Defina Impacto do Incidente e as Decisões que Deve Orientar
Antes de construir cálculos ou painéis, decida o que “impacto” realmente significa na sua organização. Se pular essa etapa, você terá uma pontuação que parece científica, mas não ajuda ninguém a agir.
O que conta como “impacto” (e o que não conta)
Impacto é a consequência mensurável de um incidente sobre algo que o negócio valoriza. Dimensões comuns incluem:
- Usuários: número de usuários que não conseguem fazer login, picos de taxa de erro em fluxos-chave, latência degradada para uma região.
- Receita: checkouts falhando, renovações de assinatura bloqueadas, impressões de anúncios caindo.
- Risco de SLA/SLO: minutos de downtime contra uma meta de disponibilidade, taxa de consumo do orçamento de erro.
- Times internos: volume de tickets de suporte, carga do on-call, deploys bloqueados.
Escolha 2–4 dimensões principais e defina-as explicitamente. Por exemplo: “Impacto = clientes pagantes afetados + minutos de SLA em risco”, não “Impacto = qualquer coisa que pareça ruim em gráficos.”
Quem usa o app e o que precisa nos primeiros 10 minutos
Papéis diferentes tomam decisões diferentes:
- Comandantes de incidente precisam de um resumo rápido e defensável: o que está quebrado, quem é afetado e como isso está evoluindo.
- Suporte precisa do escopo voltado ao cliente: quais contas, regiões ou planos foram impactados.
- Engenharia precisa de uma hipótese de blast-radius para guiar debug e mitigação.
- Executivos precisam de uma declaração concisa de negócio: gravidade, impacto no cliente e confiança no ETA.
Projete as saídas de “impacto” para que cada público responda sua principal pergunta sem traduzir métricas.
Tempo real vs quase em tempo real: defina expectativas cedo
Decida qual latência é aceitável. “Tempo real” é caro e frequentemente desnecessário; quase em tempo real (por exemplo, 1–5 minutos) pode ser suficiente para tomada de decisão.
Documente isso como requisito de produto porque influencia ingestão, cache e UI.
Decisões que o app deve permitir durante um incidente
Seu MVP deve suportar ações diretas como:
- Declarar gravidade e nível de escalonamento
- Acionar comunicações aos clientes (status page, macros de suporte)
- Priorizar trabalho de mitigação (qual serviço/time primeiro)
- Decidir rollbacks, feature flags ou mudanças de tráfego
- Identificar quais clientes precisam de contato proativo
Se uma métrica não muda uma decisão, provavelmente não é “impacto”—é apenas telemetria.
Checklist de Requisitos: Entradas, Saídas e Restrições
Antes de desenhar telas ou escolher um banco, escreva o que a “análise de impacto” deve responder durante um incidente real. O objetivo não é precisão perfeita no dia 1—é resultados consistentes e explicáveis em que os respondedores confiem.
Entradas obrigatórias (o mínimo necessário)
Comece pelos dados que você deve ingerir ou referenciar para calcular impacto:
- Incidentes: ID, horários de início/fim, status, time responsável, resumo, links para canal/ticket do incidente.
- Serviços: lista canônica de serviços (nome, responsável, tier/criticidade, link do runbook).
- Dependências: quais serviços dependem de quais outros (mesmo que a primeira versão seja grosseira).
- Sinais de telemetria: alertas, consumo de SLO, taxa de erro/latência, eventos de deploy—qualquer coisa que indique degradação.
- Contas de clientes: IDs de conta, plano/SLA, região, contatos-chave, além de como as contas se mapeiam aos serviços (diretamente ou via workloads).
Opcional no lançamento (planeje, não exija)
A maioria das equipes não tem mapeamento perfeito de dependências ou clientes no dia 1. Decida o que permitirá que as pessoas insiram manualmente para que o app siga útil:
- Seleção manual de serviços/clientes afetados quando faltar dado
- Hora de início estimada ou escopo quando a telemetria estiver atrasada
- Overrides com razões (ex.: “alerta falso positivo”, “impacto apenas interno”)
Projete esses campos como explícitos (não notas ad-hoc) para que sejam consultáveis depois.
