19 de mai. de 2025·8 min
Crie um Web App para Analisar Cancelamentos e Testar Retenção
Aprenda a planejar, construir e lançar um web app que acompanha cancelamentos de assinaturas, analisa motivos e executa experimentos de retenção de forma segura.
O que você vai construir e por que importa
Cancelamentos são um dos momentos de maior sinal em um negócio de assinaturas. Um cliente está explicitamente dizendo “isso não vale mais a pena”, muitas vezes logo após encontrar fricção, decepção ou um desalinhamento preço/valor. Se você tratar o cancelamento apenas como uma mudança de status, perde uma chance rara de aprender o que está quebrando — e de consertar.
O problema que você está resolvendo
A maioria das equipes vê o churn apenas como um número mensal. Isso esconde a história:
- Quem está cancelando (novos usuários vs clientes de longo prazo, tipo de plano, segmento)
- Quando cancelam (dia 1, após trial, depois de aumento de preço, após cobrança falhada)
- Por que cancelam (muito caro, faltam recursos, bugs, migração para concorrente, “não uso”)
Isto é o que análise de cancelamentos de assinatura significa na prática: transformar um clique de cancelamento em dados estruturados que você pode confiar e fatiar.
O que “experimentos de retenção” significam
Quando você consegue enxergar padrões, pode testar mudanças projetadas para reduzir churn — sem achismos. Experimentos de retenção podem ser mudanças de produto, preço ou mensagem, como:
- melhorar o fluxo de cancelamento (opções mais claras, caminhos melhores para downgrade)
- oferecer um plano de pausa ou desconto para o segmento certo
- corrigir lacunas no onboarding que se correlacionam com cancelamentos precoces
A chave é medir o impacto com dados limpos e comparáveis (por exemplo, um teste A/B).
O que você vai construir neste guia
Você vai construir um sistema pequeno com três partes conectadas:
- Rastreamento: eventos ao redor do ciclo de vida da assinatura e do fluxo de cancelamento, incluindo motivos.
- Um painel: funis, coortes e segmentos que revelam de onde vem o churn.
- Um loop de experimentos: capacidade de rodar testes segmentados e ver se o churn realmente cai.
Ao final, você terá um fluxo que vai de “tivemos mais cancelamentos” para “este segmento específico cancela após a semana 2 por causa de X — e esta mudança reduziu o churn em Y%”.
Como o sucesso se parece
Sucesso não é um gráfico mais bonito — é velocidade e confiança:
- Insights mais rápidos (dias, não meses)
- Redução mensurável de churn atrelada a mudanças específicas
- Aprendizado repetível: cada cancelamento ensina algo acionável
Estabeleça metas, métricas e escopo para o MVP
Antes de construir telas, rastreamento ou painéis, deixe dolorosamente claro quais decisões esse MVP deve habilitar. Um app de analytics de cancelamento tem sucesso quando responde algumas perguntas de alto valor rapidamente — não quando tenta medir tudo.
Comece pelas perguntas que geram ação
Anote as perguntas que você quer responder no primeiro release. Boas perguntas de MVP são específicas e levam a passos óbvios, por exemplo:
- Quais são os principais motivos de cancelamento, e como diferem por plano, região ou canal de aquisição?
- Quanto tempo leva para os clientes cancelarem (time-to-cancel), e que padrões aparecem nos primeiros 7/30/90 dias?
- Quais planos (ou ciclos de cobrança) têm maior taxa de cancelamento, e os usuários fazem downgrade antes de cancelar?
Se uma pergunta não influencia uma mudança de produto, playbook de suporte ou experimento, deixe para depois.
Escolha 3–5 métricas “norte” para o MVP
Escolha uma lista curta que você revisará semanalmente. Mantenha definições sem ambiguidades para que produto, suporte e liderança falem dos mesmos números.
Métricas iniciais típicas:
- Taxa de cancelamento (em um período definido, ex.: semanal/mensal)
- Taxa de salvamento (share das tentativas de cancelamento que viram um resultado retido)
- Taxa de reativação (clientes que voltam após cancelar)
- Tempo até o cancelamento (mediana de dias desde o início até o cancelamento)
- Distribuição de motivos (principais motivos por volume e por impacto de receita)
Para cada métrica, documente a fórmula exata, janela temporal e exclusões (trials, reembolsos, cobranças falhadas).
