12 jun 2025·8 min
Van user stories naar databaseschema: een AI-gestuurde methode
Leer een praktische methode om user stories, entiteiten en workflows om te zetten in een helder databaseschema, en hoe AI je kan helpen hiaten en regels te controleren.
Leer een praktische methode om user stories, entiteiten en workflows om te zetten in een helder databaseschema, en hoe AI je kan helpen hiaten en regels te controleren.
Een databaseschema is het plan voor hoe je app dingen onthoudt. In praktische termen is het:
Als het schema overeenkomt met het echte werk, weerspiegelt het wat mensen daadwerkelijk doen—aanmaken, beoordelen, goedkeuren, plannen, toewijzen, annuleren—in plaats van wat op een whiteboard netjes klinkt.
User stories en acceptatiecriteria beschrijven echte behoeften in gewone taal: wie wat doet, en wat “klaar” betekent. Als je die als bron gebruikt, is de kans kleiner dat het schema belangrijke details mist (zoals “we moeten bijhouden wie de terugbetaling heeft goedgekeurd” of “een boeking kan meerdere keren worden verzet”).
Beginnen vanuit stories houdt je ook eerlijk over scope. Als iets niet in de stories (of de workflow) staat, behandel het dan als optioneel in plaats van stiekem een complex model te bouwen “voor het geval dat”.
AI kan je helpen sneller te werken door:
AI kan niet betrouwbaar:
Zie AI als een sterke assistent, niet als de beslisser.
Als je die assistent momentum wilt geven, kan een vibe-coding platform zoals Koder.ai je helpen sneller van schema-beslissingen naar een werkende React + Go + PostgreSQL-app te gaan—terwijl jij de controle houdt over het model, constraints en migraties.
Schema-ontwerp is een cyclus: ontwerpen → testen tegen stories → ontbrekende data vinden → verfijnen. Het doel is geen perfect eerste resultaat; het is een model dat je kunt herleiden tot elke user story en waar je met vertrouwen kunt zeggen: “Ja, we kunnen alles opslaan dat deze workflow nodig heeft—en we kunnen uitleggen waarom elke tabel bestaat.”
Voordat je vereisten in tabellen omzet, wees duidelijk over wat je modelleert. Een goed schema begint zelden vanaf blanco—het begint met concreet werk dat mensen doen en het bewijs dat je later nodig hebt (schermen, outputs en randgevallen).
User stories zijn de koptekst, maar ze zijn op zichzelf niet genoeg. Verzamel:
Als je AI gebruikt, houden deze inputs het model gegrond. AI kan snel entiteiten en velden voorstellen, maar heeft echte artefacten nodig om te voorkomen dat het structuur verzint die niet bij je product past.
Acceptatiecriteria bevatten vaak de belangrijkste database-regels, zelfs als ze data niet expliciet noemen. Let op uitspraken zoals:
Vage stories (“Als gebruiker kan ik projecten beheren”) verbergen meerdere entiteiten en workflows. Een andere veelvoorkomende kloof zijn ontbrekende randgevallen zoals annuleringen, retries, gedeeltelijke terugbetalingen of herschikkingen.
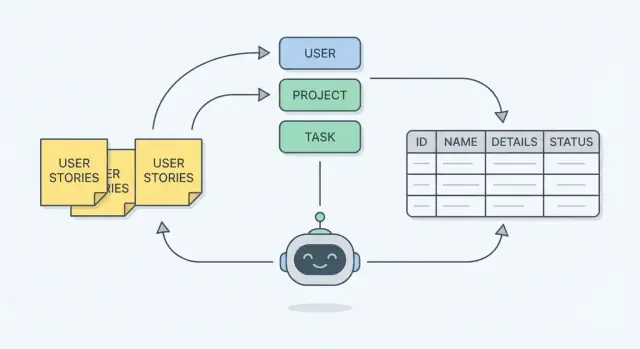
Voordat je aan tabellen of diagrammen denkt, lees de user stories en markeer de zelfstandige naamwoorden. In requirements wijzen naamwoorden meestal op de “dingen” die je systeem moet onthouden—die worden vaak entiteiten in je schema.
Een snel mentaal model: naamwoorden worden entiteiten, terwijl werkwoorden acties of workflows worden. Als een story zegt “Een manager wijst een technicus toe aan een klus”, zijn de waarschijnlijke entiteiten manager, technicus en klus—en “wijst toe” hint naar een relatie die je later zult modelleren.
