Antes de rabiscar telas ou escolher um banco de dados, esclareça para que o app serve, quem vai depender dele e o que significa “bom”. Apps de pontuação de fornecedores fracassam com mais frequência quando tentam agradar todo mundo ao mesmo tempo — ou quando não conseguem responder perguntas básicas como “Qual fornecedor estamos realmente avaliando?”
Objetivos, usuários e escopo
Quem usa (e o que eles precisam)
Comece nomeando seus grupos de usuários primários e as decisões do dia a dia deles:
- Compras precisa de um scorecard de fornecedor consistente, visões comparativas entre fornecedores e uma trilha de auditoria defensável para decisões de sourcing.
- Financeiro se importa com variação de custo, cumprimento de termos de pagamento e sinais de risco que afetam previsões.
- Operações quer resolução rápida de problemas: acompanhar incidentes, documentar ações corretivas e ver se a performance está melhorando.
- Fornecedores (portal opcional) querem visibilidade do feedback, uma forma de responder e clareza sobre como as pontuações são calculadas.
Um truque útil: escolha um “usuário central” (frequentemente compras) e desenhe a primeira versão em torno do fluxo de trabalho dele. Depois adicione o próximo grupo apenas quando você conseguir explicar qual nova capacidade isso libera.
Resultados-chave que você busca
Escreva resultados como mudanças mensuráveis, não como features. Resultados comuns incluem:
- Decisões de fornecedor melhores (ex.: listas de fornecedores preferidos baseadas em evidência, não em anedotas)
- Resolução de problemas mais rápida (propriedade clara, prazos e follow-ups)
- Avaliação mais consistente (menos variação entre avaliadores ou sites)
Esses resultados guiarão suas escolhas de acompanhamento de KPI e relatórios.
Defina o que “fornecedor” significa no seu sistema
“Fornecedor” pode significar coisas diferentes dependendo da estrutura organizacional e dos contratos. Decida cedo se um fornecedor é:
- uma entidade legal (empresa-mãe)
- um site/localização (útil quando qualidade varia por planta ou região)
- uma linha de serviço (ex.: logística vs. embalagens do mesmo fornecedor)
Sua escolha afeta tudo: consolidações de pontuação, permissões e até se uma instalação ruim deve impactar a relação geral.
Escolha a abordagem de pontuação
Existem três padrões comuns:
- KPIs ponderados: entradas numéricas (%, taxa de defeito) multiplicadas por pesos. Ótimo para transparência e automação.
- Rubricas: avaliadores selecionam níveis (ex.: “Excelente/Bom/Razoável/Ruim”) com texto de orientação. Ótimo quando os dados são qualitativos.
- Híbrido: KPIs para áreas mensuráveis + rubrica para colaboração, capacidade de resposta ou fit estratégico.
Torne o método de pontuação suficientemente compreensível para que um fornecedor (e um auditor interno) consiga acompanhá-lo.
Defina métricas de sucesso para o app
Escolha algumas métricas de nível de app para validar adoção e valor:
- Adoção: % de fornecedores ativos com pelo menos uma avaliação no último trimestre
- Completude da avaliação: campos obrigatórios preenchidos, evidências anexadas, KPIs fornecidos
- Tempo de ciclo: tempo desde abertura da avaliação → aprovação → compartilhamento com o fornecedor (se aplicável)
Com objetivos, usuários e escopo definidos, você terá uma base estável para o modelo de pontuação e o design de workflow que seguem.
Modelo de pontuação e design de KPIs
Um app de pontuação de fornecedores vive ou morre pela aderência da pontuação à experiência real das pessoas. Antes de construir telas, escreva os KPIs exatos, escalas e regras para que compras, operações e finanças interpretem os resultados da mesma forma.
Escolha um conjunto pequeno e defensável de KPIs
Comece com um núcleo que a maioria das equipes reconheça:
- Entrega no prazo (ex.: % de remessas dentro da janela acordada)
- Qualidade (taxa de defeito, taxa de devolução ou % de aprovação em inspeção)
- Aderência a SLA (tickets resolvidos dentro do tempo-alvo, uptime se relevante)
- Variação de custo (fatura vs. PO, cobranças não planejadas)
- Capacidade de resposta (tempo até primeira resposta, tempo para resolução de escalamentos)
Mantenha definições mensuráveis e vincule cada KPI a uma fonte de dados ou a uma questão de avaliação.
