Bepaal reikwijdte en gebruikersbehoeften
Voordat je schermen ontwerpt of een fileparser kiest, wees concreet over wie data in en uit je product verplaatst en waarom. Een data-import webapp voor interne operators ziet er heel anders uit dan een self-serve Excel-importtool voor klanten.
Wie zijn de gebruikers?
Begin met het opsommen van de rollen die met imports/exports werken:
- Admins die mappings, regels en permissies configureren
- Operators die importen regelmatig uitvoeren en uitzonderingen afhandelen
- Klanten die hun eigen CSV/Excel-bestanden uploaden en duidelijke begeleiding verwachten
Voor elke rol bepaal je het verwachte vaardigheidsniveau en hoeveel complexiteit ze aankunnen. Klanten hebben meestal minder opties en veel duidelijkere uitleg in de app nodig.
Kern-use-cases (en wanneer iets “klaar” is)
Schrijf je belangrijkste scenario's op en prioriteer ze. Veelvoorkomende voorbeelden:
- Initiele bulkload tijdens onboarding (hoge volumes, rommelige data)
- Periodieke sync (wekelijkse/maandelijkse updates, consistentie is belangrijk)
- Eenmalige export voor rapportage, migratie of backup
Definieer daarna succesmetingen die je kunt volgen. Voorbeelden: minder mislukte imports, snellere foutoplossingstijd, en minder supporttickets over “mijn bestand uploadt niet.” Deze metrics helpen bij het maken van trade-offs later (bijv. investeren in duidelijkere foutmeldingen vs. meer formaten ondersteunen).
Wees expliciet over wat je op dag één ondersteunt:
- Bestandsformaten: CSV, Excel (XLSX), JSON
- Maximale bestandsomvang en rijlimieten (en wat er gebeurt als ze overschreden worden)
- Encodingverwachtingen (bijv. UTF-8) en tijdzone-regels voor datums
Bepaal ook vroeg of er compliance-eisen zijn: bevatten bestanden PII, retentie-eisen (hoe lang je uploads bewaart) en audit-eisen (wie importeerde wat, wanneer en wat veranderde). Deze keuzes beïnvloeden opslag, logging en permissies in het hele systeem.
Kies architectuur en techstack
Voordat je aan een fancy kolommapping-UI of CSV-validatieregels denkt: kies een architectuur die je team zelf vertrouwt en kan draaien. Imports en exports zijn vaak “saai” infrastructuurwerk—iteratiesnelheid en debuggability zijn belangrijker dan nieuwigheid.
Begin met een stack die je team kent
Elke mainstream webstack kan een data-import webapp aandrijven. Kies op basis van bestaande vaardigheden en hiringrealiteit:
- React + Node (TypeScript) als je één taal voor full-stack wilt en een sterk ecosysteem voor background jobs.
- Django als je een batteries-included admin, een volwassen ORM en snelle levering wilt.
- Rails als je waarde hecht aan conventies, snelle CRUD en beproefde background jobpatronen.
Belangrijk is consistentie: de stack moet het makkelijk maken om nieuwe importtypes, validatieregels en exportformaten toe te voegen zonder refactors.
Als je scaffolding wilt versnellen zonder vast te lopen in een prototype, kan een vibe-coding platform zoals Koder.ai hier nuttig zijn: je beschrijft je importflow (upload → preview → mapping → validation → background processing → history) in chat, genereert een React-UI met een Go + PostgreSQL-backend en iterereert snel met planning en snapshots/rollback.
Opslag: scheid “ruw bestand” van “genormaliseerde records”
Gebruik een relationele database (Postgres/MySQL) voor gestructureerde records, upserts en auditlogs voor dataveranderingen.
Sla originele uploads (CSV/Excel) op in object storage (S3/GCS/Azure Blob). Het bewaren van ruwe bestanden is onschatbaar voor support: je kunt parsingproblemen reproduceren, jobs opnieuw draaien en beslissingen over foutafhandeling uitleggen.
