Por que o Kubernetes mudou as operações do dia a dia
Kubernetes não introduziu apenas uma nova ferramenta — mudou como são as “ops do dia a dia” quando você roda dezenas (ou centenas) de serviços. Antes da orquestração, equipes frequentemente costuravam scripts, runbooks manuais e conhecimento tribal para responder às mesmas perguntas recorrentes: Onde este serviço deve rodar? Como rodamos uma mudança com segurança? O que acontece quando um nó morre às 2 da manhã?
O que a “orquestração” realmente resolve
No núcleo, orquestração é a camada de coordenação entre sua intenção (“rode este serviço assim”) e a realidade bagunçada de máquinas falhando, tráfego mudando e deploys acontecendo continuamente. Em vez de tratar cada servidor como uma peça única, a orquestração trata o compute como um pool e as cargas de trabalho como unidades agendáveis que podem se mover.
O Kubernetes popularizou um modelo onde as equipes descrevem o que querem, e o sistema trabalha continuamente para fazer a realidade casar com essa descrição. Essa mudança é importante porque faz as operações menos sobre heroísmos e mais sobre processos repetíveis.
Kubernetes padronizou resultados operacionais que a maioria das equipes de serviço precisa:
- Deployment: uma forma consistente de declarar o que deve rodar, atualizá-lo e verificar se está saudável.
- Escalonamento: um caminho prático de uma instância para muitas, sem redesenhar o serviço ou provisionar máquinas manualmente.
- Operações de serviço: maneiras estáveis de os serviços se descobrirem, rotearem tráfego e continuarem funcionando conforme as instâncias mudam.
Uma nota sobre escopo e fontes
Este artigo foca nas ideias e padrões associados ao Kubernetes (e líderes como Brendan Burns), não em uma biografia pessoal. E quando falamos de “como começou” ou “por que foi projetado assim”, essas afirmações devem se apoiar em fontes públicas — palestras, docs de design e documentação upstream — para que a história permaneça verificável em vez de baseada em mito.
Brendan Burns na história de origem do Kubernetes (visão geral)
Brendan Burns é amplamente reconhecido como um dos três cofundadores originais do Kubernetes, ao lado de Joe Beda e Craig McLuckie. Nos primeiros trabalhos sobre Kubernetes no Google, Burns ajudou a moldar tanto a direção técnica quanto a forma como o projeto era explicado aos usuários — especialmente em torno de “como você opera software” em vez de apenas “como você roda containers”. (Fontes: Kubernetes: Up & Running, O’Reilly; listas de AUTHORS/maintainers do repositório do Kubernetes)
Colaboração open source moldou o design
Kubernetes não foi simplesmente “lançado” como um sistema interno finalizado; foi construído em público com um conjunto crescente de contribuintes, casos de uso e restrições. Essa abertura empurrou o projeto para interfaces que sobrevivessem a ambientes diferentes:
- APIs claras e versionadas em vez de detalhes de implementação escondidos
- comportamentos portáteis entre provedores de nuvem e ambientes on-prem
- pontos de extensão para que o núcleo permanecesse relativamente pequeno enquanto ainda suportava muitas necessidades
Essa pressão colaborativa importa porque influenciou o que o Kubernetes otimizou: primitivas compartilhadas e padrões repetíveis que muitas equipes poderiam concordar, mesmo quando discordavam sobre ferramentas.
O que “padronizar” realmente significa aqui
Quando as pessoas dizem que Kubernetes “padronizou” deploy e operações, geralmente não querem dizer que tornou todo sistema idêntico. Querem dizer que forneceu um vocabulário comum e um conjunto de fluxos de trabalho que podem ser repetidos entre equipes:
- “deployment”, “service”, “ingress”, “job”, “namespace” como termos compartilhados
- um modelo consistente para declarar o que você quer (e deixar o sistema trabalhar para isso)
- formas previsíveis de aplicar mudanças, escalar e recuperar de falhas
Esse modelo compartilhado facilitou que docs, ferramentas e práticas transitassem de uma empresa para outra.
Kubernetes: o projeto vs. o ecossistema
É útil separar Kubernetes (o projeto open-source) do ecossistema Kubernetes.
O projeto é a API central e os componentes do plano de controle que implementam a plataforma. O ecossistema é tudo que cresceu ao redor — distribuições, serviços gerenciados, add-ons e projetos CNCF adjacentes. Muitas “features do Kubernetes” que as pessoas usam no mundo real (stacks de observabilidade, engines de política, ferramentas GitOps) vivem nesse ecossistema, não no núcleo do projeto.