Defina escalas que as pessoas consigam explicar
Escolha 1–5 (fácil para humanos) ou 0–100 (mais granular) e defina o que cada nível significa. Por exemplo, “Entrega no prazo: 5 = ≥ 98%, 3 = 92–95%, 1 = < 85%.” Limiar claros reduzem discussões e tornam as avaliações comparáveis entre equipes.
Pesos, dados faltantes e regras de justiça
Atribua pesos por categoria (ex.: Entrega 30%, Qualidade 30%, SLA 20%, Custo 10%, Capacidade de resposta 10%) e documente quando os pesos mudam (tipos de contrato diferentes podem priorizar resultados diferentes).
Decida como lidar com dados faltantes:
- Excluir o KPI do denominador para aquele período, ou
- Aplicar um padrão neutro, ou
- Marcar a pontuação como “dados insuficientes” e bloquear o ranqueamento.
Seja qual for a escolha, aplique consistentemente e torne visível em visões de drill-down para que as equipes não confundam “faltando” com “bom”.
Múltiplos scorecards por fornecedor
Suporte mais de um scorecard por fornecedor para que as equipes possam comparar desempenho por contrato, região ou período. Isso evita que problemas isolados sejam diluídos por médias que cobrem tudo.
Disputas e correções
Documente como disputas afetam pontuações: se uma métrica pode ser corrigida retroativamente, se uma disputa marca temporariamente a pontuação e qual versão é considerada “oficial”. Mesmo uma regra simples como “pontuações recalculam quando uma correção é aprovada, com uma nota explicando a mudança” previne confusão depois.
Modelo de dados e noções básicas de esquema
Um modelo de dados limpo é o que mantém a pontuação justa, as avaliações rastreáveis e os relatórios críveis. Você quer responder perguntas simples de forma confiável — “Por que este fornecedor recebeu 72 este mês?” e “O que mudou desde o último trimestre?” — sem justificativas manuais ou planilhas espalhadas.
Entidades centrais (o que armazenar)
No mínimo, defina estas entidades:
- Vendor: perfil do fornecedor (nome, status, categoria, contatos)
- Contract: detalhes do acordo comercial e janelas de validade
- Order/Invoice (ou uma Transaction unificada): fatos operacionais que geram KPIs
- KPI Metric: definições como % de entrega no prazo, taxa de defeito, tempo de resposta
- Score: resultado calculado para um fornecedor em um período (geral e/ou por métrica)
- Review: feedback qualitativo, avaliações e evidências narrativas
- Attachment: arquivos vinculados a avaliações ou disputas (emails, fotos, PDFs)
Esse conjunto suporta tanto performance “dura” medida quanto feedback “suave” de usuários, que tipicamente precisam de workflows diferentes.
Relacionamentos (como os dados se conectam)
Modele os relacionamentos explicitamente:
- Vendor → Contracts: um vendor pode ter múltiplos contratos ao longo do tempo.
- Vendor → Orders/Invoices: transações normalmente são many-to-one para vendor.
- Score → Metric: scores devem ser rastreáveis até a definição do KPI e a versão do cálculo.
- Review → Period: avaliações precisam de um bucket temporal claro (mês/trimestre) para não flutuarem sem contexto.
Uma abordagem comum é:
scorecard_period (ex.: 2025-10)vendor_period_score (pontuação geral)vendor_period_metric_score (por métrica, inclui numerador/denominador se aplicável)
Campos que você vai agradecer por ter adicionado depois
Adicione campos de consistência across a maioria das tabelas:
- Timestamps:
created_at, updated_at, e para aprovações submitted_at, approved_at
- Autor e ator:
created_by_user_id, mais approved_by_user_id quando relevante
- Sistema de origem:
source_system e identificadores externos como erp_vendor_id, crm_account_id, erp_invoice_id
- Confiança/qualidade: um
confidence score ou data_quality_flag para marcar feeds incompletos ou estimativas
Isso alimenta trilhas de auditoria, tratamento de disputas e análises de compras confiáveis.
