06 mei 2025·8 min
Sleutel-waarde-opslag voor caching, sessies en snelle lookups
Leer hoe sleutel-waarde-opslagen caching, gebruikerssessies en snelle lookups aandrijven—plus TTLs, evictie, schaalopties en praktische afwegingen om op te letten.
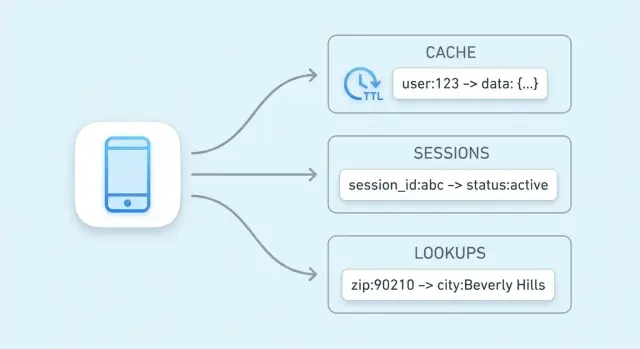
Leer hoe sleutel-waarde-opslagen caching, gebruikerssessies en snelle lookups aandrijven—plus TTLs, evictie, schaalopties en praktische afwegingen om op te letten.
Het hoofddoel van een sleutel-waarde-opslag is eenvoudig: latency voor eindgebruikers verminderen en de belasting op je primaire database verlagen. In plaats van telkens dezelfde dure query uit te voeren of een resultaat opnieuw te berekenen, kan je app een vooraf berekende waarde in één voorspelbare stap ophalen.
Een sleutel-waarde-opslag is geoptimaliseerd rond één operatie: “geef deze sleutel, retourneer de waarde.” Die nauwe focus maakt een zeer korte critical path mogelijk.
In veel systemen kan een lookup vaak worden afgehandeld met:
Het resultaat is lage en consistente responstijden—precies wat je wilt voor caching, sessieopslag en andere hogesnelheids-zoekacties.
Zelfs als je database goed is getuned, moet die nog queries parsen, plannen, indexen lezen en concurrency coördineren. Als duizenden requests vragen om dezelfde “top producten” lijst, stapelt dat herhaalde werk zich op.
Een key-value cache verschuift die herhaalde leesverkeer weg van de database. Je database kan meer tijd besteden aan requests die het echt nodig hebben: writes, complexe joins, rapportage en consistentie-kritieke reads.
Snelheid is niet gratis. Key-value stores ruilen meestal rijke querymogelijkheden (filters, joins) in en kunnen verschillende garanties hebben rond persistentie en consistentie afhankelijk van de configuratie.
Ze blinken uit wanneer je data een duidelijke sleutel heeft (bijvoorbeeld user:123, cart:abc) en je snelle toegang wilt. Als je vaak moet “vind alle items waar X”, is een relationele of documentdatabase meestal een betere primaire opslag.
Een sleutel-waarde-opslag is het eenvoudigste type database: je slaat een waarde (data) op onder een unieke sleutel (label) en later haal je de waarde op door de sleutel te geven.
Denk aan een sleutel als een identifier die je exact kunt herhalen, en een waarde als het ding dat je terug wilt.
Sleutels zijn meestal korte strings (zoals user:1234 of session:9f2a...). Waarden kunnen klein zijn (een teller) of groter (een JSON-blob).
Key-value stores zijn gebouwd voor “geef me de waarde voor deze sleutel”-queries. Intern gebruiken veel implementaties een structuur vergelijkbaar met een hash table: de sleutel wordt omgezet naar een locatie waar de waarde snel te vinden is.
Daarom hoor je vaak constant-time lookups (vaak geschreven als O(1)): prestaties hangen veel meer af van hoeveel requests je doet dan van hoeveel records er totaal zijn. Het is geen magie—collisies en geheugengrenzen blijven belangrijk—maar voor typische cache/sessie-gebruik is het erg snel.
