08 de out. de 2025·8 min
Bancos de Dados SQL Distribuídos: Quando Usar Spanner, Cockroach e Yugabyte
Entenda o que é SQL distribuído, como Spanner, CockroachDB e YugabyteDB diferem, e em quais casos reais vale a pena um banco SQL fortemente consistente e multi-região.
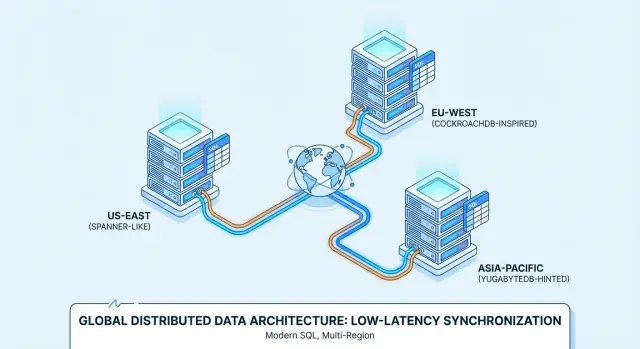
O que “Distributed SQL” Significa (Sem o Hype)
“Distributed SQL” é um banco de dados que parece e se comporta como um banco relacional tradicional—tabelas, linhas, joins, transações e SQL—mas foi projetado para rodar como um cluster em muitas máquinas (e frequentemente em várias regiões) enquanto ainda se comporta como um único banco de dados lógico.
Essa combinação importa porque tenta entregar três coisas ao mesmo tempo:
- SQL e modelagem relacional: esquemas familiares, constraints e ferramentas de consulta.
- Escala horizontal: adicionar nós para aumentar capacidade, em vez de “comprar um servidor maior”.
- Consistência forte: leituras e gravações seguem regras transacionais claras, mesmo quando os dados estão distribuídos.
Entre RDBMS clássico e NoSQL
Um RDBMS clássico (como PostgreSQL ou MySQL) costuma ser mais fácil de operar quando tudo vive em um único nó primário. Você pode escalar leituras com réplicas, mas escalar gravações e sobreviver a falhas regionais geralmente exige arquitetura adicional (sharding, failover manual e lógica de aplicação cuidadosa).
Muitos sistemas NoSQL tomaram o caminho oposto: priorizaram escala e alta disponibilidade, às vezes relaxando garantias de consistência ou oferecendo modelos de consulta mais simples.
Distributed SQL busca um caminho do meio: manter o modelo relacional e transações ACID, mas distribuir os dados automaticamente para lidar com crescimento e falhas.
O problema que está tentando resolver
Bancos Distributed SQL são construídos para problemas como:
- Aplicações globais com usuários em várias regiões, onde latência e disponibilidade importam.
- Alta disponibilidade sem procedimentos complexos de failover manual.
- Crescimento ao longo do tempo, quando você quer expandir capacidade incrementalmente e manter uma interface de banco única.
É por isso que produtos como Google Spanner, CockroachDB e YugabyteDB são frequentemente avaliados para implantação multi-região e serviços sempre ativos.
Ajuste as expectativas (não é o padrão)
Distributed SQL não é automaticamente “melhor”. Você está aceitando mais partes móveis e realidades de desempenho diferentes (saltos de rede, consenso, latência cross-region) em troca de resiliência e escala.
Se sua carga roda em um único banco bem administrado com replicação simples, um RDBMS convencional pode ser mais simples e barato. Distributed SQL justifica-se quando a alternativa é sharding personalizado, failover complexo, ou requisitos de negócio que exigem consistência multi-região e alta disponibilidade.
Como o Distributed SQL Funciona por Trás das Cenas
Distributed SQL pretende parecer um banco SQL familiar enquanto armazena dados em várias máquinas (e frequentemente em várias regiões). A parte difícil é coordenar muitos computadores para que se comportem como um sistema confiável e único.
Replicação + consenso: como os nós concordam
Cada pedaço de dado normalmente é copiado para vários nós (replicação). Se um nó falhar, outra cópia ainda pode servir leituras e aceitar gravações.
Para evitar que réplicas divergentes, sistemas Distributed SQL usam protocolos de consenso—mais comumente Raft (CockroachDB, YugabyteDB) ou Paxos (Spanner). Em alto nível, consenso significa:
- Uma réplica atua como “líder” para um grupo de réplicas.
- Gravações vão para o líder.
- O líder só confirma a gravação depois que a maioria das réplicas acusa recebimento.
Esse “voto da maioria” é o que te dá consistência forte: uma vez que uma transação commita, outros clientes não verão uma versão antiga dos dados.