A ideia central: estado desejado declarativo
Configuração declarativa é uma mudança simples em como você descreve sistemas: em vez de listar passos a executar, você afirma o que quer como resultado final.
Em termos do Kubernetes, você não diz à plataforma “inicie um container, depois abra uma porta, depois reinicie se travar.” Você declara “deve haver três cópias deste app rodando, acessíveis nesta porta, usando esta imagem de container.” O Kubernetes assume a responsabilidade de fazer a realidade casar com essa descrição.
Estado desejado vs. scripts imperativos
Operações imperativas são como um runbook: uma sequência de comandos que funcionou da última vez, executada de novo quando algo muda.
Estado desejado é mais como um contrato. Você registra o resultado pretendido em um arquivo de configuração, e o sistema trabalha continuamente para esse resultado. Se algo divergir — uma instância morre, um nó some, uma mudança manual é aplicada — a plataforma detecta a discrepância e corrige.
Antes/depois: comandos de runbook vs YAML
Antes (pensamento imperativo de runbook):
- SSH em um servidor
- Puxar a nova imagem do container
- Parar o processo antigo
- Iniciar o novo processo
- Atualizar uma regra de load balancer
- Se o tráfego subir, repetir em mais servidores
Esse método funciona, mas é fácil acabar com servidores “snowflake” e uma longa lista de verificação que só alguns confiam.
Depois (estado desejado declarativo):
apiVersion: apps/v1
kind: Deployment
metadata:
name: checkout
spec:
replicas: 3
selector:
matchLabels:
app: checkout
template:
metadata:
labels:
app: checkout
spec:
containers:
- name: app
image: example/checkout:1.2.3
ports:
- containerPort: 8080
Você altera o arquivo (por exemplo, atualiza image ou replicas), aplica, e os controllers do Kubernetes trabalham para reconciliar o que está rodando com o que foi declarado.
Por que reduz esforço operacional e drift
Estado desejado declarativo reduz o trabalho repetitivo transformando “faça esses 17 passos” em “mantenha assim”. Também diminui o drift de configuração porque a fonte de verdade é explícita e revisável — muitas vezes no controle de versão — então surpresas são mais fáceis de detectar, auditar e reverter consistentemente.
Controladores e reconciliação: o sistema que mantém as coisas corretas
Kubernetes parece “auto-gerenciável” porque foi construído em torno de um padrão simples: você descreve o que quer, e o sistema trabalha continuamente para fazer a realidade bater com essa descrição. O motor desse padrão é o controlador.
O que é um controlador (em termos simples)
Um controlador é um loop que observa o estado atual do cluster e o compara com o estado desejado que você declarou em YAML (ou via chamada de API). Quando encontra uma diferença, ele age para reduzir essa diferença.
Não é um script de vez em quando e não fica esperando um humano clicar em um botão. Roda repetidamente — observar, decidir, agir — para poder responder a mudanças a qualquer momento.
Reconciliação: como o Kubernetes “mantém as coisas verdadeiras”
Esse comportamento repetido de comparar e corrigir se chama reconciliação. É o mecanismo por trás da promessa comum de “self-healing”. O sistema não impede falhas magicamente; ele percebe drift e corrige.
O drift pode acontecer por razões mundanas:
- um processo crasha
- um nó desaparece
- alguém escala algo pra mais ou pra menos
- um deployment é atualizado
Reconciliação significa que o Kubernetes trata esses eventos como sinais para re-checar sua intenção e restaurá-la.
Os resultados que as pessoas realmente valorizam
Controladores se traduzem em resultados operacionais familiares:
- Substituir pods com falha: se um pod morrer, um controlador percebe que você ainda o quer e agenda um novo.\n- Manter contagens de réplicas: se você pediu 5 réplicas e só 4 estão rodando, o Kubernetes cria a faltante.\n- Manter progresso do rollout: durante atualizações, os controladores movem o sistema para a nova versão enquanto preservam a disponibilidade desejada.
A chave é que você não está perseguindo sintomas manualmente. Você declara o alvo, e os loops de controle fazem o trabalho contínuo de “manter assim”.
Por que isso escala além de um recurso
Essa abordagem não se limita a um tipo de recurso. Kubernetes usa a mesma ideia de controlador-e-reconciliação em muitos objetos — Deployments, ReplicaSets, Jobs, Nodes, endpoints e mais. Essa consistência é uma grande razão pela qual Kubernetes virou plataforma: uma vez que você entende o padrão, pode prever como o sistema se comportará ao adicionar novas capacidades (incluindo recursos customizados que seguem o mesmo loop).
