15 mei 2025·8 min
Hoe je een webapp bouwt voor verrijking van klantgegevens
Leer hoe je een webapp bouwt die klantrecords verrijkt: architectuur, integraties, matching, validatie, privacy, monitoring en uitroltips.
Definieer doelen, gebruikers en het verrijkingsbereik
Voordat je tools kiest of architectuurdiagrammen tekent, wees precies over wat “verrijking” voor jullie organisatie betekent. Teams mixen vaak meerdere typen verrijking en hebben daarna moeite om vooruitgang te meten — of raken het eens over wanneer iets “af” is.
Wat telt als verrijking?
Begin met het benoemen van de veldcategorieën die je wilt verbeteren en waarom:
- Firmografisch: bedrijfsomvang, sector, hoofdkantoorlocatie, financieringsfase
- Contact: functietitel, geverifieerd e‑mail/telefoon, senioriteit, rol
- Gedrag: productgebruiksignalen, intentie, engagementscore
- Aangepaste velden: interne regio, accounttier, ICP-fitscore
Schrijf op welke velden verplicht zijn, welke fijn om te hebben zijn en welke nooit verrijkt mogen worden (bijvoorbeeld gevoelige attributen).
Wie gebruikt de app — en waarvoor?
Identificeer je primaire gebruikers en hun belangrijkste taken:
- Sales ops: duplicaten verminderen, accounts standaardiseren, betere routing
- Marketing ops: leads verrijken voor segmentatie en gerichtere targeting
- Support: accountcontext tonen bij tickets
- Analisten: betrouwbare datasets voor rapportage
Elke gebruikersgroep heeft vaak een ander workflow-type (bulkverwerking vs. een record tegelijk reviewen), dus leg die behoeftes vroeg vast.
Definieer uitkomsten, scope-grenzen en succesmetrics
Noem uitkomsten in meetbare termen: hogere matchrate, minder duplicaten, snellere lead/account-routing of betere segmentatieprestaties.
Stel duidelijke grenzen: welke systemen vallen binnen de scope (CRM, billing, productanalytics, supportdesk) en welke niet — althans voor de eerste release.
Stem tot slot succesmetrics en acceptabele foutpercentages af (bijv. verrijkingscoverage, verificatiepercentage, duplicaatpercentage en “safe failure”-regels wanneer verrijking onzeker is). Dit wordt jullie noordster voor de rest van de bouw.
Modelleer je klantgegevens en identificeer hiaten
Voordat je iets verrijkt, wees duidelijk wat “een klant” betekent in jullie systeem — en wat je al weet over die klant. Dit voorkomt dat je betaalt voor verrijking die je niet kunt opslaan en voorkomt verwarrende merges later.
Inventariseer je huidige velden en bronnen
Begin met een eenvoudig overzicht van velden (bijv. naam, e‑mail, bedrijf, domein, telefoon, adres, functietitel, sector). Noteer voor elk veld waar het vandaan komt: gebruikersinput, CRM-import, billing, support tool, productinschrijving of een verrijkingsprovider.
Leg ook vast hoe het wordt verzameld (verplicht vs optioneel) en hoe vaak het verandert. Een functietitel en bedrijfsomvang veranderen bijvoorbeeld over tijd, terwijl een interne klant-ID nooit zou moeten veranderen.
Definieer je identiteitsmodel: persoon, bedrijf, account
De meeste verrijkingsworkflows werken met ten minste twee entiteiten:
- Persoon (contact/lead): een individu met e‑mails, telefoonnummers, rollen
- Bedrijf (organisatie): een zakelijke entiteit met domein, locatie, firmografische gegevens
Bepaal of je ook een Account nodig hebt (een commerciële relatie) die meerdere personen aan één bedrijf kan koppelen met attributen zoals plan, contractdata en status.
Schrijf de relaties op die je ondersteunt (bijv. veel personen → één bedrijf; één persoon → meerdere bedrijven over tijd).