Sharding/particionamento: onde os dados vivem
Nenhuma máquina única pode armazenar tudo, então tabelas são divididas em pedaços menores chamados shards/partições (o Spanner chama de splits; o CockroachDB chama de ranges; o YugabyteDB chama de tablets).
Cada partição é replicada (usando consenso) e colocada em nós específicos. O posicionamento não é aleatório: você pode influenciá-lo por políticas (por exemplo, manter registros de clientes da UE em regiões da UE, ou manter partições quentes em nós mais rápidos). Um bom posicionamento reduz viagens pela rede e mantém o desempenho mais previsível.
Transações entre nós (e por que isso acrescenta latência)
Com um banco em nó único, uma transação muitas vezes pode commitar com trabalho local de disco. No Distributed SQL, uma transação pode tocar várias partições—potencialmente em nós diferentes.
Commitar com segurança geralmente requer coordenação extra:
- Bloquear ou validar dados nas partições envolvidas
- Replicar gravações via consenso (confirmações da maioria)
- Finalizar uma decisão de commit para que todos os participantes concordem
Esses passos introduzem round trips de rede, por isso transações distribuídas tipicamente adicionam latência—especialmente quando dados atravessam regiões.
Comportamento multi-região: leituras e gravações com consciência de localidade
Quando implantações se estendem por regiões, os sistemas tentam manter operações “próximas” dos usuários:
- Leituras com consciência de localidade podem servir de réplicas próximas quando seguro.
- Gravações com consciência de localidade podem roteá-las para líderes em uma região escolhida, ou posicionar líderes perto dos escritores primários.
Esse é o equilíbrio central multi-região: você pode otimizar para responsividade local, mas consistência forte através de longas distâncias ainda terá um custo de rede.
Quando Você Realmente Precisa (E Quando Não Precisa)
Antes de optar por distributed SQL, cheque suas necessidades básicas. Se você tem uma região primária, carga previsível e um pequeno time de operações, um banco relacional convencional (ou um Postgres/MySQL gerenciado) costuma ser a maneira mais simples de entregar funcionalidades rapidamente. Muitas vezes você estica uma solução single-region com réplicas de leitura, cache e cuidado no schema/index.
Gatilhos claros: quando distributed SQL vale a pena
Distributed SQL merece consideração séria quando uma (ou mais) destas for verdadeira:
- Você tem usuários reais em múltiplas regiões e quer o banco próximo a eles sem construir sharding na aplicação.
- Requisitos de uptime são altos (por exemplo, você precisa sobreviver a falhas de zona/região) e uma única região primária é um risco inaceitável.
- Volume de dados ou throughput de gravação excede escala vertical, e você quer escalar horizontalmente mantendo semântica SQL.
- Você precisa de consistência forte entre nós/regiões para transações críticas (pedidos, saldos, reservas) sem costurar múltiplos sistemas.
- Compliance obriga colocação geográfica (residência de dados) enquanto ainda precisa de um banco lógico único.
Anti-gatilhos: quando geralmente não é a escolha certa
Sistemas distribuídos acrescentam complexidade e custo. Tenha cautela se:
- Seu time é pequeno e não tem tempo para aprender novos modos de falha e padrões operacionais.
- O tráfego é baixo ou esporádico e você provavelmente não vai ultrapassar um banco single-region em breve.
- Você tem orçamentos de latência muito apertados para gravações de chave única e não tolera o overhead de coordenação que a consistência forte pode introduzir.
- Sua carga é orientada a analytics (varreduras grandes, relatórios complexos). Talvez seja melhor separar OLTP de analytics.
Checklist rápido de decisão
Se você responder “sim” para dois ou mais, distributed SQL provavelmente vale a pena avaliar:
- Você precisa de multi-região com dados consistentes?
- Você precisa de failover automático entre zonas/regiões?
- Escalar virou uma crise recorrente?
- Sharding adicionaria mais overhead de engenharia que o próprio banco?
- Você precisa impor residência de dados com um único modelo operacional?
Consistência, Disponibilidade e Latência: Os Trade-offs Centrais
Distributed SQL soa como “ter tudo de uma vez”, mas sistemas reais forçam escolhas—especialmente quando regiões não conseguem se comunicar de forma confiável.
CAP, explicado para decisões de produto
Pense em uma partição de rede como “o link entre regiões está instável ou fora”. Nesse momento, um banco pode priorizar:
- Consistência: todos veem a mesma resposta atualizada (ou a operação falha).
