Wat deze webapp moet oplossen
Deze webapp bestaat om één praktische vraag te beantwoorden: “Hebben we genoeg supportcapaciteit voor de binnenkomende vraag?” Als het antwoord “niet zeker” is, ontstaan knelpunten, gestreste agents en inconsistente serviceniveaus.
Definieer “supportwerkdruk” voor je team
“Supportwerkdruk” is geen enkele waarde. Het is de combinatie van binnenkomend werk, werk in wachtrij en de inspanning die nodig is om het op te lossen. Voor de meeste teams omvat dat:
- Binnenkomend volume: tickets, live chats, gesprekken, e-mails (de kanalen die jullie gebruiken)
- Backlog: open items, verouderende items en items die targets overschrijden
- Werkcomplexiteit: snelle vragen vs. meerstapscases (vaak zichtbaar in handle time, tags of categorieën)
- Onderbrekingen: escalaties, heropeningen, overdrachten en “wachten-op-klant”-cycli
De app moet je laten kiezen wat als werkdruk telt, en het vervolgens consistent berekenen—zodat plannen van meningen naar gedeelde cijfers gaat.
Het gewenste resultaat
Een goede eerste versie helpt je:
- Zien waar en wanneer wachtrijen opbouwen (en waarom)
- Dagelijkse vraag omzetten naar een duidelijk personeelsplan (vandaag, volgende week, volgende maand)
- Serviceniveaus beschermen (reactietijd, oplostijd, SLA-naleving) zonder te gokken
Je probeert de toekomst niet perfect te voorspellen. Je probeert verrassingen te verminderen en afwegingen expliciet te maken.
Wie gebruikt het—en wat vragen ze elke dag
Deze app is vooral voor supportleads, support-operations en managers. Typische dagelijkse vragen zijn:
- “Houden we het nu bij, of lopen we achter?”
- “Als het volume stijgt, hoeveel extra mensen hebben we nodig—en voor hoe lang?”
- “Groeie de backlog door vraag, complexiteit of capaciteit?”
- “Welk kanaal of welke wachtrij is de echte bottleneck?”
Stel verwachtingen: begin simpel, verbeter later
Begin met een klein aantal metrics en een basis schatting van staffing. Zodra mensen de cijfers vertrouwen, verfijn je met betere segmentatie (wachtrij, regio, tier), nauwkeurigere handle times en betere forecasting in de loop van de tijd.
Vereisten: Doelen, Gebruikers en Succesmetrics
Voordat je grafieken kiest of integraties bouwt, definieer waar de app voor is—en waar niet. Duidelijke vereisten houden de eerste versie klein, nuttig en makkelijk te adopteren.
Kies een klein aantal doelen
Begin met 2–4 doelen die direct aansluiten op dagelijkse supportplanning. Goede vroege doelen zijn specifiek en meetbaar, bijvoorbeeld:
- Voorspel het ticketvolume voor volgende week per dag (optioneel per uur)
- Spot onderbezettingstijden waar backlog sneller groeit dan capaciteit
- Maak backlog vs. capaciteit zichtbaar op één plek voor vandaag en morgen
- Volg of personeelswijzigingen breaches of escalaties verminderden
Als een doel niet binnen een week of twee kan worden uitgevoerd, is het waarschijnlijk te breed voor v1.
Definieer gebruikers met 5–10 user stories
Som op wie de app opent en wat ze proberen te doen. Houd stories kort en concreet:
- “Als supportlead wil ik in één oogopslag de backlog vs. capaciteit van vandaag zien zodat ik kan beslissen of ik mensen herschik.”
- “Als teammanager wil ik volume-trends week-op-week vergelijken zodat ik het rooster voor volgende week kan plannen.”
- “Als agent wil ik weten wanneer we in ‘all-hands’-modus zijn zodat ik niet-spoedwerk kan pauzeren.”
- “Als operations wil ik een wekelijkse staffing-samenvatting exporteren om in planning te delen.”
Deze lijst wordt je build-checklist: ondersteunt een scherm of metric geen story, dan is het optioneel.
