Wat deze webapp moet oplossen
De meeste teams falen niet door gebrek aan ideeën — ze falen omdat resultaten verspreid zijn. Het ene product heeft grafieken in een analytics-tool, een ander heeft een spreadsheet, een derde heeft een slide deck met screenshots. Een paar maanden later kan niemand simpele vragen beantwoorden zoals “Hebben we dit al getest?” of “Welke versie won, met welke metriekdefinitie?”
Het kernprobleem: gefragmenteerde resultaten en inconsistente waarheid
Een experiment-tracking webapp moet centraliseren wat getest is, waarom, hoe het gemeten is en wat er gebeurde — over meerdere producten en teams heen. Zonder zo'n centrale plek verspillen teams tijd aan het herbouwen van rapporten, discussies over cijfers en het opnieuw uitvoeren van oude tests omdat learnings niet doorzoekbaar zijn.
Voor wie het is (en wat elke groep nodig heeft)
Dit is niet alleen een tool voor analisten.
- Productmanagers willen snel uitkomsten, confidence en beslissingsstatus zien.
- Analisten willen een betrouwbare plek om aannames, metriekdefinities en kanttekeningen te documenteren.
- Engineers willen duidelijkheid over welke feature flags, varianten en rollout-condities binnen scope waren.
- Leidinggevenden willen een consistente kijk op impact over producten, zonder handgemaakte decks.
Te optimaliseren uitkomsten
Een goede tracker creëert zakelijke waarde door:
- Snellere beslissingen (minder tijd kwijt aan links en goedkeuringen)
- Minder rapportagefouten (één bron van waarheid voor “de uiteindelijke cijfers”)
- Gedeelde learnings (doorzoekbare geschiedenis van wins, losses en neutrale tests)
Duidelijke scope-afbakening
Wees expliciet: deze app is primair voor het bijhouden en rapporteren van experimentresultaten — niet voor het uitvoeren van experimenten end-to-end. Hij kan linken naar bestaande tools (feature flagging, analytics, data warehouse) terwijl hij het gestructureerde record van het experiment en de uiteindelijke, afgesproken interpretatie beheert.
Vereisten: de minimale levensvatbare experiment-tracker
Een minimale tracker moet twee vragen beantwoorden zonder te hoeven zoeken in docs of spreadsheets: wat testen we en wat hebben we geleerd. Begin met een klein aantal entiteiten en velden die product-overschrijdend werken, en breid alleen uit wanneer teams echte pijn ervaren.
Kernentiteiten om te ondersteunen
Houd het datamodel simpel genoeg zodat elk team het op dezelfde manier gebruikt:
- Product: het oppervlak (app/site/API) waar de wijziging uitrolt.
- Experiment: één hypothese en één beslissing.
- Variant: control en één of meer behandelingen.
- Metriek: een benoemde meting met eigenaar en definitie.
- Segment: optionele doelgroepuitsneden (nieuwe gebruikers, betalende gebruikers, regio) gebruikt voor rapportage.
Experimenttypen (begin klein, blijf flexibel)
Ondersteun de meest voorkomende patronen vanaf dag één:
- A/B-tests (control vs treatment)
- Multivariabele tests (meerdere varianten)
- Feature flag rollouts (percentage-gebaseerde exposure)
Zelfs als rollouts in het begin geen formele statistiek gebruiken, helpt het bijhouden ervan naast experimenten teams te voorkomen dat ze dezelfde “tests” herhalen zonder registratie.
Minimale velden die elk experiment nodig heeft
Bij creatie vraag je alleen wat nodig is om de test later te kunnen interpreteren:
- Hypothese (welke wijziging, voor wie en waarom)
- Owner (één verantwoordelijk persoon)
- Start/eind-datums (gepland en daadwerkelijk)
- Targeting (eligibiliteitsregels) en allocatie (traffic split)
- Links naar rollout/flag, ticket of spec (relatieve URL's zoals /projects/123)
Succescriteria en beslissingsstatus
Maak resultaten vergelijkbaar door structuur af te dwingen:
- Primaire metriek (de belangrijkste succesmaat)
- Guardrails (metriek die niet slechter mag worden)
- Decision status: proposed → running → analyzed → shipped/rolled back → archived
Als je alleen dit bouwt, kunnen teams experimenten betrouwbaar vinden, de opzet begrijpen en uitkomsten vastleggen — zelfs voordat je geavanceerde analytics of automatisering toevoegt.
