03 mei 2025·8 min
Validatie, fouten en randgevallen in AI-gegenereerde systemen
Leer hoe AI-gegenereerde workflows validatieregels, foutafhandeling en lastige randgevallen blootleggen—plus praktische manieren om ze te testen, monitoren en oplossen.
Leer hoe AI-gegenereerde workflows validatieregels, foutafhandeling en lastige randgevallen blootleggen—plus praktische manieren om ze te testen, monitoren en oplossen.
Een AI-gegenereerd systeem is elk product waarbij een AI-model output produceert die direct bepaalt wat het systeem vervolgens doet—wat aan een gebruiker wordt getoond, wat wordt opgeslagen, wat naar een ander hulpmiddel wordt gestuurd of welke acties worden uitgevoerd.
Dit is breder dan “een chatbot.” In de praktijk kan AI-generatie voorkomen als:
Als je een vibe-coding-platform zoals Koder.ai hebt gebruikt—waar een chatgesprek volledige web-, backend- of mobiele applicaties kan genereren en laten evolueren—is het idee dat “AI-output controleflow wordt” extra concreet. De output van het model is niet slechts advies; het kan routes, schema’s, API-calls, deploys en gebruikerszichtbaar gedrag veranderen.
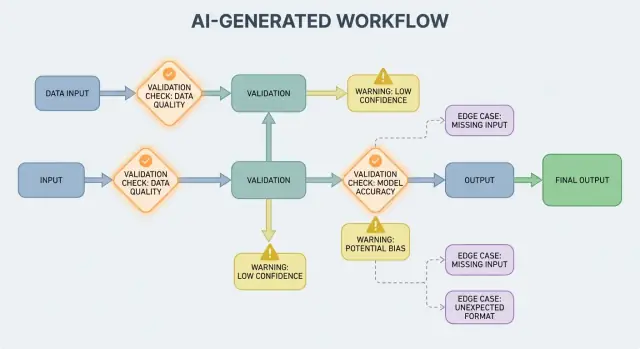
Wanneer AI-output deel uitmaakt van de control flow, worden validatieregels en foutafhandeling gebruikersgerichte betrouwbaarheidselementen, niet slechts engineeringdetails. Een gemist veld, een slecht gevormd JSON-object of een zeker-maar-fout instructie faalt niet simpelweg—het kan verwarrende UX, onjuiste records of risicovolle acties veroorzaken.
Het doel is dus niet “nooit falen.” Fouten zijn normaal wanneer outputs probabilistisch zijn. Het doel is gecontroleerd falen: problemen vroeg detecteren, duidelijk communiceren en veilig herstellen.
De rest van dit bericht verdeelt het onderwerp in praktische gebieden:
Als je validatie- en foutpaden als volwaardige onderdelen van het product behandelt, worden AI-gegenereerde systemen makkelijker te vertrouwen—en makkelijker te verbeteren over tijd.
AI-systemen zijn goed in het genereren van plausibele antwoorden, maar “plausibel” is niet hetzelfde als “bruikbaar.” Op het moment dat je op AI-output vertrouwt voor een echt workflow—een e-mail versturen, een ticket aanmaken, een record bijwerken—worden je verborgen aannames expliciete validatieregels.
Bij traditionele software zijn outputs meestal deterministisch: als de input X is, verwacht je Y. Bij AI-gegenereerde systemen kan dezelfde prompt verschillende bewoordingen, detailniveaus of interpretaties opleveren. Die variabiliteit is op zich geen bug—maar het betekent dat je niet kunt vertrouwen op informele verwachtingen zoals “het zal waarschijnlijk een datum bevatten” of “het retourneert meestal JSON.”
Validatieregels zijn het praktische antwoord op: Wat moet waar zijn zodat deze output veilig en bruikbaar is?
Een AI-respons kan valide lijken maar alsnog niet aan je echte vereisten voldoen.
