23 sep 2025·8 min
ZSTD vs Brotli vs GZIP: API-compressie kiezen
Vergelijk ZSTD, Brotli en GZIP voor API's: snelheid, ratio, CPU-kosten en praktische defaults voor JSON en binaire payloads in productie.
Wat API-compressie is (en wanneer het de moeite waard is)
API-responscompressie betekent dat je server de response-body (vaak JSON) encodeert naar een kleinere byte-stroom voordat die over het netwerk wordt verzonden. De client (browser, mobiele app, SDK of een andere service) decomprimeert die vervolgens. Over HTTP wordt dit onderhandeld via headers zoals Accept-Encoding (wat de client ondersteunt) en Content-Encoding (wat de server gekozen heeft).
Wat het oplevert voor API's
Compressie levert vooral drie dingen op:
- Minder bandbreedte: Kleinere responses gebruiken minder bytes end-to-end.
- Lagere latency op beperkte verbindingen: Minder bytes betekent vaak snellere downloads op mobiel, druk wifi en cross-region oproepen.
- Lagere egress-kosten: Als je betaalt voor uitgaande data, kan het verkleinen van transfers direct je kosten verlagen.
De afweging is eenvoudig: compressie bespaart bandbreedte maar kost CPU (compressie/decompressie) en soms geheugen (buffers). Of het de moeite waard is hangt af van je bottleneck.
Wanneer compressie het meest helpt
Compressie presteert goed wanneer responses:
- Tekstrijk en repetitief zijn, zoals JSON, GraphQL-responses, HTML of logs.
- Middelgroot tot groot zijn, waarbij tientallen of honderden kilobytes verschil uitmaken.
- Geserveerd worden over trage of dure netwerken, bijvoorbeeld mobiel, internationaal, of cross-region verkeer.
Als je grote JSON-lijsten retourneert (catalogi, zoekresultaten, analytics) is compressie vaak één van de makkelijkste winstpunten.
Wanneer het het minst helpt
Compressie is vaak een slechte besteding van CPU wanneer responses:
- Klein zijn (bijvoorbeeld enkele honderden bytes). Header- + CPU-overhead kunnen de besparing overstijgen.
- Al gecomprimeerd zijn (JPEG/PNG, MP4, ZIP, veel PDFs). Opnieuw comprimeren levert meestal weinig op en kan de grootte zelfs vergroten.
- CPU-bound diensten zijn (hot endpoints met veel rekenwerk). Compressie kan tail-latency vergroten.
De beslissing-aspecten die je door dit artikel heen zult gebruiken
Bij het kiezen tussen ZSTD vs Brotli vs GZIP voor API-compressie komt het praktisch neer op:
- Groottevermindering (compressieratio)
- Latentie (server time-to-first-byte plus client decode)
- Client-ondersteuning (wat je oproepers en tussenlagen betrouwbaar verwerken)
Alles in dit artikel draait om het balanceren van die drie voor jouw specifieke API en verkeerspatronen.
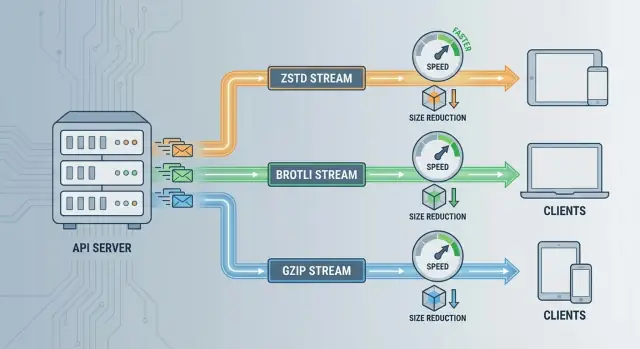
ZSTD vs Brotli vs GZIP: Korte vergelijking
Alle drie verkleinen payloads, maar ze optimaliseren voor verschillende beperkingen—snelheid, compressieratio en compatibiliteit.
Kort overzicht
- ZSTD (Zstandard): Vaak de beste balans voor API's wanneer je geeft om lage latency en voorspelbare CPU. Sterke ratio zonder traag te zijn.
