26 nov 2025·8 min
Waarom grafendatabases uitblinken in relaties — niet in alles
Grafendatabases schitteren wanneer verbindingen de vragen aansturen. Leer de beste use-cases, afwegingen en wanneer relationele of documentdatabases beter passen.
Grafendatabases schitteren wanneer verbindingen de vragen aansturen. Leer de beste use-cases, afwegingen en wanneer relationele of documentdatabases beter passen.
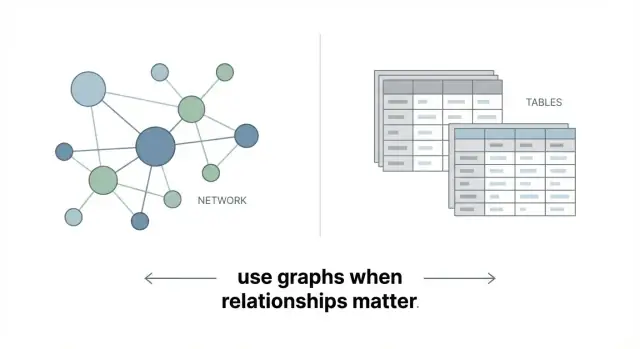
Een grafendatabase slaat data op als een netwerk in plaats van als een set tabellen. Het kernidee is eenvoudig:
Dat is het: een grafendatabase is gebouwd om verbonden data direct te representeren.
In een grafendatabase zijn relaties geen bijzaak—ze worden opgeslagen als echte, doorzoekbare objecten. Een relatie kan zijn eigen eigenschappen hebben (bijvoorbeeld een PURCHASED-relatie kan datum, kanaal en korting opslaan), en je kunt efficiënt van de ene node naar de volgende traverseren.
Dit is belangrijk omdat veel zakelijke vragen van nature over paden en verbindingen gaan: “Wie is met wie verbonden?”, “Hoeveel stappen verwijderd is dit entiteit?”, of “Wat zijn de gemeenschappelijke verbindingen tussen deze twee dingen?”
Relationele databases blinken uit in gestructureerde records: klanten, orders, facturen. Relaties bestaan daar ook, maar worden meestal indirect weergegeven via foreign keys, en het verbinden van meerdere hops betekent vaak joins over meerdere tabellen.
Grafen houden de verbindingen direct naast de data, dus het verkennen van meerstapsrelaties is vaak eenvoudiger te modelleren en te query'en.
Grafendatabases zijn uitstekend wanneer de relaties het belangrijkste punt zijn—aanbevelingen, fraudegroepen, afhankelijkheidsmapping, kennisgrafen. Ze zijn niet automatisch beter voor eenvoudige rapportages, totalen of sterk tabelachtige workloads. Het doel is niet om elke database te vervangen, maar grafen te gebruiken waar connectiviteit de waarde drijft.
De meeste zakelijke vragen gaan niet echt over losse records—ze gaan over hoe dingen verbonden zijn.
Een klant is niet zomaar een rij; hij is gekoppeld aan orders, apparaten, adressen, supporttickets, verwijzingen en soms andere klanten. Een transactie is niet alleen een gebeurtenis; ze is verbonden met een merchant, een betaalmethode, een locatie, een tijdvenster en een keten van gerelateerde activiteit. Wanneer de vraag is “wie/wat is met wat verbonden, en hoe?”, wordt relatiegegevens de hoofdrolspeler.
Grafendatabases zijn ontworpen voor traversals: je begint bij één node en “loopt” het netwerk door edges te volgen.
In plaats van herhaaldelijk tabellen te joinen, geef je het pad op dat je belangrijk vindt: Customer → Device → Login → IP Address → Other Customers. Die stap-voor-stap benadering sluit aan bij hoe mensen van nature fraude onderzoeken, afhankelijkheden traceren of aanbevelingen verklaren.
Het echte verschil verschijnt wanneer je meerdere hops nodig hebt (twee, drie, vijf stappen verwijderd) en je van tevoren niet weet waar de interessante verbindingen zullen verschijnen.
