22 sep 2025·8 min
Wat is Kafka en hoe wordt het gebruikt in moderne systemen?
Leer wat Apache Kafka is, hoe topics en partitions werken en waar Kafka past in moderne systemen voor realtime events, logs en datapijplijnen.
Leer wat Apache Kafka is, hoe topics en partitions werken en waar Kafka past in moderne systemen voor realtime events, logs en datapijplijnen.
Apache Kafka is een gedistribueerd event streaming platform. Simpel gezegd is het een gedeelde, duurzame “leiding” waarmee veel systemen feiten over wat er gebeurde kunnen publiceren en andere systemen die feiten kunnen lezen—snel, op schaal en in volgorde.
Teams gebruiken Kafka wanneer data betrouwbaar tussen systemen moet bewegen zonder strakke koppeling. In plaats van dat één applicatie direct een andere aanroept (en faalt als die down of traag is), schrijven producers events naar Kafka. Consumers lezen ze wanneer ze klaar zijn. Kafka slaat events op voor een configureerbare periode, zodat systemen kunnen herstellen van uitval en zelfs geschiedenis kunnen herprocessen.
Deze gids is voor productgerichte engineers, data-collega’s en technische leiders die een praktisch mentaal model van Kafka willen.
Je leert de kernbouwstenen (producers, consumers, topics, brokers), hoe Kafka schaalt met partitions, hoe het events opslaat en opnieuw afspeelt, en waar het past in event-driven architectuur. We behandelen ook veelvoorkomende use cases, bezorggaranties, beveiligingsbasics, operationele planning en wanneer Kafka wel of niet het juiste hulpmiddel is.
Kafka is het makkelijkst te begrijpen als een gedeelde event-log: applicaties schrijven events naar die log en andere applicaties lezen die events later—vaak realtime, soms uren of dagen later.
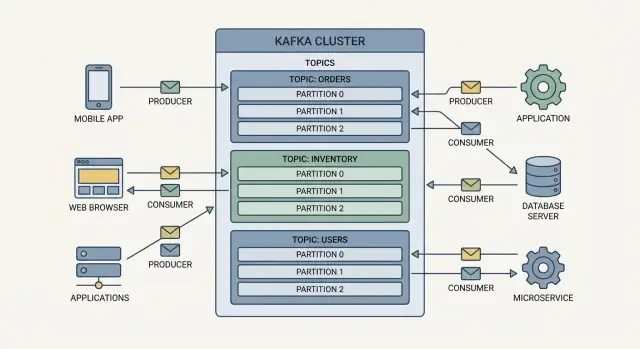
Producers zijn de schrijvers. Een producer kan een event publiceren zoals “order placed”, “payment confirmed” of “temperature reading”. Producers sturen events niet rechtstreeks naar specifieke apps—ze sturen ze naar Kafka.
Consumers zijn de lezers. Een consumer kan een dashboard aandrijven, een verzendworkflow triggeren of data laden in analytics. Consumers bepalen wat ze met events doen en kunnen in hun eigen tempo lezen.
Events in Kafka worden gegroepeerd in topics, dat zijn in feite benoemde categorieën. Bijvoorbeeld:
orders voor order-gerelateerde eventspayments voor betalings-eventsinventory voor voorraadwijzigingenEen topic wordt de “source of truth” stream voor dat soort events, waardoor meerdere teams dezelfde data kunnen hergebruiken zonder één-op-één integraties te bouwen.
Een broker is een Kafka-server die events opslaat en ze aan consumers serveert. In de praktijk draait Kafka als een cluster (meerdere brokers die samenwerken) zodat het meer verkeer aan kan en blijft draaien als een machine uitvalt.
Consumers draaien vaak in een consumer group. Kafka verdeelt het leeswerk over de groep, zodat je meer consumer-instanties kunt toevoegen om verwerking in parallel te schalen—zonder dat iedere instantie hetzelfde werk doet.
Kafka schaalt door werk te verdelen in topics (stromen van gerelateerde events) en vervolgens elk topic op te delen in partitions (kleinere, onafhankelijke slices van die stream).
