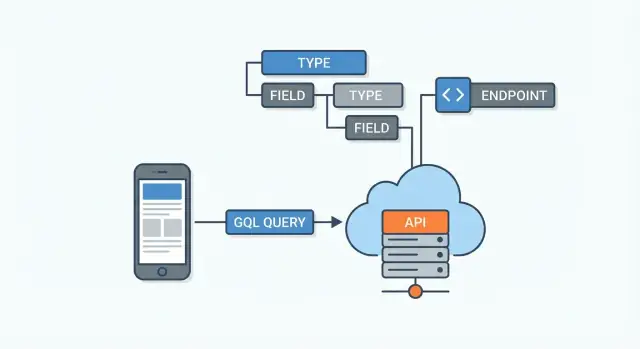
Wat GraphQL is (en wat het niet is)
GraphQL is een querytaal en runtime voor API's. Simpel gezegd: het is een manier voor een app (web, mobiel of een andere dienst) om een API gestructureerd om data te vragen — en voor de server om precies die data terug te geven die gevraagd is.
Het probleem dat het oplost
Veel API's dwingen clients om te accepteren wat een vast eindpunt teruggeeft. Dat leidt vaak tot twee problemen:
- Over-fetching: velden downloaden die je niet gebruikt.
- Under-fetching: meerdere verzoeken moeten doen om één scherm samen te stellen.
Met GraphQL kan de client exact de velden opvragen die hij nodig heeft, niet meer en niet minder. Dat is vooral handig wanneer verschillende schermen (of apps) verschillende stukken van dezelfde onderliggende data nodig hebben.
Waar GraphQL “zich bevindt”
GraphQL zit meestal tussen client-apps en je gegevensbronnen. Die bronnen kunnen zijn:
- databases
- bestaande REST-services
- third‑party API's
- microservices
De GraphQL-server ontvangt een query, bepaalt hoe elk gevraagd veld opgehaald wordt uit de juiste plek, en zet tenslotte de JSON-respons in elkaar.
Een snel mentaal model
Denk aan GraphQL als het bestellen van een responsvorm op maat:
- De client beschrijft de vorm van de data die hij wil.
- De server retourneert data in precies die vorm (waar mogelijk).
Wat GraphQL niet is
GraphQL wordt vaak verkeerd begrepen, dus een paar verduidelijkingen:
- Het is geen database (het slaat je data niet op).
- Het is niet automatisch sneller (het kan onnodige dataoverdracht verminderen, maar serverwerk blijft van belang).
- Het is niet “REST 2.0” (het is een alternatief API‑patroon met andere sterktes en afwegingen).
Als je die kerndefinitie — querytaal + runtime voor API's — onthoudt, heb je de juiste basis voor alles wat volgt.
Waarom GraphQL is gemaakt
GraphQL is gemaakt om een praktisch productprobleem op te lossen: teams besteedden te veel tijd aan het aanpassen van API's aan echte UI‑schermen.
Traditionele endpoint-gebaseerde API's dwingen vaak een keuze tussen het sturen van onnodige data of extra calls doen om te krijgen wat je nodig hebt. Naarmate producten groeien, leidt dat tot tragere pagina's, complexere clientcode en lastige afstemming tussen frontend- en backendteams.
De pijnpunten waar GraphQL op richt
Over-fetching gebeurt wanneer een eindpunt een “volledig” object terugstuurt terwijl een scherm maar een paar velden nodig heeft. Een mobiel profielscherm heeft misschien alleen naam en avatar nodig, maar de API stuurt adressen, voorkeuren, auditvelden en meer. Dat verspilt bandbreedte en schaadt de UX.
Under-fetching is het tegenovergestelde: geen enkel eindpunt heeft alles wat een view nodig heeft, dus de client moet meerdere verzoeken doen en resultaten samenvoegen. Dat verhoogt latency en de kans op gedeeltelijke fouten.
API's evolueren zonder constante versie-upgrades
Veel REST‑achtige API's reageren op veranderingen door nieuwe eindpunten toe te voegen of te versioneren (v1, v2, v3). Versionering kan nodig zijn, maar zorgt voor langdurig onderhoud: oude clients blijven oude versies gebruiken terwijl nieuwe features ergens anders worden toegevoegd.
