O que Consistência e Disponibilidade Significam na Prática
Quando um banco de dados é dividido entre várias máquinas (réplicas), você ganha velocidade e resiliência — mas também introduz períodos em que essas máquinas não concordam perfeitamente ou não conseguem se comunicar de forma confiável.
Consistência (significado simples)
Consistência significa: após uma escrita bem-sucedida, todos leem o mesmo valor. Se você atualiza o e-mail do seu perfil, a próxima leitura — não importa qual réplica responda — retorna o novo e-mail.
Na prática, sistemas que priorizam consistência podem atrasar ou rejeitar algumas requisições durante falhas para evitar respostas conflitantes.
Disponibilidade (significado simples)
Disponibilidade significa: o sistema responde a toda requisição, mesmo se alguns servidores estiverem fora ou desconectados. Você pode não obter o dado mais recente, mas recebe uma resposta.
Na prática, sistemas que priorizam disponibilidade podem aceitar gravações e servir leituras mesmo enquanto réplicas discordam, reconciliando diferenças depois.
O que o trade-off significa para aplicações reais
Um trade-off significa que você não pode maximizar ambos os objetivos ao mesmo tempo em todo cenário de falha. Se réplicas não conseguem coordenar, o banco deve ou:
- Esperar/rejeitar algumas requisições para proteger uma verdade acordada (favorecer consistência), ou
- Continuar respondendo aos usuários mesmo que corra o risco de dados obsoletos ou conflitantes (favorecer disponibilidade)
Um exemplo simples: carrinho de compras vs. transferência bancária
- Carrinho de compras: se a contagem do carrinho estiver temporariamente errada em outro dispositivo, é incômodo mas geralmente aceitável. Muitas equipes preferem alta disponibilidade e reconciliam depois.
- Transferência bancária: se você transfere $500 e seu saldo mostrar temporariamente duas respostas diferentes, é um problema sério. Aqui, consistência mais forte costuma valer falhas ocasionais com “por favor, tente novamente”.
Não há uma escolha única ideal
O equilíbrio certo depende de quais erros você tolera: uma breve indisponibilidade ou um curto período com dados errados/antigos. A maioria dos sistemas reais escolhe um ponto intermediário — e torna o trade-off explícito.
Por que Distribuir Muda as Regras
Um banco de dados é “distribuído” quando armazena e serve dados de várias máquinas (nós) que se coordenam por uma rede. Para a aplicação, pode ainda parecer um único banco — mas por trás, requisições podem ser tratadas por nós diferentes em locais distintos.
Replicação: por que equipes adicionam nós
A maioria dos bancos de dados distribuídos replica dados: o mesmo registro é armazenado em vários nós. As equipes fazem isso para:
- manter o serviço funcionando se uma máquina morrer
- reduzir latência servindo usuários de um nó próximo
- escalar leituras (e às vezes gravações) em mais hardware
A replicação é poderosa, mas imediatamente levanta uma questão: se dois nós têm uma cópia do mesmo dado, como garantir que sempre concordem?
Falha parcial é normal, não excepcional
Em um único servidor, “fora” geralmente é óbvio: a máquina está em pé ou não. Em um sistema distribuído, falha costuma ser parcial. Um nó pode estar vivo mas lento. Um link de rede pode perder pacotes. Um rack inteiro pode perder conectividade enquanto o resto do cluster continua funcionando.
Isso importa porque nós não podem saber instantaneamente se outro nó está realmente morto, temporariamente inacessível ou apenas atrasado. Enquanto esperam para descobrir, ainda precisam decidir o que fazer com leituras e gravações que chegam.
Garantias mudam quando a comunicação não é garantida
Com um servidor, há uma fonte única de verdade: toda leitura vê a última escrita bem-sucedida.
Com múltiplos nós, “mais recente” depende de coordenação. Se uma escrita é bem-sucedida no Nó A mas o Nó B não é alcançado, o banco deve:
- bloquear a escrita até B acusar recebimento (protegendo consistência), ou
- aceitar a escrita mesmo assim (protegendo disponibilidade)?
Essa tensão — tornada real por redes imperfeitas — é por que a distribuição muda as regras.
