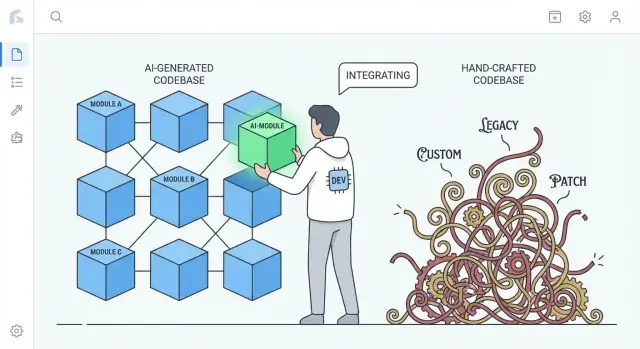
Wat "makkelijker te vervangen" betekent in echte projecten
"Makkelijker te vervangen" betekent zelden het verwijderen van een volledige applicatie en opnieuw beginnen. In echte teams gebeurt vervanging op verschillende schalen, en wat een "rewrite" is hangt af van wat je vervangt.
Vervangen vs. herschrijven: wat er eigenlijk op tafel ligt
Een vervanging kan zijn:
- Een module (facturatieregels, PDF-generatie, e-mailtemplates)
- Een service (recommendation API, background worker)
- Een front-end oppervlak (een pagina, een featuregebied of de hele UI)
- Een volledige app-herschrijving (zeldzaam, duur, soms noodzakelijk)
Als mensen zeggen dat een codebase "makkelijker te herschrijven" is, bedoelen ze meestal dat je één plak kunt herstarten zonder alles te ontwarren, de business draaiende kunt houden en geleidelijk kunt migreren.
De echte vergelijking: AI-gegenereerd vs. sterk op maat geschreven code
Dit argument is niet "AI-code is beter." Het gaat om gebruikelijke neigingen.
- Sterk op maat gemaakte handgeschreven code kan unieke patronen, slimme abstracties en een-op-een "frameworks binnen de app" verzamelen. Dat kan uitstekende engineering zijn, maar het kan ook een privaat ecosysteem creëren dat maar door een paar mensen wordt begrepen.
- AI-gegenereerde code neigt er vaak naar om vertrouwde defaults te gebruiken: gangbare libraries, conventionele lagen en patronen die je in veel referentieprojecten terugziet.
Dat verschil doet ertoe bij een herschrijving: code die algemene conventies volgt kan vaak door een andere conventionele implementatie worden vervangen met minder overleg en minder verrassingen.
Stel verwachtingen: AI-code kan rommelig zijn
AI-gegenereerde code kan inconsistent, repetitief of ondergetest zijn. "Makkelijker te vervangen" is geen claim dat het schoner is—het betekent vaak dat het minder "speciaal" is. Als een subsystem uit algemene ingrediënten bestaat, kan het vervangen vaker voelen als het wisselen van een standaard onderdeel dan het reverse-engineeren van een custom machine.
Vooruitblik: waarom standaardisatie wisselkosten verlaagt
Het kernidee is simpel: standaardisatie verlaagt de wisselkosten. Wanneer code bestaat uit herkenbare patronen en duidelijke naden, kun je stukken regenereren, refactoren of herschrijven met minder angst om verborgen afhankelijkheden te breken. De volgende secties laten zien hoe dat werkt in structuur, eigenaarschap, testing en dagelijkse ontwikkelsnelheid.
Standaardpatronen verlagen de kosten van opnieuw beginnen
Een praktisch voordeel van AI-gegenereerde code is dat het vaak standaard, herkenbare patronen gebruikt: vertrouwde mapindelingen, voorspelbare naamgeving, algemeen gebruikte frameworkconventies en "textbook" benaderingen voor routing, validatie, foutafhandeling en data-access. Zelfs als de code niet perfect is, is ze meestal leesbaar op dezelfde manier als veel tutorials en starterprojecten.
