Por que o cache ajuda — e por que complica sistemas
O cache mantém uma cópia dos dados perto de onde são necessários para que requisições possam ser atendidas mais rápido, com menos idas aos sistemas centrais. O ganho normalmente é uma combinação de velocidade (menor latência), custo (menos leituras caras no banco ou chamadas upstream) e estabilidade (os serviços de origem resistem a picos de tráfego).
A vantagem: menos trabalho para a origem
Quando um cache consegue responder uma requisição, sua “origem” (servidores de app, bancos de dados, APIs de terceiros) faz menos trabalho. Essa redução pode ser dramática: menos consultas, menos ciclos de CPU, menos saltos de rede e menos oportunidades de timeouts.
O cache também suaviza rajadas — ajudando sistemas dimensionados para carga média a lidar com picos sem escalar imediatamente (ou sem cair).
A desvantagem oculta: mais trabalho para engenheiros
Cache não elimina trabalho; ele o move para design e operações. Surgem novas perguntas:
- O que deve ser cacheado?
- Por quanto tempo?
- O que acontece quando os dados mudam?
- Como prevenir resultados desatualizados ou incorretos?
- Como depurar problemas quando um cache “esconde” o comportamento da origem?
Cada camada de cache adiciona configurações, monitoramento e casos de borda. Um cache que acelera 99% das requisições ainda pode causar incidentes dolorosos no 1%: expirações sincronizadas, experiências inconsistentes para usuários ou repentes de tráfego para a origem.
Camada de cache vs. um único cache
Um cache único é um repositório (por exemplo, um cache em memória próximo à sua aplicação). Uma camada de cache é um ponto distinto no caminho da requisição — CDN, cache do navegador, cache da aplicação, cache do banco — cada um com suas regras e modos de falha.
Este texto foca na complexidade prática introduzida por camadas múltiplas: correção, invalidação e operações (não em algoritmos de cache de baixo nível ou tunings específicos de fornecedores).
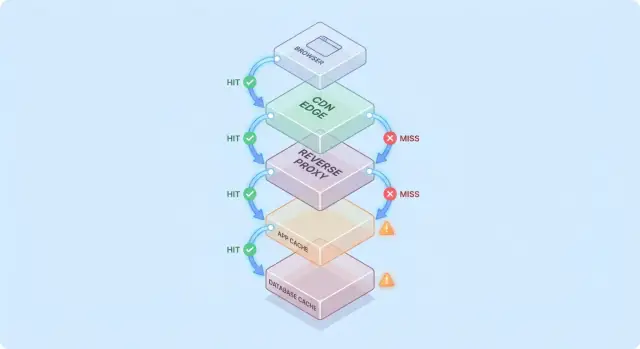
Um modelo simples: fluxo de requisição através de múltiplas camadas
Fica mais fácil raciocinar sobre cache quando você imagina uma requisição viajando por uma pilha de pontos de verificação “talvez eu já tenha isto”.
Caminho típico da requisição
Um caminho comum é:
- Cliente → Edge (CDN) → App → Banco de dados
Em cada salto, o sistema pode retornar uma resposta em cache (hit) ou encaminhar a requisição para a próxima camada (miss). Quanto mais cedo ocorrer o hit (por exemplo, na borda), mais carga você evita nas camadas profundas.
Hits são ótimos; misses são o verdadeiro teste
Hits deixam os dashboards bonitos. Misses é onde a complexidade aparece: eles disparam trabalho real (lógica do app, consultas ao BD) e adicionam overhead (buscas no cache, serialização, escritas no cache).
Um modelo mental útil é: cada miss paga pelo cache duas vezes — você ainda faz o trabalho original, mais o trabalho de cache ao redor dele.
Como as camadas movem gargalos
Adicionar uma camada de cache raramente elimina gargalos; muitas vezes ela os move:
- Uma CDN pode deslocar pressão da aplicação, mas aumenta a sensibilidade à configuração do cache e à velocidade de purge.
- Um cache de aplicação reduz a carga do banco, mas faz do CPU/memória da camada de app o novo fator limitante.