Hot data is het kleine deel van informatie dat herhaaldelijk wordt opgevraagd (populaire productpagina’s, actieve sessies, rate-limit tellers). Hot data in een key-value store bewaren—vooral in geheugen—vermijdt tragere databasequeries en houdt responstijden voorspelbaar onder load.
Caching betekent een kopie van vaak benodigde data ergens sneller bewaren dan de originele bron. Een key-value store is daar veelgebruikt voor omdat hij een waarde in één lookup kan teruggeven, vaak in enkele milliseconden.
Caching helpt het meest wanneer steeds dezelfde vragen worden gesteld: populaire pagina’s, herhaalde zoekopdrachten, veelvoorkomende API-calls of dure berekeningen. Het is ook nuttig wanneer de “echte” bron langzamer of rate-gelimiteerd is—bijvoorbeeld een primaire database onder zware load of een derdepartij-API waarvoor je per request betaalt.
Goede kandidaten zijn resultaten die vaak gelezen worden en die niet per se tot op de seconde nauwkeurig moeten zijn:
Een simpele regel: cache outputs die je opnieuw kunt genereren indien nodig. Vermijd het cachen van data die constant verandert of die bij elke read consistent moet zijn (bijv. een banksaldo).
Zonder caching kan elke paginaview meerdere databasequeries of API-calls triggeren. Met een cache kan de applicatie veel requests uit de key-value store bedienen en alleen bij een cache miss naar de primaire database of API vallen. Dat verlaagt queryvolume, vermindert connection contention en kan betrouwbaarheid verbeteren tijdens trafficpieken.
Caching ruilt versheid in voor snelheid. Als gecachte waarden niet snel genoeg worden bijgewerkt, kunnen gebruikers verouderde informatie zien. In gedistribueerde systemen kunnen twee requests kort verschillende versies van dezelfde data lezen.
Je beheert deze risico’s door geschikte TTLs te kiezen, te bepalen welke data “licht verouderd” mag zijn en je applicatie zo te ontwerpen dat incidentele cache misses of vertragingen bij verversing worden opgevangen.
Een cache “patroon” is een herhaalbare workflow voor hoe je app data leest en schrijft met een cache in de lus. De keuze hangt minder af van het gereedschap (Redis, Memcached, enz.) en meer van hoe vaak de onderliggende data verandert en hoeveel veroudering je tolereert.
Bij cache-aside bestuurt je applicatie de cache expliciet:
Beste fit: data die vaak gelezen wordt maar zelden verandert (productpagina’s, configuratie, publieke profielen). Het is ook een goede default omdat fouten gracieus degraderen: als de cache leeg is, kun je nog steeds uit de database lezen.
Read-through betekent dat de cache-laag bij een miss de database ophaalt (je app leest “uit de cache” en de cache weet hoe hij moet laden). Operationeel vereenvoudigt dit de app-code, maar het voegt complexiteit toe aan de cache-tier (je hebt een loader-integratie nodig).
Write-through betekent dat elke write synchroon naar zowel cache als database gaat. Reads zijn meestal snel en consistent, maar writes zijn langzamer omdat ze twee stappen moeten voltooien.
Beste fit: data waarvoor je minder cache misses en eenvoudigere leesconsistentie wilt (gebruikersinstellingen, feature flags) en waar schrijflatentie acceptabel is.
Bij write-back schrijft je app eerst naar de cache en de cache spoelt wijzigingen later naar de database (vaak in batches).
Voordelen: zeer snelle writes en verminderde databasebelasting.
Risico: als de cache-node faalt voordat hij heeft weggeschreven, kun je data verliezen. Gebruik dit alleen als je verlies kunt tolereren of als je sterke durable mechanismen hebt.
Als data zelden verandert, is cache-aside met een redelijke TTL meestal voldoende. Als data vaak verandert en verouderde reads pijnlijk zijn, overweeg write-through (of zeer korte TTLs plus expliciete invalidatie). Als write-volume extreem is en occasioneel verlies acceptabel, kan write-behind de moeite waard zijn.
Gecachte data “vers genoeg” houden draait vooral om de juiste expiratiestrategie per sleutel kiezen. Het doel is niet perfecte nauwkeurigheid—maar het voorkomen dat verouderde resultaten gebruikers verrassen terwijl je nog steeds de snelheidsvoordelen van caching behoudt.
