Wat dit bericht behandelt (en waarom het belangrijk is)
Snowflake maakte een eenvoudig maar verstrekkend idee populair in cloud data warehousing: bewaar data-opslag en query-compute gescheiden. Die scheiding verandert twee dagelijkse pijnpunten voor datateams—hoe warehouses schalen en hoe je ervoor betaalt.
In plaats van het warehouse te behandelen als één vast “bakje” (waar meer gebruikers, meer data of complexere queries allemaal om dezelfde resources vechten), laat het model van Snowflake je data één keer opslaan en de juiste hoeveelheid compute opstarten wanneer dat nodig is. Het resultaat is vaak snellere tijd-tot-antwoord, minder knelpunten tijdens piekbelastingen en duidelijkere controle over wat geld kost (en wanneer).
Dit bericht legt in eenvoudige taal uit wat het echt betekent om opslag en compute te scheiden—en hoe dat effect heeft op:
- Concurrency (veel mensen die tegelijk queries draaien)
- Elastische schaalbaarheid (compute omhoog en omlaag zetten)
- Kostenpatroon (alleen betalen voor compute terwijl het draait, plus doorlopende opslag)
We wijzen ook op waar het model niet per se alles oplost—want sommige kosten- en prestatieverrassingen komen door hoe workloads zijn ontworpen, niet door het platform zelf.
Thema #2: waarom het ecosysteem even belangrijk kan zijn als ruwe snelheid
Een snel platform is niet het hele verhaal. Voor veel teams hangt time-to-value af van of je het warehouse gemakkelijk kunt koppelen aan de tools die je al gebruikt—ETL/ELT-pijplijnen, BI-dashboards, catalogus-/governance-tools, beveiligingscontrols en partner-databronnen.
Het ecosysteem van Snowflake (inclusief datadeling-patronen en marktachtige distributie) kan implementatietijden verkorten en maatwerk-engineering verminderen. Dit bericht behandelt hoe “ecosysteemdiepte” er in de praktijk uitziet en hoe je het voor je organisatie kunt evalueren.
Voor wie dit is
Deze gids is geschreven voor dataleiders, analisten en niet-specialistische beslissers—iedereen die de afwegingen achter Snowflake-architectuur, schaalbaarheid, kosten en integratieopties wil begrijpen zonder te verdrinken in verkopersjargon.
Voor de scheiding: waarom traditionele warehouses tegen grenzen aanlopen
Traditionele data warehouses waren gebouwd rond een simpele veronderstelling: je koopt (of huurt) een vaste hoeveelheid hardware en draait vervolgens alles op datzelfde bakje of cluster. Dat werkte goed toen workloads voorspelbaar waren en groei geleidelijk—maar het creëerde structurele grenzen zodra datavolumes en gebruikersaantallen versnellen.
Het klassieke model: vaste clusters en zorgvuldig capacity planning
On-prem systemen (en vroege cloud “lift-and-shift” deployments) zagen er typisch zo uit:
- Een enkele MPP (massively parallel processing) cluster behandelde opslag, CPU en geheugen samen.
- Je dimensioneerde het cluster voor piekvraag, omdat herschalen traag, risicovol of downtime-veroorzakend kon zijn.
- Capacity planning werd een terugkerend project: groei voorspellen, budget verantwoorden, hardware bestellen, installeren, migreren.
Zelfs wanneer leveranciers “nodes” boden, bleef het kernpatroon hetzelfde: schalen betekende meestal grotere of meer nodes toevoegen aan één gedeelde omgeving.
De pijnpunten: trage schaalbaarheid, verspilde uitgaven en wachtrijen
Dit ontwerp creëert een paar veelvoorkomende hoofdpijndossiers:
- Trage schaalbaarheid: Als je kwartaalrapportage plotseling meer rekenkracht nodig heeft, kun je niet altijd snel bijschakelen. Je wacht of je overprovisiont “voor het geval dat.”
- Idle capaciteit: Clusters die voor pieken zijn gesized, staan het grootste deel van de tijd onderbenut—maar je betaalt er nog steeds voor (hardwarekosten, licenties, onderhoudstijd).
- Wachtrijen bij belasting: Wanneer meerdere teams tegelijk queries draaien, concurreren ze om dezelfde resources. Zware jobs kunnen interactieve dashboards blokkeren, wat leidt tot time-outs, gefrustreerde stakeholders en regels als “draai die query niet tijdens kantooruren.”
