02 de abr. de 2025·8 min
Bob Kahn e TCP/IP: a Camada Invisível que Impulsiona Aplicações
Aprenda como Bob Kahn ajudou a moldar o TCP/IP, por que redes por pacotes confiáveis importam e como esse projeto ainda sustenta apps, APIs e serviços em nuvem.
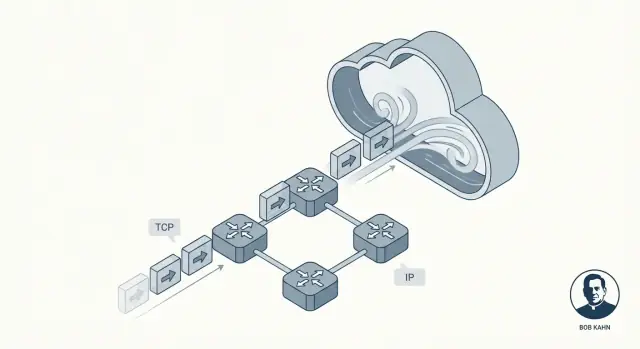
Por que TCP/IP é a fundação oculta do software moderno
A maioria dos apps parece “instantânea”: você toca um botão, um feed atualiza, um pagamento é concluído, um vídeo começa. O que você não vê é o trabalho por baixo para mover pequenos pedaços de dados através do Wi‑Fi, redes móveis, roteadores domésticos e data centers — muitas vezes entre vários países — sem que você precise pensar nas partes confusas no meio.
Essa invisibilidade é a promessa que o TCP/IP cumpre. Não é um produto único nem um recurso de nuvem. É um conjunto de regras compartilhadas que permite que dispositivos e servidores conversem entre si de uma forma que geralmente parece suave e confiável, mesmo quando a rede está ruidosa, congestionada ou parcialmente falhando.
Bob Kahn foi uma das pessoas-chave por trás de tornar isso possível. Junto com colaboradores como Vint Cerf, Kahn ajudou a moldar as ideias centrais que se tornaram o TCP/IP: uma “língua” comum para redes e um método para entregar dados de um modo que as aplicações pudessem confiar. Sem hype — esse trabalho importou porque transformou conexões não confiáveis em algo sobre o qual o software podia construir com confiança.
Comutação por pacotes, explicado para quem está ocupado
Em vez de enviar uma mensagem inteira como um fluxo contínuo, a comutação por pacotes a divide em pequenas peças chamadas pacotes. Cada pacote pode seguir seu próprio caminho até o destino, como envelopes separados passando por diferentes agências dos correios.
O que você vai aprender neste artigo
Vamos explicar como o TCP cria a sensação de confiabilidade, por que o IP intencionalmente não promete perfeição e como o empilhamento (layering) mantém o sistema compreensível. No fim, você poderá imaginar o que acontece quando um app chama uma API — e por que essas ideias de décadas atrás ainda alimentam serviços modernos em nuvem.
O problema que TCP/IP precisava resolver
Redes de computadores iniciais não nasceram como “a Internet”. Foram construídas para grupos e objetivos específicos: uma rede universitária aqui, uma rede militar ali, uma rede de laboratório de pesquisa em outro lugar. Cada uma funcionava bem internamente, mas frequentemente usava hardware, formatos de mensagem e regras diferentes para transportar dados.
Isso criou uma realidade frustrante: mesmo que dois computadores estivessem “em rede”, ainda assim podiam não conseguir trocar informações. É como ter muitos sistemas ferroviários com bitolas diferentes e sinais que significam coisas distintas. Você pode mover trens dentro de um sistema, mas atravessar para outro é confuso, caro ou impossível.
Internetworking: conectar redes, não apenas computadores
O desafio central de Bob Kahn não era simplesmente “conectar o computador A ao computador B”. Era: como conectar redes entre si para que o tráfego possa passar por vários sistemas independentes como se fossem um sistema maior?
Isso é o que “internetworking” significa — construir um método para os dados pularem de uma rede para outra, mesmo quando essas redes são projetadas de maneira diferente e gerenciadas por organizações distintas.
Por que regras compartilhadas (protocolos) importavam
Para fazer o internetworking funcionar em escala, todos precisavam de um conjunto comum de regras — protocolos — que não dependessem do projeto interno de nenhuma rede. Essas regras também tinham que refletir restrições reais:
- As redes falhariam, descartariam dados ou os entregariam fora de ordem.
