O que significa busca semântica (sem o jargão)
Busca semântica é uma forma de procurar que foca no que você quer dizer, não apenas nas palavras exatas que você digita.
Se você já pesquisou algo e pensou “a resposta está claramente aqui—por que não encontra?”, você sentiu os limites da busca por palavra-chave. A busca tradicional compara termos. Isso funciona quando a redação da sua consulta e do conteúdo se sobrepõem.
Por que a busca por palavra-chave muitas vezes erra
A busca por palavra-chave tem dificuldade com:
- Sinônimos e formulações: “cancelar” vs “encerrar” vs “dar baixa” em uma conta.
- Intenção: “como faço para não ser cobrado?” é, na prática, sobre cancelar uma assinatura.
- Contexto: “apple charger” (marca) vs “carregador de macieira” (sem sentido, mas dá a ideia).
Também pode supervalorizar palavras repetidas, retornando resultados que parecem relevantes na superfície enquanto ignora a página que realmente responde usando palavras diferentes.
Um exemplo simples
Imagine um centro de ajuda com um artigo intitulado “Pausar ou cancelar sua assinatura.” Um usuário pesquisa:
“parar meus pagamentos no próximo mês”
Um sistema por palavra-chave pode não ranquear bem esse artigo se ele não contém “parar” ou “pagamentos.” A busca semântica foi feita para entender que “parar meus pagamentos” está intimamente relacionado a “cancelar assinatura” e colocar esse artigo no topo—porque o significado é alinhado.
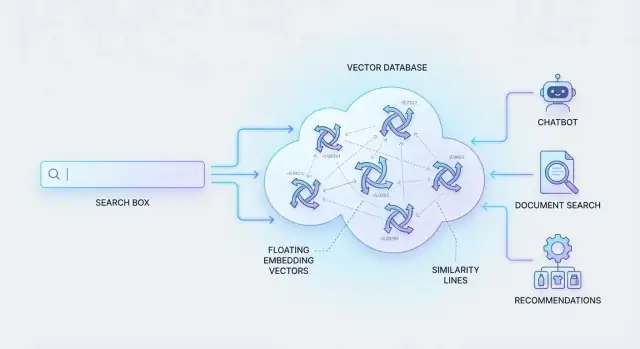
Onde os bancos vetoriais entram nisso
Para fazer isso funcionar, sistemas representam conteúdo e consultas como “impressões digitais de significado” (números que capturam similaridade). Depois eles precisam buscar através de milhões dessas impressões rapidamente.
É para isso que bancos de dados vetoriais foram construídos: armazenar essas representações numéricas e recuperar as correspondências mais similares de forma eficiente, para que a busca semântica pareça instantânea mesmo em grande escala.
Um embedding é uma representação numérica de significado. Em vez de descrever um documento com palavras-chave, você o representa como uma lista de números (um “vetor”) que captura sobre o que o conteúdo trata. Dois conteúdos que significam coisas parecidas acabam com vetores próximos nesse espaço numérico.
Como é um embedding na prática
Pense em um embedding como uma coordenada em um mapa de altíssima dimensionalidade. Normalmente você não lerá os números diretamente—eles não são feitos para humanos. O valor está em como eles se comportam: se “cancelar minha assinatura” e “como faço para parar meu plano?” produzem vetores próximos, o sistema pode tratá-los como relacionados mesmo quando compartilham poucas (ou nenhuma) palavras.
Texto, imagens e áudio também viram vetores
Embeddings não se limitam a texto.
- Embeddings de texto representam sentenças, parágrafos, tickets de suporte, descrições de produto e mais.
- Embeddings de imagem representam similaridade visual e conceitos (por exemplo, “tênis de corrida vermelho”).
- Embeddings de áudio podem representar falantes, tom, ou o significado do falado quando combinados com modelos de speech.
É assim que um único banco vetorial pode suportar “buscar por imagem”, “encontrar músicas parecidas” ou “recomendar produtos semelhantes”.
Gerados por modelos — não etiquetados à mão
Vetores não vêm de marcação manual. Eles são produzidos por modelos de machine learning treinados para comprimir significado em números. Você envia conteúdo a um modelo de embedding (hospedado por você ou por um provedor) e ele retorna um vetor. Seu app armazena esse vetor junto com o conteúdo original e metadados.
