16 mrt 2025·8 min
Maak een webapp voor klantescalaties & prioriteitsondersteuning
Leer hoe je een webapp plant, ontwerpt en bouwt die escalaties routet, SLA’s afdwingt en prioriteitsupport organiseert met heldere workflows en rapportage.
Verduidelijk de escalatieworkflow en doelen
Voordat je schermen bouwt of code schrijft: besluit waarvoor je app bedoeld is en welk gedrag hij moet afdwingen. Escalaties zijn niet alleen “boze klanten” — het zijn tickets die snellere afhandeling, meer zichtbaarheid en strakkere coördinatie vereisen.
Wat telt als een escalatie?
Definieer escalatiecriteria in klare taal zodat agenten en klanten niet hoeven te raden. Veelvoorkomende triggers zijn:
- Een uitval of ernstige degradatie
- Een VIP of klant met een “priority support”-contract
- Een dreigende SLA-overtreding (of herhaalde overtredingen)
- Een security-, facturatie- of juridische impact
Definieer ook wat geen escalatie is (bijv. how-to vragen, featureverzoeken, kleine bugs) en hoe die verzoeken in plaats daarvan moeten worden gerouteerd.
Rollen en verantwoordelijkheden
Maak een lijst met de rollen die je workflow nodig heeft en wat elke rol kan doen:
- Agent: triaget en lost op, werkt het ticket bij, volgt playbooks
- Lead: reviewt escalaties, wijst werk opnieuw toe, keurt prioriteitswijzigingen goed
- Manager: is verantwoordelijk voor rapportage, standaarden voor klantcommunicatie en escalatiebeleid
- On-call: ontvangt urgente alerts en neemt direct ownership buiten kantooruren
- Customer admin: dient tickets in en volgt ze, voegt interne stakeholders toe
Schrijf op wie het ticket bezit bij elke stap (inclusief overdrachten) en wat “bezit” betekent (antwoordeis, volgende update-tijd en bevoegdheid om te escaleren).
Kanalen om eerst te ondersteunen
Begin met een kleine set inputs zodat je sneller kunt uitrollen en triage consistent blijft. Veel teams starten met e-mail + webformulier, en voegen daarna chat toe zodra SLA’s en routing stabiel zijn.
Doelen en succesmetricen
Kies meetbare uitkomsten die de app zou moeten verbeteren:
- First response time (totaal en voor escalaties)
- Resolutietijd of time-to-mitigation bij incidenten
- Heropeningspercentage en het aantal “gevraagd om update”-meldingen
- Gemiste SLA-percentages en tijd dat tickets zonder eigenaar zijn
Deze beslissingen worden je productvereisten voor de rest van de build.
Ontwerp het datamodel voor tickets, SLA’s en escalaties
Een prioriteitsupport-app staat of valt met het datamodel. Als de basis goed is, worden routing, rapportage en SLA-handhaving eenvoudiger — omdat het systeem de feiten heeft die het nodig heeft.
Begin met ticket-“basis” (wat agenten altijd moeten weten)
Minimaal moet elk ticket vastleggen: requester (een contact), company (klantaccount), subject, description en attachments. Behandel de beschrijving als de oorspronkelijke probleemstelling; latere updates horen in comments zodat je de evolutie kunt zien.
Voeg escalatie-specifieke velden toe (wat dit “prioriteit” maakt)
Escalaties vragen om meer structuur dan algemene support. Veelvoorkomende velden zijn severity (hoe ernstig), impact (hoeveel gebruikers/welke omzet) en priority (hoe snel je reageert). Voeg een affected service-veld toe (bijv. Billing, API, Mobile App) zodat triage snel kan routeren.
Voor deadlines: sla expliciete uiterlijke tijden op (zoals “first response due” en “resolution/next update due”), niet alleen een “SLA-naam”. Het systeem kan deze timestamps berekenen, maar agenten moeten de exacte tijden zien.
Modelleer relaties voor echt werk
Een praktisch model bevat meestal:
- Customers → veel Contacts
- Customers → veel Tickets
- Tickets → veel Comments (intern + publiek)
- Tickets → veel Tasks (checklist-items, follow-ups)
Dit houdt samenwerking schoon: gesprekken in comments, actiepunten in tasks en eigenaarschap op het ticket.
Definieer statusstaten (en houd ze consistent)
Gebruik een kleine, stabiele set statussen zoals: New, Triaged, In Progress, Waiting, Resolved, Closed. Vermijd “bijna hetzelfde”-statussen — elke extra status maakt rapportage en automatisering minder betrouwbaar.