Definieer de beslissingen die de app moet ondersteunen
Vereisten moeten beslissingen beschrijven, niet alleen data. Voor staffing en load tracking moet de app beslissingen ondersteunen zoals:
- Een dienst toevoegen, dekking verlengen, of iemand uit een andere wachtrij halen
- Tickets herschikken (of routing aanpassen) om wachttijd te verminderen
- Projecten/training tijdelijk pauzeren tijdens pieken
- Overuren goedkeuren of on-call swaps toestaan
Als je de beslissing niet kunt benoemen, kun je niet evalueren of een feature helpt.
Stel succescriteria vast
Maak afspraken over een paar uitkomsten en hoe je ze meet:
- Time-to-report: bijv. “dagelijkse staffing view laadt onder 10 seconden”
- Adoptie: wekelijkse actieve gebruikers onder leads/managers; herhaald gebruik
- Operationele impact: minder escalaties, minder SLA-breaches, kortere time-to-first-response
- Planningsvertrouwen: minder last-minute roosterwijzigingen, minder verrassende backlogpieken
Schrijf deze in het projectdocument (en herzie na lancering) zodat de app beoordeeld wordt op bruikbaarheid—niet op hoeveel grafieken het heeft.
Databronnen en de Minimale Data die je Nodig Hebt
Een staffing- en workload-app is alleen zo nuttig als de data die hij betrouwbaar kan ophalen. Het doel voor een vroege versie is niet “alle data,” maar genoeg consistente data om load uit te leggen, capaciteit te meten en risico te signaleren.
Kernbronnen om op te plannen
Begin met systemen die werk, tijd en beschikbare mensen representeren:
- Helpdesk (tickets): aantallen, statussen, prioriteiten, toewijzing, tijdstempels
- Chattool: inkomende chats, afgehandelde chats, wachttijd, bezetting per wachtrij (indien beschikbaar)
- Telefoniesysteem: callvolume, beantwoord vs. gemist, gemiddelde handle time
- Roosters/WFM of agenda's: shifts, PTO, on-call rotaties, tijdzone-dekking
- HR/headcount: teamlidmaatschap, start/eind-datum, roltype (agent/lead), contractuele uren
Je hoeft op dag één niet van elk kanaal perfecte details te hebben. Als telefoon- of chatdata rommelig is, begin met tickets en voeg de rest toe zodra de pipeline stabiel is.
API-integratie vs. CSV-imports (v1-keuze)
- API-integraties zijn het beste wanneer je frequente refreshes, automatisering en consistente schema's nodig hebt. Ze kosten meer tijd om te bouwen, maar verminderen handmatig werk.
- CSV-imports zijn vaak de snelste eerste stap (wekelijks of dagelijks uploads), vooral voor roosters of HR. Maak de importtemplate strikt en versioneer hem zodat hij niet wegdrijft.
Een praktische aanpak is hybride: API voor de helpdesk (hoog volume, tijdgevoelig) en CSV voor roosters/headcount tot je klaar bent om te integreren.
Refresh-cadans: realtime is niet altijd nodig
Kies cadans op basis van de beslissingen die je ondersteunt:
- Realtime / near realtime: live wachtrijmonitoring, “we lopen achter”-alerts
- Uurlijkse updates: intradag staffing-aanpassingen en trendzichtbaarheid
- Dagelijks: wekelijkse planning, aanwervingsrechtvaardiging, executive reporting
Minimale dimensies om vast te leggen
Om metrics actiegericht te maken, sla deze dimensies op over bronnen heen:
Kanaal (ticket/chat/telefoon), team, prioriteit, tijdzone, taal, en klanttier.
Zelfs als sommige velden in het begin ontbreken, ontwerp het schema om ze later op te nemen zodat je niet opnieuw hoeft te bouwen.
Support-metrics om te volgen (zonder het te ingewikkeld te maken)
De snelste manier om een support-trackingapp te laten ontsporen is alles bijhouden. Begin met een klein aantal metrics die uitleggen (1) hoeveel werk er binnenkomt, (2) hoeveel er wacht, en (3) hoe snel je reageert en oplost.
