28 de dez. de 2025·7 min
Claude Code para investigações de desempenho: um fluxo medido
Use Claude Code para investigações de desempenho com um loop repetível: medir, formular hipótese, mudar pouco e re-medir antes de enviar.
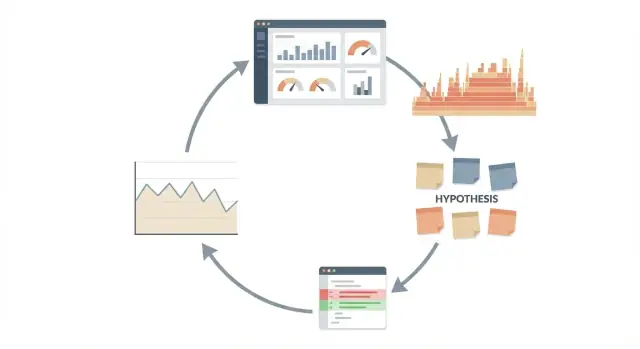
Use Claude Code para investigações de desempenho com um loop repetível: medir, formular hipótese, mudar pouco e re-medir antes de enviar.
Bugs de desempenho convidam ao palpite. Alguém percebe que uma página parece lenta ou uma API dá timeout, e a reação rápida é "limpar" o código, adicionar cache ou reescrever um loop. O problema é que "parece lento" não é uma métrica, e "mais limpo" não é sinônimo de mais rápido.
Sem medição, equipes gastam horas mudando a coisa errada. O caminho crítico pode estar no banco de dados, na rede ou numa única alocação inesperada, enquanto a equipe polia código que quase não roda. Pior, uma mudança que parece inteligente pode piorar o desempenho: logs extras em um loop apertado, um cache que aumenta a pressão de memória, ou trabalho paralelo que cria contenção de locks.
Adivinhação também corre o risco de quebrar comportamento. Ao mudar código para acelerar, você pode alterar resultados, tratamento de erros, ordenação ou retries. Se você não verificar corretude e velocidade juntos, pode "ganhar" um benchmark enquanto envia silenciosamente um bug.
Trate performance como um experimento, não como um debate. O loop é simples e repetível:
Muitos ganhos são modestos: cortar 8% do p95, reduzir pico de memória em 50 MB ou eliminar uma consulta ao banco. Esses ganhos importam, mas apenas se forem medidos, verificados e repetíveis.
Isto funciona melhor como um loop, não como um pedido pontual de "deixar mais rápido". O loop te mantém honesto porque cada ação se liga a evidência e a um número que você pode observar.
Sequência clara:
Cada passo te protege de um tipo diferente de autoengano. Medir primeiro impede que você "conserte" algo que não era um problema real. Uma hipótese escrita impede que você mude cinco coisas de uma vez e depois adivinhe qual delas importou. Mudanças mínimas reduzem o risco de quebrar comportamento ou adicionar novos gargalos. Re-medidas pegam ganhos placebo (como uma execução mais rápida por cache aquecido) e expõem regressões.
"Pronto" não é uma sensação. É um resultado: a métrica alvo se moveu na direção certa, e a mudança não causou regressões óbvias (erros, mais memória, pior p95 ou endpoints vizinhos mais lentos).
Saber quando parar também faz parte do fluxo. Pare quando os ganhos se achatam, quando a métrica já é boa o suficiente para os usuários, ou quando a próxima ideia exige grandes refactors por pouco ganho. Trabalho de performance sempre tem custo de oportunidade; o loop ajuda a gastar tempo onde vale a pena.
Se você medir cinco coisas ao mesmo tempo, não saberá o que melhorou. Escolha uma métrica primária para esta investigação e trate o resto como sinais de apoio. Para muitos problemas de interface, essa métrica é latência. Para jobs batch pode ser throughput, tempo de CPU, uso de memória ou até custo por execução na nuvem.
Seja específico sobre o cenário. "A API está lenta" é vago demais. "POST /checkout com um carrinho típico de 3 itens" é mensurável. Mantenha as entradas estáveis para que os números signifiquem algo.