In een relationeel model veranderen multi-hop vragen vaak in lange rijen joins plus extra logica om duplicaten te vermijden en padlengte te controleren. In een graf is “vind alle paden tot N hops” een normale, leesbare patroon—vooral in het property graph-model dat veel grafendatabases gebruiken.
Edges zijn niet alleen lijnen; ze kunnen data dragen:
Die eigenschappen laten je betere vragen stellen: “verbonden binnen de laatste 30 dagen”, “sterkste banden”, of “paden die high-risk transacties bevatten”—zonder alles in aparte lookup-tabellen te hoeven stoppen.
Grafendatabases blinken uit wanneer je vragen afhankelijk zijn van verbondenheid: “wie is met wie verbonden, via wat, en hoeveel stappen verwijderd?” Als de waarde van je data in relatiegegevens zit (niet alleen in rijen met attributen), kan een grafmodel zowel datamodellering als query'en natuurlijker maken.
Alles in een netwerkvorm—vrienden, volgers, collega's, teams, verwijzingen—past netjes op nodes en relaties. Typische vragen zijn “wederzijdse connecties”, “kortste pad naar een persoon”, of “wie verbindt deze twee groepen?” Deze queries worden vaak onhandig (of traag) wanneer ze in veel join-tabellen worden geperst.
Aanbevelingssystemen zijn vaak afhankelijk van meerstapsverbindingen: gebruiker → item → categorie → vergelijkbare items → andere gebruikers. Grafendatabases zijn geschikt voor “mensen die X leuk vonden, vonden ook Y”, “items die vaak samen bekeken worden”, en “vind producten verbonden door gedeelde attributen of gedrag.” Dit is vooral nuttig als signalen divers zijn en je voortdurend nieuwe relatie-types toevoegt.
Fraudedetectiegrafen werken goed omdat verdacht gedrag zelden geïsoleerd is. Accounts, apparaten, transacties, telefoonnummers, e-mails en adressen vormen webben van gedeelde identifiers. Een graf maakt het eenvoudiger om ringen, herhaalde patronen en indirecte links te zien (bijv. twee “onverwante” accounts die via een keten van activiteit hetzelfde apparaat gebruiken).
Voor services, hosts, API's, calls en ownership is de belangrijkste vraag afhankelijkheid: “wat valt uit als dit verandert?” Grafen ondersteunen impactanalyse, root-cause onderzoek en "blast radius"-queries wanneer systemen onderling verbonden zijn.
Kennisgrafen verbinden entiteiten (mensen, bedrijven, producten, documenten) met feiten en referenties. Dit helpt bij zoeken, entity resolution en het traceren van waarom een feit bekend is (provenance) over veel gekoppelde bronnen.
Grafendatabases blinken uit wanneer de vraag echt over connecties gaat: wie is verbonden met wie, via welke keten, en met welke herhalende patronen. In plaats van tabellen steeds weer te joinen, stel je de relatievraag direct en blijft de query leesbaar naarmate het netwerk groeit.
Typische vragen:
Dit is nuttig voor klantondersteuning (“waarom stelden we dit voor?”), compliance (“toon de keten van eigendom”) en onderzoeken (“hoe heeft dit zich verspreid?”).
Grafen helpen je natuurlijke groeperingen te zien:
Je kunt dit gebruiken om gebruikers te segmenteren, fraudebendes te vinden of te begrijpen hoe producten samen worden gekocht. Het belangrijkste is dat de “groep” gedefinieerd wordt door hoe dingen verbonden zijn, niet door één kolom.
Soms is de vraag niet alleen “wie is verbonden”, maar “wie telt het meest” in het web:
Deze centrale knooppunten wijzen vaak op influencers, kritieke infrastructuur of knelpunten die het waard zijn om te monitoren.