Vertrouwdheid wint van originaliteit als je moet herschrijven
Herschrijvingen zijn duur omdat mensen eerst moeten begrijpen wat er is. Code die bekende conventies volgt verkleint die "decodeertijd". Nieuwe engineers kunnen wat ze zien koppelen aan mentale modellen die ze al hebben: waar configuratie leeft, hoe requests vloeien, hoe dependencies worden aangesloten en waar tests horen.
Dat maakt het sneller om:
- naden voor vervanging te identificeren (modules, services, endpoints)
- gedrag in een nieuwe implementatie te reproduceren
- oud en nieuw naast elkaar te vergelijken zonder tussen stijlen te vertalen
Daarentegen weerspiegelen sterk handgemaakte codebases vaak een diep persoonlijke stijl: unieke abstracties, custom mini-frameworks, slimme "lijm"-code of domeinspecifieke patronen die alleen met historische context logisch zijn. Die keuzes kunnen elegant zijn—maar ze verhogen de kosten van opnieuw beginnen omdat een herschrijving eerst de wereldvisie van de auteur moet herleren.
Je kunt conventies afdwingen in beide gevallen
Dit is geen exclusieve eigenschap van AI. Teams kunnen (en zouden moeten) structuur en stijl afdwingen met templates, linters, formatters en scaffolding-tools. Het verschil is dat AI geneigd is om "generiek per default" te produceren, terwijl menselijk geschreven systemen soms naar bespoke oplossingen afdrijven tenzij conventies actief worden onderhouden.
Minder bespoke "lijm" kan minder verborgen afhankelijkheden betekenen
Veel pijn bij herschrijvingen wordt niet veroorzaakt door de "hoofd" businesslogica. Het wordt veroorzaakt door bespoke lijm—custom helpers, thuisgebouwde micro-frameworks, metaprogrammeringstrucs en éénmalige conventies die stilletjes alles aan elkaar knopen.
Wat telt als "bespoke lijm"
Bespoke lijm is het spul dat geen deel van je product is, maar waar je product zonder niet kan functioneren. Voorbeelden: een custom dependency injection-container, een zelfgemaakte routinglaag, een magische basisklasse die modellen auto-registreert, of helpers die globale state muteren "uit gemak". Het begint vaak als een tijdsbesparing en eindigt als vereiste kennis voor elke verandering.
Waarom unieke lijm koppeling en herschrijfrisico vergroot
Het probleem is niet dat lijm bestaat—het is dat het onzichtbare koppeling wordt. Als lijm uniek is voor je team, veroorzaakt het vaak:\n\n- impliciete afhankelijkheden (dingen werken alleen omdat helpers in een bepaalde volgorde draaien)\n- verspreide aannames over bestanden (naamconventies worden gedrag)\n- riskante "simpele" refactors (verander de lijm, breek alles)
Tijdens een herschrijving is deze lijm moeilijk correct te repliceren omdat de regels zelden goed zijn opgeschreven. Je ontdekt ze door productie te breken.
Waarom AI-gegenereerde code extreme cleverness vaak vermijdt
AI-uitvoer neigt naar standaardlibraries, gangbare patronen en expliciete wiring. Het zal meestal geen micro-framework uitvinden als een simpele module of service-object volstaat. Die terughoudendheid kan een voordeel zijn: minder magische hooks betekent minder verborgen afhankelijkheden, en dat maakt het makkelijker om een subsystem uit te trekken en te vervangen.
De afweging: veel tekst boven slimheid
Het nadeel is dat "platte" code vaak verboser is—meer parameters die rondgaan, meer rechttoe-rechtaan plumbing, minder snelkoppelingen. Maar verbaositeit is meestal goedkoper dan mysterie. Als je besluit te herschrijven, wil je code die makkelijk te begrijpen is, makkelijk te verwijderen en moeilijk verkeerd te interpreteren.
Voorspelbare structuur ondersteunt incrementele herschrijvingen
"Voorspelbare structuur" gaat minder over schoonheid en meer over consistentie: dezelfde mappen, naamgevingsregels en requestflows verschijnen overal. AI-gegenereerde projecten neigen naar vertrouwde defaults—controllers/, services/, repositories/, models/—met repetitieve CRUD-endpoints en gelijkaardige validatiepatronen.
