Por que a clareza importa em cloud-native
Ferramentas cloud-native prometem velocidade e flexibilidade, mas também introduzem novo vocabulário, novas peças em movimento e novas formas de pensar sobre operações. Quando a explicação é confusa, a adoção desacelera por um motivo simples: as pessoas não conseguem conectar a ferramenta aos problemas que realmente têm. Equipes hesitam, líderes adiam decisões e experimentos iniciais viram pilotos pela metade.
A clareza muda essa dinâmica. Uma explicação clara transforma “Kubernetes explicado” de uma frase de marketing em um entendimento compartilhado: o que o Kubernetes faz, o que ele não faz e pelo que sua equipe é responsável no dia a dia. Uma vez que esse modelo mental existe, as conversas ficam práticas—sobre cargas de trabalho, confiabilidade, escala, segurança e os hábitos operacionais necessários para rodar sistemas em produção.
Por que boas explicações aceleram a adoção
Quando conceitos são explicados em linguagem simples, as equipes:
- Avaliam trade-offs mais rápido (e param de tratar todo recurso como obrigatório).
- Identificam pré‑requisitos cedo (habilidades, ownership, expectativas de on‑call).
- Reduzem o medo de “quebrar produção” porque o sistema passa a parecer compreensível.
- Constroem alinhamento entre desenvolvedores, ops, SRE e liderança.
Em outras palavras, comunicação não é luxo; é parte do plano de rollout.
O que você vai aprender neste texto
Este artigo foca em como o estilo de ensino de Kelsey Hightower tornou conceitos centrais de DevOps e fundamentos do Kubernetes mais acessíveis—e como essa abordagem influenciou a adoção cloud-native de forma mais ampla. Você sairá com lições que pode aplicar na sua organização:
- Como explicar decisões de engenharia de plataforma sem jargão.
- Como ensinar o “porquê” por trás da excelência operacional, não apenas o “como.”
- Como o compartilhamento de conhecimento orientado pela comunidade acelera a adoção no mundo real.
O objetivo não é debater ferramentas. É mostrar como comunicação clara—repetida, compartilhada e melhorada por uma comunidade—pode mover uma indústria da curiosidade para o uso confiante.
Quem é Kelsey Hightower (e por que as pessoas o escutam)
Kelsey Hightower é um educador conhecido em Kubernetes e uma voz na comunidade cujo trabalho ajudou muitas equipes a entender o que a orquestração de contêineres realmente envolve—especialmente as partes operacionais que as pessoas tendem a aprender do jeito difícil.
Ele se tornou visível em papéis práticos e públicos: palestrando em conferências, publicando tutoriais e talks, e participando da comunidade cloud‑native onde praticantes compartilham padrões, falhas e correções. Em vez de posicionar Kubernetes como um produto mágico, seu material tende a tratá‑lo como um sistema que você opera—com peças em movimento, trade‑offs e modos reais de falha.
O que se destaca consistentemente é a empatia pelas pessoas que pagam o preço quando algo quebra: engenheiros on‑call, times de plataforma, SREs e desenvolvedores tentando entregar enquanto aprendem nova infraestrutura.
Essa empatia aparece em como ele explica:
- Pelo que o Kubernetes é responsável (e pelo que não é).
- De onde vem a complexidade (sistemas distribuídos, rede, identidade, upgrades).
- Como construir intuição em vez de memorizar comandos.
Também fica claro ao falar com iniciantes sem tratar ninguém com condescendência. O tom costuma ser direto, fundamentado e cauteloso com afirmações—mais “aqui está o que acontece por baixo do capô” do que “aqui está a única forma correta”.
Trabalho observável, não personalidade
Não é preciso tratar ninguém como mascote para ver o impacto. A evidência está no próprio material: talks amplamente referenciadas, recursos práticos de aprendizado e explicações que são reusadas por outros educadores e times de plataforma internos. Quando pessoas dizem que “finalmente entenderam” um conceito como planos de controle, certificados ou bootstrap de cluster, muitas vezes foi porque alguém explicou de forma simples—e muitas dessas explicações remontam ao estilo de ensino dele.
Se a adoção do Kubernetes é em parte um problema de comunicação, a influência dele lembra que ensino claro é também uma forma de infraestrutura.
