Wat semantische zoekopdracht betekent (zonder jargon)
Semantische zoekopdracht is een manier van zoeken die focust op wat je bedoelt, niet alleen op de exacte woorden die je typt.
Als je ooit iets hebt gezocht en dacht: “het antwoord staat hier duidelijk—waarom vindt het het niet?”, dan heb je de beperkingen van keyword search gevoeld. Traditioneel zoeken matcht termen. Dat werkt wanneer de bewoording in je query en de bewoording in de content overlappen.
Waarom keyword search vaak tekortschiet
Keyword search heeft moeite met:
- Synoniemen en formuleringen: “cancel” vs “close” vs “terminate” een account.
- Intentie: “hoe stop ik gefactureerd te worden?” gaat eigenlijk over het opzeggen van een abonnement.
- Context: “apple charger” (merk) vs “apple tree charger” (onzin, maar je snapt het idee).
Het kan ook te veel waarde toekennen aan herhaalde woorden, waardoor resultaten oppervlakkig relevant lijken terwijl de pagina die het antwoord echt bevat andere woorden gebruikt.
Een simpel voorbeeld
Stel je een helpcenter voor met een artikel getiteld “Pause or cancel your subscription.” Een gebruiker zoekt:
“stop my payments next month”
Een keyword-systeem zou dat artikel misschien niet hoog ranken als het de woorden “stop” of “payments” niet bevat. Semantische zoekopdracht begrijpt dat “stop my payments” sterk gerelateerd is aan “cancel subscription” en brengt dat artikel naar de top—omdat de betekenis overeenkomt.
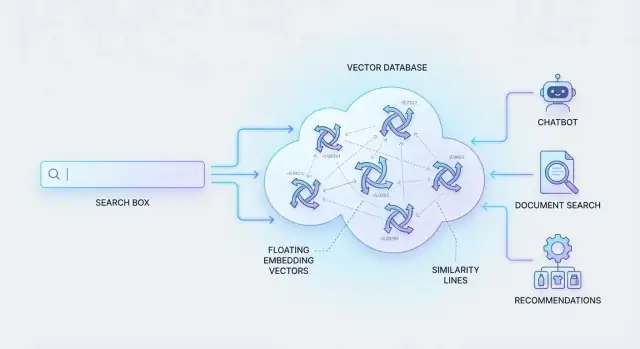
Waar vector-databases passen
Om dit te laten werken, representeren systemen content en queries als “betekenisvingerafdrukken” (getallen die gelijkenis vastleggen). Daarna moeten ze door miljoenen van die vingafdrukken zoeken, en dat snel.
Dat is waar vector-databases voor gebouwd zijn: ze slaan deze numerieke representaties op en halen de meest vergelijkbare matches efficiënt op, zodat semantisch zoeken zelfs op grote schaal direct aanvoelt.
Embeddings: content omzetten in betekenisvolle vectoren
Een embedding is een numerieke representatie van betekenis. In plaats van een document met keywords te beschrijven, representeren we het als een lijst met getallen (een “vector”) die vastlegt waar de content over gaat. Twee stukken content met vergelijkbare betekenis krijgen vectoren die dicht bij elkaar liggen in die numerieke ruimte.
Hoe een embedding er werkelijk uitziet
Zie een embedding als een coördinaat op een extreem hoog-dimensionale kaart. Je zult de getallen meestal niet rechtstreeks lezen—ze zijn niet bedoeld om mensvriendelijk te zijn. Hun meerwaarde zit in hun gedrag: als “cancel my subscription” en “how do I stop my plan?” nabijgelegen vectoren opleveren, kan het systeem ze als gerelateerd behandelen, zelfs bij weinig of geen gedeelde woorden.
Tekst, afbeeldingen en audio kunnen allemaal vectoren worden
Embeddings zijn niet beperkt tot tekst.
- Tekst-embeddings representeren zinnen, paragrafen, supporttickets, productbeschrijvingen en meer.
- Image-embeddings representeren visuele gelijkenis en concepten (bijv. “rode hardloopschoenen”).