Bepaal hoe imports draaien
Kleine bestanden kunnen synchronisch draaien (upload → validate → apply) voor een vlotte UX. Voor grotere bestanden verplaats je het werk naar background jobs:
- upload → enqueue job → toon voortgang/geschiedenis → notify bij voltooiing
Dit helpt ook bij retries en rate-limited writes.
Multi-tenant vs single-tenant
Als je SaaS bouwt, beslis vroeg hoe je tenantdata scheidt (row-level scoping, aparte schemas of aparte databases). Deze keuze beïnvloedt je data export API, permissies en performance.
Niet-functionele eisen documenteren
Leg targets vast voor uptime, max bestandsomvang, verwachte rijen per import, tijd-tot-voltooiing en kostlimits. Deze cijfers sturen de keuze van jobqueues, batchingstrategie en indexering—lang voordat je de UI afwerkt.
Bouw de import intakeflow
De intakeflow bepaalt de ervaring voor elke import. Als die voorspelbaar en vergevingsgezind aanvoelt, proberen gebruikers het opnieuw als er iets misgaat—en dalen de supporttickets.
Entry points: UI-upload en API
Bied een drag-and-drop zone en een klassieke filepicker in de web UI. Drag-and-drop is sneller voor power users; de filepicker is toegankelijker en bekender.
Als klanten importeren vanuit andere systemen, voeg dan een API-endpoint toe. Dat kan multipart uploads accepteren (bestand + metadata) of een pre-signed URL-flow voor grotere bestanden.
Bij upload doe je lichte parsing om een “preview” te maken zonder data te committen:
- Detecteer headers en toon een sample van rijen (bijv. de eerste 20–100)
- Ondersteun veelvoorkomende encodings (UTF‑8, UTF‑16) en delimiters (komma, tab, puntkomma)
- Normaliseer newlines en trim voor de hand liggende formattingissues
Deze preview voedt latere stappen zoals kolommapping en validatie.
Bewaar het originele bestand voor replay
Sla altijd het originele bestand veilig op (object storage is gebruikelijk). Houd het immutabel zodat je:
- De import opnieuw kunt draaien als validatieregels veranderen
- Bugs kunt onderzoeken met exact dezelfde input
- Een “download origineel” optie kunt aanbieden in de importgeschiedenis
Behandel elke upload als een eersteklas record. Sla metadata op zoals uploader, timestamp, bronysteem, bestandsnaam en een checksum (om duplicaten te detecteren en integriteit te waarborgen). Dit is onmisbaar voor traceerbaarheid en debugging.
Pre-checks voordat gebruikers tijd investeren
Draai snelle pre-checks direct en faal vroeg wanneer nodig:
- Bestands- en typegrenzen
- Basis leesbaarheid (kunnen we het parsen?)
- Verplichte kolommen aanwezig (op basis van importtype)
Als een pre-check faalt, geef een duidelijke melding en leg uit wat te herstellen. Het doel is slechte bestanden snel te blokkeren—zonder valide maar imperfecte data te blokkeren die later gemapt en opgeschoond kan worden.
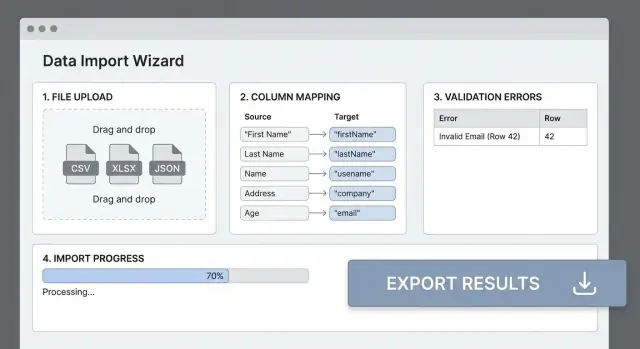
De meeste importfouten ontstaan omdat de headers in het bestand niet overeenkomen met de velden van je app. Een duidelijke kolommappingstap verandert “rommelige CSV” in voorspelbare input en bespaart gebruikers trial-and-error.