Por que a escolha do embedding afeta qualidade e custo
O modelo de embedding que você escolher influencia fortemente os resultados. Modelos maiores ou mais especializados frequentemente melhoram a relevância, mas custam mais (e podem ser mais lentos). Modelos menores podem ser mais baratos e rápidos, mas podem perder sutilezas—especialmente para linguagem de domínio, múltiplos idiomas ou consultas curtas. Muitas equipes testam alguns modelos no começo para achar o melhor trade-off antes de escalar.
Como os bancos de dados vetoriais armazenam dados
Um banco vetorial é construído em torno de uma ideia simples: armazenar “significado” (um vetor) junto das informações que você precisa para identificar, filtrar e exibir resultados.
O modelo de dados básico
A maioria dos registros se parece com isto:
- ID: um identificador único que você controla (por exemplo,
doc_18492 ou um UUID)
- Vetor (embedding): um array de números que representa o significado do conteúdo
- Metadados: campos chave–valor como title, URL, tags, author, language, created_at, ou tenant_id
Por exemplo, um artigo do centro de ajuda pode armazenar:
- ID:
kb_123
- Vetor: 768 números de ponto flutuante (para um modelo de embedding comum)
- Metadados:
{ "title": "Redefinir sua senha", "url": "/help/reset-password", "tags": ["account", "security"] }
O vetor é o que alimenta a similaridade semântica. O ID e os metadados são o que tornam os resultados utilizáveis.
Metadados fazem duas funções:
- Filtragem antes/depois da busca vetorial: “Mostrar apenas resultados do produto X”, “Apenas inglês”, “Apenas documentos que o usuário pode acessar”, ou “Apenas itens mais novos que 90 dias.” Isso é essencial para relevância e controle de acesso.
- Exibição e ações: Ao apresentar um resultado, usuários não querem um vetor—eles querem um título, um trecho e um link (URL). Metadados fornecem os detalhes que sua UI precisa.
Sem bons metadados, você pode recuperar o significado certo e ainda mostrar o contexto errado.
Tamanhos comuns de vetores e implicações de armazenamento
O tamanho do embedding depende do modelo: 384, 768, 1024, e 1536 dimensões são comuns. Mais dimensões podem capturar nuances, mas também aumentam:
- Armazenamento (cada registro guarda mais números)
- Pressão de memória para busca rápida
- Tempo de construção de índice (especialmente com indexação ANN)
Como intuição: dobrar as dimensões frequentemente aumenta custo e latência, a menos que você compense com escolhas de indexação ou compressão.
Padrões de atualização: inserções, alterações e exclusões
Conjuntos de dados reais mudam, então bancos vetoriais normalmente suportam:
- Insert: adicionar novo conteúdo com seu embedding e metadados
- Update: alterar metadados (por exemplo, tags) ou substituir o vetor se o conteúdo mudou
- Delete: remover conteúdo obsoleto ou revogado
- Re-embed: recalcular vetores quando você troca de modelo de embedding, muda o chunking ou edita o texto significativamente
Planejar atualizações cedo evita um problema de “conhecimento obsoleto” em que a busca retorna conteúdo que não corresponde mais ao que os usuários veem.
Busca por similaridade: encontrar o “significado mais próximo” rapidamente
Depois que seu texto, imagens ou produtos são convertidos em embeddings (vetores), buscar vira um problema de geometria: “Quais vetores estão mais próximos deste vetor de consulta?” Isso se chama nearest-neighbor search. Em vez de casar palavras-chave, o sistema compara significados medindo quão perto dois vetores estão.
Vizinhos mais próximos em termos simples
Imagine cada conteúdo como um ponto em um enorme espaço multidimensional. Quando um usuário pesquisa, sua consulta vira outro ponto. A busca por similaridade retorna os itens cujos pontos estão mais próximos—seus “vizinhos mais próximos”. Esses vizinhos provavelmente compartilham intenção, tópico ou contexto, mesmo sem palavras exatas em comum.
Métricas de similaridade comuns
Bancos vetoriais normalmente suportam algumas formas padrão de pontuar “proximidade”:
- Similaridade cosseno: compara o ângulo entre vetores (útil quando você se importa mais com direção/significado que com magnitude).
- Produto escalar: relacionado ao cosseno, mas também influenciado pelo comprimento do vetor; usado frequentemente com embeddings normalizados.
