09 dec 2025·8 min
SQL vs NoSQL‑databases: belangrijkste verschillen en gebruiksscenario's
Leer de echte verschillen tussen SQL en NoSQL: datamodellen, schaalbaarheid, consistentie en wanneer elk type het beste werkt voor jouw applicaties.
Leer de echte verschillen tussen SQL en NoSQL: datamodellen, schaalbaarheid, consistentie en wanneer elk type het beste werkt voor jouw applicaties.
De keuze tussen SQL en NoSQL databases bepaalt hoe je je applicatie ontwerpt, bouwt en opschaalt. Het databasemodel beïnvloedt alles: datastructuren, query‑patronen, performance, betrouwbaarheid en hoe snel je team het product kan laten evolueren.
Op hoofdlijnen zijn SQL‑databases relationele systemen. Data wordt georganiseerd in tabellen met vaste schema’s, rijen en kolommen. Relaties tussen entiteiten zijn expliciet (via foreign keys) en je raadpleegt data met SQL, een krachtig declaratief taal. Deze systemen benadrukken ACID‑transacties, sterke consistentie en een goed gedefinieerde structuur.
NoSQL‑databases zijn niet‑relationele systemen. In plaats van één rigide tabelmodel bieden ze meerdere datamodellen voor verschillende behoeften, zoals:
Dat betekent dat “NoSQL” geen enkele technologie is, maar een paraplu‑term voor verschillende benaderingen, elk met eigen afwegingen op het gebied van flexibiliteit, performance en datamodellering. Veel NoSQL‑systemen versoepelen strikte consistentie ten gunste van hoge schaalbaarheid, beschikbaarheid of lage latency.
Dit artikel behandelt de verschillen tussen SQL en NoSQL: datamodellen, querytalen, performance, schaalbaarheid en consistentie (ACID versus eventual consistency). Het doel is je te helpen kiezen tussen SQL en NoSQL voor concrete projecten en te begrijpen wanneer elk type database het beste past.
Je hoeft niet per se één keuze te maken. Moderne architecturen gebruiken vaak polyglot persistence, waarbij SQL en NoSQL samen in één systeem bestaan, elk voor de workloads waarvoor ze het meest geschikt zijn.
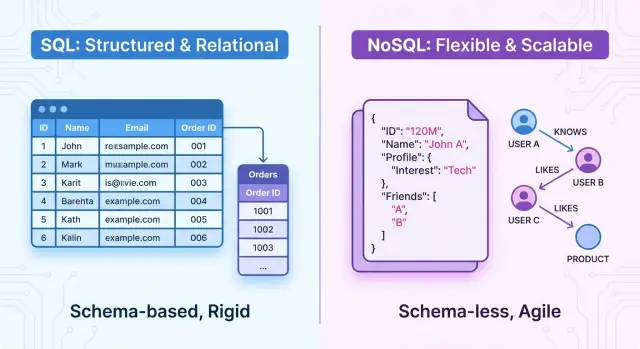
Een SQL (relationele) database slaat data op in een gestructureerde, tabulaire vorm en gebruikt Structured Query Language (SQL) om die data te definiëren, op te vragen en te manipuleren. Het is gebaseerd op het wiskundige concept van relaties—te beschouwen als goed georganiseerde tabellen.
Data is georganiseerd in tabellen. Elke tabel vertegenwoordigt één type entiteit, zoals customers, orders of products.
email of order_date.Elke tabel volgt een vast schema: een vooraf gedefinieerde structuur die specificeert
INTEGER, VARCHAR, DATE)NOT NULL, UNIQUE)Het schema wordt afgedwongen door de database, wat helpt om data consistent en voorspelbaar te houden.
Relationele databases blinken uit in het modelleren van hoe entiteiten zich tot elkaar verhouden.
customer_id).Deze keys maken het mogelijk relaties te definiëren zoals:
Relationele databases ondersteunen transacties—groepen operaties die als één geheel functioneren. Transacties worden gekenmerkt door ACID:
Deze garanties zijn cruciaal voor financiële systemen, voorraadbeheer en elke toepassing waar correctheid telt.
Populaire relationele systemen omvatten:
Ze implementeren allemaal SQL en voegen eigen extensies en tooling toe voor beheer, performance‑tuning en beveiliging.
NoSQL databases zijn niet‑relationele dataopslag die niet het traditionele tabel‑rij‑kolom‑model van SQL‑systemen hanteren. Ze focussen op flexibele datamodellen, horizontale schaalbaarheid en hoge beschikbaarheid, vaak ten koste van strikte transactionele garanties.