- Audio-embeddings kunnen sprekers, toon of de betekenis van gesproken woorden vastleggen wanneer ze met spraakmodellen worden gecombineerd.
Zo kan één vector-database “zoeken met een afbeelding”, “vind vergelijkbare nummers” of “raad producten zoals deze” ondersteunen.
Geproduceerd door modellen—niet handmatig
Vectoren komen niet uit handmatige tags. Ze worden geproduceerd door machine learning-modellen die getraind zijn om betekenis in getallen samen te drukken. Je stuurt content naar een embedding-model (gehost door jezelf of een provider) en het retourneert een vector. Je app slaat die vector op naast de originele content en metadata.
Waarom de keuze van embedding kwaliteit en kosten beïnvloedt
Het gekozen embedding-model beïnvloedt sterk de resultaten. Grotere of gespecialiseerde modellen verbeteren vaak de relevantie maar kosten meer (en kunnen trager zijn). Kleinere modellen zijn goedkoper en sneller, maar missen soms nuance—vooral bij domeinspecifieke taal, meerdere talen of korte queries. Veel teams testen een paar modellen vroeg om de beste trade-off te vinden voordat ze schalen.
Hoe vector-databases data opslaan
Een vector-database draait om een simpel idee: sla “betekenis” (een vector) op samen met de informatie die je nodig hebt om resultaten te identificeren, te filteren en te tonen.
Het basisgegevensmodel
De meeste records zien er zo uit:
- ID: een unieke identifier die jij beheert (bijv.
doc_18492 of een UUID)
- Vector (embedding): een array met getallen die de betekenis van de content representeren
- Metadata: key–value velden zoals title, URL, tags, author, language, created_at, of tenant_id
Bijvoorbeeld, een helpcenter-artikel kan opslaan:
- ID:
kb_123
- Vector: 768 floating-point nummers (voor een veelgebruikt embedding-model)
- Metadata:
{ "title": "Reset your password", "url": "/help/reset-password", "tags": ["account", "security"] }
De vector drijft semantische gelijkenis; de ID en metadata maken resultaten bruikbaar.
Metadata vervult twee taken:
- Filteren vóór/na vector-zoekopdracht: “Toon alleen resultaten van product X”, “Alleen Engels”, “Alleen documenten die de gebruiker mag zien”, of “Alleen items nieuwer dan 90 dagen.” Dit is essentieel voor relevantie en toegangscontrole.
- Weergave en acties: gebruikers willen geen vector zien—ze willen een title, een snippet en een link (URL). Metadata levert de details die je UI nodig heeft.
Zonder goede metadata haal je misschien de juiste betekenis op maar toon je nog steeds de verkeerde context.
Gebruikelijke vectorgroottes en opslaggevolgen
De grootte van een embedding hangt af van het model: 384, 768, 1024, en 1536 dimensies zijn gangbaar. Meer dimensies kunnen nuance vastleggen, maar vergroten ook:
- Opslag (elk record slaat meer getallen op)
- Geheugendruk voor snelle zoekopdrachten
- Indexbouwtijd (vooral bij ANN-indexering)
Als grove vuistregel: het verdubbelen van dimensies duwt meestal kosten en latency omhoog tenzij je dat compenseert met indexkeuzes of compressie.
Updatepatronen: inserts, wijzigingen en deletions
Reële datasets veranderen, dus vector-databases ondersteunen doorgaans:
- Insert: nieuwe content toevoegen met embedding en metadata
- Update: metadata wijzigen (bijv. tags) of de vector vervangen als de content verandert
- Delete: verouderde of ingetrokken content verwijderen
- Re-embed: vectors opnieuw berekenen bij modelwissel, andere chunking of grote tekstwijzigingen
Vroegtijdig plannen voor updates voorkomt een “verouderde kennis”-probleem waarbij zoekopdrachten content teruggeven die niet meer overeenkomt met de actuele informatie.
