21 de ago. de 2025·8 min
6 JOINs SQL que você precisa conhecer (com exemplos simples e claros)
Aprenda os 6 JOINs SQL que todo analista deve conhecer — INNER, LEFT, RIGHT, FULL OUTER, CROSS e SELF — com exemplos práticos e armadilhas comuns.
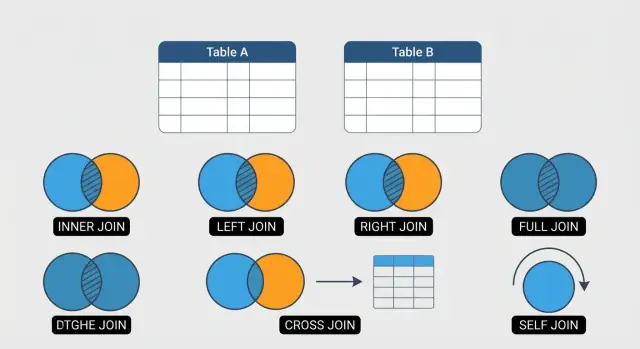
O que são JOINs em SQL e por que usá-los
Um SQL JOIN permite combinar linhas de duas (ou mais) tabelas em um único resultado ao casá-las por uma coluna relacionada — normalmente um ID.
Por que os JOINs importam
A maioria dos bancos de dados é propositalmente dividida em tabelas separadas para evitar repetir informação. Por exemplo, o nome de um cliente fica na tabela customers, enquanto as compras ficam na tabela orders. JOINs são como você reconecta essas partes quando precisa de respostas.
Por isso JOINs aparecem em todo tipo de relatório e análise:
- Montar um relatório de vendas que inclua nomes de clientes, totais de pedidos e status de pagamento
- Encontrar clientes que ainda não fizeram pedidos
- Auditar inconsistências, como pedidos sem pagamentos
- Criar resumos “uma linha por cliente” a partir de várias linhas relacionadas
Sem JOINs, você teria que rodar consultas separadas e combinar resultados manualmente — lento, sujeito a erros e difícil de repetir.
Se você está construindo produtos sobre um banco relacional (dashboards, painéis administrativos, ferramentas internas, portais), JOINs também transformam “tabelas brutas” em visões voltadas ao usuário. Plataformas como Koder.ai (que geram apps React + Go + PostgreSQL a partir de chat) ainda dependem de bons fundamentos de JOIN para páginas de lista, relatórios e telas de reconciliação — a lógica do banco não desaparece só porque o desenvolvimento ficou mais rápido.
Os 6 tipos de JOIN que você usará mais
Este guia foca em seis JOINs que cobrem a maior parte do trabalho diário em SQL:
- INNER JOIN: retorna apenas as linhas que coincidem em ambas as tabelas (bom para “mostrar relações confirmadas”).
- LEFT JOIN: mantém toda a tabela esquerda e adiciona o que for possível da direita (bom para “incluir dados relacionados ausentes”).
- RIGHT JOIN: espelho do LEFT JOIN (menos comum, mas útil dependendo do estilo de consulta ou legibilidade).
- FULL OUTER JOIN: mantém todas as linhas de ambas as tabelas, casando quando possível (ótimo para reconciliação e encontrar lacunas).
- CROSS JOIN: produz todas as combinações de linhas (útil para gerar calendários, cenários ou dados de teste — também fácil de usar errado).
- SELF JOIN: junta a tabela consigo mesma (útil para hierarquias como funcionários/gerentes).
Uma nota rápida sobre sintaxe
A sintaxe de JOIN é muito similar na maioria dos bancos (PostgreSQL, MySQL, SQL Server, SQLite). Há algumas diferenças — especialmente no suporte a FULL OUTER JOIN e em comportamentos de borda —, mas os conceitos e padrões centrais se transferem bem.
As tabelas de exemplo que usaremos (Customers, Orders, Payments)
Para manter os exemplos simples, usaremos três tabelas pequenas que refletem um cenário comum: clientes fazem pedidos, e pedidos podem (ou não) ter pagamentos.
Uma nota antes de começar: as tabelas de amostra abaixo mostram só algumas colunas, mas consultas posteriores referenciam campos adicionais (como order_date, created_at, status ou paid_at) para demonstrar padrões comuns. Considere essas colunas como campos típicos que você teria em esquemas de produção.