Retenção, versionamento e “o que mudou?”
Pontuações mudam porque dados chegam atrasados, fórmulas evoluem ou alguém corrige um mapeamento. Em vez de sobrescrever histórico, armazene versões:
- Mantenha uma versão de cálculo (ou
calculation_run_id) em cada linha de score.
- Registre reason codes para recalculação (fatura atrasada, atualização de definição de KPI, correção manual).
- Considere uma trilha de auditoria append-only para tabelas importantes (scores, reviews, aprovações) para mostrar quem mudou o quê e quando.
Para retenção, defina por quanto tempo você guarda transações brutas vs. scores derivados. Frequentemente você mantém scores derivados por mais tempo (menor armazenamento, alto valor analítico) e retém extratos brutos do ERP por uma janela de política menor.
Estratégia de identificadores para correspondência ERP/CRM
Trate IDs externas como campos de primeira classe, não como notas:
- Armazene tanto external ID quanto system name (ERP_A vs ERP_B).
- Aplique unicidade por sistema de origem (ex.:
unique(source_system, external_id)).
- Adicione tabelas de mapeamento leves quando fornecedores se fundem/dividem para que scores históricos permaneçam corretos.
Essa base torna seções posteriores — integrações, rastreamento de KPI, moderação de avaliações e auditabilidade — muito mais fáceis de implementar e explicar.
Ingestão de dados e integrações
Um app de pontuação é tão bom quanto os inputs que o alimentam. Planeje múltiplos caminhos de ingestão desde o dia 1, mesmo que comece com um. A maioria das equipes acaba precisando de uma mistura de entrada manual para casos de exceção, uploads em massa para dados históricos e sync por API para atualizações contínuas.
Fontes de dados comuns
Entrada manual é útil para fornecedores pequenos, incidentes pontuais ou quando uma equipe precisa registrar uma avaliação imediatamente.
Upload CSV ajuda a bootstrapar o sistema com desempenho passado, faturas, tickets ou registros de entrega. Faça uploads previsíveis: publique um template e versionamento para que mudanças não quebrem importações silenciosamente.
API sync costuma conectar ERPs/ferramentas de procurement (POs, receipts, invoices) e sistemas de serviço como helpdesks (tickets, violações de SLA). Prefira sync incremental (since last cursor) para evitar puxar tudo toda vez.
Validação que evita lixo entrando
Defina regras claras de validação na importação:
- Campos obrigatórios (vendor ID, data, nome/valor da métrica)
- Intervalos numéricos (ex.: scores 0–100, quantidades não-negativas)
- Detecção de duplicatas (mesmo vendor + métrica + período + source record ID)
Armazene linhas inválidas com mensagens de erro para que admins corrijam e reimportem sem perder contexto.
Correções, backfills e logs de recalculação
Importações estarão erradas às vezes. Dê suporte a re-runs (idempotentes por source IDs), backfills (períodos históricos) e logs de recalculação que registram o que mudou, quando e por quê. Isso é crítico para confiança quando a pontuação de um fornecedor se altera.
Agendamento e transparência
A maioria das equipes se vira bem com imports diários/semanais para métricas financeiras e de entrega, mais eventos near-real-time para incidentes críticos.
Exponha uma página administrativa amigável (ex.: /admin/imports) mostrando status, contagem de linhas, avisos e erros exatos — para que problemas sejam visíveis e corrigíveis sem ajuda de desenvolvedores.
Papéis, permissões e fluxo de aprovação
Papéis claros e um caminho de aprovação previsível previnem “caos no scorecard”: edições conflitantes, mudanças surpresa de nota e incerteza sobre o que um fornecedor pode ver. Defina regras de acesso cedo e as aplique consistentemente na UI e na API.
Tipos de papéis (e para que servem)
Um conjunto prático de papéis iniciais:
- Admin: gerencia configurações organizacionais, atribuições de papel, templates de pontuação e regras de moderação.
