21 de set. de 2025·8 min
Como C e C++ ainda sustentam sistemas operacionais, bancos de dados e motores de jogo
Veja como C e C++ ainda formam o núcleo de sistemas operacionais, bancos de dados e motores de jogo — por meio de controle de memória, velocidade e acesso de baixo nível.
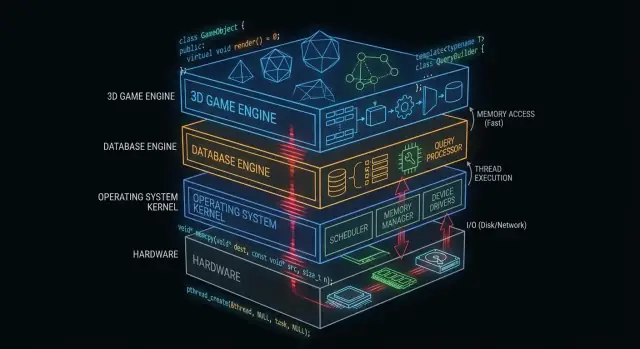
Por que C e C++ ainda importam nos bastidores
“O que está sob o capô” é tudo de que seu app depende, mas raramente toca diretamente: núcleos de sistemas operacionais, drivers de dispositivo, motores de armazenamento de bancos de dados, pilhas de rede, runtimes e bibliotecas críticas de desempenho.
Em contraste, o que muitos desenvolvedores de aplicações veem no dia a dia é a superfície: frameworks, APIs, runtimes gerenciados, gerenciadores de pacotes e serviços em nuvem. Essas camadas são construídas para serem seguras e produtivas — mesmo quando intencionalmente escondem complexidade.
Por que algumas camadas precisam ficar próximas ao hardware
Alguns componentes de software têm requisitos difíceis de atender sem controle direto:
- Desempenho e latência previsíveis (por exemplo, escalonamento de CPU, tratamento de interrupções, streaming de assets)
- Controle preciso de memória (layout, alinhamento, comportamento de cache, evitar pausas)
- Acesso direto ao hardware (registradores, DMA, drivers, sistemas de arquivos e dispositivos de bloco)
- Binários pequenos e portáteis que podem rodar cedo no boot ou em ambientes restritos
C e C++ continuam comuns aqui porque compilam para código nativo com sobrecarga mínima de runtime e dão aos engenheiros controle fino sobre memória e chamadas de sistema.
Onde C e C++ são mais comuns hoje
Em alto nível, você vai encontrar C e C++ alimentando:
- Núcleos de sistemas operacionais e bibliotecas de baixo nível
- Drivers e firmware embarcado
- Motores de banco de dados (execução de consultas, armazenamento, indexação)
- Motores de jogo e subsistemas em tempo real (renderização, física, áudio)
- Compiladores, toolchains e runtimes de linguagens dos quais outras linguagens dependem
O que este post vai (e não vai) cobrir
Este artigo foca na mecânica: o que esses componentes “dos bastidores” fazem, por que se beneficiam de código nativo e quais trade-offs vêm com esse poder.
Não vai afirmar que C/C++ são a melhor escolha para todo projeto, nem virar uma guerra de linguagens. O objetivo é uma compreensão prática de onde essas linguagens ainda justificam seu uso — e por que pilhas de software modernas continuam a se apoiar nelas.
O que torna C e C++ adequadas para software de sistemas
C e C++ são amplamente usadas para software de sistemas porque permitem programas “próximos ao metal”: pequenos, rápidos e fortemente integrados com o sistema operacional e o hardware.
Compiladas para código nativo (em linguagem simples)
Quando código em C/C++ é compilado, ele vira instruções máquina que a CPU pode executar diretamente. Não há um runtime obrigatório traduzindo instruções enquanto o programa roda.
Isso importa para componentes de infraestrutura — kernels, motores de banco de dados, motores de jogo — onde até pequenas sobrecargas podem se acumular sob carga.
Desempenho previsível para a infraestrutura central
Software de sistema frequentemente precisa de temporizações consistentes, não apenas boa velocidade média. Por exemplo:
- Um escalonador do sistema operacional deve responder rapidamente sob carga.
- Um banco de dados deve manter a latência estável enquanto muitos usuários consultam simultaneamente.
- Um motor de jogo deve cumprir um orçamento de frame (por exemplo, ~16 ms para 60 FPS).
C/C++ fornecem controle sobre uso de CPU, layout de memória e estruturas de dados, o que ajuda engenheiros a atingir desempenho previsível.
