01 sep 2025·8 min
Van idee tot gedeployde app in één AI-gestuurde workflow
Een praktische, end-to-end handleiding die laat zien hoe je van app-idee naar een gedeployd product komt met één AI-gestuurde workflow—stappen, prompts en checks.
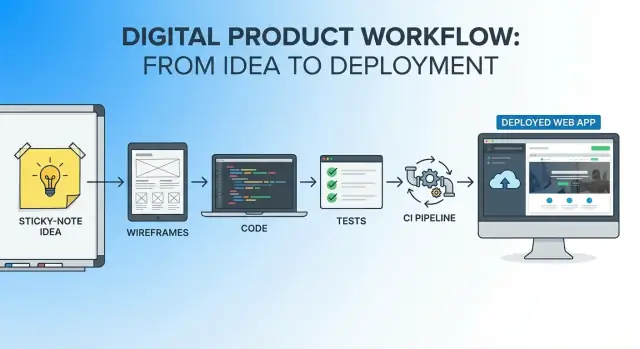
Een praktische, end-to-end handleiding die laat zien hoe je van app-idee naar een gedeployd product komt met één AI-gestuurde workflow—stappen, prompts en checks.
Stel je een klein, nuttig app-idee voor: een “Queue Buddy” waarmee een cafémedewerker met één druk op de knop een klant aan een wachtlijst toevoegt en die automatisch een sms stuurt wanneer hun tafel klaar is. De succesmetric is eenvoudig en meetbaar: verminder het aantal verwarringstelefoontjes over wachttijden met 50% binnen twee weken, terwijl de onboarding voor personeel onder de 10 minuten blijft.
Dat is de geest van dit artikel: kies een duidelijk begrensd idee, definieer wat “goed” betekent, en ga dan van concept naar live deployment zonder constant van tools, documenten en mentale modellen te wisselen.
Een enkele workflow is één doorlopende draad vanaf de eerste zin van het idee tot de eerste productie-release:
Je gebruikt nog steeds meerdere tools (editor, repo, CI, hosting), maar je hoeft het project bij elke fase niet opnieuw te “starten”. Dezelfde narratief en beperkingen worden meegenomen.
AI is het meest waardevol wanneer het:
Maar het neemt de productbeslissingen niet over. Jij doet dat. De workflow is zo opgezet dat je altijd verifieert: Verplaatst deze wijziging de metric? Is het veilig om te releasen?
In de volgende secties doorloop je stap voor stap:
Aan het einde heb je een herhaalbare manier om van “idee” naar “live app” te gaan, terwijl scope, kwaliteit en leren nauw verbonden blijven.
Voordat je een AI vraagt schermen, API's of databasetabellen te ontwerpen, heb je een scherp doel nodig. Een beetje duidelijkheid bespaart uren met “bijna goed” output later.
Je bouwt een app omdat een specifieke groep mensen telkens tegen dezelfde frictie aanloopt: ze kunnen een belangrijke taak niet snel, betrouwbaar of vol vertrouwen voltooien met de tools die ze hebben. Het doel van versie 1 is één pijnpunt uit die workflow weg te nemen—zonder te proberen alles te automatiseren—zodat gebruikers van “ik moet X doen” naar “X is klaar” kunnen in enkele minuten, met een duidelijk spoor van wat er gebeurd is.
Kies één primaire gebruiker. Secundaire gebruikers kunnen wachten.
Aannames zijn waar goede ideeën stilletjes mislukken—maak ze zichtbaar.
Versie 1 moet een kleine winst zijn die je kunt uitrollen.
Een lichtgewicht requirements-doc (denk: één pagina) is de brug tussen “tof idee” en “bouwbaar plan”. Het houdt je gefocust, geeft je AI-assistent de juiste context en voorkomt dat de eerste versie uitgroeit tot een maandenlang project.
Houd het kort en scanbaar. Een simpel template:
Schrijf 5–10 features max, geformuleerd als uitkomsten. Rangschik ze daarna:
Deze ranking stuurt ook AI-gegenereerde plannen en code: “Implementeer eerst alleen must-haves.”
Voor de top 3–5 features voeg je per feature 2–4 acceptatiecriteria toe. Gebruik eenvoudige taal en testbare uitspraken.
Voorbeeld:
Sluit af met een korte lijst “Open Questions”—dingen die je kunt beantwoorden met één chat, één klantgesprek, of een snelle zoekopdracht.