Omdat deze warehouses nauw gekoppeld waren aan hun omgeving, groeiden integraties vaak organisch: aangepaste ETL-scripts, handgebouwde connectors en eenmalige pijplijnen. Ze werkten—totdat een schema veranderde, een upstream systeem verschoven of een nieuwe tool werd geïntroduceerd. Alles draaiende houden voelde vaak als constant onderhoud in plaats van gestage vooruitgang.
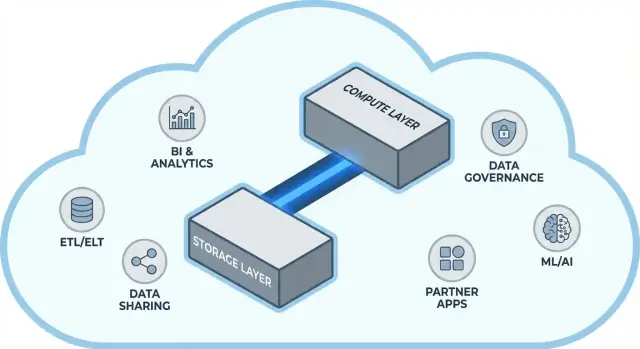
Het kernidee: opslag en compute scheiden
Traditionele data warehouses koppelen vaak twee heel verschillende taken: opslag (waar je data leeft) en compute (de rekenkracht die die data leest, joinet, aggregeert en schrijft).
Opslag versus compute (in gewone taal)
Opslag is als een voorraadkast: tabellen, bestanden en metadata worden veilig en relatief goedkoop bewaard, ontworpen om duurzaam en altijd beschikbaar te zijn.
Compute is als het keukenteam: het zijn de CPU's en het geheugen die queries “klaarmaken”—SQL uitvoeren, sorteren, scannen, resultaten bouwen en meerdere gebruikers tegelijk bedienen.
De sleutelverschuiving: ze onafhankelijk schalen
Snowflake scheidt deze twee zodat je elk kunt aanpassen zonder het andere te dwingen te veranderen.
- Als datavolume groeit, voeg je meer opslag toe (meestal incrementeel en redelijk voorspelbaar).
- Als rapportverkeer piekt, voeg je meer compute toe (door virtual warehouses te resizen of extra warehouses te starten) zonder de onderliggende data te verplaatsen of te dupliceren.
In de praktijk verandert dit de dagelijkse operatie: je hoeft niet langer compute “voor te kopen” omdat opslag groeit, en je kunt workloads isoleren (bijvoorbeeld analysts versus ETL) zodat ze elkaar niet vertragen.
Wat het niet is
Deze scheiding is krachtig, maar geen magie.
- Het is geen “gratis schaalbaarheid.” Grotere of meer warehouses betekenen doorgaans hogere compute-kosten.
- Het is niet automatisch altijd goedkoper. Slecht geschreven queries, onnodige refresh-schema’s of altijd-aan warehouses kunnen nog steeds kosten drijven.
- Het is geen vrijbrief om geen planning te doen. Je moet nog steeds warehouse-groottes kiezen, auto-suspend regels instellen en compute afstemmen op bedrijfsgebruik.
De waarde zit in controle: opslag en compute afzonderlijk betalen en elk matchen aan wat je teams echt nodig hebben.
Snowflake’s architectuur in eenvoudige termen
Snowflake is het makkelijkst te begrijpen als drie lagen die samenwerken, maar onafhankelijk kunnen schalen.
1) Opslag: cloud object storage
Je tabellen bestaan uiteindelijk als datafiles in de object storage van je cloudprovider (denk aan S3, Azure Blob of GCS). Snowflake beheert bestandsformaten, compressie en organisatie voor je. Je “voegt geen schijven toe” of dimensioneert opslagvolumes—opslag groeit mee met data.
2) Compute: virtual warehouses
Compute is verpakt als virtual warehouses: onafhankelijke clusters van CPU/geheugen die queries uitvoeren. Je kunt meerdere warehouses tegelijk tegen dezelfde data laten draaien. Dat is het belangrijkste verschil met oudere systemen waarin zware workloads elkaar uit de resources duwden.