Kubernetes antes de parecer acessível
Antes do Kubernetes se tornar a resposta padrão para “como rodamos contêineres em produção?”, ele muitas vezes parecia um muro denso de novo vocabulário e suposições. Mesmo equipes confortáveis com Linux, CI/CD e serviços de nuvem faziam perguntas básicas—e então se sentiam como se não devessem fazê‑las.
Confusão inicial: termos novos, modelos mentais novos
Kubernetes introduziu uma maneira diferente de pensar sobre aplicações. Em vez de “um servidor roda minha app”, você de repente tinha pods, deployments, services, ingresses, controllers e clusters. Cada termo soava simples isoladamente, mas o significado dependia de como ele se conectava ao resto.
Um ponto comum de atrito era o desalinhamento de modelo mental:
- “Onde eu faço SSH?” (Geralmente: você não faz.)
- “Em qual máquina minha app está?” (Pode mudar.)
- “Por que ela reiniciou?” (Por design.)
Isso não era só aprender uma ferramenta; era aprender um sistema que trata infraestrutura como fluida.
Medos comuns: confiabilidade, segurança e operações day‑2
A primeira demonstração pode mostrar um contêiner escalando de forma suave. A ansiedade começava depois, quando as pessoas imaginavam as perguntas operacionais reais:
- O que acontece durante a falha de um nó?
- Como gerenciamos segredos com segurança?
- Quem tem acesso ao quê no cluster?
- Como aplicar patches, atualizar e reverter sem quebrar produção?
Muitas equipes não tinham medo do YAML—tinham medo da complexidade oculta, onde erros podem ser silenciosos até uma queda.
A lacuna entre promessas de marketing e a configuração real
Kubernetes muitas vezes era apresentado como uma plataforma onde você “simplesmente faz deploy” e tudo é automatizado. Na prática, chegar a essa experiência exigia escolhas: rede, armazenamento, identidade, políticas, monitoramento, logs e estratégia de upgrade.
Essa lacuna gerou frustração. As pessoas não rejeitavam o Kubernetes em si; reagiam à dificuldade de conectar a promessa (“simples, portátil, self‑healing”) aos passos necessários para torná‑la real no ambiente delas.
Um estilo de ensino feito para engenheiros que trabalham
Kelsey Hightower ensina como alguém que já esteve on‑call, já viu um deploy dar errado e ainda teve que entregar no dia seguinte. O objetivo não é impressionar com vocabulário—é ajudar você a construir um modelo mental que possa usar às 2h da manhã quando um pager tocar.
Linguagem simples, no momento necessário
Um hábito chave é definir termos no momento em que importam. Em vez de largar um parágrafo de vocabulário de Kubernetes no começo, ele explica um conceito em contexto: o que é um Pod no mesmo fôlego de por que você agrupa contêineres, ou o que um Service faz quando a pergunta é “como requisições encontram minha app?”.
Essa abordagem reduz a sensação de “estou atrasado” que muitos engenheiros têm com tópicos cloud‑native. Você não precisa decorar um glossário; aprende seguindo um problema até sua solução.
Exemplos concretos em vez de diagramas abstratos
As explicações dele tendem a começar com algo tangível:
- “Se esse processo morrer, o que o reinicia?”
- “Se o nó desaparecer, o que acontece com o tráfego?”
- “Se escalar de 2 para 20 instâncias, como os clientes mantêm conexão?”
Essas perguntas levam naturalmente aos primitivos do Kubernetes, mas ancoradas em cenários que engenheiros reconhecem de sistemas reais. Diagramas ajudam, mas não são toda a lição—o exemplo faz o trabalho pesado.
Respeito pela realidade operacional
O ensino inclui as partes pouco glamorosas: upgrades, incidentes e trade‑offs. Não é “Kubernetes facilita tudo”, é “Kubernetes te dá mecanismos—agora você precisa operá‑los.”
Isso significa reconhecer restrições:
- Descompasso de versões e planejamento de upgrades não são opcionais.
- Observabilidade não é um item de checklist; é como você depura falhas distribuídas.
- Carga de on‑call é parte do desenho do sistema, não um detalhe posterior.
É por isso que o conteúdo ressoa com engenheiros em produção: trata a produção como sala de aula e a clareza como forma de respeito.