Nomeie responsáveis e restrições
Identifique quem usará e manterá o sistema: produto (decisões), suporte/success (qualidade dos motivos e follow-ups), dados (definições e validação) e engenharia (instrumentação e confiabilidade).
Depois concordem sobre restrições: requisitos de privacidade (minimização de PII, limites de retenção), integrações obrigatórias (provedor de cobrança, CRM, ferramenta de suporte), prazo e orçamento.
Escreva um escopo de uma página para frear feature creep
Mantenha curto: objetivos, usuários primários, as 3–5 métricas, integrações “must-have” e uma lista clara de non-goals (ex.: “sem suíte BI completa”, “sem atribuição multi-toque na v1”). Essa página vira seu contrato de MVP quando surgirem novos pedidos.
Modele assinaturas e eventos do ciclo de vida
Antes de analisar cancelamentos, você precisa de um modelo de assinatura que reflita como os clientes realmente se movem pelo produto. Se seus dados só armazenam o status atual da assinatura, terá dificuldade em responder perguntas básicas como “Quanto tempo ficaram ativos antes de cancelar?” ou “Downgrades previram churn?”.
Mapeie o ciclo de vida que você vai medir
Comece com um mapa de ciclo de vida simples e explícito que toda a equipe concorde:
Trial → Ativo → Downgrade → Cancelado → Win-back
Você pode adicionar mais estados depois, mas mesmo essa cadeia básica força clareza sobre o que conta como “ativo” (pago? dentro do período de carência?) e o que conta como “win-back” (reativado em 30 dias? qualquer tempo?).
Defina as entidades principais
Ao mínimo, modele estas entidades para que eventos e dinheiro possam ser ligados de forma consistente:
- Usuário: a pessoa que usa o app (pode mudar com o tempo)
- Conta: o contêiner de cobrança/cliente (frequentemente a unidade correta para churn)
- Assinatura: o acordo que pode iniciar, renovar, trocar ou terminar
- Plano: o nível de produto (nome, preço, intervalo de cobrança)
- Fatura: o que foi cobrado, quando e se foi paga/reembolsada
- Evento de cancelamento: quando o cancelamento foi solicitado e quando entrou em vigor
Escolha identificadores estáveis (account_id vs user_id)
Para analytics de churn, account_id costuma ser o identificador primário mais seguro porque usuários podem mudar (funcionários saem, admins trocam). Você ainda pode atribuir ações a user_id, mas agregue retenção e cancelamentos no nível da conta, a menos que venda assinaturas pessoais.
Armazene histórico de status, não apenas um status
Implemente um histórico de status (effective_from/effective_to) para poder consultar estados passados de forma confiável. Isso torna possível análise por coorte e comportamento pré-cancelamento.
Planeje casos de borda antecipadamente
Modele explicitamente estes casos para que não poluam os números de churn:
- Pausas (parada temporária sem cancelamento)
- Reembolsos/chargebacks (reversão de pagamento vs churn voluntário)
- Trocas de plano (upgrade/downgrade como eventos, não “novas assinaturas”)
- Períodos de carência (cobrança falhada vs cancelamento verdadeiro)
Instrumente o fluxo de cancelamento (eventos e motivos)
Se você quer entender churn (e melhorar retenção), o fluxo de cancelamento é seu momento de verdade mais valioso. Instrumente-o como uma superfície de produto, não como um formulário — cada passo deve produzir eventos claros e comparáveis.
Rastreie os passos-chave (e torne-os inescapáveis)
No mínimo, capture uma sequência limpa para que você possa montar um funil depois:
cancel_started— usuário abre a experiência de cancelamentooffer_shown— qualquer oferta de salvamento, opção de pausa, caminho de downgrade ou CTA “falar com suporte” é exibidaoffer_accepted— usuário aceita uma oferta (pausa, desconto, downgrade)cancel_submitted— cancelamento confirmado
Esses nomes de evento devem ser consistentes entre web/mobile e estáveis no tempo. Se você evoluir o payload, aumente a versão do schema (ex.: schema_version: 2) em vez de mudar significados silenciosamente.
