Wat database-indexering echt doet
Een database-index is een aparte opzoeksstructuur die de database helpt rijen sneller te vinden. Het is geen tweede kopie van je tabel. Zie het als de indexpagina's in een boek: je gebruikt de index om dicht bij de juiste plek te springen, en leest daarna de exacte pagina (rij) die je nodig hebt.
Zonder index heeft de database vaak maar één veilige optie: door veel rijen lezen om te controleren welke overeenkomen met je query. Dat kan prima zijn als een tabel een paar duizend rijen heeft. Als de tabel groeit naar miljoenen rijen, betekent "meer rijen controleren" meer schijfreads, meer geheugenbelasting en meer CPU-werk—zodat dezelfde query die eerst direct aanvoelde, traag wordt.
Wat een index verandert (en wat niet)
Indexen verkleinen de hoeveelheid data die de database moet inspecteren om vragen te beantwoorden zoals "vind de order met ID 123" of "haal gebruikers op met dit e-mailadres." In plaats van alles te scannen, volgt de database een compacte structuur die de zoekruimte snel verkleint.
Maar indexering is geen universele remedie. Sommige queries moeten nog steeds veel rijen verwerken (brede rapporten, filters met lage selectiviteit, zware aggregaties). En indexen hebben echte kosten: extra opslag en tragere schrijfbewerkingen, omdat inserts en updates de index ook moeten bijwerken.
Wat je in deze gids leert
Je ziet:
- waarom het vermijden van volledige tabelscans de grote snelheidswinst is
- hoe gangbare indexstructuren (zoals B-tree) lookups versnellen
- welke queries het meest profiteren, en wanneer ze dat niet doen
- hoe je samengestelde/covering-indexen kiest en valideert met een EXPLAIN-plan
- hoe je indexen in de loop van de tijd onderhoudt zodat prestaties niet ongemerkt verslechteren
De kernwinst: het vermijden van volledige tabelscans
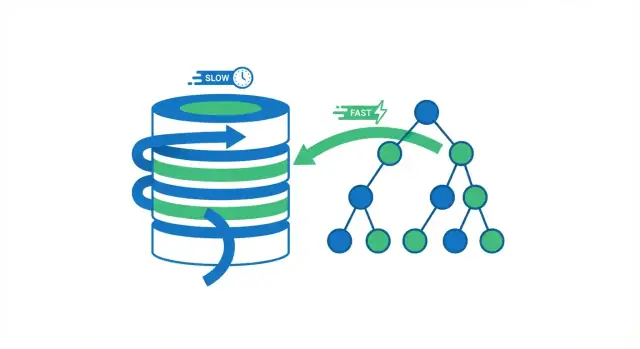
Wanneer een database een query uitvoert, heeft hij twee brede opties: de hele tabel rij voor rij scannen, of direct naar de rijen springen die matchen. Het merendeel van de indexwinsten komt voort uit het vermijden van onnodige reads.
Volledige tabelscan vs. indexlookup
Een volledige tabelscan is precies wat het klinkt: de database leest elke rij, controleert of deze voldoet aan de WHERE-voorwaarde en geeft pas dan resultaten terug. Dat is acceptabel voor kleine tabellen, maar het wordt voorspelbaar langzamer naarmate de tabel groeit—meer rijen betekent meer werk.
Met een index kan de database vaak voorkomen dat hij de meeste rijen leest. In plaats daarvan raadpleegt hij eerst de index (een compacte structuur gebouwd om te zoeken) om te vinden waar de bijpassende rijen zich bevinden, en leest daarna alleen die specifieke rijen.
Een eenvoudige analogie
Denk aan een boek. Als je elke pagina wilt lezen waar "fotosynthese" wordt genoemd, kun je het hele boek van kaft tot kaft lezen (volledige scan). Of je gebruikt de index van het boek, springt naar de opgesomde pagina's en leest alleen die secties (indexlookup). De tweede aanpak is sneller omdat je bijna alle pagina's overslaat.