- Disponibilidade: a aplicação continua aceitando leituras/gravações em cada região (mesmo que as respostas divirjam temporariamente).
Sistemas Distributed SQL tipicamente priorizam consistência para transações. Isso é o que muitas equipes querem—até que uma partição signifique que certas operações devem esperar ou falhar.
Consistência forte (e por que dinheiro e inventário se importam)
Consistência forte significa que, uma vez que uma transação commita, qualquer leitura subsequente retorna esse valor commitado—sem “funcionou em uma região mas não em outra”. Isso é crítico para:
- Pagamentos e saldos (evita double-spend ou totais incorretos)
- Inventário / reservas (previne oversell do último item)
Se sua promessa de produto é “quando confirmamos, é real”, consistência forte é um recurso, não luxo.
Read-your-writes e isolamento em apps reais
Dois comportamentos práticos importam:
- Read-your-writes: após um usuário atualizar seu perfil (ou fazer um pedido), a próxima tela deve mostrar o novo estado, não uma réplica mais antiga.
- Isolamento de transação: define como ações concorrentes interagem. Com isolamento mais forte, você evita bugs sutis como dois clientes reservando o mesmo assento.
O custo de latência do consenso cross-region
Consistência forte entre regiões normalmente requer consenso (múltiplas réplicas devem concordar antes do commit). Se réplicas estão em continentes diferentes, a velocidade da luz vira uma restrição de produto: cada gravação cross-region pode adicionar dezenas a centenas de milissegundos.
O trade-off é simples: mais segurança geográfica e correção frequentemente significa maior latência de gravação, a não ser que você escolha cuidadosamente onde os dados vivem e onde as transações podem commitar.
Spanner vs CockroachDB vs YugabyteDB: Visão Prática
Google Spanner é um banco de dados Distributed SQL oferecido principalmente como serviço gerenciado no Google Cloud. Foi projetado para implantações multi-região onde você quer um único banco lógico com dados replicados entre nós e regiões. O Spanner oferece duas opções de dialeto SQL—GoogleSQL (seu dialeto nativo) e um dialeto compatível com PostgreSQL—então a portabilidade varia dependendo da escolha.
CockroachDB é um banco Distributed SQL que busca oferecer uma experiência familiar a quem vem do PostgreSQL. Usa o protocolo wire do PostgreSQL e suporta grande parte do estilo SQL do Postgres, mas não é um substituto byte-a-byte (algumas extensões e comportamentos de canto diferem). Pode ser consumido como serviço gerenciado (CockroachDB Cloud) ou auto-hospedado.
YugabyteDB é um banco distribuído com API SQL compatível com PostgreSQL (YSQL) e uma API adicional compatível com Cassandra (YCQL). Assim como CockroachDB, costuma ser avaliado por equipes que querem ergonomia de desenvolvimento parecida com Postgres enquanto escalam por nós e regiões. Está disponível self-hosted e como oferta gerenciada (YugabyteDB Managed).
Gerenciado vs self-hosted: o que muda
Serviços gerenciados normalmente reduzem trabalho operacional (upgrades, backups, integrações de monitoramento), enquanto self-hosted dá mais controle sobre rede, tipos de instância e onde os dados rodam fisicamente. Spanner é mais comumente consumido como serviço gerenciado no GCP; CockroachDB e YugabyteDB aparecem em ambos os modelos, inclusive multi-cloud e on-prem.
Compatibilidade SQL na prática
Todos três falam “SQL”, mas a compatibilidade no dia a dia depende da escolha de dialeto (Spanner), cobertura de features do Postgres (CockroachDB/YugabyteDB) e se sua app depende de extensões, funções ou semânticas específicas do Postgres.
Planejar e testar cedo suas queries, migrações e comportamento do ORM vale muito—não assuma equivalência drop-in.
Caso de Uso: SaaS Global com Usuários Regionais
Prototipe um SaaS global
Crie um esqueleto de SaaS multi-tenant e valide cedo as suposições de alocação por tenant.
Um encaixe clássico para distributed SQL é um produto B2B SaaS com clientes na América do Norte, Europa e APAC—ferramentas de suporte, plataformas de RH, painéis analíticos ou marketplaces.
O requisito de negócio é direto: usuários querem experiência “local”, enquanto a empresa quer um banco lógico sempre disponível.
Residência de dados e colocação por cliente
Muitas equipes SaaS acabam com um misto de requisitos:
- Clientes da UE esperam que seus dados permaneçam na UE (GDPR, compromissos contratuais).
- Alguns clientes exigem armazenamento no país (por exemplo, Alemanha, Austrália, Singapura).