Documenteer terugkerende dataproblemen
Noem de problemen die je steeds tegenkomt: ontbrekende waarden, inconsistente formaten ("US" vs "United States"), duplicaten door imports, verouderde records en tegenstrijdige bronnen (billingadres vs CRM‑adres).
Kies vereiste sleutels en stel vertrouwensniveaus vast
Kies de identificatoren die je gebruikt voor matching en updates — meestal e‑mail, domein, telefoon en een interne customer ID.
Ken aan elk een vertrouwensniveau toe: welke sleutels zijn gezaghebbend, welke zijn “best effort” en welke nooit mogen worden overschreven.
Verduidelijk eigenaarschap en bewerkingsrechten
Maak afspraken wie welke velden bezit (Sales ops, Support, Marketing, Customer Success) en definieer bewerkingsregels: wat een mens mag wijzigen, wat automatisering mag wijzigen en wat goedkeuring vereist.
Deze governance bespaart tijd als verrijkingsresultaten conflicteren met bestaande data.
Kies verrijkingsbronnen en datacontracten
Voordat je integratiecode schrijft, bepaal waar verrijkingsdata vandaan komt en wat je ermee mag doen. Dit voorkomt een veelvoorkomende fout: een feature leveren die technisch werkt maar kosten, betrouwbaarheid of compliance schendt.
Typische verrijkingsbronnen
Je combineert meestal meerdere inputs:
- Interne systemen: CRM, billing, supporttickets, productanalytics, e‑mailplatform, datawarehouse
- Third‑party APIs: firmografische gegevens, contactvalidatie, industry codes, technografische data, risksignalen
- Geüploade lijsten: CSVs van sales, events, partners of dataleveranciers
- Webhooks: realtime updates van tools die veranderingen al waarnemen (bv. e‑mailverificatie, identity providers)
Hoe bronnen te evalueren
Beoordeel elke bron op coverage (hoe vaak levert het bruikbare data), freshness (hoe snel wordt het bijgewerkt), kosten (per call/per record), rate limits en gebruiksvoorwaarden (wat je mag opslaan, hoe lang en voor welk doel).
Controleer ook of de provider confidence scores en duidelijke provenance (waar een veld vandaan komt) teruggeeft.
Definieer een datacontract
Behandel elke bron als een contract dat veldnamen en formaten specificeert, verplichte vs optionele velden, updatefrequentie, verwachte latency, foutcodes en confidence‑semantiek.
Neem een expliciete mapping op (“provider veld → jouw canonieke veld”) plus regels voor nulls en conflicterende waarden.
Fallback- en opslagbeslissingen
Plan wat er gebeurt als een bron onbereikbaar is of lage‑confidence resultaten teruggeeft: retry met backoff, in de wachtrij zetten voor later of terugvallen op een secundaire bron.
Bepaal wat je opslaat (stabiele attributen die nodig zijn voor zoeken/rapportage) versus wat je on demand berekent (dure of tijdgevoelige lookups).
Documenteer ten slotte beperkingen voor het opslaan van gevoelige attributen (bijv. persoonlijke identificatoren, afgeleide demografische kenmerken) en stel bewaarbeleid in.
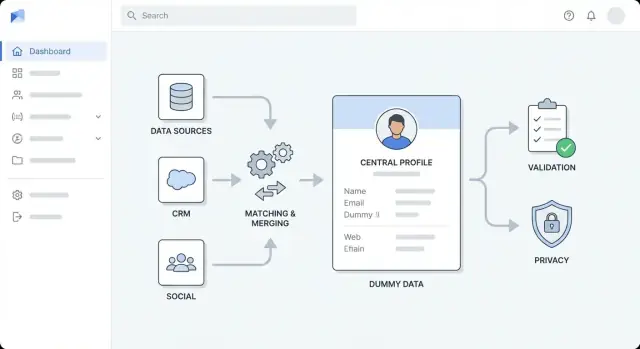
Ontwerp de high‑level architectuur
Voordat je tools kiest, bepaal je hoe de app is opgebouwd. Een duidelijk hoogniveau‑architectuur maakt verrijkingswerk voorspelbaar, voorkomt dat “quick fixes” permanent blijven en helpt inschatten van benodigde inspanning.
