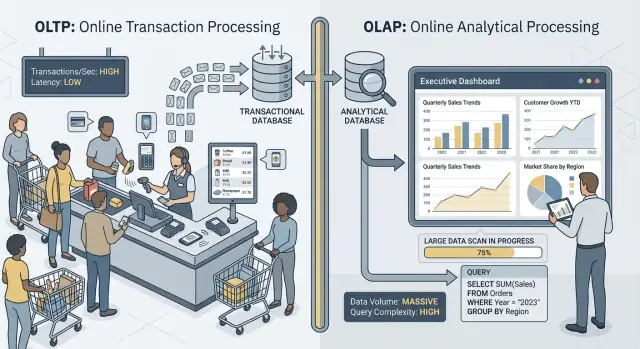
OLTP vs OLAP: wat het is (zonder vakjargon)
Als mensen “OLTP” en “OLAP” zeggen, spreken ze over twee heel verschillende manieren waarop een database wordt gebruikt.
OLTP: de database die het bedrijf laat draaien
OLTP (Online Transaction Processing) is de workload achter dagelijkse acties die elke keer snel en correct moeten zijn. Denk: “sla deze wijziging nu op.”
Typische OLTP-taken zijn een bestelling aanmaken, voorraad bijwerken, een betaling vastleggen of een klantadres wijzigen. Deze operaties zijn meestal klein (een paar rijen), frequent en moeten reageren in milliseconden omdat een persoon of ander systeem wacht.
OLAP: de database die het bedrijf verklaart
OLAP (Online Analytical Processing) is de workload die gebruikt wordt om te begrijpen wat er gebeurde en waarom. Denk: “scan veel data en vat samen.”
Typische OLAP-taken zijn dashboards, trendrapporten, cohortanalyse, forecasting en “slice-and-dice”-vragen zoals: “Hoe veranderde de omzet per regio en productcategorie in de afgelopen 18 maanden?” Deze queries lezen vaak veel rijen, voeren zware aggregaties uit en mogen seconden (of minuten) duren zonder dat dat ‘fout’ is.
Zelfde data, verschillende doelen — en verschillende behoeften
De kern is simpel: OLTP optimaliseert voor snelle, consistente schrijfacties en kleine reads, terwijl OLAP optimaliseert voor grote reads en complexe berekeningen. Omdat de doelen verschillen, verschillen vaak ook de beste database-instellingen, indexen, opslagindeling en schaalstrategie.
Let op het woord: zelden, niet nooit. Sommige kleine teams kunnen even één database delen, vooral bij beperkte datavolumes en strikte query-discipline. Latere secties behandelen wat er als eerste breekt, veelvoorkomende scheidingspatronen en hoe je veilig rapportage van productie haalt.
Snelle voorbeelden
- Checkout (OLTP): een klant klikt op “Betalen” en je app schrijft een order, betalingsstatus en voorraadupdates.
- Rapportagedashboard (OLAP): een manager opent een dashboard dat duizenden (of miljoenen) orders aggregeert om conversieratio, gemiddelde orderwaarde en wekelijkse trends te tonen.
Verschillende doelen, verschillende succesmaatstaven
OLTP en OLAP gebruiken misschien allebei “SQL”, maar ze zijn voor verschillende taken geoptimaliseerd — dat zie je terug in wat ieder als succes ziet.
OLTP: snelheid, gelijktijdigheid en correctheid
OLTP (transactionele) systemen voeden dagelijkse operaties: checkout-flows, accountupdates, reserveringen, supporttools. Prioriteiten zijn duidelijk:
- Snelle reactietijden voor kleine reads/writes (denk milliseconden)
- Veel gelijktijdige gebruikers zonder vertragingen
- Correctheid en consistentie, want een foutief saldo of dubbele order is een echt probleem
Succes wordt vaak gevolgd met latency-metrics zoals p95/p99 request time, foutpercentages en gedrag onder piekconcurrentie.
OLAP: scannen, aggregeren en flexibiliteit
OLAP (analytics) systemen beantwoorden vragen als “Wat veranderde dit kwartaal?” of “Welke segmenten churnden na de nieuwe prijsstelling?” Deze queries:
- Scannen grote hoeveelheden data over veel rijen
- Voeren aggregaties uit (SUM, COUNT, percentielen) en joins
- Veranderen vaak terwijl analisten verkennen en verfijnen
Succes hier lijkt meer op query-throughput, time-to-insight en het vermogen om complexe queries te draaien zonder per rapport handmatig te tunen.
