Schalen in gewone taal
Schaalvergroting betekent "meer aankunnen zonder in te storten." Dat “meer” kan zijn:
- Meer gebruikers die tegelijk het product gebruiken
- Meer API-aanvragen per seconde
- Meer data die opgeslagen en doorzocht wordt
- Meer achtergrondwerk (e-mails, videobewerking, rapporten) dat achter de schermen draait
Als mensen het over schalen hebben, proberen ze meestal één of meer van deze aspecten te verbeteren:
- Capaciteit: hoeveel verkeer of data het systeem kan verwerken.
- Snelheid: hoe snel het reageert onder belasting.
- Betrouwbaarheid: hoe goed het blijft werken als er iets kapotgaat.
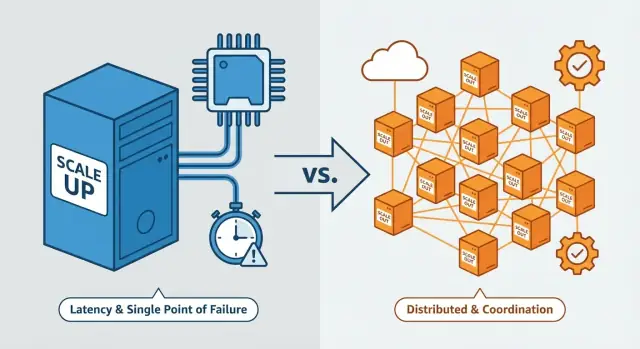
Het komt vaak neer op één thema: opschalen behoudt een "single system" gevoel, terwijl uitschalen je systeem verandert in een gecoördineerde groep onafhankelijke machines—en die coördinatie is waar de moeilijkheid enorm toeneemt.
Verticaal vs. horizontaal schalen (kort uitgelegd)
Verticale schaalvergroting (opschalen)
Verticale schaalvergroting betekent één machine krachtiger maken. Je houdt dezelfde basisarchitectuur, maar upgrade de server (of VM): meer CPU-cores, meer RAM, snellere schijven, hogere netwerkdoorvoer.
Denk eraan als het kopen van een grotere vrachtwagen: je hebt nog steeds één chauffeur en één voertuig, het vervoert alleen meer.
Horizontale schaalvergroting (uitschalen)
Horizontale schaalvergroting betekent meer machines of instanties toevoegen en het werk over hen verdelen—vaak achter een load balancer. In plaats van één krachtiger server draai je meerdere servers die samen werken.
Dat is alsof je meer vrachtwagens inzet: je kunt meer lading verplaatsen, maar je krijgt ook te maken met planning, routering en coördinatie.
Wat dwingt de keuze meestal af?
Veelvoorkomende triggers zijn:
- Verkeerspieken (marketingcampagnes, seizoenspatronen, virale groei)
- Gestaag productgroei over maanden of jaren
- Grotere datasets (meer klanten, meer events, meer historie om te bewaren)
Een belangrijke nuance: de meeste echte systemen gebruiken beide
Teams schalen vaak eerst verticaal omdat het snel is (upgrade van de box), en schalen horizontaal wanneer één machine tegen zijn limiet aanloopt of wanneer ze hogere beschikbaarheid nodig hebben. Volwassen architecturen combineren vaak beide: grotere nodes én meer nodes, afhankelijk van de bottleneck.
Waarom verticaal schalen eenvoudiger aanvoelt
Verticaal schalen is aantrekkelijk omdat het je systeem op één plek houdt. Met één node heb je meestal één bron van waarheid voor geheugen en lokale state. Eén proces beheert de in-memory cache, de jobqueue, de sessiestore (als sessies in geheugen zitten) en tijdelijke bestanden.
Minder bewegende onderdelen
Op één server zijn veel operationele zaken overzichtelijk omdat er weinig tot geen coördinatie tussen nodes nodig is:
- Debuggen is makkelijker omdat logs en metrics vaak op één plek staan.
- Fouten zijn duidelijker: of de machine is gezond of niet.
- Veel bottlenecks zijn lokaal en meetbaar.
Wanneer je opschaalt, trek je aan bekende knoppen: meer CPU/RAM, snellere opslag, betere indexen, queries en configuraties tunen. Je hoeft niet te herontwerpen hoe data verdeeld wordt of hoe meerdere nodes overeenkomen over “wat er vervolgens gebeurt.”