Kies een architectuurstijl die bij je team past
Voor de meeste teams is het goed om te beginnen met een modulaire monoliet: één deploybaar systeem, intern opgesplitst in goed gedefinieerde modules (ingestie, matching, verrijking, UI). Het is eenvoudiger om te bouwen, testen en debuggen.
Scheid services pas als je een duidelijk argument hebt — bijv. hoge throughput, onafhankelijke schaalbaarheid of verschillende teams die delen bezitten. Een gebruikelijke splitsing is:
- API‑service (sync‑verzoeken, auth, record CRUD)
- Worker‑service (async verrijking, retries)
- UI (review, goedkeuringen, bulkacties)
Scheid zorgen in lagen
Houd grenzen expliciet zodat veranderingen niet overal doorwerken:
- Ingestielaag: imports uit CRM/bestanden en normaliseert inputs
- Verrijkingslaag: roept vendors/interne bronnen aan en slaat resultaten op
- Validatielaag: past datakwaliteitsregels toe en markeert uitzonderingen
- Opslaglaag: klantprofielen, ruwe bronpayloads, auditgeschiedenis
- Presentatielaag: UI‑views, reviewqueues, goedkeuringen
Ontwerp vanaf dag één voor async verrijking
Verrijking is traag en foutgevoelig (rate limits, timeouts, gedeeltelijke data). Behandel verrijking als jobs:
- API maakt een job aan en antwoordt snel
- Workers verwerken jobs via een queue (met retries en backoff)
- UI toont jobstatus en biedt herstartopties
Plan omgevingen en configuratie
Zet dev/staging/prod vroeg op. Houd vendorkeys, drempels en featureflags in configuratie (niet in code) en maak het makkelijk om providers per omgeving te wisselen.
Stem af met een één‑pagina diagram
Schets een eenvoudig diagram: UI → API → database, plus queue → workers → verrijkingsproviders. Gebruik dit in reviews zodat iedereen het eens is over verantwoordelijkheden voordat je gaat bouwen.
Snel prototypepad (optioneel)
Als je workflow‑en reviewschermen wilt valideren vóór een volledige engineering‑cycle, kan een vibe‑coding platform zoals Koder.ai helpen om de kernapp snel te prototypen: een React‑based UI voor review/goedgekeuringen, een Go API‑laag en PostgreSQL‑backing.
Dit is vooral handig om het jobmodel (async verrijking met retries), auditgeschiedenis en rolgebaseerde toegang te bewijzen, waarna je broncode kunt exporteren wanneer je klaar bent voor productie.
Zet opslag, queues en ondersteunende services op
Voordat je verrijkingsproviders gaat koppelen, regel de “leidingen”. Opslag‑ en achtergrondverwerkingskeuzes zijn lastig later te veranderen en beïnvloeden direct betrouwbaarheid, kosten en auditbaarheid.
Primaire database: profielen + geschiedenis
Kies een primaire database voor klantprofielen die gestructureerde data en flexibele attributen ondersteunt. Postgres is een veelvoorkomende keuze omdat het kernvelden (naam, domein, sector) naast semi‑gestructureerde verrijkingsvelden (JSON) kan opslaan.
Net zo belangrijk: sla wijzigingsgeschiedenis op. In plaats van waarden stilletjes te overschrijven, leg vast wie/wat een veld wijzigde, wanneer en waarom (bijv. “vendor_refresh”, “manual_approval”). Dit vergemakkelijkt goedkeuringen en maakt rollback veiliger.
Queue: verrijking en retries
Verrijking is inherent asynchroon: API's hebben rate limits, netwerken falen en sommige vendors reageren traag. Voeg een jobqueue toe voor achtergrondwerk:
- Verrijkingsverzoeken (enkel record en bulk)
- Retries met backoff
- Geplande refreshes (bv. elke 30/90 dagen)
- Dead‑letter handling voor jobs die blijven falen
Dit houdt je UI responsief en voorkomt dat vendorproblemen de app platleggen.