Acesso direto à memória e ponteiros
Ponteiros permitem trabalhar com endereços de memória diretamente. Esse poder pode soar intimidante, mas desbloqueia capacidades que muitas linguagens de nível mais alto abstraem:
- Alocadores personalizados afinados para cargas de trabalho específicas
- Formatos compactos em memória (úteis em bancos de dados e caches)
- Padrões de I/O zero-copy, onde os dados não são duplicados repetidamente
Usado com cuidado, esse nível de controle pode entregar ganhos dramáticos de eficiência.
Trade-offs: segurança, complexidade e tempo de desenvolvimento
A mesma liberdade é também o risco. Trade-offs comuns incluem:
- Segurança: erros podem causar crashes, corrupção de dados ou vulnerabilidades.
- Complexidade: gerenciamento manual de memória e comportamento indefinido exigem disciplina.
- Tempo de desenvolvimento: testes, revisão e tooling tornam-se inegociáveis para confiabilidade.
Uma abordagem comum é manter o núcleo crítico de desempenho em C/C++ e rodeá-lo com linguagens mais seguras para recursos de produto e UX.
C/C++ em núcleos de sistemas operacionais
O núcleo do sistema operacional fica mais próximo do hardware. Quando seu laptop acorda, seu navegador abre ou um programa pede mais RAM, o kernel está coordenando essas requisições e decidindo o que acontece em seguida.
O que um kernel realmente faz
Na prática, kernels cuidam de alguns trabalhos centrais:
- Escalonamento: decidir qual programa (e qual thread) recebe tempo de CPU, e por quanto tempo.
- Gerenciamento de memória: distribuir memória para processos, mantê-los isolados e recuperar memória com segurança.
- Gerenciamento de dispositivos: conversar com hardware via drivers (disco, rede, teclado, GPU etc.).
- Fronteiras de segurança: aplicar permissões para que um programa não leia ou corrompa dados de outro.
Como essas responsabilidades estão no centro do sistema, o código do kernel é sensível tanto a desempenho quanto a correção.
Por que o controle preciso favorece C (e às vezes C++)
Desenvolvedores de kernel precisam de controle preciso sobre:
- Layout de memória: estruturas de tamanho fixo, alinhamento e comportamento previsível de alocação.
- Instruções de CPU e convenções de chamada: interagir com interrupções, trocas de contexto e sincronização de baixo nível.
- Registradores de hardware: ler/escrever endereços específicos e lidar com modos especiais da CPU.
C permanece uma “linguagem de kernel” comum porque mapeia bem para conceitos em nível de máquina, permanecendo legível e portátil entre arquiteturas. Muitos kernels também dependem de assembly para as partes mais pequenas e específicas do hardware, com C fazendo a maior parte do trabalho.
C++ pode aparecer em kernels, mas geralmente num estilo restrito (recursos de runtime limitados, políticas estritas sobre exceções e regras rígidas sobre alocação). Onde é usado, costuma melhorar abstrações sem abrir mão do controle.
Código adjacente ao kernel frequentemente escrito em C/C++
Mesmo quando o kernel em si é conservador, muitos componentes próximos são C/C++:
- Drivers de dispositivo (especialmente os de alto desempenho)
- Bibliotecas padrão e runtimes (partes do libc, threading de baixo nível)
- Bootloaders e código de inicialização precoce
- Serviços do sistema que precisam de velocidade nativa (por exemplo, auxiliares de rede ou armazenamento)
Para saber mais sobre como drivers fazem a ponte entre software e hardware, veja /blog/device-drivers-and-hardware-access.
Drivers de dispositivo e acesso ao hardware
Drivers traduzem entre o sistema operacional e o hardware físico — placas de rede, GPUs, controladores SSD, dispositivos de áudio e mais. Quando você clica em “play”, copia um arquivo ou se conecta ao Wi‑Fi, um driver costuma ser o primeiro código a responder.
Como drivers ficam no caminho quente do I/O, são extremamente sensíveis a desempenho. Alguns microssegundos extras por pacote ou por requisição de disco podem se somar rapidamente em sistemas ocupados. C e C++ continuam comuns aqui porque podem chamar APIs do kernel diretamente, controlar o layout de memória com precisão e rodar com sobrecarga mínima.
Interrupções, DMA e por que APIs de baixo nível importam
Hardware não “espera sua vez” educadamente. Dispositivos sinalizam a CPU via interrupções — notificações urgentes de que algo aconteceu (um pacote chegou, uma transferência terminou). Código de driver deve tratar esses eventos de forma rápida e correta, muitas vezes sob restrições temporais e de threading.