- Outros não se importam, mas ainda querem baixa latência.
Distributed SQL pode modelar isso de forma limpa com localidade por tenant: coloque os dados primários de cada tenant em uma região específica (ou conjunto de regiões) enquanto mantém o esquema e o modelo de consulta consistentes em todo o sistema. Assim você evita o espalhamento de “um banco por região” e ainda atende residência.
Minimizar latência: leituras regionais e posicionamento de gravações
Para manter o app rápido, normalmente visa-se:
- Leituras regionais: servir consultas com muito read a partir de réplicas perto do usuário.
- Posicionamento de gravações: colocar o líder de escrita (ou conjunto primário) na região onde as gravações do tenant ocorrem com mais frequência.
Isso importa porque round trips cross-region dominam a latência percebida pelo usuário. Mesmo com consistência forte, um bom design de localidade garante que a maioria das requisições não pague o custo de rede intercontinental.
Realidade operacional
Os ganhos técnicos só importam se a operação continuar gerenciável. Para SaaS global, planeje:
- Alterações de esquema online que não travem tabelas entre regiões.
- Migrações de tenant (mover um cliente de uma região para outra com downtime mínimo).
- Monitoramento e alerta para lag de replicação, hotspots, queries lentas e incidentes em nível de região.
Feito direito, distributed SQL te dá uma experiência de produto única que ainda parece local—sem dividir seu time de engenharia em “stack EU” e “stack APAC”.
Caso de Uso: Workflows Financeiros e Razões Contábeis
Sistemas financeiros são onde “eventual consistency” pode se traduzir em perda financeira real. Se um cliente faz um pedido, um pagamento é autorizado e um saldo é atualizado, esses passos precisam concordar em uma única verdade—agora.
Consistência forte importa porque impede que duas regiões (ou dois serviços) tomem decisões “razoáveis” diferentes que resultem em um ledger incorreto.
Por que consistência forte é inegociável
Em um fluxo típico—criar pedido → reservar fundos → capturar pagamento → atualizar saldo/ledger—você quer garantias como:
- Um pedido não pode ser marcado como “pago” se a captura do pagamento não ocorreu.
- Um saldo não pode ficar negativo porque duas transações competiram.
- Um reembolso não pode ser aplicado duas vezes por causa de retries de workers.
Distributed SQL se encaixa aqui porque oferece transações ACID e constraints entre nós (e frequentemente entre regiões), de modo que suas invariantes contábeis se mantêm mesmo durante falhas.
Idempotência e padrões “sem cobrança dupla”
A maioria das integrações de pagamento é propensa a retries: timeouts, webhooks reencaminhados e reprocessamento de jobs são normais. O banco deve ajudar a tornar retries seguras.
Uma abordagem prática é combinar chaves de idempotência a nível de aplicação com unicidade imposta pelo banco:
- Armazene uma
idempotency_keypor cliente/tentativa de pagamento. - Adicione uma constraint única em
(account_id, idempotency_key). - Envolva “criar registro de pagamento + aplicar entradas de ledger” em uma única transação.
Assim, a segunda tentativa vira um no-op em vez de uma cobrança dupla.
Lidando com picos sem quebrar a correção
Eventos de vendas e execuções de folha podem criar rajadas de gravações (autorizações, capturas, transferências). Com distributed SQL, você pode escalar horizontalmente adicionando nós para aumentar throughput de gravação enquanto mantém o mesmo modelo de consistência.
A chave é planejar para hot keys (por exemplo, uma conta comerciante recebendo todo o tráfego) e usar padrões de schema que espalhem a carga.
Compliance, auditorias e retenção
Workflows financeiros normalmente exigem trilhas de auditoria imutáveis, rastreabilidade (quem/o quê/quando) e políticas de retenção previsíveis. Mesmo sem citar regulações específicas, assuma que precisará de: entradas de ledger append-only, registros com timestamp, controle de acesso e políticas de retenção/arquivamento que não comprometam auditabilidade.
Caso de Uso: Inventário, Reservas e Booking
Transforme teoria em números
Passe de ideias de artigo para um app de benchmark mensurável que você pode executar e ajustar.
Inventário e reservas parecem simples até que várias regiões passem a servir o mesmo recurso escasso: o último assento do show, um produto de “drop” limitado, ou um quarto de hotel para uma noite específica.
A parte difícil não é ler disponibilidade—é evitar que duas pessoas consigam reivindicar o mesmo item quase simultaneamente.