- Revisor interno: submete avaliações, evidências e rascunhos de atualização de score.
- Aprovador: valida ações sensíveis (publicar avaliações, travar períodos, aprovar mudanças de score).
- Usuário fornecedor: vê seu próprio scorecard, responde a avaliações e faz uploads de esclarecimentos (se permitido).
- Somente leitura: pode ver dashboards e perfis de fornecedor, mas não editar.
Permissões que mapeiam ações reais
Evite permissões vagas como “pode gerenciar fornecedores”. Em vez disso, controle capacidades específicas:
- Visualizar: quem pode ver avaliações, nomes de avaliadores, anexos e scores históricos.
- Editar: quem pode criar/editar rascunhos, mudar valores de KPI ou ajustar pesos.
- Publicar: quem pode mover conteúdo de rascunho para visível.
- Exportar: quem pode baixar relatórios (CSV/PDF) e em que escopo (fornecedor único vs. todos).
Considere dividir “exportar” em “exportar próprios fornecedores” vs. “exportar tudo”, especialmente para análises de compras.
Regras de visibilidade para fornecedores
Usuários fornecedores normalmente devem ver apenas seus próprios dados: seus scores, avaliações publicadas e status de itens abertos. Limite detalhes de identidade dos avaliadores por padrão (ex.: mostrar departamento ou função em vez do nome completo) para reduzir atritos interpessoais. Se permitir respostas do fornecedor, mantenha-as em thread e claramente rotuladas como fornecidas pelo fornecedor.
Fluxos de aprovação para confiança e consistência
Trate avaliações e mudanças de score como propostas até serem aprovadas:
- Revisor interno submete um rascunho de avaliação/atualização de score.
- Aprovador checa evidências, política e aprova, solicita mudanças ou rejeita.
- Somente itens aprovados afetam o score “atual” e ficam visíveis para Usuários Fornecedores.
Workflows com prazo ajudam: por exemplo, mudanças de score podem exigir aprovação apenas durante o fechamento mensal/trimestral.
Requisitos de trilha de auditoria
Para compliance e responsabilização, registre cada evento significativo: quem fez o quê, quando, de onde e o que mudou (valores antes/depois). Entradas de auditoria devem cobrir mudanças de permissão, edições de avaliação, aprovações, publicações, exportes e deleções. Faça a trilha de auditoria pesquisável, exportável para auditorias e protegida contra adulteração (armazenamento append-only ou logs imutáveis).
UX e telas principais
Prepare-se para dados reais
Crie fluxos administrativos compatíveis com importação para validar dados CSV e via API antes que afetem a pontuação.
Um app de pontuação de fornecedores vence ou perde pela facilidade com que usuários ocupados encontram o fornecedor certo, entendem a pontuação num relance e deixam feedback confiável sem fricção. Comece com um pequeno conjunto de telas “base” e faça cada número explicável.
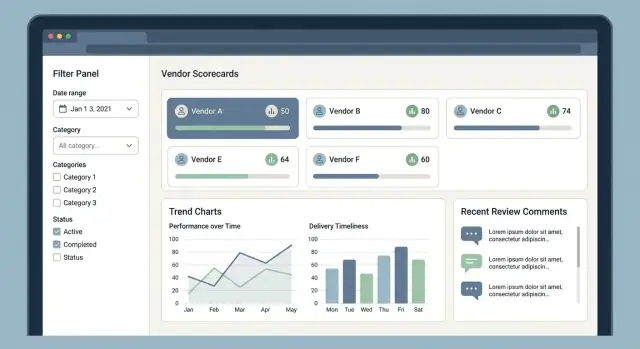
1) Lista de fornecedores (centro de comando)
Aqui começam a maioria das sessões. Mantenha o layout simples: nome do fornecedor, categoria, região, banda de score atual, status e última atividade.
Filtragem e busca devem ser instantâneas e previsíveis:
- Categoria, região, status (ativo/em espera/bloqueado)
- Intervalo de datas (ex.: última avaliação, último incidente de entrega)
- Banda de score (A/B/C ou faixas 0–100)
Salve visões comuns (ex.: “Fornecedores críticos na EMEA abaixo de 70”) para que times de compras não refaçam filtros todo dia.
