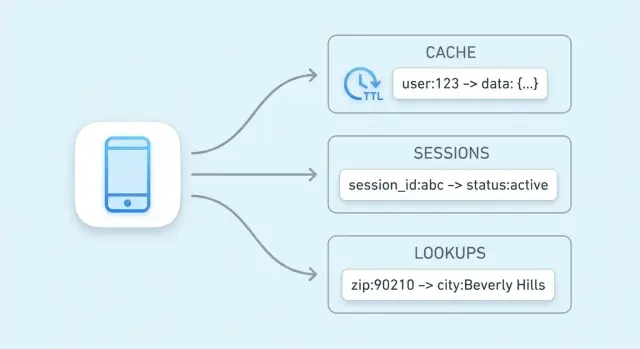
Por que armazenamentos chave-valor são usados para velocidade
O objetivo principal de um armazenamento chave-valor é simples: reduzir a latência para os usuários finais e diminuir a carga no seu banco de dados primário. Em vez de executar a mesma consulta cara ou recomputar o mesmo resultado, sua aplicação pode buscar um valor pré-computado em um único passo previsível.
Rápido porque o caminho de acesso é simples
Um armazenamento chave-valor é otimizado em torno de uma operação: “dada esta chave, retorne o valor.” Esse foco estreito permite um caminho crítico muito curto.
Em muitos sistemas, uma busca costuma ser tratada com:
- um índice em memória (então não há seek de disco)
- hashing direto de chave → localização (logo há pouca busca)
- menos recursos pesados de CPU do que um engine de consultas genérico
O resultado são tempos de resposta baixos e consistentes—exatamente o que você quer para cache, armazenamento de sessões e outras buscas de alta velocidade.
Rápido porque evita trabalho em outro lugar
Mesmo que seu banco de dados esteja bem afinado, ele ainda precisa parsear consultas, planejar, ler índices e coordenar concorrência. Se milhares de requisições pedem a mesma lista “top produtos”, esse trabalho repetido se acumula.
Um cache chave-valor desloca esse tráfego de leitura repetido para longe do banco. O banco pode gastar mais tempo em requisições que realmente exigem: gravações, joins complexos, relatórios e leituras críticas de consistência.
Nem toda carga é adequada
Velocidade não é de graça. Armazenamentos chave-valor normalmente abrem mão de consultas ricas (filtros, joins) e podem ter garantias diferentes sobre persistência e consistência dependendo da configuração.
Eles brilham quando você consegue nomear dados com uma chave clara (por exemplo, user:123, cart:abc) e quer recuperação rápida. Se você frequentemente precisa de “encontre todos os itens onde X”, um banco relacional ou documento geralmente é um armazenamento primário melhor.
Fundamentos chave-valor: chaves, valores e buscas
Um armazenamento chave-valor é o tipo mais simples de banco: você armazena um valor (algum dado) sob uma chave única (um rótulo), e depois busca o valor fornecendo a chave.
O que uma “chave” e um “valor” realmente são
Pense na chave como um identificador que é fácil de repetir exatamente, e no valor como aquilo que você quer de volta.
- Check-in de casaco: seu número de ticket é a chave; seu casaco é o valor.
- App de contatos: “Alice Chen” (ou um ID de contato) é a chave; o telefone e detalhes são o valor.
- Sessões: um token de sessão aleatório é a chave; o ID do usuário e estado de login são o valor.
Chaves costumam ser strings curtas (como user:1234 ou session:9f2a...). Valores podem ser pequenos (um contador) ou maiores (um blob JSON).
Como funcionam buscas de tempo constante (visão geral)
Armazenamentos chave-valor são construídos para consultas “me dê o valor para essa chave”. Internamente, muitos usam uma estrutura similar a uma tabela de hashing: a chave é transformada em uma localização onde o valor pode ser encontrado rapidamente.