Datamodel dat werkt over meerdere producten
Een cross-product tracker staat of valt met het datamodel. Als IDs conflicteren, metrics verschuiven of segments inconsistent zijn, kan je dashboard er “juist” uitzien maar het verkeerde verhaal vertellen.
Kies stabiele identifiers (en houd je eraan)
Begin met een duidelijke identifier-strategie:
- product_id: stabiel over hernoemingen (gebruik geen displaynamen als sleutel)
- experiment_key: mensvriendelijke slug (bijv.
checkout_free_shipping_banner) plus een onveranderlijke experiment_id
- variant_key: stabiele labels zoals
control, treatment_a
Zo kun je resultaten tussen producten vergelijken zonder te raden of “Web Checkout” en “Checkout Web” hetzelfde zijn.
Kerncollecties/tabellen
Houd de kernentiteiten klein en expliciet:
- experiments: product_id, hypothesis, primary_metric_def_id, start/end, status
- variants: experiment_id, variant_key, traffic_split
- assignments: experiment_id, user_id (of anonymous_id), variant_key, assigned_at
- metric_defs: metrieknaam, numerator/denominator-logic, unit (user/session/order), owner
- results: experiment_id, metric_def_id, time_window_id, segment_id, computed_at, effect, uncertainty
Zelfs als berekening elders gebeurt, maakt het opslaan van de uitkomsten snelle dashboards en een betrouwbare geschiedenis mogelijk.
Time windows en versioning
Metrieken en experimenten zijn niet statisch. Modelleer:
- time windows (bijv. “eerste 7 dagen na assignment”, “kalenderweken”)
- geversioneerde metriekdefinities: wanneer de berekening van een metriek verandert, maak een nieuwe versie in plaats van de oude te bewerken
Dit voorkomt dat experimenten van vorige maand veranderen wanneer iemand KPI-logic aanpast.
Segmenten en een audit trail
Plan voor consistente segments over producten: land, apparaat, plan-tier, nieuw vs terugkerend.
Voeg tenslotte een audit trail toe die vastlegt wie wat en wanneer veranderde (statuswijzigingen, traffic splits, updates van metriekdefinities). Dat is essentieel voor vertrouwen, reviews en governance.
Metriekdefinities en consistente berekeningen
Als je tracker metriekberekeningen fout doet (of inconsistent over producten), is de “uitslag” gewoon een mening met een grafiek. De snelste manier om dit te voorkomen is metriekdefinities als gedeelde productassets te behandelen — niet als ad‑hoc query-scripts.
Bouw een canonieke metriekcatalogus
Maak een metriekcatalogus die de enige bron van waarheid is voor definities, berekeningslogica en ownership. Elk metriekentree moet bevatten:
- Een plain-English definitie (welke beslissing ondersteunt het)
- Een owner (persoon/team verantwoordelijk voor wijzigingen)
- De exacte formule en benodigde events/velden
- Inclusie/exclusieregels (bijv. interne gebruikers, bots, terugbetaalde orders)
- Geldige aggregatieniveaus en ondersteunde producten
Houd de catalogus dicht bij waar mensen werken (bijv. gelinkt vanuit je experiment-creatieflow) en versioneer hem zodat je historische resultaten kunt uitleggen.
Standaardiseer aggregatieniveaus
Bepaal vooraf wat de “unit of analysis” is voor elke metriek: per user, per session, per account, of per order. Een conversieratio “per user” kan verschillen van “per session” zelfs als beide correct zijn.