- Brotli: Vaak winnaar op minimale bytes over het netwerk, vooral voor tekst-zware responses (JSON, HTML-achtige content). Hogere instellingen kosten vaak meer CPU.
- GZIP: De “werkt overal” optie. Breed ondersteund en eenvoudig te operationaliseren, maar meestal trager en/of groter dan moderne alternatieven bij vergelijkbaar CPU-budget.
Typische sterktes (en wat dat betekent voor API's)
ZSTD snelheid: Geweldig wanneer je API gevoelig is voor tail-latency of je servers CPU-beperkt zijn. Het kan snel genoeg comprimeren dat de overhead vaak te verwaarlozen is vergeleken met netwerktijd—vooral bij medium-tot-grote JSON-responses.
Brotli compressieratio: Beste keuze wanneer bandbreedte de primaire beperking is (mobiele clients, dure egress, CDN-rijke levering) en responses voornamelijk tekst zijn. Kleinere payloads kunnen de extra compressietijd waard zijn.
GZIP compatibiliteit: Beste keuze wanneer je maximale client-ondersteuning nodig hebt met minimaal onderhandelingsrisico (oudere SDK's, embedded clients, legacy-proxies). Het is een veilige basis, ook al is het niet de top-performer.
Wat "compressieniveau" echt verandert
Compressie-“niveaus” zijn presets die CPU-tijd ruilen voor kleinere output:
- Lagere niveaus: Snellere compressie, grotere payloads. Goed voor real-time API's.
- Hogere niveaus: Kleinere payloads, tragere compressie (en soms meer geheugen). Beter voor grote, cachebare responses.
Decompressie is meestal veel goedkoper dan compressie voor alle drie, maar zeer hoge niveaus kunnen nog steeds client-CPU/batterij verhogen—belangrijk voor mobiel.
Eenvoudige vuistregel
- Standaardkeuze: Gebruik ZSTD voor de meeste JSON/REST/GraphQL API's waar latency telt.
- Schakel over naar Brotli: Wanneer je optimaliseert voor minimale bytes (tekst-zware responses, CDN-levering, trage netwerken) en je extra CPU kunt veroorloven.
- Blijf bij GZIP: Wanneer je brede compatibiliteit nodig hebt of je infrastructuur/tools nieuwere encodings niet ondersteunen.
Compressieratio vs Latentie: De kernafweging
Compressie wordt vaak verkocht als “kleinere responses = snellere API's.” Dat geldt vaak op trage of dure netwerken—maar het is niet automatisch. Als compressie genoeg server-CPU-tijd toevoegt, kun je snellere requests verliezen ondanks minder bytes op het netwerk.
Waar de tijd naartoe gaat
Het helpt om twee kosten los te zien:
- Compressietijd (server-side): werk dat gedaan wordt voordat de server bytes kan beginnen te sturen. Dit kan direct bijdragen aan responstijd (TTFB).
- Decompressietijd (client-side): werk dat gedaan wordt nadat bytes ontvangen zijn. Meestal goedkoper dan compressie, maar relevant op low-power devices of high-throughput clients.
Een hoge compressieratio kan transfertijd verminderen, maar als compressie bijvoorbeeld 15–30 ms CPU per response toevoegt, win je die tijd wellicht niet terug—vooral bij snelle verbindingen.
De tail-latency val onder load
Onder load kan compressie p95/p99 latency meer schaden dan p50. Wanneer CPU-gebruik piekt, rijzen verzoeken. Queueing vergroot kleine per-request kosten tot grote vertragingen—gemiddelde latency ziet er goed uit, maar de traagste gebruikers lijden.
Meet het als een performance-feature
Raadpleeg geen gok. Voer A/B-tests of staged rollouts uit en vergelijk:
- p50 en p95 latency (en bij voorkeur p99)
- CPU-gebruik en saturatie op API-instanties
- Responsegroottes en time-to-first-byte
Test met realistische verkeerspatronen en payloads. Het “beste” compressieniveau is degene die totale tijd vermindert, niet alleen bytes.
CPU- en geheugen-kosten op server en client
Compressie is niet “gratis”—het verplaatst werk van het netwerk naar CPU en geheugen aan beide zijden. In API's uit zich dat als hogere request-afhandelingstijd, grotere geheugenfootprints en soms client-side vertragingen.