De afwegingen die je accepteert
Verticale schaal is niet "gratis"—het houdt complexiteit alleen beperkt. Uiteindelijk stuit je op grenzen: de grootste instantie die je kunt huren, afnemende meeropbrengst, of een steile kostencurve aan de bovenkant. Je loopt ook meer downtime-risico: als die ene grote machine faalt of onderhoud nodig heeft, valt een groot deel van het systeem uit tenzij je redundantie hebt toegevoegd.
Coördinatie-overhead: meer nodes, meer regels
Als je uitschaalt, krijg je niet alleen “meer servers.” Je krijgt meer onafhankelijke actoren die het eens moeten worden over wie verantwoordelijk is voor welk werk, op welk moment en met welke data.
Met één machine is coördinatie vaak impliciet: één geheugenruimte, één proces, één plek om state te bekijken. Met veel machines wordt coördinatie een feature die je moet ontwerpen.
Hoe coördinatie er in de praktijk uitziet
Veelgebruikte tools en patronen zijn:
- Leader election: kies één node om beslissingen te maken (bijv. welke worker de volgende job verwerkt). Als de leader uitvalt, moeten de anderen het eens worden over een vervanger.
- Locks/leases: zorg dat slechts één node een taak tegelijk uitvoert (zoals het versturen van een factuur of het draaien van een migratie). Leases verlopen, klokken lopen uit en “wie heeft de lock” kan ingewikkeld worden.
- Consensussystemen: een klein groepje nodes houdt een afgesproken weergave van kritieke state bij (configuratie, membership, leadership). Krachtig, maar operationeel veeleisend.
Symptomen wanneer coördinatie misgaat
Coördinatiebugs lijken zelden op nette crashes. Je ziet eerder:
- Race conditions: twee nodes handelen over dezelfde data in de verkeerde volgorde.
- Dubbele verwerking: dezelfde job draait twee keer omdat twee workers dachten dat hij onclaimed was.
- Split-brain: een netwerkstoring creëert twee “leaders”, elk die tegengestelde beslissingen neemt.
Deze problemen verschijnen vaak alleen onder echte load, tijdens deploys of bij gedeeltelijke storingen (een node is traag, een switch verliest pakketten, een zone hapert). Het systeem lijkt prima—tot het stress krijgt.
Data-partitionering en sharding zijn lastig goed te krijgen
Bij uitschalen kun je vaak niet alle data op één plek houden. Je splitst het over machines (shards) zodat meerdere nodes parallel kunnen opslaan en serveren. Die split is waar complexiteit begint: elke read en write hangt af van "welke shard dit record heeft?"
Veelgebruikte strategieën: range vs. hash
Range-partitionering groepeert data op een geordende sleutel (bijv. gebruikers A–F op shard 1, G–M op shard 2). Het is intuïtief en ondersteunt range-queries goed (“toon bestellingen van vorige week”). Het nadeel is ongelijke belasting: als één range populair wordt, wordt die shard een bottleneck.
Hash-partitionering voert een sleutel door een hash-functie en verdeelt de resultaten over shards. Het spreidt verkeer beter, maar maakt range-queries moeilijker omdat verwante records verspreid liggen.
Rebalancen is niet gratis
Voeg een node toe en je wilt die gebruiken—dus moet er data verplaatst worden. Verwijder je een node (gepland of door een storing) en andere shards moeten het overnemen. Rebalancing kan grote transfers, cache-warmups en tijdelijke prestatie-dalingen veroorzaken. Tijdens het verplaatsen moet je ook voorkomen dat er verouderde reads of verkeerd gerouteerde writes optreden.
Hot partitions en skew
Zelfs met hashing is echt verkeer niet uniform. Een beroemd account, een populair product of tijdsgebonden toegangspatronen kunnen reads/writes concentreren op één shard. Eén hot shard kan de doorvoer van het hele systeem beperken.
Operationeel werk dat je niet kunt negeren
Sharding introduceert doorlopende verantwoordelijkheden: routingregels onderhouden, migraties draaien, backfills uitvoeren na schema-wijzigingen en splitsen/samenvoegen plannen zonder clients te breken.