Een topic met één partition kan binnen een consumer group maar door één consumer tegelijk gelezen worden. Voeg meer partitions toe en je kunt meer consumers toevoegen om events parallel te verwerken. Zo ondersteunt Kafka hoge-volume event streaming en realtime datapijplijnen zonder dat elk systeem een bottleneck wordt.
Partitions helpen ook de load over brokers te spreiden. In plaats van één machine alle writes en reads voor een topic te laten verwerken, kunnen meerdere brokers verschillende partitions hosten en het verkeer delen.
Kafka garandeert ordering binnen één partition. Als events A, B en C in die volgorde naar dezelfde partition geschreven worden, zullen consumers ze A → B → C lezen.
Ordering over partitions heen is niet gegarandeerd. Als je strikte volgorde nodig hebt voor een specifieke entiteit (zoals een klant of order), zorg er dan meestal voor dat alle events voor die entiteit naar dezelfde partition gaan.
Wanneer producers een event sturen, kunnen ze een key meesturen (bijvoorbeeld order_id). Kafka gebruikt die key om gerelateerde events consistent naar dezelfde partition te routeren. Dat geeft voorspelbare ordering voor die key terwijl het topic als geheel over veel partitions kan schalen.
Elke partition kan gerepliceerd worden naar andere brokers. Als één broker uitvalt, kan een andere broker met een replica het overnemen. Replicatie is een belangrijke reden dat Kafka vertrouwd wordt voor mission-critical pub-sub messaging en event-driven systemen: het verbetert beschikbaarheid en fouttolerantie zonder dat elke applicatie zelf failover-logica hoeft te bouwen.
Een belangrijk idee in Apache Kafka is dat events niet alleen worden doorgegeven en vergeten. Ze worden naar schijf geschreven in een geordende log, zodat consumers ze nu of later kunnen lezen. Dat maakt Kafka niet alleen nuttig voor het verplaatsen van data, maar ook voor het bewaren van een duurzaam historisch overzicht van wat er gebeurde.
Als een producer een event naar een topic stuurt, voegt Kafka het toe aan de opslag op de broker. Consumers lezen vervolgens uit die opgeslagen log in hun eigen tempo. Als een consumer een uur down is, bestaan de events nog en kan deze bij herstel bijlezen.
Kafka bewaart events volgens retentionbeleid:
Retention wordt per topic ingesteld, zodat je “audit trail”-topics anders kunt behandelen dan high-volume telemetry-topics.
Sommige topics zijn meer een changelog dan een historisch archief—bijvoorbeeld “huidige klantinstellingen”. Log compaction houdt in elk geval de meest recente event per key, terwijl oudere overschreven records verwijderd kunnen worden. Zo blijf je een duurzame bron van de laatste staat houden zonder onbeperkte groei.
Omdat events bewaard blijven, kun je ze opnieuw afspelen om status te reconstrueren:
In de praktijk wordt replay gestuurd door waar een consumer begint te lezen (zijn offset), wat teams een krachtig veiligheidsnet geeft wanneer systemen evolueren.
Kafka is gebouwd om data te blijven laten stromen, zelfs als delen van het systeem falen. Dat doet het met replicatie, duidelijke regels over wie “in charge” is van elke partition en configureerbare write acknowledgments.
Elke topic-partition heeft één leader broker en één of meer follower replicas op andere brokers. Producers en consumers praten met de leader voor die partition.
Followers kopiëren continu de data van de leader. Als de leader uitvalt, kan Kafka een up-to-date follower promoveren tot nieuwe leader, zodat de partition beschikbaar blijft.
Als een broker faalt, worden de partitions waarvoor hij leader was even onbeschikbaar. De controller van Kafka (interne coördinatie) detecteert de uitval en start een leader election voor die partitions.
Als minstens één follower-replica voldoende up-to-date is, kan die het overnemen en hervatten producers/consumers hun werk. Als geen in-sync replica beschikbaar is, kan Kafka schrijven pauzeren (afhankelijk van instellingen) om te voorkomen dat bevestigd data verloren gaat.