Principais saídas (o que o app deve produzir)
Sua primeira release deve gerar com confiabilidade:
- Serviços afetados e um “porquê” claro (sinais + dependências)
- Lista de clientes com contagens por plano/região e vista de “principais contas”
- Pontuação de gravidade/impacto que possa ser explicada em linguagem simples
- Linha do tempo de quando o impacto provavelmente começou, atingiu pico e se recuperou
- Opcional, mas valioso: uma estimativa de custo (créditos de SLA, carga de suporte, risco de receita) com intervalos de confiança
Restrições não funcionais (o que o torna confiável)
Análise de impacto é uma ferramenta de decisão, então restrições importam:
- Latência: dashboards devem carregar em segundos durante um incidente
- Disponibilidade: trate como uma ferramenta interna crítica; defina uma meta de disponibilidade
- Auditabilidade: registre quem alterou um override, quando e qual era o valor anterior
- Controle de acesso: restrinja dados sensíveis de clientes; separe permissões de leitura e escrita
Escreva esses requisitos como declarações testáveis. Se não puder verificar, não poderá confiar durante uma indisponibilidade.
Modelo de Dados: Incidentes, Serviços, Dependências e Clientes
Seu modelo de dados é o contrato entre ingestão, cálculo e UI. Se acertar aqui, você pode trocar fontes de tooling, refinar a pontuação e ainda responder as mesmas perguntas: “O que quebrou?”, “Quem foi afetado?” e “Por quanto tempo?”
Entidades principais (mantenha pequenas e linkáveis)
No mínimo, modele estes como registros de primeira classe:
- Incidente: contêiner narrativo (título, gravidade, status, responsável), mais ponteiros para evidências.
- Serviço: unidade para mapear dependências (API, banco, fila, provedor terceiro).
- Dependência: aresta direcionada serviço A → serviço B com metadados (tipo, criticidade).
- Sinal: observação com timestamp (alerta, burn de SLO, pico de erro, falha de check sintético).
- Cliente: conta ou organização que consome serviços.
- Assinatura/SLA: direito do cliente (plano, metas de SLA/SLO, regras de reporting).
Mantenha IDs estáveis e consistentes entre fontes. Se já tiver um catálogo de serviços, trate-o como fonte da verdade e mapeie identificadores externos para ele.
Modelagem de tempo (impacto é um problema de janela temporal)
Armazene múltiplos timestamps no incidente para suportar relatórios e análises:
- start_time / end_time: janela de impacto real (pode ser refinada depois)
- detection_time: quando soubemos pela primeira vez
- mitigation_time: quando correções começaram a reduzir o impacto
Armazene também janelas de tempo calculadas para pontuação de impacto (ex.: buckets de 5 minutos). Isso facilita replay e comparações.
Relacionamentos que respondem “quem é afetado?”
Modele dois grafos-chave:
- Dependências serviço-para-serviço (blast radius)
- Uso cliente-para-serviço (escopo afetado)
Um padrão simples é customer_service_usage(customer_id, service_id, weight, last_seen_at) para que você possa ranquear impacto por “quanto o cliente depende disso.”
Versionamento e histórico (dependências mudam)
Dependências evoluem, e cálculos de impacto devem refletir o que era verdade no momento. Adicione data efetiva às arestas:
dependency(valid_from, valid_to)
Faça o mesmo para assinaturas de clientes e snapshots de uso. Com versões históricas, você pode reexecutar incidentes passados em revisão pós-incidente e produzir relatórios de SLA consistentes.
Coletando e Normalizando Dados das Suas Ferramentas
Sua análise de impacto é tão boa quanto as entradas que a alimentam. O objetivo é simples: puxar sinais das ferramentas que vocês já usam e convertê-los em um fluxo de eventos consistente que o app possa raciocinar.
