06 nov 2025·8 min
Hoe je een webapp bouwt voor incidentregistratie en postmortems
Een praktische blauwdruk om een webapp te ontwerpen, bouwen en lanceren voor incidentregistratie en postmortems — van workflows tot datamodellering en UX.
Een praktische blauwdruk om een webapp te ontwerpen, bouwen en lanceren voor incidentregistratie en postmortems — van workflows tot datamodellering en UX.
Voordat je schermen schetst of een database kiest, stem af wat jouw team bedoelt met een incident tracking web app — en wat “postmortem management” moet bereiken. Teams gebruiken vaak dezelfde woorden verschillend: voor de één is een incident elk door een klant gemeld probleem; voor een ander is het alleen een Sev-1-uitval met on-call-escalatie.
Schrijf een korte definitie die antwoord geeft op:
Deze definitie stuurt je incident response workflow en voorkomt dat de app te strikt wordt (niemand gebruikt hem) of te los (data inconsistent).
Bepaal wat een postmortem is binnen je organisatie: een beknopte samenvatting voor elk incident, of een volledige RCA alleen voor hoge-severity events. Maak expliciet of het doel leren, compliance, het verminderen van herhalende incidenten, of alle drie is.
Een handige regel: als je verwacht dat een postmortem tot verandering leidt, moet je tool actiepunten volgen ondersteunen, niet alleen documenten opslaan.
De meeste teams bouwen zo'n app om een klein aantal terugkerende pijnpunten op te lossen:
Houd deze lijst strak. Elke feature die je toevoegt moet ten minste één van deze problemen adresseren.
Kies een paar metrics die je automatisch kunt meten uit het datamodel van je app:
Deze worden je operationele metrics en je “definition of done” voor de eerste release.
Dezelfde app bedient verschillende rollen binnen on-call operaties:
Als je voor iedereen tegelijk ontwerpt, bouw je een rommelige UI. Kies in plaats daarvan een primaire gebruiker voor v1 — en zorg dat de rest later via aangepaste views, dashboards en permissies kan krijgen wat ze nodig hebben.
Een duidelijke workflow voorkomt twee veelvoorkomende faalmodes: incidenten die vastlopen omdat niemand weet “wat is de volgende stap”, en incidenten die “klaar” lijken maar nooit tot leren leiden. Begin met het in kaart brengen van je lifecycle end-to-end en koppel vervolgens rollen en permissies aan elke stap.
De meeste teams volgen een eenvoudige boog: detect → triage → mitigate → resolve → learn. Je app moet dit reflecteren met een beperkt aantal voorspelbare stappen, niet een eindeloos menu aan opties.
Definieer wat “klaar” betekent voor elke fase. Bijvoorbeeld: mitigatie kan betekenen dat klantimpact is gestopt, ook al is de hoofdoorzaak nog onbekend.
Maak rollen expliciet zodat mensen kunnen handelen zonder op vergaderingen te wachten:
Je UI moet de “huidige eigenaar” zichtbaar maken en je workflow moet delegatie ondersteunen (hertoewijzen, responders toevoegen, commander roteren).
Kies vereiste statussen en toegestane transities, zoals Investigating → Mitigated → Resolved. Voeg guardrails toe:
Scheid interne updates (snel, tactisch, kunnen rommelig zijn) van stakeholder-facing updates (duidelijk, tijdgestempeld, gecureerd). Bouw twee update-stromen met verschillende templates, zichtbaarheid en goedkeuringsregels — vaak is de commander de enige die stakeholder-updates publiceert.
Een goede incidenttool voelt “simpel” in de UI omdat het datamodel eronder consistent is. Bepaal voordat je schermen bouwt welke objecten bestaan, hoe ze zich verhouden en wat historisch accuraat moet blijven.
Begin met een kleine set first-class objecten:
De meeste relaties zijn one-to-many:
Gebruik stabiele identifiers (UUIDs) voor incidents en events. Mensen hebben daarnaast een vriendelijk sleutel nodig zoals INC-2025-0042, die je uit een sequentie kunt genereren.