Capture contexto que explica por que aconteceu
Todo evento relacionado a cancelamento deve incluir os mesmos campos de contexto para que você possa segmentar sem adivinhações:
- plano, tempo de contrato, preço
- país, dispositivo
- canal de aquisição
Mantenha-os como propriedades no evento (não inferidos depois) para evitar quebra de atribuição quando outros sistemas mudarem.
Colete motivos de churn que você possa analisar e ler
Use uma lista de motivos predefinida (para gráficos) mais um texto livre opcional (para nuance).
cancel_reason_code(ex.:too_expensive,missing_feature,switched_competitor)cancel_reason_text(opcional)
Armazene o motivo em cancel_submitted, e considere também logá-lo quando for selecionado pela primeira vez (ajuda a detectar indecisão ou comportamento de vai-e-volta).
Não pare no cancelamento: rastreie resultados
Para medir intervenções de retenção, registre desfechos posteriores:
reactivateddowngradedsupport_ticket_opened
Com esses eventos, você pode conectar a intenção de cancelamento a resultados — e rodar experimentos sem discutir o que os dados “realmente significam”.
Projete seu pipeline de dados e armazenamento
Boa analytics de churn começa com decisões chatas bem feitas: onde os eventos vivem, como são limpos e como todos concordam sobre o que é “um cancelamento”.
Escolha armazenamento: OLTP + (opcional) warehouse
Para a maioria dos MVPs, armazene eventos brutos primeiro no banco de dados do app (OLTP). É simples, transacional e fácil de consultar para debug.
Se você espera alto volume ou relatórios pesados, adicione um warehouse de analytics depois (replica de leitura Postgres, BigQuery, Snowflake, ClickHouse). Um padrão comum: OLTP como “fonte da verdade” + warehouse para painéis rápidos.
Tabelas principais que você vai querer
Projete tabelas em torno do “o que aconteceu” em vez de “o que você acha que vai precisar”. Um conjunto mínimo:
events: uma linha por evento rastreado (ex.:cancel_started,offer_shown,cancel_submitted) comuser_id,subscription_id, timestamps e propriedades JSON.cancellation_reasons: linhas normalizadas para seleções de motivo, incluindo texto livre opcional.experiment_exposures: quem viu qual variante, quando e em que contexto (feature flag / nome do teste).
Essa separação mantém seu analytics flexível: você pode juntar motivos e experimentos a cancelamentos sem duplicar dados.
Eventos tardios, duplicatas e idempotência
Fluxos de cancelamento geram retries (botão voltar, problemas de rede, refresh). Adicione uma idempotency_key (ou event_id) e imponha unicidade para que o mesmo evento não seja contado duas vezes.
Decida também uma política para eventos tardios (mobile/offline): tipicamente aceite-os, mas use o timestamp original do evento para análise e o tempo de ingestão para debug.
ETL/ELT para performance de relatórios
Mesmo sem um warehouse completo, crie um job leve que gere “tabelas de reporting” (agregados diários, passos de funil, snapshots de coorte). Isso mantém painéis rápidos e reduz joins caros em eventos brutos.
Documente definições para garantir que métricas batam
Escreva um dicionário de dados curto: nomes de eventos, propriedades obrigatórias e fórmulas de métricas (ex.: “taxa de churn usa cancel_effective_at”). Coloque no repositório ou docs internos para que produto, dados e engenharia interpretem gráficos da mesma forma.
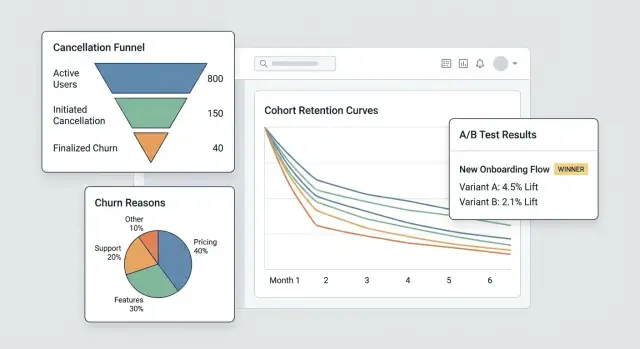
Construa o painel: funis, coortes e segmentos
Expanda para Mobile
Crie um app complementar em Flutter para que equipes de suporte ou sucesso possam revisar o contexto de cancelamento.