Niet elk naamwoord verdient zijn eigen tabel. Een naamwoord is een sterke kandidaat voor een entiteit wanneer het:
Als een naamwoord slechts één keer voorkomt, of alleen iets anders beschrijft (“rode knop”, “vrijdag”), is het mogelijk geen entiteit.
Een veelgemaakte fout is elk detail in een tabel veranderen. Gebruik deze vuistregel:
Twee klassieke voorbeelden:
AI kan het ontdekken van entiteiten versnellen door stories te scannen en een conceptlijst met kandidaat-naamwoorden terug te geven, gegroepeerd op thema (mensen, werkitems, documenten, locaties). Een nuttige prompt is: “Extraheren van naamwoorden die data representeren die we moeten opslaan, en dupes/synoniemen groeperen.”
Behandel de output als een startpunt, niet als het antwoord. Stel vervolgvragen zoals:
Het doel van Stap 1 is een korte, schone lijst met entiteiten die je kunt verdedigen door terug te verwijzen naar echte stories.
Als je de entiteiten hebt genoemd (zoals Order, Customer, Ticket), is de volgende taak het vastleggen van de details die je later nodig hebt. In een database zijn die details velden (ook attributen genoemd)—de herinneringen die je systeem niet mag vergeten.
Begin met de user story en lees dan de acceptatiecriteria als een checklist van wat opgeslagen moet worden.
Als een vereiste zegt “Gebruikers kunnen bestellingen filteren op bezorgdatum”, dan is delivery_date geen optionele waarde—het moet bestaan als veld (of betrouwbaar afgeleid worden van andere opgeslagen data). Als er staat “Toon wie het verzoek goedkeurde en wanneer”, heb je waarschijnlijk approved_by en approved_at nodig.
Een praktische test: Heeft iemand dit nodig om te tonen, zoeken, sorteren, auditen of berekenen? Zo ja, dan hoort het waarschijnlijk als veld thuis.
Veel stories bevatten woorden als “status”, “type” of “priority”. Behandel deze als controlled vocabularies—een beperkte set toegestane waarden.
Als de set klein en stabiel is, werkt een eenvoudige enum-stijl veld. Als het kan groeien, labels nodig heeft of permissies vereist (bijv. admin-beheer), gebruik dan een aparte lookup-tabel (bijv. status_codes) en sla een verwijzing op.
Dit is hoe stories veranderen in velden waarop je kunt vertrouwen—doorzoekbaar, rapporteerbaar en lastig fout in te voeren.
Zodra je de entiteiten (User, Order, Invoice, Comment, enz.) hebt genoteerd en de velden hebt opgesteld, is de volgende stap ze te verbinden. Relaties zijn de laag “hoe deze dingen met elkaar omgaan” die in je stories wordt geïmpliceerd.
One-to-one (1:1) betekent “één ding heeft precies één van een ander ding.”
User ↔ Profile (vaak kun je deze samenvoegen tenzij er een reden is om ze te scheiden).One-to-many (1:N) betekent “één ding kan veel van een ander ding hebben.” Dit is het meest voorkomend.
User → Order (sla user_id op in Order).Many-to-many (M:N) betekent “veel dingen kunnen op veel dingen betrekking hebben.” Dit vereist een extra tabel.
Databases kunnen niet netjes een “lijst met product IDs” in Order opslaan zonder later problemen (zoeken, updaten, rapporteren). Maak in plaats daarvan een join-tabel die de relatie zelf vertegenwoordigt.
Voorbeeld:
OrderProductOrderItem (join-tabel)OrderItem bevat typisch:
order_idproduct_idquantity, unit_price, discountMerk op dat details uit de story (“quantity”) vaak op de relatie horen, niet op een van de entiteiten.
Stories vertellen ook of een verbinding verplicht is of soms ontbreekt.
Order heeft user_id (niet leeg toestaan).phone kan leeg zijn.shipping_address_id kan leeg zijn voor digitale orders.Een snelle check: als de story impliceert dat je het record niet kunt aanmaken zonder de link, behandel het als verplicht. Als er uitzonderingen zijn, behandel het als optioneel.
Als je een story leest, herschrijf deze dan als een eenvoudige koppeling:
User 1:N CommentComment N:1 UserDoe dit voor elke interactie in je stories. Tegen het einde heb je een verbonden model dat overeenkomt met hoe het werk werkelijk gebeurt—voordat je ooit een ER-diagram-tool opent.