- Nenhum operador central poderia microgerenciar cada conexão.
- Novas redes continuariam sendo adicionadas ao longo do tempo.
O TCP/IP tornou-se a resposta prática: um “acordo” compartilhado que permitiu que redes independentes se interconectassem e ainda movessem dados de forma suficientemente confiável para aplicações reais.
A contribuição de Bob Kahn em termos simples
Bob Kahn é mais conhecido como um dos arquitetos das “regras da estrada” da Internet. Nos anos 1970, enquanto trabalhava na DARPA, ele ajudou a mover o networking de um experimento de pesquisa inteligente para algo que pudesse conectar muitos tipos diferentes de redes — sem forçar todas a usar o mesmo hardware, cabeamento ou design interno.
A ideia central: fazer redes conversarem entre si
A ARPANET provou que computadores podiam se comunicar por links comutados por pacotes. Mas outras redes estavam surgindo — sistemas baseados em rádio, enlaces via satélite e redes experimentais adicionais — cada uma com suas peculiaridades. O foco de Kahn foi a interoperabilidade: permitir que uma mensagem viajasse por várias redes como se fosse uma única rede.
Em vez de construir uma rede “perfeita”, ele defendeu uma abordagem em que:
- Cada rede local podia manter seu próprio design.
- Um protocolo comum ficava por cima e movia dados entre fronteiras de redes.
- A “cola” era geral o suficiente para funcionar sobre redes futuras que ninguém ainda tinha inventado.
Trabalhando com Vint Cerf, Kahn co‑projetou o que virou o TCP/IP. Um resultado duradouro foi a separação limpa de responsabilidades: o IP trata de endereçamento e encaminhamento entre redes, enquanto o TCP trata da entrega confiável para aplicações que precisam disso.
Por que desenvolvedores ainda se beneficiam hoje
Se você já chamou uma API, carregou uma página web ou enviou logs de um container para um serviço de monitoramento, você depende do modelo de internetworking que Kahn defendeu. Você não precisa se preocupar se os pacotes atravessam Wi‑Fi, fibra, LTE ou um backbone de nuvem. TCP/IP faz tudo parecer um sistema contínuo — assim o software pode focar em funcionalidades, não em cabeamento.
A ideia de camadas do TCP/IP: simples, mas poderosa
Uma das ideias mais inteligentes por trás do TCP/IP é o empilhamento (layering): em vez de construir um grande sistema de rede que faz tudo, você empilha peças menores onde cada camada faz bem uma única tarefa.
Isso importa porque redes não são todas iguais. Diferentes cabos, rádios, roteadores e provedores ainda podem interoperar quando concordam em algumas responsabilidades claras.
IP: endereçamento e roteamento entre redes
Pense em IP (Internet Protocol) como a parte que responde: Para onde esses dados vão, e como os aproximamos desse lugar?
O IP fornece endereços (para identificar máquinas) e roteamento básico (para que pacotes possam saltar de rede em rede). Importante: o IP não tenta ser perfeito. Ele foca em mover pacotes adiante, um passo de cada vez, mesmo que o caminho mude.
TCP: entrega confiável por cima do IP
Depois, TCP (Transmission Control Protocol) senta‑se acima do IP e responde: Como fazemos isso parecer uma conexão confiável?
O TCP lida com o trabalho de “confiabilidade” que as aplicações normalmente desejam: ordenar dados corretamente, notar peças faltantes, reenviar quando necessário e controlar a taxa de entrega para que o remetente não sobrecarregue o receptor ou a rede.
Uma analogia postal simples (sem exageros)
Uma forma útil de imaginar a divisão é um sistema postal:
- IP é como o endereçamento e o roteamento que move envelopes entre cidades e agências.
- TCP é como rastreamento e confirmação que garante que um envio multipartes chegue completo e na ordem certa.
Você não pede ao endereço da rua para garantir que o pacote chegue; você constrói essa garantia por cima.
Por que essa pilha simples permaneceu poderosa
Como as responsabilidades estão separadas, você pode melhorar uma camada sem redesenhar tudo. Novas redes físicas podem transportar IP, e aplicações podem confiar no comportamento do TCP sem precisar entender como o roteamento funciona. Essa divisão limpa é uma grande razão pela qual o TCP/IP se tornou a base invisível sob quase todo app e API que você usa.