- Cache no banco (buffer pools, plan caches) pode esconder consultas lentas até que o working set não caiba mais.
Exemplo simples “cacheado duas vezes”
Suponha que a página do produto esteja em cache na CDN por 5 minutos, e o app também mantenha detalhes do produto em Redis por 30 minutos.
Se um preço muda, a CDN pode atualizar rápido enquanto o Redis continua servindo o preço antigo. Agora a “verdade” depende de qual camada atendeu a requisição — um exemplo de por que camadas de cache cortam carga mas aumentam complexidade do sistema.
Camadas comuns de cache e para que servem
Cache não é uma única funcionalidade — é uma pilha de lugares onde dados podem ser salvos e reutilizados. Cada camada reduz carga, mas cada uma tem regras diferentes para frescor, invalidação e visibilidade.
Cache do navegador e do sistema operacional (o que você controla vs o que não)
Navegadores cacheiam imagens, scripts, CSS e às vezes respostas de API com base em headers HTTP (como Cache-Control e ETag). Isso pode eliminar downloads repetidos inteiramente — ótimo para performance e para reduzir tráfego na CDN/origem.
A pegadinha: uma vez que uma resposta está no cache do cliente, você não controla totalmente o tempo de revalidação. Alguns usuários podem manter ativos assets antigos por mais tempo (ou limpar o cache inesperadamente), então URLs versionadas (ex.: app.3f2c.js) são uma rede de segurança comum.
Cache CDN/edge para conteúdo estático e semi-estático
Uma CDN armazena conteúdo próxima aos usuários. Brilha para arquivos estáticos, páginas públicas e respostas “majoritariamente estáveis” como imagens de produto, documentação ou endpoints de API com limitação de taxa.
CDNs também podem cachear HTML semi-estático desde que você seja cuidadoso com variação (cookies, headers, geolocalização, dispositivo). Regras de variação mal configuradas são fonte frequente de servir conteúdo errado ao usuário errado.
Cache em proxy reverso (nível gateway)
Proxies reversos (como NGINX ou Varnish) ficam na frente da sua aplicação e podem cachear respostas inteiras. Úteis quando você quer controle centralizado, evicção previsível e proteção rápida para servidores de origem durante picos de tráfego.
Normalmente têm distribuição menos global que uma CDN, mas são mais fáceis de ajustar por rotas e headers da sua aplicação.
Cache em nível de aplicação (in-memory, Redis, Memcached)
Esse cache mira objetos, resultados computados e chamadas caras (ex.: “perfil do usuário por id” ou “regras de precificação por região”). É flexível e pode estar ciente da lógica de negócio.
Também introduz mais decisões: design de chave, escolhas de TTL, lógica de invalidação e necessidades operacionais como dimensionamento e failover.
Cache de banco de dados e cache de resultados/consultas
A maioria dos bancos cacheia páginas, índices e planos de consulta automaticamente; alguns suportam cache de resultados. Isso acelera consultas repetidas sem mudar código da aplicação.
É melhor ver isso como um bônus, não uma garantia: caches de banco são tipicamente os menos previsíveis sob padrões de consulta diversos, e não removem o custo de escrita, locks ou contenção do mesmo modo que caches upstream.
Onde o cache entrega a maior redução de carga
Cache vale mais a pena quando transforma operações repetidas e caras em uma busca barata. O truque é casar o cache com workloads em que as requisições são similares o bastante — e estáveis o bastante — para que a reutilização seja alta.
Workloads pesados em leitura e computações caras
Se seu sistema tem muito mais leituras que escritas, cache pode eliminar grande parte do trabalho no banco e na aplicação. Páginas de produto, perfis públicos, artigos de ajuda e resultados de busca/filtragem costumam ser requisitados repetidamente com os mesmos parâmetros.
Cache também ajuda em trabalho “caro” que não é estritamente bound ao banco: gerar PDFs, redimensionar imagens, renderizar templates ou calcular agregados. Mesmo um cache de curta duração (segundos a minutos) pode colapsar computação repetida durante períodos de alta demanda.