Een aparte services-laag behandelt de “hersenen” van het systeem: authenticatie, query-parsing en optimalisatie, transacties/metadata-management en coördinatie. Deze laag beslist hoe een query efficiënt uitgevoerd wordt voordat compute de data aanraakt.
Hoe een query stroomt
Als je SQL indient, parseert de services-laag van Snowflake het, bouwt een uitvoeringsplan en geeft dat plan door aan een gekozen virtual warehouse. Het warehouse leest alleen de noodzakelijke datafiles uit object storage (en profiteert van caching waar mogelijk), verwerkt ze en retourneert resultaten—zonder je basale data permanent naar het warehouse te verplaatsen.
Concurrency en isolatie (zonder jargon)
Als veel mensen tegelijk queries draaien, kun je ofwel:
- verschillende warehouses gebruiken voor teams/workloads (workload-isolatie), of
- multi-cluster warehouses inschakelen zodat Snowflake extra compute-clusters toevoegt wanneer de vraag piekt, en daarna weer terugschakelt.
Dat is de architectonische basis voor Snowflake’s performance en de controle op “noisy neighbors.”
Schalen en concurrency: wat er echt verandert
De grote praktische verschuiving van Snowflake is dat je compute onafhankelijk schaalt van data. In plaats van “het warehouse wordt groter” kun je resources per workload omhoog of omlaag draaien—zonder tabellen te kopiëren, schijven te repartitioneren of downtime te plannen.
Elasticiteit: compute resizen zonder data te verplaatsen
In Snowflake is een virtual warehouse de compute-engine die queries uitvoert. Je kunt het binnen seconden resizen (bijv. van Small naar Large), terwijl de data op zijn plek blijft in gedeelde opslag. Dat betekent dat performance-tuning vaak neerkomt op een simpele vraag: “Heeft deze workload nu meer rekenkracht nodig?”
Dit maakt tijdelijke bursts ook mogelijk: scale up voor maandafsluiting en scale terug zodra de piek voorbij is.
Concurrency: minder wachtrijgedoe
Traditionele systemen dwingen vaak verschillende teams om dezelfde compute te delen, wat drukke uren verandert in een rij bij de kassa.
Snowflake laat je aparte warehouses draaien per team of workload—bijvoorbeeld één voor analysts, één voor dashboards en één voor ETL. Omdat deze warehouses dezelfde onderliggende data lezen, verminder je het “mijn dashboard vertraagde jouw rapport”-probleem en maak je prestaties voorspelbaarder.
Concessies die je zult merken
Elastische compute is geen automatische overwinning. Veelvoorkomende valkuilen zijn:
- Cold starts: gesuspende warehouses hebben een korte opstarttijd, wat latentie kan toevoegen voor onregelmatige jobs.
- Right-sizing keuzes: te groot betekent geldverspilling; te klein veroorzaakt trage queries en frustratie.
- Guardrails zijn nodig: gebruik auto-suspend/auto-resume, resource monitors en duidelijke eigenaarschap zodat warehouses niet onnodig draaien of wildgroei veroorzaken.
De nettoverandering: schalen en concurrency worden van infrastructuurprojecten dagelijkse operationele beslissingen.
Kostenmodel: waar besparingen ontstaan (en waar niet)
Bezit je broncode
Maak een werkende webapp en exporteer de broncode wanneer je klaar bent om deze zelf te beheren.
Hoe Snowflake-facturatie eigenlijk werkt
Snowflake’s “pay for what you use” is eigenlijk twee meters die parallel lopen:
- Compute: gefactureerd voor de tijd dat je virtual warehouse draait (in credits). Als het aanstaat, loopt de meter.
- Opslag: gefactureerd voor de hoeveelheid opgeslagen data (plus eventuele extra opslag voor functies zoals Time Travel/Fail-safe).
Deze scheiding is waar besparingen kunnen ontstaan: je kunt veel data relatief goedkoop bewaren terwijl je compute alleen aanzet wanneer je het nodig hebt.