De kernmetrics (begin hier)
Focus op vier metrics die de meeste teams vroeg kunnen vertrouwen:
- Binnenkomend volume: nieuwe tickets per dag/week, bij voorkeur uitgesplitst naar kanaal en prioriteit.
- Backlog: open tickets op een moment, plus backlogleeftijd (hoeveel ouder dan X uren/dagen).
- First response time (FRT): tijd van creatie tot eerste menselijke reactie. Volg mediaan en 90e percentiel.
- Resolution time: tijd van creatie tot opgelost/gesloten (mediaan en 90e percentiel).
Deze vier cijfers beantwoorden vaak al: “Houden we het bij?” en “Waar ontstaan vertragingen?”
Productiviteitsmetrics (voeg voorzichtig toe)
Productiviteitsmetrics zijn nuttig, maar alleen als iedereen het eens is over de definitie.
Twee veelvoorkomende opties:
- Afgehandeld per agent: tickets opgelost per agent per dag/week. Definieer of “afgehandeld” betekent opgelost, geantwoord of aangeraakt.
- Occupancy: percentage van iemands tijd besteed aan ticketwerk. Als je tijd-op-taak niet betrouwbaar kunt meten, houd occupancy uit v1.
Wees voorzichtig met vergelijkingen tussen agents; routingregels, complexiteit en shifttijden kunnen vertekenen.
SLA-doelen en breaches
Als je SLA's volgt, houd het simpel:
- Definieer SLA-doelen per prioriteit en kanaal (bijv. P1 chat: FRT < 5 minuten; P3 e-mail: FRT < 8 uur).
- Tel breaches apart voor FRT en resolutie.
- Sla op of SLA-timers pauzeren buiten kantooruren (en wat “kantooruren” betekent).
Maak definities expliciet met een glossarium
Voeg een eenvoudige in-app glossariumpagina toe (bijv. /glossary) die elke metric definieert, de formule en randgevallen (samengevoegde tickets, heropeningen, interne notities). Consistente definities voorkomen discussies later—en maken dashboards geloofwaardig.
Dashboardontwerp: Schermen, Filters en Visuals
Prototypeer je staffing-dashboard
Bouw een overzicht, drill-down en planner vanuit chat en verbeter het met je team.
Een goed supportdashboard beantwoordt een handvol terugkerende vragen in seconden: “Verandert volume?”, “Houden we het bij?”, “Waar is het risico?”, en “Hoeveel mensen hebben we volgende week nodig?” Ontwerp de UI rond die vragen, niet rond elke berekening die je kunt maken.
De drie kernschermen
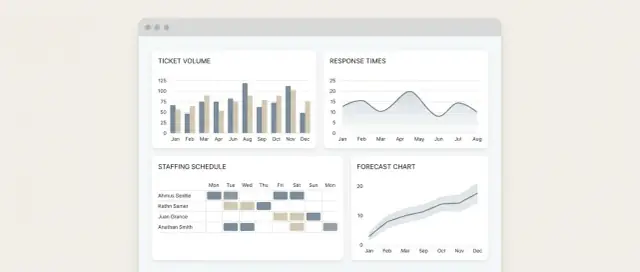
1) Overzichtsdashboard (command center)
Dit is de standaard landingview voor dagelijkse checks. Het toont vandaag/deze week in één oogopslag: inkomende tickets, opgeloste tickets, huidige backlog en of de vraag de capaciteit voorbijloopt.
2) Team drill-down (diagnose waar werk zich ophoopt)
Laat een lead doorklikken naar één team (of wachtrij) om te zien wat de load veroorzaakt: kanaalmix, prioriteitsmix en de grootste bijdragers aan backloggroei.
3) Staffing planner (zet metrics om in een personeelsgetal)
Deze view vertaalt vraag naar benodigde capaciteit: voorspeld volume, verwachte handle time-aannames, beschikbare agenturen en een eenvoudige “gap/surplus”-uitkomst.
Eén primaire grafiek per vraag
Houd elke grafiek gekoppeld aan één beslissing:
- Volume trend: eenvoudige lijngrafiek van inkomende tickets per dag/week.