Comutação por pacotes: velocidade, flexibilidade e caos
A comutação por pacotes é a ideia que tornou redes grandes práticas: em vez de reservar uma linha dedicada para toda sua mensagem, você corta a mensagem em pequenos pedaços e envia cada pedaço independentemente.
O que é um “pacote” (e por que pedaços vencem)
Um pacote é um pequeno conjunto de dados com um cabeçalho (quem enviou, para quem vai e outras informações de roteamento) e um pedaço do conteúdo.
Dividir dados em pedaços ajuda porque a rede pode:
- Compartilhar enlaces entre muitos usuários (ninguém “possui” o fio)
- Roteirar em torno de partes lentas ou quebradas da rede
- Recuperar problemas reenviando apenas peças faltantes, não o arquivo inteiro
Caminhos diferentes, ordem mista
Aqui começa o “caos”. Pacotes da mesma transferência ou chamada de API podem seguir rotas diferentes pela rede, dependendo do que está ocupado ou disponível no momento. Isso significa que podem chegar fora de ordem — o pacote #12 pode aparecer antes do #5.
A comutação por pacotes não tenta evitar isso. Ela prioriza fazer os pacotes passarem rapidamente, mesmo que a ordem de chegada fique bagunçada.
Por que pacotes são perdidos
Perda de pacotes não é rara, e nem sempre é culpa de alguém. Causas comuns incluem:
- Congestionamento: roteadores ficam sem espaço em buffer e descartam pacotes.
- Ruído/interferência: especialmente em enlaces sem fio.
- Quedas e reroutes: um link falha no meio da transmissão e alguns pacotes não chegam.
Imperfeição é recurso, não bug
A escolha de projeto chave é permitir que a rede seja imperfeita. O IP foca em encaminhar pacotes o melhor que puder, sem prometer entrega ou ordem. Essa liberdade é o que permite que redes escalem — e é por isso que camadas superiores (como o TCP) existem para limpar o caos.
Como o TCP faz redes não confiáveis parecerem confiáveis
Teste em uma rede real
Faça o deploy e hospede seu app para testar latência e taxa de transferência com usuários reais.
O IP entrega pacotes numa base de “melhor esforço”: alguns podem chegar atrasados, fora de ordem, duplicados ou não chegar. O TCP fica acima disso e cria algo em que as aplicações possam confiar: um fluxo único, ordenado e completo de bytes — o tipo de conexão que você espera ao enviar um arquivo, carregar uma página ou chamar uma API.
Confiabilidade, em termos simples
Quando se diz que o TCP é “confiável”, geralmente significa:
- Ordenado: os dados são entregues à aplicação na mesma ordem em que foram enviados.
- Completo: partes faltantes são detectadas e reenviadas.
- Sem lacunas: a aplicação lê um fluxo contínuo, não pacotes espalhados.
Mecanismos-chave (e por que funcionam)
O TCP divide seus dados em pedaços e os rotula com números de sequência. O receptor envia confirmações (ACKs) para confirmar o que recebeu.
Se o remetente não vê um ACK a tempo, assume que algo foi perdido e realiza uma retransmissão. Essa é a ilusão central: mesmo que a rede deixe cair pacotes, o TCP continua tentando até o receptor confirmar o recebimento.
Controle de fluxo vs controle de congestionamento
Soam semelhantes, mas resolvem problemas diferentes:
- Controle de fluxo protege o receptor. Diz: “Estou ocupado — envie mais devagar para meu buffer não encher.”
- Controle de congestionamento protege a rede. Diz: “O caminho entre nós está sobrecarregado — reduza para não piorar o engarrafamento.”
Juntos, ajudam o TCP a manter velocidade sem ser imprudente.
Timeouts que se adaptam
Um timeout fixo falharia tanto em redes lentas quanto em rápidas. O TCP ajusta continuamente seu timeout com base no tempo de ida e volta medido. Se as condições pioram, espera mais antes de reenviar; se melhoram, fica mais responsivo. Essa adaptação é o que faz o TCP funcionar bem em Wi‑Fi, redes móveis e enlaces de longa distância.
Uma escolha de projeto que escalou: pensamento fim a fim
Uma das ideias mais importantes por trás do TCP/IP é o princípio fim a fim: coloque as “inteligências” nas extremidades da rede (os endpoints) e mantenha o meio da rede relativamente simples.