O que ingerir (e por quê)
Comece com uma lista curta de fontes que descrevem de forma confiável “algo mudou” durante um incidente:
- Alertas de monitoramento (PagerDuty, Opsgenie, CloudWatch alarms): indicadores rápidos de sintomas e severidade
- Logs e traces (ELK, Datadog, backends OpenTelemetry): evidência de escopo (quais endpoints, quais clientes)
- Atualizações de status (Statuspage, Cachet): narrativa oficial e timestamps voltados ao cliente
- Ferramentas de ticket/incident (Jira, ServiceNow): responsabilidade, timestamps e dados pós-incidente
Não tente ingerir tudo de uma vez. Escolha fontes que cubram detecção, escalonamento e confirmação.
Métodos de ingestão para escolher
Diferentes ferramentas suportam padrões de integração distintos:
- Webhooks para atualizações quase em tempo real (melhor para alertas e status pages)
- Polling para APIs sem webhooks (use backoff e limites de taxa)
- Importações em lote para backfills históricos (útil para validação inicial)
- Entrada manual para correções de “última milha” (um analista pode corrigir uma tag de serviço faltante)
Uma abordagem prática: webhooks para sinais críticos, mais importações em lote para preencher lacunas.
Normalizar para um esquema comum
Normalize cada item recebido para uma única forma de “evento”, mesmo que a fonte o chame de alerta, incidente ou anotação. No mínimo, padronize:
- Timestamp(s): occurred_at, detected_at, resolved_at (quando disponível)
- Identificadores de serviço: mapeie tags/nomes da fonte para seus IDs canônicos de serviço
- Severidade/prioridade: converta níveis específicos da ferramenta para sua escala
- Fonte e payload bruto: mantenha o JSON original para auditoria e debug
Higiene de dados: duplicados, ordenação, campos faltantes
Espere dados bagunçados. Use chaves de idempotência (source + external_id) para deduplicar, tolere eventos fora de ordem ordenando por occurred_at (não pelo tempo de chegada) e aplique valores padrão seguros quando campos faltarem (enquanto os sinaliza para revisão).
Uma pequena fila de “serviço não casado” na UI evita erros silenciosos e mantém os resultados de impacto confiáveis.
Mapear Dependências de Serviço para um Blast Radius Preciso
Escale além do protótipo
Passe de um protótipo rápido para Pro ou Business quando seu app de impacto se tornar crítico.
Se seu mapa de dependências estiver errado, seu blast radius estará errado—mesmo que sinais e pontuação estejam perfeitos. O objetivo é construir um grafo de dependências em que se possa confiar durante e após um incidente.
Antes de mapear arestas, defina os nós. Crie uma entrada de catálogo para todo sistema que possa ser referenciado em um incidente: APIs, workers, bancos, provedores terceiros e componentes compartilhados críticos.
Cada serviço deve incluir ao menos: time/dono, tier/criticidade (ex.: voltado ao cliente vs interno), metas de SLA/SLO e links para runbooks e docs de on-call (por exemplo, /runbooks/payments-timeouts).
Capture dependências: estáticas vs aprendidas
Use duas fontes complementares:
- Dependências estáticas (declaradas): o que os times dizem que dependem (de IaC, config, manifests, ADRs). Estáveis e fáceis de auditar.
- Dependências aprendidas (observadas): o que os sistemas realmente chamam (de traces, telemetry de service mesh, logs de gateway, logs de auditoria de banco). Pegam “unknown unknowns”, como uma chamada downstream esquecida.
Trate-as como tipos de aresta separados para que as pessoas entendam a confiança: “declarado pelo time” vs “observado nos últimos 7 dias”.
Direcionalidade e criticidade importam
Dependências devem ser direcionais: Checkout → Payments não é o mesmo que Payments → Checkout. A direção guia o raciocínio (“se Payments estiver degradado, quais upstreams podem falhar?”).
Modele também dependências hard vs soft:
- Hard: falha bloqueia funcionalidade crítica (serviço de auth para login).
- Soft: degrada qualidade mas há fallback (recomendações, enriquecimento opcional).
Essa distinção evita superestimar impacto e ajuda a priorizar.
Tire snapshots do grafo para replay e análise pós-incidente
Sua arquitetura muda semanalmente. Se não armazenar snapshots, não poderá analisar um incidente de dois meses atrás. Persista versões do grafo de dependências ao longo do tempo (diariamente, por deploy ou em mudança). Ao calcular blast radius, resolva o timestamp do incidente para o snapshot de grafo mais próximo, assim “quem foi afetado” reflete a realidade naquele momento—não a arquitetura de hoje.