De onde vêm os conflitos
Em uma configuração multi-região sem consistência forte, cada região pode temporariamente acreditar que tem disponibilidade com base em dados ligeiramente desatualizados. Se dois usuários finalizarem compras em regiões diferentes nesse intervalo, ambas transações podem ser aceitas localmente e só mais tarde entrarem em conflito durante reconciliação.
É assim que acontece oversell cross-region: não porque o sistema esteja “errado”, mas porque permitiu verdades divergentes por um momento.
Bancos Distributed SQL são frequentemente escolhidos aqui porque podem impor um único resultado autoritativo para alocações de escrita—então “o último assento” realmente é alocado uma vez, mesmo se requisições chegarem de continentes diferentes.
Exemplos concretos
- Reserva de assento: Dois usuários clicam no mesmo assento do mapa. Com consistência forte, só uma transação commita; a outra falha imediatamente e a UI pode pedir atualização.
- Drops limitados: 500 itens entram no ar e milhares tentam checkout. Você quer decremento-e-alocação atômicos, não “melhor esforço” seguido de reembolsos.
- Reservas de hotel: A unidade de inventário não é só o quarto, é a diária do quarto. Dobrar reserva de um intervalo de datas é caro e difícil de desfazer.
Padrões comuns que combinam bem com Distributed SQL
Hold + confirm: Coloque uma reserva temporária (registro de hold) em uma transação, depois confirme o pagamento em uma segunda etapa.
Expirações: Holds devem expirar automaticamente (ex.: após 10 minutos) para evitar travar inventário se o usuário abandonar o checkout.
Outbox transacional: Quando uma reserva é confirmada, escreva uma linha “evento a enviar” na mesma transação e entregue-a assincronamente para email, fulfillment, analytics ou um message bus—sem arriscar um gap de “reservado mas sem confirmação enviada”.
O resumo: se seu negócio não tolera dupla alocação entre regiões, garantias transacionais fortes passam a ser um recurso de produto, não um detalhe técnico.
Caso de Uso: Alta Disponibilidade e Recuperação de Desastres
Alta disponibilidade (HA) é um bom uso para Distributed SQL quando downtime é caro, falhas imprevisíveis são inaceitáveis e você quer que manutenção seja rotineira.
O objetivo não é “nunca falhar”—é cumprir SLOs claros (por exemplo, 99.9% ou 99.99% uptime) mesmo quando nós morrem, zonas falham ou você aplica upgrades.
“Sempre ativo” na prática: SLOs, manutenção, falhas
Comece traduzindo “sempre ativo” em expectativas mensuráveis: downtime máximo mensal, recovery time objective (RTO) e recovery point objective (RPO).
Sistemas Distributed SQL podem continuar servindo leituras/gravações através de muitas falhas comuns, mas somente se sua topologia corresponder ao seu SLO e sua app tratar erros transitórios (retries, idempotência) de forma limpa.
Manutenção planejada também importa. Upgrades rolling e substituições de instância são mais fáceis quando o banco pode mover liderança/réplicas para fora dos nós impactados sem derrubar o cluster inteiro.
Redundância multi-zone vs multi-região
Multi-zone protege contra uma única zona/AZ e muitas falhas de hardware, geralmente com menor latência e custo. Muitas vezes é suficiente se compliance e base de usuários estão majoritariamente em uma região.
Multi-região protege contra queda regional completa e suporta failover regional. O trade-off é maior latência de gravação para transações fortemente consistentes que atravessam regiões, além de planejamento de capacidade mais complexo.
Expectativas de failover (e testar com game days)
Não presuma que failover seja instantâneo ou invisível. Defina o que “failover” significa para seu serviço: picos breves de erro? períodos somente leitura? alguns segundos de latência elevada?
Faça “game days” para provar:
- Mate um nó, depois uma zona; verifique dashboards de SLO e budgets de erro do cliente.
- Simule partições de rede e verifique comportamento de líder/réplica.
- Pratique evacuação de região e meça o RTO real.
Replicação não é backup
Mesmo com replicação síncrona, mantenha backups e ensaie restore. Backups protegem contra erros humanos (migrations ruins, deletes acidentais), bugs de aplicação e corrupção que pode replicar.
Valide recuperação ponto-a-tempo (se disponível), velocidade de restauração e a habilidade de recuperar em um ambiente limpo sem tocar produção.
Caso de Uso: Residência de Dados e Arquiteturas Guiadas por Compliance
Requisitos de residência aparecem quando regulações, contratos ou políticas internas dizem que certos registros devem ser armazenados (e às vezes processados) em um país ou região específica.