Twee belangrijke instellingen bepalen duurzaamheid:
Op conceptueel niveau:
Om duplicaten bij retries te verminderen, combineren teams vaak veiligere acks met idempotente producers en robuuste consumerafhandeling.
Hogere veiligheid betekent meestal wachten op meer bevestigingen en meer replicas in sync houden, wat latentie kan toevoegen en piekdoorvoer kan verlagen.
Lagere-latentie instellingen kunnen prima zijn voor telemetry of clickstream data waar af en toe verlies acceptabel is, maar betalingen, voorraad en auditlogs rechtvaardigen meestal extra veiligheid.
Event-driven architectuur (EDA) is een manier van systemen bouwen waarbij gebeurtenissen in het bedrijf—een order geplaatst, een betaling bevestigd, een pakket verzonden—worden weergegeven als events waarop andere delen van het systeem kunnen reageren.
Kafka zit vaak in het centrum van EDA als de gedeelde “event stream”. In plaats van dat Service A Service B direct aanroept, publiceert Service A een event (bijvoorbeeld OrderCreated) naar een Kafka-topic. Elk aantal andere services kan dat event consumeren en actie ondernemen—een e-mail sturen, voorraad reserveren, fraud checks starten—zonder dat Service A hoeft te weten dat ze bestaan.
Omdat services via events communiceren, hoeven ze niet voor elke interactie request/response API’s te coördineren. Dit vermindert strakke afhankelijkheden tussen teams en maakt het makkelijker om nieuwe features toe te voegen: je kunt een nieuwe consumer introduceren voor een bestaand event zonder de producer te veranderen.
EDA is van nature asynchroon: producers schrijven events snel en consumers verwerken ze in hun eigen tempo. Tijdens verkeerspieken helpt Kafka de piek op te vangen zodat downstream systemen niet meteen overbelast raken. Consumers kunnen horizontal schalen om bij te benen en als een consumer tijdelijk uitvalt, kan die vanaf waar hij gebleven was hervatten.
Zie Kafka als de “activity feed” van het systeem. Producers publiceren feiten; consumers abonneren zich op de feiten die ze belangrijk vinden. Dat patroon maakt realtime datapijplijnen en event-driven workflows mogelijk terwijl services eenvoudiger en onafhankelijker blijven.
Kafka komt vaak voor waar teams veel kleine “feiten die gebeurden” tussen systemen moeten verplaatsen—snel, betrouwbaar en zodanig dat meerdere consumers dezelfde data kunnen hergebruiken.
Applicaties hebben vaak een append-only geschiedenis nodig: user sign-ins, permissiewijzigingen, record updates of admin-acties. Kafka werkt goed als centrale stream voor deze events, zodat security-tools, rapportages en compliance-exports allemaal dezelfde bron kunnen lezen zonder extra load op de productie-database. Omdat events voor een bepaalde periode bewaard worden, kun je ze ook opnieuw afspelen om een auditview te herbouwen na een bug of schemawijziging.
In plaats van dat services elkaar direct aanroepen, kunnen ze events publiceren zoals “order created” of “payment received”. Andere services abonneren zich en reageren in hun eigen tempo. Dit vermindert strakke koppeling, helpt systemen operationeel te blijven bij gedeeltelijke uitval en maakt het makkelijker om nieuwe capabilities toe te voegen (bijvoorbeeld fraud checks) door simpelweg van de bestaande event stream te consumeren.
Kafka is een veelgebruikte backbone om data van operationele systemen naar analytics-platforms te verplaatsen. Teams kunnen wijzigingen van applicatiedatabases streamen en die met lage vertraging in een warehouse of data lake afleveren, terwijl de productie-app gescheiden blijft van zware analytische queries.
Sensors, devices en app-telemetry komen vaak in pieken binnen. Kafka kan pieken absorberen, ze veilig bufferen en downstream verwerking laten bijbenen—handig voor monitoring, alerting en lange termijn analyse.