Anote a baseline e os detalhes do ambiente antes de tocar no código: tamanho do dataset, tipo de máquina, modo de build, feature flags, concorrência e warmup. Essa baseline é sua âncora. Sem ela, qualquer mudança pode parecer progresso.
Para latência, confie em percentis, não só na média. p50 mostra a experiência típica, enquanto p95 e p99 expõem a cauda dolorosa que os usuários reclamam. Uma mudança que melhora p50 mas piora p99 ainda pode parecer mais lenta.
Decida de antemão o que "significativo" significa para não comemorar ruído:
Com essas regras, você pode testar ideias sem mover o alvo.
Comece pelo sinal mais fácil em que você confia. Um único timing em torno de uma requisição pode dizer se há um problema real e mais ou menos o tamanho dele. Reserve profiling mais profundo para quando precisar explicar por que está lento.
Boa evidência costuma vir de uma mistura de fontes:
Use métricas simples quando a pergunta for "está mais lento, e quanto?" Use profiling quando a pergunta for "para onde o tempo está indo?" Se o p95 dobrou após um deploy, comece com timings e logs para confirmar a regressão e delimitar. Se os timings mostram que a maior parte do atraso está no código da sua aplicação (não no BD), então um profiler de CPU ou um flame graph pode apontar a função exata que cresceu.
Mantenha as medições seguras. Colete o que precisa para debugar performance, não conteúdo do usuário. Prefira agregados (durações, contagens, tamanhos) ao invés de payloads brutos, e redija identificadores por padrão.
Ruído é real, então faça várias amostras e note outliers. Rode a mesma requisição 10 a 30 vezes e registre mediana e p95 em vez de uma execução isolada.
Escreva a receita exata do teste para poder repeti-la após mudanças: ambiente, dataset, endpoint, tamanho do body, nível de concorrência e como você capturou resultados.
Comece com um sintoma que você possa nomear: "p95 salta de 220 ms para 900 ms durante picos de tráfego", "CPU fica em 95% em dois núcleos" ou "memória cresce 200 MB por hora". Sintomas vagos como "parece lento" levam a mudanças aleatórias.
Depois, traduza o que você mediu para uma área suspeita. Um flame graph pode mostrar a maior parte do tempo em JSON encoding, um trace pode mostrar um caminho de chamada lento, ou estatísticas do BD podem mostrar uma consulta dominando o tempo total. Escolha a menor área que explique a maior parte do custo: uma função, uma única query SQL ou uma chamada externa.
Uma boa hipótese é uma frase, testável e ligada a uma previsão. Você está pedindo ajuda para testar uma ideia, não pedindo uma ferramenta para magicamente deixar tudo mais rápido.
Use este formato:
Exemplo: "Porque o profile mostra 38% da CPU em SerializeResponse, alocar um buffer novo por requisição está causando picos de CPU. Se reutilizarmos um buffer, a latência p95 deve cair cerca de 10–20% e a CPU deve cair ~15% sob a mesma carga."
Mantenha-se honesto nomeando alternativas antes de tocar no código. Talvez a parte lenta seja uma dependência upstream, contenção de locks, mudança no hit rate do cache ou um rollout que aumentou o tamanho do payload.
Escreva 2 a 3 explicações alternativas e então escolha a que a evidência suporta melhor. Se sua mudança não mover a métrica, você já terá a próxima hipótese pronta.
Claude é mais útil no trabalho de performance quando você o trata como um analista cuidadoso, não como um oráculo. Mantenha cada sugestão ligada ao que você mediu e garanta que cada passo possa ser provado falso.
Dê entradas reais, não descrições vagas. Cole evidências pequenas e focadas: um sumário de profiling, algumas linhas de log ao redor da requisição lenta, um plano de consulta e o caminho de código específico. Inclua números "antes" (latência p95, tempo de CPU, tempo de BD) para que ele saiba sua baseline.
Peça para explicar o que os dados sugerem e o que não suportam. Então force explicações concorrentes. Um prompt valioso termina com: "Dê 2–3 hipóteses e, para cada uma, diga o que a falsificaria." Isso evita que a equipe se prenda à primeira história plausível.
Antes de mudar qualquer coisa, peça o menor experimento que valide a hipótese principal. Mantenha-o rápido e reversível: adicione um timer ao redor de uma função, habilite uma flag de profiler, ou rode uma query com EXPLAIN.