Um bom painel não tenta responder todas as perguntas de uma vez. Deve ajudar a ir de “algo parece errado” para “aqui está o grupo e o passo exatos causando isso” em alguns cliques.
Visões principais que você vai usar toda semana
Comece com três visões que espelham como as pessoas investigam churn na prática:
- Funil de cancelamento: de
cancel_started→ motivo selecionado →offer_shown→offer_acceptedoucancel_submitted. Isso revela onde as pessoas abandonam e onde seu fluxo de salvamento está (ou não) funcionando. - Distribuição de motivos: quebra dos motivos selecionados, com um bucket “Outros (texto livre)” que pode ser amostrado. Mostre contagens e % para que picos sejam óbvios.
- Coortes por mês de início: taxa de retenção ou cancelamento por mês de início da assinatura. Coortes dificultam que você se engane com sazonalidade ou mudanças no mix de aquisição.
Segmentos que tornam insights acionáveis
Todo gráfico deve ser filtrável pelos atributos que afetam churn e aceitação de salvamento:
- Plano ou tier
- Tenure (ex.: 0–7 dias, 8–30, 31–90, 90+)
- Região / país
- Fonte de aquisição (orgânico, pago, parceiro, vendas)
- Método de pagamento (cartão, boleto/fatura, PayPal, etc.)
Mantenha a vista padrão “Todos os clientes”, mas lembre-se: o objetivo é localizar qual fatia está mudando, não apenas se o churn se moveu.
Controles de tempo e performance do “fluxo de salvamento”
Adicione presets rápidos de data (últimos 7/30/90 dias) além de intervalo customizado. Use o mesmo controle de tempo em todas as views para evitar comparações desalinhadas.
Para trabalho de retenção, trate o fluxo de salvamento como um mini-funil com impacto de negócio:
- Visualizações de oferta
- Taxa de aceitação de ofertas
- MRR líquido retido (MRR mantido após descontos, créditos ou downgrades)
Drill-down sem quebrar a confiança
Todo gráfico agregado deve suportar drill-down para uma lista de contas afetadas (ex.: “clientes que selecionaram ‘Muito caro’ e cancelaram em até 14 dias”). Inclua colunas como plano, tenure e última fatura.
Proteja o drill-down por permissões (controle baseado em funções) e considere mascarar campos sensíveis por padrão. O painel deve permitir investigação respeitando privacidade e regras internas de acesso.
Adicione um framework de experimentos (A/B e segmentação)
Se você quer reduzir cancelamentos, precisa de uma forma confiável de testar mudanças (copy, ofertas, timing, UI) sem discutir com base em opiniões. Um framework de experimentos é o “controlador de tráfego” que decide quem vê o quê, registra e conecta desfechos a uma variante específica.
1) Defina a unidade do experimento (evite contaminação)
Decida se a atribuição acontece no nível de conta ou usuário.
- Nível de conta é geralmente mais seguro para SaaS: todos no mesmo workspace veem a mesma variante, evitando mensagens misturadas e contaminação de resultados.
- Nível de usuário pode funcionar para apps consumer, mas cuidado com dispositivos compartilhados, múltiplos logins ou contas de equipe.
Registre essa escolha por experimento para que a análise seja consistente.
2) Escolha um método de atribuição
Suporte alguns modos de segmentação:
- Aleatório (A/B clássico): melhor default.
- Ponderado (ex.: 90/10): útil para rollouts cautelosos.
- Regras: mostrar variante só a segmentos específicos (plano, país, tenure, estado “prestes a cancelar”). Mantenha regras simples e versionadas.
3) Registre exposição quando ela realmente acontecer
Não conte “atribuído” como “exposto”. Registre exposição quando o usuário realmente vê a variante (ex.: tela de cancelamento renderizada, modal de oferta aberto). Armazene: experiment_id, variant_id, id da unidade (account/user), timestamp e contexto relevante (plano, número de assentos).