Beslis wat onveranderbaar moet zijn voor audits
Voor SLA-tracking en verantwoordelijkheid moet sommige data append-only zijn: created/updated timestamps, status-change history, SLA start/stop events, escalatiewijzigingen en wie elke wijziging heeft doorgevoerd. Geef de voorkeur aan een auditlog (of eventtabel) zodat je kunt reconstrueren wat er gebeurde zonder giswerk.
Stel prioriteitsniveaus en SLA-regels in
Prioriteit- en SLA-regels zijn het “contract” dat je app afdwingt: wat eerst gaat, hoe snel en wie verantwoordelijk is. Houd het schema simpel, documenteer het duidelijk en maak het moeilijk om te overrulen zonder reden.
Een simpel prioriteitsschema (P1–P4)
Gebruik vier niveaus zodat agenten snel kunnen classificeren en managers consistent kunnen rapporteren:
- P1 — Kritieke uitval / zware impact: Het product is down, dataverlies treedt op of een security-incident wordt vermoed. Meerdere gebruikers of een heel klantaccount is geblokkeerd.
- P2 — Grote degradatie: Kernfunctionaliteit werkt deels niet, workarounds zijn beperkt en zakelijke impact is hoog maar niet totaal.
- P3 — Standaardprobleem: Eén gebruiker of niet-kernfunctionaliteit is aangetast. Er is een workaround. Veel tickets zullen hier landen.
- P4 — Lage urgentie / verzoeken: How-to vragen, kleine bugs, featureverzoeken, facturatievragen die gebruik niet blokkeren.
Definieer “impact” (hoeveel gebruikers/klanten) en “urgency” (hoe tijdkritisch) in je UI om verkeerd labelen te verminderen.
Definieer SLA’s per plan, klanttier en prioriteit
Je datamodel moet SLA’s kunnen variëren per customer plan/tier (bv. Free/Pro/Enterprise) en priority. Meestal track je ten minste twee timers:
- First response SLA (tijd om te erkennen en ownership te nemen)
- Resolution SLA of next-update SLA (tijd om op te lossen of een zinvolle update te geven)
Voorbeeld: Enterprise + P1 kan vereisen dat de eerste reactie binnen 15 minuten plaatsvindt, terwijl Pro + P3 8 zakelijke uren kan zijn. Houd de regelentabel zichtbaar voor agenten en link ernaartoe vanaf de ticketpagina.
Kantooruren, 24/7 en vakantiekalenders
Support-SLA’s hangen vaak af van of het plan 24/7 dekt.
- Voor business-hours SLA’s, bewaar een werkschema (tijdzone, weekdagen, begin/eindtijden).
- Voor 24/7 SLA’s, loopt de klok altijd.
- Voeg een vakantiekalender toe (per regio indien nodig) zodat timers niet “breachen” op dagen waarop niemand verwacht wordt te werken.
Laat het ticket zowel “SLA remaining” als het gebruikte schema zien (zodat agenten de timer vertrouwen).
SLA-pauzes, “waiting on customer” en breach-afhandeling
Echte workflows hebben pauzes nodig. Een veelgebruikte regel: pauzeer SLA wanneer het ticket Waiting on customer (of Waiting on third party) is, en hervat wanneer de klant reageert.
Wees expliciet over:
- Welke statussen welke SLA-timers pauzeren
- Of pauzes van toepassing zijn op response SLA, resolution SLA, of beide
- Wat er gebeurt bij een breach (bv. auto-escalatie van prioriteit, paging van on-call, manager notifiëren, tag “SLA Breached” toevoegen)
Vermijd stille breaches. Breach-afhandeling moet een zichtbaar event in de tickethistorie creëren.
Wie krijgt waarschuwingen voor en na een breach
Stel minimaal twee alert-drempels in:
- Pre-breach waarschuwing (bv. 50% en 80% van SLA verbruikt): notificeer de ticket-eigenaar en het teamkanaal.
- Breach alert: notificeer on-call (voor P1/P2), teamlead en optioneel Customer Success voor high-tier accounts.
Route alerts op basis van prioriteit en tier zodat mensen niet voor P4-ruis gepaged worden. Als je meer detail wilt, koppel deze sectie aan je on-call regels in meldingen en on-call-waarschuwingen.
Bouw triage-, routing- en eigenaarschapslogica
Triage en routing zijn waar een prioriteitsupport-app óf tijd bespaart — óf verwarring creëert. Het doel is simpel: elk nieuw verzoek moet snel op de juiste plek landen, met een duidelijke eigenaar en een voor de hand liggende volgende stap.
Maak een triage-inbox waarop agenten kunnen vertrouwen
Begin met een dedicated triage-inbox voor unassigned of needs-review tickets. Houd het snel en voorspelbaar:
- Standaard sortering op urgentiesignalen (priority, SLA due time, customer tier)
- Filters voor productgebied, regio/tijdzone, kanaal (e-mail/chat/web) en “VIP”-accounts
- Een “No owner / No category”-weergave die datakwaliteitsgaten benadrukt
Een goede inbox minimaliseert klikken: agenten moeten een ticket kunnen claimen, rerouten of escaleren vanuit de lijst zonder elk ticket te openen.