Een mapping-UI die mensen snappen
Toon een eenvoudige tabel: Bronkolom → Doelveld. Detecteer automatisch waarschijnlijke matches (case-insensitive headermatching, synoniemen zoals “E-mail” → email), maar laat gebruikers altijd overschrijven.
Voeg een paar usability-verbeteringen toe:
- Markeer verplichte doelvelden en toon of ze gemapt zijn
- Laat “Ignore this column” toe voor irrelevante data
- Highlight unmapped kolommen zodat gebruikers niets missen
Opgeslagen mapping-templates (per klant of dataset)
Als klanten wekelijks hetzelfde formaat importeren, maak het dan één klik. Laat ze templates opslaan die gescopeerd zijn op:
- een klant/account
- een dataset/type (bijv. Contacts vs. Invoices)
- optioneel, een specifieke integratie of bron
Bij een nieuwe upload suggereer een template op basis van kolomoverlap. Ondersteun ook versiebeheer zodat gebruikers een template kunnen updaten zonder oudere runs te breken.
Voeg lichte transformaties toe per gemapt veld:
- witruimte trimmen; lege strings → null
- datumparsing (MM/DD/YYYY vs. DD.MM.YYYY) met tijdzone-opties
- valuta-normalisatie (bijv. “$1,200.00” → 1200.00 + valuta)
- enums normaliseren (bijv. “Active”, “enabled”, “1” → ACTIVE)
- velden splitsen/samenvoegen (Volledige naam → Voornaam/Achternaam, of andersom)
Houd transformaties expliciet in de UI (“Applied: Trim → Parse Date”) zodat het resultaat uitlegbaar blijft.
Preview voordat je commit
Voordat je het volledige bestand verwerkt, toon een preview van de gemapte resultaten voor bijvoorbeeld 20 rijen. Laat de originele waarde, de getransformeerde waarde en waarschuwingen zien (zoals “Kon datum niet parsen”). Hier vinden gebruikers problemen vroeg.
Detecteer duplicaten en sleutelvelden
Vraag gebruikers een sleutelveld te kiezen (email, external_id, SKU) en leg uit wat er bij duplicaten gebeurt. Zelfs als je later upserts afhandelt, zet deze stap verwachtingen: waarschuw voor dubbele sleutels in het bestand en stel voor welk record “wint” (eerste, laatste of fout).
Ontwerp het validatiesysteem
Validatie is het verschil tussen een “bestand uploader” en een importfeature die mensen vertrouwen. Het doel is niet strikt zijn om het strikt zijn, maar slechte data te voorkomen en gebruikers duidelijke, actiegerichte feedback te geven.
Scheid validatie in lagen
Behandel validatie als drie verschillende controles met elk een ander doel:
- Schema-validatie (types & verplichte velden): “Is
email een string?”, “Is amount een getal?”, “Is customer_id aanwezig?” Dit is snel en kan direct na parsing draaien.
- Businessregels: “Bedrag moet positief zijn”, “Status moet Active/Paused zijn”, “Startdatum mag niet in het verleden liggen.” Dit weerspiegelt hoe je product werkt.
- Cross-field en relationele regels: “Als
country=US, is state verplicht”, “end_date moet na start_date zijn”, “Plan-naam moet bestaan in deze workspace.” Deze vragen vaak context (andere kolommen of DB-lookups).
Het apart houden van deze lagen maakt het systeem uitbreidbaarder en makkelijker uit te leggen in de UI.
Strict vs lenient mode (en waarom het ertoe doet)
Bepaal vroeg of een import:
- Het hele bestand faalt (strict mode): geschikt voor financiële data, permissies of alles waar partial updates risico vormen.