4) Defina métricas: primária + guardrails
Escolha uma métrica primária de sucesso, como taxa de salvamento (cancel_started → desfecho retido). Adicione guardrails para evitar “vitórias” nocivas: contatos de suporte, pedidos de reembolso, taxa de reclamação, tempo até cancelamento ou churn por downgrade.
5) Planeje duração e suposições de amostragem
Antes de lançar, decida:
- Tempo mínimo de execução (frequentemente 1–2 ciclos de cobrança para comportamento de assinatura)
- Tamanho mínimo de amostra baseado na taxa atual de salvamento e no menor ganho que você quer detectar
Isso evita parar cedo por causa de ruído e ajuda o painel a mostrar “ainda aprendendo” vs. “estatisticamente útil”.
Projete intervenções de retenção para testar
Tenha o Código-Fonte
Exporte o código-fonte completo e adapte o modelo de dados, permissões e UI às suas necessidades.
Intervenções de retenção são as “coisas que você mostra ou oferece” durante o cancelamento que podem mudar a decisão — sem fazer o usuário se sentir enganado. O objetivo é aprender quais opções reduzem churn mantendo a confiança.
Variantes comuns para testar
Comece com um pequeno menu de padrões que você pode combinar:
- Ofertas alternativas: desconto por tempo limitado, mês grátis ou extensão de trial
- Opção de pausa: permitir pausar cobrança por 1–3 meses (com expectativas claras de reativação)
- Downgrade de plano: migrar para um tier mais barato ou menos assentos em vez de cancelar totalmente
- Copy da mensagem: copy curta e específica que relembra valor (“Exporte seus dados a qualquer momento”) vs copy genérica (“Lamentamos vê-lo partir”)
Projete ofertas que não prendam usuários
Deixe cada escolha clara e reversível quando possível. O caminho “Cancelar” deve ser visível e não exigir caça. Se oferecer desconto, diga exatamente por quanto tempo ele vale e para que preço voltará depois. Se oferecer pausa, mostre o que acontece com acesso e datas de cobrança.
Uma boa regra: o usuário deve conseguir explicar em uma frase o que escolheu.
Use disclosure progressivo
Mantenha o fluxo leve:
-
Peça um motivo (um toque)
-
Mostre uma resposta personalizada (pausa para “muito caro”, downgrade para “não uso o suficiente”, suporte para “bugs”)
-
Confirme o resultado final (pausa/downgrade/cancelamento)
Isso reduz fricção mantendo a experiência relevante.
Adicione uma página de resultados e um changelog
Crie uma página interna de resultados de experimento que mostre: conversão para resultado “salvo”, taxa de churn, lift vs controle e um intervalo de confiança ou regras simples de decisão (ex.: “ship se lift ≥ 3% e amostra ≥ 500”).
Mantenha um changelog do que foi testado e lançado, para que testes futuros não repitam ideias antigas e você possa conectar mudanças de retenção a alterações específicas.
Privacidade, segurança e controle de acesso
Dados de cancelamento são alguns dos mais sensíveis que você vai tratar: frequentemente incluem contexto de cobrança, identificadores e textos livres que podem conter detalhes pessoais. Trate privacidade e segurança como requisitos de produto, não como algo secundário.
Autenticação e papéis
Comece com acesso autenticado apenas (SSO se possível). Depois adicione papéis simples e explícitos:
- Admin: gerencia configurações, retenção de dados, acesso e exports.
- Analista: vê painéis, cria segmentos, roda experimentos.
- Suporte: vê histórico de cliente necessário para ajudar (campos limitados).
- Apenas leitura: vê dashboards agregados sem drill-down.
Faça checagens de papéis no servidor, não só na UI.
Minimize exposição de dados sensíveis
Limite quem pode ver registros a nível de cliente. Prefira agregados por padrão, com drill-down por trás de permissões mais fortes.
- Masque identificadores (email, ID do cliente) na UI quando possível.
- Hash identificadores para joins e deduplicação (ex.: SHA-256 com salt secreto) para que analistas segmetem sem ver PII cru.