Waarom minder reads meestal snellere queries opleveren
Databases besteden veel tijd aan wachten op reads—vooral wanneer data niet al in het geheugen staat. Het verminderen van het aantal rijen (en pagina's) dat de database moet aanraken, vermindert doorgaans:
- schijf/SSD-reads
- CPU-tijd die wordt besteed aan het evalueren van filters
- geheugenbelasting door het ophalen van onnodige data in de cache
Wanneer de snelheidswinst zichtbaar wordt
Indexering helpt het meest wanneer data groot is en het querypatroon selectief is (bijvoorbeeld: 20 matchende rijen ophalen uit 10 miljoen). Als je query toch al de meeste rijen teruggeeft, of de tabel klein genoeg is om comfortabel in geheugen te passen, kan een volledige scan net zo snel—of zelfs sneller—zijn.
Hoe indexstructuren lookups snel maken
Indexen werken omdat ze waarden organiseren zodat de database dichtbij kan springen naar wat je zoekt in plaats van elke rij te controleren.
B-tree-indexen: de standaard krachtpatser
De meest voorkomende indexstructuur in SQL-databases is de B-tree (vaak geschreven als “B-tree” of “B+tree”). Concreet:
- waarden worden gesorteerd gehouden
- de index is opgesplitst in pagina's (blokken) die naar andere pagina's wijzen, en uiteindelijk naar de overeenkomstige tabelrijen
Omdat het gesorteerd is, is een B-tree uitstekend voor zowel gelijkheidsopzoekingen (WHERE email = ...) als range-queries (WHERE created_at \u003e= ... AND created_at \u003c ...). De database kan naar de juiste buurt navigeren en daarna in volgorde vooruit scannen.
Wat “logaritmisch” betekent (zonder wiskunde)
Mensen zeggen dat B-tree-lookups “logaritmisch” zijn. Praktisch betekent dat dit: als je tabel groeit van duizenden naar miljoenen rijen, groeit het aantal stappen om een waarde te vinden langzaam, niet proportioneel.
In plaats van “dubbel zoveel data betekent dubbel zoveel werk”, is het meer: “veel meer data betekent maar een paar extra navigatiestappen”, omdat de database pointers door een klein aantal niveaus in de boom volgt.
Hash-indexen: snel voor exacte matches (met beperkingen)
Sommige engines bieden ook hash-indexen. Die kunnen erg snel zijn voor exacte gelijkheden omdat de waarde wordt omgezet in een hash en gebruikt wordt om de entry direct te vinden.
De afweging: hash-indexen helpen meestal niet bij ranges of geordende scans, en beschikbaarheid/gedrag verschilt tussen databases.
Engine-details verschillen, het idee blijft hetzelfde
PostgreSQL, MySQL/InnoDB, SQL Server en anderen slaan indexen verschillend op en gebruiken ze anders (paginaformaat, clustering, included columns, visibility checks). Maar het kernidee blijft: indexen creëren een compacte, doorzoekbare structuur waarmee de database bijpassende rijen kan lokaliseren met veel minder werk dan het scannen van de hele tabel.
Queries die het meest profiteren van indexen
Indexen versnellen niet “SQL” in het algemeen—ze versnellen specifieke toegangspatronen. Wanneer een index overeenkomt met hoe je query filtert, joinet of sorteert, kan de database direct naar relevante rijen springen in plaats van de hele tabel te lezen.
De meest indexvriendelijke querypatronen
1) WHERE-filters (vooral op selectieve kolommen)
Als je query vaak een grote tabel tot een kleine set rijen beperkt, is een index meestal het eerste waar je aan denkt. Een klassiek voorbeeld is het opzoeken van een gebruiker op identifier.
Zonder een index op users.email kan de database elke rij doorlopen:
SELECT * FROM users WHERE email = '[email protected]';
Met een index op email kan hij de overeenkomstige rij(en) snel vinden en stoppen.