É por isso que você frequentemente ouve buscas em tempo constante (escrito como O(1)): o desempenho depende muito mais de quantas requisições você faz do que de quantos registros totais existem. Não é mágica—colisões e limites de memória ainda importam—mas para uso típico de cache/sessão, é muito rápido.
Implantações típicas: em memória, em disco ou híbrido
- Em memória: leituras/gravações mais rápidas; dados podem ser perdidos no reinício, a menos que persistidos.
- Em disco: mais lento que RAM, mas comporta mais dados e sobrevive a reinícios.
- Híbrido: mantém dados “quentes” em memória enquanto grava em disco para recuperação.
O que significa “dados quentes” (e por que importa)
Dados quentes são a pequena fatia de informação requisitada repetidamente (páginas de produto populares, sessões ativas, contadores de rate-limit). Manter dados quentes em um armazenamento chave-valor—especialmente em memória—evita consultas mais lentas ao banco e mantém tempos de resposta previsíveis sob carga.
Caching 101: o que cachear e por quê
Cachear significa manter uma cópia de dados frequentemente necessários em um lugar mais rápido que a fonte original. Um armazenamento chave-valor é um local comum porque pode devolver um valor em uma única busca por chave, muitas vezes em poucos milissegundos.
Quando o cache ajuda mais
Cache funciona bem quando as mesmas perguntas são feitas repetidamente: páginas populares, buscas repetidas, chamadas de API comuns ou cálculos caros. Também é útil quando a “fonte real” é mais lenta ou limitada por taxa—como um banco primário sob alta carga ou uma API terceirizada cobrada por requisição.
O que cachear (exemplos práticos)
Bons candidatos são resultados lidos com frequência e que não precisam ser perfeitamente em tempo real:
- Resumos de perfil de usuário (nome, URL do avatar, preferências)
- Listas de produtos e páginas de categoria
- Resultados computados (recomendações, totais, trechos de relatórios)
- Configuração e feature flags lidas em cada requisição
- Respostas de APIs externas que são seguras para reutilizar por curto período
Uma regra simples: cacheie outputs que você consegue regenerar se necessário. Evite cachear dados que mudam constantemente ou que precisam ser consistentes em todas as leituras (por exemplo, saldo bancário).
Por que cache reduzir a pressão em bancos e APIs
Sem cache, cada visualização de página pode acionar múltiplas consultas ao banco ou chamadas de API. Com um cache, a aplicação pode servir muitas requisições a partir do armazenamento chave-valor e só “recorrer” ao banco primário ou API em um cache miss. Isso reduz volume de consultas, diminui contenção de conexões e pode melhorar a confiabilidade durante picos de tráfego.
Riscos: dados desatualizados e leituras inconsistentes
Cachear troca frescor por velocidade. Se valores em cache não forem atualizados rapidamente, usuários podem ver informação stale. Em sistemas distribuídos, duas requisições podem ler versões diferentes do mesmo dado brevemente.
Gerencie esses riscos escolhendo TTLs apropriados, decidindo quais dados podem ficar “um pouco antigos” e projetando sua aplicação para tolerar misses ou atrasos na atualização do cache.
Padrões comuns de cache e quando usá-los
Um “padrão” de cache é um fluxo repetível de como sua aplicação lê e escreve dados quando há um cache envolvido. Escolher o certo depende menos da ferramenta (Redis, Memcached, etc.) e mais de com que frequência os dados mudam e quanto stale você tolera.
Cache-aside (lazy loading)
Com cache-aside, sua aplicação controla o cache explicitamente:
- Leia do cache pela chave.
- Se for miss, leia do banco/fonte da verdade.
- Coloque o resultado no cache com um TTL.
- Retorne o resultado.
Melhor para: dados lidos com frequência e que mudam pouco (páginas de produto, configuração, perfis públicos). Também é um bom padrão padrão porque falhas degradam graciosamente: se o cache estiver vazio, você ainda lê do banco.
Read-through vs write-through
Read-through significa que a camada de cache busca do banco em um miss (sua app lê “do cache”, e o cache sabe como carregar). Operacionalmente, simplifica o código da app, mas adiciona complexidade ao tier de cache (você precisa integrar um loader).