- Separe tabelas de “cobrança/identidade” das tabelas de eventos analíticos, conectadas por uma chave hash.
Regras de retenção de dados
Defina retenção antecipadamente:
- Mantenha dados de evento só o tempo necessário para análise por coorte (ex.: 13–18 meses).
- Aplique retenção ou redação mais curta para textos livres de motivo de cancelamento, que podem incluir informação pessoal acidental.
- Forneça fluxos de exclusão para honrar pedidos de usuários e políticas internas.
Logs de auditoria
Registre acessos e exports do painel:
- Quem visualizou páginas a nível de cliente
- Quem exportou dados, quando e quais filtros foram usados
- Mudanças administrativas em retenção e permissões
Checklist de segurança para lançamento
Cubra o básico antes de enviar: riscos OWASP mais comuns (XSS/CSRF/injection), TLS em todos os pontos, contas de banco com privilégio mínimo, gerenciamento de segredos (sem chaves no código), rate limiting em endpoints de auth e procedimentos testados de backup/restore.
Blueprint de Implementação (Frontend, Backend e Testes)
Esta seção mapeia a construção em três partes — backend, frontend e qualidade — para você entregar um MVP consistente, rápido o bastante para uso real e seguro para evoluir.
Backend: assinaturas, eventos e experimentos
Comece com uma API pequena que suporte CRUD de assinaturas (criar, atualizar status, pausar/retomar, cancelar) e armazene datas chave do ciclo de vida. Mantenha paths de escrita simples e validados.
Depois, adicione um endpoint de ingestão de eventos para rastrear ações como “abriu página de cancelamento”, “selecionou motivo” e “confirmou cancelamento”. Prefira ingestão server-side (do backend) quando possível para reduzir bloqueios por ad-blockers e adulteração. Se precisar aceitar eventos do cliente, assine requisições e aplique rate-limit.
Para experimentos de retenção, implemente atribuição de experimento server-side para que a mesma conta sempre receba a mesma variante. Um padrão típico: buscar experimentos elegíveis → hash (account_id, experiment_id) → atribuir variante → persistir a atribuição.
Se quiser prototipar rápido, uma plataforma de vibe-coding como Koder.ai pode gerar a fundação (dashboard React, backend em Go, schema PostgreSQL) a partir de uma especificação curta em chat — então você exporta o código-fonte e adapta o modelo de dados, contratos de evento e permissões conforme necessário.
Frontend: painel, filtros e exports
Construa algumas páginas de painel: funis (cancel_started → offer_shown → cancel_submitted), coortes (por mês de signup) e segmentos (plano, país, canal de aquisição). Mantenha filtros consistentes entre páginas.
Para compartilhamento controlado, forneça export CSV com proteções: exportar só resultados agregados por padrão, exigir permissão elevada para exports por linha e registrar exports para auditoria.
Noções básicas de performance
Use paginação para listas de eventos, indexe filtros comuns (data, subscription_id, plano) e adicione pré-agregações para gráficos pesados (contagens diárias, tabelas de coorte). Faça cache de resumos dos “últimos 30 dias” com TTL curto.
Testes e confiabilidade
Escreva testes unitários para definições de métricas (ex.: o que conta como “cancelamento iniciado”) e para consistência de atribuição (a mesma conta sempre cai na mesma variante).
Para falhas de ingestão, implemente retries e uma dead-letter queue para evitar perda silenciosa de dados. Exponha erros em logs e em uma página admin para poder consertar antes que distorçam decisões.
Deploy, monitoramento e manutenção da confiança nos dados
Construa seu MVP no chat
Descreva seu MVP de análise de cancelamentos no chat e gere rapidamente a base de um app funcional.
Lançar o app de analytics de cancelamento é só metade do trabalho. A outra metade é mantê-lo preciso enquanto seu produto e experimentos mudam semanalmente.
Escolha uma abordagem de deploy
Escolha a opção mais simples que combine com o estilo da sua equipe:
- Hosting gerenciado (PaaS): caminho mais rápido para produção se você quiser deploys, logs e escalonamento embutidos.
- Containers (Docker + orquestrador): melhor quando precisa de builds repetíveis e controle de dependências.