Veel NoSQL‑databases worden omschreven als schema‑loos of schema‑flexibel. In plaats van een rigide schema vooraf kun je records opslaan met verschillende velden of structuren in dezelfde collectie of bucket.
Dit is vooral handig voor:
Omdat velden per record toegevoegd of weggelaten kunnen worden, kunnen ontwikkelteams snel itereren zonder voor elke structurele wijziging migraties uit te voeren.
NoSQL is een verzamelterm voor meerdere modellen:
Veel NoSQL‑systemen geven prioriteit aan beschikbaarheid en partition‑tolerantie en bieden eventual consistency in plaats van strikte ACID‑transacties over de hele dataset. Sommige bieden instelbare consistentieniveaus of beperkte transactionele features (per document, partitie of sleutelbereik), zodat je kunt kiezen tussen sterkere garanties en hogere performance voor specifieke bewerkingen.
Datamodellering is waar SQL en NoSQL het meest van elkaar verschillen. Het bepaalt hoe je features ontwerpt, data opvraagt en je applicatie laat evolueren.
SQL‑databases gebruiken gestructureerde, vooraf gedefinieerde schema’s. Je ontwerpt tabellen en kolommen vooraf met strikte types en constraints:
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(100) NOT NULL
);
CREATE TABLE orders (
id INT PRIMARY KEY,
user_id INT NOT NULL,
total DECIMAL(10, 2) NOT NULL,
FOREIGN KEY (user_id) REFERENCES users(id)
);
Elke rij moet aan het schema voldoen. Wijzigingen betekenen vaak migraties (ALTER TABLE, backfilling, enz.).
NoSQL‑databases ondersteunen doorgaans flexibele schema’s. Een document store kan elk document verschillende velden toestaan:
{
"_id": 1,
"name": "Alice",
"orders": [
{ "id": 101, "total": 49.99 },
{ "id": 102, "total": 15.50 }
]
}
Velden kunnen per document toegevoegd worden zonder centrale schema‑migratie. Sommige NoSQL‑systemen gebruiken optionele of afgedwongen schema’s, maar ze zijn over het algemeen losser.
Relationele modellen stimuleren normalisatie: data opsplitsen in gerelateerde tabellen om duplicatie te vermijden en integriteit te waarborgen. Dit geeft snelle, consistente writes en efficiënter opslaggebruik, maar complexe reads vereisen joins over meerdere tabellen.
NoSQL‑modellen neigen naar denormalisatie: gerelateerde data samenvoegen op basis van de meest voorkomende reads. Dit verbetert read‑performance en vereenvoudigt queries, maar writes kunnen langzamer of complexer worden omdat dezelfde informatie meerdere keren voorkomt.
In SQL zijn relaties expliciet en afgedwongen:
In NoSQL modelleer je relaties door:
De keuze hangt af van toegangspatronen:
Met SQL vragen schemawijzigingen meer planning, maar geven ze sterke garanties en consistentie over de dataset. Refactors zijn expliciet: migraties, backfills, constraint‑updates.
Met NoSQL zijn evoluerende vereisten vaak gemakkelijker op korte termijn. Je kunt meteen nieuwe velden opslaan en oude documenten geleidelijk bijwerken. Het nadeel is dat applicatiecode meerdere documentvormen en randgevallen moet afhandelen.
De keuze tussen genormaliseerde SQL‑modellen en gedenormaliseerde NoSQL‑modellen gaat niet over beter of slechter, maar om afstemmen van datastuctuur op je querypatronen, schrijflast en hoe vaak je domeinmodel verandert.
SQL‑databases worden met een declaratieve taal bevraagd: je beschrijft wat je wilt, niet hoe het opgehaald wordt. Constructies zoals SELECT, WHERE, JOIN, GROUP BY en ORDER BY stellen je in staat complexe vragen over meerdere tabellen in één statement te uiten.
Omdat SQL gestandaardiseerd is (ANSI/ISO) delen veel relationele systemen een gemeenschappelijke kernsyntax. Vendors voegen eigen uitbreidingen toe, maar vaardigheden en queries zijn vaak goed overdraagbaar tussen PostgreSQL, MySQL, SQL Server en anderen.
Deze standaardisatie brengt een rijk ecosysteem: ORMs, query builders, reporting tools, BI‑dashboards, migratieframeworks en query‑optimizers. Je kunt veel van deze tools op vrijwel elke SQL‑database aansluiten met minimale aanpassingen, wat vendor‑lock‑in vermindert en ontwikkeling versnelt.