Cache: snelle lookups en rate‑limit tracking
Een kleine cache (vaak Redis) helpt bij frequente lookups (bv. "bedrijf per domein") en bij het bijhouden van vendor‑rate limits en cooldowns. Het is ook nuttig voor idempotency keys zodat herhaalde imports geen dubbele verrijking triggeren.
Bestandsopslag en retentie
Plan objectopslag voor CSV‑imports/exports, foutrapporten en "diff"‑bestanden die in reviewflows gebruikt worden.
Stel bewaarbeleid vroeg vast: bewaar ruwe vendorpayloads alleen zo lang als nodig voor debug/audit, en expireer logs volgens je compliancebeleid.
Bouw ingestie‑ en normalisatiepijplijnen
Bouw de kernapp snel
Genereer een React review-UI met een Go API en PostgreSQL-achtergrond in één plek.
Je verrijkingsapp is zo goed als de data die je erin stopt. Ingestie bepaalt hoe informatie het systeem binnenkomt; normalisatie maakt die informatie consistent genoeg om te matchen, verrijken en rapporteren.
Bepaal hoe data binnenkomt
De meeste teams hebben een mix van ingangswegen nodig:
- API‑endpoints voor je product of interne tools om nieuwe/bijgewerkte klanten te pushen
- Webhooks van CRM's of billing voor near‑realtime wijzigingen
- Geplande pulls (nachtelijke synchronisaties) voor systemen die geen push ondersteunen
- CSV‑imports voor backfills en ad‑hoc uploads
Wat je ook ondersteunt: houd de “raw ingest” stap lichtgewicht: accepteer data, authenticatie, log metadata en enqueueer werk voor verwerking.
Normaliseer en standaardiseer vroeg
Maak een normalisatielaag die rommelige inputs omzet naar een consistente interne vorm:
- Namen: trim whitespace, split full names wanneer mogelijk, hanteer hoofdlettergebruik
- Telefoons: zet om naar E.164‑notatie en sla landaannames expliciet op
- Adressen: standaardiseer velden (straat, plaats, regio, postcode) en bewaar ook de originele tekst
- Domeinen/ e‑mails: lowercase, verwijder trackingparameters uit URLs, valideer syntaxis
Valideer, quarantaineer en wees idempotent
Definieer verplichte velden per recordtype en weiger of quarantaineer records die checks niet halen (bv. ontbrekende e‑mail/domein voor bedrijfsmatching). Quarantaineitems moeten in de UI zichtbaar en corrigeerbaar zijn.
Voeg idempotency keys toe om dubbele verwerking te voorkomen bij retries (veelvoorkomend bij webhooks en onbetrouwbare netwerken). Een eenvoudige aanpak is hashen van (source_system, external_id, event_type, event_timestamp).
Volg lineage per veld
Sla provenance op voor elk record en bij voorkeur per veld: bron, ingestietijd en transformatie‑versie. Dit maakt later vragen beantwoordbaar: “Waarom is dit telefoonnummer veranderd?” en “Welke import gaf deze waarde?”
Implementeer matching, deduplicatie en mergen
Verrijking werkt alleen als je betrouwbaar kunt herkennen wie wie is. Je app heeft heldere matchingregels, voorspelbaar merge‑gedrag en een veiligheidsnet wanneer het systeem onzeker is.
