26 nov 2025·8 min
Hoe je een webapp bouwt om operationele knelpunten te volgen
Stapsgewijze gids om een webapp te plannen, ontwerpen en uitrollen die workflowdata vastlegt, knelpunten detecteert en teams helpt vertragingen te verhelpen.
Begin bij het probleem en de beslissingen
Een proces-tracking webapp helpt alleen als hij een specifieke vraag beantwoordt: “Waar lopen we vast, en wat moeten we daaraan doen?” Voordat je schermen tekent of een webapp-architectuur kiest, definieer wat “knelpunt” betekent in jouw operatie.
Definieer wat telt als een knelpunt
Een knelpunt kan een stap zijn (bijv. “QA-review”), een team (bijv. “fulfillment”), een systeem (bijv. “betaalgateway”) of zelfs een leverancier (bijv. “carrier pickup”). Kies de definities die je daadwerkelijk wilt beheren. Bijvoorbeeld:
- Een stap is een knelpunt wanneer de gemiddelde wachttijd in de rij meer dan 24 uur bedraagt.
- Een team is een knelpunt wanneer work-in-progress boven een ingestelde drempel blijft gedurende 3 dagen.
- Een systeem is een knelpunt wanneer incidenten de doorlooptijd laten pieken buiten een afgesproken bereik.
Maak een lijst van beslissingen die de app moet ondersteunen
Je operations-dashboard moet tot actie leiden, niet alleen rapportage. Schrijf de beslissingen op die je sneller en met meer zekerheid wilt nemen, zoals:
- Personeelsplanning: “Zetten we deze week iemand van Team A naar Team B?”
- Prioritering: “Welke orders/tickets mogen de rij oversteken om SLA’s te beschermen?”
- Automatisering: “Welke stap is stabiel genoeg (en kostbaar genoeg) om eerst te automatiseren?”
Identificeer primaire gebruikers en wat ze nodig hebben
Verschillende gebruikers hebben verschillende weergaven nodig:
- Ops-managers hebben een duidelijke “waar ingrijpen vandaag” weergave nodig.
- Teamleads hebben drill-downs nodig naar individuele wachtrijen, blokkades en overdrachten.
- Analisten hebben consistente definities en exports nodig voor workflow-analyse.
Stel succesmetrics voor de app zelf vast
Bepaal hoe je weet dat de app werkt. Goede maatstaven zijn adoptie (wekelijkse actieve gebruikers), tijdsbesparing op rapportage en snellere oplossing (verkorte detectie- en hersteltijden van knelpunten). Deze metrics houden je gefocust op uitkomsten, niet op features.
Kies de workflow en schrijf een eenvoudige procesmap
Voordat je tabellen, dashboards of alerts ontwerpt, kies een workflow die je in één zin kunt beschrijven. Het doel is te volgen waar werk wacht — dus begin klein en kies één of twee processen die ertoe doen en voldoende volume genereren, zoals orderafhandeling, supporttickets of onboarding van medewerkers.
Een scherpe scope houdt de definitie van klaar helder en voorkomt dat het project vastloopt omdat teams het oneens zijn over hoe het proces zou moeten werken.
Begin met 1–2 processen met veel signaal
Kies workflows die:
- Frequent voorkomen (genoeg data om patronen te zien)
- Ten minste één overdracht omvatten (waar wachtrijen ontstaan)
- Een duidelijke klantimpact hebben (tijd, kosten, tevredenheid)
Bijvoorbeeld: “supporttickets” is vaak beter dan “customer success” omdat het een duidelijk werkunit en tijdgestempelde acties heeft.
Breng stappen en overdrachten in eenvoudige taal in kaart
Schrijf de workflow als een eenvoudige lijst van stappen met woorden die het team al gebruikt. Je documenteert geen beleid — je identificeert toestanden waar het werkdoorheen beweegt.
