26 jul 2025·8 min
Hoe je een webapp bouwt om uitzonderingen in bedrijfsprocessen bij te houden
Leer stap voor stap hoe je een webapp ontwerpt en bouwt die bedrijfsprocesuitzonderingen registreert, routet en oplost met duidelijke workflows en rapportage.
Wat bedrijfsprocesuitzonderingen zijn (en waarom je ze moet bijhouden)
Een bedrijfsprocesuitzondering is alles wat het “happy path” van een routinewerkstroom doorbreekt—een gebeurtenis die menselijke aandacht vereist omdat de standaardregels het niet afdekken, of omdat er iets misging.
Zie uitzonderingen als de operationele tegenhanger van “edge cases”, maar dan voor alledaags zakelijk werk.
Herkenbare voorbeelden
Uitzonderingen komen bijna in elke afdeling voor:
- Factuurafwijking: het factuurtotaal komt niet overeen met de inkooporder, aantallen verschillen of een regel ontbreekt.
- Ontbrekende goedkeuring: een contract wordt uitgevoerd zonder de juiste handtekening, of een uitgave wordt ingediend boven een limiet zonder goedkeuring.
- Vertraagde verzending: levering is de beloofde datum gemist, een gedeeltelijke zending arriveerde, of de verkeerde SKU werd verzonden.
Dit zijn geen “zeldzaamheden”. Ze komen veel voor—en veroorzaken vertragingen, extra werk en frustratie als je geen duidelijke manier hebt om ze vast te leggen en op te lossen.
Waarom spreadsheets en e-maildraadjes falen
Veel teams beginnen met een gedeelde spreadsheet plus e-mails of chatberichten. Het werkt—tot het niet meer werkt.
Een spreadsheetrij kan je vertellen wat er gebeurde, maar vaak gaat de rest verloren:
- Verloren context: belangrijke details zitten in inboxen (screenshots, leveranciersantwoorden, goedkeuringen), niet gekoppeld aan het record.
- Geen duidelijke eigenaar: mensen gaan ervan uit dat iemand anders het oppakt, vooral wanneer uitzonderingen teams overstijgen.
- Zwakke geschiedenis: het is moeilijk te zien wie wat en waarom heeft gewijzigd, wat belangrijk is als later vragen ontstaan.
Na verloop van tijd wordt de spreadsheet een mengelmoes van gedeeltelijke updates, dubbele vermeldingen en ‘status’-velden die niemand vertrouwt.
Wat je wint door uitzonderingen goed bij te houden
Een eenvoudige exception tracking-app (een incident-/issueregister toegespitst op je proces) levert meteen operationele waarde op:
- Snellere oplossing: de juiste persoon krijgt een melding, ondersteunende info blijft bij de uitzondering en de status is zichtbaar.
- Minder herhaling: patronen komen naar voren (zelfde leverancier,zelfde stap,zelfde goedkeuringskloof), zodat je de oorzaak kunt verhelpen.
- Duidelijke verantwoordelijkheid: elke uitzondering heeft een eigenaar, due dates (SLA/targets) en een gedocumenteerde uitkomst.
Stel verwachtingen: begin eenvoudig en iterer
Je hoeft op dag één geen perfecte workflow te hebben. Begin met het vastleggen van de basis—wat er gebeurde, wie het eigenaar is, huidige status en volgende stap—and ontwikkel daarna je velden, routing en rapportage terwijl je leert welke uitzonderingen terugkeren en welke gegevens daadwerkelijk beslissingen sturen.
Bepaal gebruikers, scope en succesmetrics
Voordat je schermen schetst of tools kiest, wees glashelder over wie de app bedient, wat versie 1 dekt en hoe je weet dat het werkt. Dit voorkomt dat een “exception tracking app” verandert in een generiek ticketsysteem.
Identificeer de primaire rollen
De meeste exception-workflows hebben een handvol duidelijke actoren nodig:
- Aanmelder (Requester): legt de uitzondering vast en geeft context (wat gebeurde, wanneer, impact).
- Goedkeurder (Approver): beslist of een uitzondering acceptabel is en onder welke voorwaarden.