“Kubernetes the Hard Way”: aprender os fundamentos
Compartilhe um link de demo limpo
Adicione um domínio personalizado ao seu sandbox para que stakeholders possam testar sem configuração.
“Kubernetes the Hard Way” é memorável não porque é difícil por desafio, mas porque faz você tocar nas partes que a maioria dos tutoriais esconde. Em vez de clicar em um assistente de serviço gerenciado, você monta um cluster funcional peça por peça. Essa abordagem de “aprender fazendo” transforma infraestrutura de caixa preta em um sistema que você pode raciocinar.
Como é aprender fazendo
O passo a passo faz você criar os blocos de construção: certificados, kubeconfigs, componentes do plano de controle, rede e configuração dos nós de trabalho. Mesmo que você nunca planeje rodar Kubernetes desse jeito em produção, o exercício ensina pelo que cada componente é responsável e o que pode dar errado quando mal configurado.
Você não apenas ouve “etcd é importante”—vê por que importa, o que ele armazena e o que acontece se ficar indisponível. Não apenas memoriza “o API server é a porta de entrada”—você o configura e entende quais chaves ele checa antes de deixar requisições passarem.
Por que começar do básico constrói confiança
Muitas equipes ficam inseguras em adotar Kubernetes porque não conseguem dizer o que está acontecendo por baixo. Construir a partir do básico inverte essa sensação. Quando você entende a cadeia de confiança (certs), a fonte da verdade (etcd) e a ideia de loop de controle (controllers reconciliando constantemente o desejado vs. o real), o sistema parece menos misterioso.
Essa confiança é prática: ajuda a avaliar recursos de fornecedores, interpretar incidentes e escolher defaults sensatos. Você pode dizer “sabemos o que esse serviço gerenciado está abstraindo” em vez de torcer para que esteja certo.
Passo a passo reduz o medo da complexidade
Um bom walkthrough divide “Kubernetes” em passos pequenos e testáveis. Cada passo tem um resultado esperado claro—o serviço inicia, um health check passa, um nó entra. O progresso é mensurável e os erros são locais.
Essa estrutura reduz a ansiedade: complexidade vira uma série de decisões compreensíveis, não um salto único para o desconhecido.
Tornando conceitos centrais do Kubernetes compreensíveis
Muita confusão vem de tratar Kubernetes como um monte de recursos em vez de uma promessa simples: você descreve o que quer e o sistema tenta fazer a realidade coincidir com isso.
Desired state (o que você quer)
“Desired state” é sua equipe escrevendo o resultado esperado: rode três cópias desta app, exponha‑a em um endereço estável, limite quanto CPU ela pode usar. Não é um runbook passo a passo.
Essa distinção importa porque espelha o trabalho operacional diário. Em vez de “faça SSH no servidor A, inicie o processo, copie configuração”, você declara o alvo e deixa a plataforma lidar com passos repetitivos.
Reconciliation (como ele se mantém verdadeiro)
Reconciliation é o loop de checagem e correção. O Kubernetes compara o que está rodando agora com o que você pediu e, se algo divergiu—uma app caiu, um nó sumiu, uma config mudou—ele age para fechar a lacuna.
Em termos humanos: é um engenheiro on‑call que nunca dorme, reaplicando continuamente o padrão acordado.
Aqui também vale separar conceitos de detalhes de implementação. O conceito é “o sistema corrige drift”. A implementação pode envolver controllers, replica sets ou estratégias de rollout—mas você pode aprender isso depois sem perder a ideia principal.
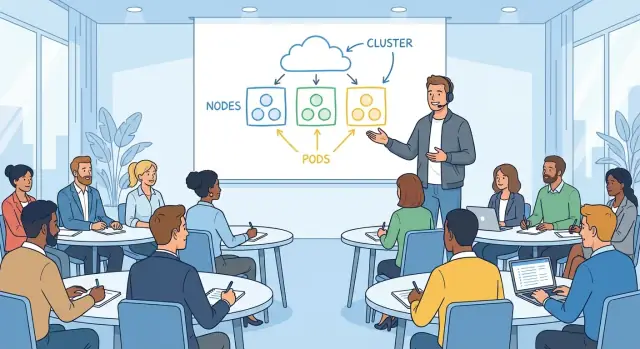
Agendamento (onde roda)
Agendamento responde a uma pergunta prática que todo operador reconhece: qual máquina deve rodar essa carga? O Kubernetes olha para capacidade disponível, restrições e políticas, e então coloca o trabalho nos nós.