Para alto throughput, drivers também dependem de DMA (Direct Memory Access), onde dispositivos leem/gravam memória do sistema sem o CPU copiar cada byte. Preparar DMA normalmente envolve:
- Preparar buffers no formato e alinhamento certos
- Passar ao dispositivo endereços físicos ou descritores mapeados
- Sincronizar a propriedade da memória entre dispositivo e CPU
Essas tarefas exigem interfaces de baixo nível: registradores mapeados em memória, flags de bits e ordenação cuidadosa de leituras/gravações. C/C++ tornam prático expressar essa lógica “próxima ao metal” mantendo portabilidade entre compiladores e plataformas.
Estabilidade é inegociável
Diferente de um app normal, um bug de driver pode travar o sistema inteiro, corromper dados ou abrir brechas de segurança. Esse risco molda como o código de driver é escrito e revisado.
Times reduzem o perigo usando padrões de codificação rigorosos, checagens defensivas e revisões em camadas. Práticas comuns incluem limitar o uso inseguro de ponteiros, validar entradas do hardware/firmware e rodar análise estática na CI.
Gerenciamento de memória: poder e armadilhas
Mantenha o código nativo isolado
Prototipe uma interface FFI e conecte seu app ao código C ou C++ existente.
O gerenciamento de memória é uma das maiores razões pelas quais C e C++ ainda dominam partes de sistemas operacionais, bancos de dados e motores de jogo. Também é um dos lugares mais fáceis para criar bugs sutis.
O que “gerenciamento de memória” significa
Na prática, gerenciamento de memória inclui:
- Alocar memória (obter um bloco para armazenar dados)
- Liberar (devolver quando não for mais usado)
- Lidar com fragmentação (buracos remanescentes que tornam futuras alocações mais lentas ou difíceis)
Em C, isso costuma ser explícito (malloc/free). Em C++, pode ser explícito (new/delete) ou envolvido em padrões mais seguros.
Por que o controle manual pode ser vantagem
Em componentes críticos de desempenho, o controle manual pode ser um recurso:
- Você pode evitar pausas imprevisíveis de um coletor de lixo.
- Pode escolher onde e como a memória é alocada (por exemplo, alocadores em pool ou arena), melhorando a consistência.
- Pode adaptar padrões de alocação à carga real (muitos objetos pequenos vs. grandes buffers contíguos).
Isso importa quando um banco de dados precisa manter latência estável ou um motor de jogo precisa cumprir o orçamento de frame.
Modos comuns de falha (e por que são graves)
A mesma liberdade cria problemas clássicos:
- Vazamentos de memória: esquecer de liberar, fazendo o uso crescer até degradar ou travar o processo.
- Buffer overflows: escrever além do fim de um array, corrompendo dados ou permitindo exploits.
- Use-after-free: usar um ponteiro após liberá-lo, levando a crashes difíceis de reproduzir.
Esses bugs podem ser sutis porque o programa pode “parecer bem” até que uma carga específica desencadeie a falha.
Como práticas modernas ajudam
C++ moderno reduz risco sem abrir mão do controle:
- RAII (Resource Acquisition Is Initialization) liga o tempo de vida de recursos ao escopo para que a limpeza ocorra automaticamente.
- Smart pointers (como
std::unique_ptrestd::shared_ptr) deixam a propriedade explícita e previnem muitos vazamentos. - Sanitizers (AddressSanitizer, UndefinedBehaviorSanitizer) e análise estática detectam problemas cedo, muitas vezes na CI.
Usadas corretamente, essas ferramentas mantêm C/C++ rápidos e reduzem a probabilidade de bugs de memória chegarem à produção.
Concorrência e desempenho em múltiplos núcleos
CPUs modernas não estão ficando dramaticamente mais rápidas por núcleo — elas estão ganhando mais núcleos. Isso muda a questão de desempenho de “Quão rápido é meu código?” para “Quão bem meu código roda em paralelo sem se atrapalhar?” C e C++ são populares aqui porque permitem controle de baixo nível sobre threads, sincronização e comportamento de memória com pouquíssima sobrecarga.
Threads, núcleos e escalonamento
Uma thread é a unidade que seu programa usa para fazer trabalho; um núcleo de CPU é onde esse trabalho roda. O escalonador do sistema operacional mapeia threads executáveis para núcleos disponíveis, fazendo trade-offs constantemente.