Waar de CPU naartoe gaat
Het grootste deel van de CPU wordt besteed aan compressie van responses. Compressie zoekt patronen, bouwt state/dictionary en schrijft gecodeerde output.
Decompressie is meestal goedkoper, maar nog steeds relevant:
- Servers kunnen requests de-comprimeren (zelden voor JSON-API's, vaker bij uploads of gebatchte events).
- Clients de-comprimeren responses op het kritieke pad voordat ze JSON parsen.
Als je API al CPU-bound is (drukke app-servers, zware auth, dure queries), kan een hoog compressieniveau tail-latentie vergroten, ook al krimpen payloads.
Geheugenoverwegingen
Compressie kan geheugengebruik verhogen op een paar manieren:
- Buffers: implementaties hebben mogelijk input/output-buffers nodig; grotere payloads betekenen grotere buffers.
- Volledige buffering vs streaming: streaming-compressie kan eerder beginnen met sturen en houdt het geheugenplafond vlakker, terwijl volledige buffering de piekgeheugen per request kan opblazen.
In container-omgevingen kan hoger piekgeheugen leiden tot OOM-kills of strakkere limits die densiteit verminderen.
Impact op autoscaling en container-limieten
Compressie voegt CPU-cycli per response toe, waardoor de throughput per instantie daalt. Dat kan autoscaling eerder triggeren en de kosten verhogen. Een veelvoorkomend patroon: bandbreedte daalt, maar CPU-gebruik stijgt—dus de juiste keuze hangt af van welke resource bij jou schaars is.
Waarom decompressiesnelheid belangrijk is voor clients
Op mobiel of low-power devices concurreert decompressie met rendering, JavaScript-executie en batterijverbruik. Een formaat dat een paar KB bespaart maar langer duurt om te decompresseren kan langzamer aanvoelen, vooral wanneer “time to usable data” telt.
ZSTD voor API's: sterktes, limieten en goede defaults
Zstandard (ZSTD) is een modern compressieformaat ontworpen om sterke compressieratio te leveren zonder je API te vertragen. Voor veel JSON-zware API's is het een sterke “default”: merkbaar kleinere responses dan GZIP bij vergelijkbare of lagere latency, plus extreem snelle decompressie op clients.
Waar ZSTD het beste in is
ZSTD is het meest waardevol wanneer je geeft om end-to-end tijd, niet alleen om de kleinste bytes. Het comprimeert vaak snel en decompresseert extreem snel—handig voor API's waar elke milliseconde CPU-tijd concurreert met request-afhandeling.
Het presteert ook goed over een breed scala aan payloadgroottes: klein-tot-medium JSON ziet vaak zinvolle winst, terwijl grote responses nog meer kunnen profiteren.
Verstandige compressieniveaus voor API's
Voor de meeste API's begin je met lage niveaus (meestal niveau 1–3). Die geven vaak de beste trade-off tussen latency en grootte.
Gebruik hogere niveaus alleen wanneer:
- Payloads groot zijn (honderden KB tot MB)
- Bandbreedte duur of beperkt is
- Je hebt gemeten dat CPU geen bottleneck is
Een pragmatische aanpak is een laag globaal default, en selectief het niveau verhogen voor een paar “grote response” endpoints.
Streaming en dictionary-modus
ZSTD ondersteunt streaming, wat piekgeheugen kan verminderen en eerder verzenden mogelijk maakt voor grote responses.
Dictionary-modus kan veel opleveren voor API's die veel vergelijkbare objecten teruggeven (herhaalde keys, stabiele schema's). Het is het meest effectief wanneer:
- Payloads relatief klein maar frequent zijn
- Je versiebeheer voor dictionaries veilig kunt managen
Compatibiliteitslimieten om op te letten
Server-side ondersteuning is in veel stacks eenvoudig, maar client-compatibiliteit kan de doorslag geven. Sommige HTTP-clients, proxies en gateways adverteren of accepteren Content-Encoding: zstd niet standaard.