1) customers
Chave primária: customer_id
| customer_id | name |
|---|---|
| 1 | Ava |
| 2 | Ben |
| 3 | Chen |
| 4 | Dia |
2) orders
Chave primária: order_id
Chave estrangeira: customer_id → customers.customer_id
| order_id | customer_id | order_total |
|---|---|---|
| 101 | 1 | 50 |
| 102 | 1 | 120 |
| 103 | 2 | 35 |
| 104 | 5 | 70 |
Note que order_id = 104 referencia customer_id = 5, que não existe em customers. Essa “correspondência ausente” é útil para ver como LEFT JOIN, RIGHT JOIN e FULL OUTER JOIN se comportam.
3) payments
Chave primária: payment_id
Chave estrangeira: order_id → orders.order_id
| payment_id | order_id | amount |
|---|---|---|
| 9001 | 101 | 50 |
| 9002 | 102 | 60 |
| 9003 | 102 | 60 |
| 9004 | 999 | 25 |
Dois detalhes importantes para ensinar aqui:
order_id = 102tem duas linhas de pagamento (pagamento dividido). Ao juntarorderscompayments, esse pedido aparecerá duas vezes — é aí que duplicatas surpreendem as pessoas.payment_id = 9004referenciaorder_id = 999, que não existe emorders. Isso cria outro caso “sem correspondência”.
O que esperar quando juntamos essas tabelas
- Linhas correspondentes: por exemplo, cliente 1 ↔ pedidos 101/102; pedido 101 ↔ pagamento 9001.
- Linhas sem correspondência: por exemplo, clientes 3 e 4 não têm pedidos; pedido 104 não tem cliente; pagamento 9004 não tem pedido.
- Duplicatas: juntar
orderscompaymentsrepetirá o pedido 102 porque tem dois pagamentos.
INNER JOIN: manter apenas as linhas que batem
Um INNER JOIN retorna apenas as linhas onde há correspondência em ambas as tabelas. Se um cliente não tem pedidos, ele não aparecerá. Se um pedido aponta para um cliente que não existe (dados errados), esse pedido também não aparecerá.
O padrão básico
Você escolhe uma tabela “esquerda”, junta uma tabela “direita” e conecta com uma condição em ON.
SELECT
c.customer_id,
c.name,
o.order_id,
o.order_date
FROM customers c
INNER JOIN orders o
ON o.customer_id = c.customer_id;
A linha chave é ON o.customer_id = c.customer_id: ela diz ao SQL como as linhas se relacionam.
Caso de uso real: clientes que fizeram pedidos
Se você quer a lista apenas de clientes que fizeram pelo menos um pedido (e os detalhes do pedido), INNER JOIN é a escolha natural:
SELECT
c.name,
o.order_id,
o.total_amount
FROM customers c
INNER JOIN orders o
ON o.customer_id = c.customer_id
ORDER BY o.order_id;
Isso é útil para coisas como “enviar um email de acompanhamento de pedido” ou “calcular receita por cliente” (quando você só se importa com clientes com compras).
Erro comum: condição de join ausente ou ambígua
Se você escrever um join e esquecer o ON (ou fizer join nas colunas erradas), pode criar um produto cartesiano (todo cliente combinado com todo pedido) ou gerar correspondências incorretas.
Ruim (não faça isto):
SELECT c.name, o.order_id
FROM customers c
JOIN orders o;
Sempre garanta uma condição clara em ON (ou USING quando aplicável — coberto mais adiante).
LEFT JOIN: manter tudo da tabela esquerda
Um LEFT JOIN retorna todas as linhas da tabela esquerda, e adiciona dados da tabela direita quando existir. Se não houver correspondência, as colunas da direita aparecem como NULL.
Quando usar
Use LEFT JOIN quando você quer uma lista completa da sua tabela primária, mais dados relacionados opcionais.
Exemplo: “Mostre todos os clientes, e inclua seus pedidos se tiverem.”
SELECT
c.customer_id,
c.name,
o.order_id,
o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
ORDER BY c.customer_id;
- Clientes com pedidos aparecem com os detalhes dos pedidos.
- Clientes sem pedidos ainda aparecem, mas
o.order_id(e outras colunas deorders) seráNULL.