Definieer routingregels (en houd ze uitlegbaar)
Routing moet regel-gebaseerd zijn, maar leesbaar voor niet-engineers. Veelvoorkomende inputs:
- Product area (geselecteerd door de gebruiker, gedetecteerd vanuit het formulier of afgeleid uit tags)
- Trefwoorden in onderwerp/body (bv. “outage”, “invoice”, “SSO”)
- Customer tier (standaard vs. priority)
- Regio (route naar teams in dezelfde tijdzone)
Bewaar het “waarom” voor elke routingbeslissing (bv. “Matched keyword: SSO → Auth team”). Dat maakt discussies makkelijker en verbetert training.
Handmatige override en escalatiepaden
Zelfs de beste regels hebben een escape-hatch nodig. Sta geautoriseerde gebruikers toe om routing te overrulen en escalatiepaden te triggeren zoals:
Agent → Team lead → On-call
Overrides moeten een korte reden vereisen en een auditentry creëren. Als je later on-call alerting hebt, koppel escalatieacties eraan.
Dedupliseren en gerelateerd werk koppelen
Duplicate tickets verspillen SLA-tijd. Voeg lichte hulpmiddelen toe:
- Suggesties voor mogelijke duplicaten op basis van klant + vergelijkbaar onderwerp + tijdsvenster
- Laat agenten tickets linken naar een parent incident (“related to INC-123”)
Gekoppelde tickets moeten statusupdates en publieke communicatie van de parent erven.
Eigenaarschapsregels: één naam, één wachtrij
Definieer duidelijke eigendomsstaten:
- Single assignee (één verantwoordelijke persoon)
- Team queue (on toegewezen binnen een team; gebruik wanneer handoffs frequent zijn)
- Handoff (expliciete overdracht met notities en eventueel een nieuw SLA-checkpoint)
Maak eigenaarschap overal zichtbaar: lijstweergave, ticketheader en activiteitlog. Als iemand vraagt “Wie heeft dit?”, moet de app meteen antwoord geven.
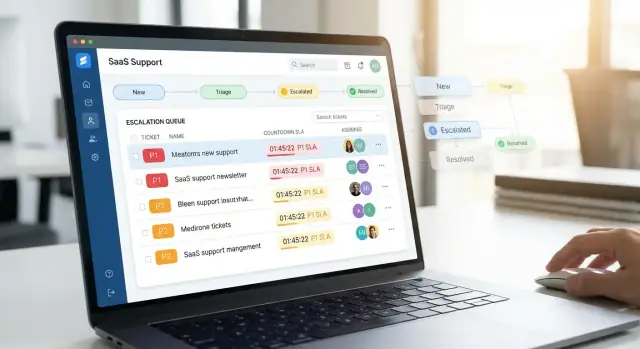
Maak een supportdashboard dat agenten snel kunnen gebruiken
Een prioriteitsupport-app slaagt of faalt in de eerste 10 seconden die een agent erin doorbrengt. Het dashboard moet drie vragen meteen beantwoorden: wat heeft nu aandacht nodig, waarom, en wat kan ik nu doen.
Belangrijke views die agenten echt gebruiken
Begin met een kleine set hoge-utility views in plaats van een doolhof aan tabbladen:
- Queue (worklist): de standaardweergave met filters voor priority, SLA-status, kanaal, productgebied en assignee.
- Ticket detail: in één klik te openen, met context en acties boven de vouw.
- Customer profile: compacte weergave van accounttier, recente escalaties, actieve incidenten en sleutelcontacten.
- SLA board: tijdgebaseerde weergave die benadrukt wat binnenkort zal breachen, niet alleen wat al te laat is.
Visuele aanwijzingen die cognitieve belasting verminderen
Gebruik heldere, consistente signalen zodat agenten niet elke regel hoeven te “lezen”:
- Priority chips (P1–P4) met toegankelijke kleur + tekst (nooit alleen kleur).
- SLA-countdown (bijv. “45m tot first response”) en een “breach risk”-indicator.
- Blocker-badges (Waiting on customer, Waiting on engineering, Needs approval) zodat vastgelopen werk zichtbaar is.
Houd typografie simpel: één primaire accentkleur en een strakke hiërarchie (titel → klant → status/SLA → laatste update).
Snelle acties en triagesnelheid
Elke ticketrij moet snelle acties ondersteunen zonder de volledige pagina te openen:
- Assign / reassign, escalate, change priority, request info, set blocker, add internal note.
Voeg bulk actions toe (assign, close, apply tag, set blocker) om backlogs snel op te ruimen.