Om verwarring te verminderen, sla de aggregatie-keuze op bij de metriekdefinitie en vereist deze bij het opzetten van een experiment. Laat teams niet ad hoc een unit kiezen.
Omgaan met vertraagde conversies en attributie
Veel producten hebben conversievensters (bijv. inschrijving vandaag, aankoop binnen 14 dagen). Definieer attributieregels consistent:
- Wanneer begint de klok (exposure time, eerste bezoek, assignment time)?
- Wat telt als conversie als een gebruiker meerdere keren wordt blootgesteld?
- Hoe behandel je cross-device of cross-product journeys?
Maak deze regels zichtbaar in het dashboard zodat lezers weten wat ze zien.
Sla ruwe tellingen en berekende statistieken op
Voor snelle dashboards en auditability, sla beide op:
- Ruwe tellingen (exposures, converters, revenue-sommen, variance inputs)
- Berekende statistieken (lift, betrouwbaarheidsintervallen, p-waarden)
Dit maakt snelle weergave mogelijk en laat je toch opnieuw berekenen wanneer definities veranderen.
Naamgevingsconventies voorkomen metriek-sprawl
Hanteer een naamstandaard die betekenis encodeert (bijv. activation_rate_user_7d, revenue_per_account_30d). Vereis unieke IDs, dwing aliassen af en markeer bijna-duplicates tijdens het aanmaken om de catalogus schoon te houden.
Data verzamelen: events, pijplijnen en kwaliteitschecks
Je tracker is alleen zo betrouwbaar als de data die erin binnenkomt. Het doel is betrouwbaar twee vragen te kunnen beantwoorden voor elk product: wie werd blootgesteld aan welke variant, en wat deden ze daarna? Alles daarop — metrics, statistiek, dashboards — steunt op die basis.
Kies een ingestie-approach
De meeste teams kiezen een van deze patronen:
- Event stream (near real-time): ideaal voor snelle inzichten en debugging. Vereist meer engineeringrijpheid om stabiel te houden.
- Dagelijkse batch: eenvoudiger en goedkoper. Beste keuze wanneer beslissingen niet elk uur hoeven te gebeuren.
- Hybride: stream exposures en kritieke events (zodat je assignments snel kunt valideren), batch de rest voor volledigheid en kostencontrole.
Wat je ook kiest, standaardiseer de minimale eventset over producten: exposure/assignment, sleutel conversie-events, en voldoende context om ze te joinen (user ID/device ID, timestamp, experiment ID, variant).
Map product-events naar metriek (en valideer volledigheid)
Definieer een duidelijke mapping van ruwe events naar de metriek waar je tracker over rapporteert (bijv. purchase_completed → Revenue, signup_completed → Activation). Houd deze mapping per product bij, maar houd naamgeving consistent zodat je A/B-testresultaten netjes kunt vergelijken.
Valideer volledigheid vroeg:
- Bevestig dat elke exposure een experiment ID en variant heeft.
- Zorg dat conversie-events dezelfde identiteitvelden bevatten als exposures.
- Let op event drop-offs tussen client, server en warehouse (mobiele SDK's zijn vaak probleemgevallen).
Datakwaliteitschecks die je moet automatiseren
Bouw checks die bij elke load draaien en hard falen:
- Ontbrekende exposure-events: conversies zonder eerdere exposure (vaak instrumentatie-gaps of identity mismatches).
- Scheve allocaties: varianten krijgen 70/30 wanneer 50/50 verwacht werd (kan targeting-bugs signaleren).
- Timestamp-sanity: exposures na conversies, of grote vertragingen die op klokproblemen wijzen.
Toon deze als waarschuwingen in de app, gekoppeld aan een experiment, niet verborgen in logs.
Backfills en reprocessing
Pijplijnen veranderen. Wanneer je een instrumentatiefout of dedupe-logic repareert, moet je historische data herberekenen om metrics en KPI's consistent te houden.