- Serverless: ótimo para cargas spiky (ingestão de eventos, jobs agendados), mas fique atento a cold starts e limites do provedor.
Trate o app de analytics como um sistema de produção: versionamento, deploys automatizados e config em variáveis de ambiente.
Se não quiser tocar a pipeline completa no primeiro dia, Koder.ai também pode cuidar do deploy e hosting (incluindo domínios customizados) e suporta snapshots e rollback — útil quando itera rápido em um fluxo sensível como cancelamento.
Separe ambientes (e dados)
Crie dev, staging e production com isolamento claro:
- Bancos e buckets separados para que eventos de teste não contaminem métricas.
- Um ambiente staging que espelhe schema e roteamento de produção.
- Namespaces de experimento distintos (ex.: prefixar IDs de experimento em non-prod) para evitar “variantes fantasmas” nos painéis.
Monitoramento que protege a tomada de decisão
Você não monitora só uptime — monitora verdade:
- Uptime/health da API, workers em background e painel.
- Lag de ingestão (tempo do evento vs tempo processado) com alertas quando oscila.
- Erros de atribuição de experimento: picos em “unassigned units”, desequilíbrio de variantes ou mudança de atribuição para a mesma conta.
Jobs automáticos de validação de dados
Agende checagens leves que disparam alto:
- Eventos-chave faltando (ex.:
cancel_startedsemcancel_submitted, quando esperado). - Mudanças de schema (novas/propriedades removidas, tipos diferentes, enums inesperados).
- Anomalias de volume (eventos caem para quase zero após um release).
Plano de rollback para mudanças na UI de experimentos
Para qualquer experimento que toque o fluxo de cancelamento, preplaneje rollback:
- Feature flags para desabilitar variantes instantaneamente.
- Caminho rápido para redeploy da última build conhecida boa.
- Nota no painel que marca a janela de rollback para que analistas não interpretem dados incorretamente.
Operar o sistema: do insight a experimentos contínuos
Um app de analytics de cancelamento só compensa quando vira hábito, não um relatório pontual. O objetivo é transformar “notamos churn” em um loop contínuo de insight → hipótese → teste → decisão.
Rode uma cadência semanal simples
Escolha um horário consistente por semana (30–45 minutos) e mantenha o ritual leve:
- Revise o painel por mudanças em métricas chave (churn geral, churn por plano, churn por tenure e principais motivos).
- Aponte uma anomalia para investigar (ex.: pico de churn em renovações anuais, ou um motivo que subiu repentinamente para #1).
- Escolha exatamente uma hipótese para testar na semana seguinte.
Limitar a uma hipótese força clareza: o que acreditamos que está acontecendo, quem é afetado e qual ação pode mudar o resultado?
Priorize experimentos (impacto × esforço)
Evite rodar muitos testes ao mesmo tempo — especialmente no fluxo de cancelamento — porque mudanças sobrepostas tornam os resultados difíceis de confiar.
Use uma grade simples:
- Alto impacto / baixo esforço: faça primeiro (mudanças de copy, redirecionamento para suporte, oferta de troca para anual).
- Alto impacto / alto esforço: planeje (flexibilidade de cobrança, correções de produto).
- Baixo impacto: coloque em espera.
Se você é novo em experimentação, alinhe no básico e regras de decisão antes do lançamento: /blog/ab-testing-basics.
Feche o loop com input qualitativo
Números dizem o que está acontecendo; notas de suporte e comentários de cancelamento frequentemente dizem por que. Toda semana, amostre alguns cancelamentos recentes por segmento e resuma temas. Depois, mapeie temas para intervenções testáveis.
Construa um playbook de “intervenções vencedoras”
Registre aprendizados ao longo do tempo: o que funcionou, para quem e sob quais condições. Guarde entradas curtas como:
- Definição de segmento (plano, tenure, uso)
- Hipótese e mudança enviada
- Resultado e confiança
- Ação seguinte (liberar, iterar ou reverter)
Quando estiver pronto para padronizar ofertas (e evitar descontos ad-hoc), conecte seu playbook de volta ao seu empacotamento e limites: /pricing.