Grafen zijn sterk in het zoeken naar herhaalbare vormen:
In Cypher (een veelgebruikte graph query-taal) kan een driehoekspatroon er zo uitzien:
MATCH (a)-[:KNOWS]->(b)-[:KNOWS]->(c)-[:KNOWS]->(a)
RETURN a,b,c
Zelfs als je nooit zelf Cypher schrijft, illustreert dit waarom grafen toegankelijk zijn: de query weerspiegelt het plaatje in je hoofd.
Relationele databases zijn fantastisch voor waar ze voor gebouwd zijn: transacties en goed-gestructureerde records. Als je data netjes in tabellen past (klanten, orders, facturen) en je het meestal opvraagt via ID's, filters en aggregaties, dan is relationeel vaak de eenvoudigste en veiligste keuze.
Joins zijn prima wanneer ze incidenteel en ondiep zijn. De frictie begint wanneer je belangrijkste vragen vaak veel joins vereisen, over meerdere tabellen.
Voorbeelden:
In SQL kunnen dit lange queries met herhaalde self-joins en complexe logica worden. Ze worden ook moeilijker te tunen naarmate de diepte van relaties groeit.
Grafendatabases slaan relaties expliciet op, zodat meerstaps traversals over verbindingen een natuurlijke operatie zijn. In plaats van tabellen op query-tijd aan elkaar te naaien, traverseer je verbonden nodes en edges.
Dat betekent vaak:
Als je team vaak meerstapsvragen stelt—“verbonden met”, “via”, “in hetzelfde netwerk als”, “binnen N stappen”—dan is een grafendatabase het overwegen waard.
Als je kernwerklast hoog-volume transacties, strikte schema's, rapportage en eenvoudige joins is, is relationeel meestal de betere standaard. Veel systemen gebruiken beide; zie /blog/practical-architecture-graph-alongside-other-databases.
Grafendatabases blinken uit wanneer relaties de “show” zijn. Als de waarde van je app niet afhangt van het traverseren van verbindingen (wie-ken-wo, hoe items zich verhouden, paden, buurten), kan een graf complexiteit toevoegen zonder veel opbrengst.
Als de meeste verzoeken zijn “haal gebruiker op per ID”, “update profiel”, “maak order”, en de benodigde data in één record (of een voorspelbare, kleine set tabellen) leeft, is een grafendatabase vaak overbodig. Je besteedt tijd aan het modelleren van nodes en edges, het tunen van traversals en het leren van een nieuwe querystijl—terwijl een relationele database dit patroon efficiënt en met vertrouwde tooling afhandelt.
Dashboards gebaseerd op totalen, gemiddelden en gegroepeerde metrics (omzet per maand, orders per regio, conversieratio per kanaal) passen meestal beter bij SQL en kolomgebaseerde analytics dan bij grafqueries. Grafengines kunnen sommige aggregatievragen beantwoorden, maar zelden op de makkelijkste of snelste manier voor zware OLAP-achtige workloads.
Wanneer je leunt op volwassen SQL-features—complexe joins met strikte constraints, geavanceerde indexstrategieën, stored procedures of goed ingebedde ACID-transacties—dan zijn relationele systemen vaak de natuurlijke keuze. Veel grafendatabases ondersteunen transacties, maar het omliggende ecosysteem en operationele patronen komen mogelijk niet overeen met wat je team al nodig heeft.
Als je data grotendeels een set onafhankelijke entiteiten is (tickets, facturen, sensorlezingen) met minimale cross-linking, voelt een grafmodel vaak geforceerd. Focus in die gevallen op een schoon relationeel schema (of documentmodel) en overweeg graf later als relatie-zware vragen centraal worden.
Een goede regel: als je je belangrijkste queries zonder woorden als “verbonden”, “pad”, “buurt” of “aanbevel” kunt beschrijven, is een grafendatabase waarschijnlijk niet de eerste keuze.
Grafendatabases schitteren als je verbindingen snel moet volgen—maar die kracht heeft een prijs. Voordat je je verbindt, is het nuttig te begrijpen waar grafen minder efficiënt, duurder of simpelweg anders te beheren zijn.