Model deze vroeg zodat je kunt filteren, zoeken en rapporteren:
Incidentdata is gevoelig en wordt vaak later bekeken. Behandel bewerkingen als data — niet als overschrijvingen:
Deze structuur maakt latere features — zoeken, metrics en permissies — veel eenvoudiger te implementeren zonder rework.
Wanneer iets faalt, is de taak van de app typen verminderen en duidelijkheid verhogen. Dit hoofdstuk behandelt het “schrijfpad”: hoe mensen een incident aanmaken, updaten en later reconstrueren wat er gebeurde.
Houd het intakeformulier kort genoeg om af te ronden terwijl je bezig bent met oplossen. Een goed default-set verplichte velden is:
Alles anders optioneel bij aanmaak (impact, klantticketlinks, vermoedelijke oorzaak). Gebruik slimme defaults: zet starttijd op “nu”, preselecteer het on-call team van de gebruiker en bied een één-klik “Create & open incident room” actie.
Je update-UI moet geoptimaliseerd zijn voor herhaalde, kleine bewerkingen. Bied een compact updatepaneel met:
Maak updates append-friendly: elke update wordt een tijdgestempeld item, geen overschrijving van eerdere tekst.
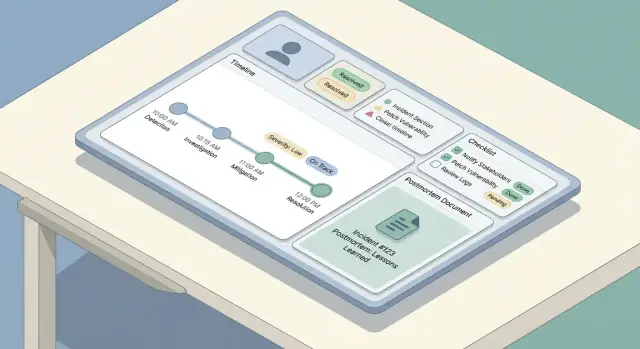
Bouw een tijdlijn die een mix toont van:
Dit creëert een betrouwbaar verhaal zonder mensen te dwingen elke klik vast te leggen.
Tijdens een outage gebeuren veel updates vanaf een telefoon. Prioriteer een snel, laagdrempelig scherm: grote touchtargets, één scrollpagina, offlinevriendelijke drafts en één-klikacties zoals “Post update” en “Kopieer incidentlink”.
Severity is de “snelkeuze” van incidentrespons: het vertelt mensen hoe urgent te handelen, hoe breed te communiceren en welke afwegingen acceptabel zijn.
Vermijd vage labels zoals “hoog/middel/laag.” Laat elk severityniveau duidelijke operationele verwachtingen bevatten — vooral responstijd en communicatiecadans.
Bijvoorbeeld:
Maak deze regels zichtbaar in de UI waar severity wordt gekozen, zodat responders de docs niet hoeven te doorzoeken.
Checklists verminderen cognitieve belasting onder stress. Houd ze kort, actiegericht en gekoppeld aan rollen.
Een bruikbaar patroon heeft een paar secties:
Maak checklistitems tijdgestempeld en toewijsbaar zodat ze onderdeel van het incidentrecord worden.
Incidenten leven zelden in één tool. Je app moet responders links laten toevoegen naar:
Geef de voorkeur aan “getypeerde” links (bijv. Runbook, Ticket) zodat ze later gefilterd kunnen worden.
Als je org betrouwbaarheidsdoelen bijhoudt, voeg dan lichte velden toe zoals SLO affected (yes/no), geschat error budget burn en klant SLA-risico. Houd ze optioneel — maar makkelijk in te vullen tijdens of direct na het incident, wanneer details vers zijn.
Een goede postmortem is makkelijk te starten, moeilijk te vergeten en consistent tussen teams. De simpelste manier is een standaardtemplate (met minimale verplichte velden) en automatisch invullen vanuit het incidentrecord zodat mensen tijd besteden aan nadenken, niet aan overtypen.