- Gedeeltelijk accepteren van valide rijen (lenient mode): handig voor grote lijsten waar gebruikers alleen problematische records verwachten te corrigeren.
Je kunt beide ondersteunen: strict als default, met een “Allow partial import” optie voor admins.
Mensvriendelijke fouten (met rij/kolomreferenties)
Elke fout moet beantwoorden: wat is er gebeurd, waar, en hoe los ik het op.
Voorbeeld: “Rij 42, Kolom ‘Start Date’: moet een geldige datum zijn in YYYY-MM-DD formaat.”
Differentieer:
- Fouten: blokkeren de verwerking voor die rij (of het hele bestand in strict mode)
- Waarschuwingen: toegestaan, maar gemarkeerd (bijv. “Onbekende afdeling; wordt leeg gelaten”)
Maak “fix and re-upload” loops mogelijk
Gebruikers lossen zelden alles in één keer op. Maak re-uploads soepel door validatieresultaten te koppelen aan een importpoging en laat gebruikers een gecorrigeerd bestand opnieuw uploaden. Combineer dit met downloadbare foutrapporten zodat ze issues batchgewijs kunnen oplossen.
Een praktische aanpak is hybride:
- Configureerbare regels voor tenant-specifieke eisen (bijv. “Medewerker-ID moet uniek zijn binnen deze workspace”).
- Code-gedefinieerde regels voor kernproductinvarianten (bijv. permissiegrenzen, verplichte relaties) om misconfiguratie te vermijden.
Dit houdt validatie flexibel zonder dat het een lastig te debuggen “settings-labyrint” wordt.
Implementeer betrouwbare verwerking en retries
Prototypeer je importwizard
Beschrijf je importstroom in de chat en ontvang snel een werkend React- en Go-scaffold.
Imports falen vaak om alledaagse redenen: trage databases, pieken in uploads of één “slechte” rij die de batch blokkeert. Betrouwbaarheid draait om het verplaatsen van zwaar werk buiten de request/response path en het zorgen dat elke stap veilig opnieuw uitgevoerd kan worden.
Gebruik background jobs voor grote bestanden
Run parsing, validatie en schrijfbewerkingen in background jobs (queues/workers) zodat uploads niet tegen web-timeouts lopen. Dit maakt het ook mogelijk om workers horizontaal te schalen als klanten grotere spreadsheets gaan importeren.
Een praktisch patroon is het opdelen in chunks (bijv. 1.000 rijen per job). Eén “parent” importjob schedulet chunk-jobs, aggregeert resultaten en update voortgang.
Houd duidelijke staten en transities bij
Model de import als een state machine zodat UI en ops-team altijd weten wat er gebeurt:
- queued → running → completed
- queued/running → failed (met reden)
- queued/running → canceled (door gebruiker of systeem)
Sla timestamps en attempt counts per state-transitie op zodat je kunt beantwoorden “wanneer is het gestart?” en “hoeveel retries?” zonder in logs te graven.
Voortgang waarop gebruikers kunnen vertrouwen
Toon meetbare voortgang: verwerkte rijen, resterende rijen en tot nu toe gevonden fouten. Als je throughput kunt schatten, voeg een ruwe ETA toe—maar geef liever “~3 min” dan een precieze countdown.
Maak verwerking idempotent (retry-safe)
Retries mogen nooit duplicaten creëren of updates dubbel toepassen. Veelgebruikte technieken:
- Gebruik een import_id plus row_number (of row-hash) als stabiele idempotency key.
- Upsert met een natuurlijke sleutel (zoals external_id) in plaats van altijd insert.
- Schrijf in transacties per chunk zodat partial failures geen corrupte staat veroorzaken.
Throttle om iedereen te beschermen
Rate-limit gelijktijdige imports per workspace en throttle schrijf-intensieve stappen (bijv. max N rijen/sec) om te voorkomen dat de database overbelast raakt en de ervaring voor andere gebruikers degradeert.