GraphQL's aanpak is om het schema geleidelijk uit te breiden door velden en types toe te voegen, terwijl bestaande velden stabiel blijven. Dat vermindert vaak de druk om “nieuwe versies” te maken alleen om nieuwe UI‑behoeften te ondersteunen.
Eén API, veel clients
Moderne producten hebben zelden maar één consument. Web, iOS, Android en partnerintegraties hebben allemaal verschillende datavormen nodig.
GraphQL is ontworpen zodat elke client precies kan opvragen welke velden hij nodig heeft—zonder dat de backend voor elk scherm of apparaat een apart eindpunt hoeft te maken.
Het GraphQL-schema: het API‑contract
Een GraphQL-API wordt bepaald door zijn schema. Zie het als de overeenkomst tussen de server en alle clients: het beschrijft welke data bestaat, hoe het verbonden is en wat gevraagd of gewijzigd kan worden. Clients gokken niet op eindpunten—ze lezen het schema en vragen specifieke velden op.
Schema basics: types, velden, relaties
Het schema bestaat uit types (zoals User of Post) en velden (zoals name of title). Velden kunnen naar andere types verwijzen; zo modelleert GraphQL relaties.
Hier is een eenvoudig voorbeeld in Schema Definition Language (SDL):
type User {
id: ID!
name: String!
posts: [Post!]!
}
type Post {
id: ID!
title: String!
body: String
author: User!
comments: [Comment!]!
}
type Comment {
id: ID!
text: String!
author: User!
post: Post!
}
Sterk typen = validatie vóór uitvoering
Omdat het schema sterk getypt is, kan GraphQL een request valideren voordat het wordt uitgevoerd. Als een client vraagt naar een veld dat niet bestaat (bijv. Post.publishDate wanneer het schema dat veld niet heeft), kan de server het verzoek afwijzen of gedeeltelijk invullen met duidelijke fouten—zonder vaag “misschien werkt het” gedrag.
Veilig evolueren in de tijd
Schema's zijn bedoeld om te groeien. Je kunt meestal nieuwe velden toevoegen (zoals User.bio) zonder bestaande clients te breken, omdat clients alleen ontvangen wat ze opvragen. Het verwijderen of wijzigen van velden is gevoeliger, dus teams markeren velden vaak eerst als deprecated en migreren clients geleidelijk.
Queries: precies vragen wat je nodig hebt
Een GraphQL-API wordt doorgaans aangeboden via één enkel eindpunt (bijvoorbeeld /graphql). In plaats van veel URL's voor verschillende resources (zoals /users, /users/123, /users/123/posts) stuur je een query naar één plek en beschrijf je welke data je exact terug wilt.
Velden kiezen (inclusief geneste data)
Een query is in feite een “boodschappenlijst” van velden. Je kunt eenvoudige velden opvragen (zoals id en name) en ook geneste data (zoals recente posts van een gebruiker) in hetzelfde verzoek—zonder extra velden te downloaden die je niet nodig hebt.
Hier is een klein voorbeeld:
query GetUserWithPosts {
user(id: "123") {
id
name
posts(limit: 2) {
id
title
}
}
}
Een voorspelbare antwoordvorm
GraphQL-responses zijn voorspelbaar: de JSON die je terugkrijgt weerspiegelt de structuur van je query. Dat maakt het eenvoudiger om er frontend mee te werken, omdat je niet hoeft te raden waar data verschijnt of verschillende response-formaten te parsen.
Een vereenvoudigd antwoord kan er zo uitzien:
{
"data": {
"user": {
"id": "123",
"name": "Sam",
"posts": [
{ "id": "p1", "title": "Hello GraphQL" },
{ "id": "p2", "title": "Queries in Practice" }
]
}
}
}
Als je een veld niet opvraagt, wordt het niet opgenomen. Vraag je het wel op, dan kun je het op de overeenkomstige plek verwachten—dat maakt GraphQL-queries een nette manier om precies te halen wat elk scherm of feature nodig heeft.
Mutaties: data veilig schrijven
Queries zijn voor lezen; mutaties zijn hoe je data verandert in een GraphQL-API—records aanmaakt, bijwerkt of verwijdert.