Je ingebouwde template moet structuur en flexibiliteit balanceren:
Maak “Root cause” optioneel in eerste instantie als je sneller publiceren wilt, maar vereis het voor definitieve goedkeuring.
De postmortem moet geen los zwevend document zijn. Wanneer een postmortem wordt aangemaakt, koppel automatisch:
Gebruik deze om postmortem-secties voor te vullen. Bijvoorbeeld: het blok “Impact” kan beginnen met start/eindtijden en huidige severity, terwijl “Wat we deden” entries uit de tijdlijn kan halen.
Voeg een lichte workflow toe zodat postmortems niet blijven liggen:
Leg bij elke stap beslissingsnotities vast: wat is veranderd, waarom en wie heeft het goedgekeurd. Dit voorkomt “stille bewerkingen” en vergemakkelijkt latere audits of leerreviews.
Als je de UI simpel wilt houden, behandel reviews als opmerkingen met expliciete uitkomsten (Approve / Request changes) en bewaar de definitieve goedkeuring als onveranderlijk record.
Voor teams die het nodig hebben, koppel “Published” aan je statusupdates-workflow (zie /blog/integrations-status-updates) zonder inhoud handmatig te kopiëren.
Postmortems verminderen toekomstige incidenten alleen als opvolgingswerk daadwerkelijk gebeurt. Behandel actiepunten als first-class objecten in je app — niet als een alinea onderaan een document.
Elk actiepunt moet consistente velden hebben zodat het gevolgd en gemeten kan worden:
Voeg nuttige metadata toe: tags (bijv. “monitoring”, “docs”), component/service en “created from” (incident ID en postmortem ID).
Vang actiepunten niet alleen in één postmortempagina. Bied:
Dit verandert opvolging in een operationele queue in plaats van versnipperde notities.
Sommige taken herhalen zich (kwartaal-oefeningen, runbookreviews). Ondersteun een recurring template die nieuwe items volgens schema genereert, terwijl elke keer afzonderlijk traceerbaar blijft.
Als teams al een andere tracker gebruiken, laat een actiepunt een externe referentielink en extern ID bevatten, terwijl je app de bron blijft voor incidentkoppeling en verificatie.
Bouw lichte nudges: waarschuw eigenaren als deadlines naderen, markeer achterstallige items voor een teamlead en toon structureel achterstallige patronen in rapporten. Houd regels configureerbaar zodat teams ze kunnen afstemmen op hun on-call-operaties en werkdruk.
Incidenten en postmortems bevatten vaak gevoelige details — klantidentificaties, interne IP's, beveiligingsbevindingen of leveranciersproblemen. Duidelijke toegangsregels houden het hulpmiddel bruikbaar voor samenwerking zonder dat het een datalek wordt.
Begin met een klein, begrijpelijk aantal rollen:
Als je meerdere teams hebt, overweeg rollen te scopen per service/team (bijv. “Payments Editors”) in plaats van brede globale toegang.
Classificeer content vroeg, voordat mensen gewoontes vormen:
Een praktisch patroon is secties als Intern of Deelbaar te markeren en dit af te dwingen bij exports en statuspagina's. Security-incidenten kunnen een apart incidenttype met strengere defaults nodig hebben.
Voor elke wijziging aan incidenten en postmortems, registreer: wie het veranderde, wat veranderde en wanneer. Neem wijzigingen in severity, tijdstempels, impact en definitieve goedkeuringen op. Maak auditlogs doorzoekbaar en niet-bewerkbaar.
Ondersteun sterke auth standaard: e-mail + MFA of magic link, en voeg SSO (SAML/OIDC) toe als gebruikers dit verwachten. Gebruik kortlopende sessies, secure cookies, CSRF-bescherming en automatische sessie-revocation bij rolwijzigingen. Voor meer roll-out-overwegingen, zie /blog/testing-rollout-continuous-improvement.
Wanneer een incident actief is, scannen mensen — ze lezen niet. Je UX moet de huidige staat in seconden duidelijk maken, terwijl responders ook diep in details kunnen duiken zonder de weg kwijt te raken.