Een lichte procesmap kan er zo uitzien:
- Ticket aangemaakt → getriageerd → toegewezen → medewerker bezig → wacht op klant → opgelost
Wijs in dit stadium overdrachten expliciet aan (triage → toegewezen, medewerker → specialist, enz.). Overdrachten zijn waar wachttijd vaak verborgen zit en het zijn de momenten die je later wilt meten.
Definieer start/eindgebeurtenissen en “klaar” voor elke stap
Voor elke stap schrijf je twee dingen:
- Startgebeurtenis (wat bewijst dat de stap begon?)
- Eindgebeurtenis (wat bewijst dat de stap klaar is?)
Houd het observeerbaar. “Agent begint met onderzoeken” is subjectief; “status gewijzigd naar In Progress” of “eerste interne notitie toegevoegd” is meetbaar.
Definieer ook wat “klaar” betekent zodat de app geen gedeeltelijke afronding voor voltooiing aanziet. Bijvoorbeeld, “opgelost” kan betekenen “oplossingsbericht verzonden en ticket gemarkeerd als Resolved”, niet alleen “intern werk voltooid”.
Noteer veelvoorkomende uitzonderingen die je later volgt
Reële operaties bevatten rommelige paden: rework, escalaties, ontbrekende informatie en heropeningen. Probeer niet alles op dag één te modelleren — schrijf de uitzonderingen op zodat je ze later doelbewust kunt toevoegen.
Een korte notitie zoals “10–15% van tickets wordt geëscaleerd naar Tier 2” is genoeg. Je gebruikt deze notities om te beslissen of uitzonderingen eigen stappen, tags of aparte flows worden wanneer je het systeem uitbreidt.
Definieer metrics die echt knelpunten onthullen
Een knelpunt is geen gevoel — het is een meetbare vertraging bij een specifieke stap. Voordat je grafieken bouwt, bepaal welke cijfers aantonen waar werk zich ophoopt en waarom.
Kies een kleine set kernmetingen
Begin met vier metrics die voor de meeste workflows werken:
- Cycle time: hoe lang een item duurt van start tot klaar.
- Wait/queue time: hoe lang een item idle zit tussen stappen.
- Throughput: hoeveel items er per tijdsperiode worden afgerond.
- WIP (work in progress): hoeveel items momenteel “in het systeem” zijn.
Deze dekken snelheid (cycle), inactiviteit (queue), output (throughput) en belasting (WIP). De meeste “mysterie-vertragingen” tonen zich als groeiende wachttijd en WIP bij een bepaalde stap.
Definieer berekeningen (inclusief randgevallen)
Schrijf definities waar je hele team het over eens kan zijn en implementeer precies dat.
- Cycle time =
done_timestamp − start_timestamp.- Randgevallen: items die heropend worden (behandel als nieuwe cycle vs. verleng de originele), items die nooit gestart zijn (sluit uit van cycle time maar tel mee in WIP), ontbrekende timestamps (markeer als datakwaliteit).
- Queue time = som van gaps tussen stappen waarin de status “waiting” is.
- Randgevallen: nachten/weekends (kalendertijd vs. kantooruren), geblokkeerde staten (apart tellen van normale wachttijd als je duidelijkere oorzaken wilt).
- Throughput = aantal items met
done_timestampin het venster.- Randgevallen: annuleringen (uitsluiten of apart bijhouden), gedeeltelijke afrondingen.
- WIP = aantal items dat zich niet in een terminale staat bevindt op een tijdspunt.
- Randgevallen: on-hold items (nog steeds WIP, maar je wilt misschien een aparte “blocked WIP”).
Kies de uitsplitsingen die beslissingen sturen
Kies slices die managers daadwerkelijk gebruiken: team, kanaal, productlijn, regio en prioriteit. Het doel is te beantwoorden: “Waar is het traag, voor wie en onder welke omstandigheden?”