Tráfego pontual e proteção contra rajadas
Cache é especialmente efetivo quando o tráfego é desigual. Se um e-mail de marketing, menção na mídia ou post viral envia um pico de usuários às mesmas URLs, uma CDN ou cache de borda pode absorver a maior parte dessa onda.
Isso reduz carga além de “respostas mais rápidas”: pode evitar thrashing de autoscaling, exaustão de conexões ao banco e ganhar tempo para limites de taxa e backpressure atuarem.
Backends de alta latência e usuários em múltiplas regiões
Se sua origem está longe dos usuários — literalmente (cross-region) ou logicamente (uma dependência lenta) — cache reduz carga percebida e latência. Servir conteúdo a partir da CDN perto do usuário evita idas repetidas de longa distância.
Cache interno também ajuda quando o gargalo é uma store de alta latência (um banco remoto, API de terceiro, ou serviço compartilhado). Cortar número de chamadas reduz pressão de concorrência e melhora a latência de cauda.
Quando cache faz pouco sentido
Cache traz pouco benefício quando respostas são altamente personalizadas (dados por usuário, detalhes sensíveis) ou quando dados mudam constantemente (dashboards ao vivo, inventários que mudam rápido). Nestes casos, taxa de acerto é baixa, custo de invalidação sobe, e o trabalho salvo pode ser marginal.
Regra prática: cache é mais valioso quando muitos usuários pedem a mesma coisa dentro de uma janela em que “a mesma coisa” permanece válida. Se essa sobreposição não existe, mais uma camada de cache pode aumentar complexidade sem reduzir carga significativamente.
Invalidação de cache: a principal fonte de complexidade
Cache é fácil quando dados nunca mudam. No momento em que mudam, você herda a parte mais difícil: decidir quando dados em cache deixam de ser confiáveis e como cada camada de cache fica sabendo da mudança.
Expiração por TTL: simples, mas raramente “certa”
Time-to-live (TTL) é atraente porque é um número só e sem coordenação. O problema é que o TTL “correto” depende do uso dos dados.
Se você definir TTL de 5 minutos para um preço de produto, alguns usuários verão o preço antigo após a mudança — potencialmente um problema legal ou de suporte. Se definir 5 segundos, talvez não reduza muito a carga. Pior ainda, diferentes campos na mesma resposta mudam em ritmos distintos (estoque vs descrição), então um único TTL força um compromisso.
Invalidação orientada a eventos: precisa, mas exige coordenação
Invalidação por evento diz: quando a fonte da verdade muda, publique um evento e purge/atualize todas as chaves afetadas. Pode ser muito correto, mas cria trabalho novo:
- Todo caminho de escrita precisa emitir eventos de forma confiável
- Cada camada de cache deve se inscrever, tentar novamente, deduplicar e lidar com entregas fora de ordem
- Você precisa de um mapeamento claro de “o que mudou” → “quais chaves invalidar”
Esse mapeamento é onde “as duas coisas difíceis: nomeação e invalidação” vira algo prático e doloroso. Se você cacheia /users/123 e também cacheia listas de “top contributors”, uma mudança de username afeta mais de uma chave. Sem rastrear relações, você servirá uma realidade misturada.
Padrões: cache-aside vs write-through vs write-back
Cache-aside (app lê/escreve DB, popula o cache) é comum, mas a invalidação fica sob sua responsabilidade.
Write-through (escreve no cache e no DB juntos) reduz risco de estaleidade, mas adiciona latência e complexidade de tratamento de falhas.
Write-back (escreve primeiro no cache, grava depois) acelera, mas torna correção e recuperação muito mais difíceis.
Stale-while-revalidate: “bom o bastante” por escolha
Stale-while-revalidate serve dados levemente antigos enquanto atualiza em segundo plano. Isso suaviza picos e protege a origem, mas é também uma decisão de produto: você está escolhendo explicitamente “rápido e majoritariamente atual” em vez de “sempre o mais recente”.