Plan voor:
- geversioneerde transformaties (zodat je weet welke logic welke resultaten produceerde)
- veilige backfills (scope limiteren op datum/product/experiment)
- een audit trail van recomputatie
Documenteer integraties
Behandel integraties als productfeatures: documenteer ondersteunde SDK's, eventschema's en troubleshooting-steps. Als je een docs-gebied hebt, link er dan naar als relatieve paden zoals /docs/integrations.
Statistiek en resultaatberekening waarop je kunt vertrouwen
Modelleer kernentiteiten snel
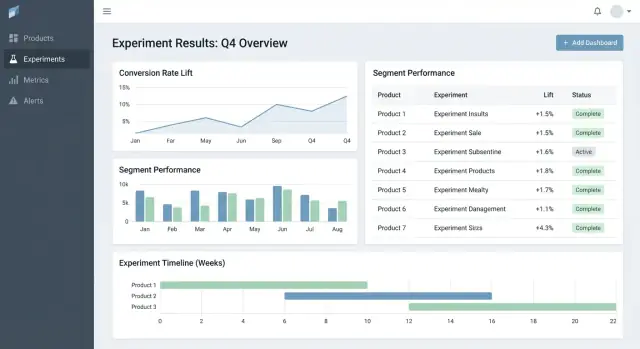
Zet Products, Experiments, Variants, Metrics en Results snel om in echte schermen.
Als mensen de cijfers niet vertrouwen, gebruiken ze de tracker niet. Het doel is niet indruk te maken met wiskunde — het doel is beslissingen reproduceerbaar en verdedigbaar te maken over producten heen.
Kies één statistische “dialect” en houd je daaraan
Beslis van tevoren of je app frequentistische resultaten rapporteert (p-waarden, betrouwbaarheidsintervallen) of Bayesiaanse resultaten (kans op verbetering, geloofwaardige intervallen). Beide werken, maar ze door elkaar gebruiken over producten heen veroorzaakt verwarring (“Waarom toont deze test 97% kans om te winnen, terwijl die p=0.08 toont?”).
Een praktische regel: kies de aanpak die je organisatie al begrijpt, en standaardiseer terminology, defaults en drempels.
Definieer precies wat de UI toont
Minimaal moet je resultatenweergave deze items onmiskenbaar maken:
- Lift (absoluut en/of relatief) versus controle
- Interval (betrouwbaarheidsinterval of geloofwaardig interval) getoond als bereik, niet alleen als punt
- Sterkte van bewijs (p-waarde voor frequentistische benadering, of kans om beter te zijn voor Bayesiaanse benadering)
Toon ook het analysevenster, getelde eenheden (users, sessions, orders) en de metriekdefinitieversie die gebruikt is. Deze details maken het verschil tussen consistente rapportage en discussie.
Meerdere vergelijkingen en “peeking”-beleid
Als teams veel varianten, veel metrics of dagelijkse checks doen, nemen valse positieven toe. Je app moet een beleid vastleggen in plaats van het aan elk team over te laten:
- Multiple comparisons: beslis of je corrigeert (bv. false discovery rate) of resultaat duidelijk als “unadjusted exploratory” labelt.
- Herhaald peeken: ontmoedig het met een vaste einddatum en “finalized” status, of ondersteun sequentiële methoden en toon “safe-to-stop” begeleiding.
Guardrails die veelvoorkomende foutmodes vangen
Voeg automatische flags toe die naast resultaten verschijnen, niet verborgen in logs:
- Sample Ratio Mismatch (SRM): waarschuw als traffic split afwijkt van verwachting
- Anomaly detection: markeer plotselinge dalingen/pieken in traffic, conversies of omzet die kunnen duiden op trackingfouten, outages of bottraffic
Eenvoudige, begrijpelijke uitleg
Naast de cijfers, voeg een korte uitleg toe die een niet-technische lezer kan vertrouwen, bijvoorbeeld: “De beste schatting is +2,1% lift, maar het werkelijke effect kan plausibel tussen -0,4% en +4,6% liggen. We hebben nog geen sterk bewijs om een winnaar aan te wijzen.”