Voorbeelden: “Hebben gebruikers Google-login nodig?” “Wat is de minimale data die we moeten opslaan?” “Hebben we admin-approval nodig?”
Dit doc is geen papierwerk; het is een gedeelde bron van waarheid die je bijhoudt terwijl de build vordert.
Voordat je AI vraagt schermen te genereren of code te schrijven, zet het verhaal van het product op papier. Een korte reis-schets houdt iedereen op één lijn: wat de gebruiker probeert te doen, wat succes is, en waar het mis kan gaan.
Begin met het happy path: de eenvoudigste volgorde die de hoofdwaarde levert.
Voorbeeldflow (generiek):
Voeg daarna een paar edge cases toe die waarschijnlijk en kostbaar zijn als ze niet goed worden afgehandeld:
Je hoeft geen groot diagram te maken. Een genummerde lijst plus aantekeningen is genoeg om prototyping en codegeneratie te sturen.
Schrijf een korte “job to be done” voor elk scherm. Focus op uitkomsten, niet op UI.
Als je met AI werkt, wordt deze lijst prima prompt-materiaal: “Genereer een Dashboard dat X, Y, Z ondersteunt en lege/laden/fout-states bevat.”
Houd dit op “servet-schema”-niveau—genoeg om schermen en flows te ondersteunen.
Noteer relaties (User → Projects → Tasks) en alles dat permissies beïnvloedt.
Markeer de punten waar fouten vertrouwen breken:
Dit gaat niet over over-engineering—maar over het voorkomen van verrassingen die een werkende demo in een supportprobleem veranderen na lancering.
De architectuur van versie 1 moet één ding goed doen: je in staat stellen de kleinste nuttige productversie te releasen zonder jezelf vast te rijden. Een goede regel is “één repo, één deploybare backend, één deploybare frontend, één database”—en voeg pas extra onderdelen toe als een duidelijke eis dat vereist.
Als je een typische webapp bouwt, is een verstandige default:
Houd het aantal services laag. Voor v1 is een “modulair monoliet” (goed georganiseerde codebase, maar één backendservice) meestal makkelijker dan microservices.
Als je een AI-first omgeving wilt waar architectuur, taken en gegenereerde code strak verbonden blijven, kunnen platforms zoals Koder.ai goed passen: je beschrijft de v1-scope in chat, iterereert in “planning mode” en genereert dan een React-frontend met een Go + PostgreSQL-backend—terwijl je review en controle behoudt.
Voordat je code genereert, schrijf je een klein API-tabel zodat jij en de AI hetzelfde doel delen. Voorbeeldvorm:
GET /api/projects → { items: Project[] }POST /api/projects → { project: Project }GET /api/projects/:id → { project: Project, tasks: Task[] }POST /api/projects/:id/tasks → { task: Task }Voeg notities toe over statuscodes, foutformaat (bijv. { error: { code, message } }) en eventuele paginatie.
Als v1 publiek of single-user kan zijn, sla auth dan over en releas sneller. Als je accounts nodig hebt, gebruik een managed provider (magic link via e-mail of OAuth) en houd permissies simpel: “user owns their records.” Vermijd complexe rollen totdat echt gebruik erom vraagt.
Documenteer een paar praktische constraints:
Deze notities sturen AI-gegenereerde code richting iets dat niet alleen functioneel is, maar ook deployable.
De snelste manier om momentum te doden is een week debatteren over tools en nog steeds geen draaiende code hebben. Het doel hier is simpel: kom tot een “hello app” die lokaal start, een zichtbaar scherm heeft en een request kan accepteren—terwijl het klein genoeg blijft dat elke wijziging makkelijk te reviewen is.
Geef de AI een strakke prompt: keuze van framework, basispagina's, een stub API en de bestanden die je verwacht. Je zoekt voorspelbare conventies, geen slimme trucs.
Een goed eerste voorstel is een structuur als:
/README.md
/.env.example
/apps/web/
/apps/api/
/package.json
Als je één repo gebruikt, vraag dan om basisroutes (bijv. / en /settings) en één API-endpoint (bijv. GET /health of GET /api/status). Dat is genoeg om te bewijzen dat de plumbing werkt.