Het typische mutatie‑proces
De meeste mutaties volgen hetzelfde patroon:
- Inputs: de client stuurt een gestructureerd input‑object met bijvoorbeeld de velden die mogen worden bijgewerkt.
- Validatie & autorisatie: de server controleert verplichte velden, format, uniciteit en of de gebruiker bevoegd is.
- Write: de server voert de databasewijziging uit (of roept een andere service aan).
- Payload/return type: de server retourneert een voorspelbare resultaatvorm zodat de UI kan updaten.
Waarom mutaties data retourneren
GraphQL-mutataties retourneren vaak bewust data, in plaats van alleen success: true. Het teruggeven van het bijgewerkte object (of ten minste het id en belangrijke velden) helpt de UI om:
- het scherm direct bij te werken zonder extra round‑trip
- de cache veilig te verversen (gebruikelijk met clients zoals Apollo Client)
- veldniveau-fouten in context te tonen
Een veelvoorkomend ontwerp is een “payload”-type dat zowel het bijgewerkte entiteit als eventuele fouten bevat.
Een basaal mutatievoorbeeld
mutation UpdateEmail($input: UpdateUserEmailInput!) {
updateUserEmail(input: $input) {
user {
id
email
}
errors {
field
message
}
}
}
Voor UI-gestuurde API's is een goede vuistregel: retourneer wat je nodig hebt om de volgende staat te renderen (bijv. de bijgewerkte user plus eventuele errors). Dat houdt de client simpel, voorkomt giswerk over wat er veranderde en maakt fouten gemakkelijker gracieus af te handelen.
Resolvers: hoe GraphQL het resultaat produceert
Deploy je GraphQL-app
Ga van lokaal idee naar gehoste app zonder meerdere tools te moeten combineren.
Een GraphQL-schema beschrijft wat gevraagd kan worden. Resolvers beschrijven hoe je het daadwerkelijk krijgt. Een resolver is een functie gekoppeld aan een specifiek veld in je schema. Wanneer een client dat veld opvraagt, roept GraphQL de resolver aan om de waarde op te halen of te berekenen.
Resolvers zijn functies per veld
GraphQL voert een query uit door de gevraagde vorm af te lopen. Voor elk veld zoekt het de bijbehorende resolver en voert die uit. Sommige resolvers geven gewoon een property terug van een reeds geladen object; andere doen een database‑call, bellen een andere service of combineren meerdere bronnen.
Als je schema User.posts heeft, kan de posts-resolver bijvoorbeeld de posts-tabel queryen op userId, of een aparte Posts-service aanroepen.
Schema-velden koppelen aan gegevensbronnen
Resolvers zijn de lijm tussen het schema en je echte systemen:
- Databases: SQL/NoSQL queries, stored procedures, ORM-aanroepen
- Services: REST/gRPC calls, interne microservices, third‑party API's
- Berekenende velden: totalen, formattering, afgeleide waarden
Deze mapping is flexibel: je kunt je backend-implementatie veranderen zonder de clientquery-vorm aan te passen—zolang het schema consistent blijft.
Prestaties: langzame resolver-ketens vermijden (N+1)
Omdat resolvers per veld en per item in een lijst kunnen draaien, kun je per ongeluk veel kleine calls triggeren (bijv. posts ophalen voor 100 gebruikers met 100 aparte queries). Dit “N+1”-patroon kan antwoorden traag maken.
Veelvoorkomende oplossingen zijn batching en caching (bijv. ID's verzamelen en in één query ophalen) en bewust zijn van welke geneste velden je clients aanmoedigt op te vragen.
Waar autorisatie en validatie plaatsvinden
Autorisatie wordt vaak afgedwongen in resolvers (of gedeelde middleware) omdat resolvers weten wie vraagt (via context) en welke data wordt geraadpleegd. Validatie gebeurt doorgaans op twee niveaus: GraphQL behandelt type/structuurvalidatie automatisch, terwijl resolvers bedrijfsregels afdwingen (zoals “alleen admins kunnen dit veld instellen”).
Fouten en gedeeltelijke resultaten
Iets wat nieuwkomers in GraphQL verrast is dat een verzoek kan “slagen” en toch fouten kan bevatten. Dat komt omdat GraphQL veld-georiënteerd is: als sommige velden kunnen worden opgelost en andere niet, kun je gedeeltelijke data terugkrijgen.