Stel tijdvensters en doelen vast
Bepaal je rapportageritme (dagelijks en wekelijks zijn gebruikelijk) en definieer doelen zoals SLA/SLO-drempels (bijvoorbeeld: “80% van high-priority items binnen 2 dagen afgerond”). Doelen maken het dashboard actiegericht in plaats van decoratief.
Plan je databronnen en verzamelmethode
De snelste manier om een bottleneck-tracking app te laten stokken is aannemen dat de data “er gewoon zal zijn”. Voordat je tabellen of grafieken ontwerpt, schrijf op waar elk event en tijdstempel vandaan komt — en hoe je het consistent houdt over tijd.
Maak een inventaris van bronnen die je al hebt
De meeste operationele teams volgen werk al op een paar plekken. Veelvoorkomende startpunten zijn:
- Spreadsheets gebruikt voor overdrachten, dagelijkse logs of productieaantallen
- ERP/CRM-systemen (orders, klanten, fulfilment-stappen)
- Ticketingtools (support-queues, change requests, onderhoudstaken)
- Interne databases (warehouse scans, job scheduling tabellen, manufacturing execution data)
Noteer voor elke bron wat het kan leveren: een stabiel record-ID, een statusgeschiedenis (niet alleen de huidige status) en minstens twee timestamps (ingang stap, uitgang stap). Zonder die gegevens wordt monitoring van wachttijden en tracking van doorlooptijden giswerk.
Kies een capture-methode die bij de bron past
Je hebt doorgaans drie opties, en veel apps gebruiken een mix:
- API pull: geplande sync van ERP/CRM/ticketing tools. Makkelijk te beredeneren, maar je moet omgaan met paginering, rate limits en incrementele updates.
- Webhooks: push-updates wanneer werk verandert. Geschikt voor near-real-time alerts, maar ontwerp voor retries en out-of-order events.
- Handmatige invoer / CSV-upload: nuttig voor teams die vanuit spreadsheets starten of voor randgevallen. Maak het veilig met templates, validatie en duidelijke foutmeldingen.
Plan voor datakwaliteit (want die zal komen)
Reken op ontbrekende timestamps, duplicaten en inconsistente statussen (“In Progress” vs “Working”). Bouw vroeg regels in:
- Geef de voorkeur aan een onveranderlijke event-log boven het overschrijven van records
- Dedupliceer op source ID + event time + status
- Normaliseer statussen naar de canonieke stappen van je app
- Flag records die geen betrouwbare cycle time kunnen produceren
Bepaal de verversingsfrequentie
Niet elk proces heeft real-time updates nodig. Kies op basis van de beslissingen:
- Realtime: dispatching, supporttriage, SLA-risico
- Uurlijks: warehouse throughput, monitoring van wachttijd
- Dagelijks: wekelijkse rapportage, continue verbeterreviews
Leg dit nu vast; het bepaalt je sync-strategie, kosten en verwachtingen voor het operations-dashboard.
Ontwerp een datamodel gericht op tijdsanalyse
Een bottleneck-tracking app leeft of sterft aan hoe goed hij tijdsvragen kan beantwoorden: “Hoe lang duurde dit?”, “Waar wachtte het?”, en “Wat veranderde net voordat het vertraagde?” De makkelijkste manier om die vragen later te ondersteunen is je data vanaf dag één rond events en timestamps te modelleren.
Begin met de kernentiteiten
Houd het model klein en duidelijk:
- Process: de algemene workflow (bijv. “Order Fulfillment”).
- Step: een fase binnen het proces (bijv. “Pick”, “Pack”, “Ship”).
- Work item: de eenheid die door stappen beweegt (ticket, order, claim).
- Event: een vastgelegde statuswijziging (ingesteld in stap, toegewezen, geblokkeerd, voltooid).
- User/Team en Assignment: wie het werk op een gegeven moment beheerde.
Deze structuur laat je doorlooptijd per stap meten, wachttijd tussen stappen berekenen en throughput over het hele proces zonder speciale gevallen uit te vinden.
