21 de mai. de 2025·8 min
Criar uma Aplicação Web para Relatórios Centralizados de SLA
Aprenda a planejar, construir e lançar um app web multi-cliente que coleta dados de SLA, normaliza métricas e entrega dashboards, alertas e relatórios exportáveis.
Aprenda a planejar, construir e lançar um app web multi-cliente que coleta dados de SLA, normaliza métricas e entrega dashboards, alertas e relatórios exportáveis.
O relatório centralizado de SLA existe porque evidências de SLA raramente vivem em um só lugar. A disponibilidade pode estar numa ferramenta de monitoramento, incidentes numa página de status, tickets num helpdesk e notas de escalonamento em email ou chat. Quando cada cliente tem uma stack levemente diferente (ou convenções de nomenclatura diferentes), o relatório mensal vira trabalho manual em planilhas — e desacordos sobre “o que realmente aconteceu” tornam-se comuns.
Um bom aplicativo de relatórios de SLA atende vários públicos com objetivos diferentes:
O app deve apresentar a mesma verdade subjacente em diferentes níveis de detalhe, dependendo do papel.
Um painel centralizado de SLA deve entregar:
Na prática, todo número de SLA deve ser rastreável até eventos brutos (alertas, tickets, timelines de incidentes) com timestamps e responsáveis.
Antes de construir qualquer coisa, defina o que está dentro do escopo e fora do escopo. Por exemplo:
Limites claros previnem debates mais tarde e mantêm os relatórios consistentes entre clientes.
No mínimo, o relatório centralizado de SLA deve suportar cinco fluxos:
Projete em torno desses fluxos desde o primeiro dia e o resto do sistema (modelo de dados, integrações e UX) permanecerá alinhado com necessidades reais de relatório.
Antes de construir telas ou pipelines, decida o que seu app vai medir e como esses números devem ser interpretados. O objetivo é consistência: duas pessoas lendo o mesmo relatório devem chegar à mesma conclusão.
Comece com um conjunto pequeno que a maioria dos clientes reconheça:
Seja explícito sobre o que cada métrica mede e o que ela não mede. Um painel de definições curto na UI (e um link para /help/sla-definitions) previne mal-entendidos depois.
Regras são onde o relatório de SLA costuma falhar. Documente em frases que seu cliente possa validar, depois traduza para lógica.
Cubra o essencial:
Escolha períodos padrão (mensal e trimestral são comuns) e se você suportará intervalos customizados. Esclareça o fuso horário usado para cortes.
Para violações, defina:
Para cada métrica, liste as entradas necessárias (eventos de monitoramento, registros de incidentes, timestamps de tickets, janelas de manutenção). Isso vira sua planta para integrações e verificações de qualidade de dados.
Antes de projetar dashboards ou KPIs, esclareça onde as evidências de SLA realmente vivem. A maioria das equipes descobre que seus “dados de SLA” estão divididos entre ferramentas, pertencem a grupos diferentes e são registrados com significados ligeiramente distintos.
Comece com uma lista simples por cliente (e por serviço):
Para cada sistema, anote o dono, período de retenção, limites de API, resolução de tempo (segundos vs minutos) e se os dados são por cliente ou compartilhados.
A maioria dos apps de relatório de SLA usa uma combinação:
Uma regra prática: use webhooks quando a frescura importa, e API pulls quando a completude importa.
Diferentes ferramentas descrevem a mesma coisa de maneiras diferentes. Normalize para um pequeno conjunto de eventos que o app possa usar, por exemplo:
incident_opened / incident_closeddowntime_started / downtime_endedticket_created / first_response / resolvedInclua campos consistentes: client_id, service_id, source_system, external_id, severity e timestamps.
Armazene todos os timestamps em UTC, e converta na exibição baseado no fuso horário preferido do cliente (especialmente para cortes mensais).
Planeje para lacunas também: alguns clientes não terão páginas de status, alguns serviços não serão monitorados 24/7, e algumas ferramentas podem perder eventos. Torne a “cobertura parcial” visível nos relatórios (por exemplo, “dados de monitoramento indisponíveis por 3 horas”) para que os resultados de SLA não sejam enganosos.
Se seu app reporta SLAs para múltiplos clientes, decisões de arquitetura determinam se você consegue escalar com segurança sem vazamentos de dados entre clientes.
Comece nomeando as camadas que você precisa suportar. Um “cliente” pode ser:
Registre isso cedo, porque afeta permissões, filtros e como você armazena configurações.