2) Perfil do fornecedor (uma página, muitas respostas)
O perfil deve resumir “quem eles são” e “como estão indo”, sem forçar o usuário a entrar em muitas abas cedo. Coloque contatos e meta-dados contratuais ao lado de um resumo claro do score.
Mostre o score geral e a quebra por KPIs (qualidade, entrega, custo, conformidade). Cada KPI precisa de uma fonte visível: as avaliações, incidentes ou métricas subjacentes que o produziram.
Um bom padrão é:
- KPI → fórmula/peso → itens contribuidores → evidência (comentários, anexos, timestamps)
4) Avaliações e incidentes (entrada rápida, contexto forte)
Torne a entrada de avaliações mobile-friendly: alvos de toque grandes, campos curtos e comentário rápido. Sempre vincule avaliações a um período e (se relevante) a um PO, site ou projeto para que o feedback permaneça acionável.
5) Relatórios (prontos para decisão)
Relatórios devem responder perguntas comuns: “Quais fornecedores estão em queda?” e “O que mudou este mês?” Use gráficos legíveis, rótulos claros e navegação por teclado para acessibilidade.
Avaliações, comentários e moderação
As avaliações são onde o app fica realmente útil: capturam contexto, evidência e o “porquê” por trás dos números. Para mantê-las consistentes (e defensáveis), trate avaliações como registros estruturados primeiro, texto livre depois.
Tipos de avaliação que você deve suportar
Momentos diferentes pedem templates diferentes. Um conjunto inicial simples:
- Avaliações periódicas (mensal/trimestral): cadência regular para performance e tendência.
- Avaliações por incidente: vinculadas a atraso de entrega, defeito de qualidade ou problema de conformidade.
- Avaliações de encerramento de projeto: resumo final com lições aprendidas.
Cada tipo pode compartilhar campos comuns, mas permitir perguntas específicas, para que equipes não forcem um incidente num formulário trimestral.
Campos estruturados: torne avaliações pesquisáveis
Além do comentário narrativo, inclua entradas estruturadas que alimentem filtragem e relatórios:
- Tags e categorias (ex.: Logística, Qualidade, Comunicação)
- Forças e falhas (campos separados para evitar feedback unilateral)
- Itens de ação com responsável, data de vencimento e status
Essa estrutura transforma “feedback” em trabalho rastreável, não apenas texto num campo.
Tratamento de evidências (sem tornar doloroso)
Permita que avaliadores anexem provas onde escrevem a avaliação:
- Anexos de arquivo (fotos, PDFs)
- Links para docs compartilhados
- Referências a tickets / POs / orders (idealmente selecionáveis de uma lista)
Armazene meta-dados (quem fez upload, quando, a que se relaciona) para que auditorias não virem uma caça ao tesouro.
Moderação e histórico de edição
Mesmo ferramentas internas precisam de moderação. Adicione:
- Checagens básicas de profane/spam
- Regras de escalonamento para alegações sérias (ex.: segurança, fraude)
- Um histórico de edição que registre o que mudou e por quem (incluindo redacções)
Evite edições silenciosas — transparência protege tanto avaliadores quanto fornecedores.
Notificações, lembretes e SLAs de resposta
Defina regras de notificação desde o início:
- Avisar fornecedores quando uma avaliação é publicada (ou quando se solicita resposta)
- Enviar lembretes internos para itens de ação vencidos
- Definir um SLA para respostas (ex.: 5 dias úteis) com escalonamento após prazos perdidos
Feito direito, avaliações se tornam um workflow de feedback fechado em vez de uma reclamação pontual.
Arquitetura e escolhas de stack tecnológico
Configure o app principal
Gere um aplicativo web para fornecedores, scorecards, avaliações e relatórios em um único lugar.
Sua primeira decisão arquitetural é menos sobre “tech do momento” e mais sobre quão rápido você pode entregar uma plataforma confiável de pontuação e avaliações sem criar ônus de manutenção.