Inteligência nas extremidades
Em termos simples, as extremidades são os dispositivos e programas que realmente se importam com os dados: seu telefone, seu laptop, um servidor e os sistemas operacionais e aplicações que rodam neles. O núcleo da rede — roteadores e enlaces intermediários — foca principalmente em mover pacotes.
Em vez de tentar tornar cada roteador “perfeito”, o TCP/IP aceita que o meio será imperfeito e deixa as extremidades lidarem com as partes que exigem contexto.
Por que um núcleo mais simples permitiu crescimento
Manter o núcleo mais simples facilitou expandir a Internet. Novas redes puderam entrar sem exigir que cada dispositivo intermediário entendesse as necessidades de cada aplicação. Roteadores não precisam saber se um pacote faz parte de uma chamada de vídeo, download de arquivo ou de uma requisição de API — eles apenas encaminham.
O que pertence a cada lado (com exemplos)
Nas extremidades, tipicamente você trata:
- Confiabilidade: retransmissões, ordenação, remoção de duplicatas (TCP).
- Segurança: criptografia e identidade (frequentemente TLS no nível de aplicação/OS).
- Comportamento da aplicação: timeouts, retries, cache, limites de taxa.
Na rede, você lida principalmente com:
- Endereçamento e encaminhamento (IP).
- Manejo básico de pacotes e sinais de congestionamento.
A troca
O pensamento fim a fim escala bem, mas empurra complexidade para fora. Sistemas operacionais, bibliotecas e aplicações ficam responsáveis por “fazer funcionar” sobre redes bagunçadas. Isso é ótimo para flexibilidade, mas também significa que bugs, timeouts mal configurados ou retries agressivos podem criar problemas reais para o usuário.
Por que o modelo de “melhor esforço” do IP foi uma escolha
Teste em redes móveis
Crie um cliente Flutter para ver como perda e latência na rede celular afetam o comportamento do app.
O IP (Internet Protocol) faz uma promessa simples: vai tentar mover seus pacotes em direção ao destino. Só isso. Sem garantias sobre se um pacote chega, se chega apenas uma vez, em ordem ou em um tempo específico.
Isso pode soar como uma falha — até você ver o que a Internet precisava para se tornar: uma rede global feita de muitas redes menores, geridas por organizações diferentes e mudando constantemente.
O que roteadores fazem (e não fazem)
Roteadores são os “direcionadores de tráfego” do IP. O trabalho principal é encaminhar: quando um pacote chega, o roteador olha o endereço de destino e escolhe o próximo salto que parece melhor naquele momento.
Roteadores não acompanham uma conversa como um operador telefônico. Geralmente não reservam capacidade para você e não ficam confirmando se o pacote passou. Ao manter os roteadores focados no encaminhamento, o núcleo da rede fica simples — e pode escalar para um número enorme de dispositivos e conexões.
Por que “melhor esforço” escala globalmente
Garantias são caras. Se o IP tentasse garantir entrega, ordem e tempo para cada pacote, toda rede no planeta teria que coordenar estreitamente, guardar muito estado e recuperar falhas do mesmo jeito. Essa coordenação frearia o crescimento e tornaria as falhas mais graves.
Em vez disso, o IP tolera a bagunça. Se um link cai, um roteador pode enviar pacotes por outra rota. Se um caminho fica congestionado, pacotes podem atrasar ou ser descartados, mas o tráfego muitas vezes continua por rotas alternativas.
O resultado é resiliência: a Internet pode continuar funcionando mesmo quando partes dela quebram ou mudam — porque a rede não é forçada a ser perfeita para ser útil.
De apps e APIs aos pacotes: o que realmente acontece
Quando você usa fetch() para uma API, clica em “Salvar” ou abre um websocket, você não está “falando com o servidor” em um fluxo suave. Seu app entrega dados ao sistema operacional, que os divide em pacotes e os envia por muitas redes separadas — cada salto tomando suas próprias decisões.
Um mapeamento simples: ações do desenvolvedor → comportamento TCP/IP
- Requisição HTTP / chamada de API: seu app escreve bytes (uma requisição HTTP). TCP transforma esse fluxo de bytes em segmentos, numera-os e espera confirmações. IP embala cada segmento em um pacote e o roteia.
- Abrir uma conexão: um handshake TCP estabelece estado compartilhado (números de sequência, tamanhos de janela). Não é gratuito — adiciona tempo antes do primeiro byte útil.
- Fazer upload de um arquivo: o TCP pode ter bastante throughput, mas o desempenho ainda pode parecer lento se a latência for alta.