Waarom “één systeem voor alles” compromissen afdwingt
Als je beide workloads in één database dwingt, vraag je die database om tegelijk uitstekend te zijn in kleine, veelvuldige transacties en in grote, verkennende scans. Het resultaat is meestal een compromis: OLTP krijgt onvoorspelbare latency, OLAP wordt afgeknepen om productie te beschermen, en teams ruziën over welke queries “toegestaan” zijn. Verschillende doelen verdienen verschillende succesmaatstaven — en meestal aparte systemen.
Resourceconcurrentie: wanneer analytics transacties wegneemt
Als OLTP (de dagelijkse transacties) en OLAP (rapportage en analyse) op dezelfde database draaien, strijden ze om dezelfde beperkte middelen. Het gevolg is niet alleen “langzamere rapporten.” Het zijn vaak tragere checkouts, vastlopende logins en onvoorspelbare app-haperingen.
CPU en geheugen: lange queries versus korte queries
Analytische queries zijn vaak langdurig en zwaar: joins over grote tabellen, aggregaties, sorteren en groeperen. Ze kunnen CPU-cores en, even belangrijk, geheugen voor hash-joins en sortbuffers monopolizeren.
Transactionele queries zijn doorgaans klein maar gevoelig voor latency. Als CPU verzadigd raakt of geheugendruk leidt tot veel evicties, moeten die kleine queries wachten achter de grote — zelfs als elke transactie maar een paar milliseconden werk nodig heeft.
Schijf-I/O: grote scans versus veel kleine reads/writes
Analytics triggert vaak grote tabelscans en leest veel pagina's sequentieel. OLTP doet het tegenovergestelde: veel kleine, willekeurige reads plus constante writes naar indexen en logs.
Samen dwingen ze het opslag-subsysteem om onverenigbare toegangs-patronen te combineren. Caches die OLTP hielpen kunnen door analytics-scans worden ‘weggespoeld’, en schrijf-latency kan stijgen wanneer de schijf data voor rapporten streamt.
Connection pool druk en wachtrijen
Een paar analisten die brede queries draaien kunnen verbindingen minutenlang bezet houden. Als je applicatie een fixed-size pool gebruikt, hopen verzoeken zich op en wachten op een vrije verbinding. Dat queuing-effect kan een gezond systeem kapot laten lijken: de gemiddelde latency lijkt acceptabel, maar de tail-latenties (p95/p99) worden pijnlijk.
Wat gebruikers daadwerkelijk merken
Vanuit het oogpunt van gebruikers verschijnt dit als timeouts, trage checkouts, vertraagde zoekresultaten en algemeen wankel gedrag — vaak “alleen tijdens rapportage” of “alleen aan het einde van de maand.” Het app-team ziet fouten; het analytics-team ziet trage queries; het echte probleem is gedeelde concurrentie eronder.
Data-indeling en indexeringsbehoeften trekken in tegengestelde richtingen
OLTP en OLAP gebruiken de database niet alleen anders — ze belonen tegengestelde fysieke ontwerpen. Als je probeert beide in één plek te bedienen, eindig je meestal met een compromis dat duur is en toch ondermaats presteert.
OLTP: geoptimaliseerd voor snelle, selectieve lookups
Transactionele workloads worden gedomineerd door korte queries die een klein deel van de data aanraken: haal één order op, werk één voorraadrij bij, lijst de laatste 20 events voor een gebruiker.
Dat stuurt OLTP-schema's naar rij-georiënteerde opslag en indexen die punt-lookups en kleine ranges ondersteunen (meestal op primaire sleutels, foreign keys en een paar belangrijke secundaire indexen). Het doel is voorspelbare, lage latency — vooral voor writes.
OLAP: geoptimaliseerd voor scannen, groeperen en samenvatten
Analytics moet vaak veel rijen lezen maar maar een paar kolommen: “omzet per week per regio”, “conversie per campagne”, “topproducten op marge”.