Se o objetivo é mover rápido, considere prototipar o workflow (vendors → scorecards → reviews → approvals → reports) em uma plataforma que gere um app funcional a partir de uma especificação clara. Por exemplo, Koder.ai é uma plataforma vibe-coding onde você pode construir web, backend e mobile via interface de chat, e então exportar o código-fonte quando estiver pronto para avançar. É uma forma prática de validar o modelo de pontuação e papéis/permissões antes de investir pesadamente em UI customizada e integrações.
Monolito vs. serviços modulares (mantenha simples)
Para a maioria das equipes, um monolito modular é o ponto ideal: um app deployável, organizado em módulos claros (Vendors, Scorecards, Reviews, Reporting, Admin). Você ganha desenvolvimento e debugging mais simples, além de deploys e segurança menos complexos.
Migre para serviços separados só quando houver razão forte — p.ex., cargas pesadas de reporting, múltiplos times de produto ou requisitos de isolamento estritos. Um caminho comum é: monolito agora, depois extrair “imports/reporting” se necessário.
Design de API (REST mapeando trabalho real)
Uma API REST é geralmente a mais fácil de entender e integrar com ferramentas de procurement. Mire em recursos previsíveis e alguns endpoints de “tarefas” onde o sistema faz trabalho pesado.
Exemplos:
/api/vendors (criar/atualizar vendors, status)/api/vendors/{id}/scores (score atual, breakdown histórico)/api/vendors/{id}/reviews (listar/criar reviews)/api/reviews/{id} (atualizar, ações de moderação)/api/exports (solicitar exports; retorna job id)
Mantenha operações pesadas (exports, recalcs em massa) assíncronas para a UI continuar responsiva.
Jobs em background (imports, recalculações, notificações)
Use uma fila de jobs para:
- importar dados de fornecedores (CSV/SFTP/API)
- recalcular scores quando KPIs, pesos ou reviews mudam
- enviar notificações (aviso de review, mudança de score, aprovação pendente)
Isso também ajuda a implementar retry automático e evita firefighting manual.
Cache para dashboards e relatórios pesados
Dashboards podem ser caros. Faça cache de métricas agregadas (por intervalo, categoria, unidade de negócio) e invalide em mudanças significativas, ou atualize por agenda. Isso mantém o “dashboard aberto” rápido preservando dados de drill-down precisos.
Documentação (para devs e admins)
Escreva docs de API (OpenAPI/Swagger serve) e mantenha um guia interno, amigável a administradores, em formato /blog — ex.: “Como a pontuação funciona”, “Como lidar com avaliações disputadas”, “Como gerar exports” — e linke isso do app para /blog para ser fácil de achar e manter atualizado.
Segurança, privacidade e confiabilidade
Dados de pontuação podem influenciar contratos e reputações, portanto controles de segurança devem ser previsíveis, auditáveis e fáceis de seguir por usuários não técnicos.
Autenticação e controle de acesso
Comece com opções de login apropriadas:
- Email/senha para times menores (use regras fortes de senha e MFA quando possível).
- SSO para empresas via SAML ou OIDC, para que acesso seja gerenciado e revogado centralmente.
Associe autenticação a RBAC: admins de compras, revisores, aprovadores e stakeholders somente leitura. Mantenha permissões granulares (ex.: “ver scores” vs “ver texto de avaliação”). Registre uma trilha de auditoria para mudanças de score, aprovações e edições.
Proteja dados sensíveis
Criptografe dados em trânsito (TLS) e em repouso (base + backups). Trate segredos (senhas DB, chaves API, certificados SSO) como itens de primeira classe:
- Armazene-os num vault gerenciado
- Rode rotações periódicas
- Nunca commit them no repositório
Prevenção de abuso e endpoints seguros
Mesmo se seu app for “interno”, endpoints públicos (reset de senha, links de convite, formulários de submissão) podem ser abusados. Adicione rate limiting e proteção contra bots (CAPTCHA ou risk scoring) onde fizer sentido, e restrinja APIs com tokens escopados.
Privacidade por design
Avaliações frequentemente contêm nomes, emails ou detalhes de incidentes. Minimize dados pessoais por padrão (campos estruturados em vez de texto livre), defina regras de retenção e ofereça ferramentas para redigir ou excluir conteúdo quando exigido.