Definieer matchingregels (en confidence‑drempels)
Begin met deterministische identificatoren:
- Exacte sleutels: e‑mail (genormaliseerd naar lowercase), customer ID, tax/VAT ID of geverifieerd domein
Voeg daarna probabilistische matching toe voor gevallen zonder exacte sleutels:
- Fuzzy matches: naam + bedrijfsdomein, naam + locatie, telefoon‑similariteit
Ken een matchscore toe en zet drempels, bijvoorbeeld:
- Auto‑merge alleen boven een hoge drempel
- In reviewqueue in het “misschien”‑bereik
- Weigeren onder een lage drempel
Plan deduplicatie- en merge‑logica
Wanneer twee records dezelfde klant vertegenwoordigen, bepaal hoe velden worden gekozen:
- Veldvoorrang: “geverifieerde e‑mail wint van niet‑geverifieerd”, “nieuwere timestamp wint”, “CRM overschrijft verrijking voor contact owner”
- Bronvertrouwensscores: rangschik bronnen (CRM, billing, verrijkingsproviders) om conflicten op te lossen
- Conflictbehandeling: bewaar beide waarden waar mogelijk (bijv. meerdere telefoonnummers) of sla de verliezende waarde in de geschiedenis op
Audittrail en reviewworkflow
Elke merge moet een audit‑event creëren: wie/wat het triggerde, voor/na‑waarden, matchscore en betrokken recordIDs.
Voor ambigu matches, bied een reviewscherm met zij‑aan‑zij vergelijking en opties: “merge / niet merge / vraag meer data”.
Beschermingen tegen accidentele massamerge
Vraag extra bevestiging voor bulk merges, cap merges per job en ondersteun een “dry run” preview.
Bied ook een undo‑pad (of merge‑reversal) op basis van de auditgeschiedenis zodat fouten niet permanent zijn.
Integreer verrijkings‑APIs en handel betrouwbaarheid af
Verrijking is waar je app de buitenwereld ontmoet — meerdere providers, inconsistente responses en onvoorspelbare beschikbaarheid.
Behandel elke provider als een verwisselbare “connector” zodat je bronnen kunt toevoegen, wisselen of uitschakelen zonder de rest van de pijplijn aan te raken.
Bouw provider‑connectors (auth, retries, errormap)
Maak één connector per verrijkingsprovider met een consistente interface (bijv. enrichPerson(), enrichCompany()). Houd provider‑specifieke logica in de connector:
- Authenticatie (API‑sleutels, OAuth‑tokens, tokenrefresh)
- Gestandaardiseerde retries voor tijdelijke fouten
- Errormapping (zet providerfouten om in je eigen categorieën zoals
invalid_request,not_found,rate_limited,provider_down)
Dit vereenvoudigt downstream workflows: zij behandelen jouw fouttypes in plaats van elke provider‑eigenaardigheid.
Handel rate limits met throttling en backoff
De meeste verrijkings‑API's hanteren quotas. Voeg per provider throttling toe (en soms per endpoint) om onder limieten te blijven.
Bij het raken van een limiet, gebruik exponentieel backoff met jitter en respecteer Retry‑After headers.
Plan ook voor “langzame fouten”: timeouts en gedeeltelijke responses moeten als retrieable events worden vastgelegd, niet stil verdwijnen.
Sla confidence en bewijs op (binnen beleid)
Verrijkingsresultaten zijn zelden absoluut. Sla provider‑confidence scores op wanneer beschikbaar, plus je eigen score gebaseerd op matchkwaliteit en veldcompleetheid.
Waar toegestaan door contract en privacybeleid, sla ruwe bewijsstukken op (bron‑URLs, identifiers, timestamps) om auditing en gebruikersvertrouwen te ondersteunen.
Multi‑providerstrategie: “best available” selectie
Ondersteun meerdere providers door selectie regels te definiëren: goedkoop‑eerst, hoogste‑confidence of veld‑voor‑veld “beste beschikbaar”.
Noteer welke provider elk attribuut leverde zodat je veranderingen kunt uitleggen en zo nodig kunt terugdraaien.
Geplande refreshregels
Verrijking raakt verouderd. Implementeer refresh‑beleid zoals “opnieuw verrijken elke 90 dagen”, “refresh bij wijziging van sleutelveld” of “refresh alleen als confidence daalt”.
Maak schema's configureerbaar per klant en per datatype om kosten en ruis te beheersen.