Die uniformiteit maakt van een herschrijving eerder een trap dan een clif.
Hoe voorspelbaarheid eruitziet
Je ziet patronen herhaald over features:
- Duidelijke mapgrenzen (API → service → data access)
- Consistente naamgeving (
UserService, UserRepository, UserController)
- Vergelijkbare CRUD-flow (list → get → create → update → delete)
- Standaard "vorm" voor fouten, logging en request/response-objecten
Als elke feature op dezelfde manier is gebouwd, kun je één stukje vervangen zonder het systeem telkens opnieuw te moeten leren.
Eén onderdeel per keer wisselen
Incrementele herschrijvingen werken het beste als je een boundary kunt isoleren en erachter kunt herbouwen. Voorspelbare structuren creëren die naden natuurlijk: elke laag heeft een smal takenpakket en de meeste aanroepen lopen via een klein aantal interfaces.
Een praktische aanpak is de "strangler"-stijl: houd de publieke API stabiel en vervang intern geleidelijk.
Voorbeeld: vervang de data-access laag zonder de API aan te raken
Stel dat je app controllers heeft die een service aanroepen, en de service roept een repository aan:
OrdersController → OrdersService → OrdersRepository
Je wilt overstappen van directe SQL-queries naar een ORM, of van de ene database naar de andere. In een voorspelbare codebase kan de verandering beperkt blijven:
- Maak
OrdersRepositoryV2 (nieuwe implementatie)
- Houd dezelfde methodesignatures (
getOrder(id), listOrders(filters))\n3. Wissel de wiring op één plek (dependency injection of factory)\n4. Draai tests en rol feature-voor-feature uit
De controller- en service-code blijft grotendeels ongemoeid.
Contrast: handgemaakte architecturen
Zeer handgemaakte systemen kunnen uitstekend zijn—maar ze coderen vaak unieke ideeën: custom abstracties, slimme metaprogrammering of cross-cutting gedrag verborgen in basisklassen. Dat kan elke wijziging vereisen dat je diep in de geschiedenis duikt. Met voorspelbare structuur is de vraag "waar verander ik dit?" meestal eenvoudig, waardoor kleine herschrijvingen week na week haalbaar zijn.
Lager "auteurs-attachment" maakt verwijderen acceptabeler
Een stille blokkade bij veel herschrijvingen is niet technisch maar sociaal. Teams dragen vaak eigenaarschapsrisico, waarbij maar één persoon echt begrijpt hoe het systeem werkt. Als die persoon grote delen van de code met de hand schreef, kan de code voelen als een persoonlijk artefact: "mijn ontwerp", "mijn slimme oplossing", "mijn workaround die de release redde." Die attachment maakt verwijderen emotioneel duur, ook als het economisch logisch is.
AI-gegenereerde code kan dat effect verminderen. Omdat het initiële concept door een tool is gemaakt (en vaak vertrouwde patronen volgt), voelt de code minder als een handtekening en meer als een uitwisselbare implementatie. Mensen zijn meestal comfortabeler met "Laten we deze module vervangen" wanneer het niet aanvoelt als het wissen van iemands vakmanschap—or het uitdagen van iemands status in het team.
Waarom dit het herschrijfgedrag verandert
Als auteursattachment lager is, zullen teams vaker:\n\n- Bestaande code vrijer ter discussie stellen ("Is dit nog steeds de beste aanpak?")\n- Grote delen verwijderen zonder trots- of politiek-onderhandelingen\n- Vroeger kiezen voor regeneratie of vervanging in plaats van maandenlang voorzichtig patchen\n- Kennis sneller verspreiden omdat niemand internals als "eigendomein" behandelt
Een praktische kanttekening
Beslissingen over herschrijven moeten nog steeds worden gedreven door kosten en uitkomsten: levertijden, risico, onderhoudbaarheid en gebruiksimpact. "Het is makkelijk te verwijderen" is een nuttige eigenschap—geen strategie op zichzelf.