Geef de voorkeur aan een event-log boven “huidige status”-velden
Behandel elke statuswijziging als een onveranderlijk eventrecord. In plaats van current_step te overschrijven en geschiedenis te verliezen, voeg je een event toe zoals:
- work_item_id
- from_step → to_step (of “entered_step”)
- event_type (assigned, started, blocked, completed)
- event_time
Je kunt nog steeds een snapshot van de “huidige staat” bewaren voor snelheid, maar je analyses moeten op de event-log vertrouwen.
Maak tijd en traceerbaarheid niet-onderhandelbaar
Sla timestamps consistent op in UTC. Bewaar ook oorspronkelijke bronidentificatoren (bijv. Jira issue key, ERP order ID) bij work items en events, zodat elke grafiek terug te voeren is op een echt record.
Leg uitzonderingen vast zonder administratieve rompslomp te creëren
Plan lichte velden voor momenten die vertragingen verklaren:
- reason_code (standaardopties zoals “Waiting on customer”)
- comment (optionele tekst)
- blocked_flag of severity
Houd ze optioneel en makkelijk in te vullen, zodat je van uitzonderingen leert zonder de app in een formuliermachine te veranderen.
Kies een architectuur die bij je team past
Maak Vertragingen Actiegericht
Genereer drill-down schermen van KPI-tegels naar exact de vastzittende items.
De “beste” architectuur is degene die je team kan bouwen, begrijpen en jarenlang opereren. Kies een stack die aansluit bij je hiring pool en bestaande vaardigheden — gangbare keuzes zijn React + Node.js, Django of Rails. Consistentie wint van nieuwigheid als je een operations-dashboard runt waarop mensen dagelijks vertrouwen.
Scheid verantwoordelijkheden zodat het systeem bewerkbaar blijft
Een bottleneck-tracking app werkt vaak beter als je het splitst in heldere lagen:
- Ingestion: events ontvangen (statuswijzigingen, timestamps, overdrachten) vanuit formulieren, integraties of imports.
- Storage: een transactionele database voor betrouwbare writes en auditgeschiedenis.
- Analytics queries: read-geoptimaliseerde queries of views om cycle time, queue time en throughput te berekenen.
- UI/API: endpoints en schermen die dashboards snel en voorspelbaar houden.
Deze scheiding laat je één deel wijzigen (bijv. een nieuwe datasource toevoegen) zonder alles te herschrijven.
Beslis waar berekeningen moeten plaatsvinden
Sommige metrics zijn eenvoudig genoeg om in databasequeries te berekenen (bijv. “gemiddelde wachttijd per stap laatste 7 dagen”). Andere zijn zwaar of hebben pre-processing nodig (bijv. percentielen, anomaly-detectie, wekelijkse cohorts). Een praktische regel:
- Doe realtime filters en uitsplitsingen in de database.
- Gebruik background jobs om zware aggregaten voor te rekenen en op te slaan voor snelle dashboardlading.
- Voeg een analyticslaag alleen toe als je team die ook goed kan onderhouden.
Plan vroeg voor performance
Operationele dashboards falen als ze traag aanvoelen. Gebruik indexering op timestamps, workflow step IDs en tenant/team IDs. Voeg paginering toe voor eventlogs. Cache veelgebruikte dashboardweergaven (zoals “vandaag” en “laatste 7 dagen”) en invalideer caches wanneer nieuwe events binnenkomen.
Als je een diepere discussie over trade-offs wilt, houd dan een kort beslissingslogboek in je repo zodat toekomstige wijzigingen niet wegdrijven.
Een snellere route voor teams die snel willen uitrollen
Als je doel is om workflow-analyse en alerting te valideren voordat je een volledige build doet, kan een vibe-coding platform zoals Koder.ai helpen een eerste versie sneller op te zetten: je beschrijft de workflow, entiteiten en dashboards in chat, en iterereert op de gegenereerde React UI en Go + PostgreSQL backend terwijl je KPI-instrumentatie verfijnt.