UX en dashboards voor snelle besluitvorming
Goede experimenttools helpen mensen twee vragen snel te beantwoorden: Waar moet ik hierna naar kijken? en Wat moeten we ermee doen? De UI moet context minimaliseren en de “decision state” expliciet maken.
Belangrijke pagina's die de workflow ankereren
Begin met drie pagina's die het meeste gebruik dekken:
- Experiments list: een sorteervolgorde voor de hele organisatie (of per product).
- Experiment detail: de enkele bron van waarheid voor setup, resultaten en beslissing.
- Product overview: een rollup van actieve tests, recente beslissingen en metriekgezondheid voor één product.
Op de lijst- en productpagina's moeten filters snel en persistent zijn: product, owner, datumbereik, status, primaire metriek en segment. Mensen moeten in seconden kunnen filteren op “Checkout-experimenten, eigenaar Maya, draaiend deze maand, primaire metriek = conversie, segment = nieuwe gebruikers”.
Beslissingsstatussen waarop mensen kunnen vertrouwen
Behandel status als een gecontroleerd vocabulaire, geen vrije tekst:
Draft → Running → Stopped → Shipped / Rolled back
Toon status overal (lijstrijen, detail-header en deelbare links) en noteer wie het wijzigde en waarom. Dit voorkomt “stille lanceringen” en onduidelijke uitkomsten.
Een resultaatentabel die de beslissing duidelijk maakt
In de experimentdetailweergave, begin met een compacte resultaatentabel per metriek:
- Baseline
- Variant
- Lift
- Onzekerheid (betrouwbaarheidsinterval of geloofwaardig interval)
- Notities (bv. instrumentatieaantekeningen, segmenteigenaardigheden)
Houd geavanceerde grafieken achter een “Meer details”-sectie zodat beslissers niet overweldigd raken.
Delen en exporteren zonder controle te verliezen
Voeg CSV-export toe voor analisten en deelbare links voor stakeholders, maar handhaaf toegang: links respecteren rollen en productpermissies. Een eenvoudige “Kopieer link”-knop plus een “Export CSV”-actie dekt de meeste samenwerkingsbehoeften.
Permissies, privacy en governance
Zet een metrieken-catalogus op
Maak geversioneerde metriekdefinities zodat resultaten over tijd vergelijkbaar blijven.
Als je tracker meerdere producten overspant, zijn toegangscontrole en auditbaarheid geen optionele extra's. Ze maken de tool veilig in gebruik over teams heen en geloofwaardig tijdens reviews.
Rolgebaseerde toegang (RBAC)
Begin met een eenvoudig set rollen en houd ze consistent door de app:
- Viewer: read-only toegang tot experiments, resultaten en dashboards.
- Editor: kan experiments aanmaken/bewerken, ondersteunende docs uploaden, status zetten (draft → running → concluded).
- Admin: beheert users, permissies, metriekdefinities, retentionregels en integraties.
Houd RBAC-beslissingen gecentraliseerd (één beleidslaag) zodat zowel UI als API dezelfde regels afdwingen.
Product-niveau en rij-niveau permissies
Veel organisaties hebben product-gescopeerde toegang nodig: Team A ziet Product A-experiments maar niet Product B. Modelleer dit expliciet (bv. user ↔ product memberships) en zorg dat elke query op product gefilterd wordt.
Voor gevoelige gevallen (bv. partnerdata, gereguleerde segments) voeg je row-level restrictions toe bovenop product-scoping. Een praktische aanpak is experiments of resultaat-uitsneden te taggen met een sensitiviteitsniveau en extra permissie te vereisen om ze te bekijken.
Audit trail: toegang + wijzigingsgeschiedenis
Log twee dingen apart:
- Change logs: wie een experiment, metriekdefinitie of beslissing bewerkte — wat veranderde en wanneer.
- Access logs: wie resultaten bekeek of exporteerde (vooral bij gevoelige experiments).
Toon de wijzigingsgeschiedenis in de UI voor transparantie en houd diepere logs beschikbaar voor onderzoek.