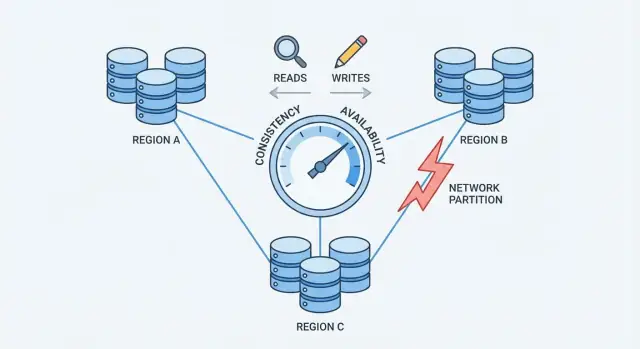
Partições de Rede: O Problema Central
Uma partição de rede é uma quebra na comunicação entre nós que deveriam funcionar como um único banco. Os nós podem continuar rodando e saudáveis, mas não conseguem trocar mensagens de forma confiável — por causa de um switch falho, um link sobrecarregado, uma mudança de roteamento ruim, uma regra de firewall mal configurada ou até um vizinho barulhento na nuvem.
Por que partições são inevitáveis em larga escala
Quando o sistema está espalhado por várias máquinas (frequentemente por racks, zonas ou regiões), você não controla mais cada salto entre elas. Redes perdem pacotes, introduzem atrasos e às vezes se dividem em “ilhas”. Em pequena escala esses eventos são raros; em grande escala são rotineiros. Mesmo uma curta interrupção basta para importar, porque bancos precisam de coordenação constante para concordar sobre o que aconteceu.
Como partições criam dados “mais recentes” conflitantes
Durante uma partição, ambos os lados continuam recebendo requisições. Se usuários escrevem em ambos os lados, cada lado pode aceitar atualizações que o outro não vê.
Exemplo: o Nó A atualiza o endereço de um usuário para “Rua Nova”. Ao mesmo tempo, o Nó B atualiza para “Antiga, Apto 2”. Cada lado acredita que sua escrita é a mais recente — porque não há como comparar em tempo real.
Sintomas visíveis ao usuário
Partições não aparecem como mensagens de erro limpas; aparecem como comportamento confuso:
- Timeouts: o banco espera por outro nó para confirmar uma escrita ou leitura.
- Leituras desatualizadas: você atualiza e ainda vê dados antigos porque bateu numa réplica que perdeu atualizações.
- Comportamento split-brain: usuários diferentes veem “verdades” diferentes, dependendo de qual lado alcançam.
Esse é o ponto de pressão que força a escolha: quando a rede não garante comunicação, um banco distribuído deve decidir priorizar consistência ou disponibilidade.
Teorema CAP Sem Jargões
CAP é uma forma compacta de descrever o que acontece quando um banco é espalhado por várias máquinas.
Os três termos (em inglês simples)
- Consistency (C): depois que você grava um valor, qualquer leitura posterior retorna esse mesmo valor.
- Availability (A): toda requisição recebe uma resposta não-erro, mesmo quando alguns servidores têm problemas.
- Partition tolerance (P): o sistema continua operando mesmo se a rede se dividir e servidores não se comunicarem de forma confiável.
A lição principal
Quando não há partição, muitos sistemas podem parecer consistentes e disponíveis.
Quando há uma partição, você deve escolher o que priorizar:
- Escolher Consistência: rejeitar ou atrasar algumas requisições até que os servidores concordem.
- Escolher Disponibilidade: aceitar requisições em cada lado da divisão, mesmo que as respostas discordem temporariamente.
Uma linha do tempo simples que você pode imaginar
- 10:00 Cliente grava
balance = 100 no Servidor A.
- 10:01 Partição de rede: Servidor A não alcança o Servidor B.
- 10:02 Cliente lê do Servidor B.
- Se você prioriza Consistência, o Servidor B deve recusar ou esperar.
- Se você prioriza Disponibilidade, o Servidor B responde, mas pode dizer
balance = 80.
Equívoco comum
CAP não significa “escolha apenas dois” como regra permanente. Significa durante uma partição, você não pode garantir ao mesmo tempo Consistência e Disponibilidade. Fora de partições, muitas vezes você chega bem perto de ambos — até a rede se comportar mal.
Escolhendo Consistência: O que Você Ganha e o que Você Perde
Escolher consistência significa que o banco prioriza “todos veem a mesma verdade” acima de “responder sempre”. Na prática, isso costuma apontar para consistência forte, muitas vezes descrita como comportamento linearizável: uma vez que uma escrita é reconhecida, qualquer leitura posterior (de qualquer lugar) retorna esse valor, como se existisse uma única cópia atualizada.