Als je Koder.ai gebruikt, is dit ook een natuurlijke plek om te starten: vraag om een minimaal “web + api + database-ready” skelet, en exporteer de bron als je tevreden bent met structuur en conventies.
Houd de UI opzettelijk saai: één pagina, één knop, één call.
Voorbeeldgedrag:
Dit geeft je een directe feedbacklus: laadt de UI maar faalt de call, dan weet je precies waar te zoeken (CORS, poort, routing, netwerkfouten). Weersta de neiging om auth, databases of complexe state hier toe te voegen—dat komt nadat het skelet stabiel is.
Maak op dag één een .env.example. Dat voorkomt “werkt op mijn machine”-problemen en maakt onboarding pijnloos.
Voorbeeld:
WEB_PORT=3000
API_PORT=4000
API_URL=http://localhost:4000
Maak de README vervolgens zodanig dat het in onder een minuut draait:
.env.example naar .envBehandel deze fase als het leggen van schone funderingslijnen. Commit na elke kleine winst: “init repo”, “add web shell”, “add api health endpoint”, “wire web to api.” Kleine commits maken AI-gestuurde iteratie veiliger: als een gegenereerde wijziging misloopt, kun je eenvoudig terugdraaien zonder een dag werk te verliezen.
Zodra het skelet end-to-end draait, weersta de drang om “alles af te maken.” Bouw in plaats daarvan een smalle verticale slice die database, API en UI raakt (indien van toepassing), en herhaal. Dunne slices houden reviews snel, bugs klein en AI-assistentie makkelijker te verifiëren.
Kies het ene model zonder welke je app niet kan functioneren—vaak het “ding” dat gebruikers maken of beheren. Definieer het helder (velden, verplicht vs optioneel, defaults) en voeg migraties toe als je een relationele DB gebruikt. Houd de eerste versie saai: vermijd slimme normalisatie en voortijdige flexibiliteit.
Als je AI gebruikt om het model te schetsen, vraag dan om een korte rechtvaardiging per veld en default. Als het iets niet in één zin kan uitleggen, hoort het waarschijnlijk niet in v1.
Maak alleen de endpoints die nodig zijn voor de eerste gebruikersreis: meestal create, read en een minimale update. Plaats validatie dicht bij de grens (request DTO/schema) en maak regels expliciet:
Validatie is onderdeel van de feature, geen detail—het voorkomt rommelige data die je later vertraagt.
Behandel foutmeldingen als UX voor debugging en support. Geef duidelijke, bruikbare berichten terug (wat misging en hoe het te repareren), en houd gevoelige details uit client-responses. Log technische context server-side met een request-ID zodat je incidenten kunt traceren zonder te gokken.
Vraag AI om incrementele PR-grootte wijzigingen: één migratie + één endpoint + één test per keer. Review diffs zoals bij het werk van een collega: check naming, edge cases, beveiligingsveronderstellingen en of de wijziging echt de gebruikerswinst ondersteunt. Als het extra features toevoegt, haal ze eruit en ga door.
V1 heeft geen enterprise-grade security nodig—maar het moet voorspelbare fouten voorkomen die van een veelbelovende app een support-nachtmerrie maken. Het doel is “veilig genoeg”: voorkom slechte input, beperk toegang standaard, en laat een spoor van bruikbare bewijzen achter bij problemen.
Behandel elke grens als onbetrouwbaar: formuliervelden, API-payloads, query-parameters en zelfs interne webhooks. Valideer type, lengte en toegestane waarden, en normaliseer data (strings trimmen, casing aanpassen) voordat je opslaat.
Een paar praktische defaults:
Als je AI handers genereert, vraag dan expliciet om validatieregels (bijv. “max 140 tekens” of “moet één van: … zijn”) in plaats van alleen “valideer input.”
Een simpel permissiemodel is meestal voldoende voor v1:
Maak ownership-checks centraal en herbruikbaar (middleware/policy-functies), zodat je niet overal if userId == … verspreidt in de codebase.
Goede logs beantwoorden: wat gebeurde, bij wie, en waar? Voeg toe:
update_project, project_id)Log events, geen secrets: schrijf nooit wachtwoorden, tokens of volledige betalingsgegevens naar logs.
Voordat je de app “veilig genoeg” noemt, controleer:
Testen draait niet om een perfecte score—maar om het voorkomen van fouten die gebruikers schaden, vertrouwen breken of dure blusacties veroorzaken. In een AI-gestuurde workflow fungeren tests ook als “contract” dat gegenereerde code op één lijn houdt met wat je bedoelde.