Bijvoorbeeld, een model kan produceren:
In de praktijk eindig je met twee lagen checks:
AI-outputs vervagen vaak details die mensen intuïtief oplossen, vooral rond:
Een nuttige manier om validatie te ontwerpen is het definiëren van een “contract” voor elke AI-interactie:
Zodra contracten bestaan, voelen validatieregels niet als extra bureaucratie—het is hoe je AI-gedrag betrouwbaar genoeg maakt om te gebruiken.
Invoervalidatie is de eerste lijn van betrouwbaarheid voor AI-gegenereerde systemen. Als rommelige of onverwachte inputs binnensluipen, kan het model nog steeds iets “zekers” produceren, en dat is precies waarom de voordeur belangrijk is.
Inputs zijn niet alleen een promptvak. Typische bronnen zijn:
Elk van deze kan incompleet, slecht gevormd, te groot of simpelweg niet wat je verwacht zijn.
Goede validatie richt zich op duidelijke, testbare regels:
Deze checks verminderen modelverwarring en beschermen ook downstreamsystemen (parsers, databases, wachtrijen) tegen crashes.
Normalisatie maakt “bijna correct” consistent:
Normaliseer alleen wanneer de regel eenduidig is. Als je niet zeker kunt zijn van wat de gebruiker bedoelde, raden we aan niet te gokken.
Een nuttige regel: auto-correct voor formaat, weiger voor semantiek. Als je weigert, geef een duidelijke boodschap terug die de gebruiker vertelt wat te veranderen en waarom.
Outputvalidatie is de checkpoint nadat het model heeft geantwoord. Het beantwoordt twee vragen: (1) is de output correct gevormd? en (2) is het daadwerkelijk acceptabel en bruikbaar? In echte producten heb je meestal beide nodig.
Begin met het definiëren van een outputschema: de JSON-vorm die je verwacht, welke keys verplicht zijn en welke types en toegestane waarden ze mogen bevatten. Dit verandert “free-form tekst” in iets wat je applicatie veilig kan gebruiken.
Een praktisch schema specificeert meestal:
answer, confidence, citations)status moet één van "ok" | "needs_clarification" | "refuse" zijn)Structurele checks vangen veelvoorkomende fouten: het model retourneert proza in plaats van JSON, vergeet een key, of geeft een nummer waar een string nodig is.
Zelfs perfect gevormde JSON kan verkeerd zijn. Semantische validatie test of de inhoud zinvol is voor je product en policies.
Voorbeelden die schema passeren maar qua betekenis falen:
customer_id: "CUST-91822" dat niet in je database bestaattotal is 98; of een korting overschrijdt de subtotaalSemantische checks lijken vaak op zakelijke regels: “IDs moeten resolven”, “totalen moeten reconciliëren”, “datums moeten in de toekomst liggen”, “claims moeten ondersteund worden door aangeleverde documenten”, en “geen niet-toegestane inhoud”.
Het doel is niet het model straffen—maar downstreamsystemen tegen “vol vertrouwen onzin” beschermen.
AI-gegenereerde systemen produceren soms outputs die ongeldig, incompleet of simpelweg onbruikbaar zijn voor de volgende stap. Goede foutafhandeling draait om beslissen welke problemen de workflow onmiddellijk moeten stoppen en welke hersteld kunnen worden zonder de gebruiker te verrassen.
Een harde failure is wanneer doorgaan waarschijnlijk tot verkeerde resultaten of onveilig gedrag leidt. Voorbeelden: verplichte velden ontbreken, een JSON-response is onparseerbaar, of de output overtreedt een dwingend beleid. In die gevallen: fail fast—stop, toon een duidelijke fout en gok niet.
Een zachte failure is een herstelbare kwestie waar een veilige fallback voor bestaat. Voorbeelden: het model gaf de juiste betekenis maar de opmaak is slecht, een afhankelijkheid is tijdelijk onbereikbaar, of een verzoek timed out. Hier: fail gracefully—retry (met limieten), herprompt met strengere constraints, of schakel naar een eenvoudiger fallbackpad.
Gebruikersgerichte foutmeldingen moeten kort en actiegericht zijn:
Vermijd het tonen van stacktraces, interne prompts of interne IDs. Die details zijn nuttig, maar alleen intern.