Write-through significa que toda escrita vai para o cache e para o banco de forma síncrona. Leituras são geralmente rápidas e consistentes, mas escritas ficam mais lentas por terem duas operações.
Melhor para: dados onde você quer menos misses e consistência de leitura mais simples (configurações de usuário, feature flags), e onde latência de escrita é aceitável.
Write-back / write-behind
Com write-back, sua aplicação escreve primeiro no cache, e o cache aplica as mudanças no banco depois (frequentemente em lotes).
Benefícios: gravações muito rápidas e menor carga no banco.
Risco adicional: se o nó de cache falhar antes de flushar, você pode perder dados. Use apenas quando perder dados for tolerável ou você tiver mecanismos fortes de durabilidade.
Se os dados mudam raramente, cache-aside com um TTL sensato geralmente é suficiente. Se mudam com frequência e leituras stale são problemáticas, considere write-through (ou TTLs muito curtos mais invalidação explícita). Se o volume de escrita é extremo e perda ocasional é aceitável, write-behind pode valer o trade-off.
Controles de frescor: TTLs, expiração e invalidação
Manter dados em cache “frescos o suficiente” é principalmente escolher a estratégia de expiração certa para cada chave. O objetivo não é precisão perfeita—é evitar que resultados stale surpreendam usuários enquanto ainda obtém os benefícios de velocidade do cache.
TTLs e expirações: o que fazem (e como escolher)
Um TTL (time to live) define expiração automática para uma chave. TTLs curtos reduzem stale mas aumentam misses; TTLs mais longos melhoram hit rate mas aumentam o risco de valores desatualizados.
Uma forma prática de escolher TTLs:
- Combine com a frequência de alteração do dado subjacente. Preços de produto podem exigir minutos; um perfil de usuário pode aguentar horas.
- Considere o impacto de negócio. Curtidas stale geralmente são aceitáveis; saldo de conta não é.
- Adicione pequena aleatoriedade (jitter). Se muitas chaves compartilham o mesmo TTL, podem expirar juntas e causar picos.
Invalidação ativa: deletar ou atualizar quando os dados mudam
TTL é passivo. Quando você sabe que os dados mudaram, muitas vezes é melhor invalidar ativamente: deletar a chave antiga ou escrever o novo valor imediatamente.
Exemplo: após um usuário atualizar o email, delete user:123:profile ou atualize-o no cache na hora. Invalidação ativa reduz janelas de stale, mas exige que sua aplicação realize essas atualizações de forma confiável.
Chaves versionadas: invalidação simples e de baixo risco
Em vez de deletar chaves antigas, inclua uma versão no nome da chave, como product:987:v42. Quando o produto muda, incremente a versão e comece a ler/escrever v43. Versões antigas expiram naturalmente depois. Isso evita corridas onde um servidor deleta uma chave enquanto outro a está escrevendo.
Um stampede acontece quando uma chave popular expira e muitas requisições a reconstroem ao mesmo tempo.
Correções comuns incluem:
- Coalescência/locking de requisições: só uma requisição recalcula; as outras esperam.
- Servir stale enquanto revalida: retornar o último valor temporariamente enquanto atualiza em background.
- Refresh antecipado: renovar um pouco antes do TTL acabar (especialmente para chaves quentes).
Prototipe um endpoint com cache
Protótipo de um endpoint com cache via chat e meça as melhorias de latência desde cedo.
Dados de sessão são o pequeno conjunto de informação que sua app precisa para reconhecer um navegador ou cliente móvel que retorna. No mínimo, é um ID de sessão (ou token) que mapeia para estado no servidor. Dependendo do produto, pode incluir estado do usuário (flags de login, papéis, nonce CSRF), preferências temporárias e dados sensíveis ao tempo como conteúdo de carrinho ou etapa de checkout.