Latência vs throughput (e por que seu app “parece” lento)
- Latência é quanto tempo uma mensagem leva para ir e voltar (round trip). Alta latência atrapalha padrões chatos: muitas requisições pequenas, redirects e chamadas repetidas.
- Throughput é quanto dado por segundo pode ser entregue. Baixo throughput prejudica transferências grandes: imagens, backups, vídeo.
Uma surpresa comum: você pode ter ótimo throughput e ainda assim sentir a UI lenta porque cada requisição espera por idas e voltas.
Retries e timeouts: por que apps refazem o que o TCP já tenta
O TCP reenvia pacotes perdidos, mas não sabe o que “tempo demais” significa para sua experiência. Por isso aplicações adicionam:
- Timeouts: “Se não houver resposta em 2 segundos, mostra erro.”
- Retries: “Tenta de novo uma vez.” Útil para quedas transitórias, mas arriscado para operações como pagamentos a menos que as requisições sejam idempotentes.
Quando “bugs” são na verdade realidades de rede
Pacotes podem atrasar, serem reordenados, duplicados ou descartados. O congestionamento pode aumentar subitamente a latência. Um servidor pode responder, mas a resposta nunca chega até você. Isso aparece como testes intermitentes, 504s aleatórios ou “funciona na minha máquina”. Frequentemente o código está certo — o caminho entre máquinas não está.
TCP/IP na nuvem: mesmas regras, maior escala
Plataformas de nuvem podem parecer um tipo completamente novo de computação — bancos de dados gerenciados, funções serverless, escalabilidade “infinita”. Por baixo, suas requisições ainda rodam sobre os mesmos fundamentos TCP/IP que Bob Kahn ajudou a iniciar: o IP move pacotes entre redes, e o TCP (ou às vezes UDP) molda como as aplicações experienciam essa rede.
O que muda na nuvem (principalmente empacotamento)
Virtualização e containers mudam onde o software roda e como ele é empacotado:
- Um “servidor” pode ser uma máquina virtual, um container ou uma função de curta duração.
- Redes costumam ser definidas por software e costuradas pelo provedor.
Mas isso são detalhes de implantação. Os pacotes ainda usam endereçamento IP e roteamento, e muitas conexões ainda dependem do TCP para entrega ordenada e confiável.
O que permanece igual (padrões que você reconhece)
Arquiteturas comuns na nuvem são construídas com blocos de rede familiares:
- Load balancers aceitam conexões TCP dos clientes (frequentemente HTTPS) e distribuem o tráfego para serviços backend.
- Chamadas entre serviços dentro de um cluster ainda são chamadas de rede — HTTP/gRPC sobre TCP é comum — só que entre IPs privados.
- Bancos de dados e caches (gerenciados ou self‑hosted) são alcançados por protocolos padrão que rodam sobre TCP (por exemplo, um driver de banco de dados mantendo uma sessão TCP).
Mesmo quando você nunca “vê” um IP, a plataforma está alocando‑o, roteando pacotes e rastreando conexões nos bastidores.
Confiabilidade ainda é um trabalho compartilhado
O TCP pode recuperar pacotes perdidos, reordenar entregas e ajustar‑se ao congestionamento — mas não pode prometer o impossível. Em sistemas na nuvem, confiabilidade é esforço conjunto:
- Rede: roteamento, capacidade, perda de pacotes, falhas transitórias.
- SO/runtime: buffers de socket, timeouts, cache de DNS, reutilização de conexões.
- Aplicação: retries com backoff, idempotência, timeouts sensatos e degradação graciosa.
Por isso plataformas “vibe-coding” que geram e deployam apps full‑stack ainda dependem desses fundamentos. Por exemplo, Koder.ai pode ajudar você a subir um app React com backend em Go e PostgreSQL rapidamente, mas no momento em que esse app conversa com uma API, banco de dados ou cliente móvel, você volta ao território do TCP/IP — conexões, timeouts, retries e tudo mais.
TCP vs UDP e o que os desenvolvedores escolhem hoje
Projete endpoints seguros para retries
Configure um fluxo de pagamento ou gravação com idempotência para que retries do app não dupliquem trabalho.
Quando desenvolvedores falam de “a rede”, muitas vezes escolhem entre dois transports principais: TCP e UDP. Ambos ficam sobre IP, mas fazem trade‑offs muito diferentes.