State: sessies, caches en achtergrondwerk
Kom naar een live omgeving
Implementeer en host je app wanneer je klaar bent om te delen of loadtests uit te voeren.
Als je uitschaalt, voeg je niet alleen meer servers toe—je krijgt ook meer kopieën van je applicatie. Het lastige is state: alles wat je app “onthoudt” tussen requests of terwijl werk in uitvoering is.
Sessies: waar staat de login?
Als een gebruiker inlogt op Server A maar de volgende request op Server B binnenkomt, weet B dan wie die gebruiker is?
- Sticky sessions blijven de gebruiker naar dezelfde server sturen. Simpel, maar kwetsbaar: restarts en ongelijke load worden zichtbaar voor gebruikers.
- Een gedeelde sessiestore (Redis of een database) laat elke server elke request afhandelen. Robuuster, maar het voegt kosten en een afhankelijkheid toe. Als de sessiestore vertraagt, voelt de hele app traag aan.
Caches: snel tot ze het niet eens zijn
Caches versnellen, maar meerdere servers betekent meerdere caches. Nu heb je te maken met:
- Invalidatie: als data verandert, hoe zorg je dat iedere cache stopt met het serveren van de oude waarde?
- Coherentie: nodes kunnen kortstondig van mening verschillen over wat “waar” is.
- Ongelijke hit rates: de ene server is warm terwijl een andere koud is, wat inconsistentie in prestaties geeft.
Achtergrondwerk: dubbele verwerking vermijden
Met veel workers kunnen background jobs twee keer draaien tenzij je er voor ontwerpt. Je hebt meestal een queue, leases/locks of idempotente joblogica nodig zodat “factuur verzenden” of “kaart belasten” niet twee keer gebeurt—vooral bij retries en restarts.
Consistentie- en concurrency-problemen nemen toe
Met één node (of één primaire database) is er meestal een duidelijke “bron van waarheid.” Als je uitschaalt, verspreiden data en requests zich over machines, en iedereen synchroon houden is een voortdurende zorg.
Sterke vs. eventual consistency (in gewone taal)
- Sterke consistentie: zodra een write slaagt, ziet iedere reader meteen de nieuwste waarde.
- Eventual consistency: updates verspreiden zich, maar voor een korte periode kunnen sommige readers oude waarden zien.
Eventual consistency is vaak sneller en goedkoper op schaal, maar het introduceert verrassende randgevallen.
Wat er misgaat in echte systemen
Veelvoorkomende issues:
- Verouderde reads: een gebruiker werkt zijn adres bij, refresh't en ziet nog steeds het oude adres.
- Schrijvingsconflicten: twee updates rond hetzelfde moment overschrijven elkaar.
- Verdwenen updates: “last write wins” gooit stilletjes een wijziging weg die had moeten worden samengevoegd.
Patronen die de schade beperken
Je kunt fouten niet uitbannen, maar je kunt ze afvangen:
- Idempotency keys: retries van “maak betaling” dubbel belasten niet.
- Retries met backoff: probeer opnieuw na 200ms, dan 400ms, dan 800ms (met jitter) om stampedes te vermijden.
- Deduplicatie: als berichten twee keer aankomen, verwerk ze één keer.
Waarom gedistribueerde transacties lastig zijn
Een transactie over services heen (order + voorraad + betaling) vereist dat meerdere systemen het eens zijn. Als één stap halverwege faalt, heb je compenserende acties en zorgvuldige administratie nodig. Klassiek "alles of niets" gedrag is lastig als netwerken en nodes onafhankelijk falen.
Waar sterke consistentie het meest telt
Gebruik sterke consistentie voor dingen die correct moeten zijn: betalingen, rekeningsaldi, voorraadtellingen, stoelreserveringen. Voor minder kritieke data (analytics, aanbevelingen) is eventual consistency vaak acceptabel.
Netwerk: latentie, timeouts en retries
Wanneer je opschaalt, zijn veel “calls” functie-aanroepen in hetzelfde proces: snel en voorspelbaar. Wanneer je uitschaalt, wordt dezelfde interactie een netwerkcall—met extra latentie, jitter en foutmodi waar je code op moet anticiperen.
Latentie is niet alleen “iets trager”
Netwerkcalls hebben vaste overhead (serialisatie, queuing, hops) en variabele overhead (congestie, routing, noisy neighbors). Zelfs als gemiddelde latentie acceptabel is, kunnen tail-latency (de langzaamste 1–5%) de gebruikerservaring domineren omdat één trage afhankelijkheid de hele request kan blokkeren.