Eles combinam naturalmente porque leituras e gravações de sessão são simples: buscar um token, recuperar um valor, atualizá-lo e definir expiração. Também facilita aplicar TTLs para que sessões inativas desapareçam automaticamente, mantendo o armazenamento limpo e reduzindo risco se um token vazar.
Fluxo comum:
- No login: crie um novo token de sessão aleatório e armazene os dados de sessão sob essa chave.
- Em cada requisição: leia pelo token, renove o TTL se usar expiração deslizante.
- No logout (ou atividade suspeita): delete a chave imediatamente.
Design de chaves de sessão
Use chaves claras e com escopo e mantenha valores pequenos:
- Nomeação:
sess:<token> ou sess:v2:<token> (versionar ajuda mudanças futuras).
- Escopo por usuário: opcionalmente mantenha
user_sess:<userId> -> <token> para impor “uma sessão ativa por usuário” ou revogar sessões por usuário.
- Limites de tamanho: evite enfiar perfis inteiros na sessão. Armazene apenas o necessário; dados maiores fiquem no banco primário e sejam referenciados.
Logout e rotação
Logout deve deletar a chave de sessão e quaisquer índices relacionados (como user_sess:<userId>). Para rotação (recomendado após login, mudanças de privilégio ou periodicamente), crie um novo token, escreva a nova sessão e depois delete a antiga. Isso reduz a janela em que um token roubado é útil.
Buscas de alta velocidade além do caching
Cache é o uso mais comum, mas não é a única forma de acelerar seu sistema. Muitas aplicações dependem de leituras rápidas para pequenos pedaços de estado “adjacentes à fonte da verdade” que precisam ser checados rapidamente em quase toda requisição.
Dados de autorização: permissões e direitos
Checagens de autorização frequentemente ficam no caminho crítico: cada chamada de API pode precisar responder “este usuário pode fazer isso?”. Buscar permissões no banco relacional a cada requisição adiciona latência e carga.
Um armazenamento chave-valor pode guardar dados compactos de autorização para buscas rápidas, por exemplo:
perm:user:123 → lista/conjunto de códigos de permissãoentitlement:org:45 → funcionalidades do plano habilitadas
Isso é útil quando o modelo de permissões é pesado em leitura e muda relativamente pouco. Quando permissões mudam, você pode atualizar ou invalidar um pequeno conjunto de chaves para que a próxima requisição reflita as novas regras.
Feature flags e leituras de configuração
Feature flags são valores pequenos, lidos com frequência e que precisam estar disponíveis rapidamente e de forma consistente em muitos serviços.
Padrão comum:
flag:new-checkout → true/falseconfig:tax:region:EU → blob JSON ou configuração versionada
Armazenamentos chave-valor funcionam bem porque leituras são simples, previsíveis e extremamente rápidas. Você também pode versionar valores (por exemplo, config:v27:...) para rollouts mais seguros e rollback rápido.
Rate limiting frequentemente se resume a contadores por usuário, chave de API ou IP. Armazenamentos chave-valor tipicamente suportam operações atômicas, que permitem incrementar um contador com segurança mesmo com muitas requisições concorrentes.
Você pode rastrear:
rl:user:123:minute → incremente a cada requisição, expire após 60 segundosrl:ip:203.0.113.10:second → controle de rajada em janela curta
Com TTL no contador, limites se resetam automaticamente sem jobs de background. É uma base prática para proteger tentativas de login, endpoints caros ou impor cotas por plano.
Chaves de idempotência para endpoints seguros a retry
Pagamentos e outras operações “faça exatamente uma vez” precisam proteção contra retrys—sejam causados por timeouts, tentativas do cliente ou re-entregas de mensagens.
Um armazenamento chave-valor pode registrar chaves de idempotência:
idem:pay:order_789:clientKey_abc → resultado armazenado ou status
Na primeira requisição, você processa e armazena o resultado com um TTL. Em retrys posteriores, retorna o resultado armazenado em vez de executar a operação novamente. O TTL evita crescimento ilimitado enquanto cobre a janela realista de retrys.