- Oplosser (Resolver): repareert het probleem, voert de tijdelijke oplossing uit of werkt gegevens bij.
- Proces-eigenaar: verantwoordelijk voor het onderliggende proces en preventieve acties.
- Auditor/viewer: leesrechten voor toezicht en nalevingscontroles.
Voor elke rol noteer je 2–3 kernpermissies (maken, goedkeuren, her toewijzen, sluiten, exporteren) en de beslissingen waarvoor ze verantwoordelijk zijn.
Verduidelijk de doelen
Houd doelen praktisch en observeerbaar. Veelvoorkomende doelen zijn:
- Uitzonderingen consistent vastleggen (steeds dezelfde minimale gegevens).
- Duidelijke eigenaarschap toewijzen zodat niets blijft liggen.
- Beslissingen documenteren (waarom een uitzondering is goedgekeurd/afgewezen, door wie).
- Herhaling verminderen door root cause en preventieve maatregelen te volgen.
Bepaal wat in scope is voor v1
Kies 1–2 workflows met veel volume waar uitzonderingen vaak voorkomen en de kosten van vertraging echt gevoeld worden (bijv. factuurafwijkingen, orderholds, onboarding met ontbrekende documenten). Begin niet met “alle bedrijfsprocessen.” Een beperkte scope stelt je in staat categorieën, statussen en goedkeuringsregels snel te standaardiseren.
Schrijf 3–5 succesmetrics
Definieer metrics die je vanaf dag één kunt meten:
- Tijd tot oplossing (mediaan, en % binnen SLA)
- Heropeningspercentage (kwaliteit van sluiting)
- Uitzonderingsvolume per type (top-drivers)
- Doorlooptijd van goedkeuring (aanvraag → beslissing)
- Herhaalde uitzonderingen gelinkt aan dezelfde root cause
Deze metrics vormen je basislijn voor iteratie en rechtvaardigen toekomstige automatisering.
Map de lifecycle van de uitzondering en statussen
Een duidelijke lifecycle zorgt dat iedereen weet waar een uitzondering zich bevindt, wie eigenaar is en wat de volgende stap moet zijn. Houd statussen beperkt, ondubbelzinnig en gekoppeld aan echte acties.
Een praktische standaardlifecycle
Created → Triage → Review → Decision → Resolution → Closed
- Created: Er wordt een uitzondering aangemaakt met de minimale vereiste details.
- Triage: Iemand valideert, wijst eigendom toe en bepaalt urgentie.
- Review: Het juiste team verzamelt bewijs en evalueert opties.
- Decision: Keur de uitzondering goed/af (of vraag wijzigingen) met een vastgelegde motivatie.
- Resolution: De corrigerende actie wordt uitgevoerd en geverifieerd.
- Closed: Het record is gefinaliseerd voor rapportage en audit.
Definieer “klaar” met entry/exit-criteria
Schrijf op wat waar moet zijn om elk stadium te betreden en te verlaten:
- Created (exit): Vereiste velden ingevuld; categorie geselecteerd; aanmelder geïdentificeerd.
- Triage (exit): Eigenaar toegewezen; impact + due date ingesteld; duplicaten gecontroleerd.
- Review (exit): Bewijs toegevoegd; stakeholders geraadpleegd; aanbeveling gedocumenteerd.
- Decision (exit): Beslissing vastgelegd; goedkeurder geïdentificeerd; eventuele voorwaarden vastgelegd.
- Resolution (exit): Acties voltooid; uitkomst gevalideerd; SLA gehaald of reden voor breach gelogd.
- Closed (exit): Laatste notities toegevoegd; geen open taken; audittrail compleet.
Escalatieregels die stagnatie voorkomen
Voeg automatische escalatie toe wanneer een uitzondering overdue is (voorbij due date/SLA), geblokkeerd is (te lang wachtend op externe afhankelijkheid), of hoog impact heeft (boven severity-drempel). Escalatie kan betekenen: manager waarschuwen, naar hoger goedkeuringsniveau routen, of prioriteit verhogen.
Heropenen en duplicaatafhandeling
- Heropenen wanneer dezelfde uitzondering terugkomt (bijv. fix is mislukt). Vereis een reden en stuur het terug naar Triage of Review.