Grafendatabases slaan en indexeren relaties vaak op een manier die hops snel maakt (bijv. van een klant naar zijn apparaten naar transacties). Het nadeel is dat ze meer kunnen kosten in geheugen en opslag dan een vergelijkbare relationele opzet, vooral zodra je indexes toevoegt voor veelvoorkomende lookups en relatiegegevens direct toegankelijk houdt.
Als je werklast op een spreadsheet lijkt—grote tabel-achtige scans, rapportagequeries over miljoenen rijen of zware aggregatie—a kan een grafendatabase trager of duurder zijn voor hetzelfde resultaat. Grafen zijn geoptimaliseerd voor traversals (“wie is met wat verbonden?”), niet voor het verwerken van grote batches onafhankelijke records.
Operationele complexiteit kan een reële factor zijn. Backups, schalen en monitoring verschillen van wat veel teams gewend zijn met relationele systemen. Sommige grafplatforms schalen het best door grotere machines, terwijl anderen horizontaal schalen ondersteunen maar zorgvuldige planning rond consistentie, replicatie en querypatronen vereisen.
Je team heeft mogelijk tijd nodig om nieuwe modelleringspatronen en querybenaderingen te leren (bijv. het property graph-model en talen als Cypher). De leercurve is beheersbaar, maar vormt wel een kost—vooral als je volwassen SQL-gebaseerde rapportageworkflows vervangt.
Een praktische aanpak is om graf waar relaties het product zijn te gebruiken, en bestaande systemen te behouden voor rapportage, aggregatie en tabelanalyse.
Een nuttige manier om over grafmodellering te denken is eenvoudig: nodes zijn dingen, en edges zijn relaties tussen dingen. Mensen, accounts, apparaten, orders, producten, locaties—dat zijn nodes. “Bought”, “logged in from”, “works with”, “is parent of”—dat zijn edges.
De meeste productgerichte grafendatabases gebruiken het property graph-model: zowel nodes als edges kunnen eigenschappen hebben (key–value velden). Bijvoorbeeld, een edge PURCHASED kan date, amount en channel opslaan. Dit maakt het natuurlijk om “relaties met details” te modelleren.
RDF stelt kennis voor als triples: subject – predicate – object. Het is goed voor interoperabele vocabularia en het linken van data over systemen heen, maar verplaatst vaak “relatiedetails” naar extra nodes/triples. In de praktijk duwt RDF je naar standaardontologieën en SPARQL-patronen, terwijl property graphs meer aansluiten bij applicatiegegevensmodellering.
Je hoeft syntax niet vroeg te onthouden—wat telt is dat grafqueries meestal worden uitgedrukt als paden en patronen, niet als het joinen van tabellen.
Grafen zijn vaak schema-flexibel, wat betekent dat je een nieuwe node-label of property kunt toevoegen zonder zware migratie. Maar flexibiliteit vereist nog steeds discipline: definieer naamgevingsconventies, vereiste eigenschappen (bijv. id) en regels voor relatie-types.
Kies relatietypen die betekenis uitleggen (“FRIEND_OF” vs “CONNECTED”). Gebruik richting om semantiek te verduidelijken (bijv. FOLLOWS van volger naar creator), en voeg edge-eigenschappen toe wanneer de relatie eigen feiten heeft (tijd, confidence, rol, gewicht).
Een probleem is “relatie-gedreven” wanneer het lastige deel niet het opslaan van records is—maar het begrijpen hoe dingen verbonden zijn en hoe die verbindingen van betekenis veranderen afhankelijk van het pad dat je volgt.
Begin door je top 5–10 vragen in gewone taal op te schrijven—de vragen die stakeholders blijven stellen en die je huidige systeem langzaam of inconsistent beantwoordt. Goede grafkandidaten bevatten meestal zinnen als “verbonden met”, “via”, “vergelijkbaar met”, “binnen N stappen” of “wie anders”.