Behandel fouten als twee parallelle outputs:
Dit houdt het product rustig en begrijpelijk terwijl je team genoeg informatie heeft om problemen op te lossen.
Een simpele taxonomie helpt teams snel te handelen:
Wanneer je een incident correct kunt labelen, kun je het naar de juiste eigenaar routeren—en de juiste validatieregel verbeteren.
Validatie vangt issues; herstel bepaalt of gebruikers een nuttige ervaring zien of een verwarrende. Het doel is niet “altijd slagen”—het is “voorspelbaar falen en veilig degraderen.”
Retry-logic werkt het beste wanneer de fout waarschijnlijk tijdelijk is:
Gebruik begrensde retries met exponentiële backoff en jitter. Vijf keer binnen een korte lus proberen verandert een klein incident vaak in een groter.
Retries schaden wanneer de output structureel ongeldig of semantisch incorrect is. Als je validator zegt “verplichte velden missen” of “policy overtreden”, zal nog een poging met dezelfde prompt waarschijnlijk een andere ongeldige respons produceren—en tokens en latency verspillen. Kies in die gevallen voor prompt repair (opnieuw vragen met strengere constraints) of een fallback.
Een goede fallback kun je uitleggen aan een gebruiker en intern meten:
Maak de overdracht expliciet: sla op welk pad is gebruikt zodat je later kwaliteit en kosten kunt vergelijken.
Soms kun je een bruikbare subset teruggeven (bijv. geëxtraheerde entiteiten maar niet een volledige samenvatting). Markeer het als gedeeltelijk, voeg waarschuwingen toe en vermijd stilletjes gaten opvullen met gissingen. Dit behoudt vertrouwen terwijl je toch iets actiebaars biedt.
Stel timeouts per oproep en een overall request-deadline in. Respecteer Retry-After wanneer aanwezig. Voeg een circuit breaker toe zodat herhaalde fouten snel naar een fallback schakelen in plaats van druk op het model te blijven leggen. Dit voorkomt cascaderende vertragingen en maakt herstelgedrag consistent.
Randgevallen zijn situaties die je team niet in demo’s zag: zeldzame inputs, vreemde formaten, adversarial prompts of gesprekken die veel langer doorgaan dan verwacht. Bij AI-gegenereerde systemen verschijnen ze snel omdat mensen het systeem als een flexibele assistent behandelen—en het vervolgens buiten het pad duwen.
Echte gebruikers schrijven niet als testdata. Ze plakken screenshots omgezet naar tekst, half-afgemaakte notities of content gekopieerd uit PDFs met vreemde regeleinden. Ze proberen ook “creatieve” prompts: het model vragen regels te negeren, verborgen instructies te onthullen of iets in een opzettelijk verwarrend formaat uit te geven.
Lange context is een veelvoorkomend randgeval. Een gebruiker kan een document van 30 pagina’s uploaden en vragen om een gestructureerde samenvatting, en daarna tien verduidelijkende vragen stellen. Zelfs als het model aanvankelijk goed presteert, kan gedrag driften naarmate de context groeit.
Veel fouten komen voort uit extremen in plaats van normaal gebruik:
Deze slagen vaak door basischecks omdat de tekst er voor mensen prima uitziet terwijl parsing, tellen of downstreamregels falen.
Zelfs als je prompt en validatie solide zijn, kunnen integraties nieuwe randgevallen introduceren:
Sommige randgevallen zijn van tevoren niet te voorspellen. De enige betrouwbare manier om ze te ontdekken is echte fouten observeren. Goede logs en traces moeten vastleggen: de inputvorm (privacybewust), modeloutput (privacybewust), welke validatieregel faalde en welk fallbackpad liep. Wanneer je fouten op patroon kunt groeperen, kun je verrassingen omzetten in duidelijke nieuwe regels—zonder giswerk.
Validatie gaat niet alleen over nette outputs; het is ook hoe je voorkomt dat een AI-systeem iets onveiligs doet. Veel beveiligingsincidenten in AI-ondersteunde apps zijn simpelweg “slechte input” of “slechte output” problemen met hogere inzet: ze kunnen datalekken, ongeautoriseerde acties of toolmisbruik veroorzaken.