Begin met drie schermen die de meeste workflows dekken:
Een simpele regel: de incidentdetailpagina moet bovenaan antwoorden op “Wat gebeurt er nu?” en daaronder “Hoe zijn we hier gekomen?”.
Incidenten stapelen zich snel op, dus maak ontdekken snel en vergevingsgezind:
Bied opgeslagen views zoals Mijn open incidenten of Sev-1 deze week zodat on-call engineers niet elke shift filters hoeven opnieuw te bouwen.
Gebruik consistente, kleurveilige badges door de hele app (vermijd subtiele tinten die onder stress slecht zichtbaar zijn). Houd overal dezelfde statusvocabulaire: lijst, detailheader en tijdlijnitems.
In één oogopslag moeten responders zien:
Geef prioriteit aan scanbaarheid:
Ontwerp voor het slechtste moment: als iemand slaapgebrek heeft en met de telefoon paget, moet de UI nog steeds snel naar de juiste actie leiden.
Integraties maken van een incidenttracker geen “plek om notities te schrijven” maar het systeem waarin je team daadwerkelijk incidenten runt. Begin met het opsommen van systemen die je moet koppelen: monitoring/observability (PagerDuty/Opsgenie, Datadog, CloudWatch), chat (Slack/Teams), e-mail, ticketing (Jira/ServiceNow) en een statuspagina.
De meeste teams eindigen met een mix:
Alerts zijn lawaaierig, worden opnieuw geprobeerd en komen vaak buiten volgorde binnen. Definieer een stabiele idempotency key per provider-event (bijv. provider + alert_id + occurrence_id), en sla die op met een unieke constraint. Voor deduplicatie kun je regels hanteren zoals “zelfde service +zelfde signature binnen 15 minuten” voegt toe aan een bestaand incident in plaats van een nieuw incident te maken.
Wees expliciet over wat jouw app beheert versus wat in de bron-tool blijft:
Wanneer een integratie faalt, degradeer gracieus: rij retries in, toon een waarschuwing op het incident (“Slack-posting vertraagd”) en laat operators altijd handmatig doorgaan.
Behandel statusupdates als een eersteklas output: een gestructureerde “Update”-actie in de UI moet naar chat kunnen publiceren, toevoegen aan de tijdlijn en optioneel synchroniseren met de statuspagina — zonder dat de responder hetzelfde bericht drie keer hoeft te schrijven.
Je incidenttool draait tijdens storingen, dus geef de voorkeur aan eenvoud en betrouwbaarheid boven nieuwigheid. De beste stack is meestal die je team kan bouwen, debuggen en beheren om 02:00 met vertrouwen.
Begin met wat je engineers al in productie shippen. Een mainstream webframework (Rails, Django, Laravel, Spring, Express/Nest, ASP.NET) is meestal veiliger dan een gloednieuw framework dat maar één persoon begrijpt.
Voor opslag past een relationele database (PostgreSQL/MySQL) goed bij incidentrecords: incidents, updates, deelnemers, actiepunten en postmortems profiteren van transacties en duidelijke relaties. Voeg Redis alleen toe als je echt caching, queues of tijdelijke locks nodig hebt.
Hosting kan zo simpel zijn als een managed platform (Render/Fly/Heroku-achtig) of je bestaande cloud (AWS/GCP/Azure). Geef de voorkeur aan managed databases en backups indien mogelijk.
Actieve incidenten voelen beter met real-time updates, maar je hebt niet altijd websockets nodig op dag één.
Een praktische aanpak: ontwerp API/events zodat je kunt starten met polling en later naar websockets upgraden zonder de UI te herschrijven.
Als deze app faalt tijdens een incident, wordt hij deel van het incident. Voeg toe:
Behandel dit als een productiesysteem:
Als je de workflow en schermen wilt valideren voordat je veel bouwt, werkt een vibe-coding-aanpak goed: gebruik een tool zoals Koder.ai om een werkend prototype te genereren vanuit een gedetailleerde chatspecificatie, en iterereer met responders tijdens tabletop-oefeningen. Omdat Koder.ai echte React-frontends met een Go + PostgreSQL-backend kan produceren (en source-export ondersteunt), kun je vroege versies als ‘wegwerp-prototypes’ behandelen of als basis die je team kan hardenen — zonder de leerpunten te verliezen die uit echte simulaties kwamen.