Retentie- en verwijderregels
Definieer retentieregels voor:
- Experimentmetadata (hypothese, owners, datums, beslissingsnotities)
- Berekende resultaten (effectgroottes, betrouwbaarheidsintervallen, significantievlaggen)
Maak retentie configureerbaar per product en sensitiviteit. Als data verwijderd moet worden, bewaar dan een minimaal tombstone-record (ID, verwijdertijd, reden) om rapportage-integriteit te bewaren zonder gevoelige inhoud te bewaren.
Workflow-features: van idee naar leerlibrary
Een tracker wordt echt nuttig wanneer hij de volledige experiment-lifecycle dekt, niet alleen de uiteindelijke p-waarde. Workflow-features veranderen verspreide docs, tickets en grafieken in een herhaalbaar proces dat de kwaliteit verbetert en learnings hergebruikbaar maakt.
Lifecycle workflow: idee → review → run → post-mortem
Model experiments als een serie staten (Draft, In Review, Approved, Running, Ended, Readout Published, Archived). Elke staat moet duidelijke “exit criteria” hebben zodat experiments niet live gaan zonder essentials zoals een hypothese, primaire metriek en guardrails.
Goedkeuringen hoeven niet zwaar te zijn. Een eenvoudige reviewer-stap (bijv. product + data) plus een audit trail van wie wat goedkeurde en wanneer kan vermijdbare fouten voorkomen. Na afronding vereist een korte post-mortem voordat een experiment “Published” kan worden gemarkeerd zodat resultaten en context vastliggen.
Templates die denken standaardiseren
Voeg templates toe voor:
- Experimentbrief (doel, hypothese, doelgroep, succesmetriek, guardrails, rollout-plan)
- Analysec notities (datasources, uitsluitingen, sanity checks, interpretatie, risico's)
Templates verminderen de “blanco pagina”-frictie en versnellen reviews omdat iedereen weet waar te kijken. Houd ze per product bewerkbaar maar met een gedeelde kern.
Learnings: link alles en houd het doorzoekbaar
Experimenten leven zelden alleen — gebruikers hebben de omliggende context nodig. Laat gebruikers links toevoegen naar tickets/specs en gerelateerde writeups (bijv. /blog/how-we-define-guardrails, /blog/experiment-analysis-checklist). Sla gestructureerde “Learning”-velden op zoals:
- Wat veranderde (beslissing)
- Wat we leerden (insight)
- Wat te doen volgend (follow-up)
Alerts voor guardrails en veranderende resultaten
Ondersteun notificaties wanneer guardrails verslechteren (bv. foutpercentage, annuleringen) of wanneer resultaten materieel veranderen na late data of metriekrecalculation. Maak alerts actiegericht: toon metriek, drempel, tijdsbestek en een owner om te erkennen of op te schalen.
Een bibliotheekweergave om eerder werk te hergebruiken
Bied een library die filtert op product, featuregebied, doelgroep, metriek, uitkomst en tags (bv. “pricing”, “onboarding”, “mobile”). Voeg suggesties voor “vergelijkbare experiments” toe op basis van gedeelde tags/metrieken zodat teams niet opnieuw dezelfde test uitvoeren maar voortbouwen op eerdere learnings.
Architectuur- en techstack-opties
Je hebt geen “perfecte” stack nodig om een experiment-tracking webapp te bouwen — maar je hebt wel heldere grenzen nodig: waar de data staat, waar berekeningen draaien en hoe teams toegang krijgen tot consistente resultaten.
Een praktisch baseline-stack
Voor veel teams ziet een eenvoudige en schaalbare opzet er zo uit:
- Frontend: React (of Vue) voor dashboards en workflows
- Backend API: Node.js/Express, Python/FastAPI of Java/Spring — kies wat het team kan onderhouden
- Database: Postgres voor app-data (experiments, metriekdefinities, permissies)
- Analytics warehouse: BigQuery/Snowflake/Redshift voor eventdata en zware aggregaties
Deze scheiding houdt transactionele workflows snel en laat het warehouse grote berekeningen doen.