- Duplicaat wanneer twee records hetzelfde onderliggende probleem beschrijven. Markeer er één als “primair”, link de duplicaten en sluit duplicaten met de uitkomst “Merged” zodat rapportage accuraat blijft.
Ontwerp het datamodel en vereiste velden
Een goede exception tracking-app staat of valt met het datamodel. Als je structuur te los is, wordt rapportage onbetrouwbaar. Als je het te sterk structureert, vullen gebruikers de velden niet consistent in. Streef naar een klein aantal verplichte velden en een grotere set optionele, duidelijk gedefinieerde velden.
Kernentiteiten om op te nemen
Begin met een paar kernrecords die de meeste scenario's dekken:
- Exception: het hoofdrecord (wat gebeurde, waar en wat moet opgelost worden).
- Comment: discussie, verduidelijkingen en voortgangsupdates.
- Attachment: screenshots, PDF's, e-mails, exports.
- Task: discrete acties toegewezen aan specifieke eigenaren.
- Decision: goedkeuringen/afwijzingen, beleidsuitzonderingen of sluitingsbesluiten.
- Category: een gecontroleerde lijst die rapportage schoon houdt.
- User: aanmelders, toegewezenen, goedkeurders en kijkers.
Verplichte velden (houd het kort)
Maak het volgende verplicht op elke Exception:
- Titel en beschrijving (in gewone taal: wat gebeurde en waarom het belangrijk is)
- Categorie
- Impact (bijv. financieel, klant, compliance, operationeel)
- Procesgebied (bijv. facturatie, fulfillment, retouren)
- Vervaldatum (of streefdatum voor oplossing)
Gestructureerde waarden die je moet standaardiseren
Gebruik gecontroleerde waarden in plaats van vrije tekst voor:
- Status (Created, Triage, Review, Decision, Resolution, Closed)
- Prioriteit (Laag/Middel/Hoog/Dringend)
- Root cause (Menselijke fout, systeemdefect, ontbrekende data, leverancier, onduidelijk beleid)
- Resolutietype (Gegevens gecorrigeerd, terugbetaling, workaround, proces aangepast, training, geen actie)
Koppelingen en traceerbaarheid
Plan velden om uitzonderingen te koppelen aan echte bedrijfsobjecten:
- Referenties van getroffen records (Order-ID, factuur-ID, klant-ID)
- Externe systeem-ID's (ERP-ticket, CRM-zaak)
- Gerelateerde uitzonderingen (duplicaten, terugkerende patronen, parent/child)
Deze koppelingen maken het makkelijker om herhaalde issues te zien en later nauwkeurige rapportage op te bouwen.
Plan de gebruikerservaring en kernschermen
Een goede exception tracking-app voelt als een gedeelde inbox: iedereen ziet snel wat aandacht vereist, wat geblokkeerd is en wat overdue is. Begin met het ontwerpen van een klein aantal schermen die 90% van het dagelijkse werk dekken, voeg later power-features toe (gevorderde rapportage, integraties).
Kernschermen om eerst te ontwerpen
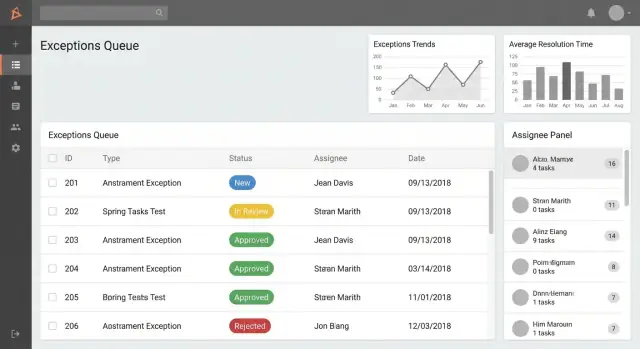
1) Uitzonderingslijst / wachtrij (home screen)
Hier werken gebruikers het meest. Maak het snel, scanbaar en actiegericht.