Als je third-party consumers bedient, houd een fallback (meestal GZIP) en schakel ZSTD alleen in wanneer Accept-Encoding het duidelijk aangeeft.
Brotli voor API's: wanneer het wint en wanneer niet
Test grootte-drempels
Genereer list-heavy endpoints en valideer drempels zodat je geen CPU verspilt aan kleine responses.
Brotli is ontworpen om tekst extreem goed te comprimeren. Op JSON, HTML en andere “woordrijke” payloads verslaat het vaak GZIP qua compressieratio—vooral bij hogere compressieniveaus.
Waar Brotli wint
Tekst-zware responses zijn het sterke punt van Brotli. Als je API grote JSON-documenten verzendt (catalogi, zoekresultaten, configuratie-blobs), kan Brotli bytes merkbaar reduceren, wat helpt op trage netwerken en egress-kosten kan verlagen.
Brotli is ook sterk wanneer je eenmaal comprimeert en veel serveert (cachebare responses, geversioneerde resources). In die gevallen kunnen hoge Brotli-niveaus de CPU-kosten rechtvaardigen omdat die over veel verzoeken worden uitgesmeerd.
Waar Brotli teleurstelt
Voor dynamische API-responses (op elk verzoek gegenereerd) vereisen Brotli's beste ratio's vaak hogere niveaus die CPU-intensief en latentieverhogend kunnen zijn. Zodra je compressietijd meerekent, kan de praktische winst over ZSTD (of zelfs goed ingestelde GZIP) kleiner zijn dan verwacht.
Het is ook minder aantrekkelijk voor payloads die slecht comprimeren (al-gecomprimeerde data, veel binaire formaten). Dan verbrand je alleen maar CPU.
Praktische niveaugids
- Runtime-compressie: gebruik lage niveaus (meestal 1–4) om CPU-pieken te vermijden.
- Vooraf gecomprimeerd/static: hogere niveaus (vaak 8–11) kunnen de moeite waard zijn wanneer de kosten over veel hits worden uitgesmeerd.
Client-ondersteuning
Browsers ondersteunen Brotli over HTTPS goed, wat het populair maakt voor webverkeer. Voor niet-browser API-clients (mobiele SDK's, IoT-apparaten, oudere HTTP-stacks) kan de ondersteuning inconsistent zijn—onderhandel dus correct via Accept-Encoding en houd een fallback (typisch GZIP).
GZIP voor API's: compatibiliteit en praktische prestatie
GZIP blijft de standaardkeuze voor API-compressie omdat het het meest universeel ondersteunde formaat is. Vrijwel elke HTTP-client, browser, proxy en gateway begrijpt Content-Encoding: gzip, en die voorspelbaarheid telt wanneer je niet volledig controle hebt over de tussenlagen.
Waarom het nog steeds veel gebruikt wordt
Het voordeel is niet dat GZIP “beste” is—maar dat het zelden de verkeerde keuze is. Veel organisaties hebben jaren operationele ervaring ermee, webservers hebben er standaard goede defaults voor, en er zijn minder verrassingen met tussenlagen die nieuwere encodings mogelijk verkeerd behandelen.
Praktische compressieniveaus voor API's
Voor API-payloads (vaak JSON) zijn mid-tot-lage compressieniveaus vaak de beste keuze. Niveaus zoals 1–6 geven meestal het grootste deel van de groottevermindering terwijl CPU redelijk blijft.
Zeer hoge niveaus (8–9) persen er nog wat extra uit, maar de extra CPU-tijd is het meestal niet waard voor dynamisch request/response verkeer waar latency telt.
Hoe het zich verhoudt op moderne CPU's
Op moderne hardware is GZIP doorgaans trager dan ZSTD bij vergelijkbare compressieratio's, en het kan vaak niet Grotte van Brotli's beste ratio's bij tekst matchen. In echte API-workloads betekent dat meestal:
- ZSTD wint vaak op snelheid-per-bespaarde-byte.
- Brotli kan winnen op grootte voor zeer compressibele tekst, maar kost mogelijk meer CPU afhankelijk van instellingen.
- GZIP blijft concurrerend omdat het “snel genoeg” is en breed geoptimaliseerd over stacks.