- Distância euclidiana: a distância em linha reta entre pontos (útil em alguns modelos e domínios).
Modelos de embedding diferentes são treinados pensando em uma métrica específica, então é importante usar a recomendada pelo provedor do modelo.
Busca exata vs aproximada (ANN)
Uma busca exata checa todo vetor para encontrar os verdadeiros vizinhos mais próximos. Isso pode ser preciso, mas fica lento e caro quando você escala para milhões de itens.
A maioria dos sistemas usa ANN (approximate nearest neighbor). ANN usa estruturas de indexação inteligentes para reduzir a busca ao conjunto de candidatos mais promissores. Normalmente você obtém resultados “bons o bastante” — muito mais rápidos.
O trade-off entre latência e recall
ANN é popular porque permite ajuste:
- Latência menor (respostas mais rápidas) ao buscar menos candidatos.
- Recall maior (encontrar mais dos verdadeiros melhores matches) ao buscar mais.
Esse ajuste é a razão pela qual a busca vetorial funciona bem em apps reais: você mantém respostas rápidas enquanto ainda retorna resultados altamente relevantes.
Fluxo de busca semântica de ponta a ponta
A busca semântica é mais fácil de entender como um pipeline simples: você transforma texto em significado, procura significado similar, e então apresenta as correspondências mais úteis.
1) Embedar a consulta
Um usuário digita uma pergunta (por exemplo: “Como cancelo meu plano sem perder dados?”). O sistema envia esse texto a um modelo de embeddings, produzindo um vetor—um array de números que representa o significado da consulta em vez de suas palavras exatas.
2) Buscar no banco vetorial
Esse vetor de consulta é enviado ao banco vetorial, que realiza uma busca por similaridade para encontrar os vetores “mais próximos” entre o conteúdo armazenado.
A maioria dos sistemas retorna top-K matches: os K chunks/documentos mais similares.
- Por que K é configurável: um K menor é mais rápido e frequentemente suficiente (por exemplo, K=5).
- Um K maior aumenta o recall (você tem menos chance de perder a resposta certa), mas pode incluir mais resultados “quase relevantes” (por exemplo, K=50).
3) (Opcional) Reordenar para precisão
A busca por similaridade é otimizada para velocidade, então o top-K inicial pode conter falsos positivos. Um reranker é um segundo modelo que olha a consulta e cada candidato juntos e os reordena por relevância.
Pense assim: a busca vetorial dá uma lista curta forte; o reranker escolhe a melhor ordem.
4) Retornar resultados (ou alimentar etapas downstream)
Por fim, você retorna as melhores correspondências ao usuário (como resultados de busca), ou as passa para um assistente de IA (por exemplo, um sistema RAG) como o contexto de fundamentação.
Se você está incorporando esse fluxo em um app, plataformas como Koder.ai podem ajudar a prototipar rápido: você descreve a experiência de busca semântica ou RAG em uma interface de chat, então itera no front-end React e no back-end Go/PostgreSQL enquanto mantém o pipeline de recuperação (embedding → busca vetorial → rerank opcional → resposta) como parte central do produto.
Um rápido exemplo “palavras-chave vs semântico”
Se seu artigo do centro de ajuda diz “encerrar assinatura” e o usuário pesquisa “cancelar meu plano”, a busca por palavra-chave pode perder porque “cancelar” e “encerrar” não batem. A busca semântica normalmente o recuperará porque o embedding captura que ambas as frases expressam a mesma intenção. Adicione reranking, e os resultados do topo costumam se tornar não só “semelhantes”, mas diretamente acionáveis para a pergunta do usuário.
Do chat ao app, de ponta a ponta
Descreva a UX que você quer e deixe o Koder.ai estruturar o app para você.
A busca vetorial pura é ótima em “significado”, mas usuários nem sempre pesquisam por significado. Às vezes precisam de uma correspondência exata: nome completo de uma pessoa, um SKU, um número de fatura ou um código de erro copiado de um log. A busca híbrida resolve isso combinando sinais semânticos (vetores) com sinais lexicais (busca tradicional por palavra-chave como BM25).
O que a “busca híbrida” realmente faz
Uma query híbrida tipicamente executa dois caminhos de recuperação em paralelo:
- Busca vetorial: encontra conteúdo conceitualmente similar, mesmo que a redação difira.