O que acontece durante uma partição
Quando a rede se divide e réplicas não conseguem conversar com segurança, um sistema fortemente consistente não pode aceitar atualizações independentes em ambos os lados. Para proteger a correção, normalmente:
- Bloqueia requisições enquanto espera coordenação, ou
- Rejeita requisições (retorna erros/timeouts) se não consegue alcançar as réplicas/leader necessários.
Do ponto de vista do usuário, isso pode parecer uma indisponibilidade mesmo que algumas máquinas ainda estejam rodando.
O que você ganha
O principal benefício é raciocínio mais simples. O código da aplicação pode se comportar como se falasse com um único banco, não várias réplicas que podem discordar. Isso reduz momentos “estranhos” como:
- Ler dados antigos logo após uma atualização bem-sucedida
- Ver dois valores diferentes para o mesmo registro dependendo da réplica
- Perder invariantes (por exemplo, vender mais do que o estoque) devido a gravações concorrentes conflitantes
Você também obtém modelos mentais mais limpos para auditoria, faturamento e qualquer coisa que deva estar correta na primeira vez.
O que você perde
Consistência tem custos reais:
- Latência maior: muitas operações precisam esperar por coordenação (geralmente entre máquinas ou regiões).
- Mais erros durante falhas: partições, réplicas lentas ou problemas no líder podem se traduzir em timeouts ou “tente novamente mais tarde”.
Se seu produto não tolera requisições falhando durante outages parciais, consistência forte pode parecer cara — mesmo quando é a escolha correta para a correção.
Escolhendo Disponibilidade: O que Você Ganha e o que Você Perde
Valide fluxos de trabalho longos
Prototipe um fluxo tipo saga com ações compensatórias para lidar com falhas parciais de forma limpa.
Escolher disponibilidade significa otimizar por uma promessa simples: o sistema responde, mesmo quando partes da infraestrutura estão saudáveis. Na prática, “alta disponibilidade” não é “sem erros nunca” — é que a maioria das requisições ainda recebe resposta durante falhas de nó, réplicas sobrecarregadas ou links quebrados.
O que acontece durante uma partição de rede
Quando a rede se divide, réplicas não conseguem conversar de forma confiável. Um banco orientado à disponibilidade tipicamente continua atendendo tráfego do lado alcançável:
- Leituras são respondidas localmente com os dados que a réplica tem no momento.
- Gravações são aceitas localmente e enfileiradas/replicadas depois quando a conectividade voltar.
Isso mantém aplicações funcionando, mas significa que réplicas diferentes podem aceitar “verdades” distintas temporariamente.
O que você ganha
Você obtém maior tempo de atividade: usuários ainda podem navegar, colocar itens no carrinho, postar comentários ou registrar eventos mesmo se uma região ficar isolada.
Também tem uma experiência de usuário mais suave sob estresse. Em vez de timeouts, seu app pode continuar com comportamento razoável (“sua atualização foi salva”) e sincronizar depois. Para muitas cargas de consumo e analytics, esse trade-off vale a pena.
O que você perde
O preço é que o banco pode retornar leituras desatualizadas. Um usuário pode atualizar um perfil em uma réplica e, imediatamente depois, ler de outra réplica e ver o valor antigo.
Você também arrisca conflitos de escrita. Dois usuários (ou o mesmo em dois locais) podem atualizar o mesmo registro em lados diferentes de uma partição. Quando a partição cura, o sistema precisa reconciliar histórias divergentes. Dependendo das regras, uma escrita pode “vencer”, campos podem ser mesclados ou o conflito pode exigir lógica na aplicação.
O design orientado à disponibilidade aceita desacordo temporário para que o produto continue respondendo — e investe em como detectar e reparar a divergência depois.
Quoruns e Votação: Um Meio-termo
Quoruns são uma técnica prática de “votação” que muitos bancos replicados usam para equilibrar consistência e disponibilidade. Em vez de confiar em uma única réplica, o sistema pergunta a suficientes réplicas para concordar.