Encontrando as linhas sem correspondência (padrão clássico)
Um motivo muito comum para usar LEFT JOIN é achar itens que não têm registros relacionados.
Exemplo: “Quais clientes nunca fizeram um pedido?”
SELECT
c.customer_id,
c.name
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
WHERE o.order_id IS NULL;
Esse WHERE ... IS NULL mantém apenas as linhas da tabela esquerda onde o join não encontrou correspondência.
Cuidado: múltiplas correspondências multiplicam linhas
LEFT JOIN pode “duplicar” linhas da tabela esquerda quando existem múltiplas linhas correspondentes à direita.
Se um cliente tem 3 pedidos, esse cliente aparecerá 3 vezes — uma vez por pedido. Isso é esperado, mas pode surpreender se você estiver tentando contar clientes.
Por exemplo, isso conta pedidos (não clientes):
SELECT COUNT(*)
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id;
Se seu objetivo é contar clientes, normalmente você contará a chave do cliente (por exemplo, COUNT(DISTINCT c.customer_id)), dependendo do que você mede.
RIGHT JOIN: manter tudo da tabela direita
Um RIGHT JOIN mantém todas as linhas da tabela direita, e só as linhas correspondentes da esquerda. Se não houver correspondência, as colunas da esquerda aparecem como NULL. É essencialmente a imagem espelhada de um LEFT JOIN.
Um exemplo simples
Com nossas tabelas, imagine que você quer listar todos os pagamentos, mesmo que não seja possível ligá-los a um pedido (talvez o pedido foi deletado ou os dados de pagamento estão bagunçados).
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount,
p.paid_at
FROM orders o
RIGHT JOIN payments p
ON o.order_id = p.order_id;
O que você recebe:
- Todos os pagamentos estão incluídos (porque
paymentsestá à direita). - Se um pagamento não tem pedido correspondente,
o.order_ideo.customer_idserãoNULL.
A mesma consulta como LEFT JOIN (geralmente preferido)
Na maioria das vezes, você pode reescrever um RIGHT JOIN como LEFT JOIN trocando a ordem das tabelas:
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount,
p.paid_at
FROM payments p
LEFT JOIN orders o
ON o.order_id = p.order_id;
Isso retorna o mesmo resultado, mas muita gente acha mais claro: você começa com a tabela “principal” (aqui, payments) e então puxa dados relacionados opcionalmente.
Legibilidade: por que muitos times evitam RIGHT JOIN
Muitos guias de estilo SQL desencorajam RIGHT JOIN porque força o leitor a inverter mentalmente o padrão comum:
- “Comece pela tabela principal”
- “LEFT JOIN nas tabelas adicionais”
Quando relacionamentos opcionais são sempre escritos como LEFT JOIN, as consultas ficam mais fáceis de ler.
Quando RIGHT JOIN ainda é conveniente
RIGHT JOIN pode ser útil ao editar uma consulta existente quando você percebe que a tabela que deve ser preservada está atualmente à direita. Em vez de reescrever toda a consulta (especialmente uma longa com vários joins), trocar um join para RIGHT JOIN pode ser uma mudança rápida e de baixo risco.
FULL OUTER JOIN: manter todas as linhas de ambas as tabelas
Traga habilidades de JOIN para sua equipe
Passe de um protótipo rápido para um espaço de trabalho compartilhado quando o projeto crescer.
Um FULL OUTER JOIN retorna todas as linhas de ambas as tabelas.
- Se uma linha combinar na chave, você obtém uma única linha combinada (como
INNER JOIN). - Se uma linha existir só na esquerda, ela aparece com
NULLnas colunas da direita. - Se uma linha existir só na direita, ela aparece com
NULLnas colunas da esquerda.
Quando é útil
Um caso clássico é reconciliar orders vs. payments:
- você quer ver pedidos pagos (correspondências)
- pedidos não pagos (pedido existe, pagamento ausente)
- pagamentos soltos (pagamento existe, mas sem pedido — erro de dados, reembolso, referência errada, etc.)
Exemplo:
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount
FROM orders o
FULL OUTER JOIN payments p
ON p.order_id = o.order_id;
Suporte de banco (quem pode rodar direto)
FULL OUTER JOIN é suportado em PostgreSQL, SQL Server e Oracle.
Não está disponível em MySQL e SQLite (você precisará de um contorno).