Trade-offs de consistência e correção visível ao usuário
Recrie o caminho da requisição
Inicie uma stack com React, Go e Postgres pelo chat para reproduzir o problema de cache.
Cache muda o que “correto” significa. Sem cache, usuários geralmente veem o último dado commitado (exceto por comportamento normal do banco). Com caches, usuários podem ver dados um pouco defasados — ou inconsistentes entre telas — às vezes sem qualquer erro óbvio.
Consistência forte vs eventual (e o que usuários realmente notam)
Consistência forte mira em “read-after-write”: se um usuário atualiza seu endereço, o próximo carregamento deve mostrar o novo endereço em todos os lugares. Isso parece intuitivo, mas pode ser caro se cada escrita precisa imediatamente purgar ou atualizar múltiplos caches.
Consistência eventual permite estaleidade breve: a atualização aparecerá em breve, mas não instantaneamente. Usuários toleram isso para conteúdo de baixo risco (contadores de visualização), mas não para dinheiro, permissões ou qualquer coisa que afete ações imediatas.
Condições de corrida entre escritas e refreshs de cache
Um problema comum é uma escrita acontecer ao mesmo tempo que a repopulação do cache:
- Usuário atualiza o perfil.
- Cache é invalidado.
- Outra requisição repopula o cache a partir de uma réplica que ainda não recebeu a atualização.
Agora o cache contém dado antigo pelo seu TTL inteiro, mesmo que o banco esteja correto.
Inconsistência multi-camada: edge diz A, app diz B
Com múltiplas camadas, partes diferentes do sistema podem discordar:
- CDN retorna uma página HTML mais antiga (“Endereço: Rua Antiga”).
- Cache da aplicação retorna um JSON mais novo (“Endereço: Rua Nova”).
- A interface fica uma mistura de ambos.
Usuários interpretam isso como “o sistema está quebrado”, não como “o sistema é eventualmente consistente”.
Versionamento reduz ambiguidade:
- ETags permitem que clientes/CDNs revalidem eficientemente e evitem servir conteúdo desatualizado quando a representação muda.
- Chaves versionadas de cache (ex.:
user:123:v7) permitem avançar com segurança: uma escrita aumenta a versão, e as leituras naturalmente mudam para a nova chave sem exigir deleções perfeitamente sincronizadas.
Definir estaleidade aceitável por funcionalidade
A decisão chave não é “dados desatualizados são ruins?” mas onde isso é ruim.
Defina orçamentos explícitos de estaleidade por funcionalidade (segundos/minutos/horas) e alinhe-os com expectativas do usuário. Resultados de busca podem atrasar um minuto; saldos de conta e controle de acesso não deveriam.
Isso transforma “correção do cache” em requisito de produto que você pode testar e monitorar.
Modos de falha: stampedes, hot keys e quedas de cache
Caches frequentemente falham de maneira que parece “tudo estava bem, então tudo quebrou de uma vez”. Essas falhas não significam que cache é ruim — significam que caches concentram padrões de tráfego, então pequenas mudanças podem disparar efeitos grandes.
Cold starts e carga desigual após deploys
Depois de um deploy, evento de autoscale ou flush de cache, o cache pode estar quase vazio. A próxima onda de tráfego força muitas requisições a atingir o banco ou APIs upstream diretamente.
Isso é especialmente doloroso quando o tráfego sobe rápido, porque o cache não teve tempo de aquecer com itens populares. Se deploys coincidem com pico de uso, você pode criar acidentalmente seu próprio teste de carga.
Stampedes de cache (thundering herd)
Um stampede ocorre quando muitos usuários pedem o mesmo item justo quando ele expira (ou ainda não está em cache). Em vez de uma requisição recomputar o valor, centenas ou milhares o fazem — sobrecarregando a origem.
Mitigações comuns incluem:
- Coalescência de requisições: permita que a primeira requisição reconstrua enquanto as outras aguardam o resultado.
- Locks / single-flight: obrigue “apenas um construtor” por chave de cache.
- TTLs com jitter: randomize expirações para que chaves não expirem simultaneamente.
Se requisitos de correção permitirem, stale-while-revalidate também pode suavizar picos.
