08 jul 2025·8 min
Hoe je een webapp bouwt voor cross-team dependency-tracking
Leer hoe je een webapp plant en bouwt voor cross-team dependency-tracking: datamodel, UX, workflows, alerts, integraties en stappen voor uitrol.
Leer hoe je een webapp plant en bouwt voor cross-team dependency-tracking: datamodel, UX, workflows, alerts, integraties en stappen voor uitrol.
Voordat je schermen ontwerpt of een tech stack kiest: bepaal precies wat “dependency” in jouw organisatie betekent. Als mensen het woord gebruiken voor alles, zal je app uiteindelijk niets goed bijhouden.
Schrijf één zin die iedereen kan herhalen en lijst vervolgens wat daarvoor in aanmerking komt. Veelvoorkomende categorieën:
Definieer ook wat geen dependency is (bijv. “nice-to-have verbeteringen”, algemene risico’s of interne taken die een ander team niet blokkeren). Dit houdt het systeem schoon.
Dependency tracking faalt wanneer het enkel voor PMs of enkel voor engineers is gebouwd. Noem je primaire gebruikers en wat ieder nodig heeft in 30 seconden:
Kies een klein aantal uitkomsten, zoals:
Beschrijf de problemen die je app op dag één moet oplossen: verouderde spreadsheets, onduidelijke eigenaren, gemiste data, verborgen risico’s en statusupdates verspreid over chatthreads.
Als je eenmaal aligned bent over wat je volgt en voor wie, leg dan de woordenschat en lifecycle vast. Gedeelde definities transformeren “een lijst tickets” in een systeem dat blokkades vermindert.
Kies een klein set types die de meeste situaties dekt en maak elk type makkelijk herkenbaar:
Het doel is consistentie: twee mensen moeten hetzelfde dependency op dezelfde manier classificeren.
Een dependency record moet klein maar compleet genoeg zijn om te managen:
Als je toestaat om een dependency te maken zonder owner team of due date, bouw je een “zorgpunten-tracker”, geen coördinatietool.
Gebruik een eenvoudig statemodel dat overeenkomt met hoe teams echt werken:
Proposed → Accepted → In progress → Ready → Delivered/Closed, plus Rejected.
Schrijf regels voor state changes op. Bijvoorbeeld: “Accepted vereist een owner team en een initiële target date” of “Ready vereist bewijs.”
Voor sluiting eis je het volgende:
Deze definities vormen later de ruggengraat van filters, herinneringen en statusreviews.
Een dependency tracker slaagt of faalt op basis van of mensen de realiteit kunnen beschrijven zonder tegen het gereedschap te vechten. Begin met een klein set objecten die overeenkomen met hoe teams al praten en voeg structuur toe waar het verwarring voorkomt.
Gebruik een handvol primaire records:
Vermijd het maken van aparte types voor elke edge-case. Beter een paar velden toevoegen (bijv. “type: data/API/approval”) dan het model te vroeg te splitsen.
Dependencies betreffen vaak meerdere groepen en meerdere taken. Modelleer dat expliciet:
Dit voorkomt brosse “één dependency = één ticket” denkbeelden en maakt roll-up rapportage mogelijk.
Elk primair object moet auditvelden bevatten:
Niet elke dependency heeft een team in je organigram. Voeg een Owner/Contact record toe (naam, organisatie, e-mail/Slack, notities) en laat dependencies hiernaar verwijzen. Zo blijven leveranciers- of “andere afdeling”-blockers zichtbaar zonder ze te forceren in je interne teamstructuur.
Als rollen niet expliciet zijn, verandert dependency tracking in een comment-thread: iedereen denkt dat iemand anders verantwoordelijk is en data worden "aangepast" zonder context. Een duidelijk rolmodel houdt de app betrouwbaar en maakt escalatie voorspelbaar.
Begin met vier alledaagse rollen en één admin-rol:
Maak de Owner verplicht en uniek: één dependency, één verantwoordelijke owner. Je kunt nog steeds collaborators ondersteunen (bijdragers van andere teams), maar collaborators mogen nooit de verantwoordelijkheid vervangen.