Conectar primitivos a tarefas familiares faz tudo encaixar:
- Pods são uma unidade executável (como um grupo de processos).
- Deployments garantem “mantenha N cópias rodando e atualize com segurança”.
- Services dão “uma forma estável de alcançar, mesmo quando as instâncias mudam”.
Uma vez que você enquadra Kubernetes como “declare, reconcile, place”, o resto vira vocabulário—útil, mas não mais misterioso.
Explicar operações sem intimidação
A conversa sobre operações pode soar como uma linguagem restrita: SLIs, error budgets, “blast radius”, planejamento de capacidade. Quando as pessoas se sentem excluídas, ou assentem sem entender ou evitam o assunto—ambos levam a sistemas frágeis.
O estilo do Kelsey faz ops parecer engenharia normal: um conjunto de perguntas práticas que você pode aprender a fazer, mesmo sendo novo.
Traduza ops em decisões do dia a dia
Em vez de tratar operações como “melhores práticas” abstratas, traduza para o que seu serviço precisa fazer sob pressão.
Confiabilidade vira: o que quebra primeiro e como vamos notar? Capacidade vira: o que acontece na segunda‑feira pela manhã? Modos de falha viram: qual dependência vai nos mentir, dar timeout ou retornar dados parciais? Observabilidade vira: se um cliente reclamar, conseguimos responder “o que mudou” em cinco minutos?
Quando conceitos de ops são colocados assim, param de soar como curiosidade e viram senso comum.
Tornar trade‑offs explícitos (e aceitáveis)
Boas explicações não afirmam um único caminho correto—mostram o custo de cada escolha.
Simplicidade vs. controle: um serviço gerenciado reduz toil, mas pode limitar ajuste fino.
Velocidade vs. segurança: entregar rápido pode significar menos checagens hoje, mas aumenta a chance de depurar produção amanhã.
Ao nomear trade‑offs de forma clara, as equipes conseguem discordar produtivamente sem envergonhar quem “não entendeu”.
Normalizar perguntas, erros e iteração
Operações se aprendem observando incidentes reais e quase‑erros, não decorando termos. Uma cultura de ops saudável trata perguntas como trabalho, não fraqueza.
Um hábito prático: após um outage ou alerta assustador, escreva três coisas—o que você esperava que acontecesse, o que aconteceu de fato e qual sinal teria avisado antes. Esse pequeno loop transforma confusão em runbooks melhores, dashboards mais claros e rotações de on‑call mais calmas.
Se você quer espalhar essa mentalidade, ensine do mesmo jeito: palavras simples, trade‑offs honestos e permissão para aprender em voz alta.
Como explicações claras se espalham pela comunidade
Hospede seu ambiente de demo
Faça deploy e hospede seu protótipo para a equipe testar em conjunto.
Explicações claras não ajudam só uma pessoa a “entender”. Elas viajam. Quando um palestrante ou escritor torna Kubernetes concreto—mostrando o que cada peça faz, por que existe e onde falha na prática—essas ideias são repetidas em conversas de corredor, copiadas em docs internas e re‑ensinadas em meetups.
Um vocabulário compartilhado que reduz atritos
Kubernetes tem muitos termos que soam familiares mas têm significado específico: cluster, node, control plane, pod, service, deployment. Quando explicações são precisas, as equipes param de falar uma língua diferente.
Alguns exemplos de como o vocabulário compartilhado aparece:
- Um desenvolvedor diz “o Service está quebrado” e todos entendem se isso significa DNS, balanceamento ou selectors.
- Um SRE diz “o control plane está degradado” e a equipe sabe que não é o mesmo que “a aplicação está caída”.
- Pessoas de produto ouvem “deployment” e aprendem que é um objeto Kubernetes—não apenas “lançamos código”.
Esse alinhamento acelera debug, planejamento e onboarding porque há menos tempo gasto traduzindo.
Confiança vence ansiedade
Muitos engenheiros evitam Kubernetes no começo não porque não conseguem aprender, mas porque parece caixa preta. Ensino claro substitui mistério por um modelo mental: “aqui o que conversa com o quê, aqui onde o estado vive, aqui como o tráfego é roteado”.