Toetsenbord, toegankelijkheid en “geen verrassingen”
Ondersteun toetsenbord-snelkoppelingen voor power users: / om te zoeken, j/k om te navigeren, e om te escaleren, a om toe te wijzen, g dan q om terug te gaan naar de queue.
Voor toegankelijkheid: zorg voor voldoende contrast, zichtbare focus-states, gelabelde controls en schermlezer-vriendelijke statustekst (bijv. “SLA: 12 minuten over”). Maak de tabel responsief zodat dezelfde flow op kleinere schermen werkt zonder cruciale velden te verbergen.
Notificaties en on-call alerting
Plan SLA's en eigenaarschap
Gebruik Planning Mode om rollen, statussen en SLA-regels in kaart te brengen voordat je code genereert.
Notificaties zijn het “zenuwstelsel” van een prioriteitsupport-app: ze zetten ticketwijzigingen om in tijdige actie. Het doel is niet om meer te notificeren — maar om de juiste mensen op het juiste kanaal te bereiken met genoeg context om te reageren.
Map de notificatietypen
Begin met een duidelijke set events die berichten triggeren. Veelvoorkomende, hoge-signaal types zijn:
- Assignment: ticket is toegewezen of opnieuw toegewezen aan een agent of team
- Mention: iemand @vermeldt een agent in een interne notitie
- SLA warning: een ticket nadert first response of resolution targets
- SLA breach: een target is gemist (met reden indien bekend)
- Escalation: prioriteit stijgt, een executive/klant wordt toegevoegd of een incident wordt gedeclareerd
Elk bericht moet ticket-ID, klantnaam, priority, huidige eigenaar, SLA-timers en een deep link naar het ticket bevatten.
Kies kanalen zonder controle te verliezen
Gebruik in-app notificaties voor dagelijkse werkzaamheden en e-mail voor duurzame updates en overdrachten. Voor echte on-call-scenario’s voeg SMS/push toe als optioneel kanaal, gereserveerd voor urgente events (zoals een P1-escalatie of dreigende breach).
Voorkom alert-fatigue
Alert-fatigue vermindert reactietijd. Voeg controles toe zoals groepering, stille uren en deduplicatie:
- Groepeer herhaalde SLA-waarschuwingen in één thread
- Dedupe flitsen van “assignment changed” binnen een korte tijd
- Respecteer quiet hours met een override voor kritieke incidenten
Templates + afleveringsgeschiedenis
Bied templates voor zowel klantgerichte updates als interne notities zodat toon en volledigheid consistent blijven. Volg afleveringsstatus (sent, delivered, failed) en houd een notificatietijdlijn per ticket voor auditbaarheid en follow-ups. Een eenvoudige “Notifications”-tab op de ticketdetailpagina maakt dit makkelijk terug te vinden.
Ticketdetailpagina: samenwerking en communicatie
De ticketdetailpagina is waar escalatiewerk daadwerkelijk gebeurt. Het moet agenten helpen context in seconden te begrijpen, met collega’s te coördineren en zonder fouten met de klant te communiceren.
Scheid wat klanten zien van wat intern blijft
Maak de composer expliciet: kies Customer Reply of Internal Note, met verschillende styling en een duidelijke preview. Interne notities moeten snelle opmaak, links naar runbooks en private tags (bijv. “needs engineering”) ondersteunen. Klantantwoorden moeten standaard vriendelijk zijn en precies tonen wat verstuurd wordt.
Threaded conversatie + veilige bijlagen
Ondersteun een chronologische thread met e-mails, chattranscripten en systeemevents. Voor bijlagen prioriteer veiligheid:
- Virus-scanning en toegestane bestandstypen
- Groottebeperkingen en expirerende downloadlinks
- Waarschuwingen voor redactie bij gevoelige data (tokens, wachtwoorden)
Als je door de klant aangeleverde bestanden toont, maak dan duidelijk wie ze heeft geüpload en wanneer.
Macros, snelle antwoorden en opgeslagen stappen
Voeg macros toe die vooraf goedgekeurde antwoorden en troubleshooting-checklists invoegen (bv. “verzamel logs”, “herstartstappen”, “statuspage-tekst”). Laat teams een gedeelde macrobibliotheek beheren met versiegeschiedenis zodat escalaties consistent en compliant blijven.
Een tijdlijn van belangrijke events
Toon naast berichten een compacte event-tijdlijn: statuswijzigingen, prioriteitsupdates, SLA-pauzes/hervattingen, assignee-transfers en escalatieniveau-wijzigingen. Dit voorkomt “wat is er veranderd?”-discussies en helpt bij post-incident review.