Waar kosten kunnen oplopen
De meeste “onverwachte” uitgaven komen door compute-gedrag in plaats van pure opslag. Gebruikelijke oorzaken zijn:
- Oversized warehouses (een grotere maat kiezen dan de workload nodig heeft)
- Altijd-aan workloads (warehouses die ’s nachts of in het weekend blijven draaien)
- Inefficiënte queries (ongefilterde scans, onnodige joins, zware transformaties die herhaaldelijk draaien)
- High-concurrency patronen (veel kleine dashboards die constant verversen)
Het scheiden van opslag en compute maakt queries niet automatisch efficiënt—slechte SQL kan nog steeds snel credits verbranden.
Praktische controls die in de echte wereld werken
Je hebt geen financiële afdeling nodig om dit te beheren—alleen een paar guardrails:
- Auto-suspend / auto-resume om te voorkomen dat je betaalt voor idle tijd
- Resource monitors om creditgebruik per warehouse/team te waarschuwen of te begrenzen
- Scheduling (batch-jobs in gedefinieerde vensters draaien; dev/test buiten kantooruren pauzeren)
- Right-sizing en testen met kleinere warehouse-groottes voordat je omhoog schaalt
Goed gebruikt beloont het model discipline: kortlopende, juist geschaalde compute gecombineerd met voorspelbare opslaggroei.
Data sharing en samenwerking als eersteklas feature
Snowflake behandelt delen als iets dat in het platform is ontworpen—niet als een nasleep geplakt op exports, file drops en eenmalige ETL-jobs.
Delen zonder te kopiëren (in veel gevallen)
In plaats van extracts rond te sturen, kan Snowflake een andere account toestaan dezelfde onderliggende data te queryen via een beveiligde “share.” In veel scenario’s hoeft de data niet in een tweede warehouse gedupliceerd of naar object storage gepusht te worden voor download. De consumer ziet de gedeelde database/tabel alsof deze lokaal is, terwijl de provider controle behoudt over wat blootgesteld wordt.
Deze “ontkoppelde” benadering is waardevol omdat het data-sprawl vermindert, toegang versnelt en het aantal pipelines dat je moet bouwen en onderhouden verlaagt.
Veelvoorkomende samenwerkingspatronen
Partner- en klantdeling: Een vendor kan geverifieerde datasets publiceren naar klanten (bijv. gebruiksanalytics of referentiegegevens) met duidelijke grenzen—alleen de toegestane schemas, tabellen of views.
Interne domeindeling: Centrale teams kunnen gecertificeerde datasets beschikbaar stellen aan product, finance en operations zonder dat elke team hun eigen kopieën hoeft te bouwen. Dat ondersteunt een “één set cijfers”-cultuur terwijl teams toch hun eigen compute draaien.
Gegovernede samenwerking: Gezamenlijke projecten (bijv. met een bureau, leverancier of dochteronderneming) kunnen werken op een gedeelde dataset terwijl gevoelige kolommen gemaskeerd blijven en toegang gelogd wordt.
Beperkingen om op te plannen
Delen is geen “set it and forget it.” Je hebt nog steeds nodig:
- Governance: duidelijk eigenaarschap, toegangsreviews en policies voor PII/gereguleerde data.
- Contracten en verwachtingen: wie betaalt voor compute, SLA’s, retentie en wat er gebeurt als definities veranderen.
- Vindbaarheid: zonder catalogus en goede naamgeving vinden mensen de juiste gedeelde data niet of vertrouwen ze die niet. Stem shares af met documentatie en je data-catalogus als je die hebt.
Een snel warehouse is nuttig, maar snelheid alleen bepaalt zelden of een project op tijd wordt opgeleverd. Wat vaak het verschil maakt, is het ecosysteem rondom het platform: de kant-en-klare verbindingen, tools en know-how die maatwerkwerk verminderen.
In de praktijk omvat een ecosysteem:
- Connectors naar databronnen en bestemmingen (SaaS-apps, databases, streaming-tools)
- Partner-tools voor ingestie, transformatie, BI, data-kwaliteit en observeerbaarheid
- Apps en native integraties die dicht bij de data draaien
- Templates en referentie-architecturen (common models, patronen, deployment guides)
- Community-kennis: voorbeelden, forums, meetups en beschikbaarheid bij werving
Waarom ecosysteem benchmarks kan verslaan voor levertijd
Benchmarks meten een smalle snede van performance onder gecontroleerde omstandigheden. Werkelijke projecten besteden de meeste tijd aan:
- Data betrouwbaar en incrementeel binnenkrijgen
- Datasets modelleren, testen en documenteren
- Operationele taken (monitoring, alerting, kostenbeheersing)
- Security reviews, toegangscontroles en audits
Als je platform volwassen integraties voor deze stappen heeft, hoef je minder glue code te bouwen. Dat verkort meestal implementatietijd, verbetert betrouwbaarheid en maakt het eenvoudiger teams of leveranciers te wisselen zonder alles te herschrijven.