Compatibiliteits-edgecases (oude clients en tussenlagen)
Als je oudere clients, embedded devices, strikte corporate proxies of legacy gateways moet ondersteunen, is GZIP de veiligste keuze. Sommige tussenlagen zullen onbekende encodings verwijderen, niet doorgeven of onderhandelingsfouten veroorzaken—problemen die veel minder vaak voorkomen met GZIP.
Als je omgeving gemengd of onzeker is, begin met GZIP (en voeg ZSTD/Brotli alleen toe waar je het volledige pad controleert) als meest betrouwbare uitrolstrategie.
Payloadtypes: wat goed comprimeert (en wat niet)
Probeer een veilige uitrol
Rol zstd veilig uit met een canary en houd gzip als fallback voor oudere clients.
Compressiewinsten gaan niet alleen over het algoritme. De grootste factor is het soort data dat je verzendt. Sommige payloads krimpen dramatisch met ZSTD, Brotli of GZIP; andere bewegen nauwelijks en verbranden alleen CPU.
Geweldige kandidaten (hoge opbrengst)
Tekst-zware responses comprimeren buitengewoon goed omdat ze herhaalde keys, whitespace en voorspelbare patronen bevatten.
- JSON (inclusief typische REST-responses)
- GraphQL-responses (vaak woordrijk met herhaalde veldnamen)
- XML en HTML
- Grote platte tekst-logs en error traces die door API's worden teruggegeven
Hoe meer herhaling en structuur, hoe beter de compressieratio doorgaans is.
Binaire payloads: “misschien” (meet eerst)
Binaire formaten zoals Protocol Buffers en MessagePack zijn compacter dan JSON, maar niet “random”. Ze kunnen nog steeds herhaalde tags, gelijke record-layouts en voorspelbare sequenties bevatten.
Dat betekent dat ze vaak nog wel comprimeerbaar zijn, vooral voor grotere responses of list-rijke endpoints. Het enige betrouwbare antwoord is meten met je echte verkeer: dezelfde endpoint, dezelfde data, compressie aan/uit, en vergelijk zowel grootte als latency.
Meestal niet de moeite (al gecomprimeerd)
Veel formaten zijn intern al gecomprimeerd. HTTP-response-compressie erop toepassen levert doorgaans weinig besparing en kan responstijd vergroten.
- Afbeeldingen: JPEG, PNG, WebP
- Video/audio: MP4 (en soortgelijke)
- Archieven: ZIP, gz
- PDF: vaak al gecomprimeerd
Voor deze formaten is het gebruikelijk compressie per content-type uit te schakelen.
Praktische heuristieken (houd het simpel)
Een eenvoudige aanpak is alleen comprimeren wanneer responses een minimale grootte overschrijden.
- Stel een minimum response size threshold in (bijvoorbeeld een paar KB) voordat
Content-Encodingwordt ingeschakeld. - Compress grote tekst-responses altijd; overweeg compressie over te slaan voor kleine JSON waar headers domineren.
Dit houdt CPU gericht op payloads waar compressie echt bandbreedte bespaart en end-to-end prestaties verbetert.
HTTP-headers en onderhandelen: doe het goed
Compressie werkt alleen soepel wanneer clients en servers het eens zijn over een encoding. Die overeenkomst gebeurt via Accept-Encoding (door de client gestuurd) en Content-Encoding (door de server gestuurd).
Accept-Encoding en Content-Encoding (simpele voorbeelden)
Een client geeft aan wat hij kan decoderen:
GET /v1/orders HTTP/1.1
Host: api.example
Accept-Encoding: zstd, br, gzip
De server kiest er één en verklaart wat gebruikt is:
HTTP/1.1 200 OK
Content-Type: application/json
Content-Encoding: zstd
Als de client Accept-Encoding: gzip stuurt en je antwoordt met Content-Encoding: br, kan die client de body niet juist parsen. Als de client geen Accept-Encoding stuurt, is de veiligste default om geen compressie te sturen.
Kies een server-side prioriteitsvolgorde
Een praktische volgorde voor API's is vaak:
zstdeerst (goede snelheid/ratio balans)- dan
br(vaak kleiner, soms trager) - dan
gzip(grootste compatibiliteit)
Met andere woorden: zstd > br > gzip.