TCP: o fluxo confiável (e seus custos ocultos)
TCP é ótimo quando você precisa que os dados cheguem na ordem, sem lacunas, e prefere esperar a arriscar perder. Pense: páginas web, chamadas de API, transferências de arquivos, conexões de banco de dados.
É por isso que grande parte da Internet cotidiana roda sobre ele — HTTPS roda sobre TCP (via TLS), e a maioria do software request/response assume o comportamento do TCP.
O porém: a confiabilidade do TCP pode acrescentar latência. Se um pacote falta, pacotes posteriores podem ficar retidos até que a lacuna seja preenchida (“head‑of‑line blocking”). Para experiências interativas, essa espera pode parecer pior do que um glitch ocasional.
UDP: simples, rápido e controlado pela aplicação
UDP é mais parecido com “envie uma mensagem e torça para que chegue”. Não há ordenação, retransmissão ou controle de congestionamento embutido na camada UDP.
Desenvolvedores escolhem UDP quando o tempo importa mais que a perfeição, como áudio/vídeo ao vivo, jogos ou telemetria em tempo real. Muitos desses apps implementam sua própria confiabilidade leve (ou nenhuma), baseada no que os usuários realmente percebem.
Um exemplo moderno importante: QUIC roda sobre UDP, permitindo tempo de setup mais rápido e evitando alguns gargalos do TCP — sem precisar mudar a rede IP subjacente.
Orientação prática para escolher
Escolha com base em:
- Necessidade de confiabilidade: cada byte precisa chegar em ordem? Prefira TCP.
- Sensibilidade à latência: “agora” é mais importante que “perfeito”? Considere UDP.
- Controle: você quer que a aplicação decida o que reenviar, o que pular e como recuperar? UDP (ou QUIC) dá mais espaço para projetar esse comportamento.
O que “confiável” ainda não pode garantir: armadilhas do mundo real
O TCP é frequentemente descrito como “confiável”, mas isso não significa que seu app sempre parecerá confiável. O TCP pode recuperar muitos problemas, mas não pode prometer baixa latência, throughput consistente ou boa experiência quando o caminho entre dois sistemas é instável.
Problemas comuns de rede que você ainda enfrentará
Perda de pacotes força retransmissões do TCP. A confiabilidade é preservada, mas o desempenho pode despencar.
Alta latência (round‑trip longo) deixa cada ciclo de requisição/resposta mais lento, mesmo sem perdas.
Bufferbloat ocorre quando roteadores ou filas do SO seguram muito dado. O TCP vê menos perdas, mas usuários experimentam grandes atrasos e interações “travadas”.
MTU mal configurada pode causar fragmentação ou blackholing (pacotes somem por serem “grandes demais”), gerando falhas confusas que parecem timeouts aleatórios.
Como isso aparece dentro das aplicações
Em vez de um claro “erro de rede”, você verá com frequência:
- Timeouts em chamadas de API que normalmente funcionam.
- Uploads ou downloads lentos que começam rápidos e depois engasgam.
- Conexões “flaky”: reconexões repetidas, streams travados ou carregamentos parciais de páginas.
Esses sintomas são reais, mas nem sempre causados pelo seu código. Muitas vezes é o TCP fazendo seu trabalho — retransmitindo, recuando e esperando — enquanto o relógio da aplicação continua correndo.
Pontos de partida práticos para depuração
Comece com uma classificação básica: o problema é mais de perda, latência ou mudanças de rota?
- Checagens estilo ping ajudam a raciocinar sobre latência e perda (mesmo que ICMP às vezes seja bloqueado).
- Uma ideia estilo traceroute ajuda a localizar onde o atraso ou perdas começam.
- Acrescente logs e métricas: duração de requisição, contagem de timeouts, contagem de retries e sinais de filas/backpressure.
Se você está construindo rápido (por exemplo, prototipando um serviço no Koder.ai e fazendo deploy com domínios personalizados), vale tornar essas bases de observabilidade parte do checklist inicial — porque falhas de rede aparecem primeiro como timeouts e retries, não como exceções organizadas.
Projete assumindo falhas
Pressupõe que redes se comportam mal. Use timeouts, retries com backoff exponencial e torne operações idempotentes para que retries não cobrem em dobro, não criem duplicações ou não corrompam estado.
Perguntas frequentes
O que é TCP/IP e por que ele importa para apps modernos?