Voorbeelden:
Zodra je vragen hebt, map je de zelfstandige naamwoorden en werkwoorden:
Bepaal dan wat een relatie moet zijn versus een node. Een praktische regel: als iets zijn eigen attributen nodig heeft en je het aan meerdere partijen wilt koppelen, maak er dan een node van (bijv. een “Order” of “Login event” kan een node zijn wanneer het detail bevat en veel entiteiten verbindt).
Voeg eigenschappen toe die het mogelijk maken resultaten te beperken en relevantie te rangschikken zonder extra joins of nabehandeling. Typische hoge-waarde eigenschappen omvatten tijd, bedrag, status, kanaal en confidence score.
Als de meeste van je belangrijke vragen meerstapsverbindingen plus filteren op die eigenschappen vereisen, heb je waarschijnlijk te maken met een relatie-gedreven probleem waar grafendatabases goed in zijn.
De meeste teams vervangen niet alles door een grafendatabase. Een praktischer aanpak is je “source of record” te houden waar het al goed werkt (vaak SQL), en een grafendatabase te gebruiken als gespecialiseerde engine voor relatie-zware vragen.
Gebruik je relationele database voor transacties, constraints en canonieke entiteiten (klanten, orders, accounts). Projecteer vervolgens een relationele weergave naar een grafdatabase—alleen de nodes en edges die je nodig hebt voor verbonden queries.
Dit houdt auditing en datagovernance eenvoudig terwijl je snelle traversals mogelijk maakt.
Een grafendatabase blinkt uit als je hem koppelt aan een duidelijk afgebakende feature, zoals:
Begin met één feature, één team en één meetbaar resultaat. Je kunt later uitbreiden als het waarde bewijst.
Als je bottleneck het bouwen van een prototype is (niet het debatteren over het model), kan een vibe-coding platform zoals Koder.ai je helpen snel een simpele grafgestuurde app op te zetten: je beschrijft de feature in chat, genereert een React UI en Go/PostgreSQL-backend, en iterereert terwijl je datateam het grafschema en de queries valideert.
Hoe vers moet de graf zijn?
Een veelgebruikt patroon is: schrijf transacties naar SQL → publiceer change events → update de graf.
Grafen worden rommelig als ID's wegdrijven.
Definieer stabiele identifiers (bijv. customer_id, account_id) die matchen tussen systemen, en documenteer wie elk veld en elke relatie “bezit”. Als twee systemen dezelfde edge kunnen aanmaken (bijv. “knows”), bepaal dan welke voorrang heeft.
Als je een pilot plant, zie /blog/getting-started-a-low-risk-pilot-plan voor een gefaseerde rollout-aanpak.
Een grafpilot moet voelen als een experiment, niet als een rewrite. Het doel is te bewijzen (of te weerleggen) dat relatie-zware queries eenvoudiger en sneller worden—zonder het hele datastack te riskeren.
Begin met een beperkte dataset die al pijn veroorzaakt: te veel JOINs, breekbare SQL of trage “wie is met wat verbonden?”-vragen. Beperk het tot één workflow (bijv.: customer ↔ account ↔ device, of user ↔ product ↔ interaction) en definieer een handvol queries die je end-to-end beantwoord wilt zien.
Meet meer dan snelheid:
Als je de “voor” cijfers niet kunt noemen, vertrouw je de “na” niet.
Het is verleidelijk alles als nodes en edges te modelleren. Weersta dat. Let op “graph sprawl”: te veel node-/edge-types zonder een duidelijke query die ze nodig heeft. Elk nieuw label of relatie moet zijn plaats verdienen door een echte vraag mogelijk te maken.
Plan privacy, toegangscontrole en dataretentie vroeg. Relatiegegevens kunnen meer onthullen dan individuele records (bijv. connecties die gedrag impliceren). Definieer wie wat mag query'en, hoe resultaten worden geaudit en hoe data wordt verwijderd wanneer dat nodig is.