Samenwerkingshulpmiddelen die geen ruis creëren
Schakel @mentions, volgers en gekoppelde tasks in (engineering-ticket, incident-doc). Mentions moeten alleen de juiste mensen notificeren en volgers krijgen samenvattingen bij materiële wijzigingen — niet bij elke toetsaanslag.
Beveiliging, privacy en permissies
Ga live voor een pilot
Deploy en host je escalatie-app zodat je team snel kan piloten.
Beveiliging is geen functie voor later: escalaties bevatten vaak klant-e-mails, screenshots, logs en interne notities. Bouw vroeg beschermingen zodat agenten snel kunnen handelen zonder data te veel te delen of vertrouwen te verliezen.
Role-based access control (RBAC) die past bij echt supportwerk
Begin met een kleine set rollen die je in één zin kunt uitleggen (bijv. Agent, Team Lead, On-Call Engineer, Admin). Definieer dan wat elke rol kan view, edit, comment, reassign en export.
Een praktische aanpak is “default deny” permissies:
- Escalation visibility: beperk op team, queue en klantaccount (bijv. alleen Enterprise-queue agenten kunnen Enterprise-escalaties openen)
- Edit-rechten: laat agents status updaten en notities toevoegen, maar beperk SLA-wijzigingen, prioriteitsoverrides en escalatieannuleringen tot leads/admins
- Gevoelige velden: behandel klant-PII (e-mail, telefoon), security-logs en bijlagen als aparte permissies
Privacy by design: least-privilege defaults
Verzamel alleen wat je workflow nodig heeft. Als je geen volledige message bodies of volledige IP-adressen nodig hebt, sla ze dan niet op. Maak bij het opslaan van klantgegevens duidelijk welke velden verplicht vs optioneel zijn en vermijd onnodige duplicatie van data uit andere systemen.
Voor toegangspatronen: ga uit van “support agents zien het minimale om het ticket op te lossen”. Gebruik account- en queue-scoping voordat je complexe regels toevoegt.
Bescherm de basis: authenticatie, sessies en CSRF
Gebruik bewezen authenticatie (SSO/OIDC indien mogelijk), vereis sterke wachtwoorden wanneer wachtwoorden gebruikt worden en ondersteun multi-factor authenticatie voor verhoogde rollen.
Harden sessies:
- Secure, HttpOnly cookies; korte sessieduur voor admin-acties
- Rotatie bij inloggen en privilege-wijzigingen
- CSRF-bescherming voor state-changing requests
Secrets, auditlogs en gevoelige toegang
Sla secrets op in een beheerde secret store (niet in source control). Log toegang tot gevoelige data (wie een escalatie heeft bekeken, een bijlage heeft gedownload, een ticket heeft geëxporteerd) en maak auditlogs moeilijk te manipuleren en doorzoekbaar.
Retentie en exports (zonder te veel te beloven)
Definieer retentiebeleid voor tickets, bijlagen en auditlogs (bijv. bijlagen verwijderen na N dagen, auditlogs langer bewaren). Bied exports voor klanten of interne rapportage, maar claim geen certificeringen tenzij je ze kunt verifiëren. Een eenvoudige “data export”-flow plus een admin-only “delete request”-workflow is een goed begin.
Kies een techstack en architectuur
Je escalatie-app is alleen effectief als hij makkelijk te wijzigen is. Escalatieregels, SLA’s en integraties evolueren continu, dus geef prioriteit aan een stack waar je team voor kan onderhouden en mee kan werken.
Kies een stack die bij je team past
Kies vertrouwde tools boven “perfecte” keuzes. Enkele veelgebruikte combinaties:
- React + Node.js (Express/NestJS): geschikt voor interactieve dashboards en realtime UI
- Django (Python): sterke admin-tools, snel CRUD-werk, goed voor workflow-zware apps
- Rails (Ruby): uitstekende conventies voor snel bouwen van ticketing-stijl producten
Als je al een monolith elders runt, kan aansluiten op dat ecosysteem onboarding en operationele complexiteit verminderen.
Als je sneller wil prototypeën zonder direct een grote engineeringbuild, kun je ook de workflow prototypen in een vibe-coding platform zoals Koder.ai — vooral voor standaarddelen zoals een React-agentdashboard, een Go/PostgreSQL-backend en job-gedreven SLA/notification-logica.
Data-opslag: relationeel eerst, search waar het helpt
Voor kernrecords—tickets, customers, SLA-events, escalatie-events, assignments—gebruik een relationele database (Postgres is een gangbare default). Dit geeft transacties, constraints en rapportagevriendelijke queries.
Voor snelle zoekacties over onderwerpregels, conversatietekst en klantnamen, overweeg later een search index (bv. Elasticsearch/OpenSearch). Houd het optioneel: begin met Postgres full-text search en schaal op als je het nodig hebt.