2) JOIN-sleutels (foreign keys en referenced keys)
Joins zijn plekken waar kleine inefficiënties grote kosten worden. Als je orders.user_id joinet met users.id, helpt het indexeren van de joinkolommen (meestal orders.user_id en de primaire sleutel users.id) de database rijen te matchen zonder herhaaldelijk te scannen.
3) ORDER BY (wanneer je resultaten al gesorteerd wilt hebben)
Sorteren is duur wanneer de database veel rijen moet verzamelen en daarna sorteren. Als je vaak runt:
SELECT * FROM orders WHERE user_id = 42 ORDER BY created_at DESC;
kan een index die user_id en de sorteerkolom uitlijnt de engine toestaan rijen in de gewenste volgorde te lezen in plaats van een grote tussenresultaatset te sorteren.
4) GROUP BY (wanneer groeperen samenvalt met een index)
Groeperen kan profiteren wanneer de database data in gegroepeerde volgorde kan lezen. Het is geen garantie, maar als je vaak groepeert op een kolom die ook voor filteren wordt gebruikt (of natuurlijk in de index is geclusterd), kan de engine minder werk doen.
Range-filters: een veelvoorkomende B-tree-winst
B-tree-indexen zijn bijzonder goed voor range-condities—denk aan datums, prijzen en "tussen"-queries:
SELECT * FROM orders
WHERE created_at \u003e= '2025-01-01' AND created_at \u003c '2025-02-01';
Voor dashboards, rapporten en "recente activiteit"-schermen komt dit patroon veel voor, en een index op de range-kolom levert vaak directe verbetering op.
Het thema is eenvoudig: indexen helpen het meest wanneer ze weerspiegelen hoe je zoekt en sorteert. Als je queries op die toegangspatronen aansluiten, kan de database gerichte reads doen in plaats van brede scans.
Selectiviteit: waarom sommige indexen niet helpen
Een index helpt het meest wanneer hij scherp beperkt hoeveel rijen de database moet aanraken. Die eigenschap heet selectiviteit.
Wat “selectiviteit” in de praktijk betekent
Selectiviteit is in feite: hoeveel rijen matchen een gegeven waarde? Een kolom met hoge selectiviteit heeft veel verschillende waarden, dus elke lookup matcht weinig rijen.
- Hoge selectiviteit:
email, user_id, order_number (vaak uniek of bijna uniek)
- Lage selectiviteit:
is_active, is_deleted, status met een paar veelvoorkomende waarden
Bij hoge selectiviteit kan een index direct naar een kleine set rijen springen. Bij lage selectiviteit wijst de index naar een groot deel van de tabel—dus moet de database nog steeds veel lezen en filteren.
Waarom boolean (en soortgelijke) indexen tegenvallen
Stel een tabel met 10 miljoen rijen en een kolom is_deleted waar 98% false is. Een index op is_deleted bespaart niet veel voor:
SELECT * FROM orders WHERE is_deleted = false;
De "matchset" is nog steeds bijna de hele tabel. Het gebruik van de index kan zelfs langzamer zijn dan een sequentiële scan omdat de engine extra werk doet tussen indexentries en tabelpagina's te springen.
Waarom de database je index kan negeren
Queryplanners schatten kosten. Als een index het werk niet genoeg vermindert—omdat te veel rijen matchen, of omdat de query ook de meeste kolommen nodig heeft—kiezen ze mogelijk een volledige tabelscan.
Selectiviteit verandert in de loop van de tijd
De distributie van data staat niet vast. Een status-kolom kan eerst gelijkmatig verdeeld zijn, en later zo verschuiven dat één waarde domineert. Als statistieken niet worden bijgewerkt, kan de planner slechte beslissingen nemen, en een index die vroeger hielp kan ineens niet meer lonen.
Samengestelde en covering-indexen (en kolomvolgorde)
Indexen op één kolom zijn een goed begin, maar veel echte queries filteren op één kolom en sorteren of filteren op een andere. Daar schitteren samengestelde (multi-kolom) indexen: één index kan meerdere delen van de query bedienen.