Alternativa portátil: UNION de um LEFT JOIN e um RIGHT JOIN
Se seu banco não suporta FULL OUTER JOIN, você pode simulá-lo combinando:
- todas as linhas de
orders(com pagamentos quando disponíveis), e - todas as linhas de
paymentsque não casaram com um pedido.
Um padrão comum:
SELECT o.order_id, o.customer_id, p.payment_id, p.amount
FROM orders o
LEFT JOIN payments p
ON p.order_id = o.order_id
UNION
SELECT o.order_id, o.customer_id, p.payment_id, p.amount
FROM orders o
RIGHT JOIN payments p
ON p.order_id = o.order_id;
Dica: quando você vê NULLs de um lado, esse é o sinal de que a linha estava “faltando” na outra tabela — exatamente o que você quer para auditorias e reconciliações.
CROSS JOIN: fazer todas as combinações (use com cautela)
Um CROSS JOIN retorna todas as combinações possíveis de linhas entre duas tabelas. Se a tabela A tem 3 linhas e a tabela B tem 4 linhas, o resultado terá 3 × 4 = 12 linhas. Isso também é chamado de produto cartesiano.
Isso pode assustar — e pode —, mas é genuinamente útil quando você quer gerar combinações.
Um exemplo pequeno e seguro: tamanhos × cores (criando SKUs)
Imagine que você mantém opções de produto em tabelas separadas:
sizes: S, M, Lcolors: Red, Blue
Um CROSS JOIN pode gerar todas as variantes (útil para criar SKUs, pré-construir um catálogo ou testar):
SELECT
s.size,
c.color
FROM sizes AS s
CROSS JOIN colors AS c;
Resultado (3 × 2 = 6 linhas):
- S / Red
- S / Blue
- M / Red
- M / Blue
- L / Red
- L / Blue
Grande aviso: resultados crescem rápido
Porque a contagem de linhas multiplica, CROSS JOIN pode explodir rapidamente:
- 10.000 clientes × 50 produtos = 500.000 linhas
- 100.000 × 100.000 = 10.000.000.000 linhas
Isso pode deixar consultas lentas, sobrecarregar memória e produzir uma saída inútil. Se precisar de combinações, mantenha as tabelas de entrada pequenas e considere limites ou filtros controlados.
SELF JOIN: juntar uma tabela com ela mesma
Projete tabelas otimizadas para JOINs
Mapeie clientes, pedidos e pagamentos claramente antes de escrever qualquer consulta.
Um SELF JOIN é exatamente o que parece: você junta uma tabela consigo mesma. Isso é útil quando uma linha numa tabela se relaciona com outra linha da mesma tabela — mais comumente em relações pai/filho como funcionários e seus gerentes.
Por que você precisa de aliases (e como ajudam)
Como você está usando a mesma tabela duas vezes, precisa dar a cada “cópia” um alias diferente. Aliases deixam a consulta legível e dizem ao SQL qual lado você quer referenciar.
Um padrão comum é:
epara o empregadompara o gerente
Exemplo prático: empregados e seus gerentes
Imagine uma tabela employees com:
idnamemanager_id(aponta para oidde outro empregado)
Para listar cada empregado com o nome do gerente:
SELECT
e.id,
e.name AS employee_name,
m.name AS manager_name
FROM employees e
LEFT JOIN employees m
ON e.manager_id = m.id;
Lidando com empregados de topo (manager_id NULL)
Note que a consulta usa LEFT JOIN, não INNER JOIN. Isso importa porque alguns empregados podem não ter gerente (por exemplo, o CEO). Nesses casos, manager_id costuma ser NULL, e um LEFT JOIN mantém a linha do empregado mostrando manager_name como NULL.
Se você usasse INNER JOIN, esses empregados de topo desapareceriam do resultado porque não há uma linha de gerente correspondente.
Condições de join: ON vs USING (e por que importa)
Um JOIN não “sabe” automaticamente como duas tabelas se relacionam — você precisa dizer. Essa relação é definida na condição do join, e ela fica ao lado do JOIN porque explica como as tabelas batem, não como você quer filtrar o resultado final.
ON: o mais flexível (e o mais comum)
Use ON quando quiser controle total sobre a lógica de correspondência — colunas com nomes diferentes, condições múltiplas ou regras extras.