Voordat je veel coverage toevoegt, identificeer waar fouten kostbaar zijn. Typische hoog-risico plekken: geld/credits, permissies, datatransformaties en rand-case validatie. Schrijf unit-tests voor deze onderdelen eerst. Houd ze klein en specifiek: gegeven input X, verwacht output Y (of een fout). Als een functie te veel takken heeft om netjes te testen, is dat een hint dat je moet vereenvoudigen.
Unit-tests vangen logica-bugs; integratietests vangen “aansluit”-bugs—routes, DB-calls, auth-checks en de UI-flow die samenwerkt. Kies de kernreis (happy path) en automatiseer die end-to-end:
Een paar solide integratietests voorkomen vaak meer incidenten dan tientallen kleine tests.
AI is goed in het genereren van test-scaffolding en het opsommen van randgevallen die je misschien mist. Vraag om:
Review daarna elke gegenereerde assertie. Tests moeten gedrag verifiëren, geen implementatiedetails. Als een test nog steeds slaagt na een bug, doet hij zijn werk niet.
Kies een bescheiden target (bijv. 60–70% op kernmodules) en gebruik het als een guardrail, niet als trofee. Focus op stabiele, reproduceerbare tests die snel draaien in CI en om de juiste redenen falen. Flaky tests ondermijnen vertrouwen—en zodra men de suite niet meer vertrouwt, beschermt hij je niet langer.
Automatisering is waar een AI-gestuurde workflow stopt met een “werkend op mijn laptop” project en verandert in iets dat je met vertrouwen kunt releasen. Het doel is geen fancy tooling, maar herhaalbaarheid.
Kies één commando dat lokaal en in CI hetzelfde resultaat oplevert. Voor Node kan dat npm run build zijn; voor Python een make build; voor mobile een specifieke Gradle/Xcode stap.
Scheid development- en production-config vanaf het begin. Een eenvoudige regel: dev-standaarden zijn handig; productie-standaarden zijn veilig.
{
"scripts": {
"lint": "eslint .",
"format": "prettier -w .",
"test": "vitest run",
"build": "vite build"
}
}
Een linter vangt risicovolle patronen (ongebruikte variabelen, onveilige async-calls). Een formatter voorkomt stijl-discussies in review. Houd regels bescheiden voor v1, maar handhaaf ze consequent.
Een praktische gate-volgorde:
Je eerste CI-workflow kan klein zijn: dependencies installeren, gates draaien en snel falen. Dat voorkomt dat kapotte code ongemerkt landt.
name: ci
on: [push, pull_request]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with:
node-version: 20
- run: npm ci
- run: npm run format -- --check
- run: npm run lint
- run: npm test
- run: npm run build
Bepaal waar secrets leven: CI secret store, een password manager, of de omgeving van je deploymentplatform. Commit ze nooit naar git—zet .env op .gitignore en voeg een .env.example met veilige placeholders toe.
Als je een volgende stap wilt: koppel deze gates aan je deploymentproces zodat alleen “groene CI” naar productie kan.
Shippen is niet één knop—het is een herhaalbare routine. Het doel voor v1 is simpel: kies een deployment-target dat bij je stack past, deploy in kleine stappen en heb altijd een manier terug.
Kies een platform dat past bij hoe je app draait:
Optimaliseren voor “makkelijk opnieuw deployen” verslaat vaak optimaliseren voor “maximale controle” in deze fase.
Als je tool-switching wilt minimaliseren, overweeg platforms die build + hosting + rollback-primitieven bundelen. Bijvoorbeeld ondersteunt Koder.ai deployment en hosting met snapshots en rollback, zodat je releases als omkeerbare stappen kunt behandelen.
Schrijf de checklist één keer en hergebruik hem voor elke release. Houd hem kort genoeg dat mensen hem echt opvolgen:
Als je de checklist in de repo opslaat (bijv. in /docs/deploy.md), blijft hij vanzelf dicht bij de code.
Maak een lichtgewicht endpoint dat antwoordt op: “Is de app up en kan hij zijn dependencies bereiken?” Gebruik patronen als:
GET /health voor load balancers en uptime monitorsGET /status met basis app-versie + dependency-checksHoud responses snel, cache-vrij en veilig (geen secrets of interne details).