Operações confiáveis sem vazar dados
Logue o suficiente para debugar (request IDs, latência, códigos de erro), mas evite capturar texto confidencial de avaliações ou anexos. Use monitoramento e alertas para imports falhos, erros de jobs de score e padrões de acesso incomuns — sem transformar logs num segundo banco de dados sensível.
Relatórios, dashboards e explicabilidade
Um app de pontuação vale pelo suporte às decisões. Relatórios devem responder três perguntas rapidamente: Quem está indo bem, comparado a quê, e por quê?
Visões de dashboard que funcionam para stakeholders ocupados
Comece com um dashboard executivo que resuma score geral, mudanças ao longo do tempo e uma quebra por categoria (qualidade, entrega, conformidade, custo, serviço, etc.). Linhas de tendência são críticas: um fornecedor com score ligeiramente menor mas em forte recuperação pode ser melhor que um scorer alto que está em queda.
Torne dashboards filtráveis por período, unidade/site, categoria de fornecedor e contrato. Use defaults consistentes (ex.: “últimos 90 dias”) para que duas pessoas vendo a mesma tela obtenham respostas comparáveis.
Benchmarking é poderoso — e sensível. Permita comparações entre fornecedores dentro da mesma categoria (ex.: “fornecedores de embalagem”) enquanto aplica permissões:
- Liderança de compras pode ver comparações nominais.
- Gerentes de site podem ver apenas fornecedores sob sua responsabilidade.
- Stakeholders gerais podem ver ranks anonimizados ou quartis.
Isso evita divulgação acidental mantendo suporte a decisões de seleção.
Relatórios de drill-down: do score à fonte
Dashboards devem linkar para relatórios de drill-down que expliquem movimentos de score:
- Por período: rollups mensais/trimestrais com deltas de KPI.
- Por site: destaque problemas específicos por local (entregas atrasadas numa planta).
- Por contrato: mostre se a performance está alinhada com SLAs e termos comerciais.
Um bom drill-down termina com “o que aconteceu”: avaliações relacionadas, incidentes, tickets ou registros de remessa.
Exports para compartilhamento interno
Suporte CSV para análise e PDF para compartilhamento. Exports devem espelhar filtros da tela, incluir timestamp e opcionalmente adicionar uma marca-d’água de uso interno (e identidade do visualizador) para desencorajar repasses fora da organização.
Explicabilidade: mostre como a pontuação foi construída
Evite scores em “caixa preta”. Cada score deve ter uma decomposição clara:
- Contribuições dos KPIs (pesos, valores brutos, normalização)
- Penalidades/bonificações aplicadas (ex.: problema crítico de conformidade)
- Notas de cálculo e versão (para auditoria quando fórmulas mudam)
Quando usuários veem os detalhes do cálculo, disputas se resolvem mais rápido — e planos de melhoria ficam mais fáceis de alinhar.
Testes e verificações de qualidade
Crie um MVP de Avaliação de Fornecedores
Prototipe seu fluxo de avaliação de fornecedores no Koder.ai antes de iniciar a construção completa.
Testar um app de pontuação não é só achar bugs — é proteger confiança. Times de compras precisam ter certeza de que um score está correto, e fornecedores precisam de garantia de que avaliações e aprovações são tratadas de forma consistente.
Crie dados de teste que reflitam a bagunça da vida real
Comece criando datasets pequenos e reutilizáveis que incluam casos de borda: KPIs faltando, submissões tardias, valores conflitantes entre imports e disputas (ex.: um fornecedor contesta um resultado de SLA). Inclua casos onde um fornecedor não tem atividade num período ou onde KPIs existem mas devem ser excluídos por datas inválidas.
Seus cálculos de pontuação são o coração do produto, então teste-os como uma fórmula financeira:
- Regras de ponderação (incluindo pesos que não somam 100% e como lidar com isso)
- Comportamento de arredondamento e empates em ranking
- Limiar (quando um KPI passa de “bom” para “precisa atenção”)
- Testes de regressão para qualquer mudança na definição de KPI
Testes unitários devem afirmar não só scores finais, mas componentes intermediários (score por KPI, normalização, penalidades/bonificações) para facilitar debugging.