Esses usos não são “cache” no sentido clássico; são sobre manter latência baixa para leituras frequentes e primitivas de coordenação que precisam de velocidade e atomicidade.
Estruturas de dados úteis e operações atômicas
Planeje sua estratégia de cache
Use o modo de planejamento para definir chaves, TTLs e invalidação antes de lançar.
“Armazenamento chave-valor” nem sempre significa “string entra, string sai”. Muitos sistemas oferecem estruturas de dados mais ricas que permitem modelar necessidades comuns diretamente dentro do store—frequentemente mais rápido e com menos peças móveis do que empurrar tudo para o código da aplicação.
Hashes/maps: múltiplos campos sob uma chave
Hashes (ou maps) são ideais quando você tem uma única “entidade” com vários atributos relacionados. Em vez de criar muitas chaves como user:123:name, user:123:plan, user:123:last_seen, você pode mantê-los juntos sob user:123 com campos.
Isso reduz proliferação de chaves e permite buscar ou alterar apenas o campo necessário—útil para perfis, feature flags ou pequenos blobs de configuração.
Sets e sorted sets: pertença e ranking
Sets são ótimos para perguntas “X está no grupo?”:
- O usuário já resgatou um cupom?
- Quais IDs de produto estão na coleção “summer-sale”?
Sorted sets adicionam ordenação por score, útil para leaderboards, “top N” e ranking por tempo ou popularidade. Você pode armazenar scores como contagens de visualização ou timestamps e ler rapidamente os itens principais.
Incrementos atômicos e gravações condicionais
Problemas de concorrência aparecem em recursos pequenos: contadores, cotas, ações únicas e rate limits. Se duas requisições chegam ao mesmo tempo e sua app faz “ler → somar 1 → escrever”, você pode perder atualizações.
Operações atômicas resolvem isso ao executar a mudança como um passo indivisível dentro do store:
- Incremento atômico para contadores (views, retries, chamadas de API)
- Gravação condicional (setar só se ausente, atualizar só se a versão bater) para evitar processamento duplo
Por que operações atômicas simplificam contadores e limites
Com incrementos atômicos, você não precisa de locks ou coordenação extra entre servidores. Isso significa menos condições de corrida, caminhos de código mais simples e comportamento mais previsível sob carga—especialmente para rate limiting e limites de uso, onde “quase correto” vira problema para o cliente.
Escalando para tráfego: replicação, sharding e disponibilidade
Quando um armazenamento chave-valor começa a lidar com tráfego sério, “torná-lo mais rápido” normalmente significa “torná-lo mais largo”: espalhar leituras e gravações por múltiplos nós mantendo previsibilidade sob falha.
Escalar leituras e gravações: replicação vs sharding
Replicação mantém múltiplas cópias dos mesmos dados.
- Para cargas pesadas de leitura (típicas de cache), réplicas podem servir leituras em paralelo.
- Gravações normalmente vão para um nó primário (ou leader) e então são copiadas para réplicas, o que pode introduzir pequenos atrasos antes das réplicas refletirem o último valor.
Sharding divide o keyspace entre nós.
- Cada nó possui um subconjunto de chaves (por exemplo, determinado por hashing da chave).
- Sharding aumenta tanto throughput de leitura quanto de escrita porque o trabalho é distribuído, mas adiciona complexidade operacional (rebalanceamento, lidar com “hot keys” e rastrear qual nó possui quais chaves).
Muitas implantações combinam os dois: shards para throughput e réplicas por shard para disponibilidade.
Alta disponibilidade e failover na prática
“Alta disponibilidade” geralmente significa que a camada de cache/sessão continua servindo requisições mesmo se um nó falhar.
- Failover é a promoção automática de uma réplica para primária quando a primária morre.
- Na prática, sua app deve tolerar erros breves ou retries durante o switchover, e aceitar que algumas escritas recentes podem não sobreviver se não foram replicadas ainda.