Detalhes pequenos de escalonamento importam em código crítico: pausar uma thread no momento errado pode bloquear um pipeline, criar filas de espera ou produzir comportamento intermitente. Para trabalho bound à CPU, manter threads ativas alinhadas com o número de núcleos frequentemente reduz thrashing.
Noções básicas de bloqueio: mutexes, atomics e contenção
- Mutexes são fáceis de raciocinar, mas compartilhamento intenso cria contenção — tempo gasto esperando em vez de trabalhando.
- Atomics podem ser mais rápidos para pequenas atualizações de estado compartilhado, mas exigem projeto cuidadoso para evitar bugs sutis de correção.
O objetivo prático não é “nunca travar”. É: travar menos, travar com inteligência — manter seções críticas pequenas, evitar locks globais e reduzir estado mutável compartilhado.
Por que picos de latência importam
Bancos de dados e motores de jogo não se importam só com velocidade média — importam com pausas no pior caso. Um combo de bloqueios, page fault ou trabalhador parado pode causar stutter visível ou uma query lenta que viola um SLA.
Padrões comuns em C/C++
Muitos sistemas de alto desempenho dependem de:
- Pools de threads para reaproveitar trabalhadores e manter o escalonamento previsível.
- Filas work-stealing para balancear carga entre núcleos.
- Filas sem locks (em caminhos quentes selecionados) para reduzir bloqueios — usadas com cautela porque provar correção é mais difícil.
Esses padrões miram throughput estável e latência consistente sob pressão.
Motores de banco de dados: onde C/C++ entrega velocidade
Um motor de banco de dados não é só “armazenar linhas”. É um loop apertado de trabalho de CPU e I/O que roda milhões de vezes por segundo, onde pequenas ineficiências se somam rápido. Por isso muitos motores e componentes centrais ainda são escritos majoritariamente em C ou C++.
O trabalho principal do motor: parsear, planejar, executar
Quando você envia SQL, o motor:
- Parseia (transforma texto em representação estruturada)
- Planeja (escolhe uma forma eficiente de responder à consulta)
- Executa (scans, buscas em índice, joins, ordenações, agregações e retorna linhas)
Cada etapa se beneficia de controle cuidadoso de memória e tempo de CPU. C/C++ habilitam parsers rápidos, menos alocações durante o planejamento e um caminho de execução enxuto — frequentemente com estruturas de dados customizadas para a carga de trabalho.
Motores de armazenamento: páginas, índices, buffering
Abaixo da camada SQL, o engine de armazenamento trata dos detalhes essenciais:
- Páginas: dados são lidos/grávados em blocos de tamanho fixo, não linha a linha.
- Índices: B-trees, LSM-trees e estruturas relacionadas precisam ser atualizadas eficientemente.
- Buffering: um buffer pool decide o que fica em memória, o que é expulso e como leituras/gravações são agrupadas.
C/C++ se encaixam bem aqui porque esses componentes dependem de layout previsível de memória e controle direto sobre as fronteiras de I/O.
Estruturas de dados amigáveis ao cache (por que importa)
O desempenho moderno muitas vezes depende mais de caches de CPU do que de velocidade bruta do core. Com C/C++, desenvolvedores podem agrupar campos frequentemente usados, armazenar colunas em arrays contíguos e minimizar chasing por ponteiros — padrões que mantêm dados próximos à CPU e reduzem stalls.
Onde linguagens de nível mais alto ainda aparecem
Mesmo em bancos de dados pesados em C/C++, linguagens de nível mais alto costumam alimentar ferramentas de administração, backups, monitoramento, migrações e orquestração. O núcleo crítico de desempenho permanece nativo; o ecossistema ao redor prioriza velocidade de iteração e usabilidade.
Armazenamento, cache e I/O em bancos de dados
Pratique o pensamento de performance
Crie um dashboard interno para explorar conceitos básicos de desempenho e latência com endpoints reais.
Bancos de dados parecem instantâneos porque trabalham pesado para evitar o disco. Mesmo em SSDs rápidos, ler do armazenamento é ordens de magnitude mais lento do que ler da RAM. Um motor escrito em C ou C++ pode controlar cada passo dessa espera — e muitas vezes evitá-la.
Buffer pool e page cache em termos cotidianos
Pense nos dados em disco como caixas em um armazém. Buscar uma caixa (leitura de disco) leva tempo, então você mantém os itens mais usados numa mesa (RAM).