Voeg datakwaliteitsregels en validatie toe
Stem het niveau af op de scope
Begin op gratis, en schakel dan over naar Pro, Business of Enterprise naarmate je uitrol groeit.
Verrijking helpt alleen als nieuwe waarden betrouwbaar zijn. Behandel validatie als een kernfunctie: het beschermt gebruikers tegen rommelige imports, onbetrouwbare derde partijen en onbedoelde corruptie tijdens merges.
Definieer veldniveau‑validatieregels
Begin met een eenvoudige “regelscatalogus” per veld, gedeeld door UI‑formulieren, ingestie‑pijplijnen en publieke API's.
Veelvoorkomende regels: formatchecks (e‑mail, telefoon, postcode), toegestane waarden (landcodes, sectorlijsten), reeksen (aantal werknemers, omzetklassen) en verplichte afhankelijkheden (als country = US dan is state verplicht).
Houd regels versieerbaar zodat je ze veilig kunt aanpassen.
Voeg kwaliteitschecks toe die aansluiten op echt gebruik
Naast basisvalidatie, voer datakwaliteitschecks uit die zakelijke vragen beantwoorden:
- Volledigheid: Hebben we de minimale velden om het record te gebruiken?
- Uniekheid: Zijn unieke identifiers (domein, tax ID) gedupliceerd?
- Consistentie: Kloppen gerelateerde velden (land vs. telefoon‑prefix)?
- Actualiteit: Hoe oud is een waarde en moet die worden ververst?
Scoreer records en bronnen
Zet checks om in scorecards: per record (algemene gezondheid) en per bron (hoe vaak levert het valide, up‑to‑date waarden).
Gebruik scores om automatisering te sturen — bijvoorbeeld alleen auto‑apply verrijkingen boven een drempel.
Routeer fouten voorspelbaar
Als een record faalt in validatie, gooi het niet weg.
Stuur het naar een “data‑quality” queue voor retry (transiënt) of handmatige review (slechte input). Bewaar de mislukte payload, regelovertredingen en voorgestelde fixes.
Maak fouten begrijpelijk
Geef duidelijke, uitvoerbare meldingen voor imports en API‑clients: welk veld faalde, waarom en een voorbeeld van een geldige waarde.
Dit vermindert support‑werk en versnelt opschoningswerk.
Maak de UI voor review, goedkeuringen en bulkwerk
Je verrijkingspijplijn levert pas waarde als mensen kunnen zien wat er is veranderd en met vertrouwen updates naar downstream systemen kunnen pushen.
De UI moet duidelijk maken: “wat gebeurde, waarom en wat doe ik hierna?”.
Kernschermen om te ontwerpen
Klantprofiel is de thuisbasis. Toon kernidentifiers (e‑mail, domein, bedrijfsnaam), huidige veldwaarden en een verrijkingsstatus badge (bv. Niet verrijkt, Bezig, Vereist review, Goedgekeurd, Afgewezen).
Voeg een wijzigingsgeschiedenis tijdlijn toe die updates in eenvoudige taal uitlegt: “Bedrijfsomvang bijgewerkt van 11–50 naar 51–200.” Maak elke invoer klikbaar voor details.
Bied merge‑suggesties wanneer duplicaten worden gedetecteerd. Toon de kandidaatrecords zij‑aan‑zij met de aanbevolen “overlevende” record en een preview van het samengevoegde resultaat.
Bulkwerk dat aansluit op operatie
De meeste teams werken in batches. Voeg bulkacties toe zoals:
- Verrijk geselecteerde records (of enqueer voor nachtverwerking)
- Goedkeuren/afkeuren voorgestelde merges
- Exporteer resultaten (CSV) voor audits of offline review
Gebruik een duidelijke bevestiging voor destructieve acties (merge, overschrijven) en bied waar mogelijk een “undo”‑venster.
Snel zoeken, filters en veld‑provenance
Voeg globale zoekfunctie en filters toe op e‑mail, domein, bedrijf, status en kwaliteitscore.
Laat gebruikers views opslaan zoals “Vereist review” of “Lage confidence updates”.
