21 jul 2025·8 min
Een webapp bouwen voor incidentimpactanalyse, stap voor stap
Leer hoe je een webapp ontwerpt en bouwt die incidentimpact berekent met serviceafhankelijkheden, near-real-time signalen en duidelijke dashboards voor teams.
Leer hoe je een webapp ontwerpt en bouwt die incidentimpact berekent met serviceafhankelijkheden, near-real-time signalen en duidelijke dashboards voor teams.
Voordat je berekeningen of dashboards bouwt, bepaal wat “impact” in jouw organisatie werkelijk betekent. Als je deze stap overslaat, krijg je een score die wetenschappelijk lijkt maar niemand helpt te handelen.
Impact is het meetbare gevolg van een incident voor iets waar het bedrijf om geeft. Veelvoorkomende dimensies zijn:
Kies 2–4 primaire dimensies en definieer ze expliciet. Bijvoorbeeld: “Impact = getroffen betalende klanten + SLA-minuten in risico”, niet “Impact = alles wat er slecht uitziet in grafieken.”
Verschillende rollen nemen verschillende beslissingen:
Ontwerp “impact”-uitvoer zodat elk publiek zijn belangrijkste vraag kan beantwoorden zonder metrics te hoeven vertalen.
Bepaal welke latentie acceptabel is. “Realtime” is duur en vaak niet nodig; near-real-time (bijv. 1–5 minuten) is meestal voldoende voor besluitvorming.
Leg dit vast als productvereiste omdat het invloed heeft op ingestie, caching en UI.
Je MVP moet direct acties ondersteunen zoals:
Als een metric geen besluit verandert, is het waarschijnlijk geen “impact” — het is alleen telemetrie.
Voordat je schermen ontwerpt of een database kiest, schrijf op wat “impactanalyse” tijdens een echt incident moet beantwoorden. Het doel is niet perfecte precisie op dag één — het is consistente, uitlegbare resultaten waar responders op kunnen vertrouwen.
Begin met de data die je moet ingesten of raadplegen om impact te berekenen:
De meeste teams hebben op dag één geen perfecte dependency- of klantmapping. Bepaal wat je mensen handmatig kunt laten invoeren zodat de app nog steeds nuttig is:
Ontwerp deze als expliciete velden (geen ad-hoc notities) zodat ze later doorzoekbaar zijn.
Je eerste release moet betrouwbaar genereren:
Impactanalyse is een beslissingsinstrument, dus randvoorwaarden zijn belangrijk:
Schrijf deze vereisten als testbare uitspraken. Als je het niet kunt verifiëren, kun je er tijdens een storing niet op vertrouwen.
Je datamodel is het contract tussen ingestie, berekening en de UI. Als je het goed doet, kun je toolingbronnen verwisselen, scoring verfijnen en toch dezelfde vragen beantwoorden: “Wat is kapot?”, “Wie is getroffen?” en “Hoe lang?”
Model minimaal deze als primair records:
Houd ID's stabiel en consistent tussen bronnen. Als je al een servicecatalogus hebt, behandel die als bron van waarheid en map externe tool-identifiers daarheen.
Sla meerdere tijdstempels op bij het incident om rapportage en analyse te ondersteunen:
Sla ook berekende tijdvensters op voor impactscoring (bijv. 5-minuten buckets). Dit maakt replay en vergelijkingen eenvoudig.
Model twee belangrijke grafen:
Een eenvoudig patroon is customer_service_usage(customer_id, service_id, weight, last_seen_at) zodat je impact kunt rangschikken op basis van “hoezeer de klant erop vertrouwt.”
Dependencies evolueren, en impactberekeningen moeten weergeven wat waar was op dat moment. Voeg effective dating toe aan randen:
dependency(valid_from, valid_to)Doe hetzelfde voor klantabonnementen en gebruikssnapshots. Met historische versies kun je incidenten uit het verleden nauwkeurig opnieuw uitvoeren tijdens post-incident reviews en consistente SLA-rapportage produceren.
Je impactanalyse is slechts zo goed als de inputs die het voedt. Het doel is simpel: neem signalen uit de tools die je al gebruikt en zet ze om naar een consistent eventstream waar je app op kan redeneren.
Begin met een korte lijst bronnen die betrouwbaar beschrijven dat “er iets is veranderd” tijdens een incident:
Probeer niet alles tegelijk te ingesten. Kies bronnen die detectie, escalatie en bevestiging dekken.
Verschillende tools ondersteunen verschillende integratiepatronen:
Een praktische aanpak: webhooks voor kritieke signalen, plus batch-imports om hiaten te vullen.
Normaliseer elk binnenkomend item naar één “event”-vorm, zelfs als de bron het alert, incident of annotatie noemt. Standaardiseer minimaal:
Verwacht rommelige data. Gebruik idempotency-keys (source + external_id) om te dedupliceren, tolereer out-of-order events door te sorteren op occurred_at (niet aankomsttijd), en pas veilige defaults toe wanneer velden ontbreken (en markeer ze voor review).