Kolomvolgorde: de "van links naar rechts"-regel
De meeste databases (vooral met B-tree-indexen) kunnen een samengestelde index efficiënt gebruiken vanaf de linkermost-kolommen vooruit. Zie de index als eerst gesorteerd op kolom A, binnen die waarden op kolom B, enz.
Dat betekent:
- een index op (account_id, created_at) is geweldig voor queries die filteren op
account_id en dan sorteren of filteren op created_at
- dezelfde index is meestal niet nuttig voor een query die alleen op
created_at filtert (omdat dat niet linkermost is)
Een praktisch patroon: per-account tijdlijnen
Een veelvoorkomende workload is "toon me de meest recente events voor dit account." Dit querypatroon:
SELECT id, created_at, type
FROM events
WHERE account_id = ?
ORDER BY created_at DESC
LIMIT 50;
voordeel vaak enorm van:
CREATE INDEX events_account_created_at
ON events (account_id, created_at);
De database kan direct naar het gedeelte van één account in de index springen en rijen in tijdsvolgorde lezen, in plaats van een grote set te scannen en te sorteren.
Covering-indexen: wanneer de index het antwoord is
Een covering-index bevat alle kolommen die de query nodig heeft, zodat de database resultaten uit de index kan teruggeven zonder de tabelrijen op te zoeken (minder reads, minder random I/O).
Wees voorzichtig: extra kolommen toevoegen kan een index groot en duur maken.
Bouw geen brede samengestelde indexen "voor het geval dat"
Brede samengestelde indexen kunnen schrijfbewerkingen vertragen en veel opslag kosten. Voeg ze alleen toe voor specifieke queries met hoge waarde, en verifieer met een EXPLAIN-plan en echte metingen vóór en na.
Indexen worden vaak beschreven als "gratis snelheid", maar ze zijn dat niet. Indexstructuren moeten worden onderhouden elke keer dat de onderliggende tabel verandert, en ze gebruiken echte resources.
Langzamere INSERT/UPDATE/DELETE (omdat elke index bijgewerkt moet worden)
Wanneer je een nieuwe rij INSERT, schrijft de database niet alleen de rij—hij voegt ook corresponderende entries toe aan elke index op die tabel. Hetzelfde geldt voor DELETE en veel UPDATEs.
Daarom kunnen meer indexen merkbaar schrijfbewerkingen vertragen. Een UPDATE die een geïndexeerde kolom raakt kan bijzonder duur zijn: de database moet mogelijk de oude indexentry verwijderen en een nieuwe toevoegen (en in sommige engines kunnen dit extra page splits of interne rebalancing triggeren). Als je app veel schrijft—orderevents, sensordata, auditlogs—kan alles indexeren de database traag maken, ook al zijn reads snel.
Elke index neemt schijfruimte in. Op grote tabellen kunnen indexen de grootte van de tabel evenaren (of overstijgen), zeker wanneer je meerdere overlappende indexen hebt.
Het raakt ook het geheugen. Databases vertrouwen sterk op caching; als je werkset meerdere grote indexen bevat, moet de cache meer pagina's vasthouden om snel te blijven. Anders zie je meer schijf-I/O en minder voorspelbare prestaties.
De praktische balans
Indexering gaat over kiezen wat je versnelt. Als je workload leesintensief is, kunnen meer indexen de moeite waard zijn. Als hij schrijfintensief is, prioriteer indexen die je belangrijkste queries ondersteunen en vermijd duplicaten. Een nuttige regel: voeg een index alleen toe als je de query kunt noemen die hij helpt—en verifieer dat de snelheidswinst opweegt tegen de kosten in schrijfbewerking en onderhoud.
Hoe te bewijzen dat een index helpt: EXPLAIN en metingen
Een index toevoegen lijkt alsof hij moet helpen—maar je kunt (en moet) het verifiëren. De twee hulpmiddelen die dit concreet maken zijn het queryplan (EXPLAIN) en echte voor- en nametingen.
Lees het plan: wordt de index daadwerkelijk gebruikt?