Kafka is meer dan brokers en topics. De meeste teams vertrouwen op aanvullende tools die Kafka praktisch maken voor dagelijkse databeweging, stream processing en operatie.
Kafka Connect is het integratiekader van Kafka om data in Kafka (sources) en uit Kafka (sinks) te krijgen. In plaats van één-op-één pipelines te bouwen en te onderhouden, draai je Connect en configureer je connectors.
Veelvoorkomende voorbeelden: veranderingen uit databases halen, SaaS-events ingesturen of Kafka-data afleveren naar een datawarehouse of object storage. Connect standaardiseert ook operationele zaken zoals retries, offsets en parallelisme.
Als Connect voor integratie is, is Kafka Streams voor berekening. Het is een bibliotheek die je aan je applicatie toevoegt om streams realtime te transformeren—events filteren, verrijken, streams joinen en aggregaten bouwen (zoals “orders per minuut”).
Omdat Streams-apps van topics lezen en terugschrijven naar topics, passen ze natuurlijk in event-driven systemen en kunnen ze schalen door meer instanties toe te voegen.
Naarmate meerdere teams events publiceren, wordt consistentie belangrijk. Schema-management (vaak via een schema registry) definieert welke velden een event moet hebben en hoe ze evolueren. Dat helpt breuken te voorkomen, zoals een producer die een veld hernoemt waar een consumer van afhankelijk is.
Kafka is operationeel gevoelig, dus basismonitoring is essentieel:
De meeste teams gebruiken ook management UIs en automatisering voor deployments, topic-configuratie en toegangsbeleid (zie /blog/kafka-security-governance).
Kafka wordt vaak beschreven als “duurzame log + consumers”, maar wat de meeste teams echt bezighoudt is: verwerk ik elk event precies één keer, en wat gebeurt er als iets faalt? Kafka geeft bouwstenen en jij kiest de afwegingen.
At-most-once betekent dat je events kunt verliezen, maar je zult geen duplicaten verwerken. Dit kan gebeuren als een consumer zijn positie commit vóórdat hij het werk af heeft en dan crasht.
At-least-once betekent dat je geen events verliest, maar duplicaten mogelijk zijn (bijvoorbeeld: de consumer verwerkt een event, crasht en verwerkt het na herstart opnieuw). Dit is de meest voorkomende default.
Exactly-once probeert zowel verlies als duplicaten te vermijden end-to-end. In Kafka omvat dit meestal transactionele producers en compatibele verwerking (vaak via Kafka Streams). Het is krachtig, maar beperkter en vereist zorgvuldige setup.
In de praktijk omarmen veel systemen at-least-once en voegen ze beschermingen toe:
Een consumer offset is de positie van het laatst verwerkte record in een partition. Als je offsets commit, zeg je: “Ik ben klaar tot hier.” Te vroeg committen vergroot het risico op verlies; te laat committen vergroot duplicaten na failures.
Retries moeten begrensd en zichtbaar zijn. Een gangbare aanpak is:
Dit voorkomt dat één “poison message” een hele consumer group blokkeert en houdt de data bewaard voor latere fixes.
Kafka vervoert vaak bedrijfskritische events (orders, betalingen, gebruikersactiviteit). Daarom horen beveiliging en governance bij het ontwerp, niet als nagedachte.
Authenticatie beantwoordt “wie ben je?” Autorisatie beantwoordt “wat mag je doen?” In Kafka gebeurt authenticatie vaak met SASL (bijv. SCRAM of Kerberos), terwijl autorisatie wordt afgedwongen met ACLs op topic-, consumer group- en cluster-niveau.
Een praktisch patroon is least privilege: producers mogen alleen naar hun topics schrijven en consumers mogen alleen de topics lezen die ze nodig hebben. Dit verkleint het risico op onbedoelde datalekken en beperkt de blast radius als credentials uitlekken.