Een TTL (time to live) zet een automatische vervaldatum op een sleutel zodat deze na een tijd verdwijnt. Korte TTLs verminderen veroudering maar verhogen cache misses en backend-belasting. Lange TTLs verbeteren de hit rate maar verhogen de kans op verouderde waarden.
Een praktische aanpak:
TTL is passief. Als je weet dat data veranderd is, is het vaak beter actief te invalidëren: delete de oude sleutel of schrijf meteen de nieuwe waarde.
Voorbeeld: nadat een gebruiker zijn e-mail bijwerkt, delete user:123:profile of update het in de cache direct. Actieve invalidatie verkleint het venster van veroudering, maar vereist dat je applicatie betrouwbaar die cache-updates uitvoert.
In plaats van oude sleutels te verwijderen, voeg een versie in de sleutelnaam toe, zoals product:987:v42. Wanneer het product verandert, verhoog je de versie en ga je naar v43 schrijven/lezen. Oude versies mogen later natuurlijk expireren. Dit vermijdt races waar een server een sleutel verwijdert terwijl een andere server hem aan het schrijven is.
Een stampede gebeurt als een populaire sleutel verloopt en veel requests hem tegelijk herbouwen.
Veelvoorkomende oplossingen:
Sessiedata is de kleine bundel informatie die je app nodig heeft om een terugkerende browser of mobiele client te herkennen. Minimaal is dat een sessie-ID (of token) dat naar server-side state verwijst. Afhankelijk van het product kan het ook user state bevatten (ingelogd-vlaggen, rollen, CSRF-nonce), tijdelijke voorkeuren en tijdgevoelige data zoals winkelwageninhoud of een checkout-stap.
Key-value stores passen goed omdat sessie-reads en -writes simpel zijn: lookup op token, waarde ophalen, bijwerken en expiratie instellen. Je kunt ook gemakkelijk TTLs toepassen zodat inactieve sessies automatisch verdwijnen, wat opslag netjes houdt en risico vermindert bij token-lekken.
Een veelvoorkomende flow:
Gebruik duidelijke, gescopeerde sleutels en houd waarden klein:
sess:<token> of sess:v2:<token> (versionering helpt bij toekomstige wijzigingen).user_sess:<userId> -> <token> bij om “één actieve sessie per gebruiker” af te dwingen of sessies per gebruiker in te trekken.Logout moet de sessiesleutel en eventuele gerelateerde indexen (zoals user_sess:<userId>) verwijderen. Voor rotatie (aanbevolen na login, privilege-wijzigingen of periodiek) maak je een nieuw token, schrijf je de nieuwe sessie en delete je de oude sleutel. Dit verkleint het venster waarin een gestolen token bruikbaar is.
Caching is de meest voorkomende use-case, maar niet de enige manier waarop een key-value store je systeem kan versnellen. Veel applicaties vertrouwen op snelle reads voor kleine, vaak geraadpleegde stukken state—zaken die “naast de bron van waarheid” zitten en snel gecontroleerd moeten worden bij vrijwel elk request.
Autorisatiechecks zitten vaak op het kritieke pad: elke API-call moet mogelijk beantwoorden “mag deze gebruiker dit doen?” Het ophalen van permissies uit een relationele database bij elke request kan merkbare latentie en load toevoegen.
Een key-value store kan compacte autorisatiedata houden voor snelle lookups, bijvoorbeeld:
perm:user:123 → een lijst/set van permissiecodesentitlement:org:45 → ingeschakelde planfeaturesDit is vooral nuttig als je permissiemodel veel reads heeft en relatief weinig verandert. Bij wijzigingen (rolupdates, planupgrades) kun je een kleine set sleutels updaten of invalidëren zodat de volgende request de nieuwe regels ziet.
Feature flags zijn kleine, vaak gelezen waarden die snel en consistent beschikbaar moeten zijn voor veel services.