Foutmeldingen en importgeschiedenis
Als mensen niet begrijpen wat er misging, blijven ze hetzelfde bestand opnieuw proberen totdat ze opgeven. Behandel elke import als een eersteklas “run” met een duidelijke paper trail en actiegerichte fouten.
Maak een import run-record
Begin met het aanmaken van een import run entiteit op het moment dat een bestand wordt ingediend. Dit record moet de essentie vastleggen:
- Wie het startte (gebruiker + organisatie)
- Wat er is geïmporteerd (originele bestandsnaam, grootte, checksum, entiteitstype)
- Wanneer het gebeurde (start/finish timestamps)
- Hoe het geïnterpreteerd werd (gebruikt mappingconfiguratie, transformatieversie)
- Uitkomst (success/failed/partial, verwerkte rijen, afgewezen rijen)
Dit wordt je importgeschiedenis-scherm: een simpele lijst van runs met status, tellingen en een “view details” pagina.
Sla rijniveaufouten op (niet alleen logs)
Applicatielogs zijn handig voor engineers, maar gebruikers hebben doorzoekbare fouten nodig. Sla fouten op als gestructureerde records gekoppeld aan de importrun, idealiter op twee niveaus:
- Rijniveau: rijnummer, primaire identifier (indien gedetecteerd), snapshot van raw values
- Veldniveau: kolomnaam, errorcode (bijv. REQUIRED, INVALID_DATE), menselijke boodschap, severity
Met deze structuur kun je snelle filters en aggregaten mogelijk maken, zoals “Top 3 fouttypes deze week.”
Maak fouten bruikbaar: UI + downloadbaar rapport
Bied op de run-detailspagina filters op type, kolom en severity, plus een zoekveld (bijv. “email”). Bied daarnaast een downloadbaar CSV-foutrapport aan dat de originele rij plus extra kolommen zoals error_columns en error_message bevat, met duidelijke instructies zoals “Pas datumformaat aan naar YYYY-MM-DD.”
Voeg een dry run-modus toe
Een “dry run” valideert alles met dezelfde mapping en regels, maar schrijft geen data weg. Ideaal voor eerste imports en laat gebruikers veilig itereren voordat ze committen.
Datamodel, upserts en auditability
Lever betere foutmeldingen
Maak een importrun-historie-UI met gestructureerde fouten die gebruikers kunnen filteren en oplossen.
Imports voelen “klaar” als rijen in de database staan—maar de lange termijn kosten zitten vaak in rommelige updates, duplicaten en onduidelijke wijzigingsgeschiedenis. Dit hoofdstuk gaat over het ontwerpen van je datamodel zodat imports voorspelbaar, omkeerbaar en uitlegbaar zijn.
Beslis: aanmaken, updaten of beide
Begin door te definiëren hoe een geïmporteerde rij mapped naar je domeinmodel. Voor elke entiteit bepaal je of de import:
- Alleen nieuwe records mag aanmaken
- Alleen bestaande records mag bijwerken
- Beide mag doen (veelvoorkomend in SaaS)
Deze keuze moet expliciet zijn in de importsetup-UI en bewaard worden bij het importjob zodat gedrag reproduceerbaar is.
Kies upsert-sleutels en collision-rules
Als je “create or update” ondersteunt, heb je stabiele upsert-sleutels nodig—velden die hetzelfde record telkens identificeren. Gebruikelijke keuzes:
external_id (beste bij data uit een ander systeem)- Email (werkt voor gebruikers/contacts, maar kan veranderen)
- Composietsleutels (bijv.
account_id + sku)
Definieer collision rules: wat gebeurt er als twee rijen dezelfde sleutel delen, of als een sleutel meerdere records matcht? Goede defaults zijn “fail de rij met een duidelijke fout” of “last row wins”, maar kies weloverwogen.