A ideia (N, R, W)
Você costuma ver quoruns descritos com três números:
- N: quantas réplicas existem para um dado
- W: quantas réplicas devem confirmar uma gravação antes dela ser considerada bem-sucedida
- R: quantas réplicas são consultadas para uma leitura
Uma regra prática é: se R + W > N, então toda leitura se sobrepõe à última escrita bem-sucedida em pelo menos uma réplica, o que reduz a chance de ler dados desatualizados.
Exemplos intuitivos
Se você tem N=3 réplicas:
- Abordagem de réplica única (R=1, W=1): rápido e altamente disponível, mas você pode facilmente ler uma réplica desatualizada.
- Votação por maioria (R=2, W=2): uma escrita deve alcançar 2 réplicas e uma leitura consulta 2 réplicas. Isso aumenta as chances de ver o valor mais novo porque os conjuntos de leitura e escrita se sobrepõem.
Alguns sistemas exigem W=3 (todas as réplicas) para consistência mais forte, mas isso pode causar mais falhas de escrita quando qualquer réplica está lenta ou caída.
O que quoruns fazem durante partições
Quoruns não eliminam problemas de partição — eles definem quem pode progredir. Se a rede se divide 2–1, o lado com 2 réplicas ainda pode satisfazer R=2 e W=2, enquanto a réplica isolada não pode. Isso reduz atualizações conflitantes, mas significa que alguns clientes verão erros ou timeouts.
Os trade-offs
Quoruns costumam significar latência maior (mais nós para contatar), custo maior (mais tráfego entre nós) e comportamento de falha mais sutil (timeouts podem parecer indisponibilidade). O benefício é um meio-termo ajustável: você regula R e W em direção a leituras mais frescas ou maior sucesso de escrita, conforme o que importa mais.
Consistência Eventual e Anomalias Comuns
Consistência eventual significa que réplicas podem ficar temporariamente dessincronizadas, desde que converjam para o mesmo valor depois.
Uma analogia concreta
Pense em uma cadeia de cafeterias atualizando um letreiro compartilhado de “esgotado” para um doce. Uma loja marca como esgotado, mas a atualização chega a outras lojas alguns minutos depois. Nesse intervalo, outra loja pode ainda mostrar “disponível” e vender o último. O sistema não está “quebrado” — as atualizações estão apenas chegando.
Anomalias comuns que você observará
Quando os dados ainda estão se propagando, clientes podem ver comportamentos surpreendentes:
- Leituras desatualizadas: você lê dados antigos de uma réplica que não recebeu a última escrita.
- Gaps de ler-a-sua-própria-escrita: você escreve uma atualização, então lê de outra réplica (ou após um failover) e não vê sua própria mudança.
- Atualizações fora de ordem: duas atualizações chegam em sequências diferentes em réplicas diferentes, produzindo visões inconsistentes por um tempo.
Técnicas que ajudam réplicas a convergir
Sistemas de consistência eventual normalmente adicionam mecanismos em segundo plano para reduzir janelas de inconsistência:
- Read repair: se uma leitura detecta réplicas divergentes, o sistema atualiza réplicas desatualizadas em background.
- Hinted handoff: se uma réplica está caída, outro nó armazena “dicas” de gravações para encaminhar quando ela voltar.
- Anti-entropy (sync): reconciliação periódica (frequentemente via árvores de Merkle ou checksums) para achar e corrigir deriva.
Quando consistência eventual funciona bem
É adequado quando disponibilidade importa mais que frescor absoluto: feeds de atividade, contadores de visualizações, recomendações, perfis em cache, logs/telemetria e outros dados não-críticos onde “correto daqui a pouco” é aceitável.
Resolução de Conflitos: Como Escritas Divergentes São Reconciliadas
Simule partições facilmente
Crie uma simulação mínima de réplicas para demonstrar partições, leituras obsoletas e conflitos.
Quando um banco aceita gravações em múltiplas réplicas, ele pode acabar com conflitos: duas (ou mais) atualizações no mesmo item que ocorreram independentemente em réplicas diferentes antes da sincronização.
Um exemplo clássico é um usuário atualizando o endereço de entrega num dispositivo enquanto troca o telefone em outro. Se cada atualização cair em réplicas diferentes durante um desconserto temporário, o sistema deve decidir qual é o registro “verdadeiro” quando as réplicas trocarem dados novamente.
Last-write-wins (LWW): simples, mas arriscado
Muitos sistemas começam com last-write-wins: a atualização com timestamp mais recente sobrescreve as outras.