Roteamento no cliente vs no servidor
Com roteamento no cliente, sua aplicação (ou biblioteca) calcula qual nó detém uma chave (comum com hashing consistente). Isso pode ser muito rápido, mas os clientes precisam conhecer mudanças de topologia.
Com roteamento no servidor, você envia requisições a um proxy ou endpoint de cluster que as encaminha ao nó certo. Isso simplifica clientes e rollouts, mas adiciona um salto a mais.
Planejamento de capacidade: memória, headroom e crescimento
Planeje memória de cima para baixo:
- Estime o tamanho do working-set (o que você espera manter “quente”), mais overhead de metadata.
- Adicione headroom (geralmente 20–50%) para picos de tráfego, rebalanceamento e distribuição desigual de chaves.
- Valide o comportamento da política de evicção sob carga para que o sistema degrade graciosamente ao invés de entrar em thrashing.
Confiabilidade e trade-offs a entender
Armazenamentos chave-valor parecem “instantâneos” porque mantêm dados quentes em memória e otimizam leituras/gravações. Essa velocidade tem custo: muitas vezes você está escolhendo entre desempenho, durabilidade e consistência. Entender os trade-offs previne surpresas dolorosas depois.
Persistência: quanto dado você pode se dar ao luxo de perder?
Muitos produtos rodam em modos de persistência diferentes:
- Nenhuma (puro em memória): mais rápido e simples—até um reinício apagar tudo. Ótimo para caches cujo dado pode ser recomputado.
- Snapshots: saves periódicos em disco. Se o nó cair, você perde alterações desde o último snapshot.
- Append-only logs: gravações são registradas sequencialmente. Recuperação é mais lenta que puro em memória, mas geralmente você perde menos dados que com snapshots.
Escolha o modo que combina com o propósito dos dados: cache tolera perda; armazenamento de sessão frequentemente precisa de mais cuidado.
Expectativas de consistência: “minha gravação realmente ficou?”
Em setups distribuídos, você pode ver consistência eventual—leituras podem retornar um valor antigo após uma gravação, especialmente durante failover ou lag de replicação. Consistência mais forte (por exemplo, exigir confirmações de múltiplos nós) reduz anomalias, mas aumenta latência e pode reduzir disponibilidade durante problemas de rede.
Quando a memória enche: evicção e comportamento sob pressão
Caches enchem. Uma política de evicção decide o que é removido: menos-recentemente-usado (LRU), menos-frequentemente-usado (LFU), aleatório, ou “não evictar” (o que transforma “memória cheia” em falhas de escrita). Decida se prefere misses no cache ou erros sob pressão.
Se o store cair: planeje modo degradado
Assuma que outages acontecem. Fallbacks típicos incluem:
- Contornar o cache e ler do banco primário (com rate limits).
- Servir dados ligeiramente stale quando for seguro.
- Falhar fechado para operações sensíveis (por exemplo, tokens de autenticação), permitindo que funcionalidades não críticas degradem.
Projetar esses comportamentos intencionalmente é o que faz o sistema parecer confiável para usuários.
Noções básicas de segurança, monitoramento e custo
Crie um starter full-stack
Gere um frontend em React e um backend em Go com PostgreSQL pronto para cache.
Armazenamentos chave-valor frequentemente ficam no “caminho quente” da sua aplicação. Isso os torna sensíveis (podem conter tokens de sessão ou identificadores de usuário) e caros (são geralmente memória-intensivos). Acertar o básico cedo evita incidentes dolorosos depois.
Segurança: restrinja o acesso
Comece com limites de rede claros: coloque o store em uma sub-rede/VPC privada e permita tráfego apenas dos serviços que realmente precisam. Use autenticação se o produto suportar e siga princípio do menor privilégio: credenciais separadas para apps, admins e automações; rotacione segredos; evite tokens “root” compartilhados.
Criptografe tráfego em trânsito (TLS) sempre que possível—especialmente se trafegar entre hosts ou zonas. Criptografia em repouso depende do produto/implantação; se suportado, habilite em serviços gerenciados e verifique também a criptografia de backups.