Het praktische voordeel voor een bottleneck-tracking app is snelheid naar feedback: je kunt ingestion (API pulls, webhooks, of CSV-import) piloten, drill-downs toevoegen en metricdefinities aanpassen zonder weken aan scaffolding. Wanneer je er klaar voor bent ondersteunt Koder.ai ook source code export en deployment/hosting, waardoor de stap van prototype naar een onderhouden intern instrument makkelijker is.
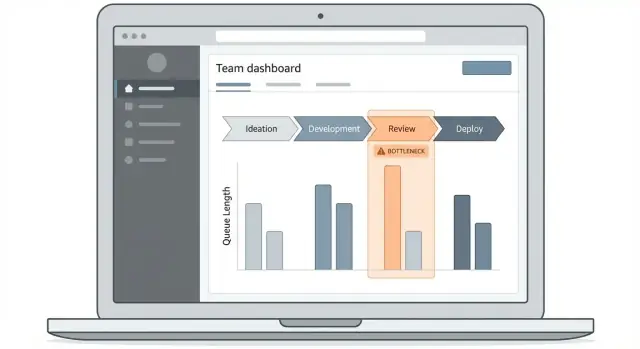
Ontwerp het dashboard en de drill-down ervaring
Een bottleneck-tracking app slaagt of faalt op de vraag of mensen snel kunnen beantwoorden: “Waar loopt het werk nu vast, en welke items veroorzaken het?” Je dashboard moet dat pad duidelijk maken, zelfs voor iemand die maar één keer per week langskomt.
Begin met 2–3 kernschermen
Houd de eerste release compact:
- Overzichtsdashboard: het “statusbord” voor cycle time, queue time en top geblokkeerde stappen.
- Work-itemlijst: een doorzoekbare, filterbare tabel van items die door vertragingen worden beïnvloed.
- Workflow-detail: een stap-voor-stap weergave die tijd per fase en overdrachtspunten toont.
Deze schermen creëren een natuurlijke drill-down flow zonder gebruikers te dwingen een complexe UI te leren.
Gebruik visuals die tijd en flow verklaren
Kies grafiektype die bij operationele vragen passen:
- Stage funnel: toont waar volume zich ophoopt (goed om wachtrijen te spotten).
- Time-in-stage balken: vergelijkt stappen op mediaan- en percentieltijd, niet alleen gemiddelde.
- Trendlijnen: beantwoorden “gaat dit beter of slechter?” over weken.
- Heatmaps: onthullen patronen zoals “maandagen in Review” of “overdrachten tijdens nachtshift.”
Houd labels eenvoudig: “Wachttijd” vs. “Queue latency.”
Maak filters consistent en duidelijk zichtbaar
Gebruik één gedeelde filterbalk over schermen (zelfde locatie, dezelfde defaults): daterange, team, prioriteit en stap. Maak actieve filters zichtbaar als chips zodat mensen de cijfers niet verkeerd interpreteren.
Ontwerp duidelijke drill-down paden
Elke KPI-tegel moet klikbaar zijn en ergens nuttigs naartoe leiden:
KPI → stap → lijst met getroffen items
Voorbeeld: klik op “Langste wachttijd” om het step detail te openen, en met één klik zie je de exacte items die daar momenteel wachten — gesorteerd op leeftijd, prioriteit en eigenaar. Dit verandert nieuwsgierigheid in een concreet takenlijstje, en dat zorgt dat het dashboard gebruikt wordt in plaats van genegeerd.
Voeg alerts en vroegsignalering toe
Houd Volledige Broncontrole
Neem de gegenereerde broncode mee wanneer je klaar bent voor langdurig eigenaarsschap.