Transacties zonder de hele wereld te vergrendelen
Gebruik transacties waar ze consistentie beschermen (bijv. creëren van een parent en zijn children). Vermijd één grote transactie voor een bestand van 200k rijen; dat kan tabellen vergrendelen en retries lastig maken. Geef de voorkeur aan chunked writes (bijv. 500–2000 rijen per batch) met idempotente upserts.
Bescherm referentiële integriteit
Imports moeten relaties respecteren: als een rij naar een parent record verwijst (zoals een Company), vereis dan dat die bestaat of maak het gecontroleerd aan. Vroegtijdig falen met “missende parent” fouten voorkomt half-aangesloten data.
Audit alles wat imports wijzigen
Voeg auditlogs toe voor importgedreven wijzigingen: wie de import startte, wanneer, bronbestand en een per-record samenvatting van wat veranderde (oud vs nieuw). Dit maakt support eenvoudiger, vergroot gebruikersvertrouwen en vereenvoudigt rollbacks.
Bouw exports die schalen
Exports lijken eenvoudig totdat klanten proberen “alles” te downloaden vlak voor een deadline. Een schaalbaar exportsysteem verwerkt grote datasets zonder je app te vertragen of inconsistente bestanden te produceren.
Bied de juiste exporttypes
Begin met drie opties:
- Volledige export: alles waar de gebruiker toegang toe heeft.
- Gefilterde export: respecteert dezelfde filters/zoekopdrachten als in de UI (status, datumbereik, eigenaar, etc.).
- Incrementele export: “wijzigingen sinds X” voor sync-jobs en reporting pipelines.
Incrementele exports zijn vooral nuttig voor integraties en verminderen de load versus herhaalde full dumps.
- CSV is de default voor spreadsheets en bulkanalyse.
- JSON is het beste voor een data export API en automatisering.
- Excel alleen wanneer nodig (meerdere sheets, rijke opmaak of niet-technische workflows).
Wat je ook kiest, houd consistente headers en stabiele kolomvolgorde zodat downstream processen niet breken.
Streamen en pagineren om geheugenpieken te vermijden
Grote exports mogen niet alle rijen in geheugen laden. Gebruik paginering/streaming om rijen te schrijven terwijl je ze ophaalt. Dit voorkomt timeouts en houdt je webapp responsief.
Genereer grote exports asynchroon
Voor grote datasets genereer je exports in een background job en notify je de gebruiker wanneer het klaar is. Een gebruikelijk patroon:
- Gebruiker vraagt export aan.
- App queueet een job.
- Job schrijft het bestand naar object storage.
- UI toont een downloadlink en bewaart het in exportgeschiedenis.
Dit past goed bij je background jobs voor imports en bij hetzelfde “run history + downloadbaar artifact” patroon dat je voor foutrapporten gebruikt.
Exports worden vaak geaudit. Voeg altijd toe:
- Een duidelijke tijdzone-policy (bijv. store in UTC, exporteer in de tijdzone van de gebruiker).
- Consistente datumformattering (ISO-8601 voor JSON; expliciete formaten voor CSV/Excel).
- Een “generated at” timestamp en, voor incrementele exports, de cutoff-tijd die gebruikt is.
Deze details verminderen verwarring en ondersteunen betrouwbare reconciliatie.
Beveiliging, permissies en dataprivacy
Imports en exports zijn krachtige features omdat ze veel data snel kunnen verplaatsen. Dat maakt ze ook een veelvoorkomende bron van securitybugs: één te ruime rol, één gelekte file-URL of één logregel met persoonlijke data.
Authenticatie: kies wat bij je productgebruik past
Begin met dezelfde authenticatie als de rest van de app—maak geen aparte auth-path alleen voor imports.
Als je gebruikers in een browser werken, past session-based auth (plus optioneel SSO/SAML) meestal het beste. Als imports/exports geautomatiseerd zijn (nightly jobs, integratiepartners), overweeg API-keys of OAuth-tokens met duidelijke scope en rotatie.