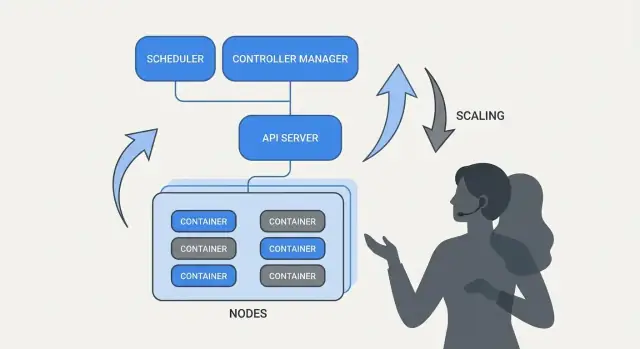
Agendamento como recurso de produto, não como tarefa manual
Vá ao vivo no seu domínio
Coloque seu projeto em um domínio personalizado quando estiver pronto para compartilhá-lo.
Se o Kubernetes apenas “rodasse containers”, ainda deixaria as equipes com a parte mais difícil: decidir onde cada workload deve rodar. Agendamento é o sistema embutido que coloca Pods nos nós certos automaticamente, com base em necessidades de recursos e regras que você define.
Isso importa porque decisões de colocação afetam diretamente uptime e custo. Uma API web presa em um nó sobrecarregado pode ficar lenta ou travar. Um job batch colocado ao lado de serviços sensíveis à latência pode criar problemas de “noisy neighbor”. Kubernetes transforma isso em uma capacidade de produto repetível ao invés de uma rotina de planilha e SSH.
O que o scheduler está otimizando
No nível básico, o scheduler procura nós que possam satisfazer os requests do seu Pod.
- Requests de CPU/memória: requests reservam capacidade para decisões de colocação. Se você pedir 500m de CPU e 1Gi de memória, o Kubernetes só considerará nós com capacidade disponível suficiente.
Esse hábito simples — definir requests realistas — frequentemente reduz instabilidade “aleatória” porque serviços críticos param de competir com tudo mais.
Restrições práticas que as equipes usam
Além de recursos, a maioria dos clusters de produção usa algumas regras práticas:
- Affinity / anti-affinity: “coloque estes juntos” (para localidade de cache) ou “mantenha estes separados” (para evitar que uma falha de nó derrube todas as réplicas).\n- Taints e tolerations: marque certos nós como de uso especial (nós com GPU, nós de sistema, nós para compliance) e permita que apenas workloads autorizados neles possam aterrissar.
Como isso reduz outages
Recursos de agendamento ajudam equipes a codificar intenção operacional:
- Espalhe réplicas pelos nós para sobreviver à falha de um nó.\n- Isole jobs “spiky” longe de serviços orientados ao cliente.\n- Evite que nós caros (como GPU) sejam consumidos por workloads errados.
A conclusão prática: trate regras de agendamento como requisitos de produto — documente, revise e aplique consistentemente — para que a confiabilidade não dependa de alguém lembrar do “nó certo” às 2 da manhã.
Escalonamento: de uma instância a milhares sem reescrever
Uma das ideias mais práticas do Kubernetes é que escalar não deve exigir mudar o código da aplicação ou inventar uma nova abordagem de deployment. Se o app pode rodar como um container, a mesma definição de workload geralmente pode crescer para centenas ou milhares de cópias.
Escalonamento tem duas camadas
Kubernetes separa escalonamento em duas decisões relacionadas:
- Quantos pods rodar (mais cópias do seu app para maior throughput ou redundância).\n- Quanta capacidade de cluster você tem (nós suficientes — e do tamanho certo — para colocar esses pods).
Essa separação importa: você pode pedir 200 pods, mas se o cluster só tem espaço para 50, “escalar” vira uma fila de pending.
Autoscaling, conceitualmente (HPA, VPA, Cluster Autoscaler)
Kubernetes usa comumente três autoscalers, cada um focado em uma alavanca diferente:
- Horizontal Pod Autoscaler (HPA): altera o número de pods com base em sinais como uso de CPU, memória ou métricas customizadas de aplicação.\n- Vertical Pod Autoscaler (VPA): ajusta requests/limits dos pods para que cada pod receba mais (ou menos) CPU/memória.\n- Cluster Autoscaler: adiciona ou remove nós para que o scheduler tenha espaço para colocar os pods que você pediu.