Testes de integração devem simular fluxos ponta a ponta: importar um scorecard, aplicar permissões e garantir que apenas papéis corretos possam ver, comentar, aprovar ou escalar uma disputa. Inclua testes para entradas da trilha de auditoria e ações bloqueadas (ex.: fornecedor tentando editar avaliação aprovada).
Realize testes de aceitação com compras e um grupo piloto de fornecedores. Mapeie momentos confusos e atualize textos da UI, validações e dicas de ajuda.
Finalmente, rode testes de performance para picos (fechamento de mês/trimestre), focando em tempo de carregamento de dashboards, exports em massa e jobs de recalculação concorrentes.
Plano de lançamento e roadmap de iteração
Um app de pontuação só funciona quando as pessoas o usam. Isso geralmente significa entregar em fases, substituir planilhas cuidadosamente e alinhar expectativas sobre o que vai mudar (e quando).
Lançamento em fases que constrói confiança
Comece com a menor versão que ainda gere scorecards úteis.
Fase 1: scorecards internos apenas. Dê a compras e stakeholders um lugar limpo para registrar valores de KPI, gerar um scorecard e deixar notas internas. Mantenha o workflow simples e foque em consistência.
Fase 2: acesso dos fornecedores. Quando a pontuação interna estiver estável, convide fornecedores para ver seus próprios scorecards, responder a feedbacks e adicionar contexto (ex.: “atraso causado por fechamento de porto”). Aqui permissões e trilha de auditoria importam.
Fase 3: automação. Adicione integrações e recalculação agendada quando você confiar no modelo de pontuação. Automatizar cedo demais pode amplificar dados ruins ou definições pouco claras.
Se quiser encurtar o tempo até um piloto, plataformas como Koder.ai podem ajudar: você pode levantar o workflow central (papéis, aprovação de reviews, scorecards, exports) rapidamente, iterar com stakeholders em “modo planejamento” e exportar o código quando quiser endurecer integrações e controles de compliance.
Se estiver substituindo planilhas, planeje uma transição gradual em vez de big-bang.
Forneça templates de importação que espelhem colunas existentes (nome do fornecedor, período, valores de KPI, revisor, notas). Adicione ajudantes de importação como erros de validação (“vendor desconhecido”), previews e modo dry-run.
Decida também se vai migrar histórico completo ou apenas períodos recentes. Frequentemente importar os últimos 4–8 trimestres é suficiente para tirar vantagem de análises de tendência sem transformar a migração numa arqueologia de dados.
Materiais de treinamento que as pessoas realmente leem
Mantenha o treinamento curto e por papel:
- Guias de uma página para revisores, aprovadores e admins
- Dicas in-app no primeiro uso (como pontuar, onde deixar contexto, o que “submeter” significa)
- Um checklist de admin: criar categorias, definir KPIs, configurar ciclos de avaliação e verificar acessos
Manutenção contínua e iteração
Trate definições de pontuação como produto. KPIs mudam, categorias se expandem e pesos evoluem.
Defina uma política de recalculo desde o início: o que acontece se uma definição de KPI mudar? Você recalcula históricos ou preserva resultados originais para auditoria? Muitas equipes mantêm resultados históricos e recalculam apenas a partir de uma data efetiva.
Próximos passos: precificação e empacotamento
Ao passar do piloto, decida o que entra em cada tier (número de fornecedores, ciclos de avaliação, integrações, reporting avançado, acesso ao portal de fornecedores). Se estiver formalizando um plano comercial, descreva pacotes e linke para /pricing para detalhes.
Se estiver avaliando construir vs comprar vs acelerar, trate “quão rápido podemos lançar um MVP confiável?” como um insumo de empacotamento. Plataformas como Koder.ai (com tiers do free ao enterprise) podem ser uma ponte prática: construir e iterar rápido, hospedar e ainda manter a opção de exportar e possuir o código-fonte completo quando o programa de pontuação maturar.