Een praktische regel: de import-UI en import-API moeten dezelfde permissies afdwingen, ook al worden ze door verschillende doelgroepen gebruikt.
Role-based access: definieer wie wat mag
Behandel import/exportmogelijkheden als expliciete privileges. Veelvoorkomende rollen:
- Can import (bestanden uploaden, imports starten)
- Can export (exports genereren en downloaden)
- Can view history (importruns, fouten, tellingen bekijken)
- Can download files (originele uploads, foutrapporten downloaden)
Maak “download files” een aparte permissie. Veel gevoelige leaks ontstaan wanneer iemand een importrun kan bekijken en het systeem ervan uitgaat dat diegene ook het originele spreadsheet mag downloaden.
Overweeg ook row-level of tenant-level boundaries: een gebruiker mag alleen importeren/exporteren voor de account (of workspace) waartoe hij behoort.
Bescherm gevoelige data end-to-end
Voor opgeslagen bestanden (uploads, gegenereerde fout-CSV's, exportarchieven) gebruik private object storage en kortlevende downloadlinks. Versleutel at-rest waar vereist door compliance en wees consistent: de originele upload, de verwerkte stagingfile en gegenereerde rapporten volgen dezelfde regels.
Wees voorzichtig met logs. Redacteer gevoelige velden (e-mails, telefoonnummers, ID's, adressen) en log standaard geen ruwe rijen. Als debugging nodig is, zet “verbose row logging” achter admin-only instellingen en zorg dat het na korte tijd vervalt.
Valideer en scan uploads voordat je verwerkt
Behandel elke upload als onbetrouwbare input:
- Handhaaf filetype checks (basis op magic bytes, niet alleen de bestandsnaam)
- Stel groottegrenzen in om DoS en per ongeluk enorme uploads te voorkomen
- Overweeg malware-scanning als je risico- of brancheprofiel dat vereist
Valideer structuur vroeg: wijs duidelijk malformed bestanden af voordat ze background jobs bereiken en geef gebruikers heldere uitleg over wat er mis is.
Audittrail voor security-relevante gebeurtenissen
Registreer events die je tijdens een onderzoek wilt hebben: wie een bestand uploadde, wie een import startte, wie een export downloadde, permissiewijzigingen en mislukte toegangspogingen.
Auditentries moeten actor, timestamp, workspace/tenant en het object betreffen (import run ID, export ID) bevatten, zonder gevoelige rijdata op te slaan. Dit past goed bij je importgeschiedenis-UI en helpt snel te beantwoorden “wie deed wat en wanneer?”.
Testen, monitoring en operability
Plan voordat je code schrijft
Breng eerst de staten, jobs en randgevallen in kaart en laat Koder.ai vervolgens de code genereren.
Als imports en exports klantdata aanraken, krijg je vroeg of laat edge-cases: vreemde encodings, samengevoegde cellen, halfgevulde rijen, duplicaten en “het werkte gisteren wel” mysteries. Operability zorgt dat die issues geen support-ramp worden.
Tests die echte bestanden nabootsen
Begin met gerichte tests rond de meest foutgevoelige onderdelen: parsing, mapping en validatie.
- Parsing tests: Gebruik een set representatieve CSV/XLSX-fixtures (verschillende delimiters, datumformaten, lege kolommen, grote getallen, UTF‑8 vs Windows-1252). Assert rijnummers en dat sleutelvelden consistent parsen.
- Mapping + transformatietests: Gegeven een inputkolomset, verifieer dat de app mapt naar de juiste interne velden en transformaties toepast (trim, case-normalisatie, valuta/procentconversie).
- Validatieregeltests: Voor elke regel (required, unique, range, foreign-key existence) includeer “goede” en “slechte” rijen en assert exacte errorcodes/berichten.