- Backlog: lijn- of gebiedsgrafiek van open tickets over tijd (plus een label “start vs. eind backlog”).
- Capaciteit vs. vraag: twee lijnen (of balken) die tickets (of uren) nodig vs. tickets (of uren) beschikbaar tonen.
Ondersteunende metrics kunnen als kleine kaarten ernaast staan (bijv. “% binnen SLA”, “mediaan first response”), maar vermijd dat elk kaartje een grafiek wordt.
Filters die mensen echt gebruiken
Standaardfilters moeten de meeste workflows dekken:
- Datumrange (met snelkeuzes zoals “Laatste 7 dagen”, “Deze maand”)
- Team/wachtrij
- Kanaal
- Prioriteit (en eventueel “klanttier”)
Maak filters sticky over schermen heen zodat gebruikers ze niet steeds opnieuw hoeven te kiezen.
Ontwerp voor snelle scanning
Gebruik platte labels (“Open tickets”, “Opgelost”) en consistente eenheden. Voeg statuskleuren toe voor drempels (groen/op schema, oranje/opletten, rood/risico). Gebruik sparklines in metriekkaarjes om richting te tonen zonder rommel. Waar mogelijk, toon “wat veranderde” (bijv. “Backlog +38 sinds maandag”) zodat de volgende actie duidelijk is.
Vraag- en capaciteitsmodel voor personeelsbehoefte
Dit is de “calculator” in het midden van je app: hoeveel supportaanvragen komen waarschijnlijk binnen (vraag), hoeveel werk kan je team realistisch aan (capaciteit), en waar zitten de gaten.
Stap 1: Model de vraag (incoming work)
Begin eenvoudig en uitlegbaar. Voor een vroege versie is een moving average vaak voldoende:
- Forecast tickets/chats per uur en dag van de week met de laatste 2–8 weken.
- Houd afzonderlijke curves per kanaal als ze zich anders gedragen (e-mail vs. chat).
- Laat gebruikers het lookback-venster kiezen (bijv. “gebruik laatste 4 weken”), omdat seizoensinvloeden en recente lanceringen kunnen vertekenen.
Als je niet genoeg historie hebt, val terug op “zelfde uur gisteren” of “zelfde dag vorige week” en label de forecast als lage betrouwbaarheid.
Stap 2: Model de capaciteit (beschikbare productieve uren)
Capaciteit is niet “headcount × 8 uur.” Het is geplande tijd aangepast voor hoeveel werk een agent per uur afhandelt.
Een praktische formule:
Capaciteit (tickets/uur) = Geplande agents × Productieve uren/agent × Productiviteitsratio
Waar:
- Productieve uren/agent geplande tijd minus shrinkage.
- Productiviteitsratio kan “tickets opgelost per productieve uur” zijn (of chats per uur). Begin met één getal per kanaal en verfijn later.
Shrinkage is tijd waarop mensen betaald krijgen maar niet beschikbaar zijn: pauzes, verlof, training, teammeetings, 1:1s. Behandel dit als aanpasbare percentages (of vaste minuten per shift) zodat operations het kunnen finetunen zonder codewijziging.
Stap 4: Output personeelsgaten waar mensen op kunnen handelen
Zet vraag vs. capaciteit om in duidelijke adviezen:
- “+2 agents nodig van 14:00–18:00” (of “overbezet met 1”).
- Voeg een betrouwbaarheidsopmerking toe zoals “medium confidence: gebaseerd op 4-week moving average; feestweek uitgesloten.”
Dit houdt het model nuttig voordat je meer geavanceerde forecasting toevoegt.
Forecastmethoden die werken voor vroege versies
Plan de app in chat
Gebruik Planning Mode om user stories, schermen en datamodel te maken voordat je code schrijft.
Vroege forecasts hoeven geen geavanceerde machine learning te gebruiken om nuttig te zijn. Het doel is een “goed genoeg” schatting te produceren die leads helpt shifts te plannen en aankomende druk te signaleren—en toch makkelijk uit te leggen en te onderhouden.