Quando o modelo encaixa, experimentar fica mais seguro. Pessoas tendem a:
- subir um pequeno cluster para testar ideias
- ler logs e eventos sem chutar
- fazer perguntas melhores em code reviews e canais de incidente
Efeito cascata: talks, meetups e docs
Quando explicações são memoráveis, a comunidade as repete. Um diagrama simples ou analogia vira forma padrão de ensinar e influencia:
- apresentações em meetups e conferências (novos palestrantes pegam o enquadramento)
- estilo de documentação open source (mais “porquê” junto com “como”)
- runbooks internos e guias de onboarding (passos e expectativas mais claros)
Com o tempo, a clareza vira artefato cultural: a comunidade aprende não só Kubernetes, mas como falar sobre operar ele.
Como a comunicação influenciou a adoção na indústria
Comunicação clara não apenas tornou Kubernetes mais fácil de aprender—mudou como organizações decidiram adotá‑lo. Quando sistemas complexos são explicados em termos simples, o risco percebido cai e as equipes conversam sobre resultados em vez de jargão.
Por que tomadores de decisão se importaram
Executivos e líderes de TI raramente precisam de todo detalhe de implementação, mas precisam de uma história crível sobre trade‑offs. Explicações diretas sobre o que Kubernetes é (e não é) ajudaram a enquadrar conversas sobre:
- Risco: o que quebra, o que é estável e o que precisa rollout cuidadoso
- Custo e ROI: onde automatizar reduz toil, onde aumenta a necessidade de equipe e quando padronizar traz retorno
- Responsabilidade: quem possui operações de cluster, segurança e expectativas de uptime
Quando Kubernetes era apresentado como blocos de construção compreensíveis—em vez de uma plataforma mística—discussões de orçamento e prazo ficaram menos especulativas. Isso facilitou rodar pilotos e medir resultados reais.
Como a educação apoiou a adoção
A adoção na indústria não se espalhou só por pitches de fornecedores; espalhou‑se por ensino. Talks de alto sinal, demos e guias práticos criaram um vocabulário compartilhado entre empresas e funções.
Essa educação normalmente se traduz em três aceleradores de adoção:
- Programas de treinamento que diminuem o tempo de onboarding para engenheiros e operadores
- Enablement interno (docs, brown‑bags, templates) que transforma conhecimento tribal em prática reutilizável
- Champions que explicam o “porquê” e o “como” para colegas, não apenas implementam o “o quê”
Quando equipes conseguem explicar conceitos como desired state, controllers e estratégias de rollout, Kubernetes vira discutível—e, portanto, adotável.
Onde a clareza não resolve tudo
Mesmo as melhores explicações não substituem mudança organizacional. Adotar Kubernetes ainda exige:
- Novas habilidades operacionais (confiabilidade, resposta a incidentes, higiene de segurança)
- Propriedade clara de plataforma e limites de serviço
- Tempo para refatorar processos de entrega, não apenas “instalar um cluster”
Comunicação tornou Kubernetes acessível; adoção bem‑sucedida ainda pede compromisso, prática e incentivos alinhados.
Lições práticas para equipes adotando Kubernetes
Ensine e ganhe créditos
Publique o que você construiu e ganhe créditos para mais projetos Koder.ai.
A adoção costuma falhar por razões banais: as pessoas não conseguem prever operações day‑2, não sabem o que aprender primeiro e a documentação assume que todo mundo já fala “cluster”. A correção prática é tratar clareza como parte do plano de rollout—não como reflexão tardia.
Construa duas trilhas de aprendizado (e diga qual é a sua)
A maioria das equipes mistura “como usar Kubernetes” com “como operar Kubernetes”. Separe o enablement em duas trilhas explícitas:
- Trilha iniciante: conceitos centrais, como fazer deploy, como debugar uma carga básica, como é um comportamento “bom”.
- Trilha operador: ciclo de vida do cluster, upgrades, rede, limites de segurança, backup/restore e resposta a incidentes.
Coloque essa separação logo no topo da documentação para que novos contratados não comecem no nível avançado por engano.
Demonstre como se estivesse ensinando um hábito, não mostrando um produto
Demos devem começar com o menor sistema possível e adicionar complexidade apenas quando necessário para responder a uma pergunta real.