Voeg daarna minstens één end-to-end test toe voor de volledige flow: upload → background processing → rapportgeneratie. Deze tests vangen contractmismatches tussen UI, API en workers.
Monitoring die antwoord geeft op “wat is er stuk?”
Volg signalen die gebruikersimpact reflecteren:
- Job failures (aantal en rate)
- Processing time (p50/p95)
- Validatiefout-rate (plotselinge pieken duiden vaak op een templatewijziging)
- Queue depth en worker throughput
Koppel alerts aan symptomen (toegenomen failures, groeiende queue depth) in plaats van elke uitzondering.
Geef interne teams een klein admin-oppervlak om jobs opnieuw te draaien, vastgelopen imports te cancellen en fouten te inspecteren (inputfile-metadata, gebruikte mapping, foutoverzicht en een link naar logs/traces).
Voor gebruikers verminder voorkombare fouten met inline tips, downloadbare sample-templates en duidelijke volgende stappen op foutschermen. Houd een centrale helppagina en link ernaartoe vanuit de import-UI (bijv. /docs).
Deployment, rollout en toekomstige verbeteringen
Het uitrollen van een import/exportsysteem is niet “gewoon push naar productie.” Behandel het als een productfeature met veilige defaults, herstelpaden en ruimte om te evolueren.
Omgevingen: dev, staging, prod
Richt aparte dev/staging/prod-omgevingen in met geïsoleerde databases en aparte object storage buckets (of prefixes) voor uploads en gegenereerde exports. Gebruik verschillende encryptiesleutels en credentials per omgeving en zorg dat jobworkers naar de juiste queues wijzen.
Staging moet productie mirroren: dezelfde jobconcurrentie, timeouts en bestandslimieten. Daar kun je performance en permissies valideren zonder echte klantdata te riskeren.
Migrations en versioned templates
Imports leven vaak “eeuwig” omdat klanten oude spreadsheets bewaren. Gebruik database-migraties zoals gewoonlijk, maar versioneer ook je importtemplates (en mappingpresets) zodat een schemawijziging niet de CSV van vorig kwartaal breekt.
Een praktische aanpak is template_version op te slaan bij elke importrun en compatibiliteitscode voor oudere versies te bewaren totdat je ze depreceert.
Rolloutstrategie met featureflags
Gebruik featureflags om veilig veranderingen te introduceren:
- Nieuwe validatieregels (eerst warn-only, daarna error)
- Nieuwe exportformaten (bijv. JSON naast CSV)
- Nieuwe mappingopties (bijv. het splitsen van “Full name”)
Flags laten je testen met interne gebruikers of een kleine klantenkring voordat je breed uitrolt.
Supportworkflows en diagnose
Documenteer hoe support falende imports onderzoekt met behulp van importgeschiedenis, job IDs en logs. Een simpele checklist helpt: bevestig templateversie, bekijk eerste falende rij, controleer storage-toegang, inspecteer worker-logs. Link dit in je interne runbook en, waar passend, in je admin-UI (bijv. /admin/imports).
Volgende stappen: integraties
Als de kernworkflow stabiel is, breid je uit voorbij uploads:
- API-gebaseerde imports voor geautomatiseerde pipelines
- Webhooks voor “import klaar” of “export gereed” events
- Connectors voor veelgebruikte tools (Google Sheets, S3, Snowflake)
Deze upgrades verminderen handwerk en laten je data-import webapp natuurlijker aanvoelen in bestaande processen van klanten.
Als je dit als productfeature bouwt en de “eerste bruikbare versie” wilt verkorten, overweeg dan Koder.ai om de importwizard, jobstatuspagina's en runhistory-schermen end-to-end te prototypen en daarna de broncode te exporteren voor een conventionele engineeringworkflow. Die aanpak is vooral praktisch wanneer betrouwbaarheid en iteratiesnelheid belangrijker zijn dan pixel-perfecte UI op dag één.