Een kleine “unmatched service” wachtrij in de UI voorkomt stille fouten en houdt je impactresultaten betrouwbaar.
Als je dependency-map niet klopt, is je blast radius fout—zelfs als je signalen en scoring perfect zijn. Het doel is een afhankelijkheidsgraf te bouwen die je zowel tijdens een incident als erna kunt vertrouwen.
Definieer eerst de nodes voordat je randen mappt. Maak een servicecatalogusvermelding voor elk systeem dat je in een incident zou kunnen noemen: API's, achtergrondworkers, datastores, externe leveranciers en andere gedeelde kritieke componenten.
Elke service zou minimaal moeten bevatten: eigenaar/team, tier/criticality (bijv. klantgericht vs intern), SLA/SLO-doelen, en links naar runbooks en on-call docs (bijvoorbeeld /runbooks/payments-timeouts).
Gebruik twee complementaire bronnen:
Behandel deze als aparte edge-types zodat mensen vertrouwen kunnen inschatten: “gedeklaard door team” versus “geobserveerd in de laatste 7 dagen.”
Afhankelijkheden moeten directioneel zijn: Checkout → Payments is niet hetzelfde als Payments → Checkout. Richting stuurt redenering (“als Payments gedegradeerd is, welke upstreams kunnen falen?”).
Model ook hard vs soft afhankelijkheden:
Dit voorkomt overschatting van impact en helpt responders prioriteren.
Je architectuur verandert wekelijks. Als je geen snapshots bewaart, kun je een incident van twee maanden geleden niet nauwkeurig analyseren.
Bewaar versies van de afhankelijkheidsgraf over tijd (dagelijks, per deploy of bij wijziging). Wanneer je blast radius berekent, los het incidenttijdstip op naar de dichtstbijzijnde graf-snapshot, zodat “wie was getroffen” de realiteit op dat moment weerspiegelt — niet de huidige architectuur.
Zodra je signalen ingestalt hebt (alerts, SLO-burn, synthetic checks, klanttickets), moet de app een consistente manier hebben om rommelige inputs om te zetten in een duidelijke uitspraak: wat is kapot, hoe erg is het en wie is getroffen?
Je kunt met elk van de volgende patronen tot een bruikbare MVP komen:
Welk pad je ook kiest, bewaar de tussenwaarden (threshold hit, weights, tier) zodat mensen kunnen begrijpen waarom de score ontstond.
Vermijd het te vroeg samenvoegen van alles tot één getal. Houd een paar dimensies gescheiden en leid daaruit een totale ernst af:
Dit helpt responders precies te communiceren (bijv. “beschikbaar maar traag” vs. “onjuiste resultaten”).
Impact is niet alleen servicegezondheid — het is wie het voelt.
Gebruik usage mapping (tenant → service, klantplan → features, gebruikersverkeer → endpoint) en bereken getroffen klanten binnen een tijdvenster dat overeenkomt met het incident (starttijd, mitigatietijd en eventuele backfillperiode).
Wees expliciet over aannames: gesamplede logs, geschatte traffic of gedeeltelijke telemetrie.
Operators zullen overrides nodig hebben: een false-positive alert, een gedeeltelijke rollout, een bekende subset tenants.
Sta handmatige bewerkingen toe voor severity, dimensies en getroffen klanten, maar eis:
Deze audittrail beschermt vertrouwen in het dashboard en maakt post-incident review sneller.
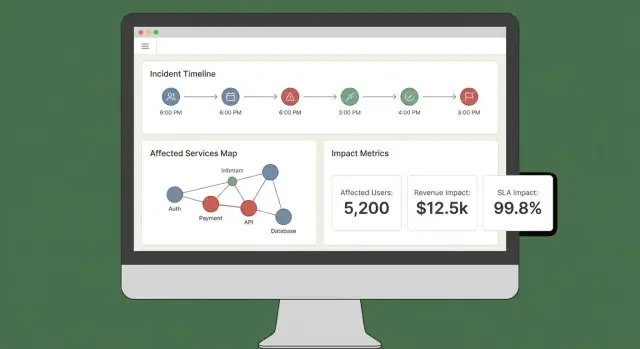
Een goed impactdashboard beantwoordt drie vragen snel: Wat is getroffen? Wie is getroffen? Hoe zeker zijn we? Als gebruikers vijf tabbladen moeten openen om dat te combineren, zullen ze de output niet vertrouwen of erop handelen.
Begin met een klein aantal “altijd-aan” views die passen bij echte incidentworkflows:
Impactscores zonder uitleg voelen arbitrair. Elke score moet traceerbaar zijn tot inputs en regels:
Een eenvoudige “Explain impact”-drawer of paneel kan dit doen zonder het hoofdscherm te vervuilen.