Voor elk verrijkt veld, toon provenance: bron, timestamp en confidence.
Een eenvoudige “Waarom deze waarde?”‑panel vergroot vertrouwen en vermindert overleg.
Guided workflows voor niet‑technische gebruikers
Houd beslissingen binair en begeleid: “Accepteer voorgestelde waarde”, “Behoud bestaande” of “Bewerk handmatig”. Als dieper controle nodig is, verberg die dan achter een “Geavanceerd” toggle.
Basisbeveiliging, privacy en compliance
Valideer het async jobmodel
Zet job-queues, retries en statusschermen neer zonder eerst verschillende tools aan elkaar te koppelen.
Klantverrijkingsapps raken gevoelige identifiers (e‑mails, telefoonnummers, bedrijfsgegevens) en halen vaak data op bij derden. Maak beveiliging en privacy kernfuncties, geen “later” taak.
Rolgebaseerde toegangscontrole (RBAC)
Begin met heldere rollen en least‑privilege defaults:
- Admin: gebruikers, rollen, connectors, retentiebeleid beheren
- Ops: verrijkingsjobs runnen, conflicten oplossen, merges goedkeuren
- Viewer: alleen‑lezen toegang voor rapportage en support
Houd permissies fijnmazig (bv. “exporteer data”, “bekijk PII”, “goedgek. merges”) en scheid omgevingen zodat productiedata niet in dev beschikbaar is.
Bescherm gevoelige data
Gebruik TLS voor alle verkeer en encryptie-at-rest voor databases en objectopslag.
Bewaar API‑sleutels in een secrets manager (niet in omgevingbestanden in source control), roteer ze regelmatig en scope sleutels per omgeving.
Als je PII in de UI laat zien, gebruik veilige defaults zoals gemaskeerde velden (bv. laat de laatste 2–4 cijfers zien) en vereis expliciete permissie om volledige waarden te tonen.
Toestemming en data‑gebruiksbeperkingen
Als verrijking afhangt van toestemming of contractuele afspraken, codeer die beperkingen in je workflow:
- Volg datasource, doel en toegestane gebruiken per veld
- Documenteer wat je opslaat en waarom (een korte interne policypagina zoals /privacy of /docs/data-handling helpt)
- Vermijd het verzamelen van velden die je niet nodig hebt — minder data betekent minder risico
Auditing, retentie en verwijdering
Maak een audittrail voor zowel toegang als wijzigingen:
- Log wie records heeft bekeken/geëxporteerd
- Log wie wat en wanneer wijzigde (voor/na‑waarden, job ID, verrijkingsprovider)
Ondersteun privacyverzoeken met praktische tooling: retentieschema's, recordverwijdering en “vergeet”‑workflows die ook kopieën in logs, caches en backups wissen of markeren voor expiry waar mogelijk.
Monitoring, analytics en operationele controles
Monitoring is niet alleen voor uptime — het is hoe je verrijking betrouwbaar houdt terwijl volumes, providers en regels veranderen.
Behandel elke verrijkingsrun als een meetbare job met duidelijke signalen die je over tijd kunt trenden.
Metrics die echt helpen
Begin met een kleine set operationele metrics die aan uitkomsten gekoppeld zijn:
- Jobthroughput (records/min) en time‑to‑complete per run
- Successrate vs. failurerate, uitgesplitst naar fouttype (validatie, matching, provider)
- Provider latency (p50/p95) en timeouts per verrijkingsbron
- Matchrate (hoe vaak koppel je verrijking met vertrouwen)
- Voorkomen duplicaten (hoeveel zou onjuist gemerged zijn zonder checks)
Deze cijfers beantwoorden snel: “Verbeteren we data, of verplaatsen we ze alleen?”.
Alerts en guardrails
Voeg alerts toe die reageren op verandering, niet op ruis:
- Piek in failures of quarantaineerrecords
- Queue‑achterstanden of langzame consumers (duidt op vastgelopen pijplijn)
- Provider‑error bursts (429/5xx), verhoogde latency of timeouts
Koppel alerts aan concrete acties, zoals het pauzeren van een provider, verlagen van concurrency of switchen naar gecachte/verouderde data.