Gebruik een simpele sync (batch of streaming) om de graf te voeden terwijl je bestaande systeem de bron van waarheid blijft. Als de pilot waarde bewijst, kun je scope uitbreiden—zorgvuldig, use case voor use case.
Als je een database kiest, begin niet met technologie—begin met de vragen die je moet beantwoorden. Grafendatabases blinken als je moeilijkste problemen gaan over connecties en paden, niet alleen over het opslaan van records.
Gebruik deze checklist om de fit te controleren voordat je investeert:
Als je op de meeste vragen “ja” antwoordt, is een graf een sterke kandidaat—vooral als je multi-hop patroonmatching nodig hebt zoals:
Als je werk vooral bestaat uit eenvoudige lookups (per ID/email) of aggregaties (“totale verkoop per maand”), is een relationele database of key-value/document store meestal eenvoudiger en goedkoper in beheer.
Schrijf je top 10 zakelijke vragen als eenvoudige zinnen, test ze op echte data in een kleine pilot. Tijd de queries, noteer wat moeilijk uit te drukken is, en houd een kort logboek van modelwijzigingen die nodig waren. Als je pilot vooral neerkomt op “meer joins” of “meer caching”, is dat een signaal dat een graf de moeite waard kan zijn. Als het vooral counts en filters is, waarschijnlijk niet.
Een grafendatabase slaat gegevens op als nodes (entiteiten) en relaties (verbindingen) met eigenschappen op beide. Hij is geoptimaliseerd voor vragen als “hoe is A verbonden met B?” en “wie zit binnen N stappen?” in plaats van primair voor tabelrapportage.
Omdat relaties als echte, doorzoekbare objecten worden opgeslagen (niet alleen als foreign-key waardes). Je kunt efficiënt meerdere stappen doorkruisen en eigenschappen aan de relatie zelf hangen (bijv. date, amount, risk_score), wat vragen die sterk afhankelijk zijn van verbindingen makkelijker maakt om te modelleren en te query'en.
Relationele databases representeren relaties indirect (foreign keys) en vereisen vaak meerdere JOINs voor multi-hop vragen. Grafendatabases houden verbindingen dicht bij de data, dus variabele-diepte traversals (zoals 2–6 hops) zijn doorgaans directer uit te drukken en te onderhouden.
Gebruik een grafendatabase wanneer je kernvragen gaan over paden, buurten en patronen:
Veelvoorkomende grafvriendelijke queries omvatten:
Vaak wanneer je werklast vooral bestaat uit:
In die gevallen is een relationeel of analytics-systeem meestal eenvoudiger en goedkoper.
Modelleer een relatie als een edge wanneer die primair twee entiteiten verbindt en mogelijk eigen eigenschappen heeft (tijd, rol, gewicht). Modelleer het als een node wanneer het een gebeurtenis of entiteit met meerdere attributen is die aan veel partijen verbonden is (bijv. een Order of Login-gebeurtenis die user, device, IP en tijd koppelt).
Typische afwegingen zijn:
Property-graphs laten nodes en relaties eigenschappen hebben (key–value velden) en zijn gebruikelijk voor applicatiegerichte modellering. RDF vertegenwoordigt kennis als triples (subject–predicate–object) en sluit vaak aan bij gedeelde vocabularia en SPARQL.
Kies op basis van of je app-centrische relatie-eigenschappen nodig hebt (property graph) of interoperabele semantische modellering (RDF).
Behoud je bestaande systeem (vaak SQL) als de bron van waarheid, en projecteer vervolgens de relevante relaties naar een graf voor één afgebakende feature (aanbevelingen, fraude, identity resolution). Sync via batch of streaming, gebruik stabiele identifiers over systemen heen en meet succes (latency, querycomplexiteit, ontwikkeltijd) voordat je uitbreidt. Zie /blog/practical-architecture-graph-alongside-other-databases en /blog/getting-started-a-low-risk-pilot-plan.