Background jobs zijn ononderhandelbaar
Escalatie-apps hangen af van tijdgebaseerd en integratiewerk dat niet in een webrequest mag draaien:
- SLA-timers en breach-checks
- Notificaties (e-mail/SMS/push)
- On-call paging
- Synchronisatie van berichten uit e-mail/chat/CRM
Gebruik een jobqueue (bv. Celery, Sidekiq, BullMQ) en maak jobs idempotent zodat retries geen dubbele alerts veroorzaken.
Definieer API’s vroeg en houd ze consistent
Of je nu REST of GraphQL kiest, definieer resource-grenzen vroeg: tickets, comments, events, customers en users. Een consistente API-stijl versnelt integraties en de UI. Plan ook webhook-endpoints vanaf het begin (signing secrets, retries en rate limits).
Hosting en omgevingen
Draai minimaal dev/staging/prod. Staging moet prod-instellingen nabootsen (e-mailproviders, queues, webhooks) met veilige testcredentials. Documenteer deployment- en rollback-stappen en bewaar configuratie in environment variables — niet in code.
Integraties: e-mail, chat, CRM en webhooks
Integraties maken je escalatie-app van “nog een plek om te checken” tot het systeem waarin je team daadwerkelijk werkt. Begin met de kanalen die klanten al gebruiken en voeg automation hooks toe zodat andere tools kunnen reageren op escalatie-events.
E-mail: inbound parsing, outbound sending, threading
E-mail is meestal de meest impactvolle integratie. Ondersteun inbound forwarding (bijv. support@) en parse:
- From/To/Cc, subject, body (geef plain-text fallback), en attachments
- Message-ID en In-Reply-To voor threading
- Customer-domein en handtekening-hints voor contactdiscovery
Voor outbound: verstuur vanuit het ticket (reply/forward) en behoud threading-headers zodat antwoorden terug in hetzelfde ticket komen. Bewaar een schone conversatietijdlijn: toon wat de klant heeft gezien, niet interne notities.
Chattools (optioneel): zet berichten om in tickets
Voor chat (Slack/Teams/intercom-achtige widgets) houd het simpel: zet een conversatie om in een ticket met een duidelijk transcript en deelnemerslijst. Vermijd het automatisch syncen van elk bericht — bied een knop “Attach last 20 messages” zodat agenten de ruis beheersen.
CRM/customer directory sync: identificeer tier en contacten
CRM-sync maakt “priority support” automatisch. Haal company, plan/tier, account owner en sleutelcontacten binnen. Koppel CRM-accounts aan je tenants zodat nieuwe tickets direct prioriteitsregels kunnen erven.
Webhooks voor belangrijke events
Bied webhooks voor events zoals ticket.escalated, ticket.resolved en sla.breached. Lever een stabiel payload (ticket ID, tijdstempels, severity, customer ID) en signeer requests zodat ontvangers authenticiteit kunnen verifiëren.
Documenteer en vereenvoudig de setup
Voeg een kleine adminflow toe met testknoppen (“Send test email”, “Verify webhook”). Houd documentatie op één plek (bijv. documentatie over integraties) en toon veelvoorkomende troubleshootingstappen zoals SPF/DKIM-problemen, ontbrekende threading-headers en CRM-veldmapping.
Testen, monitoring en betrouwbaarheid
Prototypeer de triage-inbox
Prototypeer triage, routing en auditlogs zonder eerst een volledige pipeline op te zetten.
Een prioriteitsupport-app wordt de “single source of truth” in gespannen momenten. Als SLA-timers uitlopen, routing faalt of permissies data lekken, verdwijnt vertrouwen snel. Behandel betrouwbaarheid als een feature: test wat belangrijk is, meet wat er gebeurt en plan voor falen.
Test de regels die urgentie bepalen
Richt geautomatiseerde tests op logica die uitkomsten verandert:
- SLA-berekeningen: start/stop-condities, kantooruren, pauzes, breach-drempels en “next due”-timestamps
- Routing en eigenaarschap: triage-regels, round-robin/skill-based toewijzing en escalatietriggers
- Permissies: RBAC voor queues, ticketdetails, interne notities en klantzichtbare berichten
Voeg een kleine suite end-to-end tests toe die het agentenworkflow nabootsen (create ticket → triage → escalate → resolve) om gebroken aannames tussen UI en backend te vangen.
Seed-data en realistische scenario’s
Maak seed-data die nuttig is buiten demo’s: een paar klanten, meerdere tiers (standaard vs. priority), verschillende prioriteiten en tickets in uiteenlopende staten. Neem lastige gevallen op zoals heropende tickets, “waiting on customer” en meerdere assignees. Dit maakt triage-oefening zinvol en helpt QA edge-cases reproduceerbaar te maken.