OLAP-systemen profiteren van kolomopslag (zodat je alleen benodigde kolommen leest), partitionering (om oude of irrelevante data snel te prunen) en pre-aggregatie (materialized views, rollups, samenvattingstabellen) zodat rapporten niet steeds dezelfde totalen opnieuw berekenen.
Waarom “indexeer voor alles” averechts werkt
Een veelvoorkomende reactie is indexen toevoegen totdat elk dashboard snel is. Maar elke extra index verhoogt de schrijfkosten: inserts, updates en deletes moeten meer structuren bijhouden. Het verhoogt ook opslag en kan onderhoudstaken zoals vacuuming, reindexing en backups vertragen.
Queryplanners en statistieken-drift (in gewone taal)
Databases kiezen queryplannen op basis van statistieken — schattingen van hoeveel rijen een filter matcht, hoe selectief een index is en hoe data verdeeld is. OLTP verandert data constant. Als distributies verschuiven, kunnen statistieken afdrijven en kan de planner een plan kiezen dat gisteren goed was maar vandaag traag is.
Voeg daar zware OLAP-queries aan toe die grote tabellen scannen en joinen, en je krijgt meer variabiliteit: het “beste plan” wordt moeilijker te voorspellen, en tunen voor de ene workload maakt de andere vaak slechter.
Locking, MVCC en onderhoudseffecten
Zelfs als je database “concurrency ondersteunt”, creëert het mixen van zware rapportage met live transacties subtiele vertragingen die moeilijk te voorspellen zijn — en nog lastiger uit te leggen aan een klant die naar een draaiende checkout kijkt.
Lange queries veroorzaken nog steeds lock-problemen
OLAP-queries scannen vaak veel rijen, joinen meerdere tabellen en duren seconden of minuten. In die tijd kunnen ze locks vasthouden (bijvoorbeeld op schema-objecten, of wanneer ze sorteren/aggregaten in temp-structuren moeten plaatsen) en ze verhogen vaak indirect lock-contention door veel rijen “in play” te houden.
Zelfs met MVCC (multi-version concurrency control) moet de database meerdere versies van dezelfde rij bijhouden zodat lezers en schrijvers elkaar niet blokkeren. Dat helpt, maar elimineert de contentie niet — vooral wanneer queries hete tabellen aanraken die transacties constant updaten.
MVCC heeft een verborgen kost: opruiming wordt moeilijker
MVCC betekent dat oude rijversies blijven bestaan totdat de database ze veilig kan verwijderen. Een langlopende rapportage kan een oud snapshot open houden, wat voorkomt dat opruiming ruimte terugwint.
Dat beïnvloedt:
- Vacuum/garbage collection: opruiming kan dead tuples/versies niet snel genoeg verwijderen.
- Bloat/fragmentatie: opslag groeit, indexen worden minder efficiënt en caches werken minder goed.
- Compactiedruk: sommige engines reageren met zwaarder achtergrondwerk, wat I/O en CPU van transacties afsnoept.
Het resultaat is een dubbele klap: rapportage maakt de database harder werkend en vertraagt het systeem in de loop van de tijd.
Isolatieniveaus vergroten latentievariabiliteit
Rapportagetools vragen soms sterkere isolatie (of draaien per ongeluk in een lange transactie). Hogere isolatie kan wachttijden op locks verhogen en meer versiebeheer vereisen. Vanuit OLTP-zicht zie je dit als onvoorspelbare spikes: de meeste orders schrijven snel, maar een paar stagneren plotseling.
Praktisch voorbeeld: maandafsluiting vertraagt orders
Aan het einde van de maand draait finance een “omzet per product”-query die orders en line items voor de hele maand scant. Terwijl die draait, worden nieuwe order-writes nog steeds geaccepteerd, maar vacuum kan oude versies niet terugwinnen en indexen draaien op. De order-API ziet af en toe timeouts — niet omdat het “down” is, maar omdat contentie en opruiming overhead stilletjes latency boven je limieten duwen.
Workloadpieken en onvoorspelbare latency
Prototypeer een OLTP-OLAP-scheiding
Map services, tabellen en rapportagestromen in Koder.ai planning-modus voordat je bouwt.