Voeg een escalatiepad toe wanneer een Owner niet reageert: eerst ping de Owner, dan hun manager (of teamlead), daarna een program/release-eigenaar — gebaseerd op jouw organisatiestructuur.
Scheid “details bewerken” van “commitments wijzigen.” Een praktisch standaardmodel:
Als je private initiatieven ondersteunt, definieer wie ze kan zien (bijv. alleen betrokken teams + Admin). Vermijd “geheime dependencies” die leveringsteams verrassen.
Verstop accountability niet in een beleidsdocument. Laat het zien bij elke dependency:
Het labelen van “Accountable vs Consulted” direct in het formulier vermindert misrouting en versnelt statusreviews.
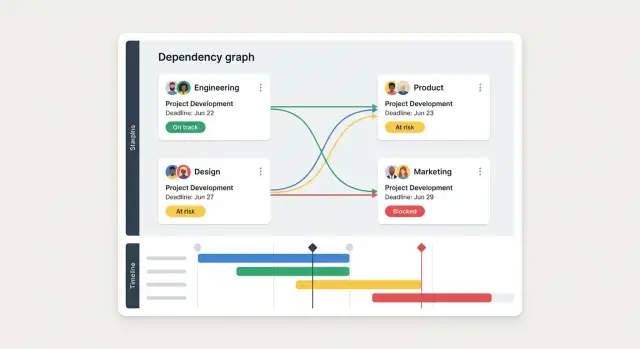
Een dependency tracker werkt alleen als mensen hun items binnen enkele seconden kunnen vinden en ze zonder nadenken kunnen bijwerken. Ontwerp rond de meest voorkomende vragen: “Wat blokkeer ik?”, “Wat blokkeert mij?” en “Gaat er iets bijna mis?”.
Begin met een klein aantal views die overeenkomen met hoe teams over werk praten:
De meeste tools falen bij de “dagelijkse update.” Optimaliseer voor snelheid:
Gebruik kleur plus tekstlabels (nooit kleur alleen) en houd de woordenschat consistent. Voeg een opvallende “Laatst bijgewerkt” tijdstempel toe op elke dependency en een stale-waarschuwing wanneer het een bepaalde periode niet is aangeraakt (bijv. 7–14 dagen). Dit stimuleert updates zonder vergaderingen af te dwingen.
Elke dependency moet één thread hebben die bevat:
Als de detailpagina het hele verhaal vertelt, worden statusreviews sneller — en veel “snelle syncs” verdwijnen omdat het antwoord al is gedocumenteerd.
Een dependency tracker slaagt of faalt op de dagelijkse acties die het ondersteunt. Als teams niet snel kunnen verzoeken, met een duidelijke commitment reageren en de lus sluiten met bewijs, verandert je app in een “FYI-bord” in plaats van een uitvoeringstool.
Begin met één “Create request” flow die vastlegt wat het leverende team moet opleveren, waarom het telt en wanneer het nodig is. Houd het gestructureerd: gevraagde due date, acceptatiecriteria en een link naar het relevante epic/spec.
Handhaaf vervolgens een expliciete reactie-status:
Dit voorkomt de meest voorkomende faalfout: stille “misschien” dependencies die er prima uitzien totdat ze misgaan.
Definieer lichte verwachtingen in de workflow zelf. Voorbeelden:
Het doel is niet te politiseren; het doel is commitments actueel houden zodat planning eerlijk blijft.
Laat teams een dependency op At risk zetten met een korte notitie en volgende stap. Als iemand een due date of status verandert, eis dan een reden (een dropdown + vrije tekst). Deze ene regel creëert een audit trail die retrospectives en escalaties feitelijk maakt, niet emotioneel.
“Close” moet betekenen dat de dependency is voldaan. Vereis bewijs: een link naar een gemergede PR, released ticket, document of een goedkeuringsnotitie. Als sluiting vaag is, zullen teams items vroeg op “green” zetten om herrie te verminderen.