Maak het makkelijk om impact te snijden op service, regio, klanttier en tijdsbereik. Laat gebruikers op elk datapunt of rij klikken om naar ruwe bewijzen te drillen (de exacte monitors, logs of events die de wijziging veroorzaakten).
Tijdens een actief incident hebben mensen draagbare updates nodig. Voeg toe:
Als je al een statuspagina hebt, verwijs ernaar via een relatieve route zoals /status zodat communicatieteams snel kunnen cross-referencen.
Impactanalyse is alleen nuttig als mensen het vertrouwen — dat betekent controleren wie wat kan zien en een duidelijke registratie van wijzigingen.
Definieer een kleine set rollen die overeenkomen met hoe incidenten in de praktijk verlopen:
Houd permissies gericht op acties, niet op functiebenamingen. Bijvoorbeeld: “kan klantimpactrapport exporteren” is een permissie die je aan commanders en een kleine groep admins kunt geven.
Impactanalyse raakt vaak klantidentificaties, contracttiers en soms contactgegevens. Pas least privilege toe als standaard:
Log sleutelacties met genoeg context voor reviews:
Bewaar auditlogs append-only, met tijdstempels en actoridentiteit. Maak ze per incident doorzoekbaar zodat ze bruikbaar zijn tijdens post-incident reviews.
Documenteer wat je nu ondersteunt — retentieperiode, toegangscontroles, encryptie en auditdekking — en wat op de roadmap staat.
Een korte “Security & Audit”-pagina in je app (bijv. /security) helpt verwachtingen stellen en vermindert ad-hoc vragen tijdens kritieke incidenten.
Impactanalyse doet er alleen toe tijdens een incident als het de volgende actie aanstuurt. Je app moet fungeren als een “co-piloot” voor het incidentkanaal: het zet binnenkomende signalen om in heldere updates en geeft aan wanneer impact wezenlijk verandert.
Begin met integreren in de plek waar responders al werken (vaak Slack, Microsoft Teams of een incidenttool). Het doel is niet het kanaal vervangen — het is contextbewuste updates posten en een gedeeld logboek bijhouden.
Een praktisch patroon is het incidentkanaal zowel als input- als outputbron te behandelen:
Als je snel prototypeert, overweeg dan eerst de volledige workflow end-to-end te bouwen (incident view → summarize → notify) voordat je de scoring perfectioneert. Platforms zoals Koder.ai kunnen hier nuttig zijn: je kunt snel itereren op een React-dashboard en een Go/PostgreSQL-backend via een chatgestuurde workflow, en vervolgens de broncode exporteren zodra het incidentteam akkoord is dat de UX overeenkomt met de realiteit.
Voorkom spam door notificaties alleen te triggeren wanneer impact expliciete drempels overschrijdt. Veelvoorkomende triggers zijn:
Wanneer een drempel wordt overschreden, stuur een bericht dat uitlegt wat veranderde, wie moet handelen en wat de volgende stap is.
Elke notificatie zou “next-step” verwijzingen moeten bevatten zodat responders snel kunnen handelen:
Houd deze verwijzingen stabiel en relatief zodat ze in verschillende omgevingen werken.
Maak twee samenvattingsformaten uit dezelfde data:
Ondersteun geplande samenvattingen (bijv. elke 15–30 minuten) en on-demand “genereer update”-acties, met een goedkeuringsstap voordat er extern wordt gecommuniceerd.
Impactanalyse is alleen nuttig als mensen het vertrouwen tijdens en na een incident. Validatie moet twee dingen aantonen: (1) het systeem levert stabiele, uitlegbare resultaten, en (2) die resultaten komen overeen met wat je organisatie later overeenkomt dat er gebeurd is.
Begin met geautomatiseerde tests die de twee meest foutgevoelige gebieden bestrijken: scoringlogica en data-ingestie.
Houd testfixtures leesbaar: wanneer iemand een regel wijzigt, moeten ze kunnen begrijpen waarom een score veranderde.
Een replay-modus is een snelle weg naar vertrouwen. Draai historische incidenten door de app en vergelijk wat het systeem “op dat moment” had laten zien met wat responders later concludeerden.
Praktische tips:
Echte incidenten lijken zelden op nette outages. Je validatiesuite moet scenario's omvatten zoals:
Voor elk scenario controleer je niet alleen de score, maar ook de uitleg: welke signalen en welke dependencies/klanten de uitkomst veroorzaakten.
Definieer nauwkeurigheid in operationele termen en volg deze.
Vergelijk berekende impact met post-incident review-uitkomsten: getroffen services, duur, klantenaantal, SLA-breach en severity. Log afwijkingen als validatie-issues met een categorie (ontbrekende data, verkeerde dependency, foute drempel, vertraagd signaal).