Behandel dit niet als universeel: als je verkeer vooral browsers is, verdient br mogelijk een hogere prioriteit; als je veel oudere mobiele clients hebt, is gzip misschien de veiligste “beste” keuze.
Vary: Accept-Encoding en caching
Als een response in meerdere encodings geserveerd kan worden, voeg dan toe:
Vary: Accept-Encoding
Zonder die header kan een CDN of proxy de gzip (of zstd) versie cachen en die verkeerdelijk serveren aan een client die die encoding niet vroeg of niet ondersteunt.
Edge-cases en veilige fallbacks
Sommige clients claimen ondersteuning maar hebben buggy decoders. Om veerkrachtig te blijven:
- Geef prioriteit aan een bekende fallback: als decode-fouten voor
zstdstijgen, val tijdelijk terug opgzip. - Overweeg allowlists voor problematische user agents of SDK-versies.
- Voor kritieke endpoints (auth, webhooks) overweeg compressie uit te schakelen of alleen de meest compatibele optie te gebruiken.
Onderhandeling gaat minder over elk byte maximaliseren en meer over nooit een client breken.
HTTP/2, HTTP/3, CDNs en gateways
API-compressie draait niet in isolatie. Je transportprotocol, TLS-overhead en elke CDN of gateway ertussen kunnen het echte resultaat veranderen—of zelfs dingen breken als verkeerd geconfigureerd.
HTTP/2 en HTTP/3: multiplexing, head-of-line en wat compressie verandert
Met HTTP/2 delen meerdere requests één TCP-verbinding. Dat vermindert connection-overhead, maar packet loss kan alle streams blokkeren door TCP head-of-line blocking. Compressie kan helpen door response-bodies te verkleinen, waardoor er minder data achter een verliesgeval vastzit.
HTTP/3 draait over QUIC (UDP) en vermijdt TCP-level head-of-line blocking tussen streams. Grootte van payloads blijft belangrijk, maar het verliesstrafje per verbinding is vaak minder dramatisch. In de praktijk blijft compressie waardevol—de voordelen tonen zich meer in bandbreedtebesparing en snellere “time to last byte” dan in dramatische latency-dalingen.
TLS-interactie: negeer CPU-budgets niet
TLS kost al CPU (handshakes, encryptie/decryptie). Extra compressie (vooral op hoge niveaus) kan je over CPU-limieten duwen tijdens pieken. Daarom presteren "snelle compressie met redelijke ratio" instellingen vaak beter in productie dan "maximale ratio".
CDNs en API-gateways: automatisch comprimeren, doorgeven of verwijderen
Sommige CDNs/gateways comprimeren automatisch bepaalde MIME-types, terwijl anderen precies doorgeven wat de origin stuurt. Een paar kunnen Content-Encoding normaliseren of zelfs verwijderen als ze verkeerd geconfigureerd zijn.
Verifieer gedrag per route en zorg dat Vary: Accept-Encoding behouden blijft zodat caches geen gecomprimeerde variant serveren aan clients die dat niet vroegen.
Cachingstrategie: edge vs origin (en meerdere varianten)
Als je op de edge cachet, overweeg aparte varianten per encoding (gzip/br/zstd) op te slaan in plaats van bij elke hit opnieuw te comprimeren. Als je op origin cachet, wil je misschien dat de edge onderhandelt en meerdere encodings cachet.
Het sleutelwoord is consistentie: correcte Content-Encoding, correcte Vary, en duidelijke verantwoordelijkheid voor waar compressie plaatsvindt.
Aanbevolen defaults en tuning-playbook
Houd rollback gereed
Gebruik snapshots en rollback om compressiewijzigingen terug te draaien zonder stressvolle incidenten.
Voorgestelde defaults per scenario
Voor browser-facing API's, geef de voorkeur aan Brotli wanneer de client het adverteert (Accept-Encoding: br). Browsers decoderen Brotli doorgaans efficiënt en het levert vaak betere grootte-reductie voor tekst-responses.