OLTP-systemen leven en sterven bij voorspelbaarheid. Een checkout of balansupdate is niet “grotendeels prima” als het 95% van de tijd snel is — gebruikers merken de trage momenten. OLAP is vaak bursty: een paar zware queries kunnen uren stil zijn en dan ineens veel CPU, geheugen en I/O verbruiken.
Pieken gebeuren om normale zakelijke redenen
Analytics-verkeer groep zich vaak rond routines:
- Ochtend “standup dashboards” waarbij veel mensen dezelfde charts vernieuwen
- Geplande rapporten die op het hele uur starten
- Maand- en kwartaalafsluitingen die lange scans en joins triggeren
OLTP-verkeer is meestal stabieler. Als beide workloads één database delen, vertalen analytics-pieken zich naar onvoorspelbare latency voor transacties — timeouts, trage pagina’s en retries die nog meer belasting toevoegen.
Waarom limieten en scheduling helpen — maar het probleem niet wegnemen
Je kunt schade beperken met tactieken zoals rapporten ’s nachts draaien, concurrency beperken, statement timeouts afdwingen of query cost caps instellen. Die zijn nuttige begrenzers, vooral voor “rapportage op productie.”
Maar ze verwijderen de fundamentele spanning niet: OLAP-queries zijn ontworpen om veel resources te gebruiken om grote vragen te beantwoorden, terwijl OLTP de hele dag kleine, snelle resource-slices nodig heeft. Zodra een onverwachte dashboard-refresh, ad-hoc query of backfill doorglipt, is de gedeelde database weer blootgesteld.
Het noisy neighbor-probleem
Op gedeelde infrastructuur kan één luidruchtige analytics-gebruiker of job cache monopolizeren, schijf verzadigen of CPU-scheduling belasten — zonder iets verkeerds te doen. De OLTP-workload wordt collateral damage, en het moeilijkste is dat de fouten er willekeurig uitzien: latency-spikes in plaats van duidelijke, reproduceerbare fouten.
Operationele complexiteit: backup, beveiliging en capacity planning
Het mixen van OLTP en OLAP veroorzaakt niet alleen performance-hoofdpijn — het maakt dagelijkse operaties ook complexer. De database wordt een enkele “allesdoos” en elke operationele taak erft de gecombineerde risico's van beide workloads.
Backups, restores en disaster recovery vertragen
Analytics-tabellen groeien vaak breed en snel (meer historie, meer kolommen, meer aggregaten). Dat extra volume verandert je recovery-verhaal.
Een volledige backup duurt langer, verbruikt meer opslag en vergroot de kans dat je je backup-window mist. Restores zijn erger: bij herstel herstel je niet alleen transactionele data die je app nodig heeft, maar ook grote analytische datasets die niet nodig zijn om het bedrijf draaiende te krijgen. Disaster recovery tests duren langer en worden dus minder vaak gedaan — precies het tegenovergestelde van wat je wilt.
Capacity planning wordt giswerk
Transactionele groei is meestal voorspelbaar: meer klanten, meer orders, meer rijen. Analytics-groei is vaak ongelijk: een nieuw dashboard, een andere retentiepolicy of één team dat “nog een jaar” raw events bewaart.
Als beide samenleven, kun je niet gemakkelijk beantwoorden:
- Groeien we door product-succes of omdat rapporten meer historie bewaren?
- Hebben we snellere storage voor transacties nodig of meer goedkope opslag voor analytics?
Die onzekerheid leidt tot overprovisioning (betalen voor headroom die je niet nodig hebt) of underprovisioning (verrassende uitval).
Guardrails zijn moeilijk eerlijk af te dwingen
In een gedeelde database kan één “onschuldige” query een incident worden. Je voegt guardrails toe zoals query timeouts, workload-quotas, geplande rapportage-vensters of workload management regels. Die helpen, maar zijn breekbaar: de app en analisten concurreren nu om dezelfde limieten, en beleidswijzigingen voor de ene groep kunnen de andere breken.
Beveiliging en toegangscontrole worden rommelig
Applicaties hebben meestal smalle, doelgerichte permissies nodig. Analisten hebben vaak brede leesrechten, soms over veel tabellen, om te verkennen en valideren. Beide in één database zetten vergroot de druk om bredere rechten te geven “zodat het rapport werkt”, waardoor de blast radius van fouten groeit en meer mensen gevoelige operationele data kunnen zien.