A maioria dos apps de relatório de SLA escolhe um destes:
tenant_id. É econômico e mais simples de operar, mas requer disciplina rigorosa nas queries.Um compromisso comum é banco compartilhado para a maioria dos tenants e bancos dedicados para clientes “enterprise”.
O isolamento deve valer em:
tenant_id para que resultados não sejam gravados no tenant erradoUse guardrails como row-level security, escopos de query obrigatórios e testes automatizados para limites de tenant.
Clientes diferentes terão alvos e definições diferentes. Planeje configurações por tenant como:
Usuários internos frequentemente precisam “impersonar” a visão de um cliente. Implemente uma troca deliberada (não um filtro livre), mostre o tenant ativo de forma proeminente, registre trocas para auditoria e impeça links que possam contornar checagens de tenant.
Um app centralizado de SLA vive ou morre pelo seu modelo de dados. Se você modelar apenas “% de SLA por mês”, terá dificuldade para explicar resultados, lidar com disputas ou atualizar cálculos depois. Se modelar apenas eventos brutos, os relatórios ficam lentos e caros. O objetivo é suportar ambos: evidência bruta rastreável e rollups rápidos prontos para o cliente.
Mantenha separação clara entre quem está sendo reportado, o que está sendo medido e como é calculado:
Projete tabelas (ou coleções) para:
A lógica de SLA muda: horário comercial atualizado, exclusões refinadas, regras de arredondamento evoluem. Adicione um calculation_version (e idealmente uma referência ao “rule set”) a todo resultado computado. Assim, relatórios antigos podem ser reproduzidos exatamente mesmo após melhorias.
Inclua campos de auditoria onde importam:
Clientes frequentemente pedem “mostre o porquê”. Planeje um esquema para evidências:
Essa estrutura mantém o app explicável, reprodutível e rápido — sem perder as provas subjacentes.
Se suas entradas são bagunçadas, seu painel de SLA também será. Um pipeline confiável transforma dados de incidentes e tickets de múltiplas ferramentas em resultados de SLA consistentes e auditáveis — sem contagem dupla, lacunas ou falhas silenciosas.
Trate ingestão, normalização e rollups como estágios separados. Rode-os como jobs em background para que a UI seja rápida e você possa reexecutar com segurança.
Essa separação também ajuda quando a fonte de um cliente está fora do ar: a ingestão pode falhar sem corromper cálculos existentes.
APIs externas time-out. Webhooks podem ser entregues duas vezes. Seu pipeline deve ser idempotente: processar a mesma entrada mais de uma vez não deve alterar o resultado.
Abordagens comuns:
Entre clientes e ferramentas, “P1”, “Critical” e “Urgent” podem significar a mesma prioridade — ou não. Construa uma camada de normalização que padronize:
Armazene tanto o valor original quanto o valor normalizado para rastreabilidade.
Adicione regras de validação (timestamps ausentes, durações negativas, transições de status impossíveis). Não descarte dados ruins silenciosamente — direcione-os para uma fila de quarentena com razão e um workflow de “corrigir ou mapear”.
Para cada cliente e fonte, calcule “última sincronização com sucesso”, “evento não processado mais antigo” e “rollup atualizado até”. Exiba isso como um indicador simples de frescor de dados para que clientes confiem nos números e sua equipe detecte problemas cedo.
Se clientes usam seu portal para revisar desempenho de SLA, autenticação e permissões precisam ser projetadas tão cuidadosamente quanto a matemática do SLA. O objetivo é simples: todo usuário vê apenas o que deve — e você pode provar isso depois.
Comece com um conjunto pequeno e claro de papéis e expanda só quando houver razões fortes:
Mantenha o princípio do menor privilégio por padrão: novas contas devem entrar em viewer a menos que explicitamente promovidas.
Para equipes internas, SSO reduz o acúmulo de contas e o risco de offboarding incorreto. Suporte OIDC (com Google Workspace/Azure AD/Okta) e, quando necessário, SAML.
Para clientes, ofereça SSO como opção de upgrade, mas permita email/senha com MFA para organizações menores.
Imponha limites de tenant em todas as camadas:
Registre acessos a páginas sensíveis e downloads: quem acessou o quê, quando e de onde. Isso ajuda conformidade e a confiança do cliente.
Crie um fluxo de onboarding onde admins ou editors do cliente podem convidar usuários, definir papéis, exigir verificação de email e revogar acesso instantaneamente quando alguém sair.