Hot keys e distribuição desigual
Algumas chaves tornam-se desproporcionalmente populares (payload da homepage, produto em alta, configuração global). Hot keys criam carga desigual: um nó de cache ou um caminho de backend é alvejado enquanto outros ficam ociosos.
Mitigações incluem dividir grandes chaves “globais” em menores, adicionar sharding/partitioning, ou cachear em outra camada (por exemplo, mover conteúdo verdadeiramente público para mais perto do usuário via CDN).
Quando o cache cai: escolha seu fallback
Quedas de cache podem ser piores que não ter cache, porque aplicações podem depender dele. Decida com antecedência:
- Fail open (ignorar cache, atingir origem): mais disponibilidade, maior risco de carga
- Fail closed (retornar erros): protege a origem, pior experiência ao usuário
- Degradar graciosamente (servir stale/padrões): frequentemente o melhor compromisso
Seja qual for a escolha, rate limits e circuit breakers ajudam a evitar que uma falha de cache vire um outage da origem.
Sobrecarga operacional: mais partes móveis para gerenciar
Mantenha controle total do código
Gere a app e depois exporte o código‑fonte para integrar seu cache e observabilidade preferidos.
Cache pode reduzir carga nas origens, mas aumenta o número de serviços que você opera no dia a dia. Mesmo caches gerenciados exigem planejamento, tuning e resposta a incidentes.
Mais componentes para rodar
Uma nova camada de cache é frequentemente um novo cluster (ou ao menos uma nova camada) com limites de capacidade próprios. Times devem decidir tamanho de memória, política de evicção e o que acontece sob pressão. Se o cache estiver subdimensionado, ele churna: taxa de acerto cai, latência sobe e a origem é atingida de qualquer forma.
Drift de configuração entre camadas
Cache raramente vive em um só lugar. Você pode ter cache na CDN, cache da aplicação e cache do banco — todos interpretando regras de forma diferente.
Pequenos desalinhamentos se somam:
- CDN respeita headers, cache da app usa TTLs codificados
- Uma camada contorna com base em cookies enquanto outra não
- Regras de purge existem em um lugar e não em outro
Com o tempo, “por que essa requisição está cacheada?” vira um projeto de arqueologia.
Tarefas operacionais novas
Caches criam trabalho recorrente: aquecer chaves críticas após deploys, purgar/revalidar quando dados mudam, resharding quando nodes são adicionados/removidos, e ensaiar o que acontece após um flush completo.
Complexidade on-call durante incidentes
Quando usuários reportam dados obsoletos ou lentidão súbita, os respondedores têm agora múltiplos suspeitos: a CDN, o cluster de cache, o cliente de cache da app e a origem. Depurar muitas vezes significa checar taxas de acerto, picos de evicção e timeouts através das camadas — e então decidir se contornar, purgar ou escalar.
Observabilidade: provar que o cache realmente ajuda
Cache é vantagem só se reduzir trabalho de backend e melhorar a percepção do usuário. Como requisições podem ser atendidas por múltiplas camadas (edge/CDN, cache da aplicação, cache do BD), você precisa de observabilidade que responda:
- Qual camada atendeu essa requisição?
- O que mudou quando não atendeu?
Métricas que realmente explicam resultados
Uma alta taxa de acerto soa bem, mas pode esconder problemas (como leituras de cache lentas ou churn constante). Monitore um conjunto pequeno de métricas por camada:
- Taxa de acerto e de miss, dividida por endpoint ou namespace
- Latência por camada (tempo de leitura do cache vs tempo da origem), idealmente p50/p95/p99
- Taxa de evicção e idade dos itens (quanto tempo entradas sobrevivem antes de remoção)
- Indicadores de carga da origem (QPS do BD, CPU, saturação de pool de conexões) correlacionados com hits no cache
Se a taxa de acerto sobe mas a latência total não melhora, o cache pode estar lento, excessivamente serializado ou retornando payloads grandes demais.