Een incidenttracking-app uitrollen zonder repetities is een gok. De beste teams behandelen het hulpmiddel als elk ander operationeel systeem: test kritieke paden, voer realistische drills uit, rol geleidelijk uit en blijf tunen op basis van echt gebruik.
Focus eerst op de flows die mensen onder hoge stress nodig hebben:
Voeg regressietests toe die cruciale zaken valideren: timestamps, tijdzones en event-volgorde. Incidenten zijn verhalen — als de tijdlijn niet klopt, verdwijnt vertrouwen.
Permissiefouten zijn operationele en security-risico's. Schrijf tests die aantonen:
Test ook ‘near misses’, zoals een gebruiker die midden in een incident toegang verliest of een teamreorganisatie die groepslidmaatschap verandert.
Voer vóór brede uitrol tabletop-simulaties uit waarbij je app de bron van waarheid is. Kies herkenbare scenario's (bijv. gedeeltelijke outage, datavertraging, derde-partij-faal). Let op frictie: verwarrende velden, ontbrekende context, te veel klikken, onduidelijk eigenaarschap.
Leg feedback direct vast en vertaal die naar kleine, snelle verbeteringen.
Begin met één pilotteam en een paar vooraf gebouwde sjablonen (incidenttypes, checklists, postmortemformaten). Bied korte training en een één-pagina “hoe we incidenten draaien” gids gelinkt vanuit de app (bijv. /docs/incident-process).
Volg adoptatiemetrics en iterereer op friction points: tijd-tot-creatie, % incidenten met updates, postmortem-completionrate en sluitingstijd van actiepunten. Behandel deze als productmetrics — niet als compliance-only metrics — en blijf verbeteren bij elke release.
Begin met het opstellen van een concrete definitie waar je organisatie het over eens is:
Die definitie moet rechtstreeks naar je workflowstatussen en verplichte velden wijzen, zodat gegevens consistent blijven zonder te zwaar te worden.
Behandel postmortems als een workflow, niet als een statisch document:
Als je verandering verwacht, heb je actiepunttracking en herinneringen nodig — niet alleen opslag.
Een praktisch v1-pakket:
Sla geavanceerde automatisering over totdat deze workflows betrouwbaar werken onder stress.
Gebruik een klein aantal voorspelbare stadia die aansluiten op hoe teams echt werken:
Definieer “klaar” voor elk stadium en voeg guardrails toe:
Dit voorkomt vastgelopen incidenten en verbetert latere analyses.
Model een paar duidelijke rollen en koppel die aan permissies:
Maak de huidige eigenaar/commander onmiskenbaar in de UI en ondersteun delegatie (herverdelen, commander roteren).
Houd het datamodel klein maar gestructureerd:
Gebruik stabiele identifiers (UUIDs) plus een mensvriendelijke sleutel (bijv. INC-2025-0042). Behandel bewerkingen als geschiedenis met created_at/created_by en een auditlog voor wijzigingen.
Scheid stromen en pas verschillende regels toe:
Implementeer verschillende templates/zichtbaarheden en sla beide op in het incidentrecord zodat je beslissingen later kunt reconstrueren zonder gevoelige details te lekken.
Definieer severityniveaus met expliciete verwachtingen (responsurgentie en communicatiecadans). Bijvoorbeeld:
Toon de regels in de UI waar severity gekozen wordt zodat responders niet in documentatie hoeven te zoeken tijdens een outage.
Behandel actiepunten als gestructureerde records, geen vrije tekst:
Bied daarna globale weergaven (overdue, binnenkort, per owner/service) en lichte herinneringen/escalatie zodat opvolging niet verdwijnt na de review.
Gebruik provider-specifieke idempotency keys en dedup-regels:
provider + alert_id + occurrence_idLaat altijd handmatige koppeling toe als API's of integraties falen.