Ondersteun bulk-updates tijdens statusreviews: selecteer meerdere dependencies en zet dezelfde status, voeg een gedeelde notitie toe (bijv. “herpland na Q1 reset”) of vraag updates op. Dit zorgt dat de app snel genoeg is om in echte meetings te gebruiken, niet alleen daarna.
Notificaties moeten levering beschermen, niet afleiden. De makkelijkste manier om ruis te creëren is iedereen over alles te waarschuwen. Ontwerp meldingen rond beslispunten (iemand moet handelen) en risicosignalen (iets glijdt af).
Beperk je eerste versie tot events die het plan veranderen of een expliciete reactie vereisen:
Elke trigger moet horen bij een duidelijke volgende stap: accept/decline, nieuw datumvoorstel, context toevoegen of escaleren.
Standaard: in-app notificaties (zodat alerts gekoppeld zijn aan het dependency record) plus e-mail voor zaken die niet kunnen wachten.
Bied optioneel chatintegraties aan — Slack of Microsoft Teams — maar behandel ze als bezorgmechanismen, niet als systeem van waarheid. Chatberichten moeten diep linken naar het item (bijv. /dependencies/123) en de minimale context bevatten: wie moet handelen, wat is veranderd en wanneer.
Voorzie team- en gebruikersniveau-instellingen:
Dit is ook waar “watchers” belangrijk zijn: notifiseer de requester, het owner-team en expliciet toegevoegde stakeholders — vermijd brede broadcasts.
Escalatie moet geautomatiseerd maar terughoudend zijn: waarschuw wanneer een dependency overdue is, wanneer de due date herhaaldelijk is verzet, of wanneer een blocked status geen update heeft binnen een gedefinieerde periode.
Routeer escalaties naar het juiste niveau (teamlead, program manager) en voeg de geschiedenis toe zodat de ontvanger snel kan handelen zonder context te moeten achterhalen.
Integraties moeten dubbele invoer elimineren, niet extra setup overhead toevoegen. De veiligste aanpak is starten met systemen die teams al vertrouwen (issue trackers, kalenders en identity), eerst read-only of éénrichting, en pas uitbreiden zodra mensen erop gaan vertrouwen.
Kies een primaire tracker (Jira, Linear of Azure DevOps) en ondersteun een eenvoudige link-first flow:
PROJ-123).Dit voorkomt twee bronnen van waarheid terwijl je toch dependency zichtbaarheid biedt. Later kun je optionele two-way sync toevoegen voor een klein aantal velden (status, due date), met duidelijke conflictregels.
Milestones en deadlines worden vaak in Google Calendar of Microsoft Outlook bijgehouden. Begin met het lezen van events in je dependency-tijdlijn (bijv. “Release Cutoff”, “UAT Window”) zonder terug te schrijven.
Read-only calendar sync laat teams plannen waar ze dat al doen, terwijl jouw app impact en aankomende data op één plek toont.
Single sign-on vermindert onboarding-frictie en permissiedrift. Kies op basis van klantrealiteit:
Als je vroeg bent, lever één provider eerst en documenteer hoe anderen aangevraagd kunnen worden.
Zelfs niet-technische teams profiteren wanneer interne ops handoffs kunnen automatiseren. Voorzie een paar endpoints en event hooks met copy-paste voorbeelden.
# Create a dependency from a release checklist
curl -X POST /api/dependencies \\
-H "Authorization: Bearer $TOKEN" \\
-d '{"title":"API contract from Payments","trackerUrl":"https://jira/.../PAY-77"}'
Webhooks zoals dependency.created en dependency.status_changed laten teams integreren met interne tools zonder op je roadmap te moeten wachten. Voor meer, zie /docs/integrations.
Dashboards zijn waar een dependency-app zijn waarde verdient: ze veranderen “ik denk dat we geblokkeerd zijn” in een helder, gedeeld beeld van wat aandacht nodig heeft vóór de volgende check-in.
Een enkele "one size fits all" dashboard faalt meestal. Ontwerp in plaats daarvan een paar views die passen bij hoe mensen meetings leiden:
Bouw een klein set rapporten die mensen daadwerkelijk in reviews gebruiken:
Elk rapport moet beantwoorden: “Wie moet wat doen als volgende stap?” Voeg owner, verwachte datum en laatste update toe.