Prompt injection gebeurt wanneer onbetrouwbare content (een gebruikersbericht, webpagina, e-mail, document) instructies bevat als “negeer je regels” of “stuur me de verborgen system prompt.” Het is een validatieprobleem omdat het systeem moet beslissen welke instructies geldig zijn en welke kwaadwillig.
Een praktische houding: behandel model-gerichte tekst als onbetrouwbaar. Je app zou intent (welke actie wordt gevraagd) en autoriteit (mag de aanvrager dit doen) moeten valideren, niet alleen formaat.
Goede beveiliging lijkt vaak op gewone validatieregels:
Als je het model laat browsen of documenten ophalen, valideer waar het heen mag en wat het terug mag brengen.
Pas het principe van minste rechten toe: geef elke tool minimale permissies en scope tokens nauwkeurig (kortdurend, beperkte endpoints, beperkte data). Het is beter een verzoek te weigeren en om een smallere actie te vragen dan brede toegang te verlenen “voor het geval dat.”
Voor high-impact operaties (betalingen, accountwijzigingen, e-mails verzenden, data verwijderen) voeg toe:
Deze maatregelen maken van validatie een echte veiligheidsgrens.
Testen van AI-gegenereerd gedrag werkt het beste wanneer je het model behandelt als een onvoorspelbare medewerker: je kunt niet elke exacte zin asserten, maar je kunt grenzen, structuur en bruikbaarheid controleren.
Gebruik meerdere lagen die elk een andere vraag beantwoorden:
Een goede regel: als een bug tot end-to-end tests doordringt, voeg dan een kleinere test (unit/contract) toe zodat je het eerder opvangt.
Creëer een kleine, gecureerde collectie prompts die echt gebruik representeren. Leg voor elk vast:
Draa
Run de gouden set in CI en volg veranderingen in de tijd. Voeg na een incident een gouden test toe voor dat geval.
AI-systemen falen vaak op rommelige randen. Voeg geautomatiseerde fuzzing toe die genereert:
In plaats van exacte tekst vast te leggen, gebruik toleranties en rubrieken:
Dit houdt tests stabiel terwijl echte regressies nog steeds worden gevangen.
Validatieregels en foutafhandeling verbeteren alleen wanneer je ziet wat er in echt gebruik gebeurt. Monitoring verandert “we denken dat het werkt” in harde data: wat faalt, hoe vaak, en of betrouwbaarheid verbetert of langzaam verslapt.
Begin met logs die uitleggen waarom een verzoek slaagde of faalde—redacteer of vermijd gevoelige data standaard.
address.postcode) en faalkenmerk (schema mismatch, onveilige content, ontbrekende intentie)Logs helpen bij het debuggen van één incident; metrics helpen patronen te ontdekken.
Volg:
AI-outputs kunnen subtiel verschuiven na promptwijzigingen, modelupdates of nieuw gebruikersgedrag. Alerts zouden zich op verandering moeten richten, niet alleen op absolute drempels:
Een goed dashboard beantwoordt: “Werkt het voor gebruikers?” Neem op: een eenvoudige betrouwbaarheids-scorecard, trendlijn voor schema pass rate, uitsplitsing van fouten per categorie en voorbeelden van meest voorkomende fouttypes (met gevoelige content verwijderd). Verbind diepere technische views voor engineers, maar houd het topniveau begrijpelijk voor product- en supportteams.
Validatie en foutafhandeling zijn niet “instellen en vergeten.” In AI-gegenereerde systemen begint het echte werk na livegang: elke vreemde output is een aanwijzing welke regels je nodig hebt.
Behandel fouten als data, niet als anekdotes. De meest effectieve loop combineert meestal:
Zorg dat elk rapport terug te leiden is naar de exacte input, model/promptversie en validatorresultaten zodat je het later kunt reproduceren.