Isso pode se aplicar a dados pessoais, informações de saúde, dados de pagamento, workloads governamentais ou conjuntos de dados “pertencentes ao cliente” onde o contrato dita onde os dados vivem.
Distributed SQL é frequentemente considerado aqui porque pode manter um banco lógico único enquanto fisicamente posiciona dados em regiões diferentes—sem forçar a execução de pilhas de aplicação completamente separadas por geografia.
Por que regras de residência mudam o desenho do banco
Se um regulador ou cliente exige “dados ficam na região”, não basta ter réplicas de baixa latência próximas. Pode ser necessário garantir que:
- A cópia primária (ou todas as cópias) de dados específicos seja armazenada apenas em regiões aprovadas
- Backups e snapshots sigam as mesmas regras
- Operadores e serviços fora da região não possam acessar os dados brutos
Isso empurra equipes a arquiteturas onde a localização é uma preocupação de primeira classe, não um detalhe.
Colocação por cliente e controles de acesso (alto nível)
Um padrão comum em SaaS é a colocação por tenant. Por exemplo: clientes da UE têm linhas/partições fixadas em regiões da UE, clientes dos EUA nas regiões dos EUA.
Em alto nível, normalmente você combina:
- Regras de colocação de dados (onde os dados de um tenant podem residir)
- Controles de identidade e acesso (quais serviços/pessoas podem ler)
- Criptografia e gestão de chaves (às vezes com chaves limitadas a regiões)
O objetivo é dificultar violações acidentais de residência via acesso operacional, restaurações de backup ou replicação cross-region.
Requisitos legais variam—consulte jurídico
Residência e obrigações de compliance variam muito por país, indústria e contrato. Também mudam com o tempo.
Trate a topologia do banco como parte do seu programa de compliance e valide suposições com assessoria jurídica qualificada (e, quando aplicável, seus auditores).
Como topologias multi-região afetam reporting e analytics
Topologias amigáveis à residência podem complicar visões “globais” do negócio. Se dados de clientes são intencionalmente mantidos em regiões separadas, analytics e reporting podem:
- Precisar pipelines regionais de reporting (compute roda onde os dados residem)
- Usar exports agregados (apenas métricas permitidas saem da região)
- Aceitar maior latência para dashboards cross-region, pois queries globais podem atravessar regiões ou depender de datasets replicados/derivados
Na prática, muitas equipes separam workloads operacionais (consistentes, sensíveis à residência) de analytics (data warehouses regionais ou datasets agregados governados) para manter compliance sem desacelerar reporting do dia a dia.
Planejamento de Custo e Desempenho para Distributed SQL
Modele eventos confiáveis
Esboce um fluxo de outbox transacional e itere rapidamente em esquema e handlers.
Distributed SQL pode te salvar de outages dolorosos e limitações regionais, mas raramente economiza dinheiro por padrão. Planejar antes ajuda a evitar pagar por “seguro” desnecessário.
Principais drivers de custo
A maioria dos orçamentos se divide em quatro buckets:
- Nós (compute): você paga por manter múltiplas réplicas online—frequentemente 3+ por região—além de capacidade extra para failover. Designs multi-região normalmente exigem mais headroom que um Postgres single-region.
- Armazenamento: replicação multiplica tamanho dos dados. Um dataset de 2 TB com três réplicas vira ~6 TB antes de backups, índices e overhead.
- Tráfego inter-regional: replicação cross-region, leituras e tráfego de cliente podem ser um item material na fatura. Normalmente é a primeira “surpresa” ao ir para active-active.
- Tempo de ops: mesmo ofertas gerenciadas exigem trabalho: tuning de schema/queries, resposta a incidentes, planejamento de capacidade, testes de upgrade e governança (especialmente sobre residência/compliance).
Estimando impacto de latência em jornadas reais
Sistemas Distributed SQL adicionam coordenação—especialmente para gravações fortemente consistentes que exigem quórum.
Uma forma prática de estimar impacto:
- Escolha 2–3 jornadas-chave (checkout, booking, “salvar alterações”).
- Conte quantos write transactions e passos de read-after-write acontecem no caminho crítico.
- Para cada passo, assuma um round trip multi-região onde coordenação é necessária. Se RTT cross-region for 80–120 ms, dois passos de gravação sequenciais podem adicionar 160–240 ms ao tempo do app.
Isso não significa “não fazer”; significa projetar jornadas para reduzir gravações sequenciais (batching, retries idempotentes, menos transações chats).
Complexidade vs alternativas mais simples
Se seus usuários estão majoritariamente em uma região, um Postgres single-region com réplicas de leitura, ótimos backups e um plano de failover testado pode ser mais barato e simples—e rápido.
Distributed SQL justifica seu custo quando você realmente precisa de gravações multi-região, RPO/RTO estritos ou colocação por residência.
Um enquadramento simples de ROI
Trate o gasto como uma troca:
- Risco evitado: menos outages que impactam receita, menos perda de dados, menos finais de semana de incidentes globais.
- Receita protegida: maior conversão por menor latência para usuários regionais, postura empresarial mais forte (SLA, compliance).
- Gasto: cluster base + overhead de replicação + tráfego + tempo de engenharia.
Se a perda evitada (downtime + churn + risco de compliance) for maior que o prêmio contínuo, o design multi-região é justificado. Caso contrário, comece mais simples e mantenha caminho de evolução.
Checklist de Adoção e Próximos Passos
Adotar distributed SQL é menos “levantar e mover” um banco e mais provar que sua carga específica se comporta bem quando dados e consenso estão espalhados entre nós (e possivelmente regiões). Um plano enxuto ajuda a evitar surpresas.
Prova de conceito (PoC) focada
Escolha uma carga que represente dor real: por ex., checkout/booking, provisionamento de conta ou lançamento de ledger.
Defina métricas de sucesso desde o início:
- Correção: sem double-bookings, sem updates perdidos, comportamento transacional previsível
- SLOs de latência: p50/p95 das 3 principais queries (inclua alvos cross-region se relevante)
- Throughput: QPS sustentado no pico + margem de segurança (frequentemente 2–3×)
- Resiliência: comportamento durante perda de nó e (se aplicável) perda de região
- Esforço operacional: tempo para detectar, diagnosticar e recuperar de um incidente simulado
Se quiser acelerar na etapa de PoC, vale construir uma pequena app “realista” (API + UI) em vez de apenas benchmarks sintéticos. Por exemplo, times às vezes usam Koder.ai para gerar um app leve React + Go + PostgreSQL via chat, então trocam a camada de banco para CockroachDB/YugabyteDB (ou conectam ao Spanner) para testar padrões de transação, retries e falhas fim-a-fim. O ponto não é o stack inicial—é encurtar o ciclo de “ideia” para “carga que você consegue medir”.
Checklist de design (o que morde mais tarde)
- Schema: escolha chaves primárias que distribuam gravações; evite chaves sequenciais “quentes”
- Índices: mantenha só o que precisa; entenda amplificação de gravação por índices secundários
- Particionamento/colocação: decida chaves de partição (e regras geo/zone) baseadas em padrões de acesso
- Hot spots: identifique “celebrity rows” (contadores globais, tabelas single-tenant) e redesenhe cedo
- Migrations: planeje alterações de esquema online e backfills; teste caminhos de rollback
Básicos operacionais para ter desde o dia um
Monitoramento e runbooks importam tanto quanto SQL:
- Dashboards para latência, retries, contenção, saúde de replicação/consenso, disco e compactions
- Runbooks de incidente: queries lentas, reinício de nó, réplicas falhando, carga desigual
- Testes de carga que imitam produção (mix read/write, rajadas, transações longas)
- Backups + exercícios de restauração (incluindo recuperação ponto-a-tempo, se suportada)
Próximos passos
Comece com uma sprint de PoC, depois reserve tempo para revisão de prontidão para produção e um corte gradual (dual writes ou shadow reads quando possível).
Se precisar de ajuda para dimensionar custos ou tiers, veja /pricing. Para guias práticos e padrões de migração, consulte /blog.
Se você documentar descobertas do PoC, trade-offs de arquitetura ou lições de migração, considere compartilhar com seu time (e publicamente, se possível): plataformas como Koder.ai até oferecem formas de ganhar créditos criando conteúdo educativo ou indicando outros builders, o que pode compensar custos de experimentação enquanto você avalia opções.
Perguntas frequentes
O que é um banco de dados “distributed SQL” em termos simples?
Um banco de dados Distributed SQL fornece uma interface relacional e SQL (tabelas, joins, constraints, transações) mas roda como um cluster em várias máquinas—frequentemente em várias regiões—enquanto age como um único banco de dados lógico.
Na prática, tenta combinar:
- Comportamento SQL/ACID familiar
- Escala horizontal (adicionar nós)
- Alta disponibilidade e tolerância a falhas sem sharding manual
Como o distributed SQL difere de um PostgreSQL/MySQL tradicional?
Um RDBMS em nó único ou com primário/replica costuma ser mais simples, barato e rápido para OLTP em uma única região.
Distributed SQL se torna atraente quando a alternativa é:
- Sharding gerenciado pela aplicação
- Failover multi-região complexo
- Requisitos de forte consistência entre zonas/regiões
- Necessidades de residência de dados com um único modelo operacional
Por que os sistemas distributed SQL usam protocolos de consenso como Raft ou Paxos?
A maioria dos sistemas depende de duas ideias centrais:
- Replicação: cada shard/partição de dados é armazenado em múltiplos nós.
- Consenso (por exemplo, Raft ou Paxos): as réplicas concordam na ordem das gravações; commits normalmente exigem que uma maioria confirme.
Isso permite consistência forte mesmo quando nós falham—mas acrescenta overhead de coordenação pela rede.
Como os dados são particionados e posicionados entre nós/regiões?
Eles dividem tabelas em pedaços menores (frequentemente chamados de partições/shards, ou nomes específicos do fornecedor como ranges/tablets/splits). Cada partição:
- Tem seu próprio grupo de réplicas
- Pode ser colocada em nós/regiões específicas
- Pode se mover conforme o cluster reequilibra
Normalmente você influencia a colocação com políticas para que dados “quentes” e escritores principais fiquem próximos, reduzindo viagens pela rede.
Por que as transações podem ser mais lentas no distributed SQL, especialmente entre regiões?
Transações distribuídas frequentemente tocam múltiplas partições, possivelmente em nós (ou regiões) diferentes. Um commit seguro pode exigir:
- Locks/validação entre participantes
- Confirmações de replicação (quorum)
- Uma decisão coordenada de commit
Essas etapas introduzem round trips pela rede, que é a principal razão para aumento da latência de gravação—especialmente quando o consenso atravessa regiões.
Quais são os sinais mais claros de que eu realmente preciso de distributed SQL?
Considere distributed SQL quando duas ou mais das seguintes condições forem verdadeiras:
- Você tem usuários relevantes em múltiplas regiões e quer dados consistentes
- Precisa de failover automático entre zonas/regiões (RTO/RPO apertados)
- Escalar verticalmente não é mais suficiente para gravações
- Precisa de consistência forte para transações críticas (dinheiro, inventário, reservas)
- Compliance exige colocação geográfica dos dados
Se sua carga roda bem em uma região com réplicas/cache, um RDBMS convencional costuma ser a melhor opção por padrão.
O que “consistência forte” me dá, e o que ela custa?
Consistência forte significa que, uma vez que uma transação commita, leituras subsequentes não verão dados antigos.
Em termos de produto, ajuda a prevenir:
- Double-spend / saldos incorretos
- Overselling do último item
- Dois usuários reservando o mesmo assento
O custo é que, durante partições de rede, um sistema fortemente consistente pode bloquear ou falhar algumas operações em vez de aceitar verdades divergentes.
Como devo tratar retries de forma segura (idempotência) com distributed SQL?
Dependa de constraints no banco + transações:
- Armazene uma
idempotency_key(ou similar) por requisição/tentativa - Adicione uma constraint única, por exemplo
(account_id, idempotency_key) - Em uma única transação, escreva o registro de negócio + quaisquer linhas de ledger/outbox
Isso transforma tentativas repetidas em no-ops em vez de duplicatas—crítico para pagamentos, provisão e reprocessamento de jobs em background.
Como escolher entre Spanner, CockroachDB e YugabyteDB?
Uma separação prática:
- Spanner: tipicamente gerenciado no GCP; forte herança para multi-região; a escolha do dialeto SQL afeta portabilidade.
- CockroachDB: experiência parecida com Postgres e protocolo wire compatível; gerenciado ou self-hosted; não é 100% compatível com Postgres.
- YugabyteDB: API SQL compatível com Postgres (YSQL) e API compatível com Cassandra (YCQL); gerenciado ou self-hosted.
Antes de escolher, teste seu ORM/migrações e quaisquer extensões Postgres das quais você dependa—não presuma compatibilidade total.
Qual é um bom plano de prova de conceito antes de adotar distributed SQL?
Comece com um PoC focado em um fluxo crítico (checkout, booking, gravação de ledger). Valide:
- Correção (sem dupla reserva/atualizações perdidas)
- Latência p50/p95 para as principais consultas (incluindo alvos cross-region)
- Comportamento em falhas (perda de nó, zona e, se relevante, região)
- Fundamentos operacionais (monitoramento, backups, exercícios de restauração)
Se precisar de ajuda para dimensionar custos/tiers, veja /pricing. Para notas de implementação relacionadas, consulte /blog.