Een eenvoudige evaluatiebril: dekking, kwaliteit, onderhoudbaarheid
Bij het beoordelen van een ecosysteem, kijk naar:
- Dekking: ondersteunt het je belangrijkste bronnen, BI-tools, orchestratie en governancebehoeften?
- Kwaliteit: worden connectors actief onderhouden, goed gedocumenteerd en bewezen op jouw schaal?
- Onderhoudbaarheid: hoeveel voortdurende inspanning vraagt het—upgrades, breaking changes, debuggen en support?
Performance geeft je capaciteit; het ecosysteem bepaalt vaak hoe snel je die capaciteit in bedrijfsresultaat omzet.
Integratie-ecosysteem: data erin krijgen, eruit halen en gebruiken
Zet KPI's op mobiel
Maak een Flutter-app voor KPI-checks en alerts die je bestaande datamodel gebruikt.
Snowflake kan snel queries draaien, maar waarde verschijnt wanneer data betrouwbaar door je stack beweegt: van bronnen, naar Snowflake, en weer uit naar tools die mensen dagelijks gebruiken. De “last mile” bepaalt meestal of een platform moeiteloos voelt of constant fragiel.
De belangrijkste integratiecategorieën om te plannen
De meeste teams hebben uiteindelijk een mix nodig van:
- ELT/ETL om te laden vanuit databases, SaaS-apps, bestanden en object storage.
- BI en analytics tools voor dashboards, self-serve exploratie en semantische lagen.
- Reverse ETL om gecureerde data terug te pushen naar CRM, marketing en support systemen.
- Orchestratie voor scheduling, afhankelijkheden, backfills en promotie tussen omgevingen.
- Streaming voor near-real-time events en change data capture.
- ML-tools voor feature-pijplijnen, training-workflows en modelmonitoring.
Vragen om te stellen voordat je connectors kiest
Niet alle “Snowflake-compatible” tools gedragen zich hetzelfde. Tijdens evaluatie, focus op praktische details:
- Is de connector gecertificeerd/ondersteund (en door wie)? Wat is het escalatiepad?
- Kan het incrementele loads goed afhandelen (CDC, timestamps, high-water marks)?
- Hoe gaat het om met schema drift—nieuwe kolommen, typewijzigingen, verwijderde velden?
- Wat zijn de garanties op retries, deduplicatie en exactly-once vs at-least-once?
Negeer operations niet
Integraties hebben ook day-2-klare functies nodig: monitoring en alerting, lineage/catalog hooks, en incident response workflows (ticketing, on-call, runbooks). Een sterk ecosysteem is niet alleen meer logo’s—het zijn minder verrassingen wanneer pijplijnen midden in de nacht falen.
Governance, security en vertrouwen op schaal
Als teams groeien, is het moeilijkste deel van analytics vaak niet snelheid maar zorgen dat de juiste mensen toegang hebben tot de juiste data, voor het juiste doel, met bewijs dat controls werken. Snowflake’s governance-functies zijn ontworpen voor die realiteit: veel gebruikers, veel dataprodukten en frequent delen.
Governance-basics die echt werken
Begin met duidelijke rollen en een least-privilege mindset. In plaats van individuele toegang te geven, definieer rollen zoals ANALYST_FINANCE of ETL_MARKETING, en geef die rollen toegang tot specifieke databases, schemas, tabellen en (indien nodig) views.
Voor gevoelige velden (PII, financiële identifiers) gebruik masking policies zodat mensen datasets kunnen queryen zonder ruwe waarden te zien tenzij hun rol dat toestaat. Combineer dat met auditing: houd bij wie wat en wanneer queried, zodat security- en compliance-teams vragen kunnen beantwoorden zonder giswerk.