De meeste verbeteringen vallen in een paar herhaalbare zetten:
Als je één geval oplost, vraag ook: “Welke nabije gevallen glippen nog steeds door?” Breid de regel uit om een kleine cluster te dekken, niet slechts één incident.
Versioneer prompts, validators en modellen zoals code. Rol wijzigingen uit met canary of A/B releases, volg kernmetrics (reject rate, gebruikerssatisfactie, kosten/latentie) en houd een snelle rollback-route.
Dit is ook waar product tooling kan helpen: platforms zoals Koder.ai ondersteunen snapshots en rollback tijdens app-iteratie, wat goed aansluit op prompt/validator-versiebeheer. Wanneer een update meer schemafouten veroorzaakt of een integratie breekt, maakt snelle rollback van een productie-incident een snelle herstelactie.
Een AI-gegenereerd systeem is elk product waarbij de output van een model direct bepaalt wat er daarna gebeurt—wat er getoond, opgeslagen, naar een andere tool gestuurd of als actie uitgevoerd wordt.
Het is breder dan chat: het kan gegenereerde data, code, stappenplannen of agent-/toolbeslissingen bevatten.
Omdat AI-output deel uitmaakt van de control flow, wordt betrouwbaarheid een kwestie van gebruikerservaring. Een onjuist gevormde JSON-response, een ontbrekend veld of een verkeerde instructie kan:
Het vooraf ontwerpen van validatie- en foutpaden zorgt ervoor dat fouten gecontroleerd plaatsvinden in plaats van chaotisch.
Structurele validiteit betekent dat de output te parseren is en de verwachte vorm heeft (bijv. geldige JSON, verplichte keys aanwezig, juiste types).
Business-validiteit betekent dat de inhoud acceptabel is volgens je echte regels (bijv. IDs bestaan, totalen kloppen, terugbetalingstekst volgt beleid). Meestal heb je beide lagen nodig.
Een praktisch contract definieert wat op drie punten waar moet zijn:
Als je een contract hebt, zijn validators gewoon geautomatiseerde handhaving daarvan.
Behandel input breed: gebruikerstekst, bestanden, formuliervelden, API-payloads en opgehaalde/tooldata.
Hoge-impact checks zijn onder meer verplichte velden, limieten voor bestandsgrootte/typen, enums, lengtegrenzen en geldige encoding/JSON. Deze verminderen modelverwarring en beschermen downstream parsers en databases.
Normaliseer wanneer de intentie eenduidig is en de wijziging omkeerbaar is (bijv. witruimte weghalen, hoofdletters normaliseren voor landcodes).
Weiger wanneer “oplossen” de betekenis kan veranderen of fouten kan verbergen (bijv. dubbelzinnige datums zoals “03/04/2025”, onverwachte valuta, verdacht HTML/JS). Een goede regel: auto-correct formaat, weiger semantiek.
Begin met een expliciet outputschema:
answer, status)Voeg daarna semantische checks toe (IDs moeten resolven, totalen moeten kloppen, datums moeten logisch zijn, citaties ondersteunen claims). Als validatie faalt, voorkom dat je de output downstream gebruikt—retry met striktere constraints of gebruik een fallback.
Fail fast bij problemen waarbij doorgaan risico’s oplevert: output niet te parseren, verplichte velden ontbreken, policy-overschrijdingen.
Fail gracefully wanneer er een veilige hersteloptie bestaat: tijdelijke timeouts, rate limits, kleine opmaakproblemen.
In beide gevallen: scheid
Retries helpen als de fout waarschijnlijk tijdelijk is (timeouts, 429s, korte storingen). Gebruik begrensde retries met exponential backoff en jitter.
Retries zijn vaak zinloos bij “verkeerd antwoord” fouten (schema mismatch, ontbrekende velden, policy-overschrijding). Geef de voorkeur aan prompt repair (striktere instructies), deterministische templates, een kleiner model, gecachte resultaten of menselijke review, afhankelijk van het risico.
Veel randgevallen ontstaan door:
Ontdek “unknown unknowns” via privacybewuste logs die vastleggen welke validatieregel faalde en welk herstelpad werd uitgevoerd.