Observability: weet het vóór klanten het zeggen
Instrumenteer de app zodat je kunt beantwoorden: “Wat faalde, voor wie en waarom?”
- Error-tracking voor uitzonderingen in SLA- en routing-jobs
- Gestructureerde logs met ticket-ID’s, regel-ID’s en correlatie-ID’s
- Performance-monitoring op kritische pagina’s en background workers
Load-testing en veilige recovery
Draai loadtests op veelbezochte views zoals queues, search en dashboards — vooral rond shiftwisselingen.
Tot slot: bereid je eigen incident-playbook voor: featureflags voor nieuwe regels, stappen voor terugdraaien van database-migraties en een duidelijke procedure om automatiseringen uit te schakelen terwijl agents productief blijven.
Launchplan, rapportage en iteratie
Een prioriteitsupport webapp is pas “klaar” zodra agenten er onder druk op vertrouwen. De beste manier daar te komen is klein lanceren, meten wat er daadwerkelijk gebeurt en in korte cycli itereren.
Begin met een MVP die de workflow bewijst
Weersta de verleiding alles tegelijk te leveren. Je eerste release moet het kortste pad dekken van “nieuwe escalatie” tot “opgelost met verantwoordelijkheid”:
- Een triage-queue met duidelijke sortering (priority, SLA due, customer tier)
- Een ticketdetailpagina die snelle updates en interne notities ondersteunt
- Zichtbare SLA-timers (first response en resolution/next update indien van toepassing)
- Basisalerts voor naderende breaches en statuswijzigingen
Als je Koder.ai gebruikt, past deze MVP-vorm goed bij de common defaults (React UI, Go services, PostgreSQL) en kan de mogelijkheid om snapshots en rollback te maken nuttig zijn tijdens het afstemmen van SLA-wiskunde, routingregels en permissiegrenzen.
Pilot met een klein team en wekelijkse review
Rol uit naar een pilotgroep (een regio, productlijn of on-call-rotatie) en houd wekelijks feedbackreviews. Houd ze gestructureerd: wat vertraagde agenten, welke data ontbrak, welke alerts waren te luidruchtig en waar escalatiemanagement mislukte (handoffs, onduidelijk eigenaarschap of verkeerd geroute tickets).
Een praktische tactiek: houd een lichte changelog in de app zodat agenten verbeteringen zien en zich gehoord voelen.
Voeg rapportage toe die tot actie leidt, niet tot navelstaren
Zodra gebruik consistent is, introduceer rapporten die operationele vragen beantwoorden:
- SLA-compliance: breach-rate per priority, klanttier en kanaal
- Escalatievolume: trends in de tijd en pieken na releases
- Top-drivers: tags/redenen gecorreleerd met escalaties
- Agent-load: open tickets per agent en time-to-first-touch
Deze rapporten moeten eenvoudig te exporteren en begrijpelijk voor niet-technische stakeholders zijn.
Iterateer op regels en macros met echte uitkomsten
Routing- en triageregels zitten er vaak naast in het begin — dat is normaal. Stel routingregels bij op basis van misroutes, resolutietijden en on-call feedback. Doe hetzelfde voor macros en canned responses: verwijder wat geen tijd bespaart en verfijn wat incidentcommunicatie en duidelijkheid verbetert.
Publiceer een simpele roadmap en helpbronnen
Houd je roadmap kort en zichtbaar in het product (“Next 30 days”). Link naar helpcontent en FAQ’s zodat training geen tribal knowledge wordt. Als je publieke info onderhoudt, maak die vindbaar via interne links zoals prijsinformatie of blog zodat teams zelf oplossingen en best practices kunnen vinden.
Veelgestelde vragen
Wat moet als een escalatie tellen in een prioriteitsupport-app?
Schrijf criteria in duidelijke bewoordingen en verwerk ze in de UI. Typische escalatie-triggers zijn:
- Uitval of ernstige degradatie
- VIP / contract voor prioriteitsupport
- Dreigende of herhaalde SLA-overtredingen
- Zaken met impact op security, facturatie of juridische kwesties
Documenteer ook wat geen escalatie is (how-to vragen, featureverzoeken, kleine bugs) en waar die verzoeken in plaats daarvan naartoe moeten worden geleid.
Welke rollen moet je definiëren en hoe wijs je eigenaarschap toe?
Definieer rollen op basis van wat ze doen in de workflow en koppel eigenaarschap aan elk stap:
- Agent: triage, oplossen, ticket bijwerken, playbooks volgen
- Lead: prioriteitswijzigingen goedkeuren, werk herverdelen, escalaties reviewen
Welke ondersteuningskanalen moet je eerst bouwen (e-mail, web, chat)?