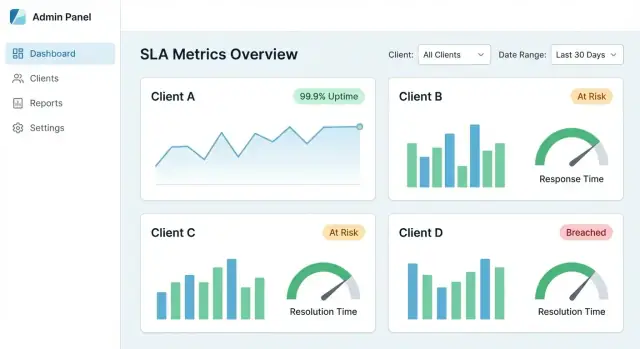
Um dashboard centralizado de SLA funciona quando um cliente pode responder três perguntas em menos de um minuto: Estamos cumprindo SLAs? O que mudou? O que causou as falhas? Sua UX deve guiá‑los de uma visão de alto nível até a evidência — sem forçá‑los a aprender seu modelo de dados interno.
Comece com um pequeno conjunto de cartões e gráficos que casem com conversas comuns de SLA:
Faça cada cartão clicável para que vire uma porta para detalhes, não um fim de linha.
Filtros devem ser consistentes entre páginas e “grudarem” enquanto o usuário navega.
Padrões recomendados:
Mostre chips de filtro ativos no topo para que os usuários sempre entendam o que estão vendo.
Cada métrica deve ter um caminho para o “porquê”. Um bom fluxo de drill-down:
Se um número não puder ser explicado com evidência, ele será questionado — especialmente em QBRs.
Adicione tooltips ou um painel de “info” para cada KPI: como é calculado, exclusões, fuso horário e frescor dos dados. Inclua exemplos como “janelas de manutenção excluídas” ou “uptime medido no gateway de API”.
Torne views filtradas compartilháveis via URLs estáveis (ex.: /reports/sla?client=acme&service=api&range=30d). Isso transforma seu dashboard centralizado de SLA em um portal pronto para clientes que suporta reuniões recorrentes e trilhas de auditoria.
Um painel centralizado de SLA é útil no dia a dia, mas clientes frequentemente querem algo que possam encaminhar internamente: um PDF para liderança, um CSV para analistas e um link que possam favoritar.
Suporte três outputs a partir dos mesmos resultados de SLA:
Para relatórios baseados em link, faça filtros explícitos (intervalo de datas, serviço, severidade) para que o cliente saiba exatamente o que os números representam.
Adicione agendamento para que cada cliente receba relatórios automaticamente — semanalmente, mensalmente e trimestralmente — enviados para uma lista específica do cliente ou uma caixa de entrada compartilhada. Mantenha agendamentos scops por tenant e auditáveis (quem criou, última vez enviado, próxima execução).
Se precisar de um ponto de partida simples, lance com um “resumo mensal” mais um download com um clique em /reports.
Construa templates que leiam como slides de QBR/MBR em forma escrita:
SLAs reais incluem exceções (janelas de manutenção, falhas de terceiros). Permita que usuários anexem notas de conformidade e sinalizem exceções que requerem aprovação, com uma trilha de aprovação.
Exports devem respeitar isolamento de tenant e papéis. Um usuário só deve exportar os clientes, serviços e períodos que pode ver — e o export deve corresponder exatamente à visão do portal (sem colunas extras que vazem dados ocultos).
Alertas são onde um app de relatório de SLA passa de “dashboard interessante” para ferramenta operacional. O objetivo não é mandar mais mensagens — é ajudar as pessoas certas a reagir cedo, documentar o que aconteceu e manter os clientes informados.
Comece com três categorias:
Vincule cada alerta a uma definição clara (métrica, janela de tempo, limite, escopo de cliente) para que os destinatários confiem nele.
Ofereça múltiplas opções de entrega para que equipes encontrem os clientes onde já trabalham:
Para relatórios multi-cliente, roteie notificações usando regras de tenant (ex.: “Quebras do Cliente A vão para o Canal A; quebras internas vão para on-call”). Evite enviar detalhes específicos de um cliente para canais compartilhados.
A fadiga de alertas mata a adoção. Implemente:
Cada alerta deve suportar:
Isso cria uma trilha de auditoria leve que pode ser usada em resumos prontos para clientes.
Forneça um editor básico de regras para limites e roteamento por cliente (sem expor lógica de query complexa). Guardrails ajudam: defaults, validação e pré-visualização (“esta regra teria disparado 3 vezes no mês passado”).
Um app centralizado de SLA rapidamente vira crítico porque clientes o usam para julgar qualidade de serviço. Isso torna velocidade, segurança e evidência (para auditorias) tão importantes quanto os gráficos.