Usados juntos, isso transforma escala em política: “mantenha latência estável” ou “mantenha CPU por volta de X%”, em vez de uma rotina manual que acorda alguém no meio da noite.
Do que depende um “bom escalonamento”
Escalonamento só funciona tão bem quanto os insumos:
- Métricas: CPU é fácil mas nem sempre significativa; taxa de requisições, profundidade de filas e latência geralmente refletem melhor a carga real.\n- Requests/limits: dizem ao scheduler o que um pod precisa. Sem eles, decisões de colocação e autoscaling viram chute.\n- Padrões de carga: tráfego em picos, warm-ups lentos e jobs pesados em background mudam a rapidez com que o escalonamento deve reagir.
Armadilhas comuns
Dois erros aparecem repetidamente: escalar com a métrica errada (CPU baixa enquanto requisições dão timeout) e falta de requests (autoscalers não conseguem prever capacidade, pods ficam aglomerados e performance fica inconsistente).
Deploys seguros: rollouts, health checks e rollbacks
Uma grande mudança que o Kubernetes popularizou é tratar “deployar” como um problema de controle contínuo, não como um script único que você roda às 17h de sexta-feira. Rollouts e rollbacks são comportamentos de primeira classe: você declara a versão desejada, e o Kubernetes move o sistema em direção a ela enquanto verifica continuamente se a mudança é realmente segura.
Rollouts como transição controlada
Com um Deployment, um rollout é uma substituição gradual de Pods antigos por novos. Em vez de parar tudo e começar de novo, o Kubernetes pode atualizar em etapas — mantendo capacidade disponível enquanto a nova versão prova que aguenta tráfego real.
Se a nova versão começar a falhar, rollback não é um procedimento de emergência. É uma operação normal: você pode reverter para um ReplicaSet anterior (a última versão conhecida boa) e deixar o controlador restaurar o estado antigo.
Probes: evitando releases “ruins mas rodando”
Health checks são o que transformam rollouts de “torcer pra dar certo” em algo mensurável.
- Readiness probes determinam se um Pod deve receber tráfego. Um container pode estar em execução mas não pronto (aquecendo caches, aguardando dependências). Readiness evita enviar usuários para instâncias que não respondem corretamente ainda.\n- Liveness probes detectam quando um container travou ou está doente e precisa reiniciar. Isso evita o modo lento de falha onde o processo está vivo mas quebrado.
Usadas bem, probes reduzem falsos sucessos — deploys que parecem ok porque os Pods subiram, mas na verdade estão falhando requisições.
Estratégias de deployment: rolling, blue/green, canary
Kubernetes suporta rolling update por padrão, mas equipes frequentemente aplicam padrões adicionais por cima:
- Blue/green: mantenha dois ambientes completos e mude o tráfego do antigo (blue) para o novo (green) quando o green for verificado.\n- Canary: envie uma pequena porcentagem do tráfego para a nova versão, observe métricas e então expanda gradualmente.
Segurança que você pode medir (e automatizar)
Deploys seguros dependem de sinais: taxa de erro, latência, saturação e impacto no usuário. Muitas equipes conectam decisões de rollout a SLOs e budgets de erro — se um canary queimar muito do budget, a promoção para produção para.
O objetivo é gatilhos automáticos de rollback baseados em indicadores reais (readiness falhando, 5xx subindo, latência disparando), de modo que “rollback” vire uma resposta previsível do sistema — não um momento heroico à noite.
Operações de serviço: descoberta, roteamento e rede estável
Planeje a implantação primeiro
Use o Modo de Planejamento para mapear serviços, APIs e implantações antes de alterar o código.
Uma plataforma de containers só parece “automática” se outras partes do sistema ainda conseguem encontrar seu app depois que ele se move. Em clusters de produção reais, pods são criados, deletados, re-agendados e escalados o tempo todo. Se cada mudança exigisse atualizar endereços IP em configs, as operações se transformariam em trabalho constante — e outages seriam rotineiros.
Por que descoberta de serviços importa
Descoberta de serviços é a prática de dar aos clientes uma forma confiável de alcançar um conjunto mutável de backends. No Kubernetes, a mudança chave é que você para de mirar instâncias individuais (“chame 10.2.3.4”) e passa a mirar um serviço nomeado (“chame checkout”). A plataforma cuida de quais pods servem esse nome no momento.