Similarity search: snel de “dichtstbijzijnde betekenis” vinden
Zodra tekst, afbeeldingen of producten zijn omgezet in embeddings (vectoren), wordt zoeken een geometrisch probleem: “Welke vectoren liggen het dichtst bij deze query-vector?” Dit heet nearest-neighbor search. In plaats van keywords te matchen, vergelijkt het systeem betekenis door te meten hoe dicht twee vectoren bij elkaar liggen.
Nearest neighbors in gewone taal
Beeld elk stuk content als een punt in een enorme multi-dimensionale ruimte. Wanneer een gebruiker zoekt, wordt de query omgezet in een ander punt. Similarity search geeft de items terug waarvan de punten het dichtst bij dat punt liggen—je “nearest neighbors.” Die buren delen waarschijnlijk intentie, onderwerp of context, zelfs als ze geen exacte woorden delen.
Gebruikelijke similarity-metrics
Vector-databases ondersteunen meestal een paar standaardmanieren om “dichtheid” te scoren:
- Cosine similarity: vergelijkt de hoek tussen vectoren (goed wanneer richting/betekenis belangrijker is dan magnitude).
- Dot product: verwant aan cosine, maar beïnvloed door vectorlengte; vaak gebruikt met genormaliseerde embeddings.
- Euclidische afstand: de rechte-lijn afstand tussen punten (bruikbaar in sommige modellen en domeinen).
Verschillende embedding-modellen zijn getraind met een bepaalde metric in gedachten, dus gebruik de metric die de modelprovider aanbeveelt.
Exacte zoekopdracht vs approximation (ANN)
Een exacte zoekopdracht vergelijkt elke vector om de echte dichtstbijzijnde buren te vinden. Dat is accuraat, maar traag en duur op miljoenen items.
De meeste systemen gebruiken approximate nearest neighbor (ANN)-search. ANN gebruikt slimme indexstructuren om de zoekruimte te beperken tot de meest veelbelovende kandidaten. Meestal krijg je resultaten die “goed genoeg” zijn voor de echte beste matches—maar veel sneller.
De latency versus recall-trade-off
ANN is populair omdat je kunt tunen voor wat je nodig hebt:
- Lagere latency (snellere reacties) door minder kandidaten te doorzoeken.
- Hogere recall (meer van de echte top-matches vinden) door meer te doorzoeken.
Daarom werkt vector search goed in echte apps: je houdt reacties vlot en levert toch relevante resultaten.
De end-to-end workflow van semantische zoekopdrachten
Semantische zoekopdracht is het makkelijkst te begrijpen als een eenvoudige pijplijn: je zet tekst om in betekenis, zoekt vergelijkbare betekenis op, en presenteert de meest bruikbare matches.
1) Embed de query
Een gebruiker typt een vraag (bijv. “How do I cancel my plan without losing data?”). Het systeem stuurt die tekst naar een embeddings-model en krijgt een vector terug—een array met getallen die de betekenis van de query representeren in plaats van de exacte woorden.
2) Zoek in de vector-database
Die query-vector wordt naar de vector-database gestuurd, die similarity search uitvoert om de “dichtstbijzijnde” vectoren in je opgeslagen content te vinden.
De meeste systemen geven top-K matches terug: de K meest vergelijkbare chunks/documenten.
- Waarom K configureerbaar is: een kleinere K is sneller en vaak voldoende (bijv. K=5).
- Een grotere K verhoogt recall (je mist minder snel het juiste antwoord), maar kan ook meer “bijna relevante” resultaten bevatten (bijv. K=50).
3) (Optioneel) Rerank voor precisie
Similarity search is geoptimaliseerd voor snelheid, dus de initiële top-K kan near-misses bevatten. Een reranker is een tweede model dat de query en elk kandidaatresultaat samen bekijkt en ze herordent op relevantie.
Zie het als: vector search geeft je een sterke shortlist; reranking kiest de beste volgorde.