Clientes grandes podem gerar milhões de tickets, incidentes e eventos de monitoramento. Para manter páginas responsivas:
Eventos brutos são valiosos para investigações, mas manter tudo para sempre aumenta custo e risco.
Defina regras claras como:
Para qualquer portal de relatórios, assuma conteúdo sensível: nomes de clientes, timestamps, notas de ticket e às vezes PII.
Mesmo se você não mira um padrão específico, evidência operacional sólida constrói confiança.
Mantenha:
Lançar um app de relatório de SLA é menos sobre um grande release e mais sobre provar precisão e depois escalar de forma repetível. Um plano de lançamento sólido reduz disputas tornando resultados fáceis de verificar e reproduzir.
Escolha um cliente com um conjunto manejável de serviços e fontes de dados. Rode os cálculos do seu app em paralelo com as planilhas existentes, exports de tickets ou relatórios de portais do cliente.
Foque em áreas comuns de divergência:
Documente diferenças e decida se o app deve igualar a abordagem atual do cliente ou substituí‑la por um padrão mais claro.
Crie um checklist repetível para que cada nova experiência de cliente seja previsível:
Um checklist também ajuda a estimar esforço e suportar discussões em /pricing.
Dashboards de SLA só são críveis se estiverem frescos e completos. Adicione monitoramento para:
Envie alertas internos primeiro; uma vez estável, você pode introduzir notas de status visíveis ao cliente.
Colete feedback sobre onde a confusão acontece: definições, disputas (“por que isto é uma violação?”) e “o que mudou” desde o mês passado. Priorize pequenas melhorias de UX como tooltips, logs de mudança e rodapés claros sobre exclusões.
Se quiser lançar um MVP interno rapidamente (modelo de tenants, integrações, dashboards, exports) sem gastar semanas em boilerplate, uma abordagem de desenvolvimento assistido pode ajudar. Por exemplo, Koder.ai permite que equipes esbocem e iterem um app multi-tenant via chat — então exportem o código fonte e façam deploy. Isso se encaixa bem para produtos de relatório de SLA, onde a complexidade central é regras de domínio e normalização de dados, não scaffolding de UI.
Você pode usar o modo de planejamento do Koder.ai para delinear entidades (tenants, serviços, definições de SLA, eventos, rollups), depois gerar uma UI em React e um backend em Go/PostgreSQL que sirvam de base para integrar suas integrações e lógica de cálculo específicas.
Mantenha um documento vivo com próximos passos: novas integrações, formatos de export, trilhas de auditoria. Link para guias relacionados em /blog para que clientes e colegas possam se autoatender.
O relatório centralizado de SLA deve criar uma fonte única de verdade ao reunir disponibilidade, incidentes e cronogramas de tickets em uma única visão auditável.
Na prática, deve:
Comece com um conjunto pequeno que a maioria dos clientes reconheça, e só expanda quando puder explicar e auditar bem.
Métricas iniciais comuns:
Para cada métrica, documente o que ela mede, o que exclui e as fontes de dados necessárias.
Escreva as regras em linguagem simples primeiro, depois converta para lógica executável.
Normalmente você precisa definir:
Se duas pessoas não concordam na versão em sentenças, a versão em código será contestada depois.
Armazene todos os timestamps em UTC e converta na exibição segundo o fuso horário de relatório do cliente.
Também decida antecipadamente:
Seja explícito na UI (por exemplo, “Os cortes do período de relatório são em America/New_York”).
Use uma mistura, conforme frescor vs completude:
Uma regra prática: use webhooks quando a frescura importa e API pulls quando a completude importa.
Defina um pequeno conjunto canônico de eventos normalizados para que diferentes ferramentas mapeiem aos mesmos conceitos.
Exemplos:
incident_opened / incident_closedEscolha um modelo de multi-tenancy e imponha isolamento além da UI.
Proteções chave:
tenant_idAssuma que exports e jobs em background são os pontos mais fáceis de vazar dados se você não projetar com contexto de tenant.
Armazene tanto eventos brutos quanto resultados derivados para ser rápido e explicável.
Uma divisão prática:
Adicione um para que relatórios antigos possam ser reproduzidos exatamente após mudanças nas regras.
Faça o pipeline em estágios e idempotente:
Para confiabilidade:
Inclua três categorias de alertas para que o sistema seja operacional, não apenas um dashboard:
Reduza o ruído com deduplicação, horários de silêncio e escalonamento, e torne cada alerta acionável com reconhecimento e notas de resolução.
downtime_started / downtime_endedticket_created / first_response / resolvedInclua campos consistentes como tenant_id, service_id, source_system, external_id, severity e timestamps em UTC.
calculation_version