijs en eindresultaat. Dit wordt de bron van waarheid voor post-incident reviews en voor het verbeteren van het runbook zonder op geheugen te vertrouwen.
Voeg audittrails en wijzigingsgeschiedenis toe waarop je kunt vertrouwen
Als een runbook verandert, is de vraag tijdens een incident niet “wat is de laatste versie?” maar “kunnen we het vertrouwen en hoe is het zo gekomen?” Een duidelijke audittrail verandert runbooks van bewerkbare notities in betrouwbare operationele documenten.
Wat te loggen (en waarom het telt)
Log minimaal elke zinvolle wijziging met wie, wat en wanneer. Ga een stap verder en bewaar before/after snapshots van de inhoud (of een gestructureerde diff) zodat reviewers precies kunnen zien wat is veranderd zonder te gokken.
Leg ook andere gebeurtenissen vast:
- Publiceren: draft → published, published → archived, rollbacks
- Goedkeuringsbeslissingen: wie goedkeurde/afkeurde, tijdstempel, optionele comment
- Ownership-wijzigingen: herbeoordeling van eigenaar of team
Dit creëert een tijdlijn waarop je kunt vertrouwen tijdens post-incident reviews en compliance-checks.
Audit-weergaven die onder druk werken
Geef gebruikers een Audit-tab per runbook met een chronologische stroom van veranderingen met filters (editor, datumbereik, gebeurtenistype). Voeg “view this version” en “compare to current” acties toe zodat responders snel kunnen bevestigen dat ze de juiste procedure volgen.
Als je organisatie dit nodig heeft, voeg exportopties toe zoals CSV/JSON voor audits. Houd exports permissie-gebonden en gescopeerd (enkel runbook of tijdvenster), en overweeg te verwijzen naar een interne admin-pagina zoals /settings/audit-exports.
Retentieregels en tamper-resistance
Definieer retentieregels die bij je eisen passen: bijvoorbeeld, bewaar volledige snapshots 90 dagen, bewaar daarna diffs en metadata 1–7 jaar. Sla auditrecords append-only op, beperk verwijdering en leg administratieve overrides ook als auditeerbare gebeurtenissen vast.
Build Execution Mode
Create a focused checklist view that tracks steps, notes, and outcomes per run.
Je runbooks worden veel nuttiger als ze één klik verwijderd zijn van de alert die het werk triggerde. Integraties verminderen contextswitching tijdens incidenten wanneer mensen gestrest zijn en tijd schaars.
Begin met een simpel integratiecontract (webhooks + APIs)
De meeste teams dekken 80% met twee patronen:
- Incoming webhooks van alerting/incidenttools naar je app (maak of update een “incident context”, stel runbooks voor).
- Outgoing webhooks of API-calls van je app terug naar die tools (post de gekozen runbook-tekst, statusupdates en sleutelbeslissingen).
Een minimale inkomende payload kan zo klein zijn als:
{
"service": "payments-api",
"event_type": "5xx_rate_high",
"severity": "critical",
"incident_id": "INC-1842",
"source_url": "https://…"
}
(Het codeblok blijft ongewijzigd.)
Deep links: breng responders meteen naar het juiste runbook
Ontwerp je URL-schema zodat een alert direct naar de beste match kan wijzen, meestal op service + event type (of tags zoals database, latency, deploy). Bijvoorbeeld:
- Link naar een specifiek runbook:
/runbooks/123
- Link naar execution view met context:
/runbooks/123/execute?incident=INC-1842
- Link naar een zoekpreset:
/runbooks?service=payments-api&event=5xx_rate_high
Dit maakt het eenvoudig voor alerting-systemen om de URL in notificaties op te nemen en voor mensen om meteen op de juiste checklist te landen zonder extra zoeken.
Chatnotificaties en delen tijdens een incident
Koppel met Slack of Microsoft Teams zodat responders kunnen:
- De geselecteerde runbook-link in het incidentkanaal posten
- Een korte samenvatting delen (“Wat we volgen, wie het bezit, huidige stap”)
- Het runbook zichtbaar houden terwijl beslissingen worden genomen
Als je al documentatie hebt voor integraties, vermeld dat in je UI (bijv. /docs/integrations) en toon configuratie waar ops teams het verwachten (een instellingenpagina en een snelle testknop).
Deploy, secure en iteratief verbeteren zonder de operatie te vertragen
Een runbook-systeem is onderdeel van je operationele veiligheidsnet. Behandel het als elke andere productiedienst: deploy voorspelbaar, bescherm het tegen veelvoorkomende fouten en verbeter in kleine, laag-risico stappen.
Hosting, backups en disaster recovery
Begin met een hostingmodel dat je ops-team kan ondersteunen (managed platform, Kubernetes of een eenvoudige VM-setup). Wat je ook kiest, documenteer het in zijn eigen runbook.
Backups moeten automatisch en getest zijn. Het is niet genoeg om “snapshots te maken”—je moet erop vertrouwen dat je kunt herstellen:
- Databasebackups volgens schema (en voor grote upgrades)
- Versleutelde backups met beperkte toegang
- Routine restore-tests (bijv. maandelijks) naar een aparte omgeving
Voor disaster recovery bepaal je targets vooraf: hoeveel data je kunt verliezen (RPO) en hoe snel de app terug moet (RTO). Houd een lichtgewicht DR-checklist met DNS, secrets en een geverifieerde restore-procedure.
Runbooks zijn het meest waardevol onder druk, dus streef naar snelle paginalaadtijden en voorspelbaar gedrag:
- Caching voor read-heavy endpoints (runbook-lijsten, templates)
- Paginatie en filtering voor zoekresultaten en auditweergaven
- Rate limiting op authenticatie en schrijfacties om misbruik en accidentele overload te verminderen
Log ook traagheid vroeg; dat is makkelijker dan later gokken.
Teststrategie die vertrouwen beschermt
Focus tests op features die, als ze stuk zijn, risicovol gedrag veroorzaken:
- Permissies (RBAC, ownership, approvals)
- Editor-gedrag (stapvolgorde, templates, validaties)
- Versiebeheer (diffs, publish-flow, rollback)
Voeg een kleine set end-to-end tests toe voor “publiceer een runbook” en “executeer een runbook” om integratieproblemen te vangen.
Ship iteratief, niet alles tegelijk
Pilot met één team—idealiter het team met veel on-call werk. Verzamel feedback in de tool (korte comments) en in wekelijkse reviews. Breid geleidelijk uit: voeg het volgende team toe, migreer de volgende set SOP’s en verfijn templates op basis van daadwerkelijk gebruik in plaats van aannames.
Versnel levering met Koder.ai (zonder je ownership-model te veranderen)
Als je snel van concept naar een werkend intern hulpmiddel wilt, kan een vibe-coding platform zoals Koder.ai helpen om het runbook-beheer webapp end-to-end te prototypen vanuit een chatgestuurde specificatie. Je kunt kernworkflows itereren (library → editor → execution mode) en vervolgens de broncode exporteren wanneer je klaar bent om te reviewen, te hardenen en binnen je standaard engineeringproces te draaien.
Koder.ai is vooral praktisch voor dit soort producten omdat het aansluit bij gebruikelijke implementiekeuzes (React voor de web-UI; Go + PostgreSQL voor de backend) en planning mode, snapshots en rollback ondersteunt—handig bij het itereren op operationeel kritieke functies zoals versiebeheer, RBAC en audittrails.