Voor interne service-to-service API's, gebruik ZSTD wanneer beide kanten onder jouw controle zijn. Het is typisch sneller bij vergelijkbare of betere ratio's dan GZIP en de onderhandeling is eenvoudig.
Voor publieke API's gebruikt door diverse SDK's, houd GZIP als universele baseline en voeg optioneel ZSTD toe als opt-in voor clients die het expliciet ondersteunen. Zo voorkom je dat oudere HTTP-stacks breken.
Voorzichtige startniveaus
Begin met niveaus die makkelijk te meten zijn en niet zullen verrassen:
- Brotli: niveau 4–6 voor dynamische API-responses (hogere niveaus kunnen merkbare server-CPU kosten)
- ZSTD: niveau 3–5 voor algemene API-payloads
- GZIP: niveau 5–6 (hogere niveaus leveren vaak weinig extra op)
Als je een sterkere ratio nodig hebt, valideer met productie-achtige payloadsamples en volg p95/p99 latency voordat je verhoogt.
Minimum size thresholds (en tuning)
Compressie van piepkleine responses kan meer CPU kosten dan het oplevert op het netwerk. Een praktisch startpunt:
- Compress niet onder 1–2 KB voor de meeste API's
- Overweeg 4 KB als je CPU-bound bent of responses al klein en chatty zijn
Tweak door te vergelijken: (1) bespaarde bytes, (2) toegevoegde servertijd, (3) end-to-end latency-verandering.
Veilige manieren om controls bloot te stellen
Rol compressie uit achter een feature flag, voeg daarna per-route config toe (aan voor /v1/search, uit voor al-kleine endpoints). Bied een client opt-out via Accept-Encoding: identity voor troubleshooting en edge-clients. Voeg altijd Vary: Accept-Encoding toe om caches correct te houden.
Waar dit naar voren komt in moderne build-and-ship workflows
Als je snel API's genereert (bijv. React-frontends met Go + PostgreSQL backends en iteratie op basis van echt verkeer), wordt compressie een van die “kleine config, grote impact” knoppen.
Op Koder.ai bereiken teams dit punt vaak eerder omdat ze snel full-stack apps kunnen prototypen en deployen, en daarna productiegedrag (inclusief response-compressie en cache-headers) tunen zodra endpoints en payloadvormen stabiel zijn. De praktische les is: behandel compressie als een performance-feature, zet het achter een vlag en meet p95/p99 voordat je het als opgelost bestempelt.
Uitrollen, monitoren en troubleshooting
Compressiewijzigingen zijn makkelijk te deployen en verrassend makkelijk fout te doen. Behandel het als een productiefeature: rol langzaam uit, meet effect en houd rollback simpel.
Een veilige uitrolstrategie
Begin met een canary: schakel de nieuwe Content-Encoding (bijv. zstd) in voor een klein deel van het verkeer of een enkele interne client.
Ramps daarna geleidelijk (bijv. 1% → 5% → 25% → 50% → 100%), pauzerend als belangrijke metrics de verkeerde kant op bewegen.
Houd een gemakkelijke rollback route:
- Een feature-flag op de gateway/service om compressie uit te zetten (of terug te vallen op
gzip). - Een manier om specifieke endpoints uit te sluiten (bestandsdownloads, al-gecomprimeerde media).
- Een snelle config-only deploy, niet een code-deploy.
Wat te monitoren (en waarom)
Volg compressie als zowel prestatie- als betrouwbaarheid-wijziging:
- CPU (server en, indien mogelijk, client): hogere niveaus kunnen CPU laten pieken.
- Latency-percentielen (p50/p95/p99): compressie helpt vaak de gemiddelde latency maar kan de tail verslechteren.
- Responsegroottes: wire-bytes per endpoint, plus “gecomprimeerd vs ongecomprimeerd” deltas.
- Foutpercentages: let op
4xx/5xx, client-decode fouten en timeouts.
Troubleshooting-checklist
Als er iets misgaat, zijn dit de gebruikelijke verdachten:
- Dubbele compressie: een upstream service comprimeert en de gateway comprimeert opnieuw.