Begin simpel: rollende gemiddelden
Een sterk uitgangspunt is een rollend gemiddelde van inkomende tickets (of chats) over de laatste N dagen. Het dempt ruis en geeft een snelle indicatie van de trend.
Als volume volatiel is, probeer twee lijnen naast elkaar:
- 7-daags rollend gemiddelde (reageert snel)
- 28-daags rollend gemiddelde (stabieler)
Voeg lichte seizoenspatronen toe (weekdag/uur)
Supportwerk heeft meestal patronen: maandagen verschillen van vrijdagen, ochtenden van avonden. Zonder ingewikkeld te worden, bereken gemiddelden per:
- Weekdag (ma–zo)
- Optioneel: uurblokken (bijv. 2-uurs buckets)
Forecast volgende week door het “typische maandag”-profiel, “typische dinsdag”-profiel, enz. toe te passen. Dat presteert vaak beter dan een simpel rollend gemiddelde.
Omgaan met pieken via eventmarkers
In de praktijk ontstaan uitschieters: productlanceringen, factureringswijzigingen, storingen, feestdagen. Laat die geen permanente vertekening van je baseline veroorzaken.
Voeg handmatige eventmarkers toe (daterange + label + notities). Gebruik ze om:
- Extreme dagen uit baseline-berekeningen te sluiten, of
- “Event-dagen” te vergelijken met normale dagen voor toekomstige planning
Valideer wekelijks en volg error
Vergelijk elke week forecast vs. actual en log een errormetriek. Houd het simpel:
- MAPE (mean absolute percentage error), of
- Gemiddelde % fout (met teken: over/onder)
Trend de error over tijd zodat je ziet of het model verbetert of afwijkt.
Maak de schatting uitlegbaar
Toon nooit “Vereist personeel: 12” zonder context. Laat de inputs en de methode naast het getal zien:
- Verwacht ticketvolume (en bron)
- Aangenomen productiviteit (tickets/uur)
- Coverage factor (meetings, pauzes, backlog)
- Welke baseline is gebruikt (7-daags, weekdagpatroon, etc.)
Transparantie bouwt vertrouwen en maakt het makkelijker om verkeerde aannames snel te corrigeren.
Gebruikersrollen, permissies en operationele workflow
Begin met de juiste stack
Genereer een React UI met een Go API en PostgreSQL-schema voor supportmetrics.
Een staffing-app werkt alleen als mensen de cijfers vertrouwen en weten wat ze mogen aanpassen. Begin met een klein aantal rollen, duidelijke edit-rechten en een goedkeuringsflow voor alles wat staffingbeslissingen beïnvloedt.
Kernrollen (en wat ze mogen doen)
Admin
Admins configureren het systeem: verbinden van datasources, mappen van ticketvelden, teams beheren en globale defaults instellen (bijv. kantooruren, tijdzones). Zij beheren ook gebruikersaccounts en permissies.
Manager
Managers zien geaggregeerde prestaties en planningsviews: ticketvolumetrends, backlogrisico, capaciteit vs. vraag en aankomende dekking. Ze kunnen wijzigingen in aannames en targets voorstellen of goedkeuren.
Agent
Agents richten zich op uitvoering: persoonlijke wachtrijmetrics, teamniveau werkdruk en relevante rooster/shiftdetails. Beperk toegang voor agents zodat de tool geen performance-leaderboard wordt.
Wat in-app bewerkbaar moet zijn (en wat niet)
Sta bewerkingen toe die planningsinput zijn, niet ruwe ticketgeschiedenis. Voorbeelden:
- Staffingdoelen (bijv. “antwoord binnen 4 uur”)
- Roosters en geplande dekking (shifts, verlof, trainingsblokken)
- Aannames (handle time, shrinkage, kanaalmix, forecastoverrides)
Vermijd het handmatig aanpassen van geïmporteerde feiten zoals ticketcounts of tijdstempels. Als er iets mis is, los het op bij de bron of via mappingregels.