Prompts en generatietraces kunnen als documentatie dienen
Start with standard patterns
Begin met voorspelbare lagen voor React, Go en PostgreSQL met duidelijke naden voor incrementele herschrijvingen.
Een onderschat voordeel van AI-gegenereerde code is dat de inputs naar generatie als een levende specificatie kunnen dienen. Een prompt, een template en generatorconfiguratie kunnen intentie in gewone taal beschrijven: wat de feature moet doen, welke beperkingen belangrijk zijn (security, performance, stijl) en wat "klaar" betekent.
Prompts als levende specificaties
Wanneer teams herhaalbare prompts (of promptbibliotheken) en stabiele templates gebruiken, creëren ze een audit trail van beslissingen die anders impliciet zouden blijven. Een goede prompt kan zaken vermelden die een toekomstige onderhoudende meestal moet raden:\n\n- de verwachte gebruikersflow en edge-cases\n- naamgevingsconventies en mapstructuur\n- hoe fouten gelogd en afgehandeld moeten worden\n- wat getest moet worden (en wat gemockt kan worden)
Dat is wezenlijk anders dan veel handgemaakte codebases, waar sleutelkeuzes verspreid zijn over commitberichten, tribale kennis en kleine, ongeschreven conventies.
Generatietraces helpen gedrag reproduceerbaar te maken
Als je generatietraces bewaart (de prompt + model/version + inputs + post-processing stappen), begint een herschrijving niet vanaf nul. Je kunt dezelfde checklist hergebruiken om hetzelfde gedrag onder een schonere structuur opnieuw te creëren en daarna outputs vergelijken.
In de praktijk kan dit een herschrijving veranderen in: "regenerate feature X onder nieuwe conventies en verifieer parity," in plaats van "reverse-engineer wat feature X eigenlijk moest doen."
Belangrijke waarschuwing: behandel prompts als code
Dit werkt alleen als prompts en configs met dezelfde discipline als broncode worden beheerd:\n\n- versioneer ze in de repo (niet in iemands notities)\n- vereis review voor wijzigingen\n- noteer welke prompt/config welke modules genereerde
Zonder dat worden prompts een andere ongedocumenteerde afhankelijkheid. Met dat beheer kunnen ze de documentatie zijn die handgemaakte systemen vaak missen.
Sterke tests maken herschrijvingen routine
"Makkelijker te vervangen" gaat niet echt over wie de code schreef. Het gaat erom of je het met vertrouwen kunt veranderen. Een herschrijving wordt routine-engineering als tests je snel en betrouwbaar vertellen dat het gedrag hetzelfde bleef.
AI-gegenereerde code kan daar bij helpen—als je erom vraagt. Veel teams vragen om boilerplate-tests samen met features (basis unit tests, happy-path integratietests, eenvoudige mocks). Die tests zijn misschien niet perfect, maar ze vormen vaak een initiële vangnet dat ontbreekt in handgemaakte systemen waar tests werden uitgesteld.
Prioriteer contracttests op grenzen
Als je vervangbaarheid wilt, zet dan testenergie op de naden waar onderdelen elkaar ontmoeten:\n\n- Externe API's: requests, responses, foutcodes, retries, paginatie\n- Adapters: payment providers, e-maildiensten, bestandsopslag, queues\n- Datamodellen: migraties, serialisatie, validatieregels\n
Contracttests leggen vast wat waar moet blijven, zelfs als je internals vervangt. Daarmee kun je een module herschrijven achter een API of een adapterimplementatie wisselen zonder steeds opnieuw businessgedrag te moeten bespreken.
Gebruik coverage als kompas, niet als trofee
Coveragecijfers kunnen aanwijzen waar je risico's zitten, maar 100% najagen leidt vaak tot fragiele tests die refactors blokkeren. In plaats daarvan:\n\n- Voeg tests toe waar fouten duur zijn (geld, dataverlies, gebruikersvertrouwen)\n- Geef de voorkeur aan minder, hoogsignaaltests boven veel oppervlakkige tests\n- Bij herschrijven, vergelijk oude en nieuwe implementatie met dezelfde contracttests
Met sterke tests worden herschrijvingen geen heroïsche projecten meer maar een reeks veilige, omkeerbare stappen.