Een rollback-plan moet expliciet zijn:
Als deployment omkeerbaar is, wordt releasen routinematig—en kun je vaker en met minder stress uitrollen.
Lanceren is het begin van de meest nuttige fase: leren wat echte gebruikers doen, waar de app faalt en welke kleine wijzigingen je succesmetric verschuiven. Het doel is dezelfde AI-gestuurde workflow te behouden—nu gericht op bewijs in plaats van aannames.
Begin met een minimale monitoringstack die drie vragen beantwoordt: Is het up? Faalt het? Is het traag?
Uptime-checks kunnen simpel zijn (periodieke hit op een health-endpoint). Error-tracking moet stacktraces en requestcontext vastleggen (zonder gevoelige data). Performance-monitoring kan beginnen met responsetijden voor kern-endpoints en front-end paginaloadstatistieken.
Vraag AI om te helpen bij het genereren van:
Track niet alles—track wat bewijst dat de app werkt. Definieer één primaire succesmetric (bijv. “voltooide checkout”, “gemaakt eerste project” of “uitgenodigde teammate”). Instrumenteer vervolgens een kleine funnel: entry → sleutelactie → succes.
Vraag AI om event-namen en properties voor te stellen, en review ze op privacy en duidelijkheid. Houd events stabiel; namen wekelijks veranderen maakt trends betekenisloos.
Maak een simpele intake: een in-app feedbackknop, een kort e-mailalias en een lichtgewicht bug-template. Triage wekelijks: groeper feedback in thema's, verbind thema's aan analytics en beslis de volgende 1–2 verbeteringen.
Behandel monitoring-alerts, dalingen in analytics en feedbackthema's als nieuwe “requirements.” Voer ze door hetzelfde proces: werk het doc bij, genereer een klein wijzigingsvoorstel, implementeer in dunne slices, voeg een gerichte test toe en deploy via hetzelfde omkeerbare releaseproces. Voor teams houdt een gedeelde “Learning Log”-pagina (gekopppeld vanuit /blog of interne docs) beslissingen zichtbaar en herhaalbaar.
Een “single workflow” is één doorlopende draad van idee tot productie waarbij:
Je mag nog steeds meerdere tools gebruiken, maar je voorkomt dat het project bij elke fase opnieuw gestart wordt.
Gebruik AI om opties en drafts te genereren, en jij maakt de keuzes en verifieert ze:
Houd een duidelijke beslisregel: Beweegt dit de metric vooruit, en is het veilig om te releasen?
Definieer een meetbare succesmetric en een strakke v1 “definition of done.” Bijvoorbeeld:
Als een feature die uitkomsten niet ondersteunt, is het een non-goal voor v1.
Houd het bij een skimmable, één-pagina PRD met:
Voeg daarna 5–10 hoofdfeatures toe, maximaal, gerangschikt als Must/Should/Nice. Gebruik die ranking om AI-gegenereerde plannen en code te begrenzen.
Voor je top 3–5 features voeg je 2–4 testbare uitspraken per feature toe. Goede acceptatiecriteria zijn:
Voorbeelden: validatieregels, verwachte redirects, foutmeldingen en permissiegedrag (bijv. “onbevoegde gebruikers zien een duidelijke fout en er lekt geen data”).
Begin met een genummerd happy path en voeg daarna een paar veelvoorkomende, kostbare fouten toe:
Een eenvoudige lijst is genoeg; het doel is UI-states, API-antwoorden en tests te sturen.
Ga voor een “modulair monoliet” voor v1:
Voeg alleen services toe wanneer een eis het echt vereist. Dit vermindert coördinatie-overhead en maakt AI-gestuurde iteratie makkelijker te reviewen en terug te draaien.
Schrijf vooraf een klein “API-contract”:
{ error: { code, message } })Dit voorkomt mismatches tussen UI en backend en geeft tests een stabiel doel.
Streef naar een “hello app” die de plumbing bewijst:
/health).env.example en een README die in onder een minuut draaitCommit kleine mijlpalen vroeg zodat je veilig kunt terugdraaien als een gegenereerde wijziging fout gaat.
Prioriteer tests die dure fouten voorkomen:
In CI, handhaaf eenvoudige gates in deze volgorde:
Houd tests stabiel en snel; flaky suites stoppen met beschermen.