Services, selectors e endpoints (em termos simples)
Um Service é uma porta de entrada estável para um grupo de pods. Ele tem um nome consistente e um endereço virtual dentro do cluster, mesmo quando os pods subjacentes mudam.
Um selector é como o Kubernetes decide quais pods estão “por trás” daquela porta. Mais comumente ele combina labels, como app=checkout.
Endpoints (ou EndpointSlices) são a lista viva de IPs de pods que atualmente casam com o selector. Quando pods escalam, fazem rollout ou são re-agendados, essa lista se atualiza automaticamente — clientes continuam usando o mesmo nome de Service.
Endereços estáveis, balanceamento e roteamento de tráfego
Operacionalmente, isso fornece:
- Endereçamento estável: apps chamam um DNS do Service em vez de perseguirem IPs de Pods.\n- Balanceamento de carga: o tráfego é distribuído entre pods saudáveis atrás do Service.\n- Roteamento previsível: você pode separar “quem deve receber tráfego” (labels/selectors) de “onde os pods estão rodando”.
Para tráfego norte–sul (de fora para dentro do cluster), o Kubernetes normalmente usa um Ingress ou a abordagem mais nova Gateway. Ambos fornecem um ponto de entrada controlado onde você pode rotear requisições por hostname ou caminho, e frequentemente centralizam preocupações como terminação TLS. A ideia importante continua a mesma: manter o acesso externo estável enquanto os backends mudam por baixo.
Auto-recuperação: o que isso realmente significa em produção
“Self-healing” no Kubernetes não é mágica. São um conjunto de reações automáticas à falha: reiniciar, re-agendar e substituir. A plataforma observa o que você disse que queria (seu estado desejado) e fica empurrando a realidade de volta para ele.
Reiniciar: quando um container crasha
Se um processo sai ou um container fica unhealthy, o Kubernetes pode reiniciá-lo no mesmo nó. Isso é geralmente guiado por:
- Liveness probes: “este container ainda está funcionando?” Se não, reinicie.\n- Restart policies: regras para quando reinícios devem ocorrer.
Um padrão comum em produção é: um container crasha → Kubernetes reinicia → seu Service só roteia para Pods saudáveis.
Re-agendar e substituir: quando um nó falha
Se um nó inteiro cai (problema de hardware, kernel panic, perda de rede), Kubernetes detecta o nó como indisponível e começa a mover trabalho para outro lugar. Em alto nível:
- O nó é marcado como unhealthy/not ready.\n- Pods que estavam lá são considerados perdidos.\n- Controladores criam Pods substitutos em outros nós saudáveis para restaurar a contagem de réplicas desejada.
Isso é “self-healing” ao nível de cluster: o sistema substitui capacidade em vez de esperar um humano dar SSH.
Observabilidade: como você sabe que está se recuperando
Auto-recuperação só importa se você puder verificá-la. Equipes normalmente observam:
- Logs (logs de app e eventos da plataforma) para ver o que reiniciou e por quê\n- Métricas como contagem de reinícios, probes falhando e readiness de nós\n- Alertas quando a recuperação não está funcionando (por exemplo, CrashLoopBackOff repetido, falta de réplicas ou muitas evictions)
Más configurações que quebram a auto-recuperação
Mesmo com Kubernetes, o “healing” pode falhar se as guardrails estiverem erradas:
- Probes de liveness/readiness ruins ou ausentes (falsos positivos ou Pods que nunca ficam prontos)\n- Falta de requests/limits, levando a agendamento imprevisível ou OOM kills\n- Réplicas insuficientes (um único Pod não dá continuidade)\n- Timings de probes agressivos que causam tempestades de reinício\n- Workloads que dependem de estado local do nó sem estratégia de armazenamento durável
Quando a auto-recuperação está bem configurada, outages ficam menores e mais curtos — e mais importante, mensuráveis.
Crie a partir de uma especificação declarativa
Transforme uma especificação pronta para operações em um app real que você pode implantar e iterar rapidamente.
Kubernetes não venceu só porque podia rodar containers. Venceu porque ofereceu APIs padrão para as necessidades operacionais mais comuns — deploy, escalonamento, rede e observabilidade. Quando as equipes concordam na mesma “forma” de objetos (como Deployments, Services, Jobs), ferramentas podem ser compartilhadas entre organizações, treinamento fica mais simples e a passagem entre dev e ops para de depender de conhecimento tribal.