SELECT
c.customer_id,
c.name,
o.order_id,
o.created_at
FROM customers AS c
INNER JOIN orders AS o
ON o.customer_id = c.customer_id;
ON também é onde você define correspondências mais complexas (por exemplo, combinando em duas colunas) sem transformar sua consulta em um jogo de adivinhação.
USING: mais curto, mas só para colunas com mesmo nome
Alguns bancos (como PostgreSQL e MySQL) suportam USING. É um atalho conveniente quando ambas as tabelas têm uma coluna com o mesmo nome e você quer juntar por ela.
SELECT
customer_id,
name,
order_id
FROM customers
JOIN orders
USING (customer_id);
Um benefício: USING normalmente retorna apenas uma coluna customer_id no resultado (em vez de duas cópias).
Evite nomes de coluna ambíguos: qualifique nas joins
Após juntar tabelas, nomes de coluna costumam se sobrepor (id, created_at, status). Se você escrever SELECT id, o banco pode lançar um erro de “coluna ambígua” — ou pior, você pode ler a id errada.
Prefira prefixos de tabela (ou aliases) para clareza:
SELECT c.customer_id, o.order_id
FROM customers AS c
JOIN orders AS o
ON o.customer_id = c.customer_id;
Evite SELECT * em queries com joins
SELECT * fica confuso rapidamente com joins: você puxa colunas desnecessárias, corre risco de nomes duplicados e dificulta entender o que a consulta deveria produzir.
Em vez disso, selecione só as colunas que precisa. O resultado fica mais limpo, fácil de manter e muitas vezes mais eficiente — especialmente quando as tabelas são largas.
Filtrando dados juntados: WHERE vs ON
Quando você junta tabelas, WHERE e ON ambos “filtram”, mas em momentos diferentes.
- ON decide quais linhas combinam durante o join.
- WHERE filtra o resultado final depois que o join foi formado.
Essa diferença de momento é a razão pela qual pessoas acidentalmente transformam um LEFT JOIN em um INNER JOIN.
Como WHERE pode quebrar acidentalmente um LEFT JOIN
Suponha que você quer todos os clientes, mesmo aqueles sem pedidos pagos recentes.
SELECT c.customer_id, c.name, o.order_id, o.status, o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
WHERE o.status = 'PAID'
AND o.order_date \u003e= DATE '2025-01-01';
Problema: para clientes sem pedido correspondente, o.status e o.order_date são NULL. A cláusula WHERE rejeita essas linhas, então os clientes não correspondentes desaparecem — seu LEFT JOIN se comporta como INNER JOIN.
Mova condições relacionadas ao join para ON para manter linhas não correspondentes
SELECT c.customer_id, c.name, o.order_id, o.status, o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
AND o.status = 'PAID'
AND o.order_date \u003e= DATE '2025-01-01';
Agora clientes sem pedidos qualificados ainda aparecem (com colunas de pedido como NULL), que normalmente é o objetivo de um LEFT JOIN.
Checklist rápido: o que pertence em ON vs WHERE?
- Coloque condições em ON quando elas descrevem quais linhas da tabela direita podem corresponder (filtros de status/data/tipo na tabela juntada).
- Coloque condições em WHERE quando elas descrevem quais linhas finais você quer manter (filtros na tabela esquerda, ou quando você realmente exige uma correspondência).
- Se você precisa “manter todas as linhas da esquerda, mas restringir o lado direito”, prefira LEFT JOIN + condições em ON.
- Se você realmente quer “apenas linhas com correspondência”, use INNER JOIN (ou
WHERE o.order_id IS NOT NULLexplicitamente).
Evitando linhas duplicadas e surpresas muitos-para-muitos
Gere um painel de relatórios
Transforme suas tabelas em páginas de lista, filtros e relatórios usando o chat.
Joins não só “adicionam colunas” — eles também podem multiplicar linhas. Isso geralmente está correto, mas frequentemente surpreende quando totais dobram (ou pior).
Por que as linhas multiplicam
Um join retorna uma linha de saída para cada par de linhas que correspondem.
- Um-para-muitos: um cliente pode ter muitos pedidos. Ao juntar
customerscomorders, cada cliente pode aparecer múltiplas vezes — uma por pedido. - Muitos-para-muitos (a verdadeira armadilha): se você juntar
orderscompaymentse cada pedido pode ter múltiplos pagamentos, você pode obter múltiplas linhas por pedido. Se você também juntar com outra tabela “muitos” (comoorder_items), você pode criar um efeito de multiplicação:payments × itemspor pedido.