Tracing entre camadas
Tracing distribuído deve mostrar se uma requisição foi atendida na borda, pelo cache da app ou pelo banco de dados. Adicione tags consistentes como cache.layer=cdn|app|db e cache.result=hit|miss|stale para filtrar traces e comparar tempos de caminhos de hit vs miss.
Logs e alertas sem vazar dados
Faça log das chaves de cache com cuidado: evite identificadores brutos de usuário, e-mails, tokens ou URLs completas com query strings. Prefira chaves normalizadas ou hashed e registre apenas um prefixo curto.
Alerta para picos anormais de miss-rate, saltos súbitos de latência em misses e sinais de stampede (muitos misses concorrentes de um mesmo padrão de chave). Separe dashboards em vistas de edge, app e banco, mais um painel end-to-end que as relacione.
Riscos de segurança e privacidade em respostas cacheadas
Cache é ótimo em repetir respostas rápido — mas também pode repetir a resposta errada para a pessoa errada. Incidentes de segurança relacionados a cache costumam ser silenciosos: tudo parece rápido e saudável enquanto dados são vazados.
Como dados sensíveis acabam em caches
Uma falha comum é cachear conteúdo personalizado ou confidencial (detalhes de conta, faturas, tickets de suporte, páginas de admin). Isso pode ocorrer em qualquer camada — CDN, proxy reverso ou cache da aplicação — especialmente com regras amplas de “cachear tudo”.
Outro vazamento sutil: cachear respostas que incluem estado de sessão (por exemplo, um header Set-Cookie) e servir essa resposta cacheada para outros usuários.
Erros de autorização: requisição correta, visualizador incorreto
Um bug clássico é cachear o HTML/JSON retornado para o Usuário A e depois servir para o Usuário B porque a chave do cache não incluía o contexto do usuário. Em sistemas multi-tenant, a identidade do tenant também deve fazer parte da chave.
Regra prática: se a resposta depende de autenticação, papéis, geolocalização, nível de preço ou feature flags, sua chave de cache (ou lógica de bypass) deve refletir essa dependência.
Comportamento de cache HTTP é fortemente dirigido por headers:
Cache-Control: previna armazenamento acidental com private / no-store quando necessárioVary: garanta que caches separem respostas por headers relevantes (ex.: Authorization, Accept-Language)Set-Cookie: frequentemente é um sinal de que a resposta não deve ser cacheada publicamente
Quando evitar cachear inteiramente
Se compliance ou risco é alto — PII, dados de saúde/financeiros, documentos legais — prefira Cache-Control: no-store e otimize no servidor. Para páginas mistas, cacheie apenas fragmentos não sensíveis ou assets estáticos, mantendo dados personalizados fora de caches compartilhados.
Custo e ROI: decidir se mais uma camada vale a pena
Faça um teste de ROI de cache
Crie um pequeno teste em torno do seu endpoint principal e compare latência e carga na origem.
Camadas de cache podem reduzir carga de origem, mas raramente são “performance grátis”. Trate cada novo cache como um investimento: você compra menor latência e menos trabalho de backend em troca de dinheiro, tempo de engenharia e uma superfície maior de correção.
O que você paga vs o que economiza
Custo extra de infraestrutura vs redução de custo de origem. Uma CDN pode reduzir egress e leituras de banco, mas você pagará por requisições CDN, armazenamento em cache e às vezes chamadas de invalidação. Um cache de aplicação (Redis/Memcached) adiciona custo de cluster, upgrades e on-call. A economia pode aparecer como menos réplicas de banco, instâncias menores ou escalonamento adiado.
Ganho de latência vs custo de frescor. Cada cache introduz “qual é o quanto de estaleidade aceitável?”. Frescor estrito exige mais plumbing de invalidação (e mais misses). Estaleidade tolerada economiza computação mas pode custar confiança do usuário — especialmente para preços, disponibilidade ou permissões.
Tempo de engenharia: velocidade de entrega vs trabalho de confiabilidade. Uma nova camada normalmente significa caminhos de código extras, mais testes e mais classes de incidentes para evitar (stampedes, hot keys, invalidação parcial). Orce manutenção contínua, não só implementação inicial.