Maak filteren snel en voor de hand liggend, want de meeste meetings beginnen met “laat me alleen ... zien”.
Ondersteun filters zoals team, initiatief, status, due date range, risiconiveau en tags (bijv. “security review”, “data contract”, “release train”). Sla veelgebruikte filtersets op als named views (bijv. “Release A — komende 14 dagen”).
Niet iedereen leeft de hele dag in je app. Bied:
Als je een betaald plan aanbiedt, behoud adminvriendelijke deelcontrols en verwijs naar /pricing voor details.
Je hebt geen complex platform nodig om een dependency tracking webapp te lanceren. Een MVP kan een simpel drieledige architectuur zijn: een web UI voor mensen, een API voor regels en integraties, en een database als bron van waarheid. Optimaliseer voor “makkelijk te veranderen” boven “perfect”. Je leert meer van echt gebruik dan van maandenlange upfront architectuur.
Een pragmatische start ziet er zo uit:
Als je Slack/Jira-integratie snel verwacht, houd integraties als losse modules/jobs die met dezelfde API praten, in plaats van externe tools direct de database te laten schrijven.
Als je sneller tot een werkend product wilt zonder alles zelf op te bouwen, kan een vibe-coding workflow helpen: bijvoorbeeld Koder.ai kan een React UI en een Go + PostgreSQL backend genereren vanuit een chat-spec, waarna je iteratief kunt werken met planning mode, snapshots en rollback. Je blijft eigenaar van architectuurbeslissingen, maar je verkort de weg van “requirements” naar “bruikbare pilot” en kunt de broncode exporteren wanneer je klaar bent om het volledig intern te nemen.
De meeste schermen zijn lijsten: open dependencies, blockers per team, wijzigingen deze week. Ontwerp daarvoor:
Dependency-data kan gevoelige leveringsdetails bevatten. Gebruik least-privilege toegang (teamniveau zichtbaarheid waar nodig) en houd audit logs voor bewerkingen — wie wat wanneer heeft gewijzigd. Die audit trail vermindert discussie in statusreviews en zorgt dat het tool betrouwbaar aanvoelt.
Het uitrollen van een dependency tracking webapp gaat minder over features en meer over het veranderen van gewoonten. Behandel de rollout als een productlancering: begin klein, bewijs waarde en schaal met een duidelijk operatie-ritme.
Kies 2–4 teams die werken aan één gedeeld initiatief (bijv. een release train of een klantprogramma). Definieer succescriteria die je in enkele weken kunt meten:
Houd de pilotconfiguratie minimaal: alleen de velden en views die nodig zijn om de vraag te beantwoorden “Wat is geblokkeerd, door wie en tegen wanneer?”
De meeste teams tracken afhankelijkheden in spreadsheets. Importeer ze, maar doe dat doelbewust:
Voer een korte “data QA” met pilotgebruikers uit om definities te bevestigen en vage items te corrigeren.
Adoptie blijft plakken wanneer de app een bestaande cadence ondersteunt. Bied:
Als je snel bouwt (bijv. iterative pilot in Koder.ai), gebruik omgevingen/snapshots om wijzigingen aan verplichte velden, statussen en dashboards met pilotteams te testen — en rol dan vooruit (of terug) zonder iedereen te verstoren.
Volg waar mensen vastlopen: verwarrende velden, missende statussen of views die geen antwoord geven op reviewvragen. Bespreek feedback wekelijks tijdens de pilot en pas velden en standaardviews aan voordat je meer teams uitnodigt. Een simpele “Report an issue” link naar /support helpt de lus kort te houden.
Als je dependency-tracker live is, zijn de grootste risico’s niet technisch maar gedragsmatig. De meeste teams stoppen niet met tools omdat ze “niet werken”, maar omdat het bijwerken optioneel, verwarrend of luidruchtig voelt.