Waarom governance delen en self-service verandert
Goede governance maakt data sharing veiliger en schaalbaarder. Wanneer je share-model is gebouwd op rollen, policies en geaudit toegangsbeheer, kun je self-service inschakelen (meer gebruikers die data verkennen) zonder per ongeluk blootstelling te veroorzaken.
Het vermindert ook frictie voor compliance: policies worden herhaalbare controls in plaats van eenmalige uitzonderingen. Dat telt wanneer datasets hergebruikt worden over projecten, afdelingen of externe partners.
Praktische tips die toekomstige pijn voorkomen
- Naamgevingsconventies: standaardiseer namen voor databases/schemas die doel en gevoeligheid signaleren (bijv.
PROD_FINANCE, DEV_MARKETING, SHARED_PARTNER_X). Consistentie versnelt reviews en vermindert fouten.
- Omgevingsscheiding: houd DEV/TEST/PROD logisch gescheiden, met striktere controls in PROD. Behandel productie-data als uitzondering, niet als standaard.
- Toegangsreviews: stel een cadans in (maandelijks voor hoog-risico data, kwartaal anders). Review rolleden, inactieve gebruikers en privileged roles.
Vertrouwen op schaal gaat minder over één “perfecte” control en meer over een systeem van kleine, betrouwbare gewoonten die toegang intentioneel en uitlegbaar houden.
Workloads en best-practice patronen
Prototypeer snel een data-app
Bouw snel een metrics-app op basis van Snowflake vanuit chat en deel die snel met belanghebbenden.
Snowflake blinkt vaak uit wanneer veel mensen en tools dezelfde data voor verschillende doeleinden moeten queryen. Omdat compute verpakt is in onafhankelijke “warehouses”, kun je elke workload afstemmen op een vorm en schema dat past.
Veelvoorkomende workload-mapping
Analytics & dashboards: Zet BI-tools op een dedicated warehouse dat is gesized voor stabiele, voorspelbare query-volumes. Dit voorkomt dat dashboard-refreshes vertraagd worden door ad hoc-exploratie.
Ad hoc-analyse: Geef analisten een apart warehouse (vaak kleiner) met auto-suspend ingeschakeld. Je krijgt snelle iteratie zonder te betalen voor idle tijd.
Data science & experimenten: Gebruik een warehouse gesized voor zwaardere scans en occasionele bursts. Als experimenten pieken, schaal dit warehouse tijdelijk op zonder BI-gebruikers te beïnvloeden.
Data-apps & embedded analytics: Behandel app-verkeer als een productie-service—apart warehouse, conservatieve timeouts en resource monitors om verrassingen in uitgaven te voorkomen.
Als je lichte interne data-apps bouwt (bijv. een ops-portal die Snowflake queryt en KPI’s toont), is een snelle route het genereren van een werkende React + API-scaffold en itereren met stakeholders. Platforms zoals Koder.ai (een vibe-coding platform dat web/server/mobile apps bouwt vanuit chat) kunnen teams helpen deze Snowflake-ondersteunde apps snel te prototypen en de broncode te exporteren zodra je klaar bent om te operationaliseren.
Best-practice patronen die blijven werken
Een eenvoudige regel: scheid warehouses per publiek en doel (BI, ELT, ad hoc, ML, app). Combineer dat met goede querygewoonten—vermijd brede SELECT *, filter vroeg en let op inefficiënte joins. Aan de modeling-kant, geef prioriteit aan structuren die passen bij hoe mensen queryen (vaak een schone semantische laag of goed gedefinieerde marts), in plaats van fysieke layouts te overoptimaliseren.
Wanneer alternatieven of aanvullingen overwegen
Snowflake vervangt niet alles. Voor hoge-throughput, lage-latentie transactionele workloads (typische OLTP) is een gespecialiseerde database meestal beter, waarbij Snowflake wordt gebruikt voor analytics, rapportage, delen en downstream dataprodukten. Hybride setups zijn gebruikelijk en vaak het meest praktisch.
Migratie-overwegingen: wat te plannen voordat je verhuist
Een Snowflake-migratie is zelden een “lift and shift.” De opslag/compute-scheiding verandert hoe je workloads dimensioneert, tuneert en betaalt—dus plannen vooraf voorkomt verrassingen later.