NoSQL‑systemen bieden meer gevarieerde manieren om queries uit te voeren:
Sommige NoSQL‑databases bieden aggregatiepijplijnen of MapReduce‑achtige mechanismen voor analytics, maar cross‑collectie of cross‑partition joins zijn vaak beperkt of afwezig. In plaats daarvan worden gerelateerde gegevens vaak embedded of gedenormaliseerd.
Relationele queries gebruiken vaak JOIN‑zware patronen: normaliseer data en reconstructeer entiteiten bij het lezen met joins. Dit is krachtig voor ad‑hoc rapportage en evoluerende vragen, maar complexe joins kunnen moeilijker te optimaliseren en te begrijpen zijn.
NoSQL‑toegangspatronen zijn eerder document‑ of key‑gericht: ontwerp data rond de meest voorkomende queries van de applicatie. Reads zijn snel en simpel—vaak één sleutel‑lookup—maar veranderende toegangspatronen later kunnen data‑herontwerp vereisen.
Voor leren en productiviteit:
Teams die rijke, ad‑hoc queries over relaties nodig hebben, geven meestal de voorkeur aan SQL. Teams met stabiele, voorspelbare toegangspatronen op zeer grote schaal vinden NoSQL‑modellen vaak beter passend.
De meeste SQL‑databases zijn ontworpen rond ACID‑transacties:
Dit maakt SQL‑databases geschikt wanneer correctheid belangrijker is dan ruwe schrijfsnelheid.
Veel NoSQL‑databases neigen naar BASE eigenschappen:
Writes kunnen zeer snel en verspreid zijn, maar een read kan kortstondig verouderde data tonen.
CAP stelt dat een gedistribueerd systeem bij netwerkpartitionering moet kiezen tussen:
Je kunt tijdens een partitionering niet zowel C als A garanderen.
Typische patronen:
Moderne systemen mixen vaak modi (bijv. tunable consistency per operatie) zodat verschillende onderdelen van een applicatie de garanties kunnen kiezen die ze nodig hebben.
Traditionele SQL‑databases zijn ontworpen voor één krachtige node.
Je begint doorgaans met verticale schaalvergroting: meer CPU, RAM en snellere schijven toevoegen aan één server. Veel engines ondersteunen ook read replicas: extra nodes die read‑only verkeer afhandelen terwijl alle writes naar de primaire gaan. Dit patroon werkt goed voor:
Echter bereikt verticale schaal uiteindelijk hardware‑ en kostengrenzen, en read replicas kunnen replicatie‑lag introduceren.
NoSQL‑systemen zijn meestal gebouwd voor horizontale schaal: data over veel knooppunten verdelen met sharding of partitionering. Elke shard houdt een subset van de data, waardoor zowel reads als writes verdeeld kunnen worden en de doorvoer toeneemt.
Dit is geschikt voor:
De trade‑off is hogere operationele complexiteit: kiezen van shard keys, rebalancing en omgaan met cross‑shard queries.
Voor read‑zware workloads met complexe joins en aggregaties kan een SQL‑database met goed ontworpen indexen extreem snel zijn, omdat de optimizer statistieken en queryplannen gebruikt.
Veel NoSQL‑systemen geven de voorkeur aan eenvoudige key‑gebaseerde toegangspatronen. Ze excelleren in lage latency lookups en hoge throughput wanneer queries voorspelbaar zijn en data rond die toegangspatronen is gemodelleerd.
Latency in NoSQL‑clusters kan erg laag zijn, maar cross‑partition queries, secundaire indexen en multi‑document operaties kunnen trager of beperkter zijn. Operationeel betekent schalen met NoSQL vaak meer clusterbeheer, terwijl schalen met SQL vaak meer hardware en zorgvuldige indexering op minder nodes vereist.
Relationele databases blinken uit wanneer je betrouwbare, hoge‑volumige OLTP (online transaction processing) nodig hebt:
Deze systemen vertrouwen op ACID‑transacties, strikte consistentie en duidelijke rollback‑gedragingen. Als een overboeking nooit dubbel mag afschrijven of geld mag verliezen tussen twee rekeningen, is een SQL‑database meestal veiliger dan de meeste NoSQL‑opties.
Wanneer je datamodel goed begrepen en stabiel is, en entiteiten sterk onderling verbonden zijn, is een relationele database vaak de natuurlijke keuze. Voorbeelden:
SQL’s genormaliseerde schema’s, foreign keys en joins maken het eenvoudiger integriteit af te dwingen en complexe relaties te query’en zonder duplicatie.
Voor rapportage en BI over duidelijk gestructureerde data (star/snowflake schema’s, data marts) zijn SQL‑databases en SQL‑compatibele datawarehouses meestal de voorkeur. Analisten kennen SQL en bestaande tools integreren direct met relationele systemen.