User stories vertellen wat mensen willen. Workflows laten zien hoe werk daadwerkelijk beweegt, stap voor stap. Een workflow naar data vertalen is een van de snelste manieren om “we vergaten dit op te slaan” problemen te ontdekken—voordat je iets bouwt.
Schrijf de workflow als een sequentie van acties en statusveranderingen. Bijvoorbeeld:
Die vette woorden worden vaak een status-veld (of een kleine “state”-tabel) met duidelijke toegestane waarden.
Terwijl je elke stap doorloopt, vraag: “Wat moeten we later weten?” Workflows tonen vaak velden zoals:
submitted_at, approved_at, completed_atcreated_by, assigned_to, approved_byrejection_reason, approval_notesequence voor multi-step processenAls je workflow wachten, escalatie of overdrachten bevat, heb je meestal minstens één timestamp en één “wie heeft het nu” veld nodig.
Sommige stappen in workflows zijn niet alleen velden—het zijn aparte datastructuren:
Geef AI zowel: (1) de user stories en acceptatiecriteria, en (2) de workflow-stappen. Vraag het een lijst te maken van elke stap en welke data voor elke stap nodig is (state, actor, timestamps, outputs), en laat het alle vereisten markeren die niet door de huidige velden/tabellen worden ondersteund.
In platforms zoals Koder.ai wordt deze “gap check” vooral praktisch omdat je snel kunt itereren: pas schema-veronderstellingen aan, genereer scaffolding opnieuw en blijf vooruitgaan zonder langdurige handmatige overhead.
Als je user stories naar tabellen omzet, lijst je niet alleen velden op—je bepaalt ook hoe data identificeerbaar en consistent blijft.
Een primaire sleutel identificeert uniek één record—denk aan het als het permanente ID-kaartje van een rij.
Waarom elke rij er één nodig heeft: stories impliceren updates, verwijzingen en historie. Als een story zegt “Support kan een order bekijken en een terugbetaling uitvoeren”, heb je een stabiele manier nodig om naar de order te verwijzen—ook als de klant zijn email verandert, het adres wordt bewerkt of de orderstatus wijzigt.
In de praktijk is dit meestal een interne id (nummer of UUID) die nooit verandert.
Een foreign key is hoe de ene tabel veilig naar een andere wijst. Als orders.customer_id verwijst naar customers.id, kan de database afdwingen dat elke order bij een echte klant hoort.
Dit sluit aan bij stories als “Als gebruiker kan ik mijn facturen zien.” De factuur zweeft niet—het hangt aan een klant (en vaak aan een order of abonnement).
User stories bevatten regelmatig verborgen uniciteitsvereisten:
Deze regels voorkomen verwarrende duplicaten die later als “dataproblemen” naar boven komen.
Indexes versnellen zoekacties zoals “vind klant op e-mail” of “lijst orders per klant”. Begin met indexes die aansluiten op je meest voorkomende queries en uniciteitsregels.
Wat uit te stellen: zware indexering voor zeldzame rapporten of speculatieve filters. Leg die behoeften vast in stories, valideer het schema eerst en optimaliseer later op basis van echte gebruiksdata en langzame query's.
Normalisatie heeft één eenvoudig doel: voorkom conflicterende duplicaten. Als hetzelfde feit op twee plekken kan worden opgeslagen, zullen ze op den duur verschillen (twee spellingen, twee prijzen, twee “huidige” adressen). Een genormaliseerd schema slaat elk feit één keer op en verwijst ernaar.
1) Let op herhaalde groepen
Als je patronen ziet zoals “Phone1, Phone2, Phone3” of “ItemA, ItemB, ItemC”, is dat een signaal voor een aparte tabel (bijv. CustomerPhones, OrderItems). Herhaalde groepen maken zoeken, valideren en schalen moeilijk.
2) Kopieer niet dezelfde naam/details in meerdere tabellen
Als CustomerName in Orders, Invoices en Shipments staat, creëer je meerdere bronnen van waarheid. Houd klantgegevens in Customers en sla alleen customer_id elders op.
3) Vermijd meerdere kolommen voor hetzelfde ding
Kolommen zoals billing_address, shipping_address, home_address kunnen prima zijn als het echt verschillende concepten zijn. Maar als je in feite “veel adressen van verschillende types” modelleert, gebruik dan een Addresses-tabel met een type-veld.