Schalen en kosten: je betaalt dubbel (of erger)
Verwijs een collega en verdien
Breng teamgenoten binnen met een verwijzing en verdien credits zodra nieuwe gebruikers meedoen.
Proberen OLTP en OLAP in dezelfde database te draaien lijkt vaak goedkoper — tot je gaat opschalen. Het probleem is niet alleen performance. De “juiste” manier om elke workload op te schalen duwt je naar verschillende infrastructuur, en combineren dwingt dure compromissen af.
OLTP-schaal is schrijfgestuurd (en meestal pijnlijk)
Transactionele systemen worden beperkt door writes: veel kleine updates, strikte latency en pieken die direct moeten worden opgevangen. OLTP opschalen betekent vaak verticaal schalen (meer CPU, snellere disks, meer geheugen) omdat write-zware workloads zich niet makkelijk verspreiden.
Als de verticale limieten bereikt zijn, kijk je naar sharding of andere write-scaling patronen. Dat verhoogt engineeringkosten en vereist vaak zorgvuldige applicatiewijzigingen.
OLAP-schaal is compute-gedreven (en vaak elastisch)
Analytics schalen anders: lange scans, zware aggregaties en veel read-throughput. OLAP-systemen schalen meestal door compute toe te voegen, en moderne setups scheiden vaak compute van storage zodat je query-power kunt verhogen zonder data te verplaatsen of te dupliceren.
Als OLAP de OLTP-database deelt, kun je analytics niet onafhankelijk opschalen. Je schaalt de hele database — zelfs als transacties prima zijn.
De verborgen rekening: OLTP-grade resources betalen voor analytics
Om transacties snel te houden terwijl je rapporten draait, overprovisioneren teams vaak de productie-database: extra CPU-headroom, high-end storage en grotere instances “voor het geval dat.” Dat betekent dat je OLTP-prijzen betaalt om OLAP-gedrag te ondersteunen.
Scheiden vermindert overprovisioning omdat elk systeem voor zijn taak kan worden gesized: OLTP voor voorspelbare low-latency writes, OLAP voor bursty zware reads. Het resultaat is vaak goedkoper — ook al zijn het “twee systemen” — omdat je stopt met het kopen van premium transactionele capaciteit voor rapportage op productie.
Veelvoorkomende architecturen die OLTP en OLAP scheiden
De meeste teams houden transactionele workload (OLTP) gescheiden van analytics workload (OLAP) door een tweede, lees-georiënteerd systeem toe te voegen in plaats van één database beide te laten bedienen.
Patroon 1: Read replica voor rapportage
Een veelgebruikte eerste stap is een read replica (of follower) van de OLTP-database, waar BI-tools queries draaien.
Voordelen: minimale app-wijzigingen, vertrouwde SQL, snel op te zetten.
Nadelen: het is nog steeds dezelfde engine en schema, dus zware rapporten kunnen replica-CPU/I/O verzadigen; sommige rapporten vereisen features die op replica's niet beschikbaar zijn; en replicatievertraging betekent dat cijfers minuten (of meer) achter kunnen lopen. Vertraging veroorzaakt ook verwarring: “waarom komt het niet overeen met productie?” tijdens incidenten.
Beste fit: kleine teams, beperkt datavolume, ‘near-real-time’ is mooi maar niet kritisch, en rapportage-queries zijn gecontroleerd.
Patroon 2: Dedicated data warehouse / analytics database
Hier blijft OLTP geoptimaliseerd voor writes en point-reads, terwijl analytics naar een data warehouse (of kolomgeoriënteerde analytics-DB) gaat die gebouwd is voor scans, compressie en grote aggregaties.
Voordelen: voorspelbare OLTP-prestaties, snellere dashboards, betere gelijktijdigheid voor analisten en duidelijker kosten/performance tuning.
Nadelen: je draait nu een extra systeem en hebt een datamodel (vaak een star schema) nodig dat analytics-vriendelijk is.
Beste fit: groeiende data, veel belanghebbenden, complexe rapportage of strikte OLTP-latency-eisen.
Patroon 3: CDC-gebaseerde pipeline naar analytics
In plaats van periodieke ETL stream je wijzigingen met CDC (change data capture) uit de OLTP-log naar het warehouse (vaak met ELT).