Admin‑dashboard voor operators
Bied een adminview voor recente runs: status, counts, retries en een lijst met gequarantaineerde records met reden.
Voeg “replay”‑controls en veilige bulkacties toe (retry alle provider‑timeouts, alleen matching opnieuw uitvoeren).
Traceerbaarheid met logs
Gebruik gestructureerde logs en een correlatie‑ID die een record end‑to‑end volgt (ingestie → match → verrijking → merge).
Dit versnelt support en incidentdebugging aanzienlijk.
Incident‑playbooks en rollback
Schrijf korte playbooks: wat te doen als een provider degradeert, als de matchrate instort of als duplicaten doorkomen.
Houd een rollback‑optie (bv. revert merges voor een tijdvenster) en documenteer deze op /runbooks.
Testen, uitrollen en iteratieplan
Testen en uitrollen is waar een verrijkingsapp betrouwbaar wordt. Het doel is niet “meer tests” maar vertrouwen dat matching, merging en validatie voorspelbaar werken met rommelige, real‑world data.
Test de risicovolle onderdelen eerst
Prioriteer tests rond logica die records stilletjes kan beschadigen:
- Matchingregels: unit tests voor exacte, fuzzy en samengestelde matches (bv. e‑mail + bedrijfsdomein). Neem near‑duplicates en verwisselde velden op.
- Merge‑uitkomsten: test veldvoorrang (bronprioriteit), conflictafhandeling en “niet overschrijven”‑regels.
- Validatie edgecases: malformed e‑mails, internationale telefoonformaten, ontbrekend land, duplicate identifiers en “unknown” waarden.
Gebruik synthetische datasets (gegenereerde namen, domeinen, adressen) om nauwkeurigheid te valideren zonder echte klantdata te gebruiken.
Houd een versieerde “golden set” met verwachte match/merge outputs zodat regressies duidelijk zijn.
Faseer de uitrol om blast radius te beperken
Begin klein, schaal op:
- Pilot scope: één team of segment (bv. alleen SMB leads)
- Beperkte acties: begin met “voorgestelde updates” die goedkeuring vereisen vóór terugschrijven naar CRM
- Opschalen: vergroot recordvolume en schakel daarna geautomatiseerde schrijfacties in voor laag‑risico velden
Definieer succesmetrics vooraf (matchprecision, goedkeuringsratio, reductie handmatige edits en time‑to‑enrich).
Documenteer workflows en integratiechecklist
Maak korte docs voor gebruikers en integratoren (link vanuit je productgebied of /pricing als je features gate). Neem een integratiechecklist op:
- API‑authmethode, rate limits en retry‑gedrag
- Vereiste velden voor verrijkingsrequests
- Webhook/event payloads (en versionering)
- Foutcodes en regels voor “gedeeltelijke verrijking”
- Auditlogverwachtingen en datavervaldatum
Voor continue verbetering plan je een lichte reviewcadans: analyseer mislukte validaties, frequente handmatige overrides en mismatches, update daarna regels en voeg tests toe.
Een praktische referentie voor het aanscherpen van regels: /blog/data-quality-checklist.
Build vs. accelerate: een praktische noot
Als je workflows al duidelijk zijn maar je de tijd van specificatie naar werkende app wilt verkorten, overweeg dan Koder.ai om een initiële implementatie (React UI, Go‑services, PostgreSQL) te genereren vanuit een gestructureerd chatplan.
Teams gebruiken dit vaak om snel review‑UI, jobprocessing en auditgeschiedenis neer te zetten en daarna iteratief te verbeteren met planning mode, snapshots en rollback. Wanneer je volledige controle nodig hebt, kun je de broncode exporteren en verder in je bestaande pipeline gaan. Koder.ai biedt free, pro, business en enterprise tiers om experimenteren vs. productiebehoeften af te stemmen.