- Buffer pool: a “mesa” do banco, mantendo páginas recentemente usadas (blocos de tamanho fixo de tabelas e índices).
- Page cache: a “mesa” do sistema operacional, cacheando dados de arquivo recentemente lidos.
Muitos bancos gerenciam seu próprio buffer pool para prever o que deve ficar quente e evitar disputar memória com o OS.
Por que disco é lento — e como cache o esconde
Armazenamento não é só lento; é imprevisível. Picos de latência, filas e acesso aleatório adicionam atrasos. Cache mitiga isso ao:
- Servir leituras da RAM na maior parte das vezes
- Agrupar gravações em operações de I/O maiores e menos frequentes
- Fazer prefetch de páginas prováveis de serem necessárias em seguida (por exemplo, durante scans de índice)
Decisões de projeto que se beneficiam de controle de baixo nível
C/C++ permite que motores de banco de dados ajustem detalhes que importam em alto throughput: leituras alinhadas, I/O direto vs. bufferizado, políticas de expulsão customizadas e layouts em memória cuidadosamente estruturados para índices e buffers de log. Essas escolhas podem reduzir cópias, evitar contenção e manter caches de CPU com dados úteis.
Compressão e checksums podem ficar bound à CPU
Cache reduz I/O, mas aumenta trabalho de CPU. Descomprimir páginas, calcular checksums, criptografar logs e validar registros podem virar gargalos. Como C e C++ oferecem controle sobre padrões de acesso à memória e loops amigáveis a SIMD, costumam ser usados para extrair mais trabalho de cada core.
Motores de jogo: restrições em tempo real
Motores de jogo operam sob expectativas estritas de tempo real: o jogador move a câmera, aperta um botão e o mundo deve responder imediatamente. Isso é medido em tempo de frame, não em throughput médio.
Orçamentos de frame: por que milissegundos importam
A 60 FPS, você tem cerca de 16,7 ms para produzir um frame: simulação, animação, física, mixagem de áudio, culling, submissão de render e frequentemente streaming de assets. A 120 FPS, esse orçamento cai para 8,3 ms. Perder o orçamento é percebido como stutter, input lag ou ritmo inconsistente.
É por isso que programação em C e programação em C++ continuam comuns nos núcleos dos motores: desempenho previsível, baixa sobrecarga e controle fino sobre memória e uso de CPU.
Subsistemas centrais frequentemente em C/C++
A maioria dos motores usa código nativo para o trabalho pesado:
- Renderização (travessia de cena, construção de draw-calls, gerenciamento de recursos GPU)
- Física (detecção de colisões, restrições, corpos rígidos)
- Animação (blending esquelético, IK, avaliação de poses)
- Áudio (mixagem em tempo real, espacialização)
Esses sistemas rodam a cada frame, então pequenas ineficiências se multiplicam rapidamente.
Loops apertados e layout de dados
Boa parte do desempenho em jogos vem de loops apertados: iterar entidades, atualizar transforms, testar colisões, skinning de vértices. C/C++ facilita estruturar memória para eficiência de cache (arrays contíguos, menos alocações, menos indireções virtuais). O layout dos dados pode importar tanto quanto a escolha do algoritmo.
Onde scripting se encaixa (e onde não)
Muitos estúdios usam linguagens de script para lógica de gameplay — quests, regras de UI, triggers — porque a velocidade de iteração importa. O núcleo do motor normalmente permanece nativo, e scripts chamam sistemas em C/C++ através de bindings. Um padrão comum: scripts orquestram; C/C++ executa as partes caras.
Compiladores, toolchains e interoperabilidade
Crie pelo chat
Crie uma app React, Go ou Flutter a partir de um simples chat com Koder.ai.
C e C++ não só “rodam” — elas são transformadas em binários nativos que casam com uma CPU e um sistema operacional específicos. Esse pipeline de build é uma grande razão pela qual essas linguagens permanecem centrais a sistemas operacionais, bancos de dados e motores de jogo.
O que realmente acontece durante um build
Uma build típica tem algumas etapas:
- Compilador: transforma código-fonte C/C++ em arquivos-objeto específicos da máquina.
- Linker: costura objetos com bibliotecas para produzir um executável ou biblioteca compartilhada.
- Saída binária: o artefato final que o SO pode carregar diretamente (frequentemente com símbolos de depuração separados).
É na etapa de link que muitos problemas do mundo real aparecem: símbolos faltando, versões de bibliotecas incompatíveis ou flags de build divergentes.