Een veelvoorkomend patroon is opslaan:
flag:new-checkout → true/falseconfig:tax:region:EU → JSON-blob of versioned configKey-value stores werken hier goed omdat reads simpel, voorspelbaar en zeer snel zijn. Je kunt ook waarden versioneren (bijv. config:v27:...) om uitrols veiliger te maken en snelle rollback mogelijk te houden.
Rate limiting komt vaak neer op tellers per gebruiker, API-key of IP-adres. Key-value stores ondersteunen doorgaans atomische bewerkingen, waarmee je veilig kunt incrementen zelfs bij veel gelijktijdige requests.
Je zou bijhouden:
rl:user:123:minute → inc per request, expire na 60 secondenrl:ip:203.0.113.10:second → korte-window burst controlMet een TTL op elke tellersleutel resetten limieten automatisch zonder achtergrondjobs. Dit is praktisch voor het throttlen van loginpogingen, het beschermen van dure endpoints of het afdwingen van planquota.
Betalingen en andere “exact één keer doen” operaties hebben bescherming nodig tegen retries—door timeouts, clientretries of message redelivery.
Een key-value store kan idempotency-keys bewaren:
idem:pay:order_789:clientKey_abc → opgeslagen resultaat of statusBij het eerste request verwerk je en sla je de uitkomst met een TTL op. Bij latere retries geef je de opgeslagen uitkomst terug in plaats van de operatie opnieuw uit te voeren. TTL voorkomt ongebreidelde groei en dekt realistische retry-vensters.
Deze gebruiksgevallen zijn niet klassiek “caching”; het gaat om lage-latentie checks en coördinatieprimitieven die snelheid en atomariteit nodig hebben.
Een “key-value store” betekent niet altijd “string in, string uit.” Veel systemen bieden rijkere datastructuren waarmee je veelvoorkomende behoeften direct in de store kunt modelleren—vaak sneller en met minder complexiteit dan alles in applicatiecode stoppen.
Hashes (of maps) zijn ideaal als je één “ding” hebt met meerdere gerelateerde attributen. In plaats van veel sleutels zoals user:123:name, user:123:plan, user:123:last_seen kun je ze samenhouden onder user:123 met velden.
Dat vermindert key-sprawl en laat je alleen het veld ophalen of wijzigen dat je nodig hebt—handig voor profielen, feature flags of kleine configuratieblobs.
Sets zijn goed voor “is X lid van de groep?” vragen:
Sorted sets voegen ordening toe via een score, wat past voor leaderboards, “top N” lijsten en rangschikking op tijd of populariteit. Je kunt scores opslaan als view-aantallen of timestamps en snel de top-items lezen.
Concurrency-problemen duiken vaak op in kleine features: tellers, quota’s, eenmalige acties en rate limits. Als twee requests tegelijk binnenkomen en je doet “read → +1 → write”, kun je updates verliezen.
Atomische operaties lossen dit op door de wijziging als één ondeelbare stap binnen de store uit te voeren:
Met atomische increments heb je geen locks of extra coördinatie tussen servers nodig. Dat betekent minder racecondities, simpelere codepaden en voorspelbaarder gedrag onder load—vooral bij rate limiting en gebruikslimieten waar “bijna goed” snel klantzichtbare problemen wordt.
Als een key-value store serieuze traffic gaat afhandelen, betekent “sneller maken” meestal “breder maken”: reads en writes over meerdere nodes verdelen terwijl het systeem voorspelbaar blijft bij storingen.
Replicatie houdt meerdere kopieën van dezelfde data bij.
Sharding splitst de keyspace over nodes.
Veel deployments combineren beide: shards voor throughput, replicas per shard voor beschikbaarheid.
“Hoge beschikbaarheid” betekent doorgaans dat de cache/sessie-laag requests blijft bedienen zelfs als een node faalt.
Met client-side routing berekent je applicatie (of bibliotheek) welke node een sleutel heeft (gebruikelijk met consistent hashing). Dit kan erg snel zijn, maar clients moeten topology-wijzigingen leren.