- Busca por palavra-chave/BM25: encontra conteúdo que compartilha os mesmos tokens, recompensando termos exatos e palavras raras.
O sistema então mescla esses candidatos em uma única lista ranqueada.
Quando híbrida é o melhor padrão
A busca híbrida brilha quando seus dados incluem strings que são “deve-casar”:
- Nomes de produto com modificadores específicos (por exemplo, “Pro Max”, “Gen 2”)
- IDs (números de pedido, IDs de ticket, números de peça)
- Códigos de erro (“E0421”, “ORA-00933”) e flags de comando
- Termos de domínio raros onde sinônimos seriam arriscados
A busca semântica sozinha pode devolver páginas amplamente relacionadas; a busca por palavra-chave sozinha pode perder respostas relevantes redigidas de forma diferente. A híbrida cobre ambos os modos de falha.
Filtros de metadados restringem a recuperação antes do ranqueamento (ou junto dele), melhorando relevância e velocidade. Filtros comuns incluem:
- Idioma (retornar apenas documentos em inglês)
- Intervalo de datas (política mais recente, notas de versão mais novas)
- Categoria ou fonte (docs vs tickets; “billing” vs “security”)
- Tags de controle de acesso (apenas o que este usuário pode ver)
Como a pontuação funciona (visão geral)
A maioria dos sistemas usa uma mistura prática: roda ambas as buscas, normaliza scores para torná-los comparáveis e então aplica pesos (por exemplo, “dar mais peso a keywords para IDs”). Alguns produtos também rerankeiam a lista mesclada com um modelo leve ou regras, enquanto filtros garantem que você esteja ranqueando o subconjunto certo em primeiro lugar.
RAG: usando bancos vetoriais para fundamentar respostas de LLMs
Retrieval-Augmented Generation (RAG) é um padrão prático para obter respostas mais confiáveis de um LLM: primeiro recupere informação relevante, depois gere uma resposta vinculada a esse contexto recuperado.
A ideia do RAG em uma frase
Em vez de pedir ao modelo que “lembre” seus documentos da empresa, você armazena esses documentos (como embeddings) em um banco de dados vetorial, recupera os chunks mais relevantes no momento da pergunta e os passa ao LLM como contexto de apoio.
Por que um banco vetorial ajuda a reduzir alucinações
LLMs são excelentes em escrever, mas tendem a preencher lacunas com confiança quando não têm os fatos necessários. Um banco vetorial facilita buscar os trechos de significado mais próximo da sua base de conhecimento e fornecê-los ao prompt.
Esse grounding desloca o modelo de “inventar uma resposta” para “resumir e explicar essas fontes”. Também torna as respostas mais auditáveis, porque você pode rastrear quais chunks foram recuperados e opcionalmente mostrar citações.
Fundamentos de chunking (para que a recuperação funcione)
A qualidade do RAG muitas vezes depende mais do chunking do que do modelo.
- Tamanho do chunk: Mire em chunks que contenham um pensamento completo (frequentemente uma seção curta). Muito pequeno perde significado; muito grande puxa ruído.
- Sobreposição: Adicione uma pequena sobreposição para que detalhes importantes nas bordas não sejam separados do contexto.
- Manter contexto: Preserve títulos, cabeçalhos e identificadores (nome do doc, seção, data) como metadados para que os resultados sejam compreensíveis e filtráveis.
Diagrama simples do pipeline RAG (descrição)
Imagine este fluxo:
Pergunta do usuário → Embedar pergunta → Banco vetorial recupera top-k chunks (+ filtros de metadados opcionais) → Montar prompt com os chunks recuperados → LLM gera resposta → Retornar resposta (e fontes).
O banco vetorial fica no meio como a “memória rápida” que fornece as evidências mais relevantes para cada requisição.
Casos de uso comuns impulsionados por bancos vetoriais
Estenda seus créditos
Crie conteúdo sobre Koder.ai ou indique colegas para aumentar seu tempo de construção.
Bancos vetoriais não apenas tornam a busca “mais inteligente”—eles viabilizam experiências de produto onde usuários descrevem o que querem em linguagem natural e ainda obtêm resultados relevantes. Abaixo alguns casos práticos recorrentes.