Voordelen: frissere data met minder belasting op OLTP, makkelijker incrementeel verwerken en betere auditability.
Nadelen: meer bewegende delen en zorgvuldige afhandeling van schemawijzigingen.
Beste fit: grotere volumes, hoge freshness-eisen en teams die klaar zijn voor datapijplijnen.
Data veilig van OLTP naar OLAP krijgen
Data van je transactionele database naar een analytics-systeem verplaatsen is minder “tabellen kopiëren” en meer “een betrouwbare, lage-impact pijplijn bouwen.” Het doel is simpel: analytics krijgt wat het nodig heeft zonder productietraffic in gevaar te brengen.
ETL vs ELT (in gewone taal)
ETL (Extract, Transform, Load) betekent dat je data schoonmaakt en herstructureert voordat het in het warehouse komt. Dit is nuttig als het warehouse duur is om in te berekenen of als je strikte controle wilt over wat wordt opgeslagen.
ELT (Extract, Load, Transform) laadt ruwe-achtige data eerst en transformeert daarna in het warehouse. Dit is vaak sneller op te zetten en makkelijker te evolueren: je bewaart vaak de bronhistorie en kunt transformaties aanpassen als vereisten veranderen.
Praktische regel: als businesslogica vaak verandert, vermindert ELT herwerk; als governance alleen gecureerde data vereist, past ETL beter.
CDC-basics: veranderingen vastleggen zonder zware queries
Change Data Capture (CDC) streamt inserts/updates/deletes van OLTP (vaak uit het databaselog) naar je analytics-systeem. In plaats van herhaaldelijk grote tabellen te scannen, verplaats je alleen wat veranderde.
Wat het mogelijk maakt:
- Near-real-time reporting zonder grote reads op productie
- Replays en backfills wanneer je analytics-tabellen moet herbouwen
- Geschiedenis bijhouden (wie wat veranderde en wanneer) als je change-events bewaart
Data-frisheid: real-time vs near-real-time vs dagelijks
Frisheid is een zakelijke beslissing met technische kosten.
- Real-time (seconden): best voor operationele dashboards, maar het moeilijkst stabiel te houden; kleine pijplijnhaperingen tonen zich direct.
- Near-real-time (minuten): een veelgebruikte sweet spot — goede besluitvorming zonder extreme complexiteit.
- Dagelijkse batches: het eenvoudigst en goedkoopst, goed voor finance-rapportage waar “gisteren” volstaat.
Definieer een duidelijke SLA (bijv. “data is maximaal 15 minuten achter”) zodat belanghebbenden weten wat “vers” betekent.
Data quality checks die stille fouten voorkomen
Pijplijnen falen vaak stilletjes — totdat iemand merkt dat de cijfers niet kloppen. Voeg lichte checks toe voor:
- Schemawijzigingen: nieuwe kolommen, hernoemde velden of typewijzigingen die data kunnen vernietigen.
- Late events: orders of betalingen die uren later binnenkomen; handel met een “lookback window”.
- Deduplicatie: retries en replays kunnen dubbel tellen; gebruik stabiele IDs en idempotente loads.
Deze waarborgen houden OLAP betrouwbaar en beschermen OLTP.
Wanneer één database delen acceptabel kan zijn
Plan je rapportage-architectuur
Plan replica-, warehouse- of CDC-stappen zonder productiestatistieken te belasten.
Het samenhouden van OLTP en OLAP is niet per definitie “verkeerd.” Het kan een verstandige tijdelijke keuze zijn wanneer de applicatie klein is, rapportagebehoeften beperkt en je harde grenzen kunt afdwingen zodat analytics je klanten niet verrast met trage checkouts of mislukte betalingen.
Situaties waarin het kan werken
Kleine apps met lichte analytics en strikte querylimieten doen het vaak prima op één database — vooral vroeg in de levenscyclus. De sleutel is eerlijk zijn over wat “licht” betekent: een handvol dashboards, beperkte rij-aantallen en een duidelijke bovengrens voor query-runtime en gelijktijdigheid.
Voor een beperkte set terugkerende rapporten kunnen materialized views of samenvattingstabellen de kosten van analytics verminderen. In plaats van raw transactions te scannen, bereken je dagelijkse totalen, topcategorieën of per-gebruiker rollups voor. Dat houdt de meeste queries kort en voorspelbaar.