Bandbreedte en packet loss worden ook constraints: bij hoge request-snelheden tellen “kleine” payloads snel op en retransmissies verhogen ongemerkt de load.
Timeouts, retries en retry-stormen
Zonder timeouts stapelen trage calls op en raken threads geblokkeerd. Met timeouts en retries kun je herstellen—tot retries de load versterken.
Een veelvoorkomend faalpatroon is een retry-storm: een backend vertraagt, clients timen out en retryen, retries verhogen de load, en de backend wordt nog trager.
Veilige retries vereisen meestal:
- Voorzichtige timeouts gebaseerd op echte latentie-data
- Beperkte retries (vaak 0–1) met exponentiële backoff en jitter
- Duidelijke regels welke operaties veilig te retryen zijn (idempotente operaties)
Load balancers en service discovery
Met meerdere instanties moeten clients weten waar ze requests heen sturen—via een load balancer of service discovery plus client-side balancing. In beide gevallen voeg je bewegende onderdelen toe: health checks, connection draining, ongelijke trafficverdeling en het risico van routeren naar half-broken instanties.
Backpressure en rate limiting
Om te voorkomen dat overbelasting zich verspreidt, heb je backpressure nodig: begrensde queues, circuit breakers en rate limiting. Het doel is snel en voorspelbaar falen in plaats van dat een kleine vertraging het hele systeem lamlegt.
Faalwijzen veranderen: gedeeltelijke uitval wordt normaal
Ship terwijl je leert
Zet een web-, server- of mobiele app op en iterereer terwijl knelpunten verschijnen.
Verticaal schalen faalt op een relatief eenvoudige manier: één grotere machine is nog steeds een enkel punt. Als die vertraagt of crasht, is de impact duidelijk.
Horizontaal schalen verandert het speelveld. Met veel nodes is het normaal dat sommige machines ongezond zijn terwijl anderen prima werken. Het systeem is “up”, maar gebruikers zien alsnog fouten, trage pagina’s of inconsistent gedrag. Dit is gedeeltelijke uitval, en het wordt de standaardtoestand waarop je ontwerpt.
Hoe gedeeltelijke uitval kan escaleren
In een uitgeschaalde omgeving hangen services van elkaar af: databases, caches, queues, downstream API's. Een klein probleem kan zich verspreiden:
- Eén node kan de database niet bereiken → hij retryt agressief
- Retries verhogen DB-load → latentie stijgt voor iedereen
- Hogere latentie veroorzaakt meer timeouts → meer retries → nog meer load
- Queues lopen vol, caches missen en downstream API's worden overspoeld
Redundantie helpt, maar voegt regels toe
Om gedeeltelijke uitval te overleven voeg je redundantie toe:
- Replicatie: meerdere kopieën van data of services
- Quorums: “succes alleen als N van M replicas het eens zijn”
- Multi-zone deploy: spreiden over zones zodat één zone-uitval niet alles neerhaalt
Dit verhoogt beschikbaarheid, maar introduceert randgevallen: split-brain, verouderde replicas en beslissingen als quorum niet bereikt wordt.
Veelgebruikte patronen zijn:
- Circuit breakers om een falende afhankelijkheid niet steeds te blijven bellen
- Bulkheads om failures te isoleren zodat één luidruchtig onderdeel niet alles overspoelt
- Graceful degradation om een eenvoudigere ervaring te serveren in plaats van harde fouten
Observability en debuggen over veel machines
Met één machine leeft het "systeemverhaal" op één plek: één set logs, één CPU-grafiek, één proces om te inspecteren. Met horizontaal schalen is het verhaal verspreid.
Meer machines, meer contextverlies
Elke extra node voegt een stroom logs, metrics en traces toe. Het lastige is niet het verzamelen van data—het is het correleren ervan. Een checkout-fout kan beginnen op een web-node, twee services aanroepen, een cache raken en lezen van een specifieke shard, met aanwijzingen op verschillende plaatsen en tijdslijnen.
Problemen worden selectief: één node heeft een verkeerde config, één shard is hot, één zone heeft hogere latentie. Debuggen voelt willekeurig omdat het meestal goed werkt.