É atraente por ser fácil de implementar e rápido de calcular. A desvantagem é que pode perder dados silenciosamente. Se o “mais novo” vence, uma alteração mais antiga — mas importante — é descartada, mesmo que as duas atualizações mexessem em campos diferentes.
Também pressupõe que timestamps são confiáveis. Desalinhamento de relógios entre máquinas (ou clientes) pode fazer a atualização “errada” vencer.
Manter histórico: vetores de versão e ideias relacionadas
Tratamento de conflito mais seguro geralmente exige rastrear histórico causal.
Em nível conceitual, vetores de versão (e variantes mais simples) anexam um pequeno metadado a cada registro que resume “qual réplica viu quais atualizações”. Quando réplicas trocam versões, o banco pode detectar se uma versão inclui outra (sem conflito) ou se divergiram (conflito que precisa resolução).
Alguns sistemas usam timestamps lógicos (por exemplo, relógios de Lamport) ou relógios lógicos híbridos para reduzir dependência do tempo de parede enquanto ainda oferecem uma pista de ordenação.
Mesclar em vez de sobrescrever
Depois que um conflito é detectado, você tem escolhas:
- Mesclas em nível de aplicação: sua aplicação decide como combinar campos, avisar usuários ou manter ambas versões para revisão.
- CRDTs (Conflict-Free Replicated Data Types): estruturas de dados projetadas para mesclar automaticamente e determinísticamente (úteis para contadores, conjuntos, texto colaborativo etc.). Elas costumam evitar comportamento “vencedor leva tudo” ao mesmo tempo em que mantêm alta disponibilidade.
A melhor abordagem depende do que “correto” significa para seus dados — às vezes perder uma escrita é aceitável, outras vezes é um bug crítico para o negócio.
Como Escolher para Seu Caso de Uso
Escolher postura de consistência/disponibilidade não é um debate filosófico — é uma decisão de produto. Comece perguntando: qual é o custo de estar errado por um momento, e qual o custo de dizer “tente novamente mais tarde”?
Mapear risco de negócio às necessidades de consistência
Alguns domínios precisam de uma resposta autoritativa no momento da escrita porque “quase certo” ainda é errado:
- Dinheiro e faturamento: cobranças em duplicidade, descobertos e reembolsos normalmente demandam consistência forte.
- Identidade e permissões: login, reset de senha, controle de acesso e mudanças de função devem evitar comportamento split-brain.
- Inventário e capacidade: se overselling é inaceitável (ingressos, estoque limitado), prefira consistência — ou projete reservas explícitas.
Se o impacto de uma incompatibilidade temporária for baixo ou reversível, você pode inclinar mais para disponibilidade.
Decida quão desatualizado você pode tolerar
Muitas experiências de usuário funcionam bem com leituras levemente antigas:
- Feeds e timelines: um post aparecer alguns segundos depois costuma ser aceitável.
- Analytics e dashboards: números por lotes ou atrasados são comuns e esperados.
- Caches e índices de busca: usuários aceitam “não atualizado ainda” se for rápido e estável.
Seja explícito sobre quanto desatualizado é aceitável: segundos, minutos ou horas. Esse orçamento de tempo guia suas escolhas de replicação e quórum.
Escolha o modo de falha que os usuários mais odiarão
Quando réplicas não concordam, tipicamente você fica com uma das três saídas de UX:
- Spinner / espera (prioriza correção; pode parecer lento)
- Erro / retry (honesto, mas disruptivo)
- Resultado desatualizado (suave, mas ocasionalmente surpreendente)
Escolha a opção menos danosa por recurso, não globalmente.
Checklist rápido
Incline para C (consistência) se: resultados errados geram risco financeiro/legal, problemas de segurança ou ações irreversíveis.
Incline para A (disponibilidade) se: usuários valorizam responsividade, dados desatualizados são toleráveis e conflitos podem ser resolvidos com segurança depois.
Se estiver em dúvida, divida o sistema: mantenha registros críticos com consistência forte e deixe visões derivadas (feeds, caches, analytics) otimizar para disponibilidade.
Padrões de Design para Reduzir a Dor do Trade-Off
Instrumente para o trade-off
Adicione métricas de latência, taxa de erros e obsolescência ao seu app e itere nos limites.
Raramente você precisa escolher um único “nível de consistência” para todo o sistema. Muitos bancos modernos permitem escolher consistência por operação — e aplicações inteligentes aproveitam isso para manter a UX suave sem fingir que o trade-off não existe.