Pré-agregue antes de juntar
Se seu objetivo é “uma linha por cliente” ou “uma linha por pedido”, resuma o lado “muitos” primeiro, depois junte.
-- Uma linha por pedido a partir de payments
WITH payment_totals AS (
SELECT
order_id,
SUM(amount) AS total_paid,
COUNT(*) AS payment_count
FROM payments
GROUP BY order_id
)
SELECT
o.order_id,
o.customer_id,
COALESCE(pt.total_paid, 0) AS total_paid,
COALESCE(pt.payment_count, 0) AS payment_count
FROM orders o
LEFT JOIN payment_totals pt
ON pt.order_id = o.order_id;
Isso mantém a forma do join previsível: uma linha por pedido continua sendo uma linha por pedido.
DISTINCT é o último recurso
SELECT DISTINCT pode fazer as duplicatas parecerem resolvidas, mas pode esconder o problema real:
- Pode remover linhas legítimas silenciosamente.
- Pode mascarar uma condição de join errada (como faltar parte de uma chave composta).
- Pode deixar totais errados (especialmente somas e contagens).
Use apenas quando tiver certeza de que as duplicatas são meramente acidentais e você entende por que ocorreram.
Checagem rápida de segurança: valide contagens
Antes de confiar nos resultados, compare contagens de linhas:
- Conte as linhas na sua tabela principal (por exemplo,
orders). - Conte as linhas depois do join.
- Se o número subir inesperadamente, investigue quais chaves causam múltiplas correspondências e decida se precisa agregar previamente ou escolher outro caminho de join.
Noções básicas de performance e uma ficha rápida de JOINs
JOINs costumam ser culpados por “consultas lentas”, mas a causa real geralmente é a quantidade de dados que você pede para combinar e o quão fácil é encontrar as linhas que batem.
Indexação (conceitualmente) e por que ajuda JOINs
Pense em um índice como o índice de um livro. Sem ele, o banco pode precisar ler muitas linhas para achar correspondências. Com um índice na chave de join (por exemplo, customers.customer_id e orders.customer_id), o banco pode pular direto para as linhas relevantes mais rapidamente.
Você não precisa conhecer os detalhes internos para usar isso bem: se uma coluna é frequentemente usada para casar linhas (ON a.id = b.a_id), é um bom candidato para ter um índice.
Junte em chaves estáveis (não nomes ou emails)
Sempre que possível, faça join em identificadores estáveis e únicos:
- Bom:
customers.customer_id = orders.customer_id - Arriscado:
customers.email = orders.emailoucustomers.name = orders.name
Nomes mudam e podem se repetir. Emails podem mudar, estar faltando ou ter diferenças de case/formato. IDs são projetados para correspondência consistente e normalmente são indexados.
Reduza o trabalho cedo
Dois hábitos tornam JOINs sensivelmente mais rápidos:
- Selecione menos colunas. Evite
SELECT *ao juntar várias tabelas — colunas extras aumentam uso de memória e rede. - Limite linhas antes ou durante o JOIN. Filtre tão cedo quanto fizer sentido.
Exemplo: limite pedidos primeiro, depois junte:
SELECT c.customer_id, c.name, o.order_id, o.created_at
FROM customers c
JOIN (
SELECT order_id, customer_id, created_at
FROM orders
WHERE created_at \u003e= DATE '2025-01-01'
) o
ON o.customer_id = c.customer_id;
Se você estiver iterando nessas consultas dentro de uma construção de app (por exemplo, criando uma página de relatório com PostgreSQL), ferramentas como Koder.ai podem acelerar o scaffolding — esquema, endpoints, UI — enquanto você mantém o controle da lógica de JOIN que determina a correção.
Ficha rápida de JOINs
- INNER JOIN → apenas linhas que batem em ambas as tabelas
- LEFT JOIN → todas as linhas da tabela esquerda, mais correspondências da direita (
NULLquando ausente) - RIGHT JOIN → todas as linhas da tabela direita, mais correspondências da esquerda (
NULLquando ausente) - FULL OUTER JOIN → todas as linhas de ambas as tabelas; correspondências se juntam, não-correspondências aparecem com
NULL - CROSS JOIN → todas as combinações de linhas (contagem multiplica; use com cuidado)
- SELF JOIN → uma tabela juntada consigo mesma (útil para hierarquias e comparações)
Perguntas frequentes
O que é um JOIN em SQL em linguagem simples?