Cálculo de Impacto: De Sinais a Pontuações e Escopo Afetado
Uma vez ingerindo sinais (alertas, burn de SLO, checks sintéticos, tickets de cliente), o app precisa de uma forma consistente de transformar entradas bagunçadas em uma afirmação clara: o que está quebrado, quão ruim é e quem foi afetado?
Escolha uma abordagem de pontuação (comece simples)
Você pode chegar a um MVP utilizável com qualquer um destes padrões:
- Regras: “Se taxa de erro do checkout \u003e 5% por 10 minutos, impacto = Alto.” Fácil de explicar e depurar.
- Fórmula ponderada: combine métricas normalizadas em uma única pontuação (ex.: 0–100). Útil quando há muitos sinais e você quer uma curva suave.
- Mapeamento por tiers: mapeie sistemas para tiers de negócio (Tier 0–3) e limite ou aumente severidade com base no tier. Mantém os resultados alinhados às prioridades do negócio.
Qualquer que seja a escolha, armazene os valores intermediários (limiar atingido, pesos, tier) para que as pessoas entendam por que a pontuação ocorreu.
Defina dimensões de impacto
Evite colapsar tudo em um número cedo demais. Acompanhe algumas dimensões separadamente e então derive uma severidade geral:
- Disponibilidade: downtime, requisições falhas, endpoints inalcançáveis
- Latência: degradação do p95/p99 contra baseline ou SLO
- Erros: picos de taxa de erro, jobs falhando, timeouts
- Correção de dados: registros faltantes/incorretos, processamento atrasado
- Risco de segurança: padrões suspeitos de acesso, indicadores de exposição de dados
Isso ajuda os respondedores a comunicar com precisão (ex.: “disponível mas lento” vs “resultados incorretos”).
Calcule o escopo afetado (clientes/usuários)
Impacto não é só saúde do serviço—é quem sentiu. Use mapeamento de uso (tenant → serviço, plano do cliente → features, tráfego por usuário → endpoint) e calcule clientes afetados dentro da janela temporal alinhada ao incidente (start, mitigation e qualquer período de backfill).
Seja explícito sobre pressupostos: logs amostrados, tráfego estimado ou telemetria parcial.
Ajustes manuais—with accountability
Operadores vão precisar sobrescrever: alerta falso, rollout parcial, subset conhecido de tenants.
Permita edições manuais de severidade, dimensões e clientes afetados, mas exija:
- Quem mudou o quê
- Quando
- Por quê (motivo curto + link opcional para ticket/runbook)
Esse rastro de auditoria protege a confiança no dashboard e acelera a revisão pós-incidente.
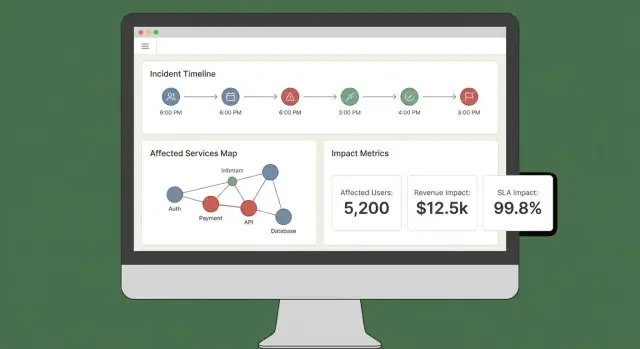
UX e Dashboards: Torne o Impacto Compreensível em Minutos
Um bom painel de impacto responde três perguntas rapidamente: O que está afetado? Quem está afetado? Quão certos estamos? Se os usuários tiverem que abrir cinco abas para montar isso, não confiarão nem agirão sobre o resultado.
Visões principais para enviar no MVP
Comece com um pequeno conjunto de vistas “sempre disponíveis” que se mapeiam a workflows reais de incidente:
- Visão geral do incidente: status, hora de início, pontuação de impacto atual, serviços/clientes mais afetados e as evidências mais recentes.