Se quiser uma estrutura apertada para saída, peça por:
Se não conseguir nomear uma métrica específica, localização e resultado esperado, você voltou a adivinhar.
Depois de ter evidência e hipótese, resista à vontade de "limpar tudo." Trabalho de performance é mais fácil de confiar quando a mudança de código é pequena e fácil de desfazer.
Mude uma coisa por vez. Se você ajustar uma query, adicionar cache e refatorar um loop no mesmo commit, não saberá o que ajudou (ou prejudicou). Mudanças de variável única tornam a próxima medição significativa.
Antes de tocar no código, anote o que você espera em números. Exemplo: "p95 deve cair de 420 ms para menos de 300 ms, e o tempo de BD deve cair ~100 ms." Se o resultado ficar aquém, você aprende rápido que a hipótese era fraca ou incompleta.
Mantenha as mudanças reversíveis:
"Mínimo" não significa "trivial." Significa focado: cachear o resultado de uma função cara, remover uma alocação repetida num loop apertado, ou parar de fazer trabalho para requisições que não precisam.
Adicione timings leves ao redor do gargalo suspeito para ver o que se moveu. Um único timestamp antes e depois de uma chamada (logado ou capturado como métrica) pode confirmar se sua mudança atingiu a parte lenta ou apenas deslocou o tempo para outro lugar.
Depois de uma mudança, rode exatamente o mesmo cenário que você usou para a baseline: mesmas entradas, ambiente e formato de carga. Se seu teste depende de caches ou warm-up, deixe isso explícito (por exemplo: "primeira execução fria, próximas 5 quentes"). Caso contrário você "encontrará" melhorias que foram apenas sorte.
Compare resultados usando a mesma métrica e os mesmos percentis. Médias podem esconder dor, então acompanhe p95 e p99, além de throughput e tempo de CPU. Rode repetições suficientes para ver se os números se estabilizam.
Antes de comemorar, cheque regressões que não aparecem num número de manchete:
Decida baseado em evidência, não em esperança. Se a melhoria for real e você não introduziu regressões, mantenha a mudança. Se os resultados forem mistos ou ruidosos, reverta e forme uma nova hipótese, ou isole ainda mais a alteração.
Se você trabalha em uma plataforma como Koder.ai, tirar um snapshot antes de experimentar pode transformar rollback em um único passo, o que facilita testar ideias ousadas com segurança.
Por fim, escreva o que aprendeu: baseline, mudança, novos números e conclusão. Esse registro curto evita que a próxima rodada repita os mesmos becos sem saída.
O trabalho de performance costuma descarrilar quando você perde a linha entre o que mediu e o que mudou. Mantenha uma cadeia limpa de evidência para poder dizer, com confiança, o que fez as coisas melhorarem ou piorarem.
Os reincidentes:
Um exemplo pequeno: um endpoint parece lento, então você otimiza o serializer porque ele está quente num profile. Depois retesta com um dataset menor e parece mais rápido. Em produção o p99 piora porque o BD ainda era o gargalo e sua mudança aumentou o tamanho do payload.
Se usar Claude Code para propor correções, mantenha-o na coleira curta. Peça 1 a 2 mudanças mínimas que combinem com a evidência coletada e exija um plano de re-medir antes de aceitar um patch.
Reivindicações de velocidade desmoronam quando o teste é vago. Antes de comemorar, certifique-se de que pode explicar o que mediu, como mediu e o que mudou.
Comece nomeando uma métrica e registrando a baseline. Inclua os detalhes que alteram números: tipo de máquina, carga de CPU, tamanho do dataset, modo de build (debug vs release), feature flags, estado do cache e concorrência. Se você não conseguir recriar o setup amanhã, você não tem uma baseline.
Checklist:
Depois que os números melhorarem, faça um rápido passe de regressão. Verifique corretude (mesmos outputs), taxa de erro e timeouts. Observe efeitos colaterais como mais memória, picos de CPU, startup mais lento ou mais carga no BD. Uma mudança que melhora p95 mas dobra memória pode ser um trade-off ruim.