TLS versleutelt data terwijl het beweegt tussen apps, brokers en tooling. Zonder TLS kunnen events op interne netwerken onderschept worden, niet alleen op het publieke internet. TLS helpt ook bij het voorkomen van man-in-the-middle-aanvallen door broker-identiteiten te valideren.
Als meerdere teams een cluster delen, zijn guardrails belangrijk. Duidelijke topic-naamgeving (bijv. <team>.<domain>.<event>.<version>) maakt eigenaarschap zichtbaar en helpt tooling policies consistent toe te passen.
Koppel naamgeving aan quota’s en ACL-templates zodat één lawaaierige workload anderen niet wegdrukt en nieuwe services met veilige defaults starten.
Behandel Kafka als een source of record voor eventgeschiedenis alleen als je dat echt bedoelt. Bevatten events PII, gebruik dan dataminimalisatie (stuur IDs in plaats van volledige profielen), overweeg field-level encryptie en documenteer welke topics gevoelig zijn.
Retention-instellingen moeten voldoen aan wettelijke en zakelijke vereisten. Als beleid zegt “verwijder na 30 dagen”, bewaar dan niet zomaar 6 maanden “voor het geval dat”. Regelmatige reviews en audits houden configuraties in lijn terwijl systemen evolueren.
Een Apache Kafka-cluster runnen is niet gewoon "installeren en vergeten". Het gedraagt zich meer als een gedeelde nutsvoorziening: veel teams vertrouwen erop en kleine fouten kunnen downstream doorwerken.
Kafka-capaciteit is vooral een rekensom die je regelmatig herbekijkt. De grootste hefbomen zijn partitions (parallelisme), throughput (MB/s in en uit) en opslaggroei (hoe lang je data bewaart).
Als verkeer verdubbelt, heb je mogelijk meer partitions nodig om load over brokers te spreiden, meer schijfruimte voor retention en meer netwerkheadroom voor replicatie. Een praktische gewoonte is de piek-schrijfsnelheid te voorspellen en die te vermenigvuldigen met retention om schijfgroei te schatten, en buffer toe te voegen voor replicatie en “onverwacht succes”.
Verwacht routinewerk naast het draaiend houden van servers:
Kosten worden gedreven door schijven, netwerk egress en het aantal/grootte van brokers. Managed Kafka kan de personele last verlagen en upgrades eenvoudiger maken, terwijl self-hosting goedkoper kan zijn op schaal als je ervaren operators hebt. Het compromis is time-to-recovery en on-call last.
Teams monitoren typisch:
Goede dashboards en alerts veranderen Kafka van een “mystery box” in een begrijpelijke dienst.
Kafka is een goede keuze als je veel events betrouwbaar wilt verplaatsen, ze een tijd wilt bewaren en meerdere systemen dezelfde data in hun eigen tempo moeten kunnen verwerken. Het is vooral nuttig als data opnieuw afgespeeld moet kunnen worden (voor backfills, audits of het herbouwen van een nieuwe service) en wanneer je verwacht dat er in de loop van de tijd meer producers/consumers bijkomen.
Kafka blinkt uit als je hebt:
Kafka kan overkill zijn als je behoeften eenvoudig zijn:
In die gevallen kan de operationele overhead (cluster sizing, upgrades, monitoring, on-call) zwaarder wegen dan de voordelen.
Kafka vult ook aan—vervangt niet—databases (system of record), caches (snelle reads) en batch ETL-tools (grote periodieke transformaties).
Vraag jezelf:
Als je op de meeste vragen “ja” antwoordt, is Kafka meestal een verstandige keuze.
Kafka past het beste wanneer je een gedeelde “source of truth” voor realtime event streams nodig hebt: veel systemen die feiten produceren (orders aangemaakt, betalingen geautoriseerd, voorraad veranderd) en veel systemen die die feiten consumeren om pipelines, analytics en reactieve features aan te sturen.
Begin met een smalle, waardevolle flow—zoals het publiceren van “OrderPlaced” events voor downstream services (email, fraud checks, fulfillment). Vermijd dat Kafka op dag één een allesomvattende queue wordt.