- Serviços afetados: lista ranqueada mostrando severidade, região e caminho de dependência (para engenheiros identificarem onde intervir).
- Clientes afetados: contagens e contas nomeadas por tier/plano, mais estimativa de usuários afetados se você acompanhar isso.
- Linha do tempo: um fluxo cronológico combinando detecções, deploys, alertas, mitigações e mudanças de impacto.
- Ações: próximos passos sugeridos, responsáveis e links para playbooks ou tickets.
Torne o “porquê” visível
Pontuações sem explicação parecem arbitrárias. Cada pontuação deve ser rastreável até entradas e regras:
- Mostre quais sinais contribuíram (erros, latência, checks de saúde, volume de suporte) e seus valores atuais.
- Exiba regras e limiares usados (ex.: “latência p95 \u003e 2s por 10 min = degradado”).
- Adicione um indicador leve de confiança (ex.: “Alta confiança: confirmado por 3 fontes”).
Um “Explique impacto” em painel deslizante pode fazer isso sem poluir a vista principal.
Filtros e drilldowns que respondem perguntas reais
Facilite fatiar impacto por serviço, região, tier de cliente e intervalo de tempo. Permita que usuários cliquem em qualquer ponto do gráfico ou linha para acessar evidências brutas (os monitores, logs ou eventos exatos que causaram a mudança).
Compartilhamento e exportações
Durante um incidente ativo, as pessoas precisam de atualizações portáveis. Inclua:
- Links compartilháveis para a vista do incidente (respeitando permissões)
- Export CSV para listas de serviços/clientes
- Export PDF para atualizações de status e sumários pós-incidente
Se já tiver uma status page, linke-a via rota relativa como /status para que o time de comunicações possa cruzar referências rapidamente.
Segurança, Permissões e Auditoria
Experimente sem risco
Itere nas regras com segurança usando instantâneos e reversão quando uma alteração falhar.
Análise de impacto só é útil se as pessoas confiarem—o que significa controlar quem vê o quê e manter um registro claro de mudanças.
Papéis e permissões (comece simples)
Defina um conjunto pequeno de papéis que reflita como incidentes são conduzidos na prática:
- Viewer: acesso somente leitura a sumários de incidente e impacto
- Responder: pode adicionar notas, confirmar serviços afetados e atualizar campos operacionais
- Comandante de incidente: pode aprovar overrides de impacto, definir status voltado ao cliente e fechar incidentes
- Admin: gerencia integrações, atribuição de papéis e retenção de dados
Mantenha permissões alinhadas a ações, não a cargos. Ex.: “pode exportar relatório de impacto de clientes” é uma permissão que pode ser concedida a comandantes e a um pequeno conjunto de admins.
Proteja dados sensíveis de clientes
Análise de impacto frequentemente toca identificadores, níveis contratuais e, às vezes, detalhes de contato. Aplique privilégio mínimo por padrão:
- Mascarar campos sensíveis (ex.: mostrar apenas os 4 últimos caracteres de um ID) a menos que o usuário tenha acesso explícito.
- Separe “quem é afetado” de “o que quebrou”. Muitos usuários só precisam de impacto a nível de serviço, não da lista de clientes.
- Proteja exports: adicione watermark em PDFs/CSVs, inclua o usuário solicitante e restrinja exports a papéis aprovados. Prefira links de download assinados e de curta duração.
Auditoria que responde “quem mudou o quê?”
Logue ações-chave com contexto suficiente para suportar revisões:
- Edições manuais de inputs de impacto (serviços/clientes afetados)
- Overrides de pontuação de impacto (valor antigo, novo, razão)
- Acknowledgments e transições de status
- Geração de relatórios e exports
Armazene logs de auditoria append-only, com timestamps e identidade do ator. Torne-os pesquisáveis por incidente para serem úteis em revisões pós-incidente.
Planeje requisitos de compliance (sem prometer demais)
Documente o que pode suportar agora—período de retenção, controles de acesso, criptografia e cobertura de auditoria—e o que está no roadmap.