TCP/IP é um conjunto compartilhado de regras de rede que permite que redes diferentes se interconectem e ainda assim movam dados de forma previsível.
Importa porque torna enlaces heterogêneos e pouco confiáveis (Wi‑Fi, LTE, fibra, satélite) utilizáveis para software — assim, os apps podem presumir que conseguem enviar bytes e receber respostas sem precisar entender os detalhes físicos da rede.
Qual foi a contribuição-chave de Bob Kahn para o design da Internet?
Bob Kahn ajudou a promover a ideia de “internetworking”: conectar redes entre si sem obrigá‑las a usar o mesmo hardware ou design interno.
Com colaboradores (notadamente Vint Cerf), esse trabalho moldou a separação onde IP trata de endereçamento/roteamento entre redes e TCP fornece confiabilidade para as aplicações por cima.
O que é comutação por pacotes em termos simples, e por que ela é usada?
A comutação por pacotes divide uma mensagem em pequenos pacotes que podem viajar independentemente.
Benefícios:
- Melhor compartilhamento de enlace (vários usuários dividem os mesmos caminhos)
- Reencaminhamento mais fácil em caso de falhas
- Reenviar apenas o que foi perdido em vez de todo o arquivo
Por que o IP não garante entrega ou ordenação?
O IP foca em uma única tarefa: encaminhar pacotes em direção a um endereço de destino. Ele não garante entrega, ordem ou tempo.
Esse modelo de “melhor esforço” escala globalmente porque os roteadores permanecem simples e rápidos, e a rede continua funcionando mesmo quando links falham, rotas mudam e novas redes entram.
Como o TCP faz uma rede não confiável parecer confiável?
O TCP transforma pacotes de melhor esforço do IP em um fluxo de bytes ordenado amigável para aplicações.
Faz isso com:
- Números de sequência (para reordenar dados)
- ACKs (confirmam o que chegou)
- (reenviam o que faltou)
Qual a diferença entre controle de fluxo do TCP e controle de congestionamento?
Eles resolvem problemas distintos:
- Controle de fluxo protege o receptor para que ele não seja sobrecarregado (o receptor indica quanto pode aceitar).
- Controle de congestionamento protege o caminho de rede para que o remetente reduza a taxa quando a rota mostra sinais de congestionamento.
Na prática, bom desempenho exige ambos: um remetente rápido deve respeitar o receptor a rede.
Por que o empilhamento (layering) do TCP/IP é tão importante para desenvolvedores?
O empilhamento por camadas separa responsabilidades para que cada parte possa evoluir independentemente.
- Camadas inferiores podem mudar (novos padrões Wi‑Fi, novo equipamento óptico, novas malhas de nuvem)
- Camadas superiores continuam funcionando (comportamento do TCP, protocolos de aplicação)
Para desenvolvedores, isso significa que você pode construir APIs sem redesenhar a aplicação para cada tipo de rede.
O que o princípio end-to-end (fim a fim) significa na prática?
O princípio fim a fim mantém o núcleo da rede (roteadores) relativamente simples e coloca as “inteligências” nas extremidades.
Implicação prática: aplicações e sistemas operacionais lidam com confiabilidade, timeouts, retries e criptografia (frequentemente via TLS), porque a rede não pode adaptar-se às necessidades de toda aplicação.
Como latência e throughput afetam o desempenho de APIs de maneira diferente?
Latência é o tempo de ida e volta; prejudica padrões “conversacionais” (muitas requisições pequenas, redirects, chamadas repetidas).
Throughput é bytes por segundo; importa para transferências grandes (uploads, imagens, backups).
Dicas práticas:
- Reutilize conexões (keep-alive/pooling) para evitar handshakes repetidos
- Agrupe requisições sempre que possível
- Defina timeouts com base na experiência do usuário, não apenas em “o TCP eventualmente entrega”
Quando os desenvolvedores devem usar TCP vs UDP (e onde o QUIC entra)?
Escolha conforme a necessidade:
- Use TCP quando cada byte deve chegar na ordem (páginas web, APIs, bancos de dados).
- Considere UDP quando a urgência for mais importante que a perfeição (áudio/vídeo em tempo real, jogos).
- QUIC (usado pelo HTTP/3) roda sobre UDP para reduzir o tempo de estabelecimento de conexão e evitar alguns gargalos do TCP.
Regra prática: se seu app é request/response e prioriza correção, comece por TCP (ou QUIC via HTTP/3).