4) Resultaten retourneren (of doorvoeren)
Uiteindelijk retourneer je de beste matches aan de gebruiker (als zoekresultaten), of je geeft ze door aan een AI-assistent (bijvoorbeeld een RAG-systeem) als de “grondslag” van het antwoord.
Als je dit in een app bouwt, kunnen platforms zoals Koder.ai je helpen snel te prototypen: je beschrijft de semantische zoek- of RAG-ervaring in een chatinterface en iterateert vervolgens aan de React-front end en Go/PostgreSQL-backend terwijl de retrieval-pijplijn (embedding → vector search → optionele rerank → antwoord) een first-class onderdeel van het product blijft.
Een kort “keywords vs semantisch” voorbeeld
Als je helpcenter-artikel “terminate subscription” zegt en de gebruiker zoekt “cancel my plan”, kan keyword search het missen omdat “cancel” en “terminate” niet matchen.
Semantische zoekopdracht haalt het meestal wel op omdat de embedding vastlegt dat beide zinnen dezelfde intentie uitdrukken. Voeg reranking toe en de topresultaten worden vaak niet alleen “vergelijkbaar”, maar direct bruikbaar voor de vraag van de gebruiker.
Build semantic search fast
Prototypeer een semantische zoekstroom in chat, verfijn daarna de React-UI en Go-backend.
Pure vector search is sterk in “betekenis”, maar gebruikers zoeken niet altijd op betekenis. Soms hebben ze een exacte match nodig: iemands volledige naam, een SKU, een factuurnummer of een foutcode gekopieerd uit een log. Hybride zoekopdrachten combineren semantische signalen (vectoren) met lexicale signalen (traditionele keyword search zoals BM25).
Wat hybride zoekopdracht daadwerkelijk doet
Een hybride query draait doorgaans twee paden parallel:
- Vector search: vindt content die conceptueel vergelijkbaar is, zelfs als de bewoording verschilt.
- Keyword/BM25 search: vindt content die dezelfde tokens deelt en geeft beloning aan exacte termen en zeldzame woorden.
Het systeem voegt die kandidaten samen tot één gerangschikte lijst.
Wanneer hybride de betere standaard is
Hybride search blinkt uit wanneer je data “must-match” strings bevat:
- Productnamen met specifieke modifiers (bijv. “Pro Max”, “Gen 2”)
- ID's (ordernummers, ticket-ID's, onderdeelnummers)
- Foutcodes (“E0421”, “ORA-00933”) en command flags
- Zeldzame domeintermen waar synoniemen riskant zijn
Semantische search alleen kan brede, verwante pagina’s teruggeven; keyword search alleen mist mogelijk relevante antwoorden die anders geformuleerd zijn. Hybride dekt beide faalgevallen.
Metadata-filters beperken retrieval vóór ranking (of ernaast), wat relevantie en snelheid verbetert. Veelvoorkomende filters zijn:
- Taal (alleen Engels teruggeven)
- Datumbereik (laatste beleid, nieuwste release notes)
- Categorie of bron (docs vs tickets; “billing” vs “security”)
- Toegangscontroles (alleen wat deze gebruiker mag zien)
Hoe scoring werkt (hoog niveau)
De meeste systemen gebruiken een praktische mix: voer beide zoektypen uit, normaliseer scores zodat ze vergelijkbaar zijn, en pas gewichten toe (bijv. “leg meer nadruk op keywords voor ID's”). Sommige producten reranken de samengevoegde shortlist met een lichtgewicht model of regels, terwijl filters zorgen dat je de juiste subset rangschikt.
RAG: vector-databases gebruiken om LLM-antwoorden te onderbouwen
Retrieval-Augmented Generation (RAG) is een praktisch patroon om betrouwbaardere antwoorden van een LLM te krijgen: haal eerst relevante informatie op, genereer daarna een antwoord dat gekoppeld is aan die opgehaalde context.
Het RAG-idee in één zin
In plaats van het model te vragen je bedrijfsdocumenten te “onthouden”, sla je die documenten op (als embeddings) in een vector-database, haal je de meest relevante chunks op op het moment van de vraag, en geef je die als ondersteunende context aan de LLM.