Uma página curta “Security & Audit” no app (ex.: /security) ajuda a definir expectativas e reduz perguntas ad-hoc em incidentes críticos.
Workflows e Notificações Durante um Incidente Ativo
Análise de impacto só importa durante um incidente se ela direcionar a próxima ação. Seu app deve funcionar como um “co-piloto” para o canal de incidente: transformar sinais em atualizações claras e lembrar pessoas quando o impacto mudar significativamente.
Conecte-se a chat e canais de incidente
Comece integrando ao lugar onde os respondedores já trabalham (Slack, Microsoft Teams ou uma ferramenta de incidentes). O objetivo não é substituir o canal—é postar atualizações com contexto e manter um registro compartilhado.
Um padrão prático é tratar o canal de incidente como input e output:
- Input: respondedores marcam o app (ex.: “/impact summarize”, “/impact add affected customer Acme”) para corrigir ou enriquecer o escopo.
- Output: o app posta atualizações concisas e consistentes (pontuação atual, serviços/clientes afetados, tendência vs última atualização).
Se estiver prototipando rápido, considere construir o workflow ponta a ponta primeiro (vista do incidente → resumir → notificar) antes de aperfeiçoar a pontuação. Plataformas como Koder.ai podem acelerar o protótipo: você pode iterar em um dashboard React e uma API Go/PostgreSQL via workflow orientado por chat e então exportar o código.
Notificações baseadas em limiar (não spam)
Evite ruído acionando notificações apenas quando o impacto cruzar limiares explícitos. Gatilhos comuns:
- Escopo: contagem de clientes afetados salta (ex.: 10 → 100)
- Tier: um serviço Tier 1 fica afetado
- Receita / SLA: projeção de violação de SLA ou alto valor contratual envolvido
- Expansão do blast radius: novos serviços dependentes entram no conjunto afetado
Quando um limiar é cruzado, envie uma mensagem que explique o que mudou, quem deve agir e o que fazer a seguir.
Links para runbooks e workflows
Toda notificação deve incluir links de “próximo passo” para que respondedores atuem rapidamente:
- Runbooks: /blog/incident-runbook-template
- Política de escalonamento: /pricing
- Página de propriedade do serviço: /services/payments
Mantenha esses links estáveis e relativos para que funcionem em vários ambientes.
Atualizações para stakeholders: internas e voltadas ao cliente
Gere dois formatos de resumo a partir dos mesmos dados:
- Atualização interna: detalhe técnico, causa suspeita, progresso da mitigação, confiança do ETA.
- Atualização ao cliente: linguagem simples, impacto atual nos usuários, contornos possíveis, próximo horário de atualização.
Suporte resumos agendados (ex.: a cada 15–30 minutos) e ações de “gerar atualização” sob demanda, com etapa de aprovação antes do envio externo.
Validação: Testes, Replay e Checagens de Acurácia
Gere a stack completa
Gere uma UI em React com uma API em Go e esquema PostgreSQL com base no seu fluxo de incidentes.
Análise de impacto só é útil se as pessoas confiarem nela durante e depois do incidente. Validação deve provar duas coisas: (1) o sistema produz resultados estáveis e explicáveis, e (2) esses resultados batem com o que a organização conclui depois.
Estratégia de testes: regras e pipelines
Comece com testes automatizados que cubram as duas áreas mais propensas a falha: lógica de pontuação e ingestão de dados.
- Testes unitários para regras de pontuação: trate cada regra como um contrato. Dado sinais específicos (taxa de erro, latência, checks sintéticos, volume de tickets), o teste deve afirmar a pontuação de impacto e o escopo afetado esperado. Inclua testes de fronteira (logo abaixo/acima dos limiares) para que jitter não vire outcomes inesperados.
- Testes de integração para ingestão: valide o caminho completo de webhook/payload até registros normalizados e impacto calculado. Use payloads gravados das suas ferramentas de observabilidade para pegar drift de esquema cedo.
Mantenha fixtures legíveis: quando alguém mudar uma regra, deve ser fácil entender por que uma pontuação mudou.