Tracing en correlatie-ID's (in gewone taal)
Distributed tracing is als het toekennen van een trackingnummer aan een request. Een correlatie-ID is dat nummer. Je leidt het mee door services en zet het in logs zodat je één ID kunt pakken en de hele route end-to-end kunt zien.
Alerts die helpen in plaats van overweldigen
Meer componenten betekent meestal meer alerts. Zonder afstemming krijgen teams alert-fatigue. Streef naar actiegerichte alerts die duidelijk maken:
- Wat stuk is
- Wie er last van heeft
- Wat je eerst moet controleren
Monitor saturatie, niet alleen fouten
Capaciteitsproblemen verschijnen vaak vóór fouten. Monitor saturatiesignalen zoals CPU, geheugen, queue-diepte en connection-pool gebruik. Als saturatie op slechts een subset van nodes verschijnt, vermoed dan balancingsproblemen, sharding of configuratie-drift—niet alleen “meer verkeer”.
Deploys, upgrades en rollbacks worden riskanter
Bij uitschalen is een deploy niet langer “vervang één box.” Het coördineren van wijzigingen over veel machines terwijl de service beschikbaar blijft, is ingewikkelder.
Rolling updates, canaries en blue/green
Horizontale deploys gebruiken vaak rolling updates (nodes geleidelijk vervangen), canaries (een klein percentage verkeer naar de nieuwe versie) of blue/green (verkeer wisselen tussen twee volledige omgevingen). Ze verminderen het blast radius, maar vereisen: traffic shifting, health checks, connection draining en een definitie van "goed genoeg om door te gaan."
Versiespreiding is de standaard
Tijdens geleidelijke deploys draaien oude en nieuwe versies naast elkaar. Die versie-scheidingsfase betekent dat je systeem gemengd gedrag moet tolereren:
- Nieuwe nodes roepen oude nodes aan (en andersom)
- Oude clients raken nieuwe servers
- Verschillende cache-formaten of job-payloads kunnen tegelijk in omloop zijn
Compatibiliteit wordt een eis
API's moeten backward/forward compatibel zijn, niet alleen correct. Databaseschema-wijzigingen moeten bij voorkeur additief zijn (voeg nullable kolommen toe vóór ze verplicht worden). Message-formaten moeten versioneerbaar zijn zodat consumenten zowel oude als nieuwe events kunnen lezen.
Rollbacks zijn lastiger met datamigraties
Terugdraaien van code is eenvoudig; terugdraaien van data niet. Als een migratie velden verwijdert of herschrijft, kan oudere code crashen of records verkeerd behandelen. "Expand/contract" migraties helpen: deploy code die beide schema's ondersteunt, migreer data en verwijder oude paden later.
Config en secrets moeten consistent zijn
Met veel nodes wordt configuratiemanagement deel van de deploy. Eén node met verouderde config, verkeerde feature flags of verlopen credentials kan flauwe, moeilijk reproduceerbare fouten veroorzaken.
Kosten en teamcomplexiteit stijgen vaak met uitschalen
Verminder verrassingen bij coördinatie
Zet coördinatierisico's om in een concrete checklist met de planningsmodus.
Horizontaal schalen kan op papier goedkoper lijken: veel kleine instanties, elk met een lage uurprijs. Maar de totale kosten zijn niet alleen compute. Het toevoegen van nodes betekent ook meer netwerk, meer monitoring, meer coördinatie en meer tijd voor het consistent houden van alles.
Weinig grote boxes vs. veel kleine instanties
Verticale schaal concentreert uitgaven in minder machines—vaak minder hosts om te patchen, minder agents om te draaien, minder logs om te versturen, minder metrics om te scrapen.
Bij uitschalen is de prijs per unit misschien lager, maar je betaalt vaak voor:
- Load balancers, service discovery en extra bandbreedte
- Meer replicas om performance- en beschikbaarheidsdoelen te halen
- Hogere baseline capaciteit omdat je overal slack nodig hebt, niet alleen op één plek
Utilisatie en overprovisioning
Om pieken veilig aan te kunnen, draaien gedistribueerde systemen vaak niet volledig benut. Je houdt headroom op meerdere lagen (web, workers, databases, caches), wat kan betekenen dat je betaalt voor idle capaciteit over tientallen of honderden instances.