Por que APIs padrão mudam fluxos de trabalho das equipes
Uma API consistente significa que sua pipeline de deployment não precisa conhecer as peculiaridades de cada app. Ela pode aplicar as mesmas ações — criar, atualizar, reverter e checar saúde — usando os mesmos conceitos Kubernetes.
Também melhora alinhamento: times de segurança podem expressar guardrails como políticas; SREs podem padronizar runbooks em torno de sinais de saúde comuns; desenvolvedores podem raciocinar sobre releases com um vocabulário compartilhado.
Estender o Kubernetes: CRDs e Operators
A mudança para plataforma fica óbvia com Custom Resource Definitions (CRDs). Uma CRD deixa você adicionar um novo tipo de objeto no cluster (por exemplo, Database, Cache ou Queue) e gerenciá-lo com os mesmos padrões de API dos recursos nativos.
Um Operator emparelha esses objetos customizados com um controlador que reconcilia continuamente a realidade ao estado desejado — cuidando de tarefas que antes eram manuais, como backups, failovers ou upgrades de versão. O benefício chave não é automação mágica; é reusar o mesmo laço de controle que o Kubernetes aplica a todo o resto.
Por ser orientado a API, Kubernetes integra bem com fluxos modernos:
- GitOps: o estado desejado vive no Git; mudanças são revisadas como código.\n- CI/CD: pipelines podem aplicar manifests, esperar por readiness e promover versões.\n- Checagens de política: admission controllers podem bloquear configs arriscadas antes de chegarem à produção.
Se quiser guias práticos de deploy e ops baseados nessas ideias, navegue por /blog.
O que equipes podem aplicar hoje (mesmo fora do Kubernetes)
As maiores ideias do Kubernetes — muitas associadas ao enquadramento inicial de Brendan Burns — se traduzem bem mesmo se você roda em VMs, serverless ou em uma configuração menor de containers.
Padrões que melhoram o dia a dia
Escreva o "estado desejado" e deixe a automação aplicá-lo. Seja com Terraform, Ansible ou uma pipeline CI, trate configuração como fonte de verdade. O resultado é menos passos manuais de deploy e bem menos surpresas do tipo “funcionou na minha máquina”.
Use reconciliação, não scripts one-off. Em vez de scripts que rodem uma vez e torçam pelo melhor, construa loops que verifiquem continuamente propriedades chave (versão, config, número de instâncias, saúde). É assim que se obtém ops repetíveis e recuperação previsível após falhas.
Faça do agendamento e do escalonamento recursos de produto. Defina quando e por que você adiciona capacidade (CPU, profundidade de fila, SLOs de latência). Mesmo sem autoscaling do Kubernetes, equipes podem padronizar regras de escala para que o crescimento não exija reescrever o app ou acordar alguém.
Padronize rollouts. Atualizações rolling, health checks e procedimentos rápidos de rollback reduzem o risco de mudanças. Você pode implementar isso com load balancers, feature flags e pipelines de deployment que bloqueiam releases com base em sinais reais.
Checklist seguro de adoção
- Defina o estado desejado de um serviço: versão, config, dependências e contagem mínima de instâncias\n- Adicione endpoints de saúde (equivalentes a liveness e readiness) e integre-os ao load balancer ou pipeline de deploy\n- Automate passos de rollout: deploy, verificar, migrar tráfego e reverter em caso de falha\n- Crie um pequeno “reconciliador”: checagens agendadas que corrijam drift (config errada, instâncias faltando)\n- Adicione gatilhos de escala com limites claros (máximo de instâncias, cooldowns, regras de aprovação)
O que isso não resolve sozinho
Esses padrões não consertam design ruim de aplicação, migrações de dados inseguras ou controle de custos. Você ainda precisa de APIs versionadas, planos de migração, orçamentos/limites e observabilidade que ligue deploys ao impacto no cliente.
Próximos passos
Escolha um serviço voltado ao cliente e implemente o checklist ponta a ponta, depois expanda.
Se você está construindo novos serviços e quer chegar a “algo implantável” mais rápido, a Koder.ai pode ajudar a gerar um app web/backend/mobile completo a partir de uma especificação via chat — tipicamente React no frontend, Go com PostgreSQL no backend e Flutter para mobile — e então exportar o código-fonte para que você aplique os mesmos padrões Kubernetes discutidos aqui (configs declarativas, rollouts repetíveis e operações com rollback). Para equipes avaliando custo e governança, você também pode revisar /pricing.