Veelvoorkomende AI-codefouten zijn vaak makkelijk te spotten en te isoleren
Offset your pilot costs
Maak content of verwijs collega’s om credits te verdienen terwijl je experimenteert met Koder.ai.
AI-gegenereerde code faalt vaak op voorspelbare manieren. Je ziet vaak gedupliceerde logica (dezelfde helper drie keer herhaald), "bijna hetzelfde" takken die edge-cases verschillend behandelen, of functies die door toevoegingen blijven groeien. Dat is niet ideaal—maar heeft één voordeel: de problemen zijn meestal zichtbaar.
Duidelijke fouten zijn beter dan subtiele slimme bugs
Handgemaakte systemen kunnen complexiteit verbergen achter slimme abstracties, micro-optimalisaties of strak gekoppeld gedrag dat er "juist" uitziet en casual review doorstaat. Die bugs doen veel pijn omdat ze correct lijken.
AI-code is eerder duidelijk inconsistent: een parameter wordt in één pad genegeerd, een validatie bestaat in het ene bestand maar niet in het andere, of foutafhandeling wisselt per paar functies. Deze mismatches vallen op tijdens review en statische analyse en zijn makkelijker te isoleren omdat ze zelden afhangen van diepe, opzetmatige invarianties.
Kandidaten voor herschrijving tekenen zich af door herhaling
Herhaling is de aanwijzing. Als je dezelfde stappen ziet terugkomen—parse input → normalize → validate → map → return—over endpoints of services, heb je een natuurlijke naad voor vervanging gevonden. AI lost vaak een nieuw verzoek op door een vorige oplossing opnieuw te printen met aanpassingen, wat clusters van near-duplicates creëert.
Een praktische aanpak: markeer elk herhaald blok als kandidaat voor extractie of vervanging, vooral als:\n\n- Het in 3+ plaatsen voorkomt met kleine verschillen\n- De verschillen vooral randgevallen of foutmeldingen zijn\n- De code geen duidelijke eigenaar heeft en steeds wordt gepatcht
Vuistregel: consolideer herhalingen in één geteste module
Als je het herhaalde gedrag in één zin kunt benoemen, moet het waarschijnlijk één module zijn.
Vervang de herhaalde stukken door één goed-geteste component (utility, shared service of library-functie), schrijf tests die de verwachte edge-cases vastleggen en verwijder daarna de duplicaten. Je hebt veel fragiele kopieën veranderd in één plek om te verbeteren—en één plek om later indien nodig te herschrijven.
Leesbaarheid en consistentie wegen vaak zwaarder dan handgemaakte optimalisaties
AI-gegenereerde code blinkt vaak uit als je het vraagt om voor duidelijkheid te optimaliseren in plaats van voor slimheid. Met de juiste prompts en lintingregels kiest het meestal vertrouwde control flow, conventionele naamgeving en "saai"-modules boven nieuwigheid. Dat kan op lange termijn meer winst opleveren dan een paar procent snelheidswinst door handgetweakte trucs.
Waarom leesbare code makkelijker te herschrijven is
Herschrijvingen slagen wanneer nieuwe mensen snel een correct mentaal model van het systeem kunnen bouwen. Leesbare, consistente code verkort de tijd om basisvragen te beantwoorden zoals "Waar komt dit request binnen?" en "Welke vorm heeft deze data hier?" Als elke service vergelijkbare patronen volgt (layout, foutafhandeling, logging, configuratie), kan een nieuw team één plak per keer vervangen zonder steeds lokale conventies te herleren.
Consistentie vermindert ook angst. Als code voorspelbaar is, kunnen engineers delen verwijderen en opnieuw bouwen met vertrouwen omdat het aangrijpingsvlak makkelijker te begrijpen is en de "blast radius" kleiner voelt.