Met server-side routing stuur je requests naar een proxy of cluster-endpoint dat doorschakelt naar de juiste node. Dit vereenvoudigt clients en rollouts, maar voegt een extra hop toe.
Plan geheugen van boven naar beneden:
Key-value stores voelen “instant” omdat ze hot data in geheugen houden en optimaliseren voor snelle reads/writes. Die snelheid heeft een prijs: je kiest vaak tussen performance, durability en consistentie. Het vooraf begrijpen van die trade-offs voorkomt pijnlijke verrassingen later.
Veel key-value stores kunnen in verschillende persistentiemodi draaien:
Kies de modus die past bij het doel van de data: caching tolereert verlies; sessieopslag vereist vaak meer zorg.
In gedistribueerde setups kun je eventual consistency zien—reads kunnen kortstondig een oudere waarde teruggeven na een write, vooral tijdens failover of replicatie-lag. Sterkere consistentie (bijv. acknowledgements van meerdere nodes) vermindert anomalieën maar verhoogt latentie en kan beschikbaarheid verminderen bij netwerkproblemen.
Caches raken vol. Een evictiebeleid bepaalt wat verwijderd wordt: least-recently-used, least-frequently-used, random of “niet evicten” (wat bij vol geheugen tot schrijf-fouten leidt). Bepaal of je liever missende cache-entries hebt of fouten onder druk.
Ga ervan uit dat storingen gebeuren. Typische fallback-opties:
Het bewust ontwerpen van deze gedragingen geeft gebruikers het gevoel van betrouwbaarheid.
Key-value stores zitten vaak op het “hot path” van je app. Dat maakt ze zowel gevoelig (ze kunnen sessietokens of gebruikersidentificatoren bevatten) als duur (geheugenintensief). De basis goed regelen voorkomt incidenten later.
Begin met duidelijke netwerkgrenzen: plaats de store in een private subnet/VPC-segment en laat alleen verkeer toe van applicatieservices die het echt nodig hebben.
Gebruik authenticatie als het product dat ondersteunt en volg least privilege: aparte credentials voor apps, admins en automatisering; roteer secrets; vermijd gedeelde “root”-tokens.
Versleutel data in transit (TLS) waar mogelijk—vooral als verkeer hosts of zones kruist. Versleuteling in rust hangt af van product en deployment; als het ondersteund wordt, schakel het in voor managed services en verifieer ook backup-encryptie.
Een kleine set metrics vertelt of de cache helpt of schaadt:
Voeg alerts toe voor plotselinge veranderingen, niet alleen absolute drempels, en log sleuteloperaties zorgvuldig (log geen gevoelige waarden).
De grootste kostenposten zijn:
Een praktisch kostenhevel is het verkleinen van waardes en realistische TTLs instellen, zodat de store alleen houdt wat actief nuttig is.
Begin met het standaardiseren van key naming zodat je cache- en sessiesleutels voorspelbaar, doorzoekbaar en veilig in bulk te bewerken zijn. Een eenvoudige conventie zoals app:env:feature:id (bijv. shop:prod:cart:USER123) helpt collisions voorkomen en versnelt debugging.
Definieer een TTL-strategie voordat je live gaat. Bepaal welke data snel mag verlopen (seconden/minuten), wat langere levensduur nodig heeft (uren) en wat helemaal niet gecached mag worden. Als je database-rijen cachet, stem TTLs af op hoe vaak de onderliggende data verandert.
Schrijf een invalidatieplan voor elk type gecachte items:
product:v3:123) wanneer je eenvoudig alles wilt invalidërenKies een paar succesmetrics en volg ze vanaf dag één:
Monitor ook evictiecijfers en geheugengebruik om te bevestigen dat je cache goed is geschaald.
Te grote waardes vergroten netwerktijd en geheugenbelasting—geef de voorkeur aan kleinere, voorbewerkte fragmenten. Vermijd ontbrekende TTLs (verouderde data en geheugenlekken) en onbegrensde sleutelgroei (bijv. elke zoekopdracht voor altijd cachen). Wees voorzichtig met het cachen van gebruikersspecifieke data onder gedeelde sleutels.