Waarom een vector-database hallucinerende antwoorden helpt verminderen
LLM's zijn uitstekend in schrijven, maar vullen gaten vaak zelfverzekerd in wanneer ze de benodigde feiten niet hebben. Een vector-database maakt het eenvoudig om de dichtstbijzijnde passages uit je kennisbank op te halen en die in de prompt te zetten.
Die grounding verschuift het model van “een antwoord verzinnen” naar “deze bronnen samenvatten en uitleggen.” Het maakt antwoorden ook makkelijker te auditen omdat je kunt bijhouden welke chunks zijn opgehaald en eventueel citaties kunt tonen.
Chunking basics (zodat retrieval echt werkt)
De kwaliteit van RAG hangt vaak meer van chunking af dan van het model.
- Grootte van chunks: streef naar chunks die een volledige gedachte bevatten (vaak een korte sectie). Te klein verliest betekenis; te groot haalt ruis binnen.
- Overlap: voeg een kleine overlap toe zodat belangrijke details op grenzen niet uit context worden gesneden.
- Behoud context: bewaar titels, koppen en identificatoren (docnaam, sectie, datum) als metadata zodat resultaten begrijpelijk en filterbaar blijven.
Eenvoudige RAG-pijplijn (beschrijving)
Beeld deze flow in:
Gebruikersvraag → Embed vraag → Vector DB haalt top-k chunks op (+ optionele metadata-filters) → Bouw prompt met opgehaalde chunks → LLM genereert antwoord → Retourneer antwoord (en bronnen).
De vector-database zit in het midden als het “snelle geheugen” dat het meest relevante bewijs voor elk verzoek aanlevert.
Veelvoorkomende AI-use-cases aangedreven door vector-databases
Deploy your AI app
Ga van een lokaal idee naar een gehoste app die je met je team kunt delen.
Vector-databases maken zoeken niet alleen “slimmer”—ze maken productervaringen mogelijk waarin gebruikers in natuurlijke taal beschrijven wat ze willen en toch relevante resultaten krijgen. Hieronder een paar praktische use-cases die vaak terugkomen.
Klantenondersteuning: antwoorden vinden voorbij keywords
Supportteams hebben vaak een kennisbank, oude tickets, chattranscripten en release notes—maar keyword search worstelt met synoniemen, parafrasering en vage probleemomschrijvingen.
Met semantische zoekopdracht kan een agent (of chatbot) oude tickets ophalen die hetzelfde betekenen, zelfs als de bewoording anders is. Dat versnelt oplossingen, vermindert dubbele inspanning en helpt nieuwe agenten sneller op snelheid te komen. Combineer vector search met metadata-filters (productlijn, taal, issue-type, datumbereik) om resultaten gefocust te houden.
Productontdekking: catalogi zoeken zoals mensen praten
Shoppers kennen zelden de exacte productnamen. Ze zoeken op intenties als “klein rugzakje dat een laptop past en er professioneel uitziet.” Embeddings vangen die voorkeuren—stijl, functie, beperkingen—zodat de resultaten aanvoelen als een menselijke verkoper.
Deze aanpak werkt voor retailcatalogi, reisaanbiedingen, vastgoed, vacatures en marktplaatsen. Je kunt semantische relevantie ook mengen met gestructureerde beperkingen zoals prijs, maat, beschikbaarheid of locatie.
Aanbevelingen: “vergelijkbare items” en contentontdekking
Een klassiek vector-database-feature is “vind items zoals dit.” Als een gebruiker een product bekijkt, een artikel leest of een video kijkt, kun je andere content ophalen met vergelijkbare betekenis of eigenschappen—zelfs als categorieën niet precies overeenkomen.