Hoe fouten eruitzien
Een typisch GraphQL-antwoord kan zowel data als een errors-array bevatten:
{
"data": {
"user": {
"id": "123",
"email": null
}
},
"errors": [
{
"message": "Not authorized to read email",
"path": ["user", "email"],
"extensions": { "code": "FORBIDDEN" }
}
]
}
Dat is nuttig: de client kan tonen wat er wel is (bijv. het gebruikersprofiel) en tegelijk het ontbrekende veld afhandelen.
Veldniveau-fouten vs verzoeksniveau-fouten
- Veldniveau-fouten ontstaan tijdens uitvoering (een resolver gooit een fout, permissie check faalt, een downstream service time‑out). Andere velden kunnen nog steeds lukken.
- Verzoeksniveau-fouten verhinderen uitvoering (ongeldige JSON, malformed query, schema-validatiefouten). In die gevallen is
data vaak null.
Gebruikersvriendelijke berichten zonder details te lekken
Schrijf foutmeldingen voor de eindgebruiker, niet voor debugging. Vermijd stacktraces, databasenaam of interne IDs. Een goed patroon is:
- Een korte, veilige
message
- Een stabiele machine-leesbare
extensions.code
- Optionele metadata die veilig is (bijv.
retryable: true)
Log de gedetailleerde fout server-side met een request ID zodat je kunt onderzoeken zonder internheden te tonen.
Tips voor consistente afhandeling over clients heen
Definieer een klein fout‑"contract" dat web- en mobiele apps delen: gemeenschappelijke extensions.code waarden (zoals UNAUTHENTICATED, FORBIDDEN, BAD_USER_INPUT), wanneer je een toast toont versus inline veldfouten, en hoe je met gedeeltelijke data omgaat. Consistentie voorkomt dat elke client zijn eigen foutregels verzint.
Subscriptions voor realtime updates
Lever vandaag een eerste query op
Zet de databehoefte van één scherm om in een werkende GraphQL-operatie binnen enkele minuten.
Subscriptions zijn GraphQL's manier om data naar clients te pushen zodra het verandert, in plaats van dat de client het steeds moet opvragen. Ze lopen meestal over een persistente verbinding (meestal WebSockets), zodat de server events kan sturen op het moment dat iets gebeurt.
Wat subscriptions zijn (en hoe ze werken)
Een subscription lijkt erg op een query, maar het resultaat is geen enkele respons. Het is een stroom van resultaten—elk item representeert een event.
Onder de motorkap “subscribe” een client op een topic (bijv. messageAdded in een chatapp). Wanneer de server een event publiceert, ontvangen alle verbonden subscribers een payload die overeenkomt met de selectie in de subscription.
Veelvoorkomende use cases
Subscriptions zijn ideaal wanneer gebruikers directe updates verwachten:
- Chatberichten die in een kamer verschijnen zonder verversen
- Notificaties (mentions, orderstatuswijzigingen, alerts)
- Live dashboards (systeemgezondheid, logistiek, trading, sportuitslagen)
Subscriptions vs polling
Bij polling vraagt de client elke N seconden “Is er iets nieuws?”. Het is simpel, maar kan veel verzoeken verspillen (vooral als er niets verandert) en voelt vertraagd.
Met subscriptions stuurt de server updates direct. Dat kan verkeer verminderen en de ervaring sneller maken—tegen de prijs van open verbindingen en extra realtime-infrastructuurbeheer.
Wanneer subscriptions onnodige complexiteit zijn
Subscriptions zijn niet altijd de moeite waard. Als updates zeldzaam, niet tijdkritisch of gemakkelijk te batchen zijn, volstaat polling of het opnieuw ophalen na gebruikersacties vaak. Ze voegen ook operationele overhead toe: schalen van verbindingen, auth op langlopende sessies, retries en monitoring. Een goede regel: gebruik subscriptions alleen wanneer realtime een productvereiste is, niet alleen omdat het leuk zou zijn.