Por que toolchains e suporte de plataforma importam
Um toolchain é o conjunto completo: compilador, linker, biblioteca padrão e ferramentas de build. Para software de sistemas, cobertura de plataformas costuma ser decisiva:
- SDKs de consoles e mobile podem requerer compiladores e linkers específicos.
- Bancos de dados e software backend precisam de builds estáveis em distribuições Linux e tipos de CPU.
- Trabalho em OS e drivers pode requerer cross-compilers, flags rígidas e disciplina de ABI.
Times muitas vezes escolhem C/C++ também porque toolchains são maduros e disponíveis em muitos ambientes — de dispositivos embarcados a servidores.
Interfacing com outras linguagens (FFI)
C é frequentemente tratado como o “adaptador universal”. Muitas linguagens conseguem chamar funções C via FFI, então times costumam colocar lógica crítica de desempenho em uma biblioteca C/C++ e expor uma API pequena para código de nível mais alto. Por isso Python, Rust, Java e outros frequentemente empacotam componentes C/C++ existentes em vez de reescrevê-los.
Depuração e profiling: o que os times medem
Times C/C++ tipicamente medem:
- Tempo de CPU (funções quentes, pilhas de chamada)
- Uso de memória (alocações, vazamentos, fragmentação)
- Latência (tempo de frame em jogos, tempo de consulta em bancos)
- Comportamento de I/O (cache misses, leituras de disco, syscalls)
O fluxo é consistente: encontrar o gargalo, confirmar com dados e então otimizar a menor peça que importe.
Escolhendo C/C++ hoje: guia prático de decisão
C e C++ continuam excelentes ferramentas — quando você está construindo software onde alguns milissegundos, alguns bytes ou uma instrução CPU específica realmente importam. Não são a escolha padrão para toda funcionalidade ou time.
Quando C/C++ é a escolha certa
Escolha C/C++ quando o componente for crítico para desempenho, precisar de controle de memória apertado ou tiver de integrar-se intimamente ao sistema operacional ou hardware.
Ajustes típicos incluem:
- Caminhos quentes onde a latência é visível (parsing, compressão, render, execução de consultas)
- Módulos de baixo nível que precisam ser previsíveis (alocadores, escalonadores, primitivos de rede)
- Bibliotecas multiplataforma onde o código nativo é o produto (SDKs, engines, embarcados)
- Situações onde portabilidade entre compiladores/toolchains é requisito forte
Quando preferir outras linguagens
Escolha uma linguagem de nível mais alto quando a prioridade for segurança, velocidade de iteração ou manutenibilidade em escala.
Frequentemente é mais sensato usar Rust, Go, Java, C#, Python ou TypeScript quando:
- O time é grande e há rotatividade esperada (menos “armadilhas” importa)
- A funcionalidade muda frequentemente e corretude pesa mais que espremer ciclos
- Você precisa de garantias fortes de segurança de memória
- Produtividade do desenvolvedor e pool de contratação são restrições maiores que velocidade bruta
Na prática, a maioria dos produtos é um misto: bibliotecas nativas para o caminho crítico e serviços/UIs em níveis mais altos para o restante.
Nota prática para times de aplicação (onde Koder.ai se encaixa)
Se você constrói principalmente web, backend ou recursos mobile, muitas vezes não precisa escrever C/C++ para se beneficiar dele — você o consome via SO, banco, runtime e dependências. Plataformas como Koder.ai exploram essa divisão: você pode produzir rapidamente apps React, backends Go + PostgreSQL ou apps Flutter via fluxo de trabalho guiado por chat, integrando componentes nativos quando necessário (por exemplo, chamando uma biblioteca C/C++ existente via FFI). Assim, a maior parte da superfície do produto fica em código de rápida iteração, sem ignorar onde código nativo é a ferramenta certa.
Checklist prático (componente a componente)
Faça estas perguntas antes de se comprometer:
- Isso está no caminho crítico? Meça primeiro; não chute.
- Quais são os modos de falha? Corrupção de memória em C/C++ pode ser catastrófica.
- Qual é a fronteira da interface? Dá para isolar o código nativo atrás de uma API pequena?
- Vocês têm a expertise? Revisão, testes e profiling são inegociáveis.
- Qual é o alvo de deploy? Consoles, embarcados, kernels e drivers costumam favorecer C/C++.
- Como vocês vão testar e perfilar? Planeje ferramentas e CI desde o dia 1.
Leituras sugeridas
- /blog/performance-profiling-basics
- /blog/memory-leaks-and-how-to-find-them
- /pricing