Comece com um único Deployment e Service. Depois acrescente configuração, health checks e autoscaling. Só após os básicos estarem estáveis introduza ingress controllers, service meshes ou operators customizados. O objetivo é que as pessoas conectem causa e efeito, não decorem YAML.
Escreva runbooks que expliquem o “porquê”, não apenas o “faça isso”
Runbooks que são só checklists viram operação cargo‑cult. Cada passo importante deve incluir uma frase de justificativa: qual sintoma resolve, qual é o sucesso esperado e o que pode dar errado.
Por exemplo: “Reiniciar o pod limpa um pool de conexões travado; se ocorrer de novo em 10 minutos, verifique latência downstream e eventos do HPA.” Esse “porquê” permite improvisar quando um incidente não bate com o script.
Meça entendimento, não presença
Você saberá que o treinamento de Kubernetes está funcionando quando:
- As mesmas perguntas param de se repetir no Slack.
- A triagem de incidentes fica mais rápida porque há um modelo mental comum.
- Postmortems têm menos momentos de “não sabíamos onde olhar”.
Acompanhe esses resultados e ajuste docs e workshops conforme necessário. Clareza é um entregável—trate‑a assim.
Uma forma subestimada de fazer Kubernetes e conceitos de plataforma “clicarem” é permitir que times experimentem com serviços realistas antes de tocarem ambientes críticos. Isso pode significar construir um app de referência interno pequeno (API + UI + banco), usando‑o como exemplo consistente em docs, demos e exercícios de troubleshooting.
Plataformas como Koder.ai podem ajudar aqui porque permitem gerar um app web funcional, serviço backend e modelo de dados a partir de uma especificação via chat, e então iterar em modo “planejamento” antes que alguém se preocupe com YAML perfeito. A ideia não é substituir o aprendizado de Kubernetes—é encurtar o tempo de ideia → serviço rodando para que seu treinamento foque no modelo operacional (desired state, rollouts, observabilidade e mudanças seguras).
A maneira mais rápida de fazer “plataforma” funcionar internamente é torná‑la compreensível. Você não precisa que todo engenheiro vire especialista em Kubernetes, mas precisa de vocabulário compartilhado e confiança para debugar problemas básicos sem pânico.
Um framework repetível: definir, mostrar, praticar, depurar
Definir: Comece com uma frase clara. Ex.: “Um Service é um endereço estável para um conjunto mutável de Pods.” Evite despejar cinco definições de uma vez.
Mostrar: Demonstre o conceito no menor exemplo possível. Um arquivo YAML, um comando, um resultado esperado. Se não dá para mostrar rápido, o escopo é grande demais.
Praticar: Dê uma tarefa curta que as pessoas possam fazer sozinhas (mesmo em sandbox). “Escale este Deployment e veja o que acontece com o endpoint do Service.” Aprender entra quando as mãos tocam as ferramentas.
Depurar: Termine quebrando de propósito e percorrendo o raciocínio. “O que você checaria primeiro: events, logs, endpoints ou network policy?” É aqui que cresce a confiança operacional.
Analogias que ajudam (e como evitar as que confundem)
Analogias orientam, não definem com precisão. “Pods são como gado, não como pets” explica substituibilidade, mas pode esconder detalhes importantes (workloads stateful, volumes persistentes, disruption budgets).
Uma boa regra: use a analogia para introduzir a ideia e logo mude para os termos reais. Diga “É como X em um aspecto; aqui é onde a comparação para.” Essa frase evita equívocos caros depois.
Checklist para talks internas que as pessoas realmente usarão
Antes de apresentar, valide quatro pontos:
- Público: Para quem é—devs de aplicação, engenheiros on‑call, novos contratados?
- Objetivo: O que eles devem ser capazes de fazer após 30 minutos?
- Demo: Uma demo funcional, ensaiada, com plano B.
- Próximos passos: Um doc, runbook ou laboratório guiado que possam seguir amanhã.
Construa uma cultura de ensino, não de gatekeeping
Consistência vence treinamentos esporádicos. Experimente rituais leves:
- Horas de atendimento semanais para “traga seu problema de cluster”.
- Brown‑bags mensais com um conceito e um exemplo ao vivo.
- Rotação de pareamento entre times de plataforma e produto durante incidentes.
Quando ensinar vira rotina, a adoção fica mais tranquila—e sua plataforma para de parecer caixa preta.