Als je opties evalueert, vergelijk een lokale in-process cache met een gedistribueerde cache en bepaal waar consistentie het belangrijkst is. Voor implementatiedetails en operationele richtlijnen, bekijk /docs. Als je capaciteit plant of prijsinschattingen nodig hebt, zie /pricing.
Als je een nieuw product bouwt (of een bestaand moderniseert), helpt het om caching en sessieopslag vanaf het begin als first-class zorgen te behandelen. Op Koder.ai prototypeer teams vaak een end-to-end app (React voor web, Go-services met PostgreSQL en optioneel Flutter voor mobiel) en itereren vervolgens op performance met patronen zoals cache-aside, TTLs en rate-limiting tellers. Features zoals planning mode, snapshots en rollback maken het makkelijker om cache-sleutelontwerpen en invalidatiestrategieën veilig te proberen, en je kunt de broncode exporteren wanneer je klaar bent om het in je eigen pipeline te draaien.
Key-value stores optimaliseren voor één operatie: geef een sleutel, retourneer een waarde. Die smalle focus maakt snelle paden mogelijk, zoals in-memory indexering en hashing, met veel minder overhead voor queryplanning dan algemene databases.
Ze versnellen je systeem ook indirect door herhaalde reads (populaire pagina’s, veelgevraagde API-responses) weg te halen bij de primaire database, zodat die zich kan concentreren op writes en complexe queries.
Een sleutel is een unieke identifier die je exact kunt herhalen (vaak een string zoals user:123 of sess:<token>). De waarde is wat je terug wilt krijgen—alles van een kleine teller tot een JSON-blob.
Goede sleutels zijn stabiel, gescopeerd en voorspelbaar, wat caching, sessies en lookups eenvoudig maakt om te beheren en te debuggen.
Cache resultaten die vaak gelezen worden en die veilig opnieuw gegenereerd kunnen worden als ze ontbreken.
Veelvoorkomende voorbeelden:
Vermijd het cachen van data die absoluut up-to-date moet zijn (bijv. banksaldi) tenzij je een sterke invalidatiestrategie hebt.
Cache-aside (lazy loading) is meestal de default:
key uit de cache.Het degradeert gracieus: als de cache leeg of down is, kun je nog steeds requests vanaf de database bedienen (met passende beveiligingen).
Read-through gebruik je wanneer de cache-laag automatisch moet laden bij misses (makkelijker applicatiecode, meer integratie in de cache-laag).
Write-through gebruik je wanneer elke write synchroon zowel naar cache als database moet, zodat reads doorgaans warm en consistenter zijn—ten koste van hogere write-latentie.
Kies ze wanneer je de operationele complexiteit (read-through) of de extra schrijftijd (write-through) kunt accepteren.
Een TTL laat een sleutel automatisch verlopen na een ingestelde duur. Korte TTLs verminderen veroudering maar verhogen cache misses en backend-belasting; langere TTLs verbeteren hit rate maar vergroten de kans op verouderde waarden.
Praktische tips:
Een cache stampede ontstaat wanneer een populaire sleutel verloopt en veel requests tegelijk deze opnieuw opbouwen.
Veelgebruikte mitigaties:
Deze technieken verminderen plotselinge piekbelasting op je database of externe API’s.
Sessies passen goed omdat toegang eenvoudig is: read/write op token en expiratie toepassen.
Beste praktijken:
sess:<token> (versionering zoals sess:v2:<token> helpt bij migraties).Veel sleutel-waarde-opslagen ondersteunen atomische increment-operaties, waardoor tellers veilig zijn onder concurrency.
Een typisch patroon:
rl:user:123:minute → incrementeer per requestAls de teller over de drempel gaat, throttle of weiger je de request. TTL-gebaseerde expiratie reset limieten automatisch zonder achtergrondjobs.
Belangrijke trade-offs om te plannen:
Ontwerp ook een degradeerstrategie: bereid je voor om de cache te omzeilen, licht verouderde data te serveren wanneer veilig, of gesloten te falen voor gevoelige operaties.