Begin met een kleine set kanalen zodat triage consistent blijft en je sneller kunt leveren — gebruik doorgaans e-mail + webformulier. Voeg chat later toe, nadat:
- SLA’s stabiel zijn
- Routingregels werken
- Eigenaarschap en overdrachten duidelijk zijn
Dit beperkt vroege complexiteit (threading, transcript-synchronisatie, realtime-ruis) terwijl je de kernworkflow valideert.
Welke velden zijn essentieel in het ticket- en escalatiedatamodel?
Minimaal moet elk ticket de volgende velden bevatten:
- Aanvrager (contact) en bedrijf (account)
- Onderwerp, beschrijving, bijlagen
- Status, toegewezen persoon/queue, tijdstempels
Voor escalaties voeg gestructureerde velden toe zoals , , en (bijv. API, Billing). Voor SLA’s bewaar expliciete deadlines (bijv. , ) zodat agenten exacte tijden zien.
Hoe moeten statussen en de auditgeschiedenis worden ontworpen voor betrouwbare SLA-rapportage?
Gebruik een kleine, stabiele set statussen (bijv. New, Triaged, In Progress, Waiting, Resolved, Closed) en definieer operationeel wat elke status betekent.
Om SLA’s en verantwoordelijkheid auditeerbaar te maken, houd een append-only geschiedenis bij voor:
- Statuswijzigingen (wie/wanneer)
- SLA start/stop en pauze/resume events
- Prioriteits- en escalatiewijzigingen
Een event-tabel of auditlog maakt reconstructie mogelijk zonder op de huidige staat te hoeven gokken.
Hoe stel je prioriteitsniveaus en SLA-regels op die agenten volgen?
Houd prioriteiten simpel (bijv. P1–P4) en koppel SLA’s aan customer tier/plan + priority. Houd minstens twee timers bij:
- First response SLA: tijd om te erkennen en ownership op te nemen
- Resolution of next-update SLA: tijd om te herstellen of een zinvolle update te geven
Maak overrides mogelijk maar gecontroleerd: vraag om een reden en registreer deze in de auditgeschiedenis zodat rapportage betrouwbaar blijft.
Hoe ga je om met kantooruren, feestdagen en SLA-pauzes zoals “waiting on customer”?
Model tijd expliciet:
- Business-hours SLA’s: bewaar tijdzone, werkdagen en begin/eindtijden
- 24/7 SLA’s: klok loopt continu
- Vakantiekalenders: voorkom valse breaches op dagen dat niemand werkt
Definieer welke statussen timers pauzeren (gebruikelijk Waiting on customer/third party) en wat er gebeurt bij een breach (tag, notificatie, auto-escalatie, paging van on-call). Vermijd “stille” breaches — maak altijd een zichtbaar ticketevent.
Wat is de beste manier om triage, routingregels en handmatige overrides te implementeren?
Bouw een triage-inbox voor ongeadresseerde/needs-review tickets met sortering op priority + SLA due time + customer tier. Houd routing regel-gebaseerd en uitlegbaar met signalen zoals:
- Productgebied (formulierkeuze, tag of afgeleid)
- Trefwoorden (bv. “SSO”, “invoice”, “outage”)\n- Customer tier en regio/tijdzone
Bewaar de reden voor elke routingbeslissing (bv. “Matched keyword: SSO → Auth team”) en sta geautoriseerde overrides toe met een verplichte notitie en auditvermelding.
Wat moet het dashboard en de ticketlijst prioriteren voor snelle agentwerking?
Optimaliseer voor de eerste 10 seconden:
- Een standaard queue/worklist met filters (priority, SLA-risk, kanaal, productgebied, toegewezen persoon)
- Duidelijke rij-visuals: priority-chip (niet alleen kleur), SLA-countdown, blocker-badges
- Snelle acties direct in de lijst: toewijzen, escaleren, prioriteit wijzigen, om info vragen, interne notitie toevoegen
Voeg bulk-acties toe voor backlog-opruiming en toetsenbord-snelkoppelingen en zorg voor toegankelijkheid (contrast, focus-states, schermlezervriendelijke statustekst).
Hoe ga je om met beveiliging (RBAC, privacy) en betrouwbaarheid (testen/monitoring) in een escalatie-app?
Bescherm escalatiegegevens vroeg met praktische maatregelen:
- RBAC met “default deny” en queue/account-scoping
- Scheid permissies voor gevoelige velden (PII, logs, bijlagen) en voor impactvolle acties (SLA/prioriteitsoverrides)
- Tamper-resistant, doorzoekbare auditlogs voor toegang tot gevoelige data (weergave, download, export)
Voor betrouwbaarheid automatiseer tests rond regels die uitkomsten veranderen (SLA-berekeningen, routing/eigenaarschap, permissies) en draai achtergrondjobs voor timers en notificaties met idempotente retries om dubbele alerts te voorkomen.