Maak rolgebaseerde wachtrijen zoals:
- Mijn uitzonderingen (aangemaakt door of toegewezen aan mij)
- Wacht op mijn goedkeuring (items die op een beslissing wachten)
- Overdue (voorbij SLA of streefdatum)
Voeg zoeken en filters toe die overeenkomen met hoe mensen over werk praten:
- Status, categorie, procesgebied
- Datumbereik (aangemaakt, vervaldatum, gesloten)
- Toegewezen / team
2) Formulier om uitzondering aan te maken
Houd de eerste stap lichtgewicht: een paar verplichte velden, met optionele details onder “Meer”. Overweeg concepten op te slaan en “onbekend” waarden toe te staan (bijv. “assignee TBD”) om omzeilingen te voorkomen.
3) Detailpagina van uitzondering
Dit moet beantwoorden: “Wat gebeurde er? Wat is de volgende stap? Wie is eigenaar?” Voeg toe:
- Samenvatting, status, eigenaar/toegewezen, vervaldatum/SLA
- Duidelijke primaire acties (Toewijzen, Vraag goedkeuring, Sluiten)
- Een zijpaneel voor belangrijke metadata
Samenwerking (zonder dat het chat wordt)
Neem op:
- Opmerkingen met @mentions om de juiste mensen erbij te halen
- Bijlagen als bewijs (screenshots, PDF's)
- Een activiteitstijdlijn die wijzigingen vastlegt (statusupdates, her-toewijzing, goedkeuringen) zodat gebruikers niet hoeven te vragen “wie dit heeft aangepast?”
Admin-instellingen (minimaal maar noodzakelijk)
Voorzie een kleine admin-ruimte om categorieën, procesgebieden, SLA-targets en notificatieregels te beheren—zodat operationele teams de app kunnen aanpassen zonder een redeploy.
Kies een technische aanpak en architectuur
Exporteer je broncode
Exporteer React-, Go- en PostgreSQL-code wanneer je diepere aanpassing of nieuwe hosting nodig hebt.
Hier balanceer je snelheid, flexibiliteit en lange-termijn onderhoudbaarheid. Het “juiste” antwoord hangt af van hoe complex je exception-lifecycle is, hoeveel teams de tool gebruiken en hoe streng je audit-eisen zijn.
Drie praktische bouwbenaderingen
1) Custom build (volledige controle). Je bouwt UI, API, database en integraties vanaf nul. Dit werkt goed als je op maat gemaakte workflows nodig hebt (routing, SLA's, audittrail, ERP/ticket-integraties) en verwacht dat het proces evolueert. Het nadeel is hogere initiële kosten en voortdurende engineering-support.
2) Low-code (snelst te lanceren). Interne app-builders kunnen formulieren, tabellen en eenvoudige goedkeuringen snel neerzetten. Ideaal voor een pilot of single-department rollout. Nadeel: limieten op complexe permissies, aangepaste rapportage, schaalprestaties of dataportabiliteit.
3) Vibe-coding / agent-assisted build (snelle iteratie met echte code). Als je snelheid wilt zonder je codebasis op te geven, kan een platform als Koder.ai helpen om een werkende webapp te maken vanuit een chat-gestuurd specificatie—en daarna de broncode te exporteren wanneer je volledige controle nodig hebt. Teams gebruiken het vaak om snel een React UI en een Go + PostgreSQL backend te genereren, itereren in “planning mode” en vertrouwen op snapshots/rollback terwijl de workflow stabiliseert.
Een eenvoudige, schaalbare architectuur
Streef naar een duidelijke scheiding van verantwoordelijkheden:
- Web UI voor gebruikers om uitzonderingen te indienen, beoordelen en oplossen
- API die validatie, permissies en workflowregels afdwingt
- Database die uitzonderingen, opmerkingen, bijlagenmeta, beslissingen, taken en audit-events opslaat
- Background jobs voor notificaties, escalaties, SLA-timers en geplande rapporten
Deze opzet blijft begrijpelijk naarmate de app groeit en maakt integraties later eenvoudiger.
Hosting en omgevingen
Plan minimaal dev → staging → prod. Staging moet prod weerspiegelen (vooral auth en e-mail) zodat je routing, SLA's en rapportage veilig kunt testen voor release.