Debatten over relationele versus niet‑relationele databases vergeten soms operationele rijpheid. SQL biedt:
Als audits, certificeringen of juridisch risico groot zijn, is een SQL‑database vaak de meer voor de hand liggende en verdedigbare keuze.
NoSQL‑databases zijn vaak beter als schaal, flexibiliteit en altijd‑aan‑toegang belangrijker zijn dan complexe joins en strikte transactionele garanties.
Als je enorme write‑volumes, onvoorspelbare verkeerspieken of datasets verwacht die in terabytes groeien, zijn NoSQL‑systemen (key‑value of wide‑column) vaak gemakkelijker horizontaal te schalen. Sharding en replicatie zijn meestal ingebouwd, waardoor je capaciteit toevoegt door knooppunten toe te voegen.
Dit komt vaak voor bij:
Als je datamodel vaak verandert, is een flexibel of schema‑loos ontwerp waardevol. Documentdatabases laten je velden en structuren evolueren zonder migraties voor elke wijziging.
Dit werkt goed voor:
NoSQL‑stores zijn sterk voor append‑heavy en tijdgeordende workloads:
Key‑value en time‑series databases zijn specifiek afgestemd op zeer snelle writes en simpele reads.
Veel NoSQL‑platforms richten zich op geo‑replicatie en multi‑region writes, waardoor gebruikers wereldwijd lokaal kunnen lezen en schrijven met lage latency. Dit is nuttig wanneer:
Trade‑off is vaak acceptatie van eventual consistency in plaats van strikte ACID‑semantiek over regio’s.
Kiezen voor NoSQL betekent vaak het opgeven van sommige features die je in SQL vanzelfsprekend vindt:
Wanneer deze afwegingen acceptabel zijn, kan NoSQL betere schaalbaarheid, flexibiliteit en mondiale bereikbaarheid bieden dan traditionele relationele databases.
Polyglot persistence betekent bewust meerdere databasetechnologieën in hetzelfde systeem gebruiken, elk voor de taak waarvoor het het beste geschikt is.
Een vaak gebruikt patroon:
Dit houdt het “systeem van record” in relationele opslag, terwijl vluchtige of read‑zware workloads naar NoSQL verschoven worden.
Je kunt ook meerdere NoSQL‑systemen combineren:
Doel is elk datastore af te stemmen op een specifiek toegangspatroon: lookups, aggregaten, zoeken of tijdsgebaseerde reads.
Hybride architecturen vertrouwen op integratiepunten:
De trade‑off is operationele overhead: meer technologieën om te leren, monitoren, beveiligen, back‑uppen en troubleshooten. Polyglot persistence werkt het best wanneer elke extra datastore duidelijk een meetbaar probleem oplost—niet alleen omdat het modern klinkt.
Kiezen tussen SQL en NoSQL is afstemmen van je data‑ en toegangspatronen op het juiste gereedschap, niet het volgen van een hype.
Vraag jezelf:
Als ja, is een relationele SQL‑database meestal de standaardkeuze. Als je data document‑achtig, genest of sterk variabel is, kan een document‑ of ander NoSQL‑model beter passen.
Strikte consistentie en complexe transacties pleiten voor SQL. Hoge schrijfsnelheid met versoepelde consistentie kan NoSQL gunstiger maken.
Veel projecten schalen ver met SQL door goede indexering en hardware. Als je echter zeer grote schaal met eenvoudige toegangspatronen verwacht (key‑value lookups, time‑series, logs), kunnen bepaalde NoSQL‑systemen economischer zijn.
SQL is sterk in complexe queries, BI‑tools en ad‑hoc exploratie. Veel NoSQL‑databases zijn geoptimaliseerd voor vooraf gedefinieerde toegangspaden en maken nieuwe querytypes lastiger.
Geef de voorkeur aan technologieën die je team betrouwbaar kan opereren, vooral voor productieprobleemoplossing en migraties.
Een enkele managed SQL‑database is vaak goedkoper en eenvoudiger totdat je duidelijk een grens bereikt.
Voor je vastlegt:
Gebruik die metingen—niet aannames—om te kiezen. Voor veel projecten is starten met SQL de veiligste route, met de optie NoSQL‑componenten later toe te voegen voor specifieke, zeer schaalbare of gespecialiseerde use cases.
NoSQL is niet gekomen om relationele databases te verdringen; het komt om ze aan te vullen.