Als gebruikers vertraagde cijfers kunnen accepteren, helpen off-peak rapportagevensters. Plan zwaardere jobs ’s nachts of tijdens lage traffic-periodes en overweeg een dedicated reporting-rol met striktere permissies en resource-limieten.
Guardrails die je moet toevoegen
- Stel statement timeouts in en beëindig runaway-queries.
- Beperk concurrentie voor rapportagegebruikers.
- Monitor p95/p99-latency voor kerntransacties apart van rapportagetijden.
Duidelijke waarschuwingssignalen dat je moet splitsen
Als je stijgende transactielatency ziet, terugkerende incidenten tijdens rapportagedraaien, connection pool-uitputting of verhalen als “één query haalde productie neer,” ben je voorbij de veilige zone. Dan is het scheiden van databases (of op zijn minst het gebruik van read replicas) geen optimalisatie meer maar basis operationele hygiëne.
Praktische migratie-checklist: van gedeeld naar gescheiden
Analytics van de productie-database halen draait minder om een grote herschrijving en meer om transparantie, doelen stellen en gecontroleerde stappen.
1) Inventariseer wat er vandaag echt gebeurt
Begin met bewijs, niet aannames. Haal een lijst:
- Top OLTP-endpoints/queries naar frequentie en p95/p99-latency (checkout, login, create order, etc.)
- Top OLAP-rapporten/dashboards naar runtime, scanvolume en zakelijke relevantie
Neem “verborgen” analytics mee: ad-hoc SQL van BI-tools, geplande exports en CSV-downloads.
2) Definieer targets: OLTP SLOs en analytics-freshness
Schrijf de targets op die je gaat optimaliseren:
- OLTP SLOs: p95/p99-latency, foutpercentages en piekdoorvoer die je moet kunnen ondersteunen
- Analytics-freshness: hoe oud is acceptabel (5 minuten, 1 uur, volgende dag) plus tijd om te herstellen als een pijplijn faalt
Dit voorkomt discussies als “het is traag” vs “het is acceptabel” en helpt bij het kiezen van de juiste architectuur.
3) Kies een scheidingspad
Kies de eenvoudigste optie die aan de targets voldoet:
- Read replica: snelst voor read-zware rapportage, maar kan nog steeds door dure queries onder druk komen en kent replicatievertraging
- Warehouse: beste keuze voor grote scans, veel joins en lange historie; meestal de juiste plek voor BI
- CDC-pijplijn (ETL/ELT): beste keuze wanneer je near-real-time analytics nodig hebt zonder productie te belasten
4) Roll-out veilig (parallel eerst)
- Valideer definities (tijdszones, refunds, “actieve gebruiker”, etc.) zodat cijfers matchen.
- Draai oude en nieuwe dashboards parallel voor een volledige business-cyclus.
- Schakel rapport per rapport over, beginnend met de pijnlijkste queries.
- Sluit directe “rapportage op productie” toegang af zodra stakeholders vertrouwen hebben in de nieuwe bron.
5) Voeg guardrails toe zodat je niet terugzakt
Monitor replica-lag/pijplijnvertragingen, dashboard-runtimes en warehouse-kosten. Stel query-budgetten in (timeouts, concurrency limits) en houd een incident-playbook: wat te doen als freshness verslechtert, loads pieken of kernmetrics uit elkaar lopen.
Een praktisch punt als je de app bouwt
Als je vroeg in een product staat en snel beweegt, is het grootste risico analytics per ongeluk in hetzelfde pad te bouwen als kerntransacties (bijv. dashboardqueries die stilletjes “productie-kritisch” worden). Een manier om dat te vermijden is de scheiding vooraf te ontwerpen — zelfs als je met een bescheiden read replica start — en het in je architectuur-checklist op te nemen.
Platformen zoals Koder.ai kunnen hier helpen omdat je de OLTP-zijde kunt prototypen (React-app + Go-services + PostgreSQL) en de scheiding naar reporting/warehouse in planningsmodus kunt schetsen voordat je live gaat. Naarmate het product groeit kun je broncode exporteren, het schema evolueren en CDC/ELT-componenten toevoegen zonder van “rapportage op productie” een permanente gewoonte te maken.