Voer EXPLAIN (of EXPLAIN ANALYZE) uit op de exacte query die je belangrijk vindt.
- Scan type: Een Seq Scan / Full Table Scan betekent dat de database de hele tabel leest. Een Index Scan / Index Seek (of Index Range Scan) suggereert dat hij een index gebruikt om rijen te beperken.
- Geschatte vs. daadwerkelijke rijen (vooral in
EXPLAIN ANALYZE): Als het plan schatte 100 rijen maar daadwerkelijk 100.000 raakte, maakte de optimizer een slechte gok—vaak omdat statistieken verouderd zijn of de filter minder selectief is dan verwacht.
- Sort-stappen: Als je een expliciete Sort ziet, ordent de database resultaten achteraf. Als een nieuwe index overeenkomt met de
ORDER BY, kan die sort verdwijnen, wat een grote winst kan zijn.
Meet goed: voor/na, onder dezelfde condities
Benchmark de query met dezelfde parameters, op representatieve datahoeveelheid, en registreer zowel latency als aantal verwerkte rijen.
Wees voorzichtig met caching: de eerste run kan langzamer zijn omdat data nog niet in geheugen staat; herhaalde runs kunnen er "vast" uitzien zelfs zonder index. Om jezelf niet te misleiden, vergelijk meerdere runs en focus op of het plan verandert (index gebruikt, minder rijen gelezen) naast ruwe tijd.
Als EXPLAIN ANALYZE minder geraakte rijen en minder dure stappen (zoals sorts) toont, heb je bewezen dat de index helpt—niet alleen gehoopt dat hij helpt.
Veelgemaakte fouten die indexvoordelen opheffen
Je kunt de "juiste" index toevoegen en toch geen snelheidswinst zien als de query zo is geschreven dat de database hem niet kan gebruiken. Deze problemen zijn vaak subtiel, omdat de query nog steeds correcte resultaten geeft—maar gedwongen wordt een trager plan te kiezen.
Anti-patronen die indexgebruik blokkeren
1) Leading wildcards
Als je schrijft:
WHERE name LIKE '%term'
kan de database geen normale B-tree-index gebruiken om op het juiste startpunt te springen, omdat hij niet weet waar in de gesorteerde volgorde "%term" begint. Hij valt vaak terug op het scannen van veel rijen.
Alternatieven:
- Waar mogelijk, gebruik prefix-zoeken:
WHERE name LIKE 'term%'.
- Als je echt "contains"-zoek nodig hebt, overweeg een gespecialiseerd indextype (bijv. full-text/trigram) in plaats van te verwachten dat een standaardindex helpt.
2) Functies op geïndexeerde kolommen
Dit lijkt onschuldig:
WHERE LOWER(email) = '[email protected]'
Maar LOWER(email) verandert de expressie, dus een index op email kan niet direct worden gebruikt.
Alternatieven:
- Sla genormaliseerde data op (bijv. e-mails in lowercase) en query
WHERE email = ....
- Of maak een expressie-/functie-gebaseerde index (database-afhankelijk) specifiek voor
LOWER(email).
Verborgen indexblokkers die mensen missen
Impliciete typecasts: Vergelijken van verschillende datatypes kan de database dwingen één kant te casten, wat een index kan uitschakelen. Voorbeeld: een integerkolom vergelijken met een stringliteral.
Mismatchende collaties/encodings: Als de vergelijking een andere collatie gebruikt dan de index (veel voorkomend bij tekstkolommen in verschillende locale-instellingen), kan de optimizer de index vermijden.
Snelle checklist: "Waarom wordt mijn index niet gebruikt?"
- Begint de conditie met een wildcard (
LIKE '%x')?
- Pas je een functie toe op de geïndexeerde kolom (
LOWER(col), DATE(col), CAST(col))?
- Zijn types identiek aan beide zijden (geen impliciete cast)?
- Is collatie/locale consistent voor de vergelijking?
- Is het predicaat selectief genoeg (matcht het geen groot deel van de tabel)?