Dit is nuttig voor:
- “Meer zoals dit” modules
- Gerelateerde artikelen en kennisbank-suggesties
- Detectie van duplicaten of bijna-duplicaten (voor moderatie of opschoning)
Interne zoekfunctie met permissies: beleidsdocumenten, notulen, meetingnotes
Binnen bedrijven is informatie verspreid over documenten, wiki's, PDF's en notulen. Semantische zoekopdracht helpt medewerkers natuurlijke vragen te stellen (“Wat is ons declaratiebeleid voor conferenties?”) en het juiste document te vinden.
Het niet-onderhandelbare onderdeel is toegang. Resultaten moeten permissies respecteren—vaak door te filteren op team, documenteigenaar, vertrouwelijkheidsniveau of een ACL-lijst—zodat gebruikers alleen vinden wat ze mogen zien.
Als je dit verder wilt brengen, is dezelfde retrieval-laag wat grounded Q&A-systemen aandrijft (besproken in het RAG-gedeelte).
Datapijplijnen: ingestie, chunking en updates
Een semantisch zoeksysteem is zo goed als de pijplijn die het voedt. Als documenten inconsistent binnenkomen, slecht gechunked worden of nooit opnieuw ge-embed nadat ze zijn bewerkt, weekt de kwaliteit af van wat gebruikers verwachten.
Een eenvoudige ingestiestroom (die werkt)
De meeste teams volgen deze herhaalbare volgorde:
- Verzamel data (docs, PDF's, tickets, chatlogs, wiki-pagina's, productdata).
- Reinig (verwijder boilerplate, fix encoding, normaliseer whitespace, extraheer hoofdtekst).
- Chunk (splits in hapklare passages die gebruikers waarschijnlijk willen ophalen).
- Embed (genereer vectors met je gekozen embedding-model).
- Upsert (schrijf vectors + metadata naar de vector-database, vervang waar nodig).
De “chunk”-stap is waar veel pijplijnen winnen of verliezen. Chunks die te groot zijn verwateren betekenis; te klein verliezen context. Een praktische aanpak is chunken op natuurlijke structuur (koppen, paragrafen, Q&A-paren) en een kleine overlap te houden voor continuïteit.
Embeddings actueel houden
Content verandert continu—beleid wordt bijgewerkt, prijzen veranderen, artikelen worden herschreven. Behandel embeddings als afgeleide data die opnieuw gegenereerd moeten worden.
Gangbare tactieken:
- Sla een source document ID, chunk ID en een content hash op. Als de hash verandert, re-embed die chunk.
- Gebruik soft deletes (markeer oude chunks als inactief) om ghost-resultaten te vermijden.
- Herbouw selectief in plaats van alles opnieuw te embedden.
Batch vs streaming updates
- Batch past bij grote backfills, nachtelijke syncs en voorspelbare content (documentatie, kennisbanken).
- Streaming past bij snel veranderende bronnen (supporttickets, user-generated content, inventory). Het vermindert veroudering maar vereist betere monitoring en kostenbeheersing.
Meerdere talen en meerdere modellen
Als je meerdere talen bedient, kun je een multilingual embedding-model gebruiken (simpeler) of per-taal modellen (soms hogere kwaliteit). Versioneer embeddings (bijv. embedding_model=v3) als je met modellen experimenteert, zodat je A/B-tests kunt draaien en terug kunt rollen zonder zoekfunctionaliteit te breken.
Hoe kwaliteit en prestaties te evalueren
Semantische zoekopdracht kan in een demo goed aanvoelen en toch falen in productie. Het verschil is meting: je hebt duidelijke relevantiemetrics en snelheidsdoelen nodig, geëvalueerd op queries die op echt gebruikersgedrag lijken.
Relevantiemetrics die gebruikers tevredenheid reflecteren
Begin met een kleine set metrics en houd daaraan vast:
- Precision / Recall: Precision vertelt hoeveel teruggegeven resultaten echt relevant zijn; recall vertelt hoeveel relevante items je überhaupt terughaalde. Gebruik deze als je een duidelijke definitie van “relevant” hebt.
- MRR (Mean Reciprocal Rank): Goed wanneer gebruikers één “beste” antwoord verwachten. Het beloont het juiste document hoog in de resultaten.