In de loop der tijd is het doel niet perfectie — het is minder verrassingen en snellere overeenstemming tijdens incidenten.
Het uitrollen van een MVP voor incidentimpactanalyse draait vooral om betrouwbaarheid en feedbackloops. Je eerste deploykeuze moet optimaliseren voor snelheid van verandering, niet voor theoretische toekomstige schaal.
Begin met een modulaire monoliet tenzij je al een sterk platformteam en duidelijke servicegrenzen hebt. Eén deploybaar geheel vereenvoudigt migraties, debugging en end-to-end testing.
Splits alleen als je echte pijnpunten voelt:
Een pragmatisch midden is één app + achtergrondworkers (queues) + een aparte ingestie-edge indien nodig.
Als je snel vooruit wilt zonder direct een groot op maat gebouwd platform te kiezen, kan Koder.ai helpen het MVP te versnellen: de chatgestuurde “vibe-coding” workflow leent zich goed voor het bouwen van een React-UI, een Go-API en een PostgreSQL-datamodel, met snapshots/rollback tijdens iteratie op scoringsregels en workflowwijzigingen.
Gebruik relationele opslag (Postgres/MySQL) voor kernentiteiten: incidenten, services, klanten, eigenaarschap en berekende impact-snapshots. Het is makkelijk te query'en, auditen en evolueren.
Voor hoogvolume signalen (metrics, log-afgeleide events) voeg een time-series store of kolomgeoriënteerde store toe wanneer raw signal-retentie en rollups kostbaar worden in SQL.
Overweeg een graph-database alleen als dependency-queries een bottleneck worden of je afhankelijkheidsmodel zeer dynamisch wordt. Veel teams komen ver met adjacency-tables plus caching.
Je impactanalyse-app wordt onderdeel van je incidenttoolchain, dus instrumeer het als productie:
Toon een “health + freshness” view in de UI zodat responders de cijfers kunnen vertrouwen (of bevragen).
Definieer MVP-scope scherp: een kleine set tools om te ingesteren, een duidelijke impactscore en een dashboard dat antwoord geeft op “wie is getroffen en hoeveel”. Itereer daarna:
Behandel het model als een product: versieer het, migreer veilig en documenteer wijzigingen voor post-incident reviews.
Impact is de meetbare consequentie van een incident op bedrijfskritieke uitkomsten.
Een praktische definitie noemt 2–4 primaire dimensies (bijv. getroffen betalende klanten + SLA-minuten in risico) en sluit expliciet “alles wat er slecht uitziet in grafieken” uit. Dat houdt de uitkomst gekoppeld aan beslissingen, niet alleen aan telemetrie.
Kies dimensies die corresponderen met acties die teams in de eerste 10 minuten nemen.
Veelvoorkomende, MVP-vriendelijke dimensies:
Beperk het tot 2–4 zodat de score uitlegbaar blijft.
Ontwerp outputs zodat elke rol zijn belangrijkste vraag kan beantwoorden zonder metrics te hoeven vertalen:
Als een metric door geen van deze doelgroepen gebruikt wordt, is het waarschijnlijk geen “impact.”
“Realtime” is kostbaar; veel teams redden het met near-real-time (1–5 minuten).
Leg een latentie-doel vast als requirement omdat het invloed heeft op:
Zet ook de verwachting in de UI (bijv. “data ververst 2 minuten geleden”).
Begin met het opsommen van de beslissingen die responders moeten nemen en zorg dat elke output één van die beslissingen ondersteunt:
Als een metric een beslissing niet verandert, laat het dan telemetry blijven, geen impact.
Minimale vereiste inputs omvatten meestal:
Sta expliciete, doorzoekbare handmatige velden toe zodat de app bruikbaar blijft als data ontbreekt:
Eis wie/wanneer/waarom voor wijzigingen zodat vertrouwen niet degraderen.
Een betrouwbaar MVP zou moeten opleveren:
Normaliseer elke bron naar één event-schema zodat berekeningen consistent blijven.
Normaliseer in ieder geval:
occurred_at, , Begin simpel en maak het uitlegbaar:
Bewaar tussenwaarden (drempel geraakt, gewichten, tier, confidence) zodat gebruikers kunnen zien de score veranderde. Houd dimensies (availability/latency/errors/data correctness/security) apart voordat je tot één getal komt.
Met deze set kun je meestal berekenen “wat kapot is”, “wie getroffen is” en “hoe lang”.
Optioneel: kostenramingen (SLA-kredieten, supportbelasting, omzetrisico) met betrouwbaarheidsintervallen.
detected_atresolved_atservice_id (gemapt van tool-tags/namen)source + originele raw payload (voor audit/debug)Omga met rommel: gebruik idempotency-keys (source + external_id) en tolerantie voor out-of-order events op basis van occurred_at.