Use níveis de consistência por operação
Trate consistência como um botão que você ajusta conforme a ação do usuário:
- Atualizações críticas (pagamentos, decrementos de inventário, mudança de senha): use consistência mais forte (por exemplo, gravações em quórum/linearizáveis).
- Leituras não críticas (feeds, dashboards, “último visto”): permita leituras mais fracas (local/uma réplica/eventual) para velocidade e resiliência.
Isso evita pagar o custo da consistência máxima para tudo, protegendo apenas o que realmente importa.
Misture forte e fraco num mesmo fluxo
Um padrão comum é forte para gravações, mais fraco para leituras:
- Grave com nível estrito para que o sistema tenha um registro autoritativo.
- Leia com nível mais frouxo e, se detectar algo “estranho” (item ausente, contador desatualizado), recarregue com uma leitura mais forte ou mostre um aviso “ainda atualizando”.
Em alguns casos, o inverso funciona: gravações rápidas (enfileiradas/eventuais) + leituras fortes ao confirmar um resultado (“Meu pedido foi feito?”).
Projete para retries: idempotência
Quando redes oscilar, clientes reexecutam. Torne retries seguros com chaves de idempotência para que um “enviar pedido” executado duas vezes não crie dois pedidos. Armazene e reutilize o primeiro resultado quando a mesma chave for vista novamente.
Fluxos longos: sagas e compensação
Para ações multi-etapa entre serviços, use uma saga: cada passo tem uma ação compensadora (estornar, liberar reserva, cancelar envio). Isso torna o sistema recuperável mesmo quando partes temporariamente discordam ou falham.
Testes e Observabilidade para Consistência vs. Disponibilidade
Você não consegue administrar o trade-off se não consegue enxergá-lo. Problemas em produção frequentemente parecem “falhas aleatórias” até você adicionar as medidas e testes corretos.
O que medir (e por quê)
Comece com um conjunto pequeno de métricas que mapeiam diretamente para impacto no usuário:
- Latência (p50/p95/p99): observe picos durante failovers, trocas de líder ou retries por quórum.
- Taxa de erro: separe “erros duros” (timeouts, 5xx) de “erros suaves” (atendidos por fallback, resultados parciais).
- Taxa de leituras desatualizadas: percentagem de leituras que retornam dados mais antigos que seu alvo (por exemplo, mais de 2 segundos).
- Taxa de conflito: com que frequência gravações concorrentes exigem reconciliação (incluindo sobrescritas por last-write-wins).
Se puder, etiquete métricas por modo de consistência (quórum vs. local) e região/zona para identificar onde o comportamento diverge.
Teste partições de propósito
Não espere a falha real. Em staging, rode experimentos de caos que simulem:
- perda de pacotes e alta latência entre réplicas
- uma região ficando inacessível
- partições parciais onde só alguns nós se comunicam
Verifique não só “o sistema fica no ar”, mas quais garantias se mantêm: leituras continuam frescas? gravações são bloqueadas? clientes recebem erros claros?
Alertas que detectam o trade-off cedo
Adicione alertas para:
- lag de replicação excedendo sua janela de staleness tolerada
- falhas de quórum (não consegue alcançar réplicas suficientes) e aumento de retries
- aumento de conflitos de escrita ou backlog de reconciliação
Por fim, torne as garantias explícitas: documente o que seu sistema promete em operação normal e durante partições, e eduque times de produto e suporte sobre o que os usuários podem ver e como responder.
Prototipando Escolhas do CAP Mais Rápido (Sem Reconstruir Tudo)
Se você está explorando esses trade-offs num produto novo, ajuda validar suposições cedo — especialmente sobre modos de falha, comportamento de retry e como “desatualizado” aparece na UI.
Uma abordagem prática é prototipar um pequeno fluxo (caminho de gravação, caminho de leitura, retry/idempotência e um job de reconciliação) antes de se comprometer com uma arquitetura completa. Com Koder.ai, equipes podem levantar web apps e backends via fluxo guiado por chat, iterar rápido em modelos de dados e APIs e testar diferentes padrões de consistência (por exemplo, gravações estritas + leituras relaxadas) sem o overhead do pipeline tradicional de build. Quando o protótipo corresponder ao comportamento desejado, você exporta o código-fonte e evolui para produção.