- Filter/orden je op de linkermost-kolommen van een samengestelde index?
- Heb je het plan met
EXPLAIN gecontroleerd om te bevestigen wat de database daadwerkelijk kiest?
Indexonderhoud: statistieken, bloat en lange-termijn gezondheid
Indexen zijn niet "set-and-forget." In de loop van de tijd veranderen data, querypatronen verschuiven, en de fysieke vorm van tabellen en indexen drift weg. Een goedgekozen index kan langzaam minder effectief—of zelfs schadelijk—worden als je hem niet onderhoudt.
Statistieken: de kaart van de planner kan verouderen
De meeste databases vertrouwen op een queryplanner (optimizer) om te kiezen hoe een query wordt uitgevoerd: welke index te gebruiken, welke joinvolgorde, en of een indexlookup de moeite waard is. Om die beslissingen te nemen gebruikt de planner statistieken—samenvattingen over waarde-distributies, rijen-aantallen en data-skew.
Wanneer statistieken verouderd zijn, kunnen de raming van rijen van de planner ver buiten de werkelijkheid liggen. Dat leidt tot slechte plankeuzes, zoals het kiezen van een index die veel meer rijen teruggeeft dan verwacht, of het overslaan van een index die sneller was.
Routine-oplossing: plan regelmatige stats-updates (vaak ANALYZE of soortgelijk). Na grote dataloads, veel deletes of significante churn, ververst je stats eerder.
Bloat en fragmentatie: wanneer structuren rommelig worden
Naarmate rijen worden ingevoegd, geüpdatet en verwijderd, kunnen indexen bloat (extra pagina's die geen bruikbare data meer bevatten) en fragmentatie (data verspreid op een manier die I/O verhoogt) opstapelen. Het resultaat is grotere indexen, meer reads en tragere scans—vooral voor range-queries.
Routine-oplossing: rebuild of reorganize zwaar gebruikte indexen wanneer ze disproportioneel gegroeid zijn of de prestaties afnemen. Exacte tooling en impact variëren per database, behandel dit dus als een gemeten operatie, geen algemene regel.
Monitor in de loop van de tijd, niet alleen één keer
Zet monitoring op voor:
- trage queries (latency, frequentie en top-gevallen)
- indexgebruik (nooit gebruikte indexen vs. "hot" indexen)
- indexgroottegroei en plotselinge planwijzigingen
Die feedbackloop helpt je te ontdekken wanneer onderhoud nodig is—en wanneer een index aangepast of verwijderd moet worden. Voor meer over het valideren van verbeteringen, zie /blog/how-to-prove-an-index-helps-explain-and-measurements.
Een praktische workflow voor het toevoegen van de juiste index
Een index toevoegen moet een weloverwogen wijziging zijn, geen gok. Een lichtgewicht workflow houdt je gefocust op meetbare winsten en voorkomt "index-sprawl."
1) Identificeer de echte probleemquery
Begin met bewijs: slow-query logs, APM-traces of gebruikersmeldingen. Kies één query die zowel traag als frequent is—een zeldzaam 10‑seconden rapport is minder belangrijk dan een veelvoorkomende 200 ms lookup.
Leg de exacte SQL vast en het parameterpatroon (bijv. WHERE user_id = ? AND status = ? ORDER BY created_at DESC LIMIT 50). Kleine verschillen veranderen welke index helpt.
2) Meet een basislijn
Registreer huidige latency (p50/p95), gescande rijen en CPU/IO-impact. Sla de huidige planoutput op (bijv. EXPLAIN / EXPLAIN ANALYZE) zodat je later kunt vergelijken.
3) Ontwerp de kleinste nuttige index
Kies kolommen die overeenkomen met hoe de query filtert en sorteert. Geef de voorkeur aan de minimale index die het plan stopt met het scannen van enorme reeksen.
Test in staging met productieachtig datavolume. Indexen kunnen er goed uitzien op kleine datasets maar teleurstellen op schaal.