Voordelen, nadelen en praktische afwegingen
GraphQL wordt vaak omschreven als “kracht voor de client”, maar die kracht heeft kosten. De afwegingen vooraf kennen helpt beslissen wanneer GraphQL goed past—en wanneer het te veel complexiteit toevoegt.
Waar GraphQL uitblinkt
De grootste winst is flexibel data-ophalen: clients mogen precies de velden opvragen die ze nodig hebben, wat over-fetching kan verminderen en UI-wijzigingen versnelt.
Een ander groot voordeel is het sterke contract dat het GraphQL-schema biedt. Het schema wordt een enkele bron van waarheid voor types en beschikbare operaties, wat samenwerking en tooling verbetert.
Teams zien vaak betere productiviteit aan de client-kant omdat front-end ontwikkelaars kunnen itereren zonder te wachten op nieuwe eindpunten, en tools zoals Apollo Client types kunnen genereren en data-ophalen stroomlijnen.
Veelvoorkomende nadelen om op te plannen
GraphQL kan caching complexer maken. Met REST is caching vaak “per URL”. Met GraphQL delen veel queries hetzelfde eindpunt, dus caching hangt af van query-vormen, genormaliseerde caches en zorgvuldige server/client-configuratie.
Aan de serverkant zijn er prestatie-valkuilen. Een ogenschijnlijk kleine query kan veel backend-calls triggeren tenzij je resolvers zorgvuldig ontwerpt (batching, N+1 vermijden en dure velden controleren).
Er is ook een leercurve: schema's, resolvers en clientpatronen kunnen onbekend zijn voor teams die gewend zijn aan endpoint-gebaseerde API's.
Beveiliging en operatie
Omdat clients veel kunnen opvragen, moeten GraphQL-API's limieten afdwingen op query-diepte en complexiteit om misbruik of per ongeluk te grote verzoeken te voorkomen.
Authenticatie en autorisatie moeten per veld worden afgedwongen, niet alleen op routeniveau, omdat verschillende velden verschillende toegangsregels kunnen hebben.
Operationeel is het belangrijk te investeren in logging, tracing en monitoring die GraphQL begrijpen: track operatienamen, variabelen (voorzichtig), resolver‑tijden en foutpercentages zodat je trage queries en regressies vroeg ziet.
GraphQL vs REST: hoe ze verschillen
GraphQL en REST helpen beide apps om met servers te praten, maar ze structureren dat gesprek op verschillende manieren.
Hoe REST typisch werkt
REST is resource-gebaseerd. Je haalt data op door meerdere eindpunten te bellen (URL's) die “dingen” representeren zoals /users/123 of /orders?userId=123. Elk eindpunt retourneert een vaste datavorm die de server bepaalt.
REST leunt ook op HTTP-semantiek: methoden zoals GET/POST/PUT/DELETE, statuscodes en caching-regels. Dat voelt natuurlijk bij eenvoudige CRUD of wanneer je sterk vertrouwt op browser/proxy-caching.
Hoe GraphQL werkt
GraphQL is schema-gebaseerd. In plaats van veel eindpunten heb je meestal één endpoint, en de client stuurt een query die exact beschrijft welke velden hij wil. De server valideert dat verzoek tegen het GraphQL-schema en retourneert een response die overeenkomt met de query-vorm.
Deze “client-gedreven selectie” is waarom GraphQL over-fetching en under-fetching kan verminderen, vooral voor UI‑schermen die data uit meerdere gerelateerde modellen nodig hebben.
Wanneer REST eenvoudiger kan zijn
REST is vaak geschikter wanneer:
- Je werkt met bestanden downloaden/uploaden (streaming, content-types, range-requests).
- Je API grotendeels eenvoudige CRUD is met voorspelbare payloads.
- Je sterk vertrouwt op HTTP-caching aan de edge en maximale compatibiliteit met bestaande tooling wilt.
Hybride benaderingen zijn gebruikelijk
Veel teams combineren beide:
- Gebruik GraphQL voor UI-gericht data-ophalen (web/mobile schermen).
- Houd REST voor specifieke services zoals auth callbacks, webhooks, bestandsverwerking of interne microservice-eindpunten.
De praktische vraag is zelden “Wat is beter?” maar eerder “Welke aanpak past bij deze use case met de minste complexiteit?”