Dashboards zijn goed voor reviews, maar knelpunten doen meestal het meeste pijn tussen vergaderingen. Alerts maken je app een vroegwaarschuwingssysteem: je vindt problemen terwijl ze ontstaan, niet nadat de week verloren is.
Begin met duidelijke, saaie regels
Begin met een kleine set alerttypes waar het team het al eens over is dat ze “slecht” zijn:
- Drempeloverschrijdingen: cycle time of queue time boven een bekende limiet (bijv. “Review stap \u003e 24 uur”).
- Abnormale stijgingen: de mediane cycle time van vandaag is 30% hoger dan vorige week.
- Vastgezette items: geen statuswijziging voor N uren/dagen, of items die ouder zijn dan een maximale leeftijd.
Houd de eerste versie simpel. Een paar deterministische regels vangen de meeste problemen en zijn makkelijker te vertrouwen dan complexe modellen.
Voeg lichte anomaliechecks toe
Als drempels stabiel zijn, voeg dan basis “is dit vreemd?” signalen toe:
- Procentuele verandering vs. vorige week (zelfde weekdag vermindert valse meldingen).
- Beweging van het voortschrijdend gemiddelde (bijv. 7-daags gemiddelde stijgt gestaag).
- Volume-ongelijkheden (input stijgt sneller dan output bij een stap).
Maak anomalieën suggesties, geen noodgevallen: label ze als “Heads up” totdat gebruikers bevestigen dat ze nuttig zijn.
Bezorgen waar mensen werken
Ondersteun meerdere kanalen zodat teams kunnen kiezen wat past:
- E-mail voor managers en dagelijkse samenvattingen
- Slack/Microsoft Teams voor real-time triage
- In-app notificaties voor eigenaren binnen de tool
Maak elke alert actiegericht
Een alert moet beantwoorden “wat, waar en wat nu”:
- Welke stap is getroffen, en het tijdvenster
- De belangrijkste oorzaken (bijv. team, categorie, prioriteit)
- Een directe link om te onderzoeken, zoals:
/dashboard?step=review&range=7d&filter=stuck
Als alerts niet leiden tot een concrete volgende stap, dempen mensen ze—behandel alertkwaliteit daarom als een productfeature, niet als extraatje.
Beheer rechten, beveiliging en auditbaarheid
Een bottleneck-tracking app wordt snel een “bron van waarheid.” Dat is geweldig — totdat de verkeerde persoon een definitie wijzigt, gevoelige data exporteert of een dashboard deelt buiten hun team. Rechten en auditsporen zijn geen bureaucratie; ze beschermen het vertrouwen in de cijfers.
Definieer rollen en toegangsregels
Begin met een klein, duidelijk rollenmodel en breid alleen uit als het nodig is:
- Viewer: read-only toegang tot dashboards en rapporten.
- Manager: kan filteren per team, opgeslagen weergaven maken, alerts erkennen en notities toevoegen (maar kan geen globale instellingen wijzigen).
- Admin: beheert procesdefinities, KPI-formules, integraties en gebruikersrechten.
Wees expliciet over wat elke rol kan doen: raw events bekijken vs. geaggregeerde metrics, data exporteren, drempels bewerken en integraties beheren.
Scheid data per team of business unit
Als meerdere teams de app gebruiken, dwing scheiding af op datalaag — niet alleen in de UI. Veelvoorkomende opties:
- Multi-tenant: elk record heeft een
tenant_iden elke query wordt daarop gescopeerd. - Partities/projects: aparte “workspaces” per business unit, met onafhankelijke instellingen en dashboards.
Bepaal vroeg of managers data van andere teams mogen zien. Maak cross-team zichtbaarheid een bewuste permissie, geen default.
Veilige authenticatie (SSO of MFA-klaar)
Als je organisatie SSO (SAML/OIDC) heeft, gebruik dat zodat offboarding en toegangscontrole centraal zijn. Zo niet, implementeer een login die MFA-klaar is (TOTP of passkeys), ondersteunt veilige wachtwoordresets en afdwingt sessie-timeouts.