4) Maak hem veilig aan
Op grote tabellen gebruik online opties waar beschikbaar (bijv. PostgreSQL CREATE INDEX CONCURRENTLY). Plan wijzigingen tijdens lagere traffic als je database schrijfbewerkingen kan blokkeren.
5) Valideer met voor/na-evidence
Draai dezelfde query opnieuw en vergelijk:
- planvorm (is het veranderd van full scan naar indexaccess?)
- uitvoeringstijd en gescande rijen
- impact op schrijfbewerkingen (insert/update-latency)
6) Heb een rollback-plan
Als de index schrijfkosten verhoogt of geheugen/opslagproblemen veroorzaakt, verwijder hem netjes (bijv. DROP INDEX CONCURRENTLY waar beschikbaar). Houd migraties omkeerbaar.
7) Documenteer het "waarom"
Schrijf in de migratie- of schema-notities welke query de index bedient en welke metric verbeterde. De toekomstige jij (of een collega) weet zo waarom hij bestaat en wanneer het veilig is hem te verwijderen.
Waar Koder.ai in deze workflow past
Als je een nieuwe service bouwt en vroege "index-sprawl" wilt vermijden, kan Koder.ai je helpen de volledige lus hierboven sneller te doorlopen: genereer een React + Go + PostgreSQL-app vanuit chat, pas schema- en indexmigraties aan als eisen veranderen, en exporteer daarna de broncode wanneer je klaar bent om zelf verder te gaan. In de praktijk maakt dat het eenvoudiger om van "dit endpoint is traag" naar "hier is het EXPLAIN-plan, de minimale index en een omkeerbare migratie" te gaan zonder te wachten op een volledig traditionele pipeline.
Wanneer indexering niet genoeg is (en wat daarna te doen)
Indexen zijn een grote hefboom, maar geen magische knop om alles snel te maken. Soms gebeurt het trage deel van een request nadat de database de juiste rijen heeft gevonden—or je querypatroon maakt indexering de verkeerde eerste stap.
Gevallen waar indexering niet de beste oplossing is
Als je query al een goede index gebruikt maar nog steeds traag aanvoelt, kijk dan naar deze veelvoorkomende oorzaken:
- Ontbrekende (of onjuiste) paginatie: Het ophalen van pagina 1.000 met
OFFSET 999000 kan traag zijn zelfs met indexen. Geef de voorkeur aan keyset-paginatie (bijv. "geef rijen na de laatst geziene id/timestamp").
- Te veel data terugsturen: Brede rijen selecteren (
SELECT *) of tienduizenden records teruggeven kan bottlenecken op netwerk, JSON-serialisatie of applicatieverwerking.
- Schema-mismatchen: Over-genormaliseerde joins, zoekbare waarden in JSON/text blobs opslaan, of verkeerde datatypes gebruiken kan dure operaties afdwingen die indexen niet volledig maskeren.
Optimalisaties die vaak belangrijker zijn
- Herschrijf de query: Verwijder onnodige joins, vermijd functies op geïndexeerde kolommen in WHERE-clausules en vereenvoudig OR-zware predicaten.
- Beperk kolommen en rijen: Selecteer alleen wat je nodig hebt, voeg zinvolle
LIMIT toe en page resultaten doelbewust.
- Caching: Cache veelgevraagde reads op applicatieniveau of gebruik een read-through cache voor dure, herhaalde queries.
- Partitionering: Als de meeste queries recente data raken, partitioneer op tijd (of een andere natuurlijke grens) om de doorzochte ruimte te verkleinen.
Als je een diepere methode wilt om bottlenecks te diagnosticeren, combineer dit dan met de workflow in /blog/how-to-prove-an-index-helps-explain-and-measurements.
Prioriteer: los de grootste bottleneck als eerste op
Raadpleeg geen giswerk. Meet waar tijd wordt besteed (database-executie vs. teruggegeven rijen vs. applicatiecode). Als de database snel is maar de API traag, helpen meer indexen niet.
Snelle checklist