4) Scheid lookups van vrije tekst
Als gebruikers uit een bekende set kiezen (status, categorie, rol), modelleer dat consequent: ofwel als een begrensde enum of als een lookup-tabel. Dit voorkomt “Pending” vs “pending” vs “PENDING.”
5) Check dat elk niet-ID veld afhangt van het juiste ding
Een nuttige controle: in een tabel, als een kolom iets anders beschrijft dan de hoofdentiteit van de tabel, hoort het waarschijnlijk ergens anders. Voorbeeld: Orders zou product_price niet moeten bevatten tenzij het de “prijs op het moment van bestelling” is (een historisch snapshot).
Soms sla je duplicaten bewust op:
Belangrijk is dat het intentioneel is: document welke kolom de bron van waarheid is en hoe kopieën worden bijgewerkt.
AI kan verdachte duplicatie signaleren (herhaalde kolommen, vergelijkbare veldnamen, inconsistente “status”-velden) en splitsingen naar tabellen voorstellen. Mensen maken nog steeds de afweging—simpliciteit vs. flexibiliteit vs. performance—gebaseerd op hoe het product daadwerkelijk gebruikt wordt.
Een nuttige regel: sla feiten op die je niet betrouwbaar later kunt recreëren; bereken de rest.
Opgeslagen data is de bron van waarheid: individuele lijnitems, timestamps, statuswijzigingen, wie wat deed. Berekende (afgeleide) data komt voort uit die feiten: totalen, counters, flags zoals “is overdue”, en rollups zoals “huidige voorraad”.
Als twee waarden uit dezelfde onderliggende feiten berekend kunnen worden, geef dan de voorkeur aan het opslaan van de feiten en het berekenen van de rest. Anders riskeer je tegenstrijdigheden.
Afgeleide waarden veranderen wanneer hun inputs veranderen. Als je zowel de inputs als het resultaat opslaat, moet je ze synchroon houden in elke workflow en elk randgeval (bewerkingen, refunds, gedeeltelijke leveringen, backdated changes). Eén gemiste update en de database vertelt twee verschillende verhalen.
Voorbeeld: order_total opslaan terwijl je ook order_items opslaat. Als iemand een hoeveelheid wijzigt of een korting toepast en de total niet perfect wordt bijgewerkt, ziet finance een ander cijfer dan de winkelwagen.
Workflows laten zien wanneer je historische waarheid nodig hebt, niet alleen de huidige staat. Als gebruikers moeten weten wat de waarde was op dat moment, sla dan een snapshot op.
Voor een order kun je opslaan:
order_total bij het afrekenen (snapshot), omdat belastingen, kortingen en prijsregels later kunnen veranderenVoor voorraad wordt “voorraadniveau” vaak berekend uit bewegingen (ontvangsten, verkopen, aanpassingen). Maar als je een audittrail nodig hebt, sla je de bewegingen op en eventueel periodieke snapshots voor rapportagesnelheid.
Voor inlogtracking sla je last_login_at op als feit (een event timestamp). “Is actief in de laatste 30 dagen?” blijft een berekening.
Laten we een bekend support ticket-app gebruiken. We gaan van vijf user stories naar een eenvoudig ER-model (entiteiten + velden + relaties) en checken het tegen één workflow.
Uit die naamwoorden halen we de kernentiteiten:
Voor (veelvoorkomend gemis): Ticket heeft assignee_id, maar we vergaten ervoor te zorgen dat alleen agents als assignees kunnen worden ingesteld.
Na: AI signaleert dit en je voegt een praktische regel toe: assignee moet een User met role = “agent” zijn (geïmplementeerd via applicatievalidatie of een database constraint/policy, afhankelijk van je stack). Dit voorkomt “toegewezen aan klant” data die rapporten later breekt.
Een schema is pas “klaar” wanneer elke user story beantwoord kan worden met data die je daadwerkelijk kunt opslaan en opvragen. De eenvoudigste validatiestap is elke story te pakken en te vragen: “Kunnen we deze vraag betrouwbaar uit de database beantwoorden, in alle gevallen?” Als het antwoord “misschien” is, heeft je model een gat.
Herschrijf elke user story als een of meer testvragen—zaken die je van een rapport, scherm of API zou verwachten. Voorbeelden:
Als je een story niet als een duidelijke vraag kunt formuleren, is de story onduidelijk. Als je het wel kunt formuleren—maar het schema kan het antwoord niet geven—dan mis je een veld, relatie, status/event of constraint.