Maak wijzigingen auditbaar
Log acties die uitkomsten kunnen veranderen of data kunnen blootstellen: exports, drempelwijzigingen, workflow-edits, permissiewijzigingen en integratie-instellingen. Leg vast wie het deed, wanneer, wat er veranderde (voor/na) en waar (workspace/tenant). Bied een “Audit Log” weergave zodat issues snel onderzocht kunnen worden.
Zet inzichten om in acties en procesverbeteringen
Een bottleneck-dashboard telt alleen als het verandert wat mensen daarna doen. Dit deel heeft als doel “interessante grafieken” om te zetten in een herhaalbaar operationeel ritme: beslissen, handelen, meten en behouden wat werkt.
Creëer een lichte bottleneck-review
Stel een eenvoudige wekelijkse cadans in (30–45 minuten) met duidelijke eigenaren. Begin met de top 1–3 knelpunten per impact (bijv. hoogste wachttijd of grootste throughput-daling) en stem af op één actie per knelpunt.
Houd de workflow klein:
- Eigenaar: één verantwoordelijk persoon per actie
- Vervaldatum: standaard bij de volgende review
- Definition of done: een meetbare verandering (niet “meer onderzoeken”)
Leg beslissingen direct in de app vast zodat dashboard en actielog verbonden blijven.
Volg verbeteringen als experimenten
Behandel fixes als experimenten zodat je snel leert en willekeurige optimalisaties voorkomt. Voor elke wijziging registreer je:
- Hypothese (wat vertraagt en waarom)
- Verandering (wat je gaat doen)
- Verwachte impact (welke metric zou bewegen en hoeveel)
- Resultaat (wat er daadwerkelijk gebeurde)
Na verloop van tijd wordt dit een playbook van wat doorlooptijd vermindert, wat rework vermindert en wat niet werkt.
Voeg context toe met annotaties
Grafieken kunnen misleiden zonder context. Voeg eenvoudige annotaties toe op tijdlijnen (bijv. nieuwe medewerker onboarded, systeemstoring, beleidswijziging) zodat kijkers verschuivingen in wachttijd of throughput correct kunnen interpreteren.
Maak delen makkelijk
Bied exportopties voor analyse en rapportage — CSV-downloads en geplande rapporten — zodat teams resultaten in operationele updates en leiderschapsreviews kunnen opnemen. Als je al een rapportagepagina hebt, link er dan naartoe vanuit je dashboard (bijv. /reports).
Zet uit, monitor en houd data fris
Zet Vroege Waarschuwingen Op
Maak eenvoudige drempelregels zodat knelpunten tussen wekelijkse reviews worden opgemerkt.
Een bottleneck-tracking app is alleen nuttig als hij consistent beschikbaar is en de cijfers betrouwbaar blijven. Behandel deployment en dataverversing als productonderdelen, niet als een bijzaak.
Gebruik gescheiden omgevingen en herhaalbare deploys
Zet dev / staging / prod vroeg op. Staging moet productie spiegelen (zelfde database-engine, soortgelijke datavolumes, dezelfde background jobs) zodat je trage queries en gebroken migraties vangt voordat gebruikers ze zien.
Automatiseer deploys met één pipeline: draai tests, pas migraties toe, deploy en voer een korte smoke-check uit (inloggen, dashboard laden, verificatie dat ingestion draait). Houd deploys klein en frequent; dat vermindert risico en maakt rollback realistisch.
Monitor de app en de pipeline
Je wilt monitoring op twee fronten:
- App health: foutpercentages, latency, trage endpoints en trage queries.
- Data health: ingestie-falingen, backlog-grootte en “tijd sinds laatste ontvangen event”.