Relationele databases domineren nog steeds systemen van record: finance, HR, ERP, voorraad en workflows waar strikte consistentie en rijke transacties nodig zijn. NoSQL blinkt uit waar flexibele schema’s, enorme schrijflast of wereldwijd verdeelde reads belangrijker zijn dan complexe joins en strikte ACID‑garanties.
De meeste organisaties gebruiken uiteindelijk beide en kiezen het juiste gereedschap per workload.
Relationele databases hebben traditioneel opgeschaald door sterkere servers, maar moderne engines ondersteunen:
Horizontaal schalen met relationele systemen kan complexer zijn dan bij sommige NoSQL‑clusters, maar is zeker mogelijk met het juiste ontwerp en tooling.
"Schema‑loos" betekent eigenlijk dat het schema door de applicatie wordt afgedwongen in plaats van door de database.
Document, key–value en wide‑column stores hebben nog steeds structuur; ze laten gewoon toe dat die structuur per record evolueert. Zonder duidelijke datacontracten en validatie leidt dit snel tot inconsistente data.
Performance hangt veel meer af van datamodellering, indexering en toegangspatronen dan van de categorie “SQL vs NoSQL”.
Een slecht geïndexeerde NoSQL‑collectie is langzamer dan een goed getunede relationele tabel voor veel queries. En een relationeel schema dat querypatronen negeert zal achterblijven bij een NoSQL‑model dat rond die queries is ontworpen.
Veel NoSQL‑databases ondersteunen sterke durability, encryptie, auditing en toegangscontrole. Omgekeerd kan een verkeerd geconfigureerde relationele database onveilig en fragiel zijn.
Beveiliging en betrouwbaarheid zijn eigenschappen van het specifieke product, de deployment, configuratie en operationele volwassenheid—niet van “SQL” of “NoSQL” als categorieën.
Teams stappen meestal tussen SQL en NoSQL vanwege schaal en flexibiliteit. Een druk product behoudt vaak een relationele database als betrouwbaar systeem van record en introduceert NoSQL om reads op te schalen of nieuwe features met flexibele schema’s te ondersteunen.
Een big‑bang migratie van SQL naar NoSQL (of andersom) is risicovol. Veiliger opties zijn:
Bij migreren van SQL naar NoSQL proberen teams vaak tabellen één‑op‑één in documenten of key‑value paren te spiegelen. Dat leidt vaak tot:
Plan eerst nieuwe toegangspatronen en ontwerp dan het NoSQL‑schema rond de daadwerkelijke queries.
Een gangbaar patroon is SQL voor autoritatieve data (billing, user accounts) en NoSQL voor read‑zware views (feeds, search, caching). Investeer in:
Zo blijven SQL vs NoSQL migraties gecontroleerd in plaats van pijnlijke, onomkeerbare stappen.
SQL en NoSQL verschillen voornamelijk op vier punten:
Geen enkele categorie is universeel beter. De juiste keuze hangt af van je werkelijke vereisten, niet van trends.
Schrijf je behoeften op:
Stel slimme defaults in:
Begin klein en meet:
Blijf open voor hybriden:
/docs/architecture/datastores).Voor diepere studies, breid dit overzicht uit met interne standaarden, migratiechecklists en verdere leestips in je engineering‑handboek of /blog.
SQL (relationele) databases:
NoSQL (niet‑relationele) databases:
Gebruik een SQL‑database wanneer:
Voor de meeste nieuwe business‑systemen van record is SQL een verstandige standaardkeuze.
NoSQL past het beste wanneer:
SQL databases:
NoSQL databases:
SQL databases:
Veel NoSQL systemen:
Kies SQL wanneer verouderde reads gevaarlijk zijn; kies NoSQL wanneer korte termijn stale reads acceptabel zijn in ruil voor schaal en uptime.
SQL databases doorgaans:
NoSQL databases doorgaans:
Ja. Polyglot persistence is gebruikelijk:
Integratiepatronen omvatten:
Belangrijk is dat je elke extra datastore alleen toevoegt als die een duidelijk probleem oplost.
Om geleidelijk en veilig te migreren:
Vermijd big‑bang migraties; geef de voorkeur aan gecontroleerde, goed‑gemonitorde stappen.
Overweeg:
Veelvoorkomende misvattingen zijn:
Evalueer concrete producten en architecturen in plaats van op categorie‑niveau te vertrouwen.
Dit betekent dat schema‑controle bij SQL in de database zit, terwijl bij NoSQL de applicatie vaker de controle voert.
Het nadeel is dat NoSQL‑clusters operationeel complexer zijn, terwijl SQL sneller tegen grenzen op een enkele node aan kan lopen.
Prototypeer beide opties voor kritieke flows en meet latency, throughput en complexiteit voordat je beslist.