Als je vroege ops-overhead wilt verminderen, overweeg een platform dat deployment en hosting out-of-the-box aanbiedt (Koder.ai, bijvoorbeeld, ondersteunt deployment/hosting, custom domains en wereldwijde AWS-regio's)—en kies later voor een eigen setup als de workflow bewezen is.
Kosten- en complexiteitstrade-offs
Low-code verkort time-to-first-version, maar aanpassing en compliance-eisen kunnen later de kosten verhogen (workarounds, add-ons, vendorlimieten). Custom builds kosten meer aanvankelijk, maar kunnen op termijn goedkoper zijn als exception handling kern voor de operatie is. Een middenweg—snel uitbrengen, de workflow valideren en een duidelijke migratie-route (bijv. via code-export)—biedt vaak de beste verhouding tussen kosten en controle.
Stel authenticatie, rollen en toegangscontrole in
Uitzonderingsrecords bevatten vaak gevoelige details (klantnamen, financiële correcties, beleidsinbreuken). Als toegang te ruim is, riskeer je privacyproblemen en “schaduwwijzigingen” die het vertrouwen in het systeem ondermijnen.
Aanmelden en veilige sessies
Begin met bewezen authenticatie in plaats van zelf wachtwoorden bouwen. Als je organisatie al een identity provider heeft, gebruik SSO (SAML/OIDC) zodat gebruikers inloggen met hun werkaccount en je bestaande controles zoals MFA en account-offboarding overneemt.
Ongeacht SSO of e-mail-login: behandel sessiebeheer als een first-class feature: kortdurende sessies, secure cookies, CSRF-bescherming voor browserapps en automatische uitlog voor inactieve, risicovolle rollen. Log ook authenticatiegebeurtenissen (login, logout, mislukte pogingen) om ongebruikelijke activiteiten te onderzoeken.
Rollen en permissies (wat kan wie doen)
Definieer rollen in gewone zakelijke termen en koppel ze aan acties in de app. Een typische start:
- Aanmelder/Reporter: maakt uitzonderingen aan, voegt notities/bijlagen toe, ziet eigen items
- Assignee/Resolver: bewerkt velden, stelt oplossing voor, werkt status bij
- Approver/Manager: keurt goed of wijst af, vraagt extra info, sluit items
- Admin: configureert het systeem (niet dagelijkse verwerking)
Wees expliciet over wie kan verwijderen. Veel teams schakelen harde verwijdering uit en laten alleen admins archiveren, zodat geschiedenis behouden blijft.
Toegang per record (wie ziet welke uitzonderingen)
Naast rollen, voeg regels toe die zichtbaarheid beperken op basis van afdeling, team, locatie of procesgebied. Veelvoorkomende patronen:
- Gebruikers zien items die ze zelf hebben aangemaakt plus items toegewezen aan hun team
- Managers zien alle items binnen hun organisatie-eenheid
- Compliance/audit-rollen zien alles, read-only
Dit voorkomt “open bladeren” terwijl samenwerking toch mogelijk blijft.
Admin-mogelijkheden die nodig zijn
Admins moeten categorieën en subcategorieën kunnen beheren, SLA-regels (due dates, escalatiedrempels), notificatiesjablonen en gebruikersrol-toewijzingen. Houd admin-acties auditbaar en vereis verhoogde bevestiging voor impactvolle veranderingen (zoals SLA-wijzigingen), omdat deze instellingen rapportage en verantwoordelijkheid beïnvloeden.
Bouw workflows, routing en notificaties
Stel SLA-escalaties in
Prototypeer overdue regels en notificaties, verfijn ze daarna als exceptionpatronen duidelijk worden.
Workflows maken van een simpele ‘log’ een exception tracking-app waar mensen op kunnen vertrouwen. Het doel is voorspelbare voortgang: elke uitzondering heeft een duidelijke eigenaar, volgende stap en deadline.