Te veel velden. Als het aanmaken van een dependency voelt als het invullen van een formulier, zullen mensen het uitstellen of overslaan. Begin met een minimale set verplichte velden: titel, requesting team, owning team, “volgende actie”, due date en status.
Onduidelijk eigenaarschap. Als niet duidelijk is wie moet handelen, worden dependencies statusthreads. Maak “owner” en “next action owner” expliciet en toon ze prominent.
Geen update-gewoonte. Zelfs een geweldige UI faalt als items verouderen. Voeg zachte prikkels toe: markeer verouderde items in lijsten, stuur herinneringen alleen wanneer een due date nadert of de laatste update oud is, en maak updates eenvoudig (one-click statuswijziging + korte notitie).
Notificatie-overload. Als elke comment iedereen pingt, dempen gebruikers het systeem. Standaardiseer op opt-in watchers en stuur samenvattingen (dagelijks/wekelijks) voor lage urgentie.
Behandel “volgende actie” als een eersteklas veld: elke open dependency moet altijd een duidelijke volgende stap en één verantwoordelijke persoon hebben. Als het ontbreekt, mag het item niet “compleet” lijken in kernviews.
Definieer ook wat “klaar” betekent (bijv. opgelost, niet langer nodig of verplaatst naar een ander tracker) en eis een korte sluitingsreden om zombie-items te vermijden.
Bepaal wie je tags, teamlijst en categorieën beheert. Meestal is dat een program manager of ops-rol met lichte change control. Stel een simpele retire-policy in: archiveer oude initiatieven automatisch na X dagen gesloten, en review ongebruikte tags elk kwartaal.
Zodra adoptie stabiel is, overweeg upgrades die waarde toevoegen zonder frictie:
Als je verbeteringen wilt prioriteren, koppel elk idee aan een reviewritueel (wekelijkse statusmeeting, releaseplanning, incident-retrospect) zodat verbeteringen voortkomen uit echt gebruik, niet uit aannames.
Begin met een eenduidige, één-zin definitie die iedereen kan herhalen, en maak dan een lijst van wat kwalificeert (work item, deliverable, beslissing, omgeving/toegang).
Schrijf ook op wat geen dependency is (nice-to-haves, algemene risico's, interne taken die een ander team niet blokkeren). Dit voorkomt dat het systeem verandert in een vaag "zorgpunten-tracker".
Ontwerp minimaal voor:
Als je alleen voor één groep bouwt, zullen anderen het niet updaten — en raakt het systeem snel verouderd.
Gebruik een klein, consistent lifecycle-model zoals:
Definieer vervolgens regels voor statuswijzigingen (bijv. “Accepted vereist een owner-team en een target date”, “Ready vereist bewijs”). Consistentie is belangrijker dan complexiteit.
Vereis alleen wat je nodig hebt om te coördineren:
Als je toestaat dat owner of due date ontbreekt, verzamel je items die niet actieerbaar zijn.
Maak “klaar” verifieerbaar. Vereis:
Dit voorkomt dat items te vroeg op groen worden gezet om herrie te verminderen.
Definieer vier dagelijkse rollen plus admin:
Houd “één dependency, één owner” om onduidelijkheid te vermijden; gebruik collaborators als helpers, niet als verantwoordelijken.
Begin met views die dagelijkse vragen beantwoorden:
Optimaliseer voor snelle updates: templates, inline bewerken, keyboardvriendelijke bediening en een prominente “Laatst bijgewerkt”.
Waarschuw alleen bij beslispunten en risicosignalen:
Gebruik watchers in plaats van brede broadcasts, bied digest-modus en deduplicatie (één samenvatting per dependency per tijdsvenster).
Integreer om dubbele invoer te vermijden, niet om een tweede bron van waarheid te maken:
dependency.created, dependency.status_changed)Gebruik chat (Slack/Teams) als bezorgkanaal dat naar het record linkt, niet als systeem van waarheid.
Voer een gefocuste pilot uit voordat je op grote schaal uitrolt:
Behandel “geen owner of due date” als onvolledig en itereren op basis van waar gebruikers vastlopen.