Sterk geoptimaliseerde, handgemaakte code kan moeilijk te herschrijven zijn omdat performance-technieken overal lekken: custom caching-lagen, micro-optimalisaties, thuisgemaakte concurrency-patronen of strakke koppeling aan specifieke datastructuren. Die keuzes zijn soms valide, maar creëren vaak subtiele beperkingen die pas duidelijk worden als iets faalt.
Leesbaarheid is geen vrijbrief om traag te zijn. Het punt is: verdien performance met bewijs. Leg voor een herschrijving baseline-metrics vast (latency-percentielen, CPU, geheugen, kosten). Meet opnieuw na het vervangen van een component. Als performance terugloopt, optimaliseer het specifieke hot path—zonder de hele codebase een raadsel te maken.
Regenereren vs refactoren vs herschrijven: kies de juiste reset
Als een AI-ondersteunde codebase "off" begint te voelen, heb je niet automatisch een volledige herschrijving nodig. De beste reset hangt af van hoeveel van het systeem verkeerd is versus alleen maar rommelig.
Drie resetopties
Regenereren betekent een deel van de code opnieuw creëren vanuit een spec of prompt—vaak vanaf een template of bekend patroon—en daarna integratiepunten (routes, contracten, tests) weer aansluiten. Het is niet "alles verwijderen", maar "dit stuk herbouwen vanuit een duidelijke beschrijving."\n\nRefactoren houdt gedrag gelijk maar verandert interne structuur: hernoemen, splitsen van modules, vereenvoudigen van conditionals, duplicatie verwijderen, tests verbeteren.\n\nHerschrijven vervangt een component of systeem door een nieuwe implementatie, meestal omdat het huidige ontwerp niet gezond te maken is zonder gedrag, boundaries of dataflows te veranderen.
Wanneer regeneratie uitstekend past
Regeneratie schittert als de code grotendeels boilerplate is en de waarde in interfaces zit in plaats van in slimme internals:\n\n- CRUD-schermen en admin-panelen\n- API-adapters en dunne integratielagen\n- scaffolding: routing, serializers, DTO's, eenvoudige validatie, generieke foutafhandeling
Als de spec duidelijk is en de moduleboundary schoon, is regenereren vaak sneller dan het uitklooien van incrementele wijzigingen.
Wanneer regeneratie riskant is (of faalt)
Wees voorzichtig als de code harde domeinkennis of subtiele correctheidsvoorwaarden bevat:\n\n- domeinintensieve businessregels met veel edge-cases\n- lastige concurrency (queues, locks, retries, idempotency)\n- compliance-logica (audit trails, retentie, privacyregels)\n
In deze gebieden kan "bijna hetzelfde" gevaarlijk fout zijn—regeneratie helpt dan alleen als je equivalentie kunt bewijzen met sterke tests en grondige reviews.
Reviewpoorten en kleine uitrols
Behandel gegenereerde code als een nieuwe dependency: vereis menselijke review, draai de volledige test-suite en voeg gerichte tests toe voor eerder geziene fouten. Rol in kleine slices uit—één endpoint, één scherm, één adapter—achter een feature-flag of geleidelijke release als dat mogelijk is.
Een nuttige vuistregel: regenerate de shell, refactor de naden, herschrijf alleen de delen waar aannames blijven breken.
Risico's en vangrails voor "vervangbaar-by-design" code
Extend the rewrite to mobile
Genereer een Flutter-app vanuit chat en behoud dezelfde conventies voor web en mobiel.
"Makkelijk te vervangen" blijft alleen een voordeel als teams vervanging als een engineered activiteit behandelen, niet als een casual resetknop. AI-geschreven modules kun je sneller wisselen—maar ze kunnen ook sneller falen als je ze meer vertrouwt dan je verifieert.
Belangrijke risico's om te bewaken
AI-gegenereerde code ziet er vaak compleet uit, ook als dat niet zo is. Dat kan valse zekerheid creëren, vooral als happy-path-demo's slagen.
Een tweede risico is ontbrekende edge-cases: ongewone inputs, timeouts, concurrency-kwesties en foutafhandeling die niet in de prompt of sample data zaten.