Routingregels: wie krijgt wat en wanneer
Begin met een klein aantal routingregels die makkelijk uit te leggen zijn. Je kunt routen op:
- Categorie (bijv. datakwaliteit, beleidsafwijking, systeemuitval)
- Impact (financieel bedrag, aantal klanten, severity)
- Procesgebied (AP/AR, onboarding, fulfillment)
- Drempels (bijv. “Bedrag > $10.000” of “Hoge severity”)
Houd regels deterministisch: als meerdere regels matchen, definieer een prioriteitsvolgorde. Voeg ook een veilige fallback toe (bijv. routeer naar een “Exception Triage” wachtrij) zodat niets onassigned blijft.
Goedkeuringen: simpel, meerstaps en overrides
Veel uitzonderingen hebben een goedkeuring nodig voordat ze worden geaccepteerd, verholpen of gesloten.
Ontwerp voor twee veelvoorkomende patronen:
- Enkele goedkeurder: één persoon keurt goed/af (snelst om te implementeren).
- Meerstapsgoedkeuring: een volgorde zoals Manager → Compliance → Finance.
Wees duidelijk over wie mag overrulen (en onder welke omstandigheden). Als overrides toegestaan zijn, eis een reden en registreer deze in de audittrail (bijv. “Overruled vanwege SLA-risico”).
Notificaties die geen ruis veroorzaken
Voeg e-mail- en in-app notificaties toe voor momenten die eigenaarschap of urgentie veranderen:
- Toewijzing en her-toewijzing
- Nieuwe opmerkingen of mentions
- Goedkeuring aangevraagd / goedgekeurd / afgewezen
- Overdue items en “verloopt binnenkort” herinneringen
Laat gebruikers optionele notificaties beheren, maar houd kritieke meldingen (toewijzing, overdue) standaard aan.
Maak oplossingswerk zichtbaar met taken/checklists
Uitzonderingen falen vaak omdat werk “ernaast” gebeurt. Voeg lichte taken of checklists toe gekoppeld aan de uitzondering: elke taak heeft een eigenaar, vervaldatum en status. Dit maakt voortgang traceerbaar, verbetert overdrachten en geeft managers realtime zicht op wat een sluiting blokkeert.
Voeg rapportage en operationele dashboards toe
Rapportage is waar een exception tracking-app stopt met een “register” en verandert in een operationeel hulpmiddel. Het doel is leiders patronen vroeg te laten zien en teams te helpen beslissen wat ze als volgende moeten aanpakken—zonder elk record te hoeven openen.
Standaardrapporten om op te nemen
Begin met een kleine set rapporten die veelgestelde vragen betrouwbaar beantwoorden:
- Volume over tijd (dagelijks/wekelijks/maandelijks): nemen uitzonderingen toe, af of zijn ze seizoensgebonden?
- Per categorie/oorzaak: welke typen uitzonderingen veroorzaken de meeste verstoring?
- Per team/eigenaar: waar concentreert de werkdruk zich?
- Per status: hoeveel zit in elk stadium (Created, Triage, Review, Decision, Resolution, Closed)?
Houd grafieken simpel (lijn voor trends, staaf voor verdelingen). De waarde zit in consistentie—gebruikers moeten erop vertrouwen dat het rapport overeenkomt met wat ze in de uitzonderingslijst zien.
Prestaties en SLA-tracking
Voeg operationele metrics toe die de gezondheid van de service reflecteren:
- Gemiddelde resolutietijd (en mediaan als mogelijk)
- SLA-breach rate (% uitzonderingen die het target overschrijden)
- Backlog-grootte (open uitzonderingen) en aging (hoe lang items openstaan)
Als je timestamps zoals created_at, assigned_at en resolved_at opslaat, worden deze metrics eenvoudig en uitlegbaar.
Drill-down, exports en geplande samenvattingen
Elke grafiek moet drill-down ondersteunen: klikken op een staaf of segment brengt de gebruiker naar de gefilterde uitzonderingslijst (bijv. “Categorie = Shipping, Status = Open”). Dit houdt dashboards actiegericht.
Voor delen en offline analyse, bied CSV-export vanuit zowel de lijst als belangrijke rapporten. Als stakeholders regelmatige zichtbaarheid willen, voeg geplande samenvattingen toe (wekelijkse e-mail of in-app digest) die trendveranderingen, topcategorieën en SLA-breaches highlighten, met verwijzingen terug naar de gefilterde weergaven (bijv. /exceptions?status=open&category=shipping).