Operationele kosten: de verborgen multiplier
Uitschalen verhoogt on-call belasting en vereist volwassen tooling: alert-tuning, runbooks, incidentdrills en training. Teams besteden ook tijd aan eigendomsgedeling (wie is eigenaar van welke service?) en incidentcoördinatie.
Het resultaat: “goedkoper per unit” kan alsnog duurder uitpakken als je mensenuren, operationeel risico en het werk om veel machines als één systeem te laten gedragen meerekent.
De juiste keuze maken: wanneer opschalen vs. uitschalen
Kiezen tussen opschalen (bigger machine) en uitschalen (meer machines) gaat niet alleen over prijs. Het gaat over het type workload en hoeveel operationele complexiteit je team kan dragen.
Beslissingscriteria die echt tellen
Begin bij de workload:
- Type workload: CPU-bound taken profiteren vaak van opschalen; request-rijke webtrafiek profiteert vaak van uitschalen achter load balancing.
- Statefulness: als requests afhangen van lokale state (sessies, caches, lopend werk), dwingt uitschalen je om te herontwerpen waar die state leeft.
- Consistentiebehoefte: als correctheid streng is (betalingen, voorraad), brengt uitschalen moeilijkere trade-offs rond concurrency en consistentie met zich mee.
- Groei en pieken: voorspelbare groei kun je opvangen door in stappen op te schalen; onvoorspelbare pieken duwen je eerder naar horizontale capaciteit.
Een praktische voortgang (die tijd bespaart)
Een veelvoorkomend, verstandig pad:
- Optimaliseer duidelijke knelpunten (trage queries, missende indexen, inefficiënte endpoints).
- Schaal op eerst (grotere VM/DB-instantie), omdat het minder aannames verandert.
- Schaal uit wanneer één node echt de limiterende factor is—or wanneer je beschikbaarheid nodig hebt die één node niet kan bieden.
Hybride patronen zijn normaal
Veel teams houden de database verticaal (of licht geclusterd) terwijl ze de stateless app-tier horizontaal schalen. Dit beperkt sharding-pijn terwijl je snel web-capaciteit kunt toevoegen.
"Klaar" signalen om uit te schalen
Je bent dichterbij wanneer je solide monitoring en alerts hebt, geteste failover, loadtests en herhaalbare deploys met veilige rollbacks.
Vragen om te stellen voordat je committeert
- Kunnen we doelen halen door te optimaliseren of opschalen voor de komende 6–12 maanden?
- Waar komen sessies, caches en background jobs te liggen?
- Hebben we sterke consistentie nodig, en welke fouten accepteren we?
- Wat is ons plan voor data-partitionering (indien van toepassing) en rebalancing?
- Hebben we tooling om issues over meerdere nodes te debuggen?
Waar Koder.ai past (praktische hulp zonder alles opnieuw uit te vinden)
Veel schaalpijn is niet alleen architectuur—het is de operationele loop: veilig itereren, betrouwbaar deployen en snel terugrollen als de werkelijkheid anders blijkt dan het plan.
Als je web-, backend- of mobiele systemen bouwt en snel wilt bewegen zonder controle te verliezen, kan Koder.ai helpen je sneller te prototypen en te deployen terwijl je deze schaalbeslissingen neemt. Het is een vibe-coding platform waar je applicaties bouwt via chat, met een agent-gebaseerde architectuur onder de motorkap. In de praktijk betekent dat dat je kunt:
- Snel een React webapp, een Go + PostgreSQL backend of een Flutter mobiele app opzetten en itereren terwijl je bottlenecks ontdekt.
- Planning mode gebruiken om opschalen vs. uitschalen veranderingen door te denken voordat je ze implementeert.
- Deploy-risico verminderen met snapshots en rollback, wat belangrijker wordt naarmate je nodes toevoegt en versie-scheidingen normaal worden.
- Broncode exporteren wanneer je klaar bent om naar je eigen pipeline te verhuizen, en deployen/hosten met custom domains.
Omdat Koder.ai wereldwijd op AWS draait, kan het ook deploys in verschillende regio's ondersteunen om latency- en datatransferbeperkingen te adresseren—nuttig zodra multi-zone of multi-region beschikbaarheid deel wordt van je schaalverhaal.