Reproduza incidentes passados para validar saídas
Um modo de replay é um caminho rápido para confiança. Rode incidentes históricos pelo app e compare o que o sistema teria mostrado “naquele momento” com o que os respondedores concluíram depois.
Dicas práticas:
- Reconstrua timelines usando timestamps de evento (não tempo de ingestão) para refletir a realidade.
- Congele grafos de dependência na data do incidente se o catálogo mudou.
- Armazene resultados de replay para comparar versões após ajustes nas regras.
Incidentes reais raramente são outages limpos. Sua suíte de validação deve incluir cenários como:
- Outages parciais (alguns endpoints ou segmentos de clientes falhando)
- Performance degradada (lento mas não falhando) onde o impacto de negócio pode ser alto
- Falhas multi-região onde o mesmo serviço tem saúde diferente por região
Para cada caso, afirme não apenas a pontuação, mas também a explicação: quais sinais e quais dependências/clientes guiaram o resultado.
Medir acurácia contra descobertas pós-incidente
Defina acurácia em termos operacionais e então acompanhe. Compare impacto computado com resultados da revisão pós-incidente: serviços afetados, duração, contagem de clientes, violação de SLA e severidade. Logue discrepâncias como issues de validação com categoria (dados faltantes, dependência errada, limiar ruim, sinal atrasado).
Com o tempo, o objetivo não é perfeição—é menos surpresas e mais concordância rápida durante incidentes.
Deploy, Escala e Iteração Pós-MVP
Enviar um MVP de análise de impacto é principalmente sobre confiabilidade e ciclos de feedback. Sua escolha de deploy inicial deve priorizar velocidade de mudança, não escala teórica futura.
Escolha um estilo de deploy que você possa evoluir
Comece com um monólito modular a menos que já tenha um time de plataforma forte e limites claros entre serviços. Uma unidade deployável simplifica migrações, debug e testes end-to-end.
Separe em serviços só quando houver dor real:
- pipeline de ingestão precisa de escalabilidade independente
- times diferentes precisam deploys independentes
- domínios de falha ficam difíceis de raciocinar em um app único
Um meio prático é uma aplicação + workers em background (filas) + uma borda de ingestão separada se necessário.
Se quiser acelerar sem construir plataforma sob medida, Koder.ai pode ajudar a prototipar: fluxo vibe-coding orientado por chat é bom para construir UI React, API em Go e modelo de dados PostgreSQL, com snapshots/rollback enquanto itera em regras e workflows.
Use armazenamento relacional (Postgres/MySQL) para entidades core: incidentes, serviços, clientes, propriedade e snapshots calculados de impacto. É fácil de consultar, auditar e evoluir.
Para sinais de alto volume (métricas, eventos derivados de logs), adicione um store time-series (ou coluna) quando retenção de sinais brutos e rollups ficarem caros em SQL.
Considere um grafo DB só se consultas de dependência virarem gargalo ou o modelo ficar altamente dinâmico. Muitas equipes vão longe com tabelas de adjacência + cache.
Adicione observabilidade para o próprio app
Seu app de análise torna-se parte da cadeia de ferramentas de incidente, então instrumente-o como software de produção:
- taxa de erro e endpoints lentos (especialmente “recalcular impacto”)
- profundidade/lag de filas de workers e taxas de retry
- throughput de ingestão e contagens de falha por fonte
- frescor dos dados (tempo desde último pull/push bem-sucedido)
- duração de cálculo e taxa de hit do cache
Expose uma vista de “health + freshness” na UI para que respondedores confiem (ou questionem) os números.
Planeje iterações e refactors deliberadamente
Defina escopo MVP apertado: um conjunto pequeno de ferramentas para ingerir, uma pontuação clara de impacto e um dashboard que responda “quem foi afetado e quanto”. Depois itere:
- Próximas features: maior acurácia de dependências, ponderação específica por cliente, exportes de relatório de SLA, replay de incidentes
- Gatilhos de refactor: você adiciona exceções toda semana, recalculo está lento ou o modelo de dados não expressa a realidade sem gambiarras
Trate o modelo como produto: version it, migre com segurança e documente mudanças para a revisão pós-incidente.