Schrijf op:
Houd vroege schema’s eenvoudig en consistent (timestamps, IDs en een duidelijke eventnaam). Bepaal of je schemas van tevoren afdwingt of voorzichtig laat evolueren.
Kafka slaagt wanneer iemand eigendom heeft over:
Voeg meteen monitoring toe (consumer lag, broker health, throughput, error rates). Als je nog geen platformteam hebt, begin dan met een managed aanbod en duidelijke limieten.
Produceer events vanuit één systeem, consumeer ze op één plek en bewijs de lus end-to-end. Breid daarna pas uit naar meer consumers, partitions en integraties.
Als je snel van “idee” naar een werkende event-driven service wilt, kunnen tools zoals Koder.ai je helpen de omliggende applicatie te prototypen (React web UI, Go-backend, PostgreSQL) en iteratief Kafka producers/consumers toe te voegen via een chatgestuurde workflow. Het is vooral nuttig voor het bouwen van interne dashboards en lichte services die topics consumeren, met functies zoals planning mode, source code export, deployment/hosting en snapshots met rollback.
Als je dit in een event-driven aanpak wilt plaatsen, zie /blog/event-driven-architecture. Voor planning van kosten en omgevingen, check /pricing.
Kafka is een gedistribueerd platform voor event streaming dat events opslaat in duurzame, append-only logs.
Producers schrijven events naar topics, en consumers lezen ze onafhankelijk (vaak in realtime, maar ook later), omdat Kafka data behoudt voor een configureerbare periode.
Gebruik Kafka wanneer meerdere systemen dezelfde stream van events nodig hebben, je losse koppeling wilt en je mogelijk geschiedenis wilt kunnen replayen.
Het is vooral nuttig voor:
Een topic is een benoemde categorie van events (zoals orders of payments).
Een partition is een deel van een topic dat zorgt voor:
Kafka garandeert ordering alleen binnen één enkele partition.
Kafka gebruikt de record key (bijvoorbeeld order_id) om gerelateerde events consistent naar dezelfde partition te routeren.
Praktische regel: als je ordering per entiteit nodig hebt (alle events voor een order/klant in volgorde), kies dan een key die die entiteit vertegenwoordigt zodat die events in één partition landen.
Een consumer group is een set consumer-instanties die het werk voor een topic delen.
Binnen een groep:
Als twee verschillende apps elk elk event moeten krijgen, moeten ze verschillende consumer groups gebruiken.
Kafka bewaart events op schijf volgens topic-beleid, zodat consumers kunnen bijlezen na downtime of geschiedenis kunnen herprocessen.
Veelvoorkomende retention-typen:
Retention is per topic configureerbaar, zodat hoogwaardige audit-streams langer bewaard kunnen worden dan high-volume telemetry.
Log compaction behoudt in elk geval de meest recente record per key en verwijdert na verloop van tijd oudere overschreven records.
Het is nuttig voor “huidige status” streams (zoals instellingen of profielen) waar je de laatste waarde per key belangrijk vindt, niet elke historische wijziging—en je toch een duurzame bron voor de actuele staat wilt houden.
Het meest gebruikelijke end-to-end patroon is at-least-once: je verliest doorgaans geen events, maar duplicaten zijn mogelijk.
Om dit veilig te behandelen:
Offsets zijn de “bladwijzer” van een consumer per partition.
Als je offsets te vroeg commit, kun je werk verliezen bij crashes; te laat committen zorgt voor herverwerking en duplicaten.
Een gangbaar operationeel patroon is begrensde retries met backoff en het publiceren van mislukte records naar een dead-letter topic zodat één slechte record niet de hele consumer group blokkeert.
Kafka Connect verplaatst data in/uit Kafka via connectors (sources en sinks) in plaats van custom pipeline-code.
Kafka Streams is een bibliotheek om streams realtime te transformeren en aggregeren binnen je applicaties (filteren, joinen, verrijken, aggregaten bouwen), die leest van topics en terugschrijft naar topics.
Connect gebruik je meestal voor integratie; Streams voor verwerking.