Um JOIN SQL combina linhas de duas (ou mais) tabelas em um único conjunto de resultados ao relacionar colunas relacionadas — na maioria das vezes uma chave primária com uma chave estrangeira (por exemplo, customers.customer_id = orders.customer_id). É assim que você “reconecta” tabelas normalizadas quando precisa gerar relatórios, auditorias ou análises.
Quando devo usar INNER JOIN?
Use INNER JOIN quando você quer apenas as linhas em que a relação existe em ambas as tabelas.
- Clientes sem pedidos não aparecerão.
- Pedidos que apontam para um cliente ausente não aparecerão.
É ideal para “relações confirmadas”, como listar somente clientes que realmente fizeram pedidos.
Como encontro linhas que não têm correspondência em outra tabela?
Use LEFT JOIN quando precisar de todas as linhas da sua tabela principal (esquerda), mais dados relacionados opcionais da tabela à direita.
Para encontrar “não correspondências”, faça o join e depois filtre o lado direito para NULL:
c.customer_id, c.name
customers c
orders o o.customer_id c.customer_id
o.order_id ;
Eu realmente preciso de RIGHT JOIN? Como substituí-lo por LEFT JOIN?
RIGHT JOIN mantém todas as linhas da tabela à direita e preenche com NULL as colunas da esquerda quando não há correspondência. Muitas equipes evitam porque a leitura fica “ao contrário”.
Na maioria dos casos, você pode reescrever como LEFT JOIN invertendo a ordem das tabelas:
FROM payments p
orders o o.order_id p.order_id
Para que serve melhor o FULL OUTER JOIN?
Use FULL OUTER JOIN para reconciliação: você quer correspondências, linhas só à esquerda e linhas só à direita em uma única saída.
É ótimo para auditorias como “pedidos sem pagamento” e “pagamentos sem pedido”, pois os lados não correspondentes aparecem com NULL.
E se meu banco de dados não suportar FULL OUTER JOIN?
Alguns bancos (notavelmente MySQL e SQLite) não suportam FULL OUTER JOIN diretamente. Uma solução comum é combinar duas consultas:
orders LEFT JOIN payments- mais as linhas que só aparecem do lado de
payments
Geralmente isso é feito com UNION (ou com cuidado) para manter os registros “somente à esquerda” e “somente à direita”.
O que é CROSS JOIN e quando ele é realmente útil?
Um CROSS JOIN retorna todas as combinações possíveis de linhas entre duas tabelas (produto cartesiano). É útil para gerar cenários (como tamanhos × cores) ou construir uma grade de calendário.
Cuidado: a contagem de linhas cresce rapidamente, podendo explodir o tamanho da saída e deixar as consultas lentas se as entradas não forem pequenas e controladas.
O que é SELF JOIN e por que preciso de aliases?
Um self join é juntar uma tabela com ela mesma para relacionar linhas dentro da mesma tabela (comum em hierarquias como empregado → gerente).
Você deve usar aliases para distinguir as duas “cópias”:
FROM employees e
LEFT JOIN employees m
ON e.manager_id = m.id
Qual é a diferença entre filtrar em ON vs WHERE para joins?
ON define como as linhas se correspondem durante o join; WHERE filtra depois que o resultado do join já foi formado. Com LEFT JOIN, uma condição WHERE no lado direito pode remover linhas NULL e transformar o comportamento em um INNER JOIN.
Se quiser manter todas as linhas da esquerda, mas restringir quais linhas da direita podem corresponder, coloque o filtro do lado direito em .
Por que joins criam duplicatas e como evito contagens duplicadas?
Joins podem multiplicar linhas quando a relação é um-para-muitos (ou muitos-para-muitos). Por exemplo, um pedido com dois pagamentos aparece duas vezes ao juntar orders com payments.
Para manter “uma linha por pedido/cliente”, agregue primeiro o lado “muitos” (por exemplo, SUM(amount) agrupado por order_id) e então faça o join. Use DISTINCT apenas como último recurso, pois pode mascarar problemas reais e estragar totais.