Maak een klein datasetje (5–20 rijen per belangrijke tabel) met normale en lastige gevallen (duplicaten, missende waarden, annuleringen). Speel vervolgens de stories door met die data. Je ziet snel problemen zoals “we kunnen niet bepalen welk adres op dat moment is gebruikt” of “we hebben nergens vastgelegd wie de wijziging heeft goedgekeurd”.
Vraag AI validatievragen per story te genereren (inclusief randgevallen en deletiescenario’s) en lijst welke data nodig is om ze te beantwoorden. Vergelijk die lijst met je schema: iedere mismatch is een concrete actielijst, geen vaag gevoel dat “er iets mis is”.
AI kan het datamodelleren versnellen, maar het verhoogt ook het risico op het lekken van gevoelige informatie of het vastleggen van slechte aannames. Behandel het als een zeer snelle assistent: nuttig, maar met harnassen.
Deel inputs die realistisch zijn om te modelleren, maar geanonimiseerd genoeg om veilig te zijn:
invoice_total: 129.50, status: "paid")Vermijd alles dat personen identificeert of vertrouwelijke operaties onthult:
Als je realisme nodig hebt, genereer synthetische voorbeelden die formats en bereiken nabootsen—kopieer nooit productierijen.
Schemas mislukken meestal omdat “iedereen aannam” dat iets zo werkte. Houd naast je ER-model (of in dezelfde repo) een korte beslislog bij:
Dit maakt AI-output teamkennis in plaats van een eenmalig artefact.
Je schema zal evolueren met nieuwe stories. Houd het veilig door:
Als je een platform zoals Koder.ai gebruikt, profiteer dan van guardrails zoals snapshots en rollback wanneer je schemas verandert, en exporteer de broncode als je diepere aanpassingen of traditionele reviews nodig hebt.
Begin met de stories en markeer de zelfstandige naamwoorden die dingen vertegenwoordigen die je systeem moet onthouden (bijv. Ticket, User, Category).
Promoveer een zelfstandig naamwoord naar een entiteit wanneer het:
Houd een korte lijst bij die je kunt rechtvaardigen door naar specifieke zinnen in de stories te verwijzen.
Gebruik een “attribuut vs. entiteit”-test:
customer.phone_number).Een snelle tip: als je ooit “veel van deze” nodig hebt, heb je waarschijnlijk een extra tabel nodig.
Behandel acceptatiecriteria als een opslag-checklist. Als een vereiste zegt dat je iets moet filteren/sorteren/tonen/auditen, moet je het opslaan (of betrouwbaar afleiden).
Voorbeelden:
approved_by, approved_atdelivery_dateHerschrijf story-zinnen naar relatiezinnen:
customer_id op orders)order_items)Als de relatie zelf data heeft (quantity, price, role), hoort die data op de join-tabel.
Model M:N met een join-tabel die beide foreign keys bevat plus relationele velden.
Typisch patroon:
ordersproductsLoop de workflow stap voor stap door en vraag: “Wat moeten we later kunnen bewijzen?”
Veelvoorkomende aanvullingen:
submitted_at, closed_atBegin met:
id)orders.customer_id → customers.id)Voeg daarna indexes toe voor je meest voorkomende zoekacties (bijv. , , ). Stel speculatieve indexering uit tot je echte querypatronen ziet.
Run een snelle consistentie-check:
Phone1/Phone2, splitst dan naar een child-tabel.Denormaliseer later alleen met een duidelijk doel (performance, rapportage, audit snapshots) en documenteer wat de autoritatieve bron is.
Sla feiten op die je later niet betrouwbaar kunt recreëren; bereken de rest.
Goed om op te slaan:
Goed om te berekenen:
Als je afgeleide waarden opslaat (zoals ), beslis hoe die synchroon gehouden worden en test edit-, refund- en gedeeltelijke scenario’s.
Gebruik AI voor drafts en verifieer altijd tegen je artifacts.
Praktische prompts:
Guardrails:
emailorder_items met order_id, product_id, quantity, unit_priceVermijd het opslaan van “een lijst met IDs” in één kolom—zoeken, bijwerken en integriteit afdwingen wordt dan lastig.
created_by, assigned_to, closed_byrejection_reasonAls je wilt weten “wie wat wanneer heeft veranderd”, voeg dan een event-/audit-tabel toe in plaats van één veld te overschrijven.
emailcustomer_idstatus + created_atorder_total