Rode experimentos pequenos para medir ROI
Antes de ampliar, faça um teste limitado:
- Escolha um endpoint ou página com carga clara (ex.: top 5% do tráfego).
- Defina métricas de sucesso: latência p95, QPS do BD, taxa de erro, hit ratio do cache.
- Aumente gradualmente; monitore custo junto com performance.
- Timebox o experimento e mantenha um switch de rollback.
Checklist simples de decisão
Adicione uma nova camada de cache somente se:
- O gargalo estiver comprovado (não só estimado) via métricas.
- Houver um alvo claro (ex.: reduzir leituras no BD em 40%).
- Regras de estaleidade e invalidação forem explicitamente aceitáveis.
- Você puder monitorar (hit rate, evicções, latência, erros).
- A economia esperada superar custos operacionais e de engenharia em um horizonte realista.
Diretrizes práticas para reduzir complexidade ao usar cache
Cache compensa mais rapidamente quando você trata como um recurso de produto: precisa de dono, regras claras e um modo seguro de desligá-lo.
Comece pequeno, atribua propriedade
Adicione uma camada de cada vez (ex.: CDN ou cache de aplicação primeiro) e atribua um time/pessoa responsável diretamente.
Defina quem possui:
- mudanças de configuração (TTL, regras de bypass)
- capacidade e comportamento de evicção
- resposta a incidentes (o que fazer quando está errado)
Faça chaves de cache entediantes e previsíveis
A maioria dos bugs de cache são realmente “bugs de chave”. Use uma convenção documentada que inclua as entradas que mudam a resposta: escopo tenant/usuário, locale, classe de dispositivo e feature flags relevantes.
Adicione versionamento explícito de chave (ex.: product:v3:...) para poder invalidar com segurança aumentando a versão em vez de tentar deletar milhões de entradas.
Prefira estaleidade limitada a frescor perfeito
Tentar manter tudo perfeitamente fresco empurra complexidade para cada caminho de escrita.
Em vez disso, decida o que “aceitavelmente desatualizado” significa por endpoint (segundos, minutos, ou “até a próxima atualização”), então codifique com:
- TTLs que casem com expectativas de negócio
- refresh em background (servir levemente desatualizado enquanto atualiza)
- invalidação orientada a eventos somente para dados realmente sensíveis
Construa defaults seguros para falhas
Assuma que o cache vai ficar lento, errado ou cair.
Use timeouts e circuit breakers para que chamadas ao cache não derrubem sua rota de requisição. Degradação explícita: se o cache falhar, caia para a origem com rate limits, ou sirva uma resposta mínima.
Liberte o cache atrás de um canary ou rollout por porcentagem, e mantenha um switch de bypass (por rota ou header) para troubleshooting rápido.
Documente runbooks: como purgar, como aumentar versão de chave, como desativar cache temporariamente e onde checar métricas. Linke-os nas páginas internas de runbook para que on-call aja rápido.
Prototipar mudanças de cache sem travar entrega
Trabalhos de cache costumam travar porque tocam múltiplas camadas (headers, lógica de app, modelos de dados e planos de rollback). Uma forma de reduzir custo de iteração é prototipar todo o caminho de requisição em um ambiente controlado.
Com Koder.ai, times podem rapidamente criar uma stack de app realista (React no web, backends Go com PostgreSQL e até clientes mobile Flutter) via workflow orientado por chat, então testar decisões de cache (TTL, design de chave, stale-while-revalidate) ponta a ponta. Recursos como planning mode ajudam a documentar o comportamento de cache pretendido antes da implementação, e snapshots/rollback tornam mais seguro experimentar configurações de cache ou lógica de invalidação. Quando prontos, é possível exportar código-fonte ou fazer deploy/host com domínios customizados — útil para testes de performance que precisam espelhar padrões de tráfego em produção.
Se usar uma plataforma assim, trate-a como complemento à observabilidade de produção: o objetivo é iterar mais rápido no design do cache enquanto mantém requisitos de correção e procedimentos de rollback explícitos.