Een praktische migratiereeks
Begin met een inventaris: welke dat bronnen voeden het warehouse, welke pijplijnen transformeren het, welke dashboards zijn ervan afhankelijk en wie is eigenaar van elk onderdeel. Prioriteer dan op bedrijfsimpact en complexiteit (bijv. kritieke finance-rapportage eerst, experimentele sandboxes later).
Vervolgens converteer je SQL en ETL-logica. Veel standaard SQL draagt over, maar details zoals functies, datumafhandeling, procedurele code en temp-table patronen hebben vaak herschrijven nodig. Valideer resultaten vroeg: draai parallelle outputs, vergelijk rijen- en aggregate-aantallen en bevestig randgevallen (nulls, tijdzones, deduplicatie-logica). Plan tenslotte de cutover: een freeze-venster, een rollback-pad en een duidelijke "definition of done" voor elk dataset en rapport.
Typische risico’s om op te letten
Verborgen afhankelijkheden zijn het meest voorkomend: een spreadsheet-extract, een hard-coded connection string, een downstream job die niemand zich herinnert. Prestatieverrassingen ontstaan wanneer oude tuning-veronderstellingen niet meer gelden (bijv. overmatig gebruik van tiny warehouses, of veel kleine queries zonder rekening te houden met concurrency). Kostenpieken komen meestal door warehouses die draaien, ongecontroleerde retries of duplicerende dev/test workloads. Permissiegaten verschijnen bij migratie van grove rollen naar fijnmazigere governance—testen moeten "least privilege" gebruikersruns omvatten.
Change management (sla dit niet over)
Stel een eigenaarschapsmodel op (wie bezit data, pijplijnen en kosten), geef rolgebaseerde training voor analisten en engineers en definieer een supportplan voor de eerste weken na cutover (on-call rotatie, incident-runbook en een plek om issues te melden).
Het kiezen van een modern datapplatform gaat niet alleen over piekbenchmark-snelheid. Het gaat om of het platform past bij je echte workloads, je manier van werken en de tools waar je op vertrouwt.
Een praktische evaluatie-checklist
Gebruik deze vragen om je shortlist en leveranciersgesprekken te sturen:
- Workloads: Draai je voornamelijk geplande dashboards, ad-hoc analyse, data science, ELT/ETL of klantgerichte apps? Heb je voorspelbare batch-vensters nodig of elastische burst-capaciteit?
- Concurrency-behoeften: Hoeveel mensen (of applicaties) zullen tegelijk queryen en hoe "spiky" is het gebruik tijdens kantooruren?
- Data-sharing requirements: Moet je live data delen met partners, business units of klanten zonder bestanden te versturen? Verwacht je third-party datasets te consumeren?
- Tooling fit: Integreren je BI-tools, orchestratie, catalogus en CI/CD-workflows soepel? Wat breekt als je verhuist?
- Governance en security: Heb je fijnmazige toegangscontrole, audit trails, masking, retentiepolicies en duidelijke scheiding van taken nodig?
- Kostenbeperkingen: Welke kosten zijn het belangrijkst—steady-state uitgaven, piekuren of het vermogen om compute uit te zetten? Hoe voorkom je "altijd-aan" verspilling?
Een korte pilot-plan (2–4 weken)
Kies twee of drie representatieve datasets (geen toy-samples): één grote fact-table, één rommelige semi-gestructureerde bron en één business-kritisch domein.
Draai daarna echte gebruikersqueries: dashboards tijdens ochtendpiek, analyst-exploratie, geplande loads en een paar worst-case joins. Meet: querytijd, concurrency-gedrag, tijd-tot-ingest, operationele inspanning en kosten per workload.
Als onderdeel van je evaluatie hoeveel snel je iets bruikbaars kunt opleveren, overweeg dan een klein deliverable voor de pilot—zoals een interne metrics-app of een gereguleerd data-request workflow die Snowflake queryt. Het bouwen van die dunne laag onthult integratie- en security-realiteiten sneller dan benchmarks alleen, en tools zoals Koder.ai kunnen het prototype-to-production traject versnellen door de app-structuur via chat te genereren en je toe te staan de code te exporteren voor langdurig onderhoud.
Voorgestelde volgende stappen
Als je hulp wilt bij het inschatten van kosten en het vergelijken van opties, begin bij pricing.
Voor migratie- en governance-advies, bekijk gerelateerde artikelen in de blog.