Als je de workflow-UI snel wilt prototypen (experiments list → detail → readout) voordat je aan een volledige engineeringcyclus begint, kan een vibe-coding platform zoals Koder.ai je helpen een werkende React + backend basis te genereren vanuit een chat-spec. Het is vooral handig om entities, formulieren, RBAC-scaffolding en auditvriendelijke CRUD neer te zetten en daarna de datacontracten met je analytics-team te verfijnen.
Waar moeten metriekberekeningen draaien?
Je hebt meestal drie opties:
- Warehouse-first: SQL-modellen berekenen metriek- en experimentresultaatstabellen. De app leest vooral.
- Backend-jobs: Een worker berekent resultaten volgens schema of bij veranderingen.
- Hybride: Canonieke aggregaties in het warehouse, met backend nabehandeling (formatting, guardrails, caching).
Warehouse-first is vaak het eenvoudigst als je data-team al vertrouwde SQL beheert. Backend-zwaarte werkt als je lage latency-updates nodig hebt of custom logic, maar verhoogt de applicatiecomplexiteit.
Experimentdashboards herhalen vaak dezelfde queries (top-line KPI's, timeseries, segmentcuts). Plan om:
- Rollups voor te calculeren (dagelijkse aggregaten per experiment/variant/segment)
- Expensive reads te cachen op API-laag (bijv. Redis) met duidelijke invalidatieregels
- Materialized views of geplande tabellen in het warehouse te gebruiken voor veelvoorkomende dashboards
Multi-tenant vs single-tenant
Als je veel producten of business units ondersteunt, beslis vroeg:
- Single-tenant (gedeeld schema): makkelijker te beheren, maar vereist strikte permissiefiltering.
- Multi-tenant: aparte schema's/projects per product/team voor sterkere isolatie, meer overhead.
Een veelvoorkomende compromis is gedeelde infrastructuur met een sterk tenant_id-model en afgedwongen rij-niveau toegang.
Definieer de kern-API's
Houd de API-surface klein en expliciet. De meeste systemen hebben endpoints voor experiments, metrics, results, segments en permissions (plus auditvriendelijke reads). Dat maakt het makkelijker nieuwe producten toe te voegen zonder de hele plumbing te herschrijven.
Testen, monitoring en betrouwbare operatie
Plaats het op je eigen domein
Gebruik een custom domein zodat de tracker als een echt intern product voelt.
Een experiment-tracker is alleen nuttig als mensen hem vertrouwen. Dat vertrouwen komt van gedisciplineerd testen, duidelijke monitoring en voorspelbare operaties — vooral wanneer meerdere producten en pijplijnen dezelfde dashboards voeden.
Observability passend bij hoe mensen de app gebruiken
Begin met gestructureerde logging voor elke kritieke stap: event-ingestion, assignment, metriek-rollups en resultaatberekening. Voeg identifiers toe zoals product, experiment_id, metric_id en pipeline run_id zodat support één resultaat terug kan traceren naar zijn inputs.
Voeg systemmetriek toe (API-latency, job-runtimes, queue-depth) en data-metriek (events verwerkt, % late events, % gedropt door validatie). Complement dit met tracing over services zodat je kunt beantwoorden: “Waarom mist dit experiment de data van gisteren?”
Dataversheidschecks voorkomen stille fouten. Als een SLA “dagelijks om 9u” is, monitor dan per product en bron of:
- de nieuwste partition ontbreekt
- eventvolume sterk afwijkt van baseline
- rollup-jobs afronden maar nul rijen produceren
Geautomatiseerde tests: bescherm data en wiskunde
Maak tests op drie niveaus:
- Schema en constraints: verplichte velden, uniciteit (bijv. één assignment per user per experiment), foreign keys en geldige datumbereiken.
- Permissies: RBAC-tests (viewer/editor/admin) en productscoping zodat teams alleen zien wat ze mogen.
- Resultaatwiskunde: unittests voor lift, betrouwbaarheidsintervallen, significantievlaggen en randgevallen (kleine samples, nul-denominators, meerdere varianten).