Ten slotte is er licentie-/IP-onzekerheid. Zelfs als het risico in veel opstellingen laag is, moeten teams een beleid hebben over welke bronnen en tools acceptabel zijn en hoe provenance wordt vastgelegd.
Vangrails die herschrijvingen veilig houden
Zet vervanging achter dezelfde poorten als elke andere verandering:\n\n- Code review met een expliciete lens voor "gegenereerde code": duidelijkheid, faalwijzen, inputvalidatie en logging.\n- Security checks (SAST, dependency scanning, secrets-detectie) en een regel dat gegenereerde code die niet mag omzeilen.\n- Dependency-beleid: geef de voorkeur aan minder, bekende libraries; pin versies; vermijd het binnenhalen van een nieuw framework alleen omdat een prompt het suggereerde.\n- Audit trails: bewaar prompts, model-/toolversies en generatie-aantekeningen in de repo zodat wijzigingen later uitlegbaar zijn.
Documenteer boundaries voordat je modules vervangt
Voordat je een component vervangt, schrijf zijn boundary en invarianties op: welke inputs het accepteert, wat het garandeert, wat het nooit mag doen (bijv. "nooit klantdata verwijderen") en performance-/latencyverwachtingen. Dit contract test je—ongeacht wie (of wat) de code schrijft.
Een lichtgewicht checklist
- Definieer modulecontract (inputs/outputs, invarianties).\n2) Voeg/controleer tests voor edge-cases.\n3) Draai security + dependency scans.\n4) Review op leesbaarheid en foutafhandeling.\n5) Noteer prompt/tooling metadata.\n6) Ship achter een flag en monitor.
Praktische conclusies en een eenvoudig vervolgstappenplan
AI-gegenereerde code is vaak makkelijker te herschrijven omdat het geneigd is vertrouwde patronen te volgen, minder diepe “craft”-persoonlijkheid heeft en sneller te regenereren is wanneer eisen veranderen. Die voorspelbaarheid verlaagt de sociale en technische kosten van het verwijderen en vervangen van onderdelen.
Het doel is niet "code weggooien", maar vervanging een normale, lage-frictie optie te maken—gedekt door contracten en tests.
Actiestappen die je deze week kunt uitvoeren
Begin met het standaardiseren van conventies zodat gegenereerde of herschreven code in dezelfde mal past:\n\n- Veranker conventies: formatting, mapstructuur, naamgeving, foutafhandeling en API-vorm. Schrijf ze kort op in een CONTRIBUTING.md.\n- Voeg contracttests toe op grenzen: focus op inputs/outputs voor modules en services (HTTP-endpoints, queue-berichten, DB-access-lagen). Deze tests moeten slagen ongeacht implementatie.\n- Volg prompts en specs: sla prompts, requirements-notities en generatietraces naast de code op zodat toekomstige herschrijvingen intentie kunnen reproduceren, niet alleen tekst.
Als je een "vibe-coding" workflow gebruikt, zoek tooling die deze praktijken eenvoudig maakt: prompts en planning-specs naast de repo bewaren, generatietraces vastleggen en veilige rollback ondersteunen. Bijvoorbeeld, Koder.ai is ontworpen rond chat-gestuurde generatie met snapshots en rollback, wat goed past bij een "replaceable by design" aanpak—regenerate een slice, houd het contract stabiel en revert snel als parity-tests falen.
Voer een kleine "vervangbare module" pilot uit
Kies één module die belangrijk maar veilig geïsoleerd is—rapportage, notificatieverzending of één CRUD-gebied. Definieer het publieke interface, voeg contracttests toe en laat jezelf de internals regenereren/refactoren/herschrijven totdat het saai is. Meet doorlooptijd, defectratio en reviewinspanning; gebruik de resultaten om teamregels vast te leggen.
Om dit te operationaliseren, houd een checklist in je interne playbook (of deel het via /blog) en maak de trio "contracts + conventions + traces" een vereiste voor nieuw werk. Als je tooling evalueert, documenteer dan wat je van een oplossing nodig hebt voordat je naar /pricing kijkt.