Zorg voor auditbaarheid en basiscompliance
Als je exception tracking-app goedkeuringen, betalingen, klantuitkomsten of wettelijke rapportage beïnvloedt, moet je uiteindelijk het antwoord op “Wie deed wat, wanneer en waarom?” kunnen geven. Auditbaarheid vanaf dag één voorkomt lastige retrofits en geeft teams vertrouwen dat het record betrouwbaar is.
Leg een onbetwistbare activity log vast
Maak een complete activiteitlog voor elk uitzonderingrecord. Log de actor (gebruiker of systeem), timestamp (met tijdzone), actietype (aangemaakt, veld gewijzigd, statusovergang) en de before/after waarden.
Houd de log append-only. Wijzigingen voegen nieuwe events toe in plaats van historie te overschrijven. Moet je iets corrigeren, registreer dan een “correctie”-event met uitleg.
Sla beslissingen op met redenen en bewijs
Goedkeuringen en afwijzingen moeten als volwaardige events worden vastgelegd, niet alleen als statuswijziging. Leg vast:
- Beslissing (goedgekeurd/afgewezen/teruggestuurd)
- Redencode + vrije-tekstvoeging (verplicht voor sleutelbeslissingen)
- Bijlagen (screenshots, PDF's, e-mails) en wie ze uploadde
Dit versnelt reviews en vermindert gedoe als iemand vraagt waarom een uitzondering is geaccepteerd.
Retentie- en verwijderregels (bewust instellen)
Bepaal hoelang uitzonderingen, bijlagen en logs worden bewaard. Voor veel organisaties is een veilige standaard:
- Bewaar records en audit-events voor een vaste periode (bijv. 3–7 jaar)
- Beperk verwijderen tot een kleine groep admins, met verplichte motivatie
- Geef de voorkeur aan “soft delete” (verborgen voor normale weergaven) terwijl de audittrail intact blijft
Stem het beleid af op interne governance en eventuele wettelijke vereisten.
Ontwerp voor reviews en audits
Auditors en compliance reviewers willen snelheid en duidelijkheid. Voeg filters toe specifiek voor reviewwerk: op datumbereik, eigenaar/team, status, reason codes, SLA-breach en goedkeuringsuitkomsten.
Bied printvriendelijke samenvattingen en exporteerbare rapporten die de onveranderlijke geschiedenis bevatten (tijdlijn van events, beslissingsnotities en lijst met bijlagen). Een goede vuistregel: als je het volledige verhaal niet uit het record en de log kunt reconstrueren, is het systeem niet audit-ready.
Test, pilot en rol uit
Bouw een Exception Tracker
Bouw je exception tracker in Koder.ai vanaf een simpele chat en iterer veilig.
Testen en uitrollen is waar een exception tracking-app stopt met een “goed idee” en begint met een betrouwbaar hulpmiddel te worden. Focus op de paar flows die elke dag gebeuren, en breid dan uit.
Test de belangrijkste flows end-to-end
Maak een simpel testscript (een spreadsheet is prima) dat de volledige lifecycle doorloopt:
- Maak een uitzondering aan, voeg een bestand toe en bevestig dat verplichte velden worden afgedwongen.
- Wijs het toe aan de juiste persoon/team en verifieer dat zij het direct kunnen zien.
- Goedkeur- en afwijsroutes: zorg dat elke beslissing een reden en timestamp vastlegt.
- Sluit de uitzondering en controleer dat het read-only (of beperkt-bewerkbaar) wordt zoals bedoeld.
- Heropen en controleer dat geschiedenis/audittrail duidelijk toont wat veranderde.
Neem variaties uit het echte leven op: prioriteitswijzigingen, her-toewijzingen en overdue items zodat je SLA- en resolutietijdberekeningen kunt verifiëren.
Voeg validatie en foutafhandeling toe die slechte data voorkomt
De meeste rapportageproblemen komen door inconsistente invoer. Voeg vroegtijdig guardrails toe:
- Verplichte velden (bv. procesgebied, uitzonderingstype, eigenaar, vervaldatum).
- Limieten voor bestandupload (grootte/type) met duidelijke foutmeldingen.