Auditgeschiedenis en goedkeuringen
Elke wijziging die forecasts of dekking beïnvloedt, moet een audit-entry maken:
- Wie veranderde het, wat veranderde en wanneer
- Optionele notitie (“feestweek-aanpassing”, “nieuwe productlancering”)
- Versiebeheer van aannames en roosters (zodat je oude plannen met uitkomsten kunt vergelijken)
Een eenvoudige workflow werkt goed: Manager stelt op → Admin keurt goed (of Manager keurt voor kleinere teams).
Toegangscontrole voor gevoelige data
Bescherm twee categorieën:
- Individuele agentprestaties (handle time per persoon, reopen-rates)
- Klantgegevens (namen, e-mails, berichtinhoud)
Stel standaard least privilege in: agents zien geen individuele metrics van anderen; managers zien aggregaten; alleen admins kunnen klantniveau-drilldowns openen wanneer nodig. Voeg “gemaskeerde weergaven” toe zodat plannen kan plaatsvinden zonder persoonlijke of klantdata bloot te geven.
Architectuur en techstack (eenvoudig, onderhoudbaar)
Een goede eerste versie heeft geen ingewikkelde stack nodig. Hij moet voorspelbare data, snelle dashboards en een structuur hebben die niet in de weg zit als je later nieuwe supporttools toevoegt.
Een eenvoudige, bewezen vorm
Begin met vier bouwblokken:
- Web UI: waar managers het ticketvolumedashboard en staffing-forecast bekijken.
- API: één backend die dashboardqueries bedient en ingebrachte metrics accepteert.
- Database: slaat ruwe events (tickets, statusveranderingen) en geaggregeerde metrics op.
- Gereguleerde jobs: halen data op, berekenen dagelijkse/uurlijke samenvattingen en verversen caches.
Deze opzet maakt het makkelijker om storingen te diagnosticeren (“ingest kapot” vs. “dashboards traag”) en houdt deploys overzichtelijk.
Opslag: time-series zonder speciale DB (nog)
Voor vroege helpdesk-analytics werken relationele tabellen goed, ook voor time-series metrics. Een veelgebruikte aanpak:
tickets_raw (één rij per ticket of statusevent)metrics_hourly (één rij per uur per queue/kanaal)metrics_daily (dagelijkse rollups voor snelle rapportage)
Voeg indexes toe op tijd, queue en kanaal. Als de data groeit, kun je partitioneren per maand of aggregaten naar een dedicated time-series store verplaatsen—zonder de hele app te herschrijven.
Datapijplijnen: ingest → normalize → aggregate → cache
Ontwerp je pipeline als expliciete fasen:
- Ingest van je helpdesktools via API/webhooks.
- Normalize velden naar een consistent schema (queues, prioriteiten, kantooruren).
- Aggregate in metrics die nodig zijn voor wachtrijbeheer en de staffing-calculator.
- Cache dashboard-klare resultaten (materialized views of een simpele cache) zodat filters snel laden.
Schoon afgescheiden integratiepunten
Behandel elk extern systeem als een connectormodule. Houd toolspecifieke eigenaardigheden binnen die connector en bied een stabiel intern formaat aan de rest van de app. Zo voegt het toevoegen van een tweede inbox, chattool of telefoniesysteem later geen complexiteit toe aan je support operations webapp.
Als je een referentiestructuur wilt, link je “Connectors” en “Data Model” pagina’s vanaf /docs zodat niet-engineers begrijpen wat inbegrepen is en wat niet.
Versnel de eerste build met Koder.ai (optioneel)
Als je doel is om snel een werkende v1 voor supportleads te krijgen, kan een vibe-coding platform zoals Koder.ai helpen bij het prototypen van kernschermen (overview, drill-down, staffing planner), de API en een PostgreSQL-ondersteunde schema vanuit een begeleid gesprek—en dan itereren op de vereisten met stakeholders.
Omdat Koder.ai broncode-export, snapshots en rollback ondersteunt, kan het nuttig zijn voor snelle experimenten (bijv. verschillende staffing-formules of SLA-definities proberen) zonder je vast te leggen op een eenmalig prototype.