Uma equipe relata que GET /orders parece ok em dev, mas fica lento em staging com carga moderada. Usuários reclamam de timeouts, mas a latência média ainda parece "ok", que é uma armadilha clássica.
Primeiro, defina uma baseline. Sob um teste de carga estável (mesmo dataset, mesma concorrência, mesma duração), você registra:
Agora colete evidência. Um trace rápido mostra que o endpoint roda uma query principal por orders, depois itera e busca itens relacionados por order. Você também nota que a resposta JSON é grande, mas o tempo do BD domina.
Transforme isso em uma lista de hipóteses testáveis:
Peça uma mudança mínima que combine com a evidência mais forte: remover uma chamada N+1 óbvia buscando os itens em uma única query com chave por order IDs (ou adicionar o índice faltante se o plano de execução mostrar scan completo). Mantenha reversível e em um commit focado.
Re-meça com o mesmo teste de carga. Resultados:
Decisão: enviar a correção (ganho claro) e então iniciar um segundo ciclo focado na lacuna restante e nos picos de CPU, já que o BD não é mais o limitador principal.
A maneira mais rápida de melhorar investigações de performance é tratar cada execução como um pequeno experimento repetível. Quando o processo é consistente, os resultados ficam mais fáceis de confiar, comparar e compartilhar.
Um template simples de uma página ajuda:
Decida onde essas notas vivem para que não desapareçam. Um lugar compartilhado importa mais que a ferramenta perfeita: uma pasta no repositório ao lado do serviço, um doc de time ou notas do ticket. O importante é que seja encontrável. Alguém deve conseguir achar "p95 spike após mudança de cache" meses depois.
Faça experimentos seguros um hábito. Use snapshots e rollback fácil para tentar ideias sem medo. Se você está construindo com Koder.ai, o Planning Mode pode ser um lugar conveniente para esboçar o plano de medição, definir a hipótese e manter a mudança no escopo antes de gerar um diff enxuto e re-medir.
Defina uma cadência. Não espere incidentes. Adicione checagens pequenas de performance após mudanças como novas queries, novos endpoints, payloads maiores ou upgrades de dependência. Um check de baseline de 10 minutos agora pode poupar um dia de adivinhação depois.
Comece com um número que corresponda à reclamação, normalmente latência p95 para um endpoint e entrada específicos. Registre uma baseline nas mesmas condições (tamanho dos dados, concorrência, cache aquecido/frio), depois mude uma coisa e re-meça.
Se você não conseguir reproduzir a baseline, você ainda não está medindo — está adivinhando.
Uma boa baseline inclui:
Anote antes de tocar no código para não mover o alvo.
Percentis mostram melhor a experiência do usuário que uma média. p50 é o “típico”, mas os usuários reclamam da cauda lenta, que são p95/p99.
Se p50 melhora mas p99 piora, o sistema pode parecer mais lento mesmo que a média pareça melhor.
Use timings simples quando a pergunta for “está mais lento e quanto?” Use profiling quando a pergunta for “para onde o tempo está indo?”
Um fluxo prático: confirme a regressão com timings de requisição, então rode um profiler apenas depois de saber que a lentidão é real e está bem delimitada.
Escolha uma métrica primária e trate o resto como guardrails. Um conjunto comum é:
Isso evita “ganhar” em um gráfico enquanto causa timeouts, crescimento de memória ou piora da cauda.
Escreva uma hipótese de uma frase ligada a evidência e previsão:
Se você não conseguir nomear a evidência e o movimento esperado da métrica, a hipótese não é testável ainda.
Faça pequeno, focado e fácil de desfazer:
Diffs pequenos tornam a próxima medição significativa e reduzem o risco de quebrar comportamento enquanto persegue velocidade.
Rerun o mesmo passo de teste (mesmas entradas, carga, ambiente, regras de cache). Então cheque regressões além do número principal:
Se os resultados estiverem ruidosos, colete mais amostras ou reverta e aperfeiçoe o experimento.
Dê entradas concretas e force uma abordagem test-driven:
Se a saída não incluir métrica específica e plano de re-teste, você está voltando à adivinhação.
Pare quando:
O fluxo (medir → hipotetizar → mudar → re-medir) ajuda a gastar tempo só onde os números provam que vale a pena.