Hoe je een GraphQL-API ontwerpt (beginners-checklist)
Krijg credits voor delen
Creëer content over je build en verdien credits om sneller door te blijven bouwen.
Het ontwerpen van een GraphQL-API is het gemakkelijkst als je het ziet als een product voor de mensen die schermen bouwen, niet als een spiegel van je database. Begin klein, valideer met echte use cases en breid uit als de behoeften groeien.
1) Begin bij UI‑schermen (niet bij tabellen)
Maak een lijst van belangrijke schermen (bijv. “Productlijst”, “Productdetails”, “Checkout”). Noteer voor elk scherm exact welke velden en interacties het nodig heeft.
Dit helpt god‑queries te vermijden, vermindert over-fetching en maakt duidelijk waar filtering, sortering en paginatie nodig zijn.
2) Modelleer domeintypes, voeg operaties stapsgewijs toe
Definieer eerst je kern‑types (bijv. User, Product, Order) en hun relaties. Voeg vervolgens toe:
- een klein aantal queries die echte schermen dekken
- een klein aantal mutaties die echte gebruikersacties afdekken (
addToCart, placeOrder)
Geef de voorkeur aan business‑taal in namen boven databasenaamgeving. “placeOrder” communiceert intentie beter dan “createOrderRecord”.
3) Naamgeving en paginatie basics
Houd naamgeving consistent: enkelvoud voor items (product), meervoud voor collecties (products). Voor paginatie kies je meestal één:
- Cursor-based: beter voor veranderende lijsten en infinite scroll (stabieler)
- Offset-based: eenvoudiger, maar kan items overslaan/dupliceren als data verandert
Kies vroeg, want het bepaalt de structuur van je API-response.
4) Documenteer terwijl je bouwt
GraphQL ondersteunt beschrijvingen direct in het schema—gebruik die voor velden, argumenten en edgecases. Voeg daarnaast een paar copy‑paste voorbeelden toe in je docs (inclusief paginatie en veelvoorkomende foutscenario's). Een goed beschreven schema maakt introspectie en API-explorers veel nuttiger.
Beginnen met GraphQL draait vooral om het kiezen van een paar goed ondersteunde tools en het opzetten van een workflow waar je op vertrouwt. Je hoeft niet alles tegelijk aan te nemen—haal één query werkend end‑to‑end en breid daarna uit.
Kies een serverframework
Kies een server op basis van je stack en hoeveel “batterijen inbegrepen” je wilt:
- Apollo Server: populaire keuze met groot ecosysteem en goede docs.
- GraphQL Yoga: lichtgewicht, moderne defaults, prettige developer experience.
- NestJS: ideaal als je al Nest gebruikt en GraphQL geïntegreerd wil met modules, DI en patronen.
Een praktische eerste stap: definieer een klein schema (een paar types + één query), implementeer resolvers en koppel een echte gegevensbron (ook als het een in‑memory lijst is).
Als je sneller van idee naar werkende API wilt, kan een vibe‑coding platform zoals Koder.ai helpen bij het scaffolden van een kleine full‑stack app (React frontend, Go + PostgreSQL backend) en het itereren op GraphQL schema/resolvers via chat—en wanneer je er klaar voor bent kun je de broncode exporteren.
Kies een client-aanpak
Aan de frontend hangt je keuze vaak af van of je voorkeur hebt voor opinionated conventies of flexibiliteit:
- Apollo Client: veelgebruikt, sterke caching en devtools.
- Relay: striktere patronen, vaak gebruikt door grotere apps die consistentie willen.
- urql: kleiner, composable, goed voor teams die controle willen.
Bij migratie van REST, begin met GraphQL voor één scherm of feature en houd REST voor de rest totdat de aanpak zich bewezen heeft.
Testen: schema + resolvers + integratie
Behandel je schema als een API-contract. Nuttige testlagen zijn onder andere:
- Schema-validatie (bouw het schema in CI; faal snel bij ongeldige types)
- Resolver unit tests (mock gegevensbronnen en verifieer edgecases en auth‑regels)
- Integratietests (voer echte GraphQL‑operaties uit tegen een testserver en database)
Vervolgstappen
Verder leren kan met onderwerpen zoals "GraphQL vs REST" en "GraphQL schema‑ontwerp".