- Verkeerde headers:
Content-Encodingstaat ingesteld maar de body is niet gecomprimeerd (of andersom). - Slechte onderhandeling:
Accept-Encodinggenegeerd, of een encoding teruggegeven die de client niet adverteerde. - Gecorrumpeerde streams: afgebroken bodies, onjuiste
Content-Length, of proxy/CDN interferentie.
Documenteer client-verwachtingen
Leg duidelijk vast welke encodings ondersteund worden, inclusief voorbeelden:
- Wat clients moeten sturen:
Accept-Encoding: zstd, br, gzip - Wat ze zullen ontvangen:
Content-Encoding: zstd(of fallback)
Als je SDK's levert, voeg dan kleine copy-paste decode-voorbeelden toe en vermeld duidelijk minimale versies die Brotli of Zstandard ondersteunen.
Veelgestelde vragen
Wanneer is API-responscompressie echt de moeite waard?
Gebruik response-compressie wanneer responses tekst-zwaar zijn (JSON/GraphQL/XML/HTML), middelgroot tot groot, en je gebruikers op trage/duurzame netwerken zitten of je aanzienlijke egress-kosten betaalt. Schakel het uit (of gebruik een hoge drempel) voor zeer kleine responses, al-gecomprimeerde media (JPEG/MP4/ZIP/PDF) en CPU-beperkte diensten waar extra per-request werk p95/p99 kan verslechteren.
Waarom kan compressie een API trager maken terwijl responses kleiner zijn?
Omdat het opslag van bytes inruilt voor extra CPU (en soms geheugen). Compressietijd kan vertragen wanneer de server bytes kan beginnen te versturen (TTFB), en onder load kan het wachtrijen versterken—waardoor vooral de tail-latentie verslechtert, ook al verbetert de gemiddelde latency. De “beste” instelling is degene die de end-to-end tijd vermindert, niet alleen de payloadgrootte.
Hoe kies ik tussen ZSTD, Brotli en GZIP?
Een praktische standaardprioriteit voor veel API's is:
zstdeerst (snel, goede ratio)- dan
br(vaak kleinste voor tekst, kan meer CPU kosten) - dan
gzip(breedste compatibiliteit)
Baseer de uiteindelijke keuze altijd op wat de client aangeeft in , en houd een veilige fallback (gewoonlijk of ).
Welke compressieniveaus zijn zinnige defaults voor dynamische API-responses?
Begin laag en meet.
- ZSTD: niveau 1–3 (of tot ) voor de meeste dynamische JSON-API's
Moet ik elke response comprimeren, of alleen boven een bepaalde grootte?
Gebruik een minimale response-size drempel zodat je geen CPU verbrandt aan piepkleine payloads.
- Typisch startpunt: 1–2 KB
- Als je CPU-kritisch bent of erg chatty: overweeg 4 KB
Stel per endpoint bij door te vergelijken: bespaarde bytes vs toegevoegde servertijd en het effect op p50/p95/p99.
Welke payloadtypes comprimeren goed (en welke meestal niet)?
Focus op contenttypes die gestructureerd en repetitief zijn:
Hoe werken Accept-Encoding en Content-Encoding voor API's?
Compressie volgt HTTP-onderhandeling:
- Client stuurt
Accept-Encoding(bijv.zstd, br, gzip) - Server antwoordt met een ondersteunde
Content-Encoding
Als de client geen stuurt, is het veiligst meestal te sturen. Stuur nooit terug die de client niet heeft aangekondigd, want dat kan tot client-fouten leiden.
Waarom is Vary: Accept-Encoding belangrijk bij compressie?
Voeg toe:
Vary: Accept-Encoding
Dit voorkomt dat CDNs/proxies een (bijv.) gzip-response cachen en die ten onrechte serveren aan een client die gzip niet vroeg of niet kan decoderen (of voor zstd/br). Als je meerdere encodings ondersteunt is deze header essentieel voor correcte caching.
Wat zijn de meest voorkomende compressie-bugs in productie?
Veelvoorkomende foutmodi zijn:
Hoe rol ik API-compressie veilig uit en monitor ik het?
Rol het uit als een prestatie-feature:
- Canary of kleine slice eerst, dan geleidelijk verhogen (bijv. 1% → 5% → 25% → 100%)