- Detectie van duplicaten (bijv. zelfde klant/order/datum) met een optie “link aan bestaand”.
- Veilige afhandeling van randgevallen: ontbrekende assignee, ongeldige data, verwijderde gebruikers.
Test ook ongunstige paden: netwerkonderbrekingen, verlopen sessies en permissiefouten.
Voer een pilot uit met één team eerst
Kies een team met voldoende volume om snel te leren, maar klein genoeg om snel aan te passen. Pilot 2–4 weken, en evalueer daarna:
- Vangen de velden op wat mensen echt nodig hebben?
- Komen statussen overeen met hoe werk gebeurt?
- Zijn notificaties nuttig of juist storend?
Voer wekelijks wijzigingen door, maar vries de workflow in voor de laatste week om te stabiliseren.
Rol uit met een lichtgewicht launch-kit
Houd de uitrol simpel:
- Een één-pagina “Hoe gebruiken wij de app” handleiding (stati, eigendomsregels, SLA's).
- Een korte trainingssessie (15–30 minuten) plus opname.
- Een launch-checklist: toegang/rollen, standaardrouting, sjablonen en een supportcontact.
Na lancering monitor je adoptie en backloggezondheid dagelijks in de eerste week, daarna wekelijks.
Onderhoud, verbeter en schaal op over tijd
Het uitbrengen van de app is het begin van het echte werk: het register nauwkeurig, snel en in lijn houden met hoe de organisatie daadwerkelijk werkt.
Monitor gebruik en knelpunten
Behandel je exception-flow als een operationele pijplijn. Bekijk waar items blijven liggen (per status, team en eigenaar), welke categorieën domineren en of SLA's realistisch zijn.
Een eenvoudige maandelijkse check is vaak genoeg:
- Mediaan en 90e percentiel resolutietijden per categorie
- “Aging” aantallen (bijv. open > 7/30/60 dagen)
- Heropeningspercentages en “teruggestuurde” loops
- Top velden die leeg blijven (signaal voor UX-wrijving)
Gebruik deze bevindingen om statussen, verplichte velden en routingregels bij te stellen—zonder constant complexiteit toe te voegen.
Houd een iteratiebacklog bij
Maak een lichte backlog voor verzoeken van operators, goedkeuringverleners en compliance. Typische items:
- Nieuwe velden (alleen als rapportage of beslissingen ze echt nodig hebben)
- Automatiseringen (auto-toewijzen op basis van categorie, default due-dates)
- Sjablonen voor veelvoorkomende uitzonderingstypes
- Kleine UI-fixes die verkeerd classificeren verminderen
Prioriteer veranderingen die doorlooptijd verkorten of terugkerende uitzonderingen voorkomen.
Integraties: begin veilig, verdiep later
Integraties kunnen veel waarde toevoegen, maar verhogen ook risico en onderhoud. Begin met read-only koppelingen:
- Sla externe record-ID's op (ERP/CRM/ticketing)
- Deep-link naar het bronsysteem (bijv. order, klant, factuur)
Als het stabiel is, ga naar selectieve write-backs (statusupdates, opmerkingen) en event-based synchronisatie.
Stel duidelijke eigenaarschap vast
Wijs eigenaren aan voor de onderdelen die het meest veranderen:
- Categorie-taxonomie (en wanneer te mergen/uit te faseren)
- SLA-definities en escalatieregels
- Workflow/routingregels en notificatiebeleid
Als eigenaarschap expliciet is, blijft de app betrouwbaar als volume groeit en teams reorganiseren.
Een opmerking over hoge build-snelheid
Exception tracking is zelden “klaar”—het evolueert terwijl teams leren wat voorkomen, automatiseren of escaleren moet worden. Als je frequente workflowwijzigingen verwacht, kies dan een aanpak die iteratie veilig maakt (feature flags, staging, rollback) en houdt je in controle over code en data. Platforms zoals Koder.ai worden hier vaak gebruikt om snel een eerste versie te leveren (Free/Pro tiers zijn genoeg voor pilots) en kunnen opschalen naar Business/Enterprise wanneer governance, toegangscontrole en deployment-eisen strenger worden.