Houd een klein “gouden dataset” met bekende outputs om regressies te vangen vóór uitrol.
Deployments, migraties en historische veiligheid
Behandel migraties als onderdeel van operatie: versioneer metriekdefinities en resultaatberekeningslogic en vermijd het herschrijven van historische experiments tenzij expliciet gevraagd. Als veranderingen nodig zijn, bied een gecontroleerd backfill-pad en documenteer wat veranderde in een audit trail.
Voorzie een admin-view om een pijplijn opnieuw te draaien voor een specifiek experiment/datumbereik, validatiefouten te inspecteren en incidenten van statusupdates te voorzien. Link incidentnotities direct vanuit aangedane experiments zodat gebruikers vertragingen begrijpen en geen beslissingen nemen op incomplete data.
Uitrolplan en veelvoorkomende valkuilen
Het uitrollen van een experiment-tracking webapp over producten heen gaat minder over “lanceringsdag” en meer over het geleidelijk wegnemen van onduidelijkheid: wat wordt vastgelegd, wie is eigenaar en komen cijfers overeen met de werkelijkheid.
Een praktische uitrolvolgorde
Begin met één product en een kleine, betrouwbare metriekset (bijv. conversie, activatie, omzet). Het doel is je end-to-end workflow te valideren — experiment aanmaken, exposure en uitkomsten vastleggen, resultaten berekenen en de beslissing registreren — voordat je complexiteit opschaalt.
Als het eerste product stabiel is, breid product-voor-product uit met voorspelbare onboarding. Elk nieuw product moet voelen als een herhaalbare setup, niet als een maatwerkproject.
Als je organisatie vastloopt in lange “platformbouw”-cycli, overweeg een twee-sporen aanpak: bouw duurzame datacontracten (events, IDs, metriekdefinities) parallel met een dunne applicatielaag. Teams gebruiken soms Koder.ai om die dunne laag snel neer te zetten — formulieren, dashboards, permissies en export — en hardenen het daarna naarmate adoptie groeit (inclusief broncode-export en stapsgewijze rollbacks via snapshots wanneer eisen wijzigen).
Uitrol-checklist per nieuw product
Gebruik een lichte checklist om producten en eventschema's consistent onboard te brengen:
- Bevestig event-taxonomie en naamgevingsconventies (en wie ze mag wijzigen)
- Verifieer dat exposure-events bestaan en toewijsbaar zijn aan een unieke gebruiker
- Map metriek naar het eventschema van het product (inclusief randgevallen zoals refunds, annuleringen)
- Voer een backfill of parallel-run periode uit om te vergelijken met bestaande analytics
- Wijs ownership toe voor experiment-setup, datavalidatie en uiteindelijke beslissingsnotities
Waar het adoptie helpt, link je “volgende stappen” vanuit experimentresultaten naar relevante productgebieden (bijv. pricing-gerelateerde experiments linken naar /pricing). Houd links informatief en neutraal — geen impliciete uitkomsten.
Meet adoptie zodat je frictie vroeg kunt oplossen
Meet of de tool de standaardplaats voor beslissingen wordt:
- Wekelijkse actieve gebruikers per rol (PM, analist, engineer)
- Experiments aangemaakt en afgerond
- Percentage met ingevulde beslissingsnotities (niet alleen bekeken resultaten)
- Tijd van experiment-einde → beslissing geregistreerd
Veelvoorkomende valkuilen
In de praktijk struikelen uitrols vaak over een paar terugkerende problemen:
- Inconsistente metriekdefinities tussen producten (zelfde naam, andere berekening)
- Ontbrekende of gebrekkige exposure-tracking, leidend tot vertekende resultaten
- Onduidelijk eigenaarschap voor validatie en sign-off, wat “zombie-experiments” veroorzaakt
- Stille schemawijzigingen die trends breken zonder waarschuwing
- Te snel opschalen naar veel metrics voordat de kernworkflow vertrouwen heeft opgebouwd