Monitoramento: o que observar diariamente
Um conjunto pequeno de métricas diz se o cache está ajudando ou atrapalhando:
- Hit rate: queda pode indicar chaves ruins, TTLs curtos demais ou churn por evicções.
- Latência (p95/p99): picos indicam saturação, problemas de rede ou valores grandes.
- Uso de memória & evicções: memória alta sustentada mais evicções significa que seus dados não cabem ou a política está errada.
- Erros/timeouts: até pequenas quedas podem escalar para lentidão do banco e falhas visíveis ao usuário.
Adicione alertas para mudanças súbitas, não apenas limiares absolutos, e logue operações de chave com cuidado (evitando valores sensíveis).
Custo: o que impulsiona a conta
Os maiores direcionadores são:
- Pegada de memória: valores grandes, demasiadas chaves ou guardar dados “nice-to-have”.
- Tráfego: volume de leituras/gravações e transferência entre zonas.
- Réplica & alta disponibilidade: mais nós para resiliência aumentam custo.
- Retenção: TTLs longos mantêm dados por mais tempo e inflacionam necessidade de memória.
Uma alavanca prática de custo é reduzir tamanho de valor e definir TTLs realistas, para que o store mantenha apenas o que é ativamente útil.
Checklist de implementação e próximos passos
Checklist prático de rollout
Comece padronizando nomeação de chaves para que cache e chaves de sessão sejam previsíveis, pesquisáveis e seguras para operações em lote. Uma convenção simples como app:env:feature:id (por exemplo, shop:prod:cart:USER123) ajuda a evitar colisões e torna debug mais rápido.
Defina uma estratégia de TTL antes do lançamento. Decida quais dados podem expirar rápido (segundos/minutos), quais precisam de vida mais longa (horas) e o que nunca deve ser cacheado. Se cachear linhas de banco, alinhe TTLs com a frequência de alteração dos dados subjacentes.
Escreva um plano de invalidação para cada tipo de item em cache:
- Expiração por tempo (só TTL) para frescor “bom o suficiente”
- Invalidação por evento quando você souber exatamente o que mudou (ex.: atualização de produto)
- Chaves versionadas (ex.:
product:v3:123) quando quiser invalidar tudo de forma simples
Como medir sucesso
Escolha algumas métricas e monitore desde o primeiro dia:
- Taxa de acerto do cache por endpoint (para muitas aplicações, 70–95% é um intervalo útil)
- Redução de carga no banco (queries/sec, CPU, utilização de réplicas de leitura)
- Mudanças de latência em p95/p99, não apenas média
Monitore também contagens de evicção e uso de memória para confirmar que o cache está dimensionado corretamente.
Armadilhas comuns a evitar
Valores muito grandes aumentam tempo de rede e pressão de memória—prefira cachear fragmentos menores e pré-computados. Evite TTLs ausentes (dados stale e vazamentos de memória) e crescimento ilimitado de chaves (por exemplo, cachear toda consulta de busca para sempre). Tenha cuidado ao cachear dados específicos de usuário sob chaves compartilhadas.
Próximos passos
Se estiver avaliando opções, compare um cache local em processo versus um cache distribuído e decida onde a consistência é mais importante. Para detalhes de implementação e orientação operacional, revise /docs. Se estiver planejando capacidade ou precisar de suposições de preço, veja /pricing.
Se você está construindo um produto novo (ou modernizando um existente), ajuda projetar cache e armazenamento de sessão como preocupações de primeira classe desde o início. Em protótipos e iterações de desempenho, equipes frequentemente constroem um app ponta a ponta e iteram com padrões como cache-aside, TTLs e contadores de rate-limiting. Recursos como modos de planejamento, snapshots e rollback tornam mais seguro testar designs de chaves de cache e estratégias de invalidação, e você pode exportar o código-fonte quando estiver pronto para rodar em seu próprio pipeline.