- nDCG: Handig als meerdere resultaten relevant kunnen zijn op verschillende niveaus (zeer relevant vs enigszins relevant).
- Latency (p50/p95): Volg zowel gemiddelde als tail-latency. Een snelle p50 met een trage p95 voelt nog steeds traag voor gebruikers.
Bouw een testset waarop je kunt vertrouwen
Maak een evaluatieset van:
- Echte queries uit zoeklogs of supporttickets (geanonimiseerd).
- Verwachte documenten (gouden labels) afgesproken door domeinexperts.
- Edge cases: korte queries (“refund”), lange vragen, ambiguïteit, zeldzame productnamen en “no-result” queries waarbij het juiste gedrag is om “niets gevonden” te zeggen.
Versioneer de testset zodat je resultaten tussen releases kunt vergelijken.
A/B-testen en feedbackloops
Offline metrics vangen niet alles. Draai A/B-tests en verzamel lichte signalen:
- Duimpje omhoog/omlaag op resultaten
- Click-through en dwell time
- "Verfijn zoekopdracht"-events
Gebruik deze feedback om relevantiebeoordelingen bij te werken en faalpatronen te ontdekken.
Monitoring van drift in de tijd
Prestaties kunnen veranderen als:
- Je van embedding-model wisselt of de chunking verandert.
- Je corpus verschuift (nieuwe producten, beleidswijzigingen, seizoensgebonden termen).
Draai je testsuite opnieuw na elke wijziging, monitor metriektrends wekelijks en zet alerts voor plotselinge dalingen in MRR/nDCG of pieken in p95-latency.
Beveiliging, privacy en toegangsoverwegingen
Share on your domain
Plaats je semantische zoekfunctie of chatbot op een custom domain zodat stakeholders kunnen testen.
Vector search verandert hoe data wordt opgehaald, maar het mag niet veranderen wie er toegang toe heeft. Als je semantische zoek- of RAG-systeem het juiste chunk kan vinden, kan het per ongeluk ook een chunk teruggeven die de gebruiker niet mocht zien—tenzij je permissies en privacy in de retrieval-stap ontwerpt.
Toegangscontrole: handhaaf het bij retrieval
De veiligste regel is simpel: een gebruiker mag alleen content ophalen die hij/zij mag lezen. Vertrouw niet op de app om resultaten te “verbergen” nadat de vector-database ze al heeft teruggegeven—want dan is de content al buiten je opslaggrens gekomen.
Praktische aanpakken omvatten:
- Per-document (of per-chunk) ACL's: bewaar permissievelden naast elke vector zodat elke query ze kan afdwingen.
- Tenantisolatie: voor multi-tenant apps scheid data per tenant (logische partities, namespaces of aparte indexen) om cross-tenant lekken te voorkomen.
Veel vector-databases ondersteunen metadata-gebaseerde filters (bijv. tenant_id, department, project_id, visibility) die naast similarity search draaien. Juist gebruikt is dit een nette manier om permissies tijdens retrieval toe te passen.
Een belangrijk detail: zorg dat de filter verplicht en server-side is, niet optionele clientlogica. Wees ook voorzichtig met “role explosion” (te veel combinaties). Als je permissiemodel complex is, overweeg dan het vooraf berekenen van “effectieve toegangsgroepen” of een dedicated autorisatieservice die een query-time filtertoken uitgeeft.
PII en gevoelige data: bepaal wat nooit ge-embed mag worden
Embeddings kunnen betekenis uit de originele tekst coderen. Dat onthult niet automatisch ruwe PII, maar verhoogt mogelijk risico's (bijv. dat gevoelige feiten makkelijker terugvindbaar worden).
Gidslijnen die goed werken:
- Vermijd het embedden van hooggevoelige velden (BSN, betaalgegevens, medische identifiers) indien mogelijk.
- Redacteer vóór het embedden als de tekst doorzoekbaar moet zijn (vervang exacte waarden door placeholders).
- Sla originelen apart op en haal ze alleen op na permissiechecks.