Suporte ao cliente: encontrar respostas além de palavras-chave
Equipes de suporte costumam ter base de conhecimento, tickets antigos, transcrições de chat e notas de release—mas a busca por palavra-chave sofre com sinônimos, paráfrases e descrições vagas de problemas.
Com busca semântica, um agente (ou chatbot) pode recuperar tickets passados que significam a mesma coisa mesmo que a redação seja diferente. Isso acelera resolução, reduz trabalho duplicado e ajuda novos agentes a subirem de nível mais rápido. Combinar busca vetorial com filtros de metadados (linha de produto, idioma, tipo de problema, intervalo de datas) mantém os resultados focados.
Descoberta de produto: buscar catálogos como as pessoas falam
Compradores raramente sabem nomes exatos de produtos. Eles pesquisam intenções como “mochila pequena que caiba um laptop e pareça profissional.” Embeddings capturam essas preferências—estilo, função, restrições—para que os resultados pareçam mais com um vendedor humano.
Essa abordagem funciona para catálogos de varejo, anúncios de viagem, imóveis, vagas e marketplaces. Você também pode misturar relevância semântica com restrições estruturadas como preço, tamanho, disponibilidade ou localização.
Recomendações: “itens semelhantes” e descoberta de conteúdo
Uma funcionalidade clássica de bancos vetoriais é “encontrar itens como este.” Se um usuário visualiza um item, lê um artigo ou assiste a um vídeo, você pode recuperar outros conteúdos com significado ou atributos similares—mesmo quando as categorias não coincidem perfeitamente.
Isso é útil para:
- Módulos “Mais como este”
- Artigos relacionados e sugestões da base de conhecimento
- Detecção de duplicatas ou quase-duplicatas (moderação de conteúdo ou limpeza)
Dentro das empresas, a informação está espalhada por docs, wikis, PDFs e notas de reunião. A busca semântica ajuda funcionários a perguntar naturalmente (“Qual é nossa política de reembolso para conferências?”) e encontrar a fonte certa.
A parte inegociável é controle de acesso. Resultados devem respeitar permissões—frequentemente filtrando por time, dono do doc, nível de confidencialidade ou uma lista ACL—para que usuários só recuperem o que têm direito a ver.
Se quiser ir além, essa mesma camada de recuperação é o que alimenta sistemas de Q&A fundamentados (cobertos na seção RAG).
Pipelines de dados: ingestão, chunking e atualizações
Um sistema de busca semântica só é tão bom quanto o pipeline que o alimenta. Se documentos chegam de modo inconsistente, são chunkados mal ou nunca re-embeddados após edições, os resultados se afastam do que os usuários esperam.
Um fluxo de ingestão simples (que funciona)
A maioria das equipes segue uma sequência repetível:
- Coletar dados (docs, PDFs, tickets, logs de chat, páginas de wiki, dados de produto).
- Limpar (remover boilerplate, corrigir encoding, normalizar espaços, extrair texto principal).
- Chunkar (dividir em trechos do tamanho que usuários realmente gostariam de recuperar).
- Embeder (gerar vetores com o modelo de embedding escolhido).
- Upsert (gravar vetores + metadados no banco vetorial, substituindo quando necessário).
O passo de “chunk” é onde muitos pipelines ganham ou perdem. Chunks muito grandes diluem significado; muito pequenos perdem contexto. Uma abordagem prática é chunkar por estrutura natural (títulos, parágrafos, pares Q&A) e manter uma pequena sobreposição para continuidade.
Manter embeddings atualizados
O conteúdo muda constantemente—políticas são atualizadas, preços mudam, artigos são reescritos. Trate embeddings como dados derivados que precisam ser regenerados.
Táticas comuns:
- Armazene um source document ID, chunk ID e um hash do conteúdo. Se o hash mudar, re-embede aquele chunk.
- Use soft deletes (marcar chunks antigos como inativos) para evitar resultados fantasmas.
- Reconstituir seletivamente em vez de re-embedar tudo.
Atualizações em lote vs streaming
- Batch é ideal para backfills grandes, sincronizações noturnas e conteúdo previsível (documentação, bases de conhecimento).
- Streaming serve fontes que mudam rápido (tickets de suporte, conteúdo gerado por usuários, inventário). Reduz obsolescência mas exige monitoramento e controle de custo mais rigorosos.