Waarschuw op symptomen die gebruikers voelen (dashboards time-outs) en op vroege signalen (een groeiende wachtrij van 30 minuten). Volg ook metric-berekeningsfouten — ontbrekende cycle times kunnen eruitzien als “verbetering”.
Houd data fris: late events, correcties en backfills
Operationele data komt laat, out-of-order of wordt gecorrigeerd. Plan voor:
- Idempotente ingestie (het opnieuw verwerken van hetzelfde event verdubbelt niet).
- Backfills voor datumbereiken wanneer een bron uitviel.
- Herberekeningen wanneer referentiegegevens veranderen (bijv. bijgewerkte shiftkalenders).
Definieer wat “fris” betekent (bijv. 95% van events binnen 5 minuten) en toon verversingsstatus in de UI.
Schrijf runbooks zodat fixes geen giswerk zijn
Documenteer stapsgewijze runbooks: hoe je een kapotte sync herstart, KPI’s van gisteren valideert en verifieert dat een backfill historische cijfers niet onverwacht heeft veranderd. Bewaar ze bij het project en link ze vanaf /docs zodat het team snel kan reageren.
Itereer met gebruikers en breid dekking uit
Een bottleneck-tracking app slaagt als mensen hem vertrouwen en daadwerkelijk gebruiken. Dat gebeurt pas nadat je echte gebruikers hebt bekeken die echte vragen proberen te beantwoorden (“Waarom zijn approvals deze week traag?”) en het product scherpt rond die workflows.
Begin met een pilot en leer wat breekt
Start met één pilotteam en een klein aantal workflows. Houd de scope klein genoeg om gebruik te observeren en snel te reageren.
In de eerste week of twee richt je je op wat verwart of ontbreekt:
- Welke grafieken lezen gebruikers verkeerd?
- Waar lopen ze vast bij het drillen?
- Welke data verwachten ze maar vinden ze niet?
- Welke operationele knelpunten voelen voor hen “duidelijk” maar staan niet in de app?
Vang feedback in het hulpmiddel zelf (een eenvoudige “Was dit nuttig?” prompt op sleutelpagina’s werkt goed) zodat je niet op vergadergeheugen hoeft te vertrouwen.
Valideer metrics om “dashboard-discussies” te voorkomen
Voordat je naar meer teams uitrolt, leg definities vast met degenen die er verantwoordelijk voor worden gehouden. Veel rollouts mislukken omdat teams het oneens zijn over wat een metric betekent.
Voor elke KPI (cycle time, queue time, rework rate, SLA-overtredingen) documenteer:
- Exacte start- en eindgebeurtenissen
- Hoe pauzes, weekends en ontbrekende timestamps worden behandeld
- Hoe uitzonderingen worden geteld (annuleringen, escalaties, heropeningen)
Review die definities met gebruikers en voeg korte tooltips in de UI toe. Als je een definitie aanpast, toon dan een duidelijke changelog zodat mensen begrijpen waarom cijfers veranderden.
Breid dekking uit zonder de app rommelig te maken
Voeg features voorzichtig toe en alleen wanneer de workflow-analyses van het pilotteam stabiel zijn. Veelvoorkomende volgende stappen zijn aangepaste stappen (verschillende teams labelen fasen anders), extra bronnen (tickets + CRM + spreadsheets) en geavanceerde segmentatie (per productlijn, regio, prioriteit, klantniveau).
Een nuttige regel: voeg één dimensie tegelijk toe en verifieer dat het beslissingen verbetert, niet alleen rapportage.
Maak onboarding eenvoudig en herhaalbaar
Als je naar meer teams rolt, heb je consistentie nodig. Maak een korte onboardinggids: hoe data te koppelen, hoe het operations-dashboard te interpreteren en hoe te handelen op alerts voor knelpunten.
Link mensen naar relevante pagina’s binnen je product en content, zoals /pricing en /blog, zodat nieuwe gebruikers zichzelf kunnen helpen in plaats van op trainingssessies te wachten.