Operationele behoeften: backups, retentie en audit
Behandel je vector-index als productiedata:
- Backups en recovery: indexen kunnen duur zijn om opnieuw op te bouwen; plan snapshots of een rebuild-pad vanuit brondata.
- Retentiebeleid: verwijder vectoren wanneer brondocumenten verlopen of wanneer gebruikers verwijdering aanvragen.
- Auditability: log wie wat vroeg (in ieder geval query-context en geretourneerde document-ID's) voor onderzoeken en compliance.
Goed uitgevoerd maken deze praktijken semantische zoekopdrachten magisch voor gebruikers—zonder later beveiligingsverrassingen.
Valkuilen, kosten en een praktische selectielijst
Vector-databases kunnen “plug-and-play” aanvoelen, maar de meeste teleurstellingen komen van omliggende keuzes: hoe je chunked, welk embedding-model je kiest en hoe je alles up-to-date houdt.
Veelvoorkomende faalmodi (en hoe ze op te merken)
Slechte chunking is de belangrijkste oorzaak van irrelevante resultaten. Chunks die te groot zijn verdunnen betekenis; te klein verliezen context. Als gebruikers vaak zeggen “hij vond het juiste document maar de verkeerde passage”, is je chunkingstrategie waarschijnlijk het probleem.
Het verkeerde embedding-model toont zich als consequente semantische mismatch—resultaten zijn vloeiend maar off-topic. Dit gebeurt wanneer het model niet geschikt is voor je domein (juridisch, medisch, supporttickets) of je contenttype (tabellen, code, meertalige tekst).
Verouderde data creëert snel vertrouwenstekort: gebruikers zoeken het nieuwste beleid en krijgen verouderde informatie. Als je brondata verandert, moeten embeddings en metadata ook worden geüpdatet (en deleties moeten echt verwijderen).
Cold-start en omgaan met lege-resultaten
In het begin heb je misschien te weinig content, te weinig queries of onvoldoende feedback om retrieval te tunen. Plan voor:
- Fallbacks: keyword search of gecureerde “top-antwoorden” wanneer semantische resultaten zwak zijn.
- UX voor lege resultaten: toon gerelateerde categorieën, stel een verduidelijkende vraag of verruim filters.
- Warm-up queries: test met een kleine set representatieve vragen voor lancering.
Kostendrivers om in budget op te nemen
Kosten komen meestal uit vier bronnen:
- Embedding compute (backfill + doorlopende updates)
- Opslag (vectoren, metadata en indexen)
- Queryvolume (reads, netwerk egress en concurrency)
- Reranking (optioneel maar krachtig; voegt per-query modelkosten toe)
Bij leveranciersvergelijking vraag om een eenvoudige maandelijkse schatting gebaseerd op je verwachte documentaantal, gemiddelde chunkgrootte en piek-QPS. Veel verrassingen komen tijdens indexering en verkeerspieken.
Een praktische selectielijst
Gebruik deze korte checklist om een vector-database te kiezen die bij je past:
- Zoekkwaliteit: ondersteunt het hybrid search (keyword + vectors) en metadata-filters? Kun je reranking toevoegen?
- Prestaties: ANN-indexopties, voorspelbare latency bij piekverkeer en eenvoudige schaalbaarheid.
- Data-operaties: upserts, deletes, re-indexing, versioning en backfills zonder downtime.
- Observeerbaarheid: querylogs, recall/latency-metrics en tools om te debuggen “waarom dit resultaat?”.
- Beveiliging: encryptie, tenantisolatie, role-based access en filter-by-permission-patronen.
- Integratie: SDK's, ondersteunde talen en connectors voor je opslag (S3, databases, docs).
- Totale kosten: transparante prijzen voor opslag, schrijfacties, reads en eventueel managed compute.
Goed kiezen draait minder om het najagen van het nieuwste indextype en meer om betrouwbaarheid: kun je data vers houden, toegang regelen en kwaliteit behouden naarmate content en verkeer groeien?