Multiplos idiomas e múltiplos modelos
Se você atende múltiplos idiomas, pode usar um modelo de embedding multilíngue (mais simples) ou modelos por idioma (às vezes com qualidade superior). Se experimentar modelos, versione seus embeddings (por ex., embedding_model=v3) para rodar A/B tests e reverter sem quebrar a busca.
Como avaliar qualidade e desempenho
Busca semântica pode parecer “boa” em demo e ainda falhar em produção. A diferença é medição: você precisa de métricas claras de relevância e metas de velocidade, avaliadas em consultas que parecem com o comportamento real do usuário.
Métricas de relevância que refletem satisfação do usuário
Comece com um pequeno conjunto de métricas e mantenha-as ao longo do tempo:
- Precision / Recall: Precision diz quantos retornados são realmente relevantes; recall diz quantos itens relevantes você conseguiu recuperar. Use quando houver definição clara de “relevante”.
- MRR (Mean Reciprocal Rank): Ótimo quando usuários esperam uma “melhor” resposta. Recompensa colocar o documento certo no topo.
- nDCG: Útil quando múltiplos resultados podem ser relevantes em diferentes níveis (altamente relevante vs. moderadamente relevante).
- Latência (p50/p95): Acompanhe média e cauda. Um p50 rápido com p95 lento ainda parece devagar para usuários.
Construir um conjunto de testes confiável
Crie um conjunto de avaliação a partir de:
- Consultas reais dos logs de busca ou tickets de suporte (anonimizadas).
- Documentos esperados (labels ouro) acordados por especialistas do domínio.
- Casos de borda: consultas curtas (“reembolso”), perguntas longas, termos ambíguos, nomes de produto raros e queries “sem resultado” onde o comportamento correto é dizer “nada encontrado”.
Mantenha o conjunto de testes versionado para comparar resultados entre releases.
A/B testing e ciclos de feedback
Métricas offline não capturam tudo. Rode A/B tests e colete sinais leves:
- Polegares para cima/baixo nos resultados
- Click-through e tempo de permanência
- Eventos de “refinar busca”
Use esse feedback para atualizar julgamentos de relevância e detectar padrões de falha.
Monitorar drift ao longo do tempo
O desempenho pode mudar quando:
- Você troca modelos de embedding ou atualiza como chunka conteúdo.
- Seu corpus muda (novos produtos, mudanças de política, termos sazonais).
Rode sua suíte de testes após qualquer mudança, monitore métricas semanalmente e configure alertas para quedas bruscas em MRR/nDCG ou picos na latência p95.
Segurança, privacidade e considerações de controle de acesso
Implemente uma busca de suporte melhor
Transforme o conteúdo do seu centro de ajuda em uma experiência de busca com filtros e opções de reordenação.
A busca vetorial muda como dados são recuperados, mas não deveria mudar quem pode vê-los. Se seu sistema semântico ou RAG consegue “encontrar” o trecho correto, ele também pode, acidentalmente, retornar um trecho que o usuário não estava autorizado a ver—a menos que você projete permissões e privacidade na etapa de recuperação.
Controle de acesso: aplique na recuperação
A regra mais segura é simples: um usuário deve recuperar apenas conteúdo que ele tem permissão para ler. Não confie no app para “esconder” resultados depois que o banco vetorial os retornou—porque, nesse ponto, o conteúdo já saiu do seu limite de armazenamento.
Abordagens práticas incluem:
- ACLs por documento (ou por chunk): armazene campos de permissão junto a cada vetor para que toda query possa aplicá-los.
- Isolamento de tenant: para apps multi-tenant, separe dados por tenant (partições lógicas, namespaces ou índices separados) para evitar vazamento entre tenants.
Muitos bancos vetoriais suportam filtros baseados em metadados (por exemplo, tenant_id, department, project_id, visibility) que rodam junto da busca por similaridade. Usados corretamente, isso é uma forma limpa de aplicar permissões durante a recuperação.
Um detalhe chave: garanta que o filtro seja obrigatório e server-side, não lógica opcional no cliente. Também tome cuidado com “explosão de papéis” (muitas combinações). Se seu modelo de permissão for complexo, considere pré-calcular “grupos de acesso efetivos” ou usar um serviço dedicado de autorização para emitir um token de filtro no momento da query.
PII e dados sensíveis: decida o que nunca embeder
Embeddings podem codificar significado do texto original. Isso não revela automaticamente PII em bruto, mas ainda aumenta risco (por exemplo, fatos sensíveis ficando mais fáceis de recuperar).
Diretrizes que funcionam bem:
- Evitar embeder campos altamente sensíveis (SSNs, dados de pagamento, identificadores médicos) quando possível.
- Redigir antes de embeder se o texto precisa ser pesquisável (substituir valores exatos por placeholders).
- Armazenar originais separadamente e recuperá-los só após checagens de permissão.
Necessidades operacionais: backups, retenção e auditoria
Trate seu índice vetorial como dados de produção:
- Backups e recuperação: índices podem ser caros de reconstruir; planeje snapshots ou um caminho de rebuild a partir dos dados fonte.
- Políticas de retenção: delete vetores quando documentos fontes expirarem ou quando o usuário solicitar remoção.
- Auditabilidade: registre quem consultou o quê (pelo menos contexto da query e IDs de documentos retornados) para apoiar investigações e conformidade.
Feito direito, essas práticas fazem a busca semântica parecer mágica para usuários—sem virar uma surpresa de segurança depois.
Armadilhas, custos e uma checklist prática de seleção
Bancos vetoriais podem parecer “plug-and-play”, mas a maioria das decepções vem das escolhas ao redor: como chunkar dados, qual modelo de embedding escolher e quão confiável você mantém tudo atualizado.
Falhas comuns (e como detectá-las)
Chunking pobre é a causa número 1 de resultados irrelevantes. Chunks muito grandes diluem significado; muito pequenos perdem contexto. Se usuários frequentemente dizem “achou o documento certo, mas o trecho errado”, sua estratégia de chunking provavelmente precisa de ajuste.
O modelo de embedding errado aparece como descompasso semântico consistente—resultados são fluidos mas fora do tema. Isso acontece quando o modelo não é adequado ao seu domínio (jurídico, médico, tickets de suporte) ou ao seu tipo de conteúdo (tabelas, código, texto multilíngue).
Dados desatualizados criam problemas de confiança rapidamente: usuários procuram a política mais recente e encontram a versão do trimestre passado. Se sua fonte muda, seus embeddings e metadados também precisam mudar.
Tratamento de início frio e resultados vazios
No começo, você pode ter pouco conteúdo, poucas consultas ou pouco feedback para afinar a recuperação. Planeje para:
- Fallbacks: busca por palavra-chave ou “respostas top” curadas quando resultados semânticos forem fracos.
- UX para resultado vazio: mostrar categorias relacionadas, fazer uma pergunta de esclarecimento ou alargar filtros.
- Consultas de aquecimento: testar com um pequeno conjunto de perguntas representativas antes do lançamento.
Motores de custo para orçar
Os custos costumam vir de quatro lugares:
- Computação para embeddings (backfill único + atualizações contínuas)
- Armazenamento (vetores, metadados e índices)
- Volume de queries (reads, egress de rede e concorrência)
- Reranking (opcional mas poderoso; pode adicionar custo por query com modelos)
Se estiver comparando fornecedores, peça uma estimativa mensal simples usando sua contagem esperada de documentos, tamanho médio de chunk e pico de QPS. Muitas surpresas aparecem após indexação e durante picos de tráfego.
Checklist prático de seleção
Use esta lista curta para escolher um banco vetorial que atenda suas necessidades:
- Qualidade de busca: suporta busca híbrida (keywords + vetores) e filtros de metadados? Dá para adicionar reranking?
- Desempenho: opções de indexação ANN, latência previsível no pico e escalabilidade fácil.
- Operações de dados: upserts, deletes, reindexação, versionamento e backfills sem downtime.
- Observabilidade: logs de query, métricas de recall/latência e ferramentas para depurar “por que esse resultado?”.
- Segurança: criptografia, isolamento de tenant, controle por papéis e padrões de filtro por permissão.
- Integração: SDKs, linguagens suportadas e conectores para seu armazenamento (S3, bancos, docs).
- Custo total: precificação transparente para armazenamento, gravações, leituras e qualquer compute gerenciado.
Escolher bem é menos sobre correr atrás do tipo de índice mais novo e mais sobre confiabilidade: você consegue manter